Linux进程控制
一.进程创建
1.1 fork()函数
通过进程概念这篇文章,我们初步理解了在Linux环境下,执行进程创建这个操作的大多是fork这个函数。
在Linux环境下,调用fork这个函数就会以父进程为模板创建一个子进程。
函数返回类型 pid_t 实质是 int 类型,Linux 内核 2.4.0 版本的定义是:
typedef int _kenrnel_pid_t;
typedef _kenrnel_pid_t pid_t;
fork这个函数是一个很特殊的函数,他在成功创建子进程后有两个返回值,给父进程返回子进程pid,给子进程返回 0,如果创建失败那么就返回 -1。
为什么会这样呢?
我们都明白 进程 == 内核数据结构( PCB) + 该进程对应的代码和数据 ,那么这些东西,对于子进程来说,我们该如何获取呢?
答案是,子进程直接继承父进程的所有东西,把所有的内容直接拷贝进 子进程(暂时这么理解,实际上是发生了写时拷贝),既然子进程继承了父进程的所有内容,那么,在子进程中,我们是不只是还在执行fork函数呢?
是这样的,我们继承了父进程所有代码的同时,也继承了父进程的运行位置。同时,因为fork是一个函数,当我们继承父进程在这个函数的执行位置时:
这时 创建子进程的代码已经执行完毕,但是,return 语句 一定还没有 发生 。
因此,当return时,父进程和子进程 分别return 两个内容 (这里我们应该是 通过 if else 语句 判断返回内容的) 。
#include
#include
#include
using namespace std;
int main()
{
pid_t id=fork();
if(id<0)
{
cout<<"进程创建失败"< 
注意 : fork之前父进程独立执行,fork之后,父子两个执行流分别执行。但是 fork()之后先后执行顺序完全由调度器决定。
1.2 写时拷贝
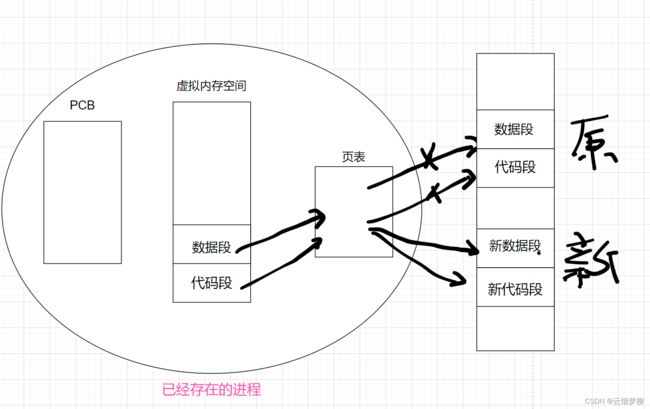
通常,父子进程刚创建之初,数据和代码共享,当父子在对数据和代码没有更改需求时,数据也是共享的;但是当任意一方有更改需求时,便以写时拷贝的方式以父进程的代码和数据做一份副本,从而父子进程分别有自己的代码和数据。具体见下图:
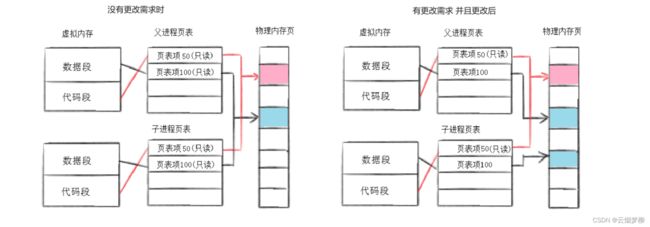
在子进程修改页表项100映射的物理内存时,操作系统会重新分配内存,将原页表项100映射的物理内存中数据拷贝过去,然后子进程再对其进行修改。这就是写时拷贝,即如果只进行读的操作,那么父子进程共享一份数据,如果父进程或者子进程要修改数据,那么要重新拷贝一份数据再进行修改,在这里,写时拷贝即减少了内存开销又保证了进程的独立性。
1.3 fork的使用场景
- 一个父进程希望复制自己,使父,子进程同时执行不同的代码段。这在网络服务进程中是常见的----父进程等待客户端的服务请求。当这种请求到达时,父进程调用fork,使子进程处理此请求。父进程则继续等待下一个服务请求到达。
- 一个进程要执行一个不同的程序。这对shel是常见的情况。在这种情况下,子进程从fork返回后立即调用exec。
1.4 fork调用失败的原因
系统中有太多的进程
实际用户的进程数超过了限制
ps: 实际上不太可能创建失败
二 .进程终止
一般而言,当我们在游戏中做任务时,任务终止的时候,大多数也就是我们任务真正圆满完成的时候。
进程也是如此,在大多数情况下,当进程需要完成的工作完成后,就会正常终止,但还有某些例外。
2.1 进程终止场景
代码运行完毕,结果正确
代码运行完毕,结果不正确
代码异常终止
2.2 进程常见退出方法
正常终止(可以通过echo $? 查看进程退出码):
1. 从main返回 (main函数内的return)
2. 调用exit
3. _exit
2.2.1 通过main函数内的return语句返回
平常写的C语言代码,在任务执行完毕之后,总要return 0。
那么,我们为什么要return 0呢?
我们都知道,我们自己写的程序运行起来,父进程为bash程序,那么,当我们的孩子出了问题,饿了渴了累了,父亲需不需要知道呢?
完全需要!!!
因此,我们的return 语句就是充当这个给父亲通知的作用,return 返回给父进程一个子进程的运行结果通知,这就是我们为什么要return 0 的原因。
而每次return 的那个数字,我们就称为进程退出码。
在Linux 系统中,我们通过echo $?语句获取进程退出码。

在日常使用时,return 语句可以返回不同的结果,以让用户(或者是父进程)来查看这个信息,如:
#include
using namespace std;
int main()
{
int i=0;
cin>>i;
if(i==0)
{
return 3;
}
return 0;
} 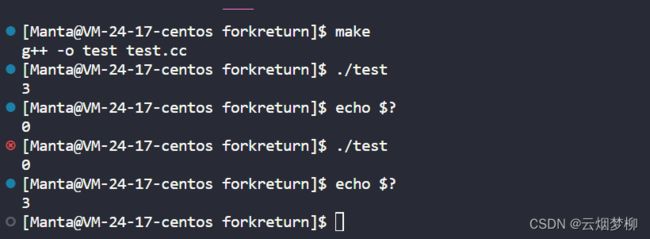
系统规定了进程退出码表示的意义,在系统中,0表示成功,当return其他数字时,指定唯一的运行错误。通过strerror函数,我们可以打印进程退出码代表的信息。
在系统中,函数定义如下:
代码示例:
#include
#include
int main()
{
for(int i=0;i<150;i++)
{
printf("%d:%s\n",i,strerror(i));
}
return 0;
} 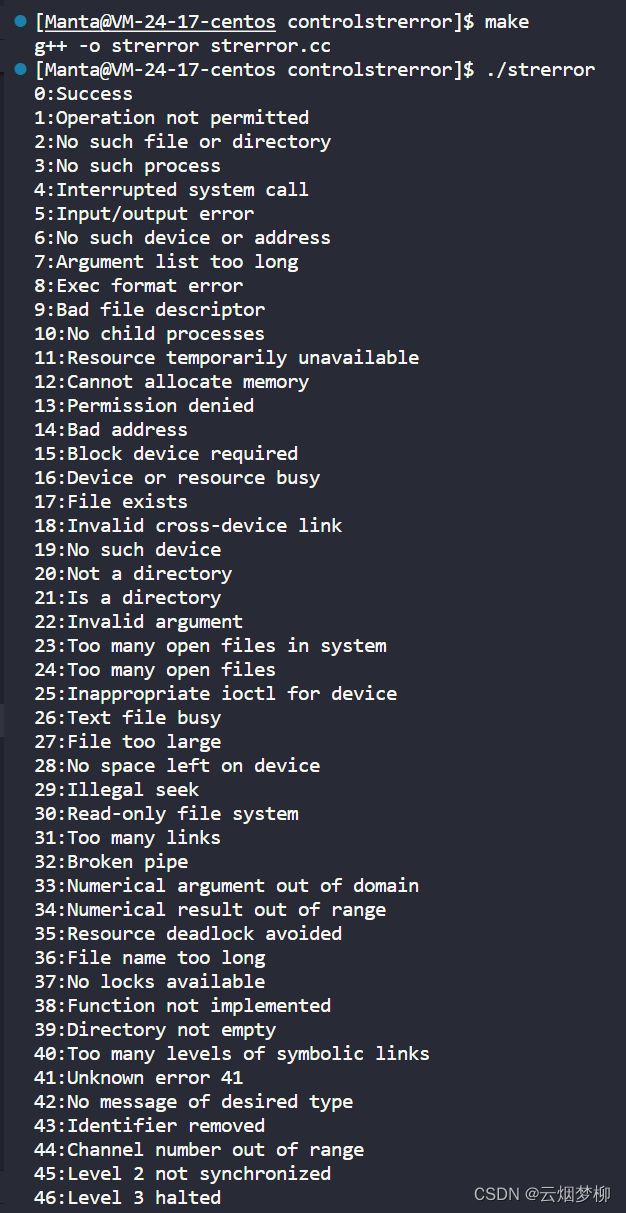
可以看到直到130多就没有错误原因了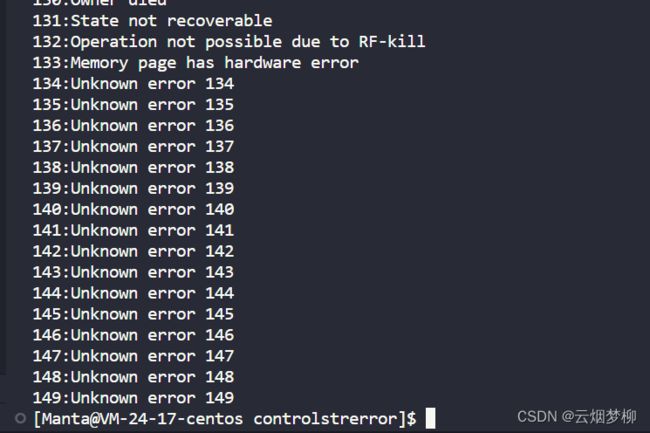
2.2.2 通过exit函数终止
2.2.2.1 exit函数
exit 也是一个终止进程的函数。
exit函数的作用和return一样,都是表示进程正常终止,然后返回不同的数字表示进程的运行结果是否正确,基本上和return的作用差别不大。
值得注意的是,return只能在main函数中终止进程,在其他函数中的作用也只是终止函数的调用。而exit函数可以在任何函数中终止进程。
例如:
#include
#include
int func()
{
int i=0;
scanf("%d",&i);
if(i==0)
{
return 3;
}
else exit(3);
}
int main()
{
func();
return 0;
} 示例:
2.2.2.2 _exit函数
exit函数是C语言的库函数,而_exit函数是系统的函数,这两个函数的区别在于:exit终止进程时,会主动刷新缓冲区;_exit终止进程时,不会刷新缓冲区。

区别:
exit
#include
#include
int main()
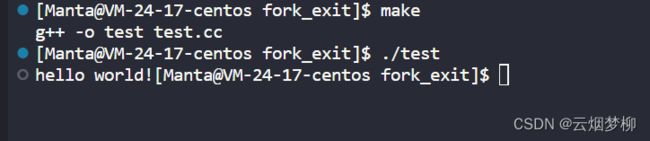
{
printf("hello world!"); //不能加换行 换行会自动刷新缓冲区
exit(0);
}#include
#include
int main()
{
printf("hello world!"); //不能加换行 换行会自动刷新缓冲区
exit(0);
} 
_exit
#include
#include
#include
int main()
{
printf("hello world!");
//exit(0);
_exit(0);
} 
可以看出 没有打印出任何内容。
其原因在于:exit是C语言提供的函数,是属于用户层的;_exit是内核提供的系统调用,是属于系统层的;而缓冲区也在用户层,所有的指令都会向内核发送;所以exit能够刷新缓冲区,而_exit做不到。
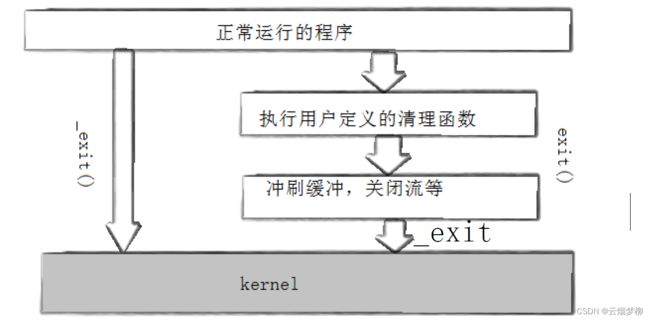
实际上,exit的底层实现也是借用了_exit,只不过比_exit多执行了两步罢了,实际组成如下。
三.进程等待
3.1 为什么需要进程等待
我们在Linux进程概念这篇文章中指出,如果一个子进程退出,如果它先于父进程退出而父进程没有进行等待来读取子进程的退出信息,那么子进程就会处于僵尸状态,从而造成内存泄漏问题。
并且,因为子进程已经退出,那就已经刀枪不入,“杀人不眨眼” 的kill -9 也无能为力,因为谁也没有办法杀死一个已经死去的进程。
最后,父进程派给子进程的任务完成的如何,我们都需要通过回收子进程的退出信息收集到,这就需要我们的父进程等待子进程退出。如,子进程运行完成,结果对还是不对,或者是否正常退出。
因此: 父进程通过进程等待的方式,以达到回收子进程资源,获取子进程退出信息等目的。
3.2进程等待的方法
3.2.1 wait函数
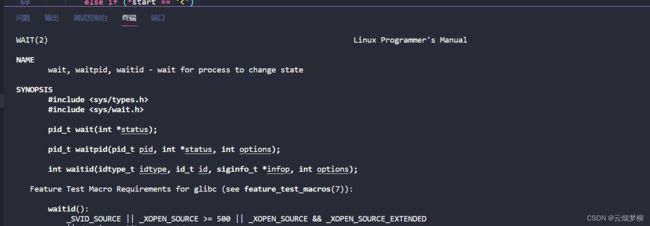
1 头文件
#include
#include2 函数原型
pid_t wait(int* status);3 返回值
成功返回被等待进程pid,失败返回-1。4 参数
输出型参数status,获取子进程退出状态(退出码),不关心可以设置为NULL
我们先进行一段代码,观看一段父进程等待子进程的示例:
#include
#include
#include
#include
#include
#include
int main()
{
pid_t id=fork();
if(id==0)
{
int cnt=5;
while(cnt--)
{
printf("我是子进程,pid:%d,ppid:%d,cnt:%d\n",getpid(),getppid(),cnt);
sleep(1);
}
exit(0);
}
sleep(10); //父进程先不回收子进程,先让子进程进入僵尸状态,在让父进程回收
// 父进程执行内容
pid_t ret_id = wait(NULL);
printf("我是父进程,等待子进程成功, pid: %d, ppid: %d, ret_id:%d\n",getpid11(), getppid(), ret_id);
return 0;
} 执行结果如下:
一开始 两个程序都在运行中
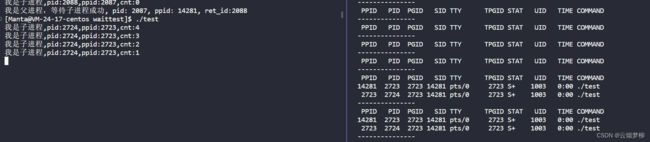
后来 子进程退出,但父进程没有回收子进程,子进程进入僵尸模式
 最后 父进程回收了
最后 父进程回收了
子进程,两个进程一起终止

3.2.1 status 参数
wait和我们接下来的waitpid,都有一个status参数,该参数是一个输出型参数,由操作系统填充。
如果传递NULL,表示不关心子进程的退出状态信息。 否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程。
举个例子,当我们做题的时候,假设只有三种情况:
一:有思路,结果正确
二:有思路,结果不正确
三:没有思路,一个字憋不出来
当我们的进程退出时,也有以下三种状态:
进程成功运行完毕,结果正确!
进程成功运行,结果不正确!
进程异常终止(程序崩溃!)
而status正是向我们反映这三种状态的一个参数。
status不能简单的当作整形来看待,可以当作位图来看待,具体细节如下图(只研究status低16比特位):
( 在status中,我们把前两种状态合为一种状态(因为他俩都正常退出),因此status有两种表达方式)


3.2.1.1 信号的浅薄认知
那么,进程退出状态我们理解,什么是终止信号呢?
我们先浅显的理解一下,当我们在ctrl+c 或者说kill -9 的时候,是不是我们给我们进程发送了一个信息,然后我们的程序就停止了?
那么,我们给进程发送的信息,是不是就是信号呢?
那么信号本质是什么呢?信号本质上是一种向一个进程通知发生异步事件的机制,是在软件层次上对中断的一种模拟。
实际上,不只是ctrl+c或者说kill -9 这种我们主动给我们的进程发送信号的情况,当我们的程序在编译期间报错或者是其它错误导致我们的进程无法运行时,实际上我们都可以理解为编译器向这个进程的父进程发送了请求,然后让父进程杀死这个进程。
3.2.1.2 利用status获取子进程退出信息
那么 status该如何获取 子进程退出信息呢?
我们常用两种形式:
一种是用status 手动获取:
因为status 本质上还是个int类型的数字,因此我们本质上可以通过一些位运算符获取我们所需要的信息。
status wait code=(status >> 8) & 0xFF; //退出码
status exit signal=status & 0x7F; //退出信号
例如:
#include
#include
#include
#include
#include
#include
int main()
{
pid_t id=fork();
if(id==0)
{
//child
int cnt=5;
while(cnt)
{
printf("child[%d] is running! cnt is %d\n",getpid(),cnt);
cnt--;
sleep(1);
}
exit(2);//退出码为2
}
int status=0;
pid_t ret =waitpid(id,&status,0);
if(ret>0)
{
printf("father wait:%d sucess,status wait code:%d,status exit signal:%d\n",ret,(status>>8)&0xFF,status&0x7F);
}
else
{
printf("father wait failed!\n");
}
return 0;
}
代码结果为: 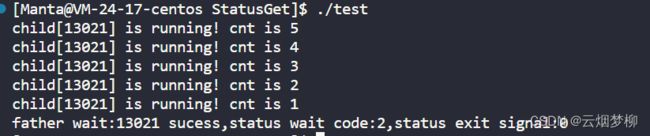
3.2.1.3 利用库函数获取子进程退出信息
用下面的常用的两个宏:
WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出,一般当进程杀死时返回假)WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。(查看进程的退出码)
我们把上面的代码稍微变动一下
#include
#include
#include
#include
#include
#include
int main()
{
pid_t id=fork();
if(id==0)
{
//child
int cnt=5;
while(cnt)
{
printf("child[%d] is running! cnt is %d\n",getpid(),cnt);
cnt--;
sleep(1);
}
exit(2);//退出码为2
}
int status=0;
pid_t ret =waitpid(id,&status,0);
if(ret>0)
{
//主要改动看这里
printf("father wait:%d sucess,status wait code:%d,status exit signal:%d\n",ret,WEXITSTATUS(status),WIFEXITED(status));
}
else
{
printf("father wait failed!\n");
}
return 0;
}
代码结果依旧如下:
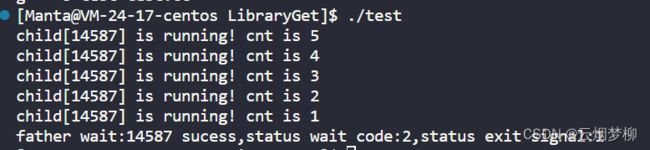
3.2.2 waitpid函数

| 函数名称 | waitpid |
| 函数功能 | 获取进程退出时的状态 |
| 头文件 | #include #include |
| 参数 | pid:指定的子进程PID status:子进程终止状态的地址 options:控制操作方式的选项 |
| 返回值 | (常用)pid_t 类型 >0:成功 |
3.2.2.1 三个参数的进一步解读
1 pid:
1、pid<-1 等待进程组识别码为pid绝对值的任何子进程.
2、pid=-1 等待任何子进程,相当于wait().
3、pid=0 等待进程组识别码与目前进程相同的任何子进程.
4、pid>0 等待任何子进程识别码为pid的子进程.
2 status:
用下面的常用的两个宏:
WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出)WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。(查看进程的退出码)
3 options:
- 0:默认行为,阻塞等待(父进程什么都不做,就是等待子进程退出)
WNOHANG:设置等待方式为非阻塞等待(一般设置在循环里面)
因为前面已经给出wait函数的示例,这里我们只展示非阻塞等待的waitpi用法。
#include
#include
#include
#include
#include
int main()
{
pid_t id=fork();
if(id==0)
{
int cnt=5;
while(cnt--)
{
printf("我是子进程,pid:%d,ppid:%d,cnt:%d\n",getpid(),getppid(),cnt);
sleep(1);
}
exit(4);
}
int status=0;
pid_t ret_id=0;
do
{
// 父进程执行内容 循环等待
ret_id = waitpid(-1,&status,WNOHANG);
if(ret_id==0)
{
printf("child is running\n");
}
sleep(1);
}while(ret_id == 0);
if(ret_id>0)
{
printf("father wait:%d sucess,status wait code:%d,status exit signal:%d\n",ret_id,WEXITSTATUS(status),WIFEXITED(status));
}
else
{
printf("father wait failed!\n");
}
return 0;
} 结果如下:
四. 进程替换
4.1 进程替换的原理
替换:
进程替换也是一样的道理:进程不变,仅仅替换当前进程的代码和数据的技术。用已经存在的进程的外壳,去往里面填充新进程的代码和数据,其中并没有创建新的进程。
4.2 进程替换的使用
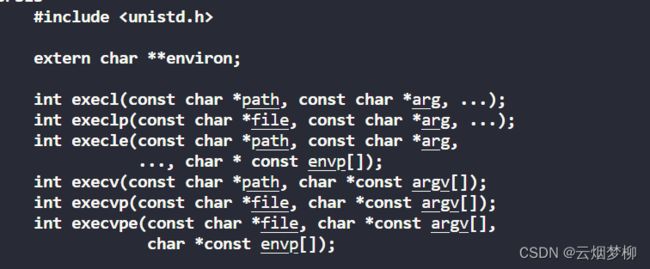
| 函数名 | 参数格式 | 是否带路径 | 是否可以改变环境变量 |
|---|---|---|---|
| execl | 列表 | 不带 | 否 |
| execlp | 列表 | 带 | 否 |
| execle | 列表 | 不带 | 是 |
| execv | 数组 | 不带 | 否 |
| execvp | 数组带 | 数组带 | 否 |
| execve | 数组 | 不带 | 是 |
六个函数的使用:
execl
#include
#include
#include
#include
int main()
{
pid_t id=fork();
if(id==0)
{//child
printf("command begin...\n");
execl("/usr/bin/ls","ls","-a","-l","-i",NULL);
printf("command end...\n");//这里是否会打印呢?
exit(1);
}
//father
waitpid(-1,NULL,0);//等待任意一个子进程
printf("father wait success!\n");
return 0;
}
execv
我们将该数组的地址传入execv函数之中。本质上和execl函数是一样的
#include
#include
#include
#include
int main()
{
pid_t id=fork();
if(id==0)
{//child
printf("command begin...\n");
char* argv[]={"ls","-a","-l", "-i", NULL};//必须以NULL结尾 };
execv("/usr/bin/ls",argv);
//execl("/usr/bin/ls","ls","-a","-l","-i",NULL);
printf("command end...\n");//这里是否会打印呢?
exit(1);
}
//father
waitpid(-1,NULL,0);//等待任意一个子进程
printf("father wait success!\n");
return 0;
} execlp:
直接传入文件的名字即可,不用再带上路径了,因为有环境变量PATH的存在,它会去环境变量里面自动搜索文件路径。
#include
#include
#include
#include
int main()
{
pid_t id=fork();
if(id==0)
{//child
printf("command begin...\n");
//char* argv[]={"ls", "-a", "-l", "-i", NULL//必须以NULL结尾 };
// execv("/usr/bin/ls",argv);
//execl("/usr/bin/ls","ls","-a","-l","-i",NULL);
execlp("ls","ls","-a","-l","-d",NULL); //直接上传文件名即可
printf("command end...\n");//这里是否会打印呢?
exit(1);
}
//father
waitpid(-1,NULL,0);//等待任意一个子进程
printf("father wait success!\n");
return 0;
}
execvp:
传入参数是文件名和命令选项的指针数组的地址
#include
#include
#include
#include
int main()
{
pid_t id=fork();
if(id==0)
{//child
printf("command begin...\n");
char* argv[]={"ls","-a","-l", "-i", NULL};//必须以NULL结尾 };
// execv("/usr/bin/ls",argv);
//execl("/usr/bin/ls","ls","-a","-l","-i",NULL);
//execlp("ls","ls","-a","-l","-d",NULL); //直接上传文件名即可
execvp("ls",argv);
printf("command end...\n");//这里是否会打印呢?
exit(1);
}
//father
waitpid(-1,NULL,0);//等待任意一个子进程
printf("father wait success!\n");
return 0;
}
execle
相较之前的函数,不过多了一个e参数,表示自己维护的环境变量,意思就是你可以把指定的环境变量传给被替换的程序。我们接下来验证的是,不再替换系统的指令,而是替换我我们自己写的程序了。(不过一般我们很少使用,不再做演示)
execve
同理。
结果均为:
只要程序替换成功,就不会执行后续的代码,意味着exec* 系列的函数,执行成功的时候就不需要返回值检测!只要exec* 返回了,那就意味着替换失败,调用函数也失败了!(返回-1)
所以exec函数只有出错的返回值而没有成功的返回值!
4.3 总结
这些函数看似容易混淆,其实隐藏着见名知意的规律
- l(list):表示采用参数列表,比如"ls",“-a”,“-l”,"-i"这样传参
- v(vector):表示参数采用数组
- p(path):有p自动搜索环境变量的PATH
- e(env):表示自己维护的环境变量