竞赛选题 题目:基于机器视觉的图像矫正 (以车牌识别为例) - 图像畸变校正
文章目录
- 0 简介
- 1 思路简介
-
- 1.1 车牌定位
- 1.2 畸变校正
- 2 代码实现
-
- 2.1 车牌定位
-
- 2.1.1 通过颜色特征选定可疑区域
- 2.1.2 寻找车牌外围轮廓
- 2.1.3 车牌区域定位
- 2.2 畸变校正
-
- 2.2.1 畸变后车牌顶点定位
- 2.2.2 校正
- 7 最后
0 简介
优质竞赛项目系列,今天要分享的是
基于机器视觉的图像矫正 (以车牌识别为例)
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 思路简介
目前车牌识别系统在各小区门口随处可见,识别效果貌似都还可以。查阅资料后,发现整个过程又可以细化为车牌定位、畸变校正、车牌分割和内容识别四部分。本篇随笔主要介绍车牌定位及畸变校正两部分,在python环境下通过opencv实现。
1.1 车牌定位
目前主流的车牌定位方法从大的方面来说可以分为两类:一种是基于车牌的背景颜色特征;另一种基于车牌的轮廓形状特征。基于颜色特征的又可分为两类:一种在RGB空间识别,另一种在HSV空间识别。经测试后发现,单独使用任何一种方法,效果均不太理想。目前比较普遍的做法是几种定位方法同时使用,或用一种识别,另一种验证。本文主要通过颜色特征对车牌进行定位,以HSV空间的H分量为主,以RGB空间的R分量和B分量为辅,后续再用车牌的长宽比例排除干扰。
1.2 畸变校正
在车牌的图像采集过程中,相机镜头通常都不是垂直于车牌的,所以待识别图像中车牌或多或少都会有一定程度的畸变,这给后续的车牌内容识别带来了一定的困难。因此需要对车牌进行畸变校正,消除畸变带来的不利影响。
2 代码实现
2.1 车牌定位
2.1.1 通过颜色特征选定可疑区域
取了不同光照环境下车牌的图像,截取其背景颜色,利用opencv进行通道分离和颜色空间转换,经试验后,总结出车牌背景色的以下特征:
-
(1)在HSV空间下,H分量的值通常都在115附近徘徊,S分量和V分量因光照不同而差异较大(opencv中H分量的取值范围是0到179,而不是图像学中的0到360;S分量和V分量的取值范围是到255);
-
(2)在RGB空间下,R分量通常较小,一般在30以下,B分量通常较大,一般在80以上,G分量波动较大;
-
(3)在HSV空间下对图像进行补光和加饱和度处理,即将图像的S分量和V分量均置为255,再进行色彩空间转换,由HSV空间转换为RGB空间,发现R分量全部变为0,B分量全部变为255(此操作会引入较大的干扰,后续没有使用)。
根据以上特征可初步筛选出可疑的车牌区域。随后对灰度图进行操作,将可疑位置的像素值置为255,其他位置的像素值置为0,即根据特征对图像进行了二值化。二值化图像中,可疑区域用白色表示,其他区域均为黑色。随后可通过膨胀腐蚀等操作对图像进一步处理。
for i in range(img_h):
for j in range(img_w):
# 普通蓝色车牌,同时排除透明反光物质的干扰
if ((img_HSV[:, :, 0][i, j]-115)**2 < 15**2) and (img_B[i, j] > 70) and (img_R[i, j] < 40):
img_gray[i, j] = 255
else:
img_gray[i, j] = 0

2.1.2 寻找车牌外围轮廓
选定可疑区域并将图像二值化后,一般情况下,图像中就只有车牌位置的像素颜色为白,但在一些特殊情况下还会存在一些噪声。如上图所示,由于图像右上角存在蓝色支架,与车牌颜色特征相符,因此也被当做车牌识别了出来,由此引入了噪声。
经过观察可以发现,车牌区域与噪声之间存在较大的差异,且车牌区域特征比较明显:
-
(1)根据我国常规车牌的形状可知,车牌的形状为扁平矩形,长宽比约为3:1;
-
(2)车牌区域面积远大于噪声区域,一般为图像中最大的白色区域。

可以通过cv2.findContours()函数寻找二值化后图像中白色区域的轮廓。
注意:在opencv2和opencv4中,cv2.findContours()的返回值有两个,而在opencv3中,返回值有3个。视opencv版本不同,代码的写法也会存在一定的差异。
# 检测所有外轮廓,只留矩形的四个顶点
# opencv4.0, opencv2.x
contours, _ = cv2.findContours(img_bin, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# opencv3.x
_, contours, _ = cv2.findContours(img_bin, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
这里,因为二值化图像中共有三块白色区域(车牌及两处噪声),因此返回值contours为长度为3的list。list内装有3个array,每个array内各存放着一块白色区域的轮廓信息。每个array的shape均为(n,
1, 2),即每个array存放着对应白色区域轮廓上n个点的坐标。
目前得到了3个array,即3组轮廓信息,但我们并不清楚其中哪个是车牌区域对应的那一组轮廓信息。此时可以根据车牌的上述特征筛选出车牌区域的轮廓。
#形状及大小筛选校验
det_x_max = 0
det_y_max = 0
num = 0
for i in range(len(contours)):
x_min = np.min(contours[i][ :, :, 0])
x_max = np.max(contours[i][ :, :, 0])
y_min = np.min(contours[i][ :, :, 1])
y_max = np.max(contours[i][ :, :, 1])
det_x = x_max - x_min
det_y = y_max - y_min
if (det_x / det_y > 1.8) and (det_x > det_x_max ) and (det_y > det_y_max ):
det_y_max = det_y
det_x_max = det_x
num = i
# 获取最可疑区域轮廓点集
points = np.array(contours[num][:, 0])
最终得到的points的shape为(n, 2),即存放了n个点的坐标,这n个点均分布在车牌的边缘上
2.1.3 车牌区域定位
获取车牌轮廓上的点集后,可用cv2.minAreaRect()获取点集的最小外接矩形。返回值rect内包含该矩形的中心点坐标、高度宽度及倾斜角度等信息,使用cv2.boxPoints()可获取该矩形的四个顶点坐标。
# 获取最小外接矩阵,中心点坐标,宽高,旋转角度
rect = cv2.minAreaRect(points)
# 获取矩形四个顶点,浮点型
box = cv2.boxPoints(rect)
# 取整
box = np.int0(box)
但我们并不清楚这四个坐标点各对应着矩形的哪一个顶点,因此无法充分地利用这些坐标信息。
可以从坐标值的大小特征入手,将四个坐标与矩形的四个顶点匹配起来:在opencv的坐标体系下,纵坐标最小的是top_point,纵坐标最大的是bottom_point,
横坐标最小的是left_point,横坐标最大的是right_point。
# 获取四个顶点坐标
left_point_x = np.min(box[:, 0])
right_point_x = np.max(box[:, 0])
top_point_y = np.min(box[:, 1])
bottom_point_y = np.max(box[:, 1])
left_point_y = box[:, 1][np.where(box[:, 0] == left_point_x)][0]
right_point_y = box[:, 1][np.where(box[:, 0] == right_point_x)][0]
top_point_x = box[:, 0][np.where(box[:, 1] == top_point_y)][0]
bottom_point_x = box[:, 0][np.where(box[:, 1] == bottom_point_y)][0]
# 上下左右四个点坐标
vertices = np.array([[top_point_x, top_point_y], [bottom_point_x, bottom_point_y], [left_point_x, left_point_y], [right_point_x, right_point_y]])


2.2 畸变校正
2.2.1 畸变后车牌顶点定位
要想实现车牌的畸变矫正,必须找到畸变前后对应点的位置关系。
可以看出,本是矩形的车牌畸变后变成了平行四边形,因此车牌轮廓和得出来的矩形轮廓并不契合。但有了矩形的四个顶点坐标后,可以通过简单的几何相似关系求出平行四边形车牌的四个顶点坐标。
在本例中,平行四边形四个顶点与矩形四个顶点之间有如下关系:矩形顶点Top_Point、Bottom_Point与平行四边形顶点new_top_point、new_bottom_point重合,矩形顶点Top_Point的横坐标与平行四边形顶点new_right_point的横坐标相同,矩形顶点Bottom_Point的横坐标与平行四边形顶点new_left_point的横坐标相同。
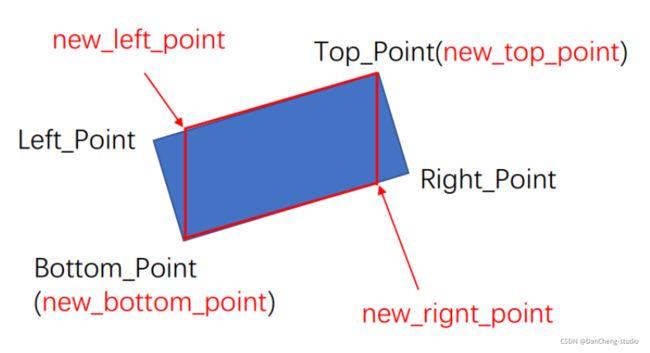
但事实上,由于拍摄的角度不同,可能出现两种不同的畸变情况。可以根据矩形倾斜角度的不同来判断具体是哪种畸变情况。

判断出具体的畸变情况后,选用对应的几何相似关系,即可轻易地求出平行四边形四个顶点坐标,即得到了畸变后车牌四个顶点的坐标。
要想实现车牌的校正,还需得到畸变前车牌四个顶点的坐标。因为我国车牌的标准尺寸为440X140,因此可规定畸变前车牌的四个顶点坐标分别为:(0,0),(440,0),(0,140),(440,140)。顺序上需与畸变后的四个顶点坐标相对应。
# 畸变情况1
if rect[2] > -45:
new_right_point_x = vertices[0, 0]
new_right_point_y = int(vertices[1, 1] - (vertices[0, 0]- vertices[1, 0]) / (vertices[3, 0] - vertices[1, 0]) * (vertices[1, 1] - vertices[3, 1]))
new_left_point_x = vertices[1, 0]
new_left_point_y = int(vertices[0, 1] + (vertices[0, 0] - vertices[1, 0]) / (vertices[0, 0] - vertices[2, 0]) * (vertices[2, 1] - vertices[0, 1]))
# 校正后的四个顶点坐标
point_set_1 = np.float32([[440, 0],[0, 0],[0, 140],[440, 140]])
# 畸变情况2
elif rect[2] < -45:
new_right_point_x = vertices[1, 0]
new_right_point_y = int(vertices[0, 1] + (vertices[1, 0] - vertices[0, 0]) / (vertices[3, 0] - vertices[0, 0]) * (vertices[3, 1] - vertices[0, 1]))
new_left_point_x = vertices[0, 0]
new_left_point_y = int(vertices[1, 1] - (vertices[1, 0] - vertices[0, 0]) / (vertices[1, 0] - vertices[2, 0]) * (vertices[1, 1] - vertices[2, 1]))
# 校正后的四个顶点坐标
point_set_1 = np.float32([[0, 0],[0, 140],[440, 140],[440, 0]])
# 校正前平行四边形四个顶点坐标
new_box = np.array([(vertices[0, 0], vertices[0, 1]), (new_left_point_x, new_left_point_y), (vertices[1, 0], vertices[1, 1]), (new_right_point_x, new_right_point_y)])
point_set_0 = np.float32(new_box)
2.2.2 校正
该畸变是由于摄像头与车牌不垂直而引起的投影造成的,因此可用cv2.warpPerspective()来进行校正。
# 变换矩阵
mat = cv2.getPerspectiveTransform(point_set_0, point_set_1)
# 投影变换
lic = cv2.warpPerspective(img, mat, (440, 140))

import cv2
import numpy as np
# 预处理
def imgProcess(path):
img = cv2.imread(path)
# 统一规定大小
img = cv2.resize(img, (640,480))
# 高斯模糊
img_Gas = cv2.GaussianBlur(img,(5,5),0)
# RGB通道分离
img_B = cv2.split(img_Gas)[0]
img_G = cv2.split(img_Gas)[1]
img_R = cv2.split(img_Gas)[2]
# 读取灰度图和HSV空间图
img_gray = cv2.cvtColor(img_Gas, cv2.COLOR_BGR2GRAY)
img_HSV = cv2.cvtColor(img_Gas, cv2.COLOR_BGR2HSV)
return img, img_Gas, img_B, img_G, img_R, img_gray, img_HSV
# 初步识别
def preIdentification(img_gray, img_HSV, img_B, img_R):
for i in range(480):
for j in range(640):
# 普通蓝色车牌,同时排除透明反光物质的干扰
if ((img_HSV[:, :, 0][i, j]-115)**2 < 15**2) and (img_B[i, j] > 70) and (img_R[i, j] < 40):
img_gray[i, j] = 255
else:
img_gray[i, j] = 0
# 定义核
kernel_small = np.ones((3, 3))
kernel_big = np.ones((7, 7))
img_gray = cv2.GaussianBlur(img_gray, (5, 5), 0) # 高斯平滑
img_di = cv2.dilate(img_gray, kernel_small, iterations=5) # 腐蚀5次
img_close = cv2.morphologyEx(img_di, cv2.MORPH_CLOSE, kernel_big) # 闭操作
img_close = cv2.GaussianBlur(img_close, (5, 5), 0) # 高斯平滑
_, img_bin = cv2.threshold(img_close, 100, 255, cv2.THRESH_BINARY) # 二值化
return img_bin
# 定位
def fixPosition(img, img_bin):
# 检测所有外轮廓,只留矩形的四个顶点
contours, _ = cv2.findContours(img_bin, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
#形状及大小筛选校验
det_x_max = 0
det_y_max = 0
num = 0
for i in range(len(contours)):
x_min = np.min(contours[i][ :, :, 0])
x_max = np.max(contours[i][ :, :, 0])
y_min = np.min(contours[i][ :, :, 1])
y_max = np.max(contours[i][ :, :, 1])
det_x = x_max - x_min
det_y = y_max - y_min
if (det_x / det_y > 1.8) and (det_x > det_x_max ) and (det_y > det_y_max ):
det_y_max = det_y
det_x_max = det_x
num = i
# 获取最可疑区域轮廓点集
points = np.array(contours[num][:, 0])
return points
#img_lic_canny = cv2.Canny(img_lic_bin, 100, 200)
def findVertices(points):
# 获取最小外接矩阵,中心点坐标,宽高,旋转角度
rect = cv2.minAreaRect(points)
# 获取矩形四个顶点,浮点型
box = cv2.boxPoints(rect)
# 取整
box = np.int0(box)
# 获取四个顶点坐标
left_point_x = np.min(box[:, 0])
right_point_x = np.max(box[:, 0])
top_point_y = np.min(box[:, 1])
bottom_point_y = np.max(box[:, 1])
left_point_y = box[:, 1][np.where(box[:, 0] == left_point_x)][0]
right_point_y = box[:, 1][np.where(box[:, 0] == right_point_x)][0]
top_point_x = box[:, 0][np.where(box[:, 1] == top_point_y)][0]
bottom_point_x = box[:, 0][np.where(box[:, 1] == bottom_point_y)][0]
# 上下左右四个点坐标
vertices = np.array([[top_point_x, top_point_y], [bottom_point_x, bottom_point_y], [left_point_x, left_point_y], [right_point_x, right_point_y]])
return vertices, rect
def tiltCorrection(vertices, rect):
# 畸变情况1
if rect[2] > -45:
new_right_point_x = vertices[0, 0]
new_right_point_y = int(vertices[1, 1] - (vertices[0, 0]- vertices[1, 0]) / (vertices[3, 0] - vertices[1, 0]) * (vertices[1, 1] - vertices[3, 1]))
new_left_point_x = vertices[1, 0]
new_left_point_y = int(vertices[0, 1] + (vertices[0, 0] - vertices[1, 0]) / (vertices[0, 0] - vertices[2, 0]) * (vertices[2, 1] - vertices[0, 1]))
# 校正后的四个顶点坐标
point_set_1 = np.float32([[440, 0],[0, 0],[0, 140],[440, 140]])
# 畸变情况2
elif rect[2] < -45:
new_right_point_x = vertices[1, 0]
new_right_point_y = int(vertices[0, 1] + (vertices[1, 0] - vertices[0, 0]) / (vertices[3, 0] - vertices[0, 0]) * (vertices[3, 1] - vertices[0, 1]))
new_left_point_x = vertices[0, 0]
new_left_point_y = int(vertices[1, 1] - (vertices[1, 0] - vertices[0, 0]) / (vertices[1, 0] - vertices[2, 0]) * (vertices[1, 1] - vertices[2, 1]))
# 校正后的四个顶点坐标
point_set_1 = np.float32([[0, 0],[0, 140],[440, 140],[440, 0]])
# 校正前平行四边形四个顶点坐标
new_box = np.array([(vertices[0, 0], vertices[0, 1]), (new_left_point_x, new_left_point_y), (vertices[1, 0], vertices[1, 1]), (new_right_point_x, new_right_point_y)])
point_set_0 = np.float32(new_box)
return point_set_0, point_set_1, new_box
def transform(img, point_set_0, point_set_1):
# 变换矩阵
mat = cv2.getPerspectiveTransform(point_set_0, point_set_1)
# 投影变换
lic = cv2.warpPerspective(img, mat, (440, 140))
return lic
def main():
path = 'F:\\Python\\license_plate\\test\\9.jpg'
# 图像预处理
img, img_Gas, img_B, img_G, img_R, img_gray, img_HSV = imgProcess(path)
# 初步识别
img_bin = preIdentification(img_gray, img_HSV, img_B, img_R)
points = fixPosition(img, img_bin)
vertices, rect = findVertices(points)
point_set_0, point_set_1, new_box = tiltCorrection(vertices, rect)
img_draw = cv2.drawContours(img.copy(), [new_box], -1, (0,0,255), 3)
lic = transform(img, point_set_0, point_set_1)
# 原图上框出车牌
cv2.namedWindow("Image")
cv2.imshow("Image", img_draw)
# 二值化图像
cv2.namedWindow("Image_Bin")
cv2.imshow("Image_Bin", img_bin)
# 显示校正后的车牌
cv2.namedWindow("Lic")
cv2.imshow("Lic", lic)
# 暂停、关闭窗口
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == '__main__':
main()

7 最后
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate