Python面试总结
目录
Python基础
1. print()函数调用Python底层的什么方法?
2. 简单说下对input()函数的理解
3. read、readline和readlines的区别
4. 在except中return还会不会执行finally中的代码?如何抛出自定义异常?
5. 内存小于文件大小的场景,如何读入文件内容?怎么实现?
6. 字符串拼接使用+和使用str.join()方法的比较
7. 经典类和新式类的区别
8. 单例模式实现
9. 赋值、浅拷贝和深拷贝
9.1 赋值
9.2 浅拷贝
9.3 深拷贝
10. Python单元测试框架
11. 输入年、月、日,判断这一天是这一年的第几天
12. 列举random模块的常用方法
13. lambda函数
14. 闭包
15. 不使用中间变量交换两个变量的值
Python并发
1. Python线程的描述
2. Python进程的描述
3. 进程与线程的区别
4. Python多线程执行耗时长的原因
数据库
1. 使用 Python DB Api访问数据库流程
Linux
1. find .
2. 查找目录中大于特定大小的文件
算法
1. 冒泡排序
1.1 原理
1.2 代码
1.3 分析
TCP/IP
1. 常见HTTP状态码
1.1 404
1.2 403
1.3 500
编程题
题目1:求字符串中的最长子串
题目描述
解决方案
代码
题目2: 求一个数的n次方
题目描述
解决方案
笔者总结下自己在2019.7 ---- 2019.8这个时间段内面试Python相关岗位时遇到的部分面试题。仅供参考。
Python基础
绝大多数公司在面试的开始会提问几个基础性问题做为暖场。
1. print()函数调用Python底层的什么方法?
答案:print()函数默认调用sys.stdout.write()方法,即往控制台打印字符串。
print()函数传送门:
https://blog.csdn.net/TCatTime/article/details/83450692
2. 简单说下对input()函数的理解
答案:在Python3中,input()函数获取用户输入,无论用户输入的是什么,获取到的都是字符串类型。
input()函数传送门:
https://blog.csdn.net/TCatTime/article/details/82556033
3. read、readline和readlines的区别
- read()方法:读取整个文件;
- readline()方法:每次读入文件的一行。借助循环可一行行读完整个文件;
- readlines()方法:读入所有行,并返回一个列表。列表中的每个元素就是文件中的每一行。
read()方法传送门:
https://blog.csdn.net/TCatTime/article/details/97376248
4. 在except中return还会不会执行finally中的代码?如何抛出自定义异常?
在except中return(甚至exit())都还会执行finally中的代码。
使用关键字raise抛出自定义异常。
5. 内存小于文件大小的场景,如何读入文件内容?怎么实现?
设计思路
文件需要分批读入。分批读入数据要记录每次读入数据的位置;还要考虑每次分批读入数据的大小,太小就会在读取操作上花费过多时间。
代码实现
import os
def get_data(url, size):
if not os.isFile(url):
raise Exception("%s is not a file." % url)
if size <= 0:
raise Exception("Can not read file. Size must more than zero.")
with open(url, "r") as file:
while True:
line = file.readlines(size)
if not line:
break
yield line
6. 字符串拼接使用+和使用str.join()方法的比较
在Python中字符串是不可变对象,修改字符串就得将原字符串中的值复制,开辟一块新的内存,将修改后的内容写到新内存中,以达到“修改”字符串的效果。使用+多次拼接字符串时,重复性的申请新内存和写入消耗了大量时间。而使用join()方法拼接字符串时,会先计算总共需要申请多少内存,然后一次性申请所需内存并将字符串拼接后的结果复制过去。这样便省去了重复性的内存申请和写入,节省了时间消耗。
str.join()方法传送门:
https://blog.csdn.net/TCatTime/article/details/85254896
7. 经典类和新式类的区别
- 在Python中凡是继承了object的类,都是新式类
- Python3中只有新式类
- 经典类目前在Python中基本没有应用
8. 单例模式实现
def deo(cls):
ins = {}
def wapper(*args, **kwargs):
if cls not in ins:
ins[cls] = cls(*args, **kwargs)
return ins[cls]
return wapper
@ deo
class Demo():
pass
9. 赋值、浅拷贝和深拷贝
9.1 赋值
对象的赋值就是简单地对象引用。
赋值操作不会开辟新的内存空间,它只是复制了对象的引用。
>>> demo = 3
>>> new_demo = demo
>>> id(demo)
4531386368
>>> id(new_demo)
45313863689.2 浅拷贝
【定义】
浅拷贝会创建新的对象,其内容并非原对象本身的引用,而是原对象内第一层对象的引用。
【浅拷贝的三种形式】
- 切片
- 内置函数转换
- copy.copy()函数
【示例】
例如下面的代码,使用copy.copy()函数浅拷贝了demo列表得到一个新列表new。new的内存地址与demo不同,但是new内的每一个元素的内存地址与demo的每一个元素的内存地址是一样的。
>>> import copy
>>> demo = [2, 6, 1]
>>> new = copy.copy(demo)
>>> id(demo)
4534666120
>>> id(new)
4534627272
>>>
>>> id(demo[0])
4531386336
>>> id(new[0])
45313863369.3 深拷贝
【定义】
深拷贝拷贝对象的所有元素,包括多层嵌套的元素。因此深拷贝的时空开销较高。
【深拷贝的形式】
- copy.deepcopy()
【示例】
import copy
class Test():
def __init__(self, data):
self.level = data
if __name__ == '__main__':
t1 = Test(3)
t2 = Test(6)
demo = [t1, t2]
clone = copy.deepcopy(demo)
print("id(demo)=%s, id(clone)=%s" % (id(demo), id(clone)))
print("id(demo[0])=%s, id(clone[0])=%s" % (id(demo[0]), id(clone[0])))运行结果:
id(demo)=4424245384, id(clone)=4424228296
id(demo[0])=4424516328, id(clone[0])=4424555600可见,深拷贝将每一层嵌套的元素也都拷贝了。
10. Python单元测试框架
unittest测试框架
11. 输入年、月、日,判断这一天是这一年的第几天
import datetime
def compute_days(year, month, day):
try:
date1 = datetime.date(year=int(year), month=int(month),
day=int(day))
date2 = datetime.date(int(year), 1, 1)
result = (date1 - date2).days + 1
return result
except ValueError:
print("Invalid datetime %s-%s-%s." % (year, month, day))⚠️注意事项:注意审题,结果是要求“第”几天,因此要在求得的最终差值上+1.
12. 列举random模块的常用方法
- random.random() 生成一个0~1之间的浮点数
- random.uniform(a, b) 生成一个a~b之间的浮点数(包含a、b)
- random.randint(a, b) 生成一个a~b之间的整数(包含a、b)
- random.choice(sequence) 从序列中随机选取一个数
- random.shuffle(list) 打乱一个列表
13. lambda函数
lambda函数是用一条语句表达的匿名函数,可以用它来代替小的函数。通常使用实际的函数会比使用lambda函数更清晰明了。但是,当需要定义很多小的函数以及记住它们的名字时,lambda会非常有用。
14. 闭包
闭包是一个可以由另一个函数动态生成的函数,并且可以改变和存储函数外创建的变量的值。
15. 不使用中间变量交换两个变量的值
>>> a = 1
>>> b = 2
>>> a, b = b, a
>>> print("a=%s, b=%s" % (a, b))
a=2, b=1
Python并发
1. Python线程的描述
线程是一个基本的CPU执行单元。它必须依托于进程存活。一个线程是一个执行上下文,即一个CPU执行时所需要的一串指令。在Python中,多线程耗时更长。
2. Python进程的描述
进程是指一个程序在给定数据集合上的一次执行过程,是系统进行资源分配和运行调用的独立单位。可以简单地理解为操作系统中正在执行的程序。也就是说,每个应用程序都有一个自己的进程。
每一个进程启动时都会最先产生一个线程,即主线程。主线程会创建其它的子线程。
3. 进程与线程的区别
- 线程必须在某个进程中执行;
- 一个进程可以包含多个线程,其中有且只有一个是主线程;
- 多线程共享同一个地址空间、打开的文件以及其它资源;
- 多进程共享物理内存、磁盘、打印机以及其它设备。
4. Python多线程执行耗时长的原因
其它语言(例如Java),CPU是多核时是支持多个线程同时执行。但在Python中,无论程序执行在单核还是多核的机器,同时只能由一个线程在执行,其根源是GIL的存在。
GIL是全局解释器锁。来源是Python设计之初的考虑,为了数据安全所做的决定。某个线程想要执行,必须先拿到GIL。但在一个Python进程中,GIL只有一个。拿不到GIL的线程,就不允许进入CPU执行。
数据库
1. 使用 Python DB Api访问数据库流程
1、创建connection
2、获取cursor
3、执行命令,处理数据
4、关闭cursor
5、关闭connection
Linux
1. find .
find . 命令列出当前目录下的所有文件和文件夹
2. 查找目录中大于特定大小的文件
find 目录 -size +大小例如要查找当前目录下文件大于10k的文件:
➜ log git:(master_6.0.0) ✗ find /Users/mymac/FusionStudent_lite/log -size +10k
/Users/mymac/FusionStudent_lite/log/warn.log
/Users/mymac/FusionStudent_lite/log/.DS_Store
/Users/mymac/FusionStudent_lite/log/info.log
算法
1. 冒泡排序
1.1 原理
从第1个元素开始,比较相邻元素的大小。若大小顺序有误,则对调后再进行下一个元素的比较。如此扫描过一次之后,就可以确保最后一个元素位于正确的顺序。
1.2 代码
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]1.3 分析
- 最好时间复杂度
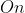
- 平均时间复杂度
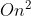
- 最坏时间复杂度
- 只需要1个额外空间,因此空间复杂度为最佳
- 冒泡排序适用于数据量小或部分数据已经排过序的状况
TCP/IP
1. 常见HTTP状态码
1.1 404
服务器无法根据客户端发送的请求找到资源(网页)。
1.2 403
服务器理解客户端的请求,但是拒绝执行此请求。
1.3 500
服务器内部错误,无法完成请求。
编程题
题目1:求字符串中的最长子串
题目描述
编写一个函数,要求在一个已知字符串找到最长的子串,子串要求首尾字符相同,在此子串中不能再包含首尾字符,输出复合要求的最长子串。
例如:ABCDAEFA的最长子串输出为BCD
请考虑所有可能的情况进行程序设计。
解决方案
可以使用队列来解决此问题。当队列的首尾字符相同时,队列中间部分的字符串就是所得解。比较所有所得解的最长字符,就是最终的结果。最后将结果输出即可。
代码
class Queue():
def __init__(self):
self.base = []
def insert(self, element):
self.base.append(element)
def length(self):
return len(self.base)
def pop(self):
if self.length() <= 0:
return
return self.base.pop(0)
def bingo(self):
if self.length() <= 1:
return False
return self.base[0] == self.base[-1]
def front(self):
if self.length() <= 0:
return
return self.base[0]
def exist(self, text):
if self.length() < 1:
return False
top = self.base[0]
if top in text:
return True
else:
return False
def dump(queue):
pre = ""
first = queue.pop()
while queue.front() != first:
pre += queue.pop()
return pre
def get_max_length_string(text):
result = ""
queue = Queue()
index = 0
for char in text:
queue.insert(char)
if queue.bingo():
pre = dump(queue)
if len(pre) > len(result):
result = pre
if not queue.exist(text[index:]):
queue.pop()
index += 1
return result
if __name__ == '__main__':
demo = "abacdsqa"
result = get_max_length_string(demo)
print(result)
题目2: 求一个数的n次方
题目描述
给定一个整数x和一个整数n,求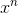 的值。要求时间复杂度尽可能低。
的值。要求时间复杂度尽可能低。
解决方案
时间复杂度为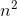 的解决方案:
的解决方案:
pow(x, n)时间复杂度为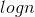 的解决方案:
的解决方案:
def my_pow(x, n):
if n == 0:
return 1
p = pow(x, n//2)
if n % 2 == 0:
return p * p
if n > 0:
return p * p * x
return p * p / x在上例优化下,使用递归变成更短的时间复杂度:
def my_pow(x, n):
if n == 0:
return 1
p = pow(x, n//2)
if n % 2 == 0:
return p * p
if n > 0:
return p * p * x
return p * p / x
def power(x, n):
if n < 0:
result = my_pow(x, abs(n))
return 1 / result
else:
return my_pow(x, n)
if __name__ == '__main__':
print(power(3, -1))