数据库系统-学习记录13
ch6.系统故障对策
数据库在使用的过程中,难免会出现各种各样的故障。这些故障往往会给数据带来损失,这个时候就需要进行数据库的恢复
可恢复操作的问题和模型
故障模式
在数据库的使用中,最重要的故障包括错误数据输入、介质故障、灾难性故障和系统故障等。解决由系统错误引起的故障的基本方法,在于使用日志,通过记录每一条更新操作,以在必要时进行恢复
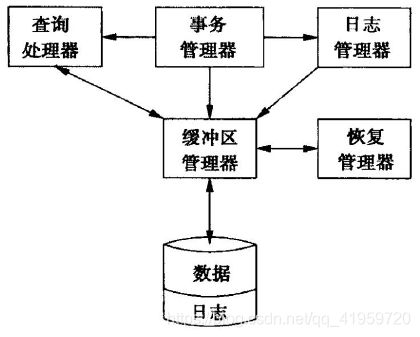
日志管理器与事务管理器
一项事务只能是“全做”或“全不做”,事务管理器便是用于满足这一规定。实际上,事务管理器的主要作用就是保证事务的正确执行,它的主要功能有:
1、通过给日志管理器发送信号,让日志存储相关的必要信息
2、保证并发执行的事务不会相互干扰
而日志管理器则是用于维护日志。日志的空间最早会出现在主存缓冲区中,而这些缓冲区又会在一定的时候被复制到磁盘上。日志和数据一样,都会占用磁盘上的空间
下图是日志管理器与事务管理器的结构图:
数据库的一致性状态
当数据库的数据满足数据库模式所有约束时,称数据库处于一致性的状态
由此引出事务的一个基本假设——正确性原则:如果事务在没有其他任何事务和系统错误的情况下执行,并且在它开始执行时数据库处于一致的状态,那么当事务结束时,数据库仍然处于一致的状态
事务的基础(Primitive)操作
为了使后续描述方便简洁,使用下述记法来描述所有数据在地址空间之间移动的操作:
- INPUT(X):将包含数据库元素X的磁盘块拷贝到主存缓冲区
- READ(X, t):将数据库元素X拷贝到事务的局部变量t。更准确地说,如果包含数据库元素X的块不在主存缓冲区中,则首先执行INPUT(X),接着将X的值赋给局部变量t
- WRITE(X, t):将局部变量t的值拷贝到主存缓冲区中的数据库元素X。更准确地说,如果包含数据库元素X的块不在主存缓冲区中,则首先执行INPUT(X),接着将t的值拷贝到缓冲区中的X
- OUTPUT(X):将包含X的缓冲区中的块拷贝回磁盘
现在,举例说明上述几种记法的使用方式:
假定有一个数据库,只包含A、B两个元素,这两个元素需要满足A=B的约束。即:满足A=B的约束时,这个数据库处于一致性状态
现在,假定事务T在逻辑上包含下述两步:
A := A*2;
B := B*2;
则T从一个一致的状态(A=B)出发,在不受到干扰的情况下,到达的最终状态必然也是一致的(根据之前提到的正确性原则)
假定初始时刻,A=B=8,则完成事务T的过程可以由下表表示:
| 动作 | t | 内存中的A | 内存中的B | 磁盘中的A | 磁盘中的B |
|---|---|---|---|---|---|
| READ(A, t) | 8 | 8 | 8 | 8 | |
| t := t*2 | 16 | 8 | 8 | 8 | |
| WRITE(A, t) | 16 | 16 | 8 | 8 | |
| READ(B, t) | 8 | 16 | 8 | 8 | 8 |
| t := t*2 | 16 | 16 | 8 | 8 | 8 |
| WRITE(B, t) | 16 | 16 | 16 | 8 | 8 |
| OUTPUT(A) | 16 | 16 | 16 | 16 | 8 |
| OUTPUT(B) | 16 | 16 | 16 | 16 | 16 |
只有在执行OUTPUT(A)和OUTPUT(B)这两步之间发生故障时,才会影响到磁盘中的值的一致性。如果在这样的地方出现了故障,恢复的时候就应该考虑让A和B都等于16,或者都还原为8
undo日志
日志记录构成的文件,称为日志。日志有多种类型,其中,undo日志通过撤销事务在系统崩溃前可能还没有完成的影响来修复数据库状态
日志记录
日志可以被看做一个按只允许附加的方式打开的文件
各种日志类型所用到的日志记录包括:
1、
2、
3、
对于undo日志而言,还需要的日志记录类型是更新记录:
undo日志不记录新值,只记录旧值。在恢复时,是通过还原旧值来进行的
undo日志规则
为了让undo日志能够保证从系统故障中恢复,与一个事务相关的内容应该按如下顺序写入到磁盘:
1、指出“改变数据库元素”的日志记录
2、对数据库元素进行修改
3、COMMIT日志记录
这样,按undo日志来考虑之前提到的那个事务(初始时刻A=B=8)时,就可以在进行各动作时,写入相应的日志记录:
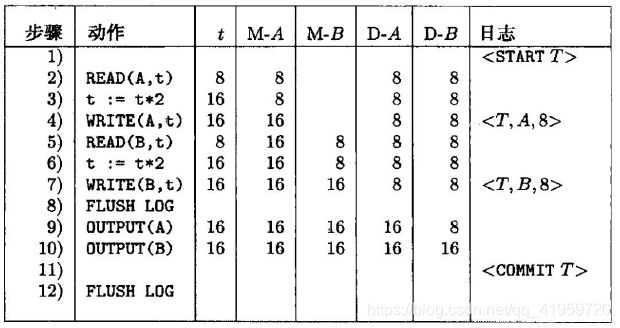
从表中可以看出,START出现在所有动作之前,COMMIT出现在OUTPUT之后,而更新记录则分别出现在两个WRITE处。其中,步骤8表示刷新日志,这是为了保证这些日志记录出现在磁盘上;而步骤12则是单独保证COMMIT能够出现在磁盘上
使用undo日志的恢复
在事务执行到一半时发生故障的情况下,事务的原子性将无法得到保证。此时,恢复管理器会使用日志,将数据库恢复到某个一致的状态
为方便讨论,此处先假定恢复管理器会查看整个日志的全部内容。如果查看到了日志记录
而如果只看到事务T的
在进行了恢复操作后,需要再往日志中添加
需要注意的是,可能有多个未完成的事务,并且这些事务对同一个值X进行了多次修改。所以从尾部开始往上扫描是非常重要的,这样可以保证按顺序恢复
检查点
前面提及恢复管理器的运作时,假设了恢复管理器会查看整个日志的全部内容。但这显然是不现实的:随着日志内容的增加,恢复管理器查看日志的耗时会越来越长
如何解决这样的问题?首先考虑在接收到COMMIT日志记录时删除整个日志的方法,这是行不通的,因为在接收到一个事务T的COMMIT记录时,另一个事务T’可能正在运行,如果直接删除,T’的记录就会丢失,变得不完整
而周期性地对日志做检查点则可以很好地解决这个问题,在一个检查点中:
- 停止接收新的事务
- 等到所有当前活跃的事务提交或中止并且在日志中写人了 COMMIT或ABORT记录
- 将日志刷新到磁盘
- 写入日志记录
,并再次刷新日志 - 重新开始接收事务
这样一来,每次从日志尾部往前走时,只要在碰到
非静止检查点
静止检查点有一个缺陷,就是等待活跃事务结束的这个过程可能会很长,这样一来,系统就会有很长一段时间处于不工作的阶段。因此,非静止检查点作为不需要等待的方法,是更受欢迎的
非静止检查点使用
对于非静止检查点而言,从日志尾部往前走时,如果先遇到了
而如果先遇到的是START记录,则说明在设立检查点期间出现了故障。这样的话,可以知道的是:未运行完成的事务一定出现在T1,…,Tn之间。这种情况下,只需从这些事务中·开始得最早的那个的START记录·开始检查即可
redo日志
undo日志有一个缺点,就是在COMMIT之后才能真正地输入新值,否则在中间发生故障就一定得“打回原点”(恢复旧值)。如果让数据库的修改暂时只存在于主存中,那么就可以节省磁盘I/O
与undo日志相反,使用redo日志恢复时,恢复的是新值(而不会打回原点)
redo日志规则
与undo日志不同,redo日志中的三元组
在redo日志规则下,与一个事务相关的内容应该按如下顺序写入到磁盘:
1、指出“改变数据库元素”的日志记录
2、COMMIT日志记录
3、改变数据库元素自身
继续以前述数据库(A=B=8)为例,其动作与日志项对应的redo版本为:
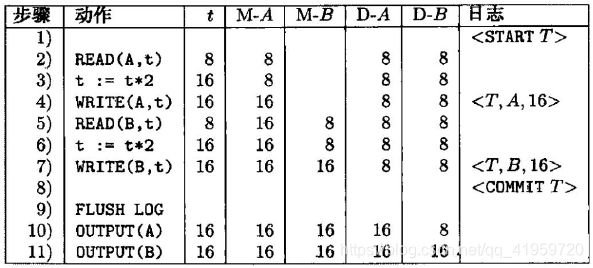
注意到与undo版本不同的地方:COMMIT不再是在OUTPUT之后,而是到了OUTPUT之前
使用redo日志的恢复
使用redo日志恢复的大致流程如下:
- 确定已提交的事务
- 从首部开始扫描日志。对遇到的每一
a) 如果T是未提交的事务,则什么也不做
b) 如果T是提交的事务,则为数据库元素X写入值v; - 对每个未完成的事务T,在日志中写人一个< ABORT T>记录并刷新日志
如果有START没有COMMIT,则肯定是可以保证磁盘没有被修改的,这个时候就可以完全不管。但如果已经COMMIT过了的话,则可能会存在磁盘只被修改了一半的情形,这个时候,以防万一,就需要将事务中涉及到的数据X恢复为新值v
redo日志的检查点
与undo不同,redo日志的检查点需要考虑脏缓冲区。因为COMMIT后并不能确认是否完整地将数据写入了磁盘,所以在检查点的开始和结束之间必须将已被提交事务修改的所有数据库元素写入到磁盘
redo日志检查时不需要等待活跃事务提交或中止就能完成检查点,redo日志的非静止检查点步骤如下:
- 写入日志记录
,其中T1,…,Tn是所有活跃(即未提交的)事务,并刷新日志 - 将
记录写入日志时所有已提交事务已经写到缓冲区但还没有写到磁盘的数据库元素写到磁盘。 - 写入日志记录
并刷新日志
使用带检查点redo日志的恢复
由于在START CKPT时不能确定在这之前提交并已经COMMIT的事务是否完成了磁盘写入,因此需要定位到上一个END CKPT对应的START CKPT处开始检查
undo/redo日志
前面所提到的undo日志和redo日志,都各有缺陷:前者具有更多磁盘I/O数,后者可能使用更多平均缓冲区数
而undo/redo日志则是以在日志中维护更多信息为代价,提供动作顺序上的更大的灵活性
undo/redo规则
undo/redo规则,在数据库元素修改值的时候,写入的更新日志记录会是一个四元组:
undo/redo日志系统必须遵从的约束:在由于某个事务T所做改变而修改磁盘上的数据库元素X前,更新记录
在undo/redo规则下,COMMIT可以出现在写入磁盘前,也可以出现在写入磁盘后,还可以出现在几次写入磁盘操作的中间
再次回到之前的例子(A=B=8)中,日志的日志项的一个可能序列为:
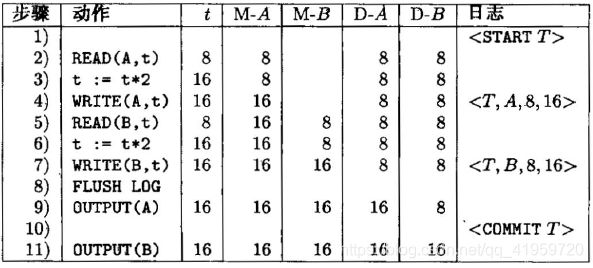
使用undo/redo日志的恢复
undo/redo日志恢复的策略:
- 按照从前往后做顺序,重做所有已提交的事务
- 按照从后往前做顺序,撤销所有未提交的事务
注意到在undo/redo日志下,undo和redo这两种日志的恢复策略被结合了起来
undo/redo日志的检查点
undo/redo日志的非静止检查点:
- 写人日志记录
,其中T1,…,Tk是所有的活跃事务,并刷新日志 - 将所有脏缓冲区写到磁盘,脏缓冲区即包含一个或多个修改过的数据库元素的缓冲区。和redo日志不同的是,我们刷新所有的脏缓冲区,而不是仅刷新那些被提交事务写过的缓冲区
- 写入日志记录
并刷新日志
针对介质故障的防护
备份
备份:维护与自身分离的一个数据库拷贝
在利用备份进行恢复时,可以使用日志恢复到最近状态