通义千问 Qwen-7B-Chat-Int4 模型本地化部署

如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。
以本项目中默认使用的 LLM 模型 THUDM/ChatGLM2-6B 与 Embedding 模型 moka-ai/m3e-base 为例:
下载模型需要先安装 Git LFS,然后运行
参考:通义千问部署搭建_代码浪人的博客-CSDN博客
![]()
git clone https://www.modelscope.cn/qwen/Qwen-7B-Chat.git
git clone https://www.modelscope.cn/qwen/Qwen-7B-Chat-Int4.git
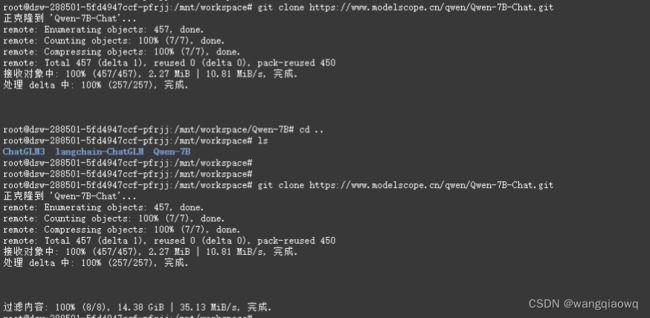
拉代码
git clone https://github.com/QwenLM/Qwen-7B.git
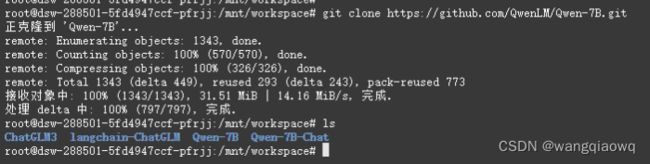

pip install -r requirements.txt

pip install -r requirements_web_demo.txt
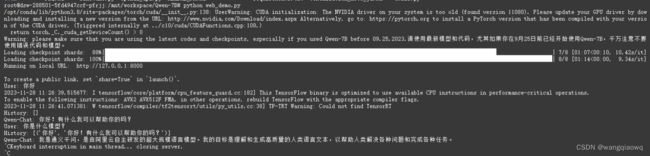
修改web_demo.py
启动:python web_demo.py

量化:(量化过程 报GPU版本问题 暂时未调通)
GPTQ
请注意:我们更新量化方案为基于 AutoGPTQ 的量化,提供Int4量化模型。该方案在模型评测效果几乎无损,且存储需求更低,推理速度更优。
以下我们提供示例说明如何使用Int4量化模型。在开始使用前,请先保证满足要求(如torch 2.0及以上,transformers版本为4.32.0及以上,等等),并安装所需安装包:
pip install auto-gptq optimum
随后即可使用和上述一致的用法调用量化模型:
下载:git clone https://www.modelscope.cn/qwen/Qwen-7B-Chat-Int4.git

没成功 一直报这个GPU版本的问题

nvidia-smi

Start Locally | PyTorch
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
conda info --envs
conda remove --name ancillary --all
-------------------------------------------------------------
参考:【PyTorch】PyTorch、Cuda 的安装和使用_cuda pytorch-CSDN博客
conda create -n pytorch python=3.8
进入: conda activate pytorch
nvcc --version
查看版本
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia

检查:
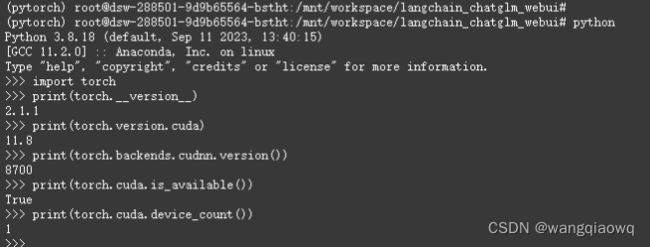
import torch
print(torch.__version__)
print(torch.version.cuda) # gpu
print(torch.backends.cudnn.version()) # cudnn
print(torch.cuda.is_available()) # gpu
print(torch.cuda.device_count())
退出:deactivate(参考)
pip install -r requirements.txt


再次启动 GPU 可以使用了。
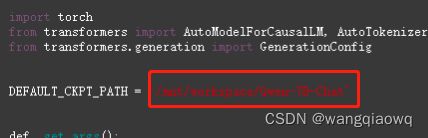
改用量化的模型

修改模型的路径后

参考:通义千问-7B-Chat-Int4 · 模型库 (modelscope.cn)
pip install modelscope
pip install auto-gptq optimum
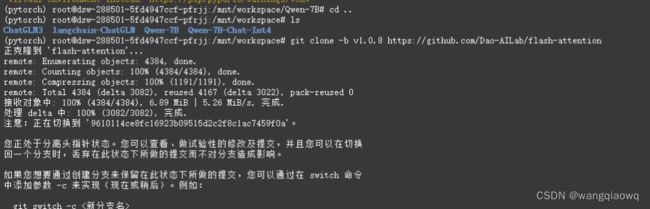
cd ..
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention
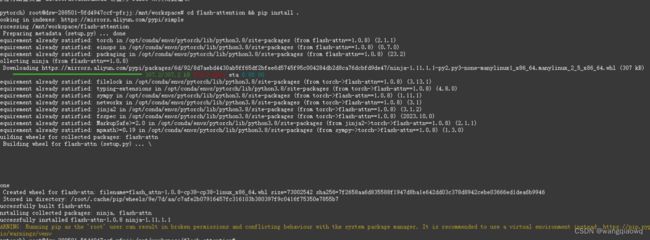
cd flash-attention && pip install .
启动成功后 速度不错:
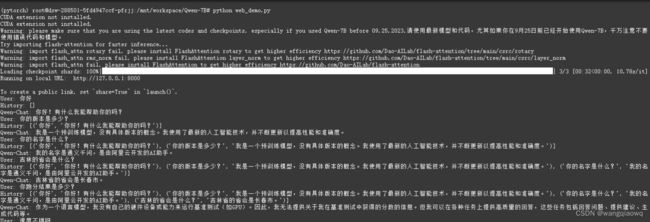
---------------------------------------------------------------------
conda deactivate
#获取版本号
conda --version 或 conda -V
#检查更新当前conda
conda update conda
#查看当前存在哪些虚拟环境
conda env list 或 conda info -e
#查看--安装--更新--删除包
conda list:
conda search package_name# 查询包
conda install package_name
conda install package_name=1.5.0
conda update package_name
conda remove package_name
#创建名为your_env_name的环境
conda create --name your_env_name
#创建制定python版本的环境
conda create --name your_env_name python=2.7
conda create --name your_env_name python=3.6
#创建包含某些包(如numpy,scipy)的环境
conda create --name your_env_name numpy scipy
#创建指定python版本下包含某些包的环境
conda create --name your_env_name python=3.6 numpy scipy
conda activate your_env_name
deactivate your_env_name
conda remove -n your_env_name --all
conda remove --name your_env_name --all