浅学C++
1C++基础入门
1.2注释
格式:
1. 单行注释://
2. 多行注释:/* */
1.3变量
变量存在的意义:方便我们管理内存空间
变量创建的语法:数据类型 变量名 = 变量初始值;
int a = 10;
1.4常量
作用:用于记录程序中不可更改的数据
C++定义常量的两种方式:
1.通常在文件上方定义,表示一个常量:
#define 宏常量
2.通常在变量定义前加关键字const,修饰该变量为常量,不可修改:
const 数据类型 变量名 = 常量值
1.5关键字
作用:关键字是C++中预先保留的单词(标识符)

1.6标识符命名规则

2数据类型
数据类型存在的意义:给变量分配合适的内存空间
2.1整型

2.2sizeof关键字
作用:利用sizeof关键字可以统计数据类型所占内存大小
语法:sizeof(数据类型/变量)
整型大小比较:short < int <= long <= long long
2.3实型(浮点型)
作用:用于表示小数
浮点型变量分为两种:
1.单精度float
2.双精度double

2.4字符型
作用:字符型变量用于显示单个字符
语法:char ch = 'a';
注意1:在显示字符型变量时,用单引号将字符括起来,不要用双引号
注意2:单引号内只能有一个字符串,不可以是字符串
·C和C++中字符型变量只占用1个字节
·字符型变量并不是把字符本身放到内存中存储,而是将对应的ASCII编码放入到存储单元
2.5转义字符
作用:用于表示一些不能显示出来的ASCII字符

2.6字符串型
作用:用于表示一串字符
两种风格:
1.C风格字符串: char 变量名[] = "字符串值"
2.C++风格字符串: string 变量名 = "字符串值"
注:使用C++风格字符串时需包含#include
2.7布尔数据bool
作用:布尔数据类型代表真或假的值
bool类型只有两个值:
true 真(本质是1)
false 假 (本质是0)
2.8数据的输入
作用:用于从键盘获取数据
关键字:cin
语法:cin >> 变量
3运算符
作用:用于执行代码的运算

3.1算术运算符
作用:用于处理四则运算

注:1.两个整数相除,结果依然是整数,将小数部分去除
2.两个小数相除结果可以是小数
注:1.前置递增: ++a 即:变量+1
2.后置递增:a++ 即:变量+1
3.前置递增和后置递增的区别:前置递增:先让变量+1,然后进行表达式运算
后置递增:先进行表达式运算,然后让变量+1
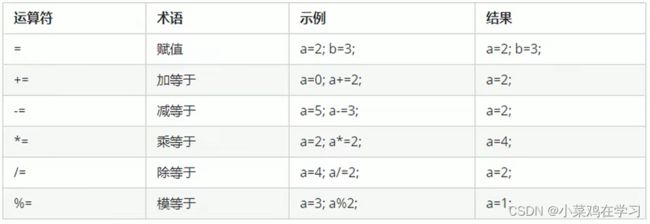
3.2赋值运算符
作用:用于将表达式的值赋给变量
3.3比较运算符
作用:用于表达式的比较,并返回一个真值或假值

3.4逻辑运算符
作用:用于根据表达式的值返回真值或假值

注:1.&& 同真为真,其余为假
2.|| 同假为假,其余为真
4程序流程结构
顺序结构、选择结构、循环结构
顺序结构:程序按顺序执行,不发生跳转
选择结构:依据条件是否满足,有选择的执行相应功能
循环结构:依据条件是否满足,循环多次执行某段代码
4.1选择结构
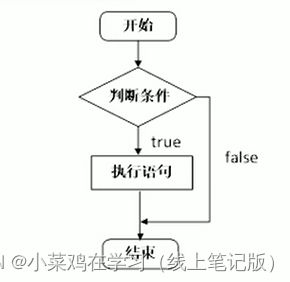
4.1.1if 语句
作用:执行满足条件的语句
if语句的三种形式:
单行格式if语句
多行格式if语句
多条件的if语句
1.单行格式if语句:if(条件){条件满足的语句}
注:if 后不加分号
2.多行格式if语句:if(条件){条件满足执行的语句}else{条件不满足的语句};

3.多条件的if语句:if(条件1){条件1满足执行的语句}else if(条件2){条件2满足执行的语句}...else{都不满足执行的语句}
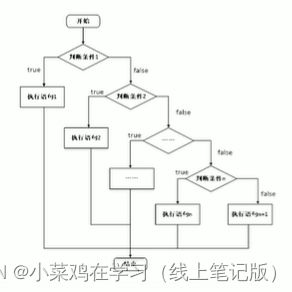
嵌套if语句:在if语句中,可以嵌套使用if语句,达到更精确的条件判断
4.1.2三目运算符
作用:通过三目运算符实现简单的判断
语法:表达式1 ? 表达式2 : 表达式3
解释:如果表达式1的值为真,执行表达式2,并返回表达式2的结果
如果表达式1的值为假,执行表达式3,并返回表达式3的结果
注:在C++中三目运算符返回的是变量,可以继续赋值
4.1.3switch语句
作用:执行多条件分支语句

注:1.switch语句中表达式类型只能是整型或者字符型
2.case里如果没有break,那么程序一直向下执行
3.与if语句比,对于多条件判断时,switch的结构清晰,执行效率高,缺点是switch不可以判断区间
4.2循环结构
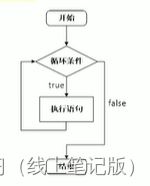
4.2.1while循环语句
作用:满足循环条件,执行循环语句
语法:while(循环条件){循环语句}
解释:只要循环条件的结果为真,就执行循环语句
4.2.2do...while循环结构
作用:满足循环条件,执行循环结构
语法:do{循环语句}while(循环条件);
注意:与while循环的区别在于do...while会先执行一次循环语句,再判断循环条件

练习案例:水仙花数
案例描述:水仙花数是指一个3位数,他的每个位上的数字的3次幂之和等于它本身
#include
#include
using namespace std;
//遍历从100-999的三位数
int main()
{
int num = 100;
do {
if ((std::pow((num / 100), 3) + std::pow(((num / 10) % 10), 3) + std::pow((num % 10), 3)) == num){
std::cout << "水仙花数是:" << num << std::endl;
}
else;
num++;
}
while (num < 1000);
system("pause");
return 0;
} 4.2.3for循环语句
作用:满足循环条件,执行循环语句
语法:for(起始表达式;条件表达式;末尾循环体){循环语句;}
练习案例:敲桌子
案例描述:从1开始数到数字100,如果数字个位含有7,或者数字十位含有7,或者该数字是7的倍数,打印出该数字。
#include
using namespace std;
int main()
{
for (int num = 1; num < 101; num++)
{
if ((num % 10 == 7) || (num / 10 == 7) || (num % 7 == 0))
{
std::cout << "值为:" << num << endl;
}
else;
}
system("pause");
return 0;
} 4.2.4嵌套循环
作用:在循环体中再嵌套一层循环,解决一些实际问题
练习案例:乘法口诀表
#include
using namespace std;
int main()
{
for (int i = 1; i <= 9; i++) //行数
{
for (int j = 1; j <= i; j++)
{
cout << j << "*" << i << "=" << j * i << " ";
}
cout << endl;
}
system("pause");
return 0;
} 4.3跳转语句
4.3.1break语句
作用:用于跳出选择结构或者循环结构
break使用的时机:
1.出现在switch条件语句中,作用是终止case并跳出switch
2.出现在循环语句中,作用是跳出当前的循环语句
3.出现在嵌套循环中,跳出最近的内层循环语句
4.3.2continue语句
作用:在循环语句中,跳出本次循环中余下尚未执行的语句,继续执行下一次循环
4.3.3跳转语句
作用:可以无条件跳转语句
语法:goto 标记;
解释:如果标记的名称存在,执行到goto语句时,会跳转到标记的位置
5数组
5.1概述
所谓数组,就是一个集合,里面存放了相同类型的数据元素
特点1:数组中的每个数据元素都是相同的数据类型
特点2:数组是由连续的内存位置组成的
5.2一维数组
5.2.1一维数组定义的三种方式
一维数组定义的三种方式:
1.数据类型 数组名[ 数据长度 ];
2.数据类型 数组名[ 数组长度 ] = { 值1,值2,...};
3.数据类型 数组名[ ] = { 值1, 值2 ...};
数组的特点:
1.放在一块连续的内存空间中
2.数组中每个元素都是相同数据类型
5.2.2一维数组数组名
一维数组名称的用途:
1.可以统计整个数组在内存中的长度
sizeof(arr)
2.可以获取数组在内存中的首地址
sizeof(arr)/sizeof(arr[0])

练习案例:五只小猪称体重
案例描述:在一个数组中记录了五只小猪的体重,如:int arr[5]={300,350,200,400,250};找出并打印最重的小猪体重
#include
using namespace std;
int main()
{
int arr[5] = { 300, 350, 200, 400, 250 };
int a = 0;
int b = 0;
for (int i = 0; i < 5; i++) {
if (arr[i] < arr[i + 1])
{
a = arr[i + 1];
b = i;
}
}
cout << a << endl;
cout << b << endl;
system("pause");
return 0;
} 练习案例:数组元素逆置
案例描述:请声明一个5个元素的数组,并且将元素逆置。(如原数组元素为:1,3,2,5,4;逆置后输出结果:4,5,2,3,1)
/*
#include
using namespace std;
int main() {
int arr[5] = {1, 2, 3, 4, 5};
int a = 0;
for (int i = 0; i < 3; i++) {
a = arr[i];
arr[i] = arr[4 - i];
arr[4 - i] = a;
}
for (int i = 0; i < 5; i++) {
cout << arr[i] << endl;
}
system("pause");
return 0;
}
*/
#include
using namespace std;
int main()
{
//实现数组元素逆置
//1.创建数组
int arr[5]= {1, 2, 3, 4, 5};
cout << "数组逆置前:" << endl;
for (int i = 0; i < 5; i++)
{
cout << arr[i] << endl;
}
//2.实现逆置
//2.1记录起始下标位置
//2.2记录结束下标位置
//2.3起始下标与结束下标的元素互换
//2.4起始位置++ 结束位置--
//2.5循环执行2.1操作,直到起始位置>=结束位置
int start = 0; //起始下标
int end = sizeof(arr) / sizeof(arr[0]) - 1;//结束下标
while (start < end)
{
//实现元素逆转
int temp = arr[start];
arr[start] = arr[end];
arr[end] = temp;
//下标更新
start++;
end--;
}
//3.打印逆置后的数组
cout << "数组逆置后:" << endl;
for (int i = 0; i < 5; i++)
{
cout << arr[i] << endl;
}
} 5.2.3冒泡排序
作用:最常用的排序算法,对数组内元素进行排序
1.比较相邻的元素。如果第一个比第二个大,就交换他们两个
2.对每一对相邻元素做同样的工作,执行完毕后,找到第一个最大值
3.重复以上的步骤,每次比较次数-1,直到不需要比较

#include
using namespace std;
int main()
{
//利用冒泡排序实现升序序列
int arr[] = { 4, 2, 8, 0, 5, 7, 1, 3, 9 };
cout << "排序前:" << endl;
for (int i = 0; i < 9; i++)
{
cout << arr[i] << " ";
}
cout << endl;
//开始冒泡排序
//总共排序轮数为元素个数-1
for (int i = 0; i < 9 - 1; i++)
{
//内层循环对比 次数=元素个数-当前论述-1
for (int j = 0; j < 9 - i - 1; j++)
{
//如果第一个数字比第二个数字大,交换这两个数字
if (arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
//排序后的结果
cout << "排序后:" << endl;
for (int i = 0; i < 9; i++)
{
cout << arr[i] << " ";
}
cout << endl;
system("pause");
return 0;
} 5.3二维数组
二维数组就是在一维数组上,多加一个维度
5.3.1二维数组定义方式
二维数组定义的四种方式:
1.数据类型 数据名[ 行数 ][ 列数 ];
2.数据类型 数据名[ 行数 ][ 列数 ] = { { 数据1, 数据2 }, { 数据3, 数据4 } };
1.数据类型 数据名[ 行数 ][ 列数 ] = { 数据1, 数据2 , 数据3, 数据4 };
1.数据类型 数据名[ ][ 列数 ] = { 数据1, 数据2 , 数据3, 数据4 };
建议:以上4种方式,利用第二种更加直观,提高代码的可读性
5.3.2二维数组数组名
查看二维数组所占内存空间
获取二维数组首地址
#include
using namespace std;
int main()
{
//二维数组名称用途
//1.可以查看二维数组的首地址
int arr[2][3] =
{
{1,2,3},
{4, 5, 6}
};
cout << "二维数组占用内存空间为:" << sizeof(arr) << endl;
cout << "二维数组第一行占用内存空间为:" << sizeof(arr[0]) << endl;
cout << "二维数组第一个元素占用内存空间为:" << sizeof(arr[0][0]) << endl;
cout << "二维数组行数为:" << sizeof(arr) / sizeof(arr[0]) << endl;
cout << "二维数组列数为:" << sizeof(arr[0]) / sizeof(arr[0][0]) << endl;
//2.可以查看二维数组的首地址
cout << "二维数组首地址为:" << (int)arr << endl;
cout << "二维数组第一行首地址为:" << (int)arr[0] << endl;
cout << "二维数组第二行首地址为:" << (int)arr[1] << endl;
//&对某个值查看地址,取值符&
cout << "二维数组第一个元素首地址为:" << (int)&arr[0][0] << endl;
system("pause");
return 0;
} 应用案例:
考试成绩统计:有三位同学(张三,李四,王五),在一次考试中的成绩分别如下表,请分别输出三名同学的总成绩:
| 语文 | 数学 | 英语 | |
| 张三 | 100 | 100 | 100 |
| 李四 | 90 | 50 | 100 |
| 王五 | 60 | 70 | 80 |
#include
using namespace std;
#include
int main()
{
//二维数组案例-考试成绩统计
//1.创建二维数组
int scores[3][3] =
{
{100,100,100},
{90,50,100},
{60,70,80}
};
string names[3] = { "张三", "李四", "王五" };
//2.统计每个人的综合分数
for (int i = 0; i < 3; i++)
{
int sum = 0; //统计分数总和变量
for (int j = 0; j < 3; j++)
{
sum += scores[i][j];
}
cout << names[i] << "的总分为:" << sum << endl;
}
system("pause");
return 0;
} 6函数
6.1概述
作用:将一段经常使用的代码封装起来,减少重复代码
一个较大的程序,一般分为若干个程序块,每个模块实现特定的功能
6.2函数的定义
函数的定义一般主要有5个步骤:
1.返回值类型
2.函数名
3.参数列表
4.函数体语句
5.return表达式
语法:
返回值类型 函数名 (参数列表)
{
函数体语句
return表达式
}
返回值类型:一个函数可以返回一个值,在函数定义中
函数名:给函数起个名称
参数列表:使用该函数时,传入的数据
函数体语句:花括号内的代码,函数内需要执行的语句
return表达式:和返回值类型挂钩,函数执行完后,返回相应的数据
6.3函数的调用
功能:使用定义好的函数
语法:函数名(参数)
6.4值传递
所谓值传递,就是函数调用时实参将数值传入形参
值传递时,如果形参发生,并不会影响实参
6.5函数的常见形式
常见的函数样式有4种:
1.无参无返
2.有参无返
3.无参有返
4.有参有返
6.6函数的声明
作用:告诉编译器函数名称及如何调用函数。函数的实际主体可以单独定义
函数的声明可以多次,但是函数的定义只能有一次
6.7函数的分文件编写
作用:让代码结构更加清晰
函数分文件编写一般有4个步骤
1.创建后缀名为.h的头文件
2.创建后缀名为.cpp的源文件
3.在头文件中写函数的声明
4.在源文件中写函数的定义
7指针
7.1指针的基本概念
指针的作用:可以通过指针间接访问内存
内存编号是从0开始记录的,一般用十六进制数字表示
可以利用指针变量保存地址
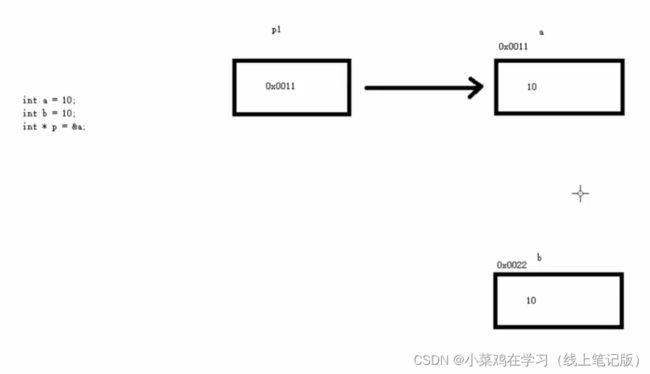
7.2指针变量的定义和使用
指针定义的语法:数据类型 * 指针变量名;
#include
using namespace std;
int main()
{
//1.定义指针
int a = 10 ;
//指针定义的语法: 数据类型 * 指针变量名;
int * p ;
//让指针记录变量a的地址
p = &a;
cout << "a的地址为:" << &a << endl;
cout << "指针p为:" << p << endl;
//2.使用指针
//可以通过解引用的方式来找到指针指向的内存
//指针前加 * 代表解引用,找到指针指向的内存中的数据
*p = 1000;
cout << "a=" << a << endl;
cout << "*p=" << *p << endl;
system("pause");
return 0;
} 7.3指针所占内存空间
32位操作系统:占4个内存空间
64位操作系统: 占8个内存空间
7.4空指针和野指针
空指针:指针变量指向内存中编号为0的空间
用途:初始化指针变量
注意:空指针指向的内存是不可以访问的
野指针:指针变量指向非法的内存空间
#include
using namespace std;
int main()
{
//空指针
//1.空指针用于给指针变量进行初始化
int* p = NULL;
//2.空指针是不可以进行访问的
//0~255之间的内存编号是系统占用的,因此不可以访问
system("pause");
return 0;
} 总结:空指针和野指针都不是我们申请的空间,因此不要访问他
7.5const修饰指针
const修饰指针有三种情况:
1.const修饰指针 --常量指针
const int * p = &a;
特点:指针的指向可以修改,但是指针指向的值不可以改
*p = 20; 错误,指针指向的值不可以改
p = &b;正确,指针指向可以改
2.const修饰常量 --指针常量
int * const p = &a;
特点:指针的指向不可以改,指针指向的值可以改
*p = 20;正确,指向的值可以改
p = &b;错误,指针指向不可以改
3.const即修饰指针,又修饰常量
const int * const p = &a;
特点:指针的指向和指针指向的值都不可以改
*p = 20;错误,指向的值不可以改
p = &b;错误,指针指向不可以改
技巧:看const右侧紧跟着的是指针还是常量,是指针就是常量指针,是常量就是指针常量
7.6指针和数组
作用:利用指针访问数组中元素
#include
using namespace std;
int main()
{
//指针和数组
//利用指针访问数组中的元素
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = arr; //arr就是数组首地址
cout << "利用指针访问第一个元素:" << *p << endl;
p++;//让指针向后偏移4个字节
cout << "利用指针访问第二个元素:" << *p << endl;
cout << "利用指针遍历数组" << endl;
int* p2 = arr;
for (int i = 0; i < 10; i++)
{
cout << *p2 << endl;
p2++;
}
system("pause");
return 0;
} 7.7指针和函数
作用:利用指针作函数参数,可以修改实参的值
#include
using namespace std;
//实现两个数字进行交换
void swap01(int a, int b)
{
int temp = a;
a = b;
b = temp;
cout << "swap01 a=" << a << endl;
cout << "swap01 b=" << b << endl;
}
void swap02(int * p1, int * p2)
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
cout << "swap01 a=" << *p1 << endl;
cout << "swap01 b=" << *p2 << endl;
}
int main()
{
//指针和函数
//1.值传递
int a = 10;
int b = 20;
swap01(a, b);
cout << "a=" << a << endl;
cout << "b=" << b << endl;
//2.地址传递
swap02(&a, &b);
cout << "a=" << a << endl;
cout << "b=" << b << endl;
system("pause");
return 0;
} 总结:如果不想修改实参,就用值传递,如果想修改实参,就用地址传递
7.8指针、数组、函数
案例描述:封装一个函数,利用冒泡排序,实现对整型数组的升序排序
例如数组: int arr[10] = {1, 2, 3, 4, 6, 7, 8, 9, 10, 5};
#include
using namespace std;
//冒泡排序函数 参数1:数组的首地址,参数2:数组长度
void bubbleSort(int * arr, int len)
{
for (int i = 0; i < len - 1; i++)
{
for (int j = 0; j < len - i - 1; j++)
{
//如果j>j+1的值,交换数字
if (arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
//打印数组
void printArray(int * arr, int len)
{
for (int i = 0; i < len; i++)
{
cout << arr[i] << endl;
}
}
int main()
{
//1.先创建一个数组
int arr[10] = { 1, 2, 3, 4, 6, 7, 8, 9, 10, 5 };
//数组长度
int len = sizeof(arr) / sizeof(arr[0]);
//2.创建一个函数,实现冒泡排序
bubbleSort(arr, len);
//3.打印排序后的数组
printArray(arr, len);
system("pause");
return 0;
} 8结构体
8.1结构体基本概念
结构体属于用户自定义的数据类型,允许用户存储不同的数据类型
8.2结构体定义和使用
语法:struct 结构体名 { 结构体成员列表 };
通过结构体创建变量的方式有三种:
·struct 结构体名 = 变量名
·struct 结构体名 变量名 = { 成员1值, 成员2值... }
·定义结构体时顺便创建变量
#include
using namespace std;
#include
//1.创建学生数据类型:学生包括(姓名,年龄,分数)
//自定义数据类型,一些类型集合组成的一个类型
//语法 struct 类型名称 { 成员列表 姓名 年龄 分数 }
struct Student
{
//成员列表
//姓名
string name;
//年龄
int age;
//分数
int score;
}s3; //顺便创建结构体变量
//2.通过学生类型创建具体学生
int main()
{
//2.1 struct Student s1
//struct关键词可以省略
struct Student s1;
//给s1属性赋值,通过.访问结构体变量中的属性
s1.name = "张三";
s1.age = 18;
s1.score = 100;
cout << "姓名:" << s1.name << "年龄:" << s1.age << "分数:" << s1.score << endl;
//2.2 struct Student s2 = { ... }
struct Student s2 = { "李四", 19, 80 };
cout << "姓名:" << s2.name << "年龄:" << s2.age << "分数:" << s2.score << endl;
//2.3 在定义结构体时顺便创建结构体变量
s3.name = "王五";
s3.age = 20;
s3.score = 60;
cout << "姓名:" << s3.name << "年龄:" << s3.age << "分数:" << s3.score << endl;
system("pause");
return 0;
} 总结:
定义结构体时的关键字是struct,不可省略
创建结构体变量时,关键字struct可以省略
结构体变量利用操作符“ . ”访问成员
8.3结构体数组
作用:将自定义的结构体放入到数组中方便维护
语法:struct 结构体名 数组名[ 元素个数 ] = { {}, {}, ... {} }
#include
using namespace std;
#include
//结构体数组
//1.定义结构体
struct Student
{
//成员列表
//姓名
string name;
//年龄
int age;
//分数
int score;
};
int main()
{
//2.创建结构体数组
struct Student stuArray[3] =
{
{"张三", 18, 100},
{"李四", 28, 99},
{"王五", 38, 66}
};
//3.给结构体数组中的元素赋值
stuArray[2].name = "赵六";
//4.遍历结构体数组
for (int i = 0; i < 3; i++)
{
cout << "姓名: " << stuArray[i].name <<" "
<< "年龄: " << stuArray[i].age << " "
<< "分数: " << stuArray[i].score << " " << endl;
}
system("pause");
return 0;
} 8.4结构体指针
作用:通过指针访问结构体中的成员
利用操作符 -> 可以通过结构体指针访问结构体属性
#include
using namespace std;
#include
//结构体指针
//定义结构体
struct Student
{
//成员列表
//姓名
string name;
//年龄
int age;
//分数
int score;
};
int main()
{
//1.创建学生结构体变量
struct Student s = { "张三", 18, 100 };
//2.通过指针指向结构体变量
Student* p = &s;
//3.通过指针访问结构体变量中的数据
//通过结构体指针 访问结构体中的属性,需要利用“->”
cout << "姓名:" << p->name << "年龄:" << p->age << "分数:" << p->score << endl;
system("pause");
return 0;
} 8.5结构体嵌套结构体
作用:结构体中的成员可以是另一个结构体
例如:每个老师辅导一个学员,一个老师的结构体中,记录一个学生的机构体
#include
#include
using namespace std;
//学生结构体定义
struct student
{
//成员列表
string name; //姓名
int age; //年龄
int score; //分数
};
//教师结构体定义
struct teacher
{
//成员列表
int id; //职工编号
string name; //教师姓名
int age; //教师年龄
struct student stu; //子结构体 学生
};
int main()
{
struct teacher t1;
t1.id = 10000;
t1.name = "老王";
t1.age = 81;
t1.stu.name = "小王";
t1.stu.age = 12;
cout << "老师的编号:" << t1.id
<< "\n老师的姓名:" << t1.name
<< "\n老师的年龄:" << t1.age
<< "\n学生的姓名:" << t1.stu.name
<< "\n学生的年龄:" << t1.stu.age << endl;
system("pause");
return 0;
} 总结:在结构体中可以定义另一个结构体作为成员,用来解决实际问题
8.6结构体做函数参数
作用:将结构体作为参数向函数中传递
传递方式有两种
值传递
地址传递
#include
#include
using namespace std;
//学生结构体定义
struct student
{
//成员列表
string name; //姓名
int age; //年龄
int score; //分数
};
//值传递
void printStudent(student stu)
{
stu.age = 28;
cout << "子函数中 姓名:" << stu.name << " 年龄: " << stu.age << " 分数:" << stu.score << endl;
}
//地址传递
void printStudent2(student* stu)
{
stu->age = 28;
cout << "子函数中 姓名:" << stu->name << " 年龄: " << stu->age << " 分数:" << stu->score << endl;
}
int main() {
student stu = { "张三",18,100 };
//值传递
printStudent(stu);
cout << "主函数中 姓名:" << stu.name << " 年龄: " << stu.age << " 分数:" << stu.score << endl;
cout << endl;
//地址传递
printStudent2(&stu);
cout << "主函数中 姓名:" << stu.name << " 年龄: " << stu.age << " 分数:" << stu.score << endl;
system("pause");
return 0;
} 总结:如果不想修改主函数中的数据,用值传递,反之用地址传递
8.7结构体中const使用场景
作用:用const来防止误操作
#include
#include
using namespace std;
//学生结构体定义
struct student
{
//成员列表
string name; //姓名
int age; //年龄
int score; //分数
};
//const使用场景
//将函数中的形参改为指针,可以减少内存空间,而且不会复制新的副本出来
void printStudent(const student* stu) //加const防止函数体中的误操作
{
//stu->age = 100; //操作失败,因为加了const修饰
//加入const之后,一旦有修改的操作就会报错,可以防止我们的误操作
cout << "姓名:" << stu->name << " 年龄:" << stu->age << " 分数:" << stu->score << endl;
}
int main() {
//创建结构体变量
student stu = { "张三",18,100 };
printStudent(&stu);
system("pause");
return 0;
} 8.8结构体案例
8.8.1案例1
案例描述:
学校正在做毕设项目,每名老师带领5个学生,总共有3名老师,需求如下:设计学生和老师的结构体,其中在老师的结构体中,有老师姓名和一个存放5名学生的数组作为成员学生的成员属性有姓名、考试分数,创建数组存放3名老师,通过函数给每个老师及所带的学生赋值。最终打印出老师数据以及老师所带的学生数据。
#include
#include
#include
using namespace std;
//学生结构体
struct Student
{
string name;
int score;
};
//老师结构体
struct Teacher
{
string name;
Student sArray[5];
};
//给老师和学生赋值的函数
void allocateSpace(Teacher tArray[], int len)
{
string tName = "教师";
string sName = "学生";
string nameSeed = "ABCDE";
//给老师开始赋值
for (int i = 0; i < len; i++)
{
tArray[i].name = tName + nameSeed[i];
//通过循环给每名老师所带的学生赋值
for (int j = 0; j < 5; j++)
{
tArray[i].sArray[j].name = sName + nameSeed[j];
tArray[i].sArray[j].score = rand() % 61 + 40; //40~100
}
}
}
//打印老师和学生的信息
void printTeachers(Teacher tArray[], int len)
{
for (int i = 0; i < len; i++)
{
cout << tArray[i].name << endl;
for (int j = 0; j < 5; j++)
{
cout << "\t姓名:" << tArray[i].sArray[j].name << " 分数:" << tArray[i].sArray[j].score << endl;
}
}
}
int main() {
srand((unsigned int)time(NULL)); //随机数种子 头文件 #include
//1.创建3名老师的数组
Teacher tArray[3];
//2.通过函数给3名老师的信息赋值,并给老师带的学生信息赋值
int len = sizeof(tArray) / sizeof(Teacher);
allocateSpace(tArray, len); //创建数据
//3.打印所有老师以及所带的学生信息
printTeachers(tArray, len); //打印数据
system("pause");
return 0;
} 8.8.2案例2
案例描述:
设计一个英雄的结构体,包括成员姓名,年龄,性别;创建结构体数组,数组中存放5名英雄。通过冒泡排序的算法,将数组中的英雄按照年龄进行升序排序,最终打印排序后的结果。
五名英雄信息如下:
{"刘备",23,"男"},
{"关羽",22,"男"},
{"张飞",20,"男"},
{"赵云",21,"男"},
{"貂蝉",19,"女"},#include
#include
using namespace std;
//1.设计英雄结构体
struct hero
{
string name; //姓名
int age; //年龄
string gender; //性别
};
//冒泡排序 实现年龄升序排列
void bubbleSort(struct hero heroArray[], int len)
{
for (int i = 0; i < len - 1; i++)
{
for (int j = 0; j < len - i - 1; j++)
{
//如果j下标的元素年龄 大于 j+1下标的元素的年龄,交换两个元素
if (heroArray[j].age > heroArray[j + 1].age)
{
struct hero temp = heroArray[j];
heroArray[j] = heroArray[j + 1];
heroArray[j + 1] = temp;
}
}
}
}
//打印排序后数组中的信息
void printhero(struct hero heroArray[], int len)
{
for (int i = 0; i < len - 1; i++)
{
cout << " 姓名: " << heroArray[i].name << " 年龄: " << heroArray[i].age << " 性别: " << heroArray[i].gender << endl;
}
}
int main()
{
//2.创建数组存放5名英雄
struct hero heroArray[5] =
{
{"刘备",23,"男"},
{"关羽",22,"男"},
{"张飞",20,"男"},
{"赵云",21,"男"},
{"貂蝉",19,"女"},
};
int len = sizeof(heroArray) / sizeof(heroArray[0]);
cout << "排序前的结果:" << endl;
for (int i = 0; i < len; i++)
{
cout << " 姓名: " << heroArray[i].name << " 年龄: " << heroArray[i].age << " 性别: " << heroArray[i].gender << endl;
}
//3.对数组进行排序,按照年龄进行升序排序
bubbleSort(heroArray, len);
//4.将排序后结果打印输出
cout << "排序后的结果:" << endl;
printhero(heroArray, len);
system("pause");
return 0;
}