Windows核心编程(第五版)_1_错误处理_字符处理_内核对象
ʕ •ᴥ•ʔ ɔ:
1 Windows API返回值
调用Windows函数时,它会先验证我们传给它的参数,然后再开始执行任务。如果传入的参数无效,或者由于其他原因导致操作无法执行,则函数的返回值将指出函数因为某些原因失败了。表1-1展示了大多数Windows函数使用的返回值的数据类型。
1.1 函数的错误码
通常情况下,如果 Windows函数能返回错误代码,将有助于我们理解函数调用为什么会失败。 Microsoft编辑了一个列表,其中列出了所有可能的错误代码,{% label success @并为每个错误代码都分配了一个32位的编号 %}。定义于{% label danger @WinError.h %}头文件中。
DWORD GetlastError();
此函数的作用很简单,就是返回由上一个函数调用设置的线程的32位错误代码。
在这个头文件中每个错误码(消息ID)都对应:一个消息ID(一个可在源代码中使用的宏,用于与GetLastError的返回值进行比较)、消息文本(描述错误的英文文本)和一个编号(应该避免使用此编号,尽量使用消息ID)。
{% note primary %}
**注意:**Windows函数失败之后,应该马上调用GetLastError,因为假如又调用了另一个Windows函数,则此值很可能被改写。注意,成功调用的Windows函数可能用ERROR_SUCCESS改写此值。
{% label default @不管成功与否,使用GetLastError都可以知道函数调用的额外信息。 %}
{% endnote %}
1.2 自定义错误码
为了指出错误,只需{% label warning @设置线程的上一个错误代码 %},然后令自己的函数返回FALSE,INVALID_HANDLE_VALUE、NULL或者其他合适的值。为了设置线程的上一个错误代码,只需调用以下函数,并传递我们认为合适的任何32位值:
VOID SetlastError(DWORD dwErrCode);
该32位值的每一位含义如下:

Microsoft承诺,在它所生成的所有错误代码中,第29位将始终为0。但是,如果要创建我们自己的错误代码,就必须在此位放入一个1。通过这种方式,可以保证我们的错误代码绝不会与Microsoft现在和将来定义的错误代码冲突。注意,Facility字段非常大,足以容纳4096个可能的值。其中,前256个值是为Microsoft保留的,其余的值可由我们自己的应用程序来定义。
2 字符和字符串处理
2.1 字符集
| 字符集 | 字节数 | 表示范围 | 注释 |
|---|---|---|---|
| 标准ASCII | 1字节,使用低7位,最高位始终为0. | 0~127 | 标准 ASCII 码使用 7 位二进制数来表示所有的大写和小写字母,数字 0 到 9、标点符号,以及在美式英语中使用的特殊控制字符。 |
| 扩展 ASCII 码(ANSI) | 1字节,使用8位,最高位为0时相当于标准ASCII. | 0~255 | 扩展 ASCII 码允许将每个字符的第 8 位用于确定附加的 128 个特殊符号字符、外来语字母和图形符号。 ASCll码的字符集可以扩充了128个字符,即十进制数128~255,称为扩展ASCII码。扩展ASCII码所增加的字符包括加框文字、圆圈和其他图形符号。 |
| GB2312 | 2字节,高9位为0时,低7位含义同标准ASCII. | 0~65535 | 一个小于127的字符的意义与原来相同, 但两个大于127的字符连在一起时,就表示一个汉字。不同的文字(国家语言)存于不同的序段。 虽然是双字节编码,但是编码完全不同于Unicode。 |
| GBK | 2字节,属于扩展的GB2312. | 0~65535 | GB2312是简体汉字编码规范,GBK编码能够用来同时表示繁体字和简体字,而GB2312只能表示简体字,GBK是兼容GB2312编码的。 |
| Unicode | 1~4字节,Windows使用UTF-16编码形式存储字符. | 0x000000~0x0010FFFF | Unicode只规定了字符的二进制表示方式,并没有指出这些二进制数据如何在计算机中存储(规则)。并且不同国家的语言使用不同的区域,Unicode 只是字符集,UTF-8、UTF-16、UTF-32 才是真正的字符编码规则,常用的编码规则: **UTF-8:**变长编码方式,使用1~4字节来编码不同字符,存储划算,常用于网络传输。 **UTF-16:**定长编码,使用2字节或者4字节。编码效率高,Windows、Java使用。 **UTF-32:**定长编码,使用4字节,存储非常不划算,更不用说网络传输了。所以这种实现用得极少。 |
参考:
- Unicode、UTF-8、UTF-16,终于懂了
- Unicode 编码及 UTF-32, UTF-16 和 UTF-8
- 彻底弄懂 Unicode 编码
2.2 ANSI、Unicode字符、字符串数据类型
C语言的char使用8位的ANSI字符。
wchar_t数据类型使用16位(UTF-16)的Unicode。Microsoft的C/C++编译器定义了这个内建的数据类型wchar_t。
Unicode编码的数据类型:
- 数据类型定义在Windows头文件{% label danger @WinNT.h %}中;
- 使用
L''、L""来表示字符和字符串,如wchar_t wchar = L'A';; - 使用通用字符数据类型
TEXT('')和TEXT("")会在使用ANSI或Unicode的编译器中自动使用char或wchar数据类型。
Windows常用数据类型、API、结构体可查看:{% label primary @MSDN %}{% label default @ReactOS %}{% label warning @Win32头文件 %}{% label info @Win32API参考手册 %}等。
2.3 Windows中的ANSI和Unicode函数
一、A版、W版Win32 API
自Windows NT起,Windows的所有版本都完全用Unicode来构建。
调用Windows函数时,如果向它传入一个ANSI字符串(由单字节字符组成的一个字符串),那么函数首先会把字符串转换为Unicode,再把结果传给操作系统。如果希望函数返回ANSI字符串,那么操作系统会先把Unicode字符串转换为ANSI字符串,再把结果返回给我们的应用程序。所有这些转换都是在幕后进行的。
如果一个Windows函数的多数列表中有字符串,则该函数通常有两个版本,{% label danger @A %}版、{% label danger @W %}版。如:
CreateWindowExA:接受ANSI字符串;CreateWindowExW:接受Unicode字符串。
{% note primary %}
备注:使用时只需要用宏CreateWindowEx即可,因为编译器会自动使用A版或W版。这些类似的宏在{% label danger @WinUser.h %}中定义。
ANSI版本只是分配内存,执行必要的字符串转换,然后调用该函数的Unicode版本与操作系统打交道。
{% endnote %}
#ifdef UNICODE
#define CreateWindowEx CreateWindowExW
#else
#define CreateWindowEx CreateWindowExA
#endif // !UNICODE
二、尽量使用新函数
Windows API中的一些函数如:
WinExec和OpenFile存在的唯一目的就是为了向后兼容16位Windows程序,因为后者只支持ANSI字符串。在开发的新程序中,应避免使用这些函数。应该用CreateProcess和CreateFile函数调用来代替。
在内部,老函数总是会调用新函数。但老函数的最大问题在于,它们不接受Unicode字符串,而且支持的功能一般都要少一些。调用这些函数的时候,必须向其传递ANSI字符串。
2.4 C运行库中的ANSI和Unicode函数
和Windows函数一样,C运行库提供了一系列函数来处理ANSI字符和字符串,并提供了另一系列函数来处理Unicode字符与字符串。然而,与Windows不同的是,{% label info @ANSI版本的函数是不会把字符串转换为Unicode形式,再从内部调用函数的Unicode版本 %}。当然,Unicode版本的函数也是“自力更生”的,它们不会在内部调用ANSI版本。
字符(串)处理函数举例(使用时应该包含{% label danger @TChar.h %}头文件):
ANSI:strlen
Unicode:wcslen
通用版:_tcslen
#ifdef _UNICODE
#define _tcslen wcslen
#else
#define_tcslen strlen
#endif
{% note danger %}
备注:有_t一般都是都用版本的宏,如_tmain。
{% endnote %}
2.5 C运行库中的安全字符串函数
许多字符串处理函数默认以\0作为一个字符串的结束符,或者没有考虑缓冲区与处理字符串长度而导致缓冲区溢出。
所以建议使用安全函数,这些函数仅在原函数后面加了_s(代表Secure)后缀,在{% label danger @StrSafe.h %}头文件中定义,使用该头文件时应该安全SDK才可以使用。
安全函数解析举例:
PTSTR _tcscpy(PTSTR strDestination, PCTSTR strSource);
errno_t _tcscpy_s(PTSTR strDestination, size_t numberOfcharacters, PCTSTR strSource);
PTSTR _tcscat(PTSTR strDestination, PCTSTR strSource);
errno_t _tcscat_s(PTSTR strDestination, size_t numberOfcharactere, PCTSTR strSource);
安全解决方法:{% label success @在将一个可写的缓冲区作为参数传递时,必须同时提供它的大小 %}。
{% note default %}
关于_countof和sizeof:
_countof:Windows宏,用来计算一个静态分配的数组中的元素的个数。sizeof:运算符(不是函数),用来计算字节数。
如使用宽字符的程序,一个字符占2字节,假设一个使用4个字符的字符串,_countof结果为4,sizeof结果为8。
{% endnote %}
MSDN中的许多Win32 API函数不指定参数使用in bytes(以字节为单位)时,默认使用in TCHAR(以字符为单位)。
还有些API函数名称就已经指定使用字符还是字节:
StringCchCpy()、StringCchPrintf()…:都含有Cch(Count of characters)使用字符数,则使用_countof;StringCbCat(Ex)、StringCbCopy(Ex)…:都含有Cb(Count of bytes)使用字节数,则使用sizeof。
{% note danger %}
注意C运行库中的Ex函数会比其常规函数多三个参数(更安全,更详细),具体参见2.5.2最后,该EX应区别于Win32 API的EX。
{% endnote %}
2.6 Windows字符串函数
Windows中的许多字符串函数是不安全的,如lstrcat、lstrcpy等(Kernel32方法)。所以在{% label danger @ShlwApi.h %}定义了大量字符串处理函数,以更安全的方式来使用。
{% note info %}
Shlwapi是Windows的Shell API函数。主要分为三类函数,每一类函数都要区分A版和W版。:
- 第一类是字符串处理函数,通常以
Str开头; - 第二类是路径或者文件夹处理函数,通常以
Path开头; - 第三类是注册表处理函数,通常以
SH开头。
{% endnote %}
**Unicode与ANSI字符串互相转换:**使用函数MultiByteToWideChar与WideCharToMultiByte)
int MultiByteToWideChar(
[in] UINT CodePage,
[in] DWORD dwFlags,
[in] _In_NLS_string_(cbMultiByte)LPCCH lpMultiByteStr,
[in] int cbMultiByte,
[out, optional] LPWSTR lpWideCharStr,
[in] int cchWideChar
);
int WideCharToMultiByte(
[in] UINT CodePage,
[in] DWORD dwFlags,
[in] _In_NLS_string_(cchWideChar)LPCWCH lpWideCharStr,
[in] int cchWideChar,
[out, optional] LPSTR lpMultiByteStr,
[in] int cbMultiByte,
[in, optional] LPCCH lpDefaultChar,
[out, optional] LPBOOL lpUsedDefaultChar
);
应特别注意:
cchWideChar单位是:字符;cbMultiByte单位是:字节。
**判断文本是ANSI还是Unicode:**使用函数IsTextUnicode
BOOL IsTextUnicode(
[in] const VOID *lpv,
[in] int iSize,
[in, out, optional] LPINT lpiResult
);
3 内核对象
各种对象的区分:
{% note success %}
- {% label danger @HINSTANCE %}:HINSTANCE是个数据类型,本质就是个结构体指针,里面结构体成员只有一个int类型变量,指向的是PE结构中讲到的ImageBase,仅此而已;
- {% label danger @HMODULE %}:事实上,HMODULE和HINSTANCE完全是一回事。如果某个函数的文档指出需要一个HMODULE参数,我们可以传入一个HINSTANCE,反之亦然。之所以有两种数据类型,是由于在16位Windows中,HMODULE和HINSTANCE表示不同类型的数据。《Windows核心编程第五版-4.1.1进程实例句柄》
- {% label danger @HWND %}:也是个结构体类型指针,里面定义的类型同样是int类型,只是她这个结构体指针指向的是Windows给其分配的一个唯一的ID而已;HWND同样是个数据类型,只是改了名称叫法而已,叫做窗口句柄,将其实例化后,就是个整型int类型的数据,只是是用指针的方式指向她,其本质是个结构体指针,里面结构体成员只有一个int类型变量,所以HWND是个带有int类型成员的结构体指针,指向每个不同的窗口,并且给不同的窗口分配唯一的编号,通过这个编号就能找到不同的窗口,仅此而已;
- 内核句柄{% label danger @HANDLE %}:系统用索引来表示内核对象的信息保存在进程句柄表中的具体位置,要得到实际的索引值,句柄值实际应该除以4(或右移两位,以忽略Windows操作系统内部使用的最后两位)。所以,在调试应用程序时查看内核对象句柄的实际值时,会看到4、8之类的很小的值。记住,句柄的含义尚未公开,将来可能发生变化
{% endnote %}
3.1 内核对象是什么
{% note danger %}
每个内核对象都只是一个内存块,它由操作系统内核分配,并只能由操作系统内核访问。这个内存块是一个数据结构,其成员维护着与对象相关的信息。
{% label warning @每个内核对象都是一个数据结构 %}。该结构少数成员(安全描述符和使用计数等)是所有对象都有的,但其他大多数成员都是不同类型的对象特有的。该数据结构只能由操作系统访问,应用程序无法访问。
{% endnote %}
例如:
- 进程对象有一个进程ID、一个基本的优先级和一个退出代码;
- 文件对象有一个字节偏移量(byte offset)、一个共享模式和一个打开模式。
{% note danger %}
创建一个内核对象,会返回一个句柄。32位的进程中,句柄值为32位;64位进程中句柄值为64位。
句柄值仅用于当前进程,其他进程不可用,因为不同进程中句柄值都是从1*4开始的。
{% endnote %}
3.2 内核对象成员-使用计数
进程终止运行,内核对象并不一定会销毁。大多数情况下,这个内核对象是会销毁的,但假如另一个进程正在使用我们的进程创建的内核对象,那么在其他进程停止使用它之前,它是不会销毁的。总之,内核对象的生命期可能长于创建它的那个进程。
原因:内核对象的所有者是操作系统内核,而非进程。
{% note info %}
操作系统内核知道当前有多少个进程正在使用一个特定的内核对象,因为每个对象都包含一个使用计数(usage count)。{% label primary @使用计数是所有内核对象类型都有的一个数据成员 %}。初次创建一个对象的时候,其使用计数被设为1。另一个进程获得对现有内核对象的访问后,使用计数就会递增。进程终止运行后,操作系统内核将自动递减此进程仍然打开的所有内核对象的使用计数。如果一旦对象的使用计数变成0,操作系统内核就会销毁该对象。这样一来,可以保证系统中不存在没有被任何进程引用的内核对象。
{% endnote %}
3.3 内核对象成员-安全属性
内核对象可以用一个安全描述符(security descriptor, SD)来保护。
{% note danger %}
用于创建内核对象的所有函数几乎都有指向一个SECURITY_ATTRIBUTES结构的指针{% label danger @PSECURITY_ATTRIBUTES %}作为参数。
{% endnote %}
如下创建进程函数的第三、四参数就是描述进程、线程安全属性的:
BOOL WINAPI CreateProcess(
__in_opt LPCTSTR lpApplicationName,
__inout_opt LPTSTR lpCommandLine,
__in_opt LPSECURITY_ATTRIBUTES lpProcessAttributes,
__in_opt LPSECURITY_ATTRIBUTES lpThreadAttributes,
__in BOOL bInheritHandles,
__in DWORD dwCreationFlags,
__in_opt LPVOID lpEnvironment,
__in_opt LPCTSTR lpCurrentDirectory,
__in LPSTARTUPINFO lpStartupInfo,
__out LPPROCESS_INFORMATION lpProcessInformation
);
安全属性结构定义如下:
typedef struct _SECURITY_ATTRIBUTES {
DWORD nLength;
LPVOID lpSecurityDescriptor;
BOOL bInheritHandle;
} SECURITY_ATTRIBUTES, *PSECURITY_ATTRIBUTES, *LPSECURITY_ATTRIBUTES;
nLength:结构的字节大小,sizeof(SECURITY_ATTRIBUTE);lpSecurityDescriptor:安全访问属性,指向一个安全描述符结构;bInheritHandle:控制内核对象句柄是否可被继承,TRUE或FALSE。
如果利用句柄来调用API函数,API往往是需要获得一定权限才可以访问的。如OpenProcess函数的第一个参数:
HANDLE OpenProcess(
[in] DWORD dwDesiredAccess,
[in] BOOL bInheritHandle,
[in] DWORD dwProcessId
);
3.4 进程内核对象句柄表
个进程在初始化时,系统将为它分配一个句柄表(handle table)。一个进程刚创建(初始化)时,其句柄表时空的。
每在该进程中创建一个内核对象,就会在该进程的内核对象句柄表中填充一项句柄表记录。
用于创建内核对象的任何函数都会返回一个与进程相关的句柄,这个句柄可由同一个进程中运行的额所有线程使用。
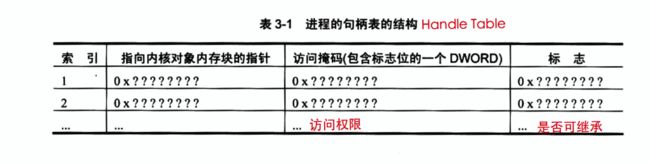
{% note default %}
句柄值和句柄表索引值的对应关系:{% label danger @句柄值 = 索引值*4 %}
{% endnote %}
凡是用于创建内核对象的函数,都要仔细检查它的返回值,比如失败:有的返回0(NULL),有的返回(-1)INVALID_HANDLE_VALUE。