HashMap的实现原理
1.HashMap实现原理
HashMap的数据结构: *底层使用hash表数据结构,即数组+链表+红黑树
当我们往HashMap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
存储时,如果出现hash值相同的key,此时有两种情况。
a. 如果key相同,则覆盖原始值;
b. 如果key不同(出现冲突),则将当前的key-value放入链表或红黑树中
获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
2. HashMap的jdk1.7和jdk1.8有什么区别
JDK1.8之前采用的是拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
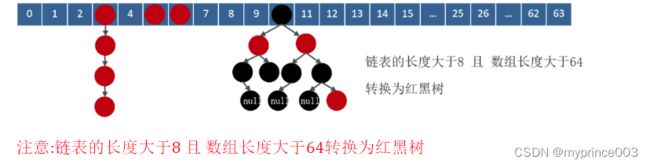
jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8) 时并且数组长度达到64时,将链表转化为红黑树,以减少搜索时间。扩容 resize( ) 时,红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表

3. HashMap的put方法的具体流程
3.1. HashMap源码分析 – 常见属性
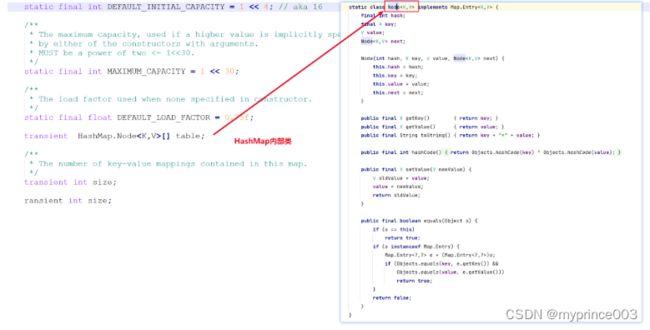
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
transient HashMap.Node<K,V>[] table;
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
ransient int size;
DEFAULT_INITIAL_CAPACITY 默认的初始容量
DEFAULT_LOAD_FACTOR 默认的加载因子
扩容阈值 == 数组容量 * 加载因子
3.2. HashMap put方法使用
Map<String, String> map = new HashMap<>();
map.put("name", "springboot");
HashMap构造方法,默认创建的时,初始化容量
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
HashMap是懒惰加载,在创建对象时并没有初始化数组
在无参的构造函数中,设置了默认的加载因子是0.75
3.3. HashMap的put方法的具体流程
HashMap,添加数据流程图
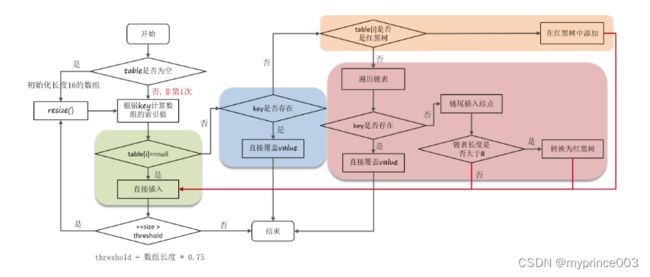
1、判断键值对数组table是否为空或为null,否则执行resize()进行扩容(初始化长度16的数组)
2、根据键值key计算hash值得到数组索引
3、判断table[i]==null,条件成立,直接新建节点添加
4、如果table[i]==null ,不成立
4.1 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
4.2 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对
4.3 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操 作,遍历过程中若发现key已经存在直接覆盖value
5、插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
4. HashMap的扩容机制
在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据初始化数组长度为16,以后每次每次扩容都是达到了扩容阈值(数组长度 * 0.75)
每次扩容的时候,都是扩容之前容量的2倍
扩容之后,会新创建一个数组,需要把老数组中的数据挪动到新的数组中
没有hash冲突的节点,则直接使用 e.hash & (newCap - 1) 计算新数组的索引位置
如果是红黑树,走红黑树的添加
如果是链表,则需要遍历链表,可能需要拆分链表,判断(e.hash & oldCap)是否为0,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上
4.1. hashMap的寻址算法
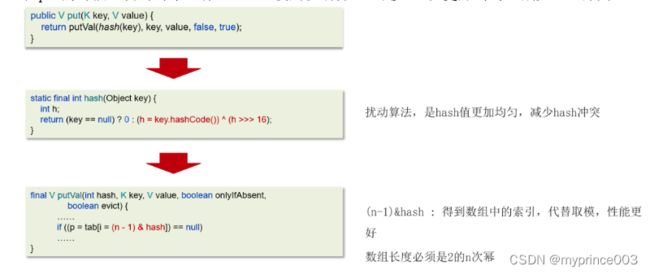
在put的时候,会对对象进行hash,使用扰动算法,是hash值更加均匀,减少hash冲突
为何HashMap的数组长度一定是2的次幂?
计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模
扩容时重新计算索引效率更高: hash & oldCap == 0 的元素留在原来位置 ,否则新位置 = 旧位置 + oldCap
HashMap面试题
HashMap的实现原理?
主要分为了一下几个部分:
1,底层使用hash表数据结构,即数组+(链表 | 红黑树)
2,添加数据时,计算key的值确定元素在数组中的下标
key相同则替换
不同则存入链表或红黑树中
3,获取数据通过key的hash计算数组下标获取元素
HashMap的jdk1.7和jdk1.8有什么区别
JDK1.8之前采用的拉链法,数组+链表
JDK1.8之后采用数组+链表+红黑树,
链表长度大于8且数组长度大于64则会从链表转化为红黑树
HashMap的put方法的具体流程?
1、判断键值对数组table是否为空或为null,否则执行resize()进行扩容(初始化长度16的数组)
2、根据键值key计算hash值得到数组索引
3、判断table[i]==null,条件成立,直接新建节点添加
4、如果table[i]==null ,不成立
4.1 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
4.2 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对
4.3 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操 作,遍历过程中若发现key已经存在直接覆盖value
5、插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
HashMap的扩容机制?
在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据初始化数组长度为16,以后每次每次扩容都是达到了扩容阈值(数组长度 * 0.75)
每次扩容的时候,都是扩容之前容量的2倍;
扩容之后,会新创建一个数组,需要把老数组中的数据挪动到新的数组中
没有hash冲突的节点,则直接使用 e.hash & (newCap - 1) 计算新数组的索引位置
如果是红黑树,走红黑树的添加
如果是链表,则需要遍历链表,可能需要拆分链表,判断(e.hash & oldCap)是否为0,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上
hashMap的寻址算法?
这个哈希方法首先计算出key的hashCode值,
然后通过这个hash值右移16位后的二进制进行按位异或运算得到最后的hash值。
在putValue的方法中,计算数组下标的时候使用hash值
与数组长度取模得到存储数据下标的位置,hashmap为了性能更好,
并没有直接采用取模的方式,而是使用了数组长度-1
得到一个值,用这个值按位与运算hash值,
最终得到数组的位置。
为何HashMap的数组长度一定是2的次幂?
第一:
计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模
第二:
扩容时重新计算索引效率更高:在进行扩容是会进行判断 hash值按位与运算旧数组长租是否 == 0
如果等于0,则把元素留在原来位置 ,否则新位置是等于旧位置的下标+旧数组长度