小白IT:Python的框架,应用最广泛的Web框架 Django~先了解和学习什么是http协议,以及Django 路由系统及框架模式
文章目录
- Django框架—web本质和http协议
- 一、Django基础之web框架的本质
-
- 1.什么是web框架
- 2.自定义web框架
- 二、HTTP超文本传输协议
-
- 1.http协议的简介
-
-
- 什么是http协议
- http发展
-
- 2.http协议概述
-
-
- HTTP协议概述
- HTTP实现前提
- HTTP实现过程
-
- 3.HTTP协议工作原理
-
- HTTP请求/响应的步骤**
-
- 例如:浏览器中输入url回车后会经历的流程
- HTTP请求的特点**
-
- 1.基于请求-响应的模式
- 2.无状态保存
- 3.无连接
- 4.http请求方法
-
-
- GET方法*
- HEAD方法
- POST方法*
- PUT方法
- DELETE方法
- TRACE方法
- OPTION方法
- CONNECT方法
- 注意
- get和post区别
-
- 5.http状态码
-
- 状态码分类
- 6.URL资源统一定位符
-
-
- 统一资源定位符组成
- url实例
-
- 7.http协议格式**
-
- http请求格式
- http响应格式
- 三、WSGI规范
-
- 1.WSGI规范由来
- 2.WSGI(Web Server Gateway Interface)
-
-
- environ参数
- start_response方法
-
- 3.python中的wsgiref模块
-
-
- wsgiref 模块
- wsgiref模块对于网页提交数据的获取
-
- 四、模板渲染jinja2
-
-
-
- 模块下载
- 使用方法
-
-
- Django框架—MTV模式和路由系统
- 一、MVC和MTV模式
-
- 1.MVC框架模式
- 2.MTV模式
- 二、Django基本命令
-
- 1.Django的安装
- 2.创建一个Django项目
-
-
- cmd中创建项目
- pycharm中创建项目
- 目录结构文件的意义
- 两种创建方式的区别
-
- 3.在项目中创建应用
- 4.启动Django项目
-
- 简单的Django项目实例
-
- 1.配置urls控制器
- 2.配置路径对应的视图函数
- 3.配置模板文件
-
- 配置login.html文件
- 配置index.html文件
- 4.注意项目路径下的settings文件配置
- 5.启动项目
- 三、视图层之路由配置系统(urls)
-
- 1.什么是url配置
-
-
- urls中的配置
- 参数说明
-
- 2.URLconf的正则字符串参数
-
- 1.简单正则匹配
-
- 几点注意
- 关于URL尾是否带斜杠
- 3.分组命名匹配
-
-
- 无名分组
- 有名分组
-
- 4.传递默认参数
- 5.命名URL(别名)和URL的反向解析
-
- 命名URL由来
- url的双向使用
-
- URL反查
- 如何使用
- 注意
- 6.别名的使用
-
- 什么是url别名
- 配置两种别名
-
- 1.给url请求路径配置别名
- 2.给静态文件配置别名
- 7.路由分发include
-
-
- 什么是路由分发
- 路由分发配置
-
- 8.命名空间模式
-
- 为什么使用命名空间
- 命名空间的使用
-
- 命名空间使用语法
Django框架—web本质和http协议
一、Django基础之web框架的本质
1.什么是web框架
web应用的本质就是一个socket服务端,用户使用的浏览器就是客户端。服务端基于客户端的请求作出对相应的响应,从而实现网络通信,这种应用程序结构就是一个web框架。
还记的什么是socket把?socket是基于应用层和传输层之间的一个抽象层,网络通信的数据都要按照一定协议来发送,而socket的功能就是帮助我们将数据根据不同协议封装好数据头,比如以太网头、ip头、tcp/tdp头。
那么当用户在浏览器一输入网址,会给服务端发送数据,那浏览器会发送什么数据?怎么发?这个谁来定?所以在应用层中也需要遵循一定的协议,这协议就是HTTP协议。
2.自定义web框架
其实通过socket和网络通信,我们完全可以自己写一个web框架,下面我们就基于socket实现一个最基本的web框架,让浏览器来请求,并将自己服务器下的页面返回给浏览器。
import socket
# 启动一个socket的服务端
server = socket.socket()
server.bind(('0.0.0.0',8001))
server.listen()
conn,addr = server.accept()
# 接受客户端的请求
client_msg = conn.recv(1024).decode('utf-8')
print(client_msg)
"""
socket帮我们封装了传输层以下的协议格式,我们无需操心,但是应用层也有它自己的协议需要我们遵循,如果不按照协议的格式发送消息,浏览器是无法识别的。
"""
# 基于浏览器的HTTP协议封装数据,发送给客户端
conn.send(b'HTTP/1.1 200 ok /r/n/r/n')
conn.send(b'welcome to visit!')
我们通过浏览器访问127.0.0.1:8001,发送请求,可以看到服务端收到的消息格式如下:
GET / HTTP/1.1Host: 127.0.0.1:8001Connection: keep-aliveCache-Control: max-age=0Upgrade-Insecure-Requests: 1User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3Accept-Encoding: gzip, deflate, brAccept-Language: zh-CN,zh;q=0.9
这个请求的消息就是按照HTTP协议的格式来发送的,接下来,我们就学习一下HTTP协议。
二、HTTP超文本传输协议
1.http协议的简介
什么是http协议
超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议。HTTP是万维网的数据通信的基础。
http协议位于位于OSI七层应用层中的协议,协议规定了在应用层请求和响应双发发送消息的消息格式。
http发展
HTTP的发展是由蒂姆·伯纳斯-李于1989年在欧洲核子研究组织(CERN)所发起。HTTP的标准制定由万维网协会(World Wide Web Consortium,W3C)和互联网工程任务组(Internet Engineering Task Force,IETF)进行协调,最终发布了一系列的RFC,其中最著名的是1999年6月公布的 RFC 2616,定义了HTTP协议中现今广泛使用的一个版本——HTTP 1.1。
2014年12月,互联网工程任务组(IETF)的Hypertext Transfer Protocol Bis(httpbis)工作小组将HTTP/2标准提议递交至IESG进行讨论,于2015年2月17日被批准。 HTTP/2标准于2015年5月以RFC 7540正式发表,取代HTTP 1.1成为HTTP的实现标准。
2.http协议概述
HTTP协议概述
HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。
通过使用网页浏览器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端口为80),我们称这个客户端为用户代理程序(user agent)。
应答的服务器上存储着一些资源,比如HTML文件和图像。我们称这个应答服务器为源服务器(origin server)。在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器、网关或者隧道(tunnel)。
HTTP实现前提
尽管TCP/IP协议是互联网上最流行的应用,但在HTTP协议中,并没有规定必须使用TCP/IP协议或它支持的层。
事实上,HTTP可以在任何互联网协议上,或其他网络上实现。HTTP假定其下层协议提供可靠的传输。
因此,任何能够提供这种保证的协议都可以被其使用。这就是为什么在TCP/IP协议中使用TCP作为其传输层。
HTTP实现过程
通常,由HTTP客户端发起一个请求,创建一个到服务器指定端口(默认是80端口)的TCP连接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态,比如"HTTP/1.1 200 OK",以及返回的内容,如请求的文件、错误消息、或者其它信息。
3.HTTP协议工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。
HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
HTTP请求/响应的步骤**
- 客户端连接到Web服务器
- 一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.luffycity.com。
- 发送HTTP请求
- 通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
- 服务器接受请求并返回HTTP响应
- Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
- 释放连接TCP连接
- 若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
- 客户端浏览器解析HTML内容
- 客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
例如:浏览器中输入url回车后会经历的流程
- 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
- 解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
- 浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
- 服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
- 释放 TCP连接;
- 浏览器将该 html 文本并显示内容;
HTTP请求的特点**
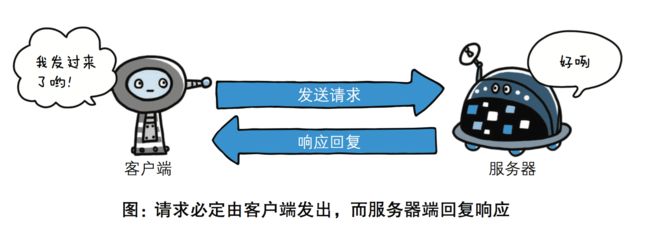
1.基于请求-响应的模式
HTTP协议规定,请求从客户端发出,最后服务器端响应该请求并 返回。也就是说,肯定是先从客户端开始建立通信的,服务器端在没有 接收到请求之前不会发送响应。
2.无状态保存
HTTP是一种不保存状态,即无状态(stateless)协议。
HTTP协议 自身不对请求和响应之间的通信状态进行保存。也就是说在HTTP这个级别,协议对于发送过的请求或响应都不做持久化处理。

使用HTTP协议,每当有新的请求发送时,就会有对应的新响应产 生。协议本身并不保留之前一切的请求或响应报文的信息。这是为了更快地处理大量事务,确保协议的可伸缩性,而特意把HTTP协议设计成 如此简单的。
无状态的特点也会导致一些业务问题变得棘手,比如用户需要反复登录页面,于是为了实现保持状态问题,引入了cookie技术。有了Cookie再用HTTP协议通信,就可以管 理状态了。
3.无连接
无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。
采用这种方式可以节省传输时间,并且可以提高并发性能,不能和每个用户建立长久的连接,请求一次相应一次,服务端和客户端就中断了。
无连接有两种方式:
- 早期的http协议是一个请求一个响应之后,直接就断开了
- 现在的http协议1.1版本不是直接就断开了,而是等几秒钟,这几秒钟是等什么呢,等着用户有后续的操作,可以避免短时间内多次连接,提高效率。
4.http请求方法
HTTP/1.1协议中共定义了八种方法(也叫“动作”)来以不同方式操作指定的资源:
GET方法*
向指定的资源发出“显示”请求。使用GET方法应该只用在读取数据,而不应当被用于产生“副作用”的操作中,例如在Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问。
HEAD方法
与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据)。
POST方法*
向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
PUT方法
向指定资源位置上传其最新内容。
DELETE方法
请求服务器删除Request-URI所标识的资源。
TRACE方法
回显服务器收到的请求,主要用于测试或诊断。
OPTION方法
这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用’*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
CONNECT方法
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的链接(经由非加密的HTTP代理服务器)。
注意
1.方法名称是区分大小写的。当某个请求所针对的资源不支持对应的请求方法的时候,服务器应当返回状态码405(Method Not Allowed),当服务器不认识或者不支持对应的请求方法的时候,应当返回状态码501(Not Implemented)。
2.HTTP服务器至少应该实现GET和HEAD方法,其他方法都是可选的。当然,所有的方法支持的实现都应当匹配下述的方法各自的语义定义。此外,除了上述方法,特定的HTTP服务器还能够扩展自定义的方法。例如PATCH(由 RFC 5789 指定的方法)用于将局部修改应用到资源。
get和post区别
- GET提交的数据会放在URL之后,也就是请求行里面,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456.(请求头里面那个content-type做的这种参数形式,后面讲) POST方法是把提交的数据放在HTTP包的请求数据中.
- GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
- GET与POST请求在服务端获取请求数据方式不同,就是我们自己在服务端取请求数据的时候的方式不同了,这句废话昂。
5.http状态码
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔。
状态码分类
状态代码的第一个数字代表当前响应的类型
-
1xx消息——请求已被服务器接收,继续处理
-
2xx成功——请求已成功被服务器接收、理解、并接受
-
3xx重定向——需要后续操作才能完成这一请求
-
4xx请求错误——请求含有词法错误或者无法被执行
-
5xx服务器错误——服务器在处理某个正确请求时发生错误

常见的状态码:
- 403:非法客户端,禁止请求
- 405:页面访问不存在
- 301:永久重定向
6.URL资源统一定位符
统一资源定位符组成
- 传送协议。
- 层级URL标记符号(为[//],固定不变)
- 访问资源需要的凭证信息(可省略)
- 服务器。(通常为域名,有时为IP地址)
- 端口号。(以数字方式表示,若为HTTP的默认值“:80”可省略)
- 路径。(以“/”字符区别路径中的每一个目录名称)
- 查询。(GET模式的窗体参数,以“?”字符为起点,每个参数以“&”隔开,再以“=”分开参数名称与数据,通常以UTF8的URL编码,避开字符冲突的问题)
- 片段。以“#”字符为起点
url实例
以为例http://www.luffycity.com:80/news/index.html?id=250&page=1 , 其中:
http是协议;www.luffycity.com,是服务器;80,是服务器上的默认网络端口号,默认不显示;/news/index.html,是路径(URI:直接定位到对应的资源);?id=250&page=1,是查询。
大多数网页浏览器不要求用户输入网页中“http://”的部分,因为绝大多数网页内容是超文本传输协议文件。同样,“80”是超文本传输协议文件的常用端口号,因此一般也不必写明。一般来说用户只要键入统一资源定位符的一部分(www.luffycity.com:80/news/index.html?id=250&page=1)就可以了。
由于超文本传输协议允许服务器将浏览器重定向到另一个网页地址,因此许多服务器允许用户省略网页地址中的部分,比如 www。从技术上来说这样省略后的网页地址实际上是一个不同的网页地址,浏览器本身无法决定这个新地址是否通,服务器必须完成重定向的任务。
7.http协议格式**
http请求格式
下面图片是http请求协议数据格式。
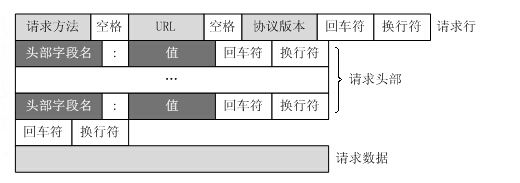
url中包含了路径和参数:/index/index2?a=1&b=2;
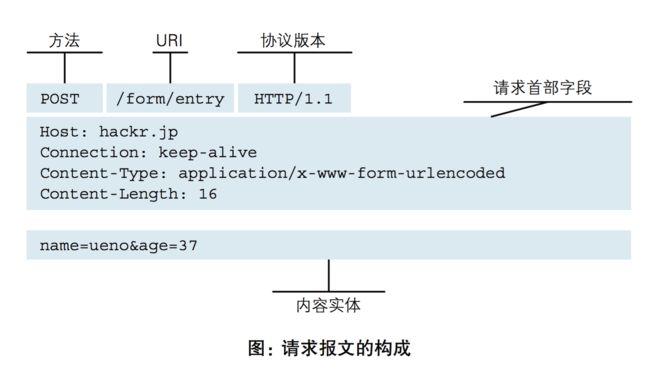
http响应格式

三、WSGI规范
1.WSGI规范由来
我们知道web应用就是服务端把写好的HTML文件根据请求发送给客户端,如果要动态生成HTML,那么读取HTML中的不同数据,接受请求,解析请求,发送响应,这些底层的代码都需要我们来自己来实现,那么会浪费大量的精力。
正缺的做法就是把这些底层代码由专门的服务器软件实现,而我们专注于生成HTML文档,以及处理响应的业务逻辑。因为我们不希望接触到TCP连接、HTTP原始请求和响应格式,所以,需要一个统一的接口,让我们专心用Python编写Web业务。
这个接口就是WSGI。
2.WSGI(Web Server Gateway Interface)
Web服务器网关接口(Web Server Gateway Interface, WSGI)用Python写的一个服务器软件和web应用之间的通用接口。定义了使用Python编写的web应用程序与web服务器程序之间的接口格式,实现web应用程序与web服务器程序间的解耦。
WSGI接口定义非常简单,它只要求Web开发者实现一个函数,就可以响应HTTP请求。我们来看一个最简单的Web版本的“Hello, web!”
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')]) # start_response作用是发送http消息格式的响应头。
"""中间写我们的业务逻辑代码"""
return 'Hello, web!
' # 函数返回数据交给wsgi中,wsgi会发送这个数据
上面的application()函数就是符合WSGI标准的一个HTTP处理函数,它接收两个参数:
- environ:一个包含所有HTTP请求信息的dict对象;
- start_response:一个发送HTTP响应的函数。
environ参数
environ是WSGI加工好的请求信息,加工成了一个字典,通过字典取值的方式就能拿到很多你想要拿到的信息。
environ["PATH_INFO"] # 获取请求的路径
environ["REQUEST_METHOD"] # 获取请求的方法
可以查看environ字典,查看详细的封装数据。
start_response方法
start_response('200 OK', [('Content-Type', 'text/html')])
在application()函数中,调用start_response,就发送了HTTP响应的Header,注意Header只能发送一次,也就是只能调用一次start_response()函数。start_response()函数接收两个参数,一个是HTTP响应码,一个是一组list表示的HTTP Header,每个Header用一个包含两个 str 的 tuple 表示。
3.python中的wsgiref模块
wsgiref 模块
Web server Gateway Interface references library web服务器网关接口参考库。Python标准库提供的独立WSGI服务器,帮助我们封装了socket、客户端请求消息、服务端响应消息的类。
wsgiref模块使用方法
wsgiref模块对于网页提交数据的获取
获取网页请求的方式,注意不同的请求方式获取数据的方式是不同的。
environ.get("REQUEST_METHOD") # 获取网页的请求方法
1.对于网页请求方式为GET的数据提取
GET方式的请求,数据的提交是将数据直接拼接在url后面。
request_data = environ['QUERY_STRING'] # 获取GET请求的数据
注:request_data是类似"username=chao&password=123"的字符串数据
2.对于网页请求方式为POST的数据提取
POST方式的请求,数据提交是将数据放在请求信息的请求数据中。
request_body_size = int(environ.get('CONTENT_LENGTH', 0)) # 先获取请求体中的数据长度
request_data = environ['wsgi.input'].read(request_body_size) # 在根据数据长度获取请求数据
注:request_data是一个bytes类型的数据,b"username=chao&password=123"
3.使用urllib.parse中的parse_qs类可以快速解析请求的数据
from urllib.parse import parse_qs
parse_data = parse_qs(request_data) # 解析获取的数据
注:解析后的数据是个字典,如{"password": ["123"], "username": ["chao"]}
四、模板渲染jinja2
一个第三方模块,帮助我们更简单的实现字符串替换,也就是模板渲染,然后再发送给浏览器完成渲染。本质上就是HTML内容中利用一些规定好的特殊符号来替换要展示的数据。替换字符串要遵循jinja指定的语法规则。
模块下载
pip install jinja2 # 或者在pycharm中安装 File->settings->project->Project interpreter
使用方法
HTML中使用一定规则特殊字符
1.使用 {{ 变量名 }} 来表示特殊符号,给变量占位。
2.使用 {% for 变量 in 变量列表 %} {{ 变量 }} {% endfor %}
python文件中使用
from jinja2 import Template
# 从html中读取字符串数据data
template = Template(data) # 生成模板文件
# render方法将数据填充到特殊字符中
ret = template.render({"name":"于谦", "hobby_list":["烫头","泡吧"]})
使用实例!
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="x-ua-compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Title</title>
</head>
<body>
<h1>姓名:{{name}}</h1>
<h1>爱好:</h1>
<ul>
{% for hobby in hobby_list %}
<li>{{hobby}}</li>
{% endfor %}
</ul>
</body>
</html>
from jinja2 import Template
def index():
with open("index2.html", "r",encoding='utf-8') as f:
data = f.read()
template = Template(data) # 生成模板文件
ret = template.render({"name": "于谦", "hobby_list": ["烫头", "泡吧"]}) # 把数据填充到模板里面
return [bytes(ret, encoding="utf8"), ]
Django框架—MTV模式和路由系统
一、MVC和MTV模式
1.MVC框架模式
MVC的全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,是一种软件设计典范。
MVC模式把Web应用分为模型(M),控制器©和视图(V)三层,他们之间以一种插件式的、松耦合的方式连接在一起,模型负责业务对象与数据库的映射(ORM),视图负责与用户的交互(页面),控制器接受用户的输入调用模型和视图完成用户的请求。
MVC是web开发的通用的模型,其他语言web开发中也遵循这个模式。
- M:model,模型;代表一个存取数据的对象,可以带有逻辑,在数据变化时更新控制器。
- V:view ,视图;代表模型包含的数据的可视化,也就是html文件。
- C:controller ,是应用程序中处理用户交互的部分,通常控制负责从视图中读取数据,控制用户输入,并向模型发送数据;

2.MTV模式
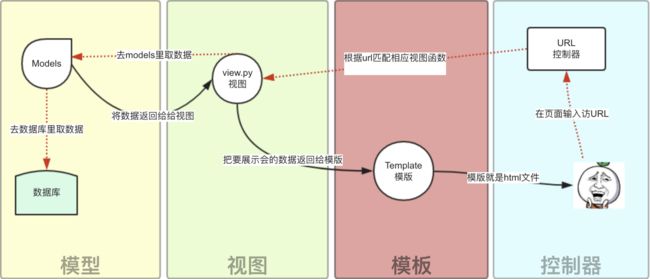
在Django中的web框架模式是MTV模式 Model–Template–View,本质上和MVC是一样的,将各个组件实现松耦合,只不过定义上有些许不同。
用户通过浏览器向我们的服务器发起一个请求(request),这个请求回去访问视图函数,(如果不涉及到数据调用,那么这个时候视图函数返回一个模板也就是一个网页给用户),视图函数调用模型,模型去数据库查找数据,然后逐级返回,视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。
- M:model,模型;负责业务对象和数据库的关系映射(ORM)
- T:templates,模板;负责如何把页面展示给用户(html),也就是html文件
- V:view,视图;负责业务逻辑,并在适当时候调用Model和Template。
在MTV模型中,除了上面三层以外,还有一个URL分发器,它的作用是将一个个URL的页面请求分发给不同的View处理,View再调用相应的Model和Template。
MTV的响应模式如下所示:
二、Django基本命令
1.Django的安装
1.cmd中使用pip命令安装。
注意:使用pip安装的时候,确认scripts添加到了环境变量中。
pip3 install django==1.11.x # 安装Django指定版本
2.使用pycharm安装
# File->settings->project->Project interpreter 搜索Django,安装即可,specify version 可以选择版本
2.创建一个Django项目
创建项目的两种方式
cmd中创建项目
在需要创建项目的路径下运行cmd,或者运行cmd切换到需要创建项目的路径下。执行
django-admin startproject mysite # 在需要创建项目的路径下执行
创建好的目录结构如下

pycharm中创建项目
File->create Project->Django
# 设置里面指定项目路径,和应用名
# 如果不指定应用名,创建后的目录结构和cmd中创建的是一样的。
目录结构文件的意义
- manage.py ----> Django项目里面的工具,通过它可以调用django shell和数据库,启动关闭项目与项目交互等,不管你将框架分了几个文件,必然有一个启动文件,其实他们本身就是一个文件。
- settings.py ----> 包含了项目的默认设置,包括数据库信息,调试标志以及其他一些工作的变量。
- urls.py ----> 负责把URL模式映射到应用程序。
- wsgi.py ----> runserver命令就使用wsgiref模块做简单的web server,后面会看到renserver命令,所有与socket相关的内容都在这个文件里面了,目前不需要关注它。
此时我们执行如下命令就可以启动Django项目了,只不过里面没有任何逻辑。
python manage.py runserver 127.0.0.1:8080 # 本机的话ip地址可以不填
注意:上面的目录结构中并没有view视图函数文件,我们要理解一个项目中,应该是有不用的应用来服务不同的业务,而在一定程度上这些应用都是独立的。view视图就应该是每个应用与应用之间相互独立拥有的,这样更利于我们对不同应用业务逻辑的管理。
而我们上面创建的项目中还没有创建应用,所以没有视图文件。
两种创建方式的区别
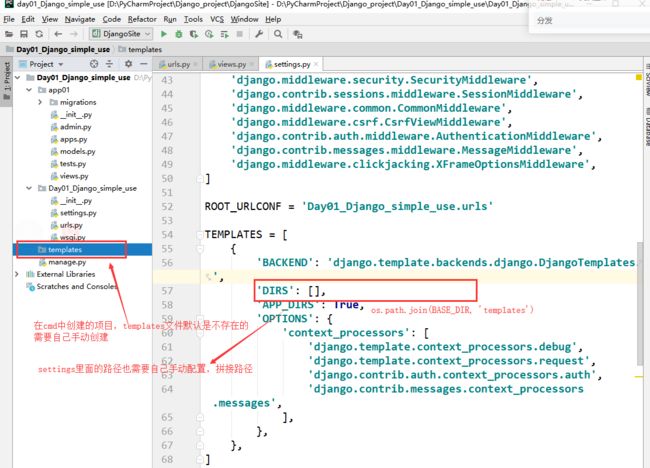
- 在cmd中创建的项目,不带应用文件,而pycharm中创建的项目,如果写了应用名,会创建;不写则不创建
- cmd中创建的项目,不带templates文件夹,而且settings文件中的TEMPLATES中DIR路径也是空的,需要自己配置后,里面的文件才能通过相对路径使用。而pycharm中创建的项目,自带templates文件夹,路径也给配置好了。
3.在项目中创建应用
创建应用的两种命令;
注意创建应用的方式只能在cmd中创建,需要切换到项目路径下执行。
# 第一种
python manage.py startapp 应用名
# 第二种
django-admin startapp 应用名
应用文件目录结构如下

- models.py :这个文件是存放与该app(应用)相关的数据表结构。
- views.py :存放与该app相关的视图函数的
4.启动Django项目
python manage.py runserver 127.0.0.1:8080 # 地址是本机就可以不用写ip地址 如果连端口都没写,默认是本机的8000端口
执行这个命令,django项目就启动了,当我们访问http://127.0.0.1:8080/时就可以看到

简单的Django项目实例
创建一个django项目,比如DjangoSite
python-admin startproject DjangoSite
创建一个应用app01
python manage.py startapp app01
1.配置urls控制器
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
# url(r'^admin/', admin.site.urls), # djando项目自带,可注释掉
url(r'^login/', views.login), # 配置自己的url路径
]
2.配置路径对应的视图函数
视图文件
from django.shortcuts import render,HttpResponse
def login(request): # request是django封装好的请求数据对象
if request.method == "GET": # 通过request的method属性,判断请求方式
name=input('请输入你的名字')
return render(request,"login.html",{"name":"xiaohei"})
# render方法用传递的字典数据来渲染login.html文件,通过return返回给前端。
# 注意login.html文件放在templates路径下,django帮我们配置好了路径,直接通过文件名就可以找到文件。
# {"name":"xiaohei"}是render替换html中特殊字符的数据,类似jinja2中的字符串替换。
else:
username = request.POST.get("username") # 获取post请求的数据,post请求数据封装在字典中
password = request.POST.get("password")
if username == "alex" and password == "alex": # 验证帐号密码
return render(request,"index.html")
else:
# 验证错误,发送一个http响应
return HttpResponse("滚犊子")
3.配置模板文件
django中的html文件都放在template中,
配置login.html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>欢迎:{{ name }}</h1>
<form action="login/" method="post">
帐号:<input type="text" name="username">
密码:<input type="password" name="password">
<input type="submit">
</form>
</body>
</html>
配置index.html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
来了小老弟
</body>
</html>
4.注意项目路径下的settings文件配置
settings文件下的middleware注释掉一样,不然无法正常启动
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
# 'django.middleware.csrf.CsrfViewMiddleware', # 需要注释掉这一行,涉及到csrf认证,以后再打开
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
settings文件中的INSTALLED_APPS添加应用名
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config', # 添加自己的应用,有几个添加几个,可以直接添加应用名字,如app01
]
5.启动项目
1.pycharm中启动项目
注意服务器的地址配置是通过下图地方配置,在这里修改服务器ip和端口。

2.cmd中启动服务
在项目文件路径下,cmd中执行命令
python manage.py runserver 127.0.0.1:8080
三、视图层之路由配置系统(urls)
1.什么是url配置
URL配置(URLconf)就像Django所支撑网站的目录。它的本质是URL与要为该URL调用的视图函数之间的映射表;
Django中是以这种方式告诉Django,对于不同的URL需要调用不同的视图函数,处理业务。
urls中的配置
from django.conf.urls import url
urlpatterns = [
url(正则表达式1, views视图函数1,参数,别名),
url(正则表达式2, views视图函数2,参数,别名),
# 等等
]
参数说明
- 正则表达式:一个正则表达式字符串
- views视图函数:一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
- 参数:可选的要传递给视图函数的默认参数(字典形式)
- 别名:一个可选的name参数
注意:这里传入的额外参数是字典形式的,也就是以关键字的参数传入,而且字典的键名要与views视图函数中的形参一致。
当有正则分组的参数传入时,注意分组参数是位置参数还是关键字参数,从而确认参数填写的顺序。
2.URLconf的正则字符串参数
1.简单正则匹配
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^articles/2003/$', views.special_case_2003),
url(r'^articles/([0-9]{4})/$', views.year_archive),
url(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive),
url(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail),
] # 根据不同的访问请求,通过正则匹配,来获取不同的视图处理函数
几点注意
- rulpatterns中的路径一但匹配成功则不再继续匹配
- 若要从URL中捕获一个值,需要把他们放在圆括号中。
- 匹配开头不需要添加反斜杠,每个URL中自带。
- 每个正则表达式前面的’r’,不是必须,但是推荐加上
- ^…& 以什么结尾,以什么开头,严格限制路径
关于URL尾是否带斜杠
关于路径结束是否带斜杠,在Django中,如果你访问的页面URL后没有带斜杠/,Django会返回301状态码,重定向URL,强制浏览器带上斜杠/在来请求。
取消这个设定方法,在settings中修改配置
APPEND_SLASH=False # 默认是True,修改False就取消了上述设定。
注意:取消这个设置后,如果我们访问时不带后面的斜杠,会访问不到页面。
3.分组命名匹配
无名分组
正则表达式分组匹配(通过圆括号)来捕获URL中的值并以位置参数形式传递给视图。
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^articles/(\d{4})/$', views.year_archive)
#year_archive(request,n),小括号为分组,有分组,那么这个分组得到的用户输入的内容,就会作为对应函数的位置参数传进去
]
有名分组
在更高级的用法中,可以使用分组命名匹配的正则表达式组来捕获URL中的值并以关键字参数形式传递给视图。
在Python的正则表达式中,分组命名正则表达式组的语法是(?Ppattern),其中name是组的名称,pattern是要匹配的模式。
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'r'^articles/(?P<year>[0-9]{4})/$', views.year_archive)
#year_archive(request,year),有名分组,给分组起个名字,那么这个分组得到的用户输入的内容,就会作为对应函数的关键字参数传进去,形参和命名需要一致。
]
注意:分组命名中捕获的数据,永远都是字符串,无论正则表达式使用什么匹配方式。
4.传递默认参数
views中的视图函数可以指定默认参数,如果没有实参覆盖,那么就只用默认参数,有的话使用传入的实参。
# urls.py中
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^blog/$', views.page),
url(r'^blog/page(?P[0-9]+)/$' , views.page),
]
# views.py中,可以为num指定默认值
def page(request, num="1"):
pass
5.命名URL(别名)和URL的反向解析
命名URL由来
在项目中,我们配置好的url路径可能会更改,如果说我们的路径更改了,那我们在前端页面中写入访问路径的所有标签(a标签、form表单等)里面的属性值全都需要手动更改,这样对于我们扩展修改就十分不方便,尤其是前端页面可能不是你写的,那么修改更加麻烦。
在Django项目中,一个常见的需求是获得URL的最终形式,以用于嵌入到生成的内容中(视图中和显示给用户的URL等)或者用于处理服务器端的导航(重定向等)。
但是我们又不希望使用硬编码(写死路径),所以我们需要一个能够DRY的机制,能够允许url自动更新而不用遍历项目的源代码来更换过期的url。
url的双向使用
Django提供了一个办法,只需在URL中提供一个name参数,并赋值一个你自定义的、好记的、直观的字符串。这样你就可以双向使用这个url。
- 根据用户/浏览器发起的URL 请求,它调用正确的Django 视图,并从URL 中提取它的参数需要的值。
- 根据Django 视图的标识和将要传递给它的参数的值,获取与之关联的URL。
第一种方式就是就是通过浏览器发起的url去调用正确的视图函数,并响应浏览器;
第二种方式叫做反向解析URL、反向URL匹配、反向URL查询、或URL反查。
URL反查
在需要URL的地方,对于不同层级,Django提供了不同的工具用于URL反查:
- 在模板文件中:使用URL模板标签
- 在python代码中:使用Django.core.urlresolvers.reverse()函数
- 在更高层的与处理Django模型实例相关的代码中:使用get_absolute_url()方法
简单来说,就是我们可以给我们的URL匹配规则起个名字,一个URL匹配模式起一个名字,这样就可以不写死URL代码了,只需要通过名字反向解析获取当前的URL。
如何使用
举个栗子,在url路由配置中为url取别名
url(r'^home', views.home, name='home'), # 给我的url匹配模式起名(别名)为 home,别名不需要改,在所有页面使用别名,这样前头路径你就可以随便改了
url(r'^index/(\d*)', views.index, name='ind'), # 给我的url匹配模式起名为index
在模板中可以这样使用
{% url 'home' %} #模板渲染的时候,被django解析成了这个名字对应的那个url,这个过程叫做反向解析
而在views函数中,可以使用reverse根据别名获取实际url路径
from django.urls import reverse
def redister(request):
path1 = reverse('ind') # 根据别名,反向解析获取实际url路径
if reqeust.method =="POST":
return redirect(path1) # 跳转页面
# return redirect("ind") # 也可以直接写别名,因为redirect内部调用了reverse方法
注意
- 使用url反查,需要命名url,命名url的名称可以包含任何你想用的字符
- 当命名你的URL 模式时,请确保使用的名称不会与其它应用中名称冲突。
- 为减少url名称与应用的冲突,建议使用前缀,如app01-comment
6.别名的使用
什么是url别名
urlconf中配置url路径时最后一个参数给url指定别名,这是一个可选的参数。
url别名的作用,在视图函数或者模板文件中使用别名后,无论urls中的匹配路径如何改变,都可以通过这个别名都能反解找到对应的访问路径或视图函数。而前端访问的路径还是需要符合匹配规则的,这样有利于后端开发的修改维护。
配置两种别名
1.给url请求路径配置别名
在url分发任务时,别名参数以关键字传递,如 name=“别名”,name是固定写法。
如果在模板文件也就是html文件中使用了该路径,则需要按照模板渲染的规则,写入 {% url “别名” %} 特殊字符,通过视图函数中的render方法,将路径通过反向解析替换为实际的访问路径,从而访问正确的url路径,返回正确的响应。
使用实例
<!DOCTYPE html>
<html lang="en">
<head> <meta charset="UTF-8"></head>
<body>
{#
{#
<form action="{% url 'log' %}" method="post"> {# 注意,action外部没有引号,大括号里面url 引号#}
<input type="text" name="user"> {# 注意,这里只能用name,不能用id哈 #}
<input type="password" name="pass"> {# 注意,这里只能用name,不能用id哈 #}
<input type="submit" value="submit">
</form>
</body>
</html>
from django.contrib import admin
from django.urls import path
from blog import views
from django.conf.urls import url
urlpatterns = [
# URL第四个参数别名操作,name="XXXX",name里面的值代表的是我们的URL路径
url(r'^login', views.login, name="log"), # 将路径名跟函数进行映射
]
from django.shortcuts import render, HttpResponse
import datetime
# URL之别名操作
def login(request):
if request.method == "POST":
username = request.POST.get("user")
password = request.POST.get("pass")
if username == "ryx" and password == "123":
print("username: %s password: %s" % (username, password))
return HttpResponse("登录成功".encode("utf8"))
return render(request, "login.html")
2.给静态文件配置别名
为应用中的静态文件static文件夹配置别名,访问网页时,无论后端静态文件夹路径如何修改,前端访问静态文件的路径始终不变。
- 在应用程序中新建static文件夹,用于存放应用的所有静态文件
- 在mysite的settings.py文件中配置静态文件路径
STATIC_URL = '/static/'
TEMPLATE_DIRS = (os.path.join(BASE_DIR, 'templates'),) # 原配置
# 静态资源文件
STATICFILES_DIRS = (os.path.join(BASE_DIR, "statics"),) # 现添加的配置,这里是元组或列表都可以,注意逗号
7.路由分发include
什么是路由分发
我们之前的url分发都配置在项目下的urls.py中,但是我们想过没有,一个项目下可能存在成百上千的应用,而我们将所有应用下的urls分发全部配置在项目下的urls中供全部app使用,会有多么混乱,耦合性太高,十分不利于管理维护。
django中在url分发中提供了一个分发接口,就是include方法。
At any point, your urlpatterns can “include” other URLconf modules. This
essentially “roots” a set of URLs below other ones.
For example, here’s an excerpt of the URLconf for the Django website itself.
It includes a number of other URLconfs:
路由分发配置
- 在项目文件根路径下的urls.py中配置每一个应用的路径分发
[ ](javascript:void(0)
](javascript:void(0)
from django.conf.urls import url,include
urlpatterns = [
# url(r'^admin/', admin.site.urls),
url(r'^app01/', include('app01.urls')), # 可以包含其他的URLconfs文件
url(r'^app02/',include('app02.urls')),
]
# 别忘了要去不同app路径下创建一个urls.py的文件,现在意思是凡是以app01开头的路径请求,都让它去找app01下的urls文件中去找对应的视图函数
注意一点:此时这个文件里面的那个app01路径不能用结尾,因为如果写了,就没办法比配上app01/后面的路径。
- 分别在不同应用下创建urls.py文件,分配当前应用的不同url请求
from django.conf.urls import url
#from django.contrib import admin
from app01 import views
# 被项目路径下的urls筛选后,对于app01的请求url全部分配到app01下的urls中再分配。
urlpatterns = [
# url(r'^admin/', admin.site.urls),
url(r'^articles/2003/', views.special_case_2003,{'foo':'xxxxx'}),
# {'foo':'xxxxx'},给视图函数传递额外的参数,而视图函数里面必须有个形参叫做foo来接收这个关键字参数。
url(r'^articles/(\d{4})/(\d{2})/', views.year_archive,name="articles"), # 同样可以取别名
]
8.命名空间模式
为什么使用命名空间
在django项目中,我们可能产生多个应用,多个应用之间的url路由,为了结构更加清晰,明朗,会使用路由分发将对应的url分配到不同的应用中。
而当我们应用数量很多,会不会出现这个问题,就是两个应用中的url别名出现了重复。
这个时候django,会按照app注册的顺序去寻找对应别名的url,但是因为别名重复了,我们发现django总是会找到第一个url,这样就会出现路由解析错误的问题。
命名空间的使用
项目下urls.py文件
from django.conf.urls import url, include
urlpatterns = [
url(r'^app01/', include('app01.urls', namespace='app01')), # 配置命名空间
url(r'^app02/', include('app02.urls', namespace='app02')),
]
app01中的urls.py
from django.conf.urls import url
from app01 import views
app_name = 'app01' # 指定应用名称app01
urlpatterns = [
url(r'^detail/(?P\d+)/$' , views.detail, name='detail')
]
app02中的url.py
from django.conf.urls import url
from app02 import views
app_name = 'app02' # 指定应用名app02
urlpatterns = [
url(r'^detail/(?P\d+)/$' , views.detail, name='detail')
]
以上这种情况,就出现了两个应用中url别名重复的问题,如果我们不定义应用的命名空间,直接使用别名,就会出现url反解错误的可能。
命名空间使用语法
`'命名空间名称:url名称'`
模板中使用
`{% url 'app01:detail' pk=12 %}`
views中视图函数
`v ``=` `reverse(``'app01:detail'``, kwargs``=``{``'pk'``:``12``})`
这样即使app中url重名,我么也可以反转正确的URL。
javascript:void(0))