【数据挖掘】国科大刘莹老师数据挖掘课程作业 —— 第三次作业
Written Part
1. 基于表 1 1 1 回答下列问题(min_sup=40%, min_conf=75%):
| Transaction ID | Items Bought |
| 0001 | {a, d, e} |
| 0024 | {a, b, c, e} |
| 0012 | {a, b, d, e} |
| 0031 | {a, c, d, e} |
| 0015 | {b, c, e} |
| 0022 | {b, d, e} |
| 0029 | {c, d} |
| 0040 | {a, b, c} |
| 0033 | {a, d, e} |
| 0038 | {a, b, e} |
表 1 数据集
-
使用 Apriori 算法确定全部的频繁项集。
Apriori 算法执行过程如图 1 1 1 所示。

图 1 Apriori
可以看出,频繁项集有 {a},{b},{c},{d},{e},{ab},{ad},{ae},{be},{de},{ade}。
-
计算关联规则的置信度,并判断这些置信度是否具有对称性。
C o n f i d e n c e ( a ⇒ d e ) = 4 7 C o n f i d e n c e ( d ⇒ a e ) = 4 6 C o n f i d e n c e ( e ⇒ a d ) = 4 8 C o n f i d e n c e ( a d ⇒ e ) = 4 4 C o n f i d e n c e ( a e ⇒ d ) = 4 6 C o n f i d e n c e ( d e ⇒ a ) = 4 5 {\rm Confidence}(a\Rightarrow de) = \frac{4}{7} \\ {\rm Confidence}(d\Rightarrow ae) = \frac{4}{6} \\ {\rm Confidence}(e\Rightarrow ad) = \frac{4}{8} \\ {\rm Confidence}(ad\Rightarrow e) = \frac{4}{4} \\ {\rm Confidence}(ae\Rightarrow d) = \frac{4}{6} \\ {\rm Confidence}(de\Rightarrow a) = \frac{4}{5} Confidence(a⇒de)=74Confidence(d⇒ae)=64Confidence(e⇒ad)=84Confidence(ad⇒e)=44Confidence(ae⇒d)=64Confidence(de⇒a)=54
显然,不满足对称关系。 -
确定强关联规则。
其中只有 C o n f i d e n c e ( a d ⇒ e ) ≥ {\rm Confidence}(ad\Rightarrow e)\ge Confidence(ad⇒e)≥ min_conf, C o n f i d e n c e ( d e ⇒ a ) ≥ {\rm Confidence}(de\Rightarrow a)\ge Confidence(de⇒a)≥ min_conf,所以强关联规则为
a d ⇒ e [ 0.4 , 1.0 ] d e ⇒ a [ 0.4 , 0.8 ] ad\Rightarrow e \;\;\;\; [0.4, 1.0]\\ de \Rightarrow a \;\;\;\; [0.4,0.8] ad⇒e[0.4,1.0]de⇒a[0.4,0.8]
2. 基于表 1 1 1 回答下列问题(min_sup=40%):
-
使用 FP-Growth 算法确定频繁项集、FP 树和条件模式基。
根据 C1,可以统计出 F - l i s t = e , a , b , d , c {\rm F\text-list} = e, a, b, d, c F-list=e,a,b,d,c。根据 F - l i s t \rm F\text-list F-list,对表 1 1 1 进行筛选、排序,得到表 2 2 2。
Transaction ID Items Bought 0001 {e, a, d} 0024 {e, a, b, c} 0012 {e, a, b, d} 0031 {e, a, d, c} 0015 {e, b, c} 0022 {e, b, d} 0029 {d, c} 0040 {a, b, c} 0033 {e, a, d} 0038 {e, a, b}
表 2 经过过滤、排序后的数据
构建的 FP 树如图 2 2 2 所示。
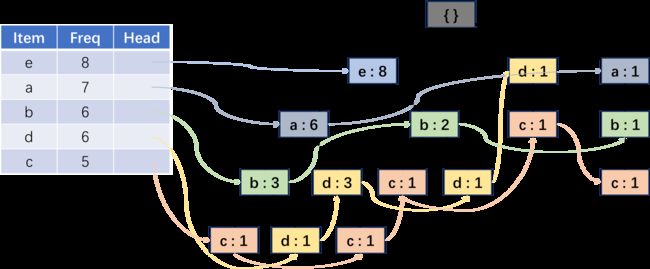
图 2 FP 树
从出现频次少的 item 开始确定条件模式基、条件 FP 树和频繁项集。
c 的条件模式基为 {{e,a,b:1}, {e,a,d:1}, {e,b:1}, {d:1}, {a,b:1}},统计基于其条件模式基的候选一项集:{a:3,b:3,e:3,d:2}。由于均小于最小支持度,所以不存在(条件)频繁一项集,无法构建条件 FP 树,也没法构建频繁二项集。
d 的条件模式基为 {{e,a,b:1}, {e,a:3}, {e,b:1}},统计候选一项集:{e:5, a:4, b:2}。只有 b 小于最小支持度,所以频繁一项集为 {e:5, a:4}。现在,以 d 的条件模式基作为”数据集“,执行构建 FP 树的过程,即按照频次对一项集排序,去掉数据集中每条数据的非频繁项并排序,最后基于处理后的数据集构建 FP 树,该树为 d 的条件 FP 树,如图 3 3 3 所示。

图 3 d-conditional FP tree
由于该 FP 树只有一条路径,因此无需递归建树,根据 d 对应的条件 FP 树统计的频繁项集为 {ead:4, ed:5, ad:4}。在表 2 2 2 所示的原始数据集中进行验证,结果正确。
b 的条件模式基为 {{e,a:3}, {e:2}, {a:1}},频繁一项集为 {e:5, a:4}。条件 FP 树如图 4 4 4 所示。

图 4 b-conditional FP tree
统计频繁二项集为 {eb:5, ab:4}。由于不止一条路径,所以统计频繁三项集需要递归建树。建立 ba 条件 FP 树,需要从图 4 4 4 中确定 a 的条件模式基 {{e:3}},以该条件模式基为”数据集“,统计频繁一项集发现为空,所以无法建立 ba 条件 FP 树,故无法生成频繁三项集。再建立 be 条件 FP 树,显然,其条件模式基为空,建树与生成频繁项集也无从谈起。
a 的条件模式基为 {{e:6}},频繁一项集为 {e:6}。条件 FP 树如图 5 5 5 所示,由此确定频繁项集为 {ea:6}。
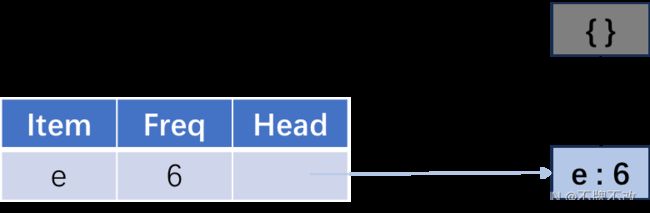
图 5 a-conditional FP tree
e 的条件模式基为空,所以不考虑。
综上所述,根据 FP-Growth 算法确定的频繁项集为 {a},{b},{c},{d},{e},{ab},{ad},{ae},{be},{de},{ade}。与 Apriori 算法结果一致。
-
对比 FP-Growth 和 Apriori 的效率。
FP-Growth 算法只需要对数据集遍历两次,所以速度更快。FP 树将集合按照支持度降序排序,不同路径如果有相同前缀路径共用存储空间,使得数据得到了压缩。相比于 Apriori,FP 树第二次遍历会存储很多中间过程的值,会占用很多内存。
3. 使用 AGNES 算法将表 4 4 4 所示的十个点聚类成两类。
| ID | Name | Pos |
| 0 | A1 | (4,2,5) |
| 1 | A2 | (10,5,2) |
| 2 | A3 | (5,8,7) |
| 3 | B1 | (1,1,1) |
| 4 | B2 | (2,3,2) |
| 5 | B3 | (3,6,9) |
| 6 | C1 | (11,9,2) |
| 7 | C2 | (1,4,6) |
| 8 | C3 | (9,1,7) |
| 9 | C4 | (5,6,7) |
表 4 十点位置
① 合并 A3 和 C4,二者的欧式距离为 2 2 2,记簇为 α \alpha α。
② 合并 B1 和 B2,二者距离为 6 \sqrt 6 6,记簇为 β \beta β;
③ 合并 B3 和 α \alpha α,二者距离由 B3 与 α \alpha α 中最近点的距离定义,即 B3 与 C4,距离为 8 \sqrt 8 8,记簇为 α \alpha α;
④ 合并 β \beta β、A1 和 C2, β \beta β 与 A1 的距离定义为 C2 与 A1 的距离,即 14 \sqrt {14} 14,B2 与 A1 的距离也为 14 \sqrt{ 14} 14,所以三者合并,记簇为 β \beta β;
⑤ 合并 A2 和 C1,二者距离为 17 \sqrt {17} 17。另外,合并 α \alpha α 和 β \beta β,二者距离由 B3 和 C2 决定,也为 17 \sqrt{17} 17。分别记簇为 γ \gamma γ 和 α \alpha α;
⑥ 合并 C3 和 α \alpha α,二者距离由 C3 和 A1 决定,即 30 \sqrt{30} 30,记簇为 α \alpha α。
此时只剩两个簇, α \alpha α 和 γ \gamma γ,分别为 {A2, C1} 和 {A1, A3, B1, B2, B3, C2, C3, C4}。
通过程序代码验证,如图 6 6 6 所示。
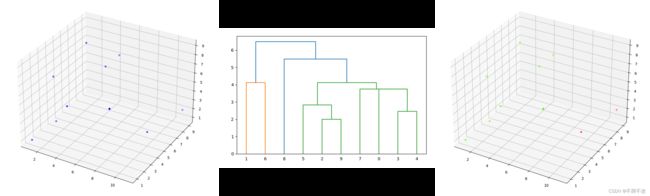
图 6 分类前(左)、分类过程(中)和分类后(右)
对应代码如下:
#步骤1:创建数据
import matplotlib.pyplot as plt
import numpy as np
X = np.array([[4,2,5], [10,5,2], [5,8,7], [1,1,1], [2,3,2], [3,6,9], [11,9,2], [1,4,6], [9,1,7], [5,6,7]])
fig = plt.figure(figsize=(8, 5))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c='b')
plt.show()
#步骤 2:调用函数实现层次聚类
from scipy.cluster.hierarchy import linkage
Z = linkage(X, method='single', metric='euclidean')
#步骤 3:画出树形图
from scipy.cluster.hierarchy import dendrogram
plt.figure(figsize=(8, 5))
dendrogram(Z,p=1, leaf_font_size=10)
plt.show()
#步骤 4:获取聚类结果
from scipy.cluster.hierarchy import fcluster
# 根据聚类数目返回聚类结果
k = 2
labels_2 = fcluster(Z, t=k, criterion='maxclust')
# 聚类的结果可视化,相同的类的样本点用同一种颜色表示
fig = plt.figure(figsize=(8, 5))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=labels_2, cmap='prism')
plt.show()
4. 根据表 5 5 5 所示的 User-Product rating 矩阵回答下列问题:
| Product 1 | Product 2 | Product 3 | Product 4 | |
| User 1 | 1 | 1 | 5 | 3 |
| User 2 | 3 | ? | 5 | 4 |
| User 3 | 1 | 3 | 1 | 1 |
| User 4 | 4 | 3 | 2 | 1 |
| User 5 | 2 | 2 | 2 | 4 |
表 5 User-Product
-
使用余弦相似度计算与 User 2 最相似的三个 User。
s i m ( 1 , 2 ) = 1 × 3 + 5 × 5 + 3 × 4 35 50 ≈ 0.956 s i m ( 3 , 2 ) = 1 × 3 + 1 × 5 + 1 × 4 3 50 ≈ 0.980 s i m ( 4 , 2 ) = 4 × 3 + 2 × 5 + 1 × 4 21 50 ≈ 0.802 s i m ( 5 , 2 ) = 2 × 3 + 2 × 5 + 4 × 4 24 50 ≈ 0.924 \begin{align} {\rm sim}(1,2) = \frac{1\times 3 + 5\times 5 + 3\times 4}{\sqrt{35} \sqrt{50}} ≈ 0.956 \\ {\rm sim}(3,2) = \frac{1\times 3 + 1\times 5 + 1\times 4}{\sqrt{3} \sqrt{50}} ≈ 0.980 \\ {\rm sim}(4,2) = \frac{4\times 3 + 2\times 5 + 1\times 4}{\sqrt{21} \sqrt{50}} ≈ 0.802 \\ {\rm sim}(5,2) = \frac{2\times 3 + 2\times 5 + 4\times 4}{\sqrt{24} \sqrt{50}} ≈ 0.924 \\ \end{align} sim(1,2)=35501×3+5×5+3×4≈0.956sim(3,2)=3501×3+1×5+1×4≈0.980sim(4,2)=21504×3+2×5+1×4≈0.802sim(5,2)=24502×3+2×5+4×4≈0.924
显然,User 2 和 User 1、User 3、User 5 最相似。 -
使用与 User 2 最相似的三个 User 预测 User 2 的 Product 2。
r ˉ U s e r 1 = 1 4 ( 1 + 1 + 5 + 3 ) = 5 2 r ˉ U s e r 2 = 1 3 ( 3 + 5 + 3 ) = 4 r ˉ U s e r 3 = 1 4 ( 1 + 3 + 1 + 1 ) = 3 2 r ˉ U s e r 5 = 1 4 ( 2 + 2 + 2 + 4 ) = 5 2 \begin{align} \bar r_{\rm User \;1} &= \frac{1}{4}(1+1+5+3) = \frac{5}{2} \\ \bar r_{\rm User \;2} &= \frac{1}{3} (3+5+3) = 4 \\ \bar r_{\rm User \;3} &= \frac{1}{4} (1+3+1+1) = \frac{3}{2} \\ \bar r_{\rm User \;5} &= \frac{1}{4}(2+2+2+4) = \frac{5}{2} \end{align} rˉUser1rˉUser2rˉUser3rˉUser5=41(1+1+5+3)=25=31(3+5+3)=4=41(1+3+1+1)=23=41(2+2+2+4)=25r U s e r 2 , P r o d u c t 2 = r ˉ U s e r 2 + s i m ( 1 , 2 ) ( r U s e r 1 , P r o d u c t 2 − r ˉ U s e r 1 ) + s i m ( 3 , 2 ) ( r U s e r 3 , P r o d u c t 2 − r ˉ U s e r 3 ) + s i m ( 5 , 2 ) ( r U s e r 5 , P r o d u c t 2 − r ˉ U s e r 5 ) s i m ( 1 , 2 ) + s i m ( 3 , 2 ) + s i m ( 5 , 2 ) ≈ 3.851 \begin{align} r_{\rm User \;2, Product \;2} &= \bar r_{\rm User \;2} + \frac{{{\rm sim(1,2)}(r_{\rm User\; 1, Product\;2}- \bar r_{\rm User\; 1}) } + {{\rm sim(3,2)}(r_{\rm User\; 3, Product\;2}- \bar r_{\rm User\; 3})} + {{\rm sim(5,2)}(r_{\rm User\; 5, Product\;2}- \bar r_{\rm User\; 5}) }}{\rm sim(1,2) + sim(3,2)+ sim(5,2)} \\ &≈ 3.851 \end{align} rUser2,Product2=rˉUser2+sim(1,2)+sim(3,2)+sim(5,2)sim(1,2)(rUser1,Product2−rˉUser1)+sim(3,2)(rUser3,Product2−rˉUser3)+sim(5,2)(rUser5,Product2−rˉUser5)≈3.851
Lab Part
Churn Management
churn_training.txt 文件包括 2000 条数据,churn_validation.txt 包括 1033 条数据。
-
采用决策树模型,设置 minimum records per child branch 为 40,pruning severity 为 70。

图 7 决策树
-
采用神经网络模型,默认设置。
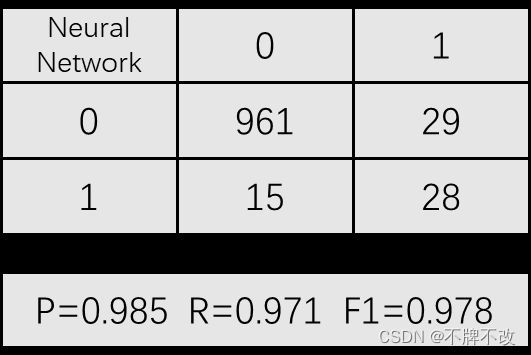
图 8 神经网络
-
采用逻辑回归模型,默认设置。

图 9 逻辑回归
-
对比不同参数设置下的决策树模型、神经网络模型和逻辑回归模型。
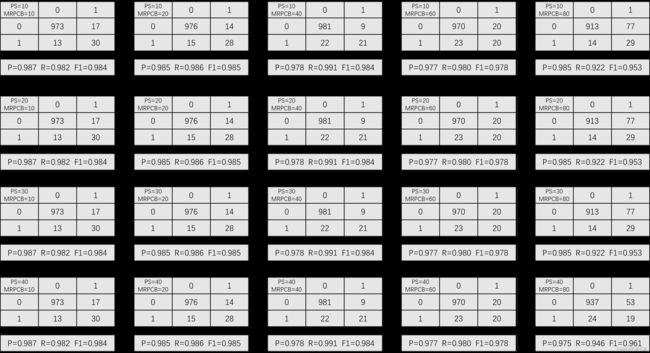
图 10 不同参数下决策树的效果
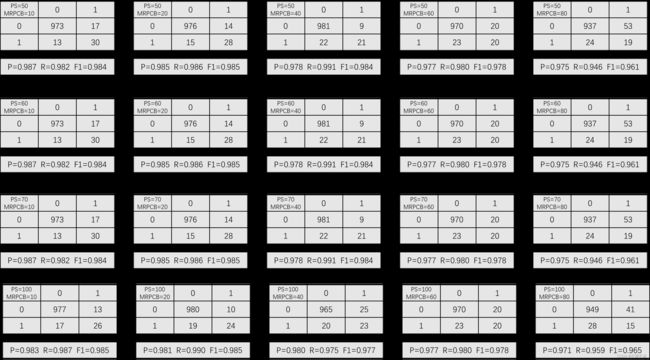
图 11 不同参数下决策树的效果(续)

图 12 不同参数下神经网络的效果
图 13 不同参数下逻辑回归的效果
Market Basket Analysis
采用 Apriori 算法,设置 Minimum antecedent support 为 7%,Minimum confidence 为 45%,Maximum number of antecedents 为 4。
-
确定产生的关联规则。
全部关联规则如图 14 14 14 所示。
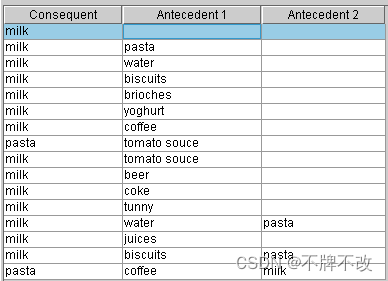
图 14 全部关联规则
-
分别按照提升度(lift)、支持度(support)和置信度(confidence)对关联规则进行排序,选择前五个非冗余的关联规则。
前五个关联规则如表 6 6 6 所示。
order lift support confidence 1 tomato souce → pasta pasta → milk biscuits, pasta → milk 2 coffee, milk → pasta water → milk water, pasta → milk 3 biscuits, pasta → milk biscuits → milk juices → milk 4 water, pasta → milk brioches → milk tomato souce → pasta 5 juices → milk yoghurt → milk yoghurt → milk 表 6 前五关联规则
比较符合常识,比如买番茄酱的购物者很可能意大利面;买意大利面的购物者很可能因为口渴买牛奶;买水或者酸奶等饮品的购物者常常会一起买上牛奶。