BoltDB学习笔记
文章目录
-
- 一、boltdb简介
-
- 1、boltdb是什么
- 2、为什么分析boltdb
- 3、boltdb对比其它数据库
- 4、boltdb的用法入门
- 5、boltdb性能提升
- 二、BoltDB的数据结构
- 三、BoltDB中的B+树和Bucket
-
- 1、Bucket结构
- 2、Cursor结构
- 3、Node结构
- 4、K/V操作
- 四、BoltDB事务
-
- 1、事务原理
- 2、事务源码
-
- Tx结构体
- Begin()
- Commit()
- Rollback()
- 五、BoltDB应用:API接口
-
- 1、应用入门
- 2、API接口源码
-
- DB结构体
- Open()创建数据库接口
- View()查询接口
- Update()更新接口
- Batch()批量更新接口
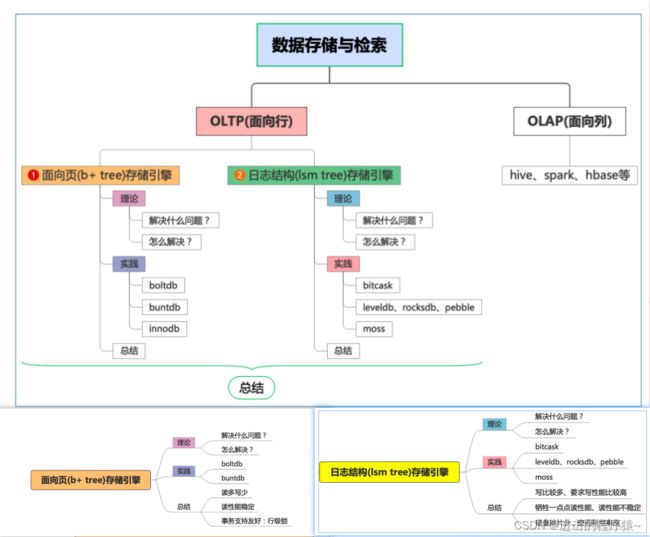
- 附录:数据存储与检索
相关链接:
https://github.com/boltdb/bolt
https://www.bookstack.cn/books/jaydenwen123-boltdb_book
https://www.bilibili.com/video/BV1Zv411G7ty
一、boltdb简介
1、boltdb是什么
BoltDB 是一个使用 Go 语言开发的支持事务的低级 Key/Value 文件型单机数据存储系统,简单、快速而且可靠。
- Go语言开发:boltdb项目100%由golang语言开发,不涉及其它语言。
- 事务:支持读写事务和只读事务。
- Key/Value:键值对数据库,对外暴露kv接口。key和value都是[]byte。
- 文件型单机:boltdb所有的数据都是存储在磁盘上的,所以它属于文件型数据库。 另外,boltdb不是分布式数据库,它是一款单机版的数据库。它适用于用来做wal日志或者读多写少的存储场景【比如etcd】。 【分布式数据库——TiDB】
2、为什么分析boltdb
- why learn boltdb?
首先在互联网里面,所有的系统、软件都离不开数据。而提到数据,无非我们就会想到 数据存储 和 数据检索。这些功能不就是一个数据库最基本的吗。从而数据库在计算机的世界里面有着无比重要的位置。
其次因工作需要了解mysql和redis,在看完了从根上理解mysql后。整体上对innodb有了宏观和微观的了解和认识,但是更近一步去看mysql的代码。有几个难点:1、本人项目主要以golang为主。说实话看c和c++的项目或多或少有些理解难度;2、mysql作为上古神兽,虽然功能很完善,但是要想短期内看完源码基本上是不可能的,而工作之余的时间有限,因此性价比极低。而boltdb很像一个简陋版的innodb存储引擎,设计简单、代码少而通俗,是个很不错的用来入门数据库的项目。
最后在学习etcd的时候发现etcd里的数据存储就用到了开源boltdb组件。如此 火热的etcd技术 竟然都选择了boltdb,这个boltdb到底是个什么牛马?哈哈哈。
通过分析这个项目,可以在下面三个方面有所提升。
- 一方面让自己能加深原先学习的理论知识;
- 另外一方面也能真正的了解工程上是如何运用的,理论结合实践,然后对存储引擎有一个清晰的认识;
- 最后也是希望借助这个项目开启个人探索存储方向的大门。
3、boltdb对比其它数据库
-
Postgres, MySQL, & other relational databases
关系型数据库的结构设计到行记录,在存储和查询数据的时候更加灵活,但是对sql语句的解析需要消耗一定的性能。而Bolt数据库可以通过字节切片访问所有数据,这使得 Bolt 可以通过key快速读取和写入数据,但不提供join查询的内置支持。
大多数关系数据库(SQLite 除外)都是独立于应用程序运行的独立服务器。 这使系统可以灵活地将多个应用程序服务器连接到单个数据库服务器,但也增加了在网络上序列化和传输数据的开销。 Bolt 作为应用程序中的库libraries工具运行,因此所有数据访问都必须通过应用程序的进程。 这使数据更接近应用程序,但限制了对数据的多进程访问。
-
LevelDB, RocksDB
LevelDB 及其衍生产品(RocksDB、HyperLevelDB)与 Bolt 的相似之处在于它们都是捆绑到应用程序中的libraries,但它们的底层结构是日志结构的合并树(LSM 树)。 LSM 树通过使用预写日志和称为 SSTables 的多层排序文件来优化随机写入。 Bolt 在内部使用 B+树,并且只使用一个文件。 两种方式都各有千秋。
如果需要高随机写入吞吐量(>10,000 w/sec)或者需要使用旋转磁盘,那么 LevelDB 可能是一个不错的选择。 如果应用程序需要大量读取或进行大量范围扫描,那么 Bolt 可能是一个不错的选择。
另一个重要的考虑因素是 LevelDB 没有事务。 它支持键/值对的批量写入,并支持读取快照,但它不会让您能够安全地进行比较和交换操作。 Bolt 支持完全可序列化的 ACID 事务。
-
LMDB
Bolt 最初是 LMDB 的一个分支,因此在架构上相似。 两者都使用 B+树,具有完全可序列化事务的 ACID 语义,并支持使用单个写入器和多个读取器的无锁 MVCC。
这两个项目后来分道扬镳。LMDB 非常注重原始性能,而 Bolt 则专注于简单性和易用性【etcd设计的初衷也是简单易用。所以etcd选择了boltdb?】。例如,LMDB 允许一些不安全的操作,例如出于性能考虑的直接写入。Bolt 选择禁止可能使数据库处于损坏状态的操作。另外它们的API 也有一些差异。LMDB 需要最大 mmap 大小,而 Bolt 会自动处理增量 mmap 调整大小。 LMDB 和 Bolt在getter 和 setter 函数上设计和实现也完全不同。
4、boltdb的用法入门
boltdb的用法很简单,先来明确几个基本概念。
- DB:即数据库db,一个db对应一个真实的磁盘文件
- k/v:键值对数据,它们都是byte类型
- Bucket:桶,表示键值对的集合,可以理解为B+树结构
- Cursor:对Bucket的CRUD是通过Cursor对象来定位的,它就是一个迭代器
- page: boltdb是按照以page为单位来读取和写入数据的, 所以数据在磁盘上也是按照页(page)来存储【页大小4KB】【page页类型: 分支节点页/叶子节点页/元数据页/空闲列表页】
- node:节点node【叶子节点/根节点/分支节点】 是物理磁盘上读取进来的页page的内存表现形式
一句话总结:一个数据库DB里有多个桶Bucket,每个桶用来存放键值对数据k/v。
在内存中,分支节点页和叶子节点页都是通过node来表示,只不过的区别是通过其node中的isLeaf这个字段来区分。因此page页和内存中的node的存在转换关系。
-
数据写入流程
step1:新建数据库DB【如果没有的话就是新建,一个db对应底层的一个磁盘文件】
step2:新建桶Bucket【如果没有的话就是新建】
step3:存入key/value数据【数据的存储有一定的规则】
-
数据读取流程
step1:指定数据库DB【一定存在】
step2:找到对应的桶Bucket【一定存在】
step3:根据key找到value数据【根据数据存储的规则拿出数据】
-
代码示例
package main
import (
"github.com/boltdb/bolt"
"log"
)
func main() {
// step1:新建数据库DB
db, err := bolt.Open("./test.db", 0600, nil)
if err != nil {
panic(err)
}
defer db.Close()
// 往db里面插入数据
err = db.Update(func(tx *bolt.Tx) error {
// step2:新建桶Bucket
bucket, err := tx.CreateBucketIfNotExists([]byte("user"))
if err != nil {
log.Fatalf("CreateBucketIfNotExists err:%s", err.Error())
return err
}
//step3:存入key/value数据【数据的存储有一定的规则】
if err = bucket.Put([]byte("hello"), []byte("world")); err != nil {
log.Fatalf("bucket Put err:%s", err.Error())
return err
}
return nil
})
if err != nil {
log.Fatalf("db.Update err:%s", err.Error())
}
// step1:指定数据库DB【一定存在】
err = db.View(func(tx *bolt.Tx) error {
// step2:找到桶Bucket
bucket := tx.Bucket([]byte("user"))
//step3:根据key找到value数据
val := bucket.Get([]byte("hello"))
log.Printf("the get val:%s", val)
val = bucket.Get([]byte("hello2"))
log.Printf("the get val2:%s", val)
return nil
})
if err != nil {
log.Fatalf("db.View err:%s", err.Error())
}
}
5、boltdb性能提升
-
mmap
在boltdb中所有的数据都是以page页为单位组织的,那这时候通常我们的理解是,当通过索引定位到具体存储数据在某一页时,然后就先在页缓存中找,如果页没有缓存,则打开数据库文件中开始读取那一页的数据就好了。 但这样的话性能会极低。boltdb中是通过mmap内存映射技术来解决这个问题。当数据库初始化时,就会进行内存映射,将文件中的数据映射到内存中的一段连续空间,后续再读取某一页的数据时,直接在内存中读取。性能大幅度提升。
-
b+数
在boltdb中,索引和数据时按照b+树来组织的。其中一个bucket对象对应一颗b+树,叶子节点存储具体的数据,非叶子节点只存储具体的索引信息,很类似mysql innodb中的主键索引结构。同时值得注意的是所有的bucket也构成了一颗树。但该树不是b+树。
-
嵌套bucket
在boltdb中,一个bucket对像是一颗b+树,它上面存储一批kv键值对。但同时它还有一个特性,一个bucket下面还可以有嵌套的subbucket。subbucket中还可以有subbucket。这个特性也是一个巧妙的设计。
二、BoltDB的数据结构
- boltdb的数据结构
下面这幅图完整的展示了boltdb中数据在磁盘文件(file)、文件中的每页(page)上的存储格式以及内存(bucket、node)中b+树形式的组织情况。
图片来源:jaydenwen123
- 1、page物理页
type pgid uint64
type page struct {
// 页id 8字节
id pgid
// flags:页类型,可以是分支,叶子节点,元信息,空闲列表 2字节,该值的取值详细参见下面描述
flags uint16
// 个数 2字节,统计叶子节点、非叶子节点、空闲列表页的个数
count uint16
// 4字节,数据是否有溢出,主要在空闲列表上有用
overflow uint32
// 真实的数据
ptr uintptr
}
// 页头的大小:16字节
const pageHeaderSize = int(unsafe.Offsetof(((*page)(nil)).ptr))
const minKeysPerPage = 2
//分支节点页中每个元素所占的大小
const branchPageElementSize = int(unsafe.Sizeof(branchPageElement{}))
//叶子节点页中每个元素所占的大小
const leafPageElementSize = int(unsafe.Sizeof(leafPageElement{}))
const (
branchPageFlag = 0x01 //分支节点页类型
leafPageFlag = 0x02 //叶子节点页类型
metaPageFlag = 0x04 //元数据页类型
freelistPageFlag = 0x10 //空闲列表页类型
)
-
2、元数据页
每页都有一个meta()方法,如果该页是元数据页的话,可以通过该方法来获取具体的元数据信息。
page<->meta:元数据与页信息存在转换关系。
type meta struct {
magic uint32 //魔数
version uint32 //版本
pageSize uint32 //page页的大小,该值和操作系统默认的页大小保持一致
flags uint32 //保留值,目前貌似还没用到
root bucket //所有小柜子bucket的根
freelist pgid //空闲列表页的id
pgid pgid //元数据页的id
txid txid //最大的事务id
checksum uint64 //用作校验的校验和
}
-
3、空闲列表页
空闲列表页中主要包含三个部分:①所有已经可以重新利用的空闲页列表ids、②将来很快被释放掉的事务关联的页列表pending、③页id的缓存。
page<->freelist: 空闲列表与页信息存在转换关系。
// freelist represents a list of all pages that are available for allocation.
// It also tracks pages that have been freed but are still in use by open transactions.
type freelist struct {
// 已经可以被分配的空闲页
ids []pgid // all free and available free page ids.
// 将来很快能被释放的空闲页,部分事务可能在读或者写
pending map[txid][]pgid // mapping of soon-to-be free page ids by tx.
cache map[pgid]bool // fast lookup of all free and pending page ids.
}
// newFreelist returns an empty, initialized freelist.
func newFreelist() *freelist {
return &freelist{
pending: make(map[txid][]pgid),
cache: make(map[pgid]bool),
}
}
-
4、分支节点页
分支节点主要用来构建索引,方便提升查询效率。
在内存中,分支节点页和叶子节点页都是通过node来表示,只不过的区别是通过其node中的isLeaf这个字段来区分。
page<->node:分支节点页page与node存在转换关系。
// branchPageElement represents a node on a branch page.
type branchPageElement struct {
pos uint32 //该元信息和真实key之间的偏移量
ksize uint32
pgid pgid
}
分支节点和叶子节点的node结构
// node represents an in-memory, deserialized page.
type node struct {
bucket *Bucket
isLeaf bool
unbalanced bool
spilled bool
key []byte
pgid pgid
parent *node
children nodes
inodes inodes
}
-
5、叶子结点页
叶子节点主要用来存储实际的数据,也就是key+value。在boltdb中,每一对key/value在存储时,都有一份元素元信息,也就是leafPageElement。其中定义了key的长度、value的长度、具体存储的值距离元信息的偏移位置pos。
page<->node:叶子节点页page与node存在转换关系。
叶子节点存储方式如下:

// leafPageElement represents a node on a leaf page.
// 叶子节点既存储key,也存储value
type leafPageElement struct {
flags uint32 //该值主要用来区分,是子桶叶子节点元素还是普通的key/value叶子节点元素。flags值为1时表示子桶。否则为key/value
pos uint32
ksize uint32
vsize uint32
}
// 叶子节点的key
// key returns a byte slice of the node key.
func (n *leafPageElement) key() []byte {
buf := (*[maxAllocSize]byte)(unsafe.Pointer(n))
// pos~ksize
return (*[maxAllocSize]byte)(unsafe.Pointer(&buf[n.pos]))[:n.ksize:n.ksize]
}
// 叶子节点的value
// value returns a byte slice of the node value.
func (n *leafPageElement) value() []byte {
buf := (*[maxAllocSize]byte)(unsafe.Pointer(n))
// key:pos~ksize
// value:pos+ksize~pos+ksize+vsize
return (*[maxAllocSize]byte)(unsafe.Pointer(&buf[n.pos+n.ksize]))[:n.vsize:n.vsize]
}
三、BoltDB中的B+树和Bucket
了解了BoltDB中数据结构后,可以进一步了解上述数据结构是如果组织成Bucket结构的。
1、Bucket结构
Bucket表示数据库中的键值对集合。Bucket在逻辑上可以简单的理解为一棵B+树。
// Bucket represents a collection of key/value pairs inside the database.
// 一组key/value的集合,也就是一个b+树
type Bucket struct {
*bucket //在内联时bucket主要用来存储其桶的value并在后面拼接所有的元素,即所谓的内联
tx *Tx // the associated transaction
buckets map[string]*Bucket // subbucket cache
page *page // inline page reference,内联页引用
rootNode *node // materialized node for the root page.
nodes map[pgid]*node // node cache
// This is non-persisted across transactions so it must be set in every Tx.
// 填充率
FillPercent float64
}
// bucket represents the on-file representation of a bucket.
type bucket struct {
root pgid // page id of the bucket's root-level page
sequence uint64 // monotonically incrementing, used by NextSequence()
}
// newBucket returns a new bucket associated with a transaction.
func newBucket(tx *Tx) Bucket {
var b = Bucket{tx: tx, FillPercent: DefaultFillPercent}
if tx.writable {
b.buckets = make(map[string]*Bucket)
b.nodes = make(map[pgid]*node)
}
return b
}
// 16 byte
const bucketHeaderSize = int(unsafe.Sizeof(bucket{}))
const (
minFillPercent = 0.1
maxFillPercent = 1.0
)
// DefaultFillPercent is the percentage that split pages are filled.
// This value can be changed by setting Bucket.FillPercent.
const DefaultFillPercent = 0.5
- Bucket的CRUD
创建一个Bucket: CreateBucketIfNotExists()、CreateBucket()
根据指定的key来创建一个Bucket,如果指定key的Bucket已经存在,则会报错。如果指定的key之前有插入过元素,也会报错。否则的话,会在当前的Bucket中找到合适的位置,然后新建一个Bucket插入进去,最后返回给客户端。
// CreateBucketIfNotExists creates a new bucket if it doesn't already exist and returns a reference to it.
func (b *Bucket) CreateBucketIfNotExists(key []byte) (*Bucket, error) {
child, err := b.CreateBucket(key)
if err == ErrBucketExists {
return b.Bucket(key), nil
} else if err != nil {
return nil, err
}
return child, nil
}
// CreateBucket creates a new bucket at the given key and returns the new bucket.
func (b *Bucket) CreateBucket(key []byte) (*Bucket, error) {
if b.tx.db == nil {
return nil, ErrTxClosed
} else if !b.tx.writable {
return nil, ErrTxNotWritable
} else if len(key) == 0 {
return nil, ErrBucketNameRequired
}
// Move cursor to correct position.
// 拿到游标
c := b.Cursor()
// 开始遍历、找到合适的位置
k, _, flags := c.seek(key)
// Return an error if there is an existing key.
if bytes.Equal(key, k) {
// 是桶,已经存在了
if (flags & bucketLeafFlag) != 0 {
return nil, ErrBucketExists
}
// 不是桶、但key已经存在了
return nil, ErrIncompatibleValue
}
// Create empty, inline bucket.
var bucket = Bucket{
bucket: &bucket{},
rootNode: &node{isLeaf: true},
FillPercent: DefaultFillPercent,
}
// 拿到bucket对应的value
var value = bucket.write()
// Insert into node.
key = cloneBytes(key)
// 插入到inode中
// c.node()方法会在内存中建立这棵树,调用n.read(page)
c.node().put(key, key, value, 0, bucketLeafFlag)
// Since subbuckets are not allowed on inline buckets, we need to
// dereference the inline page, if it exists. This will cause the bucket
// to be treated as a regular, non-inline bucket for the rest of the tx.
b.page = nil
//根据key获取一个桶
return b.Bucket(key), nil
}
// write allocates and writes a bucket to a byte slice.
// 内联桶的话,其value中bucketHeaderSize后面的内容为其page的数据
func (b *Bucket) write() []byte {
// Allocate the appropriate size.
var n = b.rootNode
var value = make([]byte, bucketHeaderSize+n.size())
// Write a bucket header.
var bucket = (*bucket)(unsafe.Pointer(&value[0]))
*bucket = *b.bucket
// Convert byte slice to a fake page and write the root node.
var p = (*page)(unsafe.Pointer(&value[bucketHeaderSize]))
// 将该桶中的元素压缩存储,放在value中
n.write(p)
return value
}
// node returns the node that the cursor is currently positioned on.
func (c *Cursor) node() *node {
_assert(len(c.stack) > 0, "accessing a node with a zero-length cursor stack")
// If the top of the stack is a leaf node then just return it.
if ref := &c.stack[len(c.stack)-1]; ref.node != nil && ref.isLeaf() {
return ref.node
}
// Start from root and traverse down the hierarchy.
var n = c.stack[0].node
if n == nil {
n = c.bucket.node(c.stack[0].page.id, nil)
}
// 非叶子节点
for _, ref := range c.stack[:len(c.stack)-1] {
_assert(!n.isLeaf, "expected branch node")
n = n.childAt(int(ref.index))
}
_assert(n.isLeaf, "expected leaf node")
return n
}
// put inserts a key/value.
// 如果put的是一个key、value的话,不需要指定pgid。
// 如果put的一个树枝节点,则需要指定pgid,不需要指定value
func (n *node) put(oldKey, newKey, value []byte, pgid pgid, flags uint32) {
if pgid >= n.bucket.tx.meta.pgid {
panic(fmt.Sprintf("pgid (%d) above high water mark (%d)", pgid, n.bucket.tx.meta.pgid))
} else if len(oldKey) <= 0 {
panic("put: zero-length old key")
} else if len(newKey) <= 0 {
panic("put: zero-length new key")
}
// Find insertion index.
index := sort.Search(len(n.inodes), func(i int) bool { return bytes.Compare(n.inodes[i].key, oldKey) != -1 })
// Add capacity and shift nodes if we don't have an exact match and need to insert.
exact := (len(n.inodes) > 0 && index < len(n.inodes) && bytes.Equal(n.inodes[index].key, oldKey))
if !exact {
n.inodes = append(n.inodes, inode{})
copy(n.inodes[index+1:], n.inodes[index:])
}
inode := &n.inodes[index]
inode.flags = flags
inode.key = newKey
inode.value = value
inode.pgid = pgid
_assert(len(inode.key) > 0, "put: zero-length inode key")
}
删除一个Bucket
DeleteBucket()方法用来删除一个指定key的Bucket。其内部实现逻辑是先递归的删除其子桶。然后再释放该Bucket的page,并最终从叶子节点中移除。
// DeleteBucket deletes a bucket at the given key.
func (b *Bucket) DeleteBucket(key []byte) error {
if b.tx.db == nil {
return ErrTxClosed
} else if !b.Writable() {
return ErrTxNotWritable
}
// Move cursor to correct position.
c := b.Cursor()
k, _, flags := c.seek(key)
// Return an error if bucket doesn't exist or is not a bucket.
if !bytes.Equal(key, k) {
return ErrBucketNotFound
} else if (flags & bucketLeafFlag) == 0 {
return ErrIncompatibleValue
}
// Recursively delete all child buckets.
child := b.Bucket(key)
// 将该桶下面的所有桶都删除
err := child.ForEach(func(k, v []byte) error {
if v == nil {
if err := child.DeleteBucket(k); err != nil {
return fmt.Errorf("delete bucket: %s", err)
}
}
return nil
})
if err != nil {
return err
}
// Remove cached copy.
delete(b.buckets, string(key))
// Release all bucket pages to freelist.
child.nodes = nil
child.rootNode = nil
child.free()
// Delete the node if we have a matching key.
c.node().del(key)
return nil
}
// del removes a key from the node.
func (n *node) del(key []byte) {
// Find index of key.
index := sort.Search(len(n.inodes), func(i int) bool { return bytes.Compare(n.inodes[i].key, key) != -1 })
// Exit if the key isn't found.
if index >= len(n.inodes) || !bytes.Equal(n.inodes[index].key, key) {
return
}
// Delete inode from the node.
n.inodes = append(n.inodes[:index], n.inodes[index+1:]...)
// Mark the node as needing rebalancing.
n.unbalanced = true
}
// free recursively frees all pages in the bucket.
func (b *Bucket) free() {
if b.root == 0 {
return
}
var tx = b.tx
b.forEachPageNode(func(p *page, n *node, _ int) {
if p != nil {
tx.db.freelist.free(tx.meta.txid, p)
} else {
n.free()
}
})
b.root = 0
}
- Bucket的分裂和合并
// spill writes all the nodes for this bucket to dirty pages.
func (b *Bucket) spill() error {
... ...
}
// rebalance attempts to balance all nodes.
func (b *Bucket) rebalance() {
for _, n := range b.nodes {
n.rebalance()
}
for _, child := range b.buckets {
child.rebalance()
}
}
2、Cursor结构
创建、获取、删除一个Bucket等操作都是建立在首先定位到一个Bucket所属的位置,然后才能对其进行操作。而定位一个Bucket的功能就是由Cursor来完成的。
一个Bucket对象关联一个Cursor。
// Cursor represents an iterator that can traverse over all key/value pairs in a bucket in sorted order.
type Cursor struct {
bucket *Bucket
// 保存遍历搜索的路径
stack []elemRef
}
// elemRef represents a reference to an element on a given page/node.
type elemRef struct {
page *page
node *node
index int
}
// isLeaf returns whether the ref is pointing at a leaf page/node.
func (r *elemRef) isLeaf() bool {
if r.node != nil {
return r.node.isLeaf
}
return (r.page.flags & leafPageFlag) != 0
}
// count returns the number of inodes or page elements.
func (r *elemRef) count() int {
if r.node != nil {
return len(r.node.inodes)
}
return int(r.page.count)
}
//对外接口:主体也就是三类:定位到某一个元素的位置、在当前位置从前往后找、在当前位置从后往前找。
func (c *Cursor) First() (key []byte, value []byte)
func (c *Cursor) Last() (key []byte, value []byte)
func (c *Cursor) Next() (key []byte, value []byte)
func (c *Cursor) Prev() (key []byte, value []byte)
func (c *Cursor) Delete() error
func (c *Cursor) Seek(seek []byte) (key []byte, value []byte)
3、Node结构
一个node节点,既可能是叶子节点,也可能是根节点,也可能是分支节点。node是物理磁盘上读取进来的页page的内存表现形式。 因此node和page可以相互转换。
// node represents an in-memory, deserialized page.
type node struct {
bucket *Bucket // 关联一个桶
isLeaf bool
unbalanced bool // 值为true的话,需要考虑页合并
spilled bool // 值为true的话,需要考虑页分裂
key []byte // 对于分支节点的话,保留的是最小的key
pgid pgid // 分支节点关联的页id
parent *node // 该节点的parent
children nodes // 该节点的孩子节点
inodes inodes // 该节点上保存的索引数据
}
// inode represents an internal node inside of a node.
type inode struct {
// 表示是否是子桶叶子节点还是普通叶子节点。如果flags值为1表示子桶叶子节点,否则为普通叶子节点
flags uint32
// 当inode为分支元素时,pgid才有值,为叶子元素时,则没值
pgid pgid
key []byte
// 当inode为分支元素时,value为空,为叶子元素时,才有值
value []byte
}
type inodes []inode
- node节点的CRUD
put
// put inserts a key/value.
// 如果put的是一个key、value的话,不需要指定pgid。
// 如果put的一个树枝节点,则需要指定pgid,不需要指定value
func (n *node) put(oldKey, newKey, value []byte, pgid pgid, flags uint32) {
if pgid >= n.bucket.tx.meta.pgid {
panic(fmt.Sprintf("pgid (%d) above high water mark (%d)", pgid, n.bucket.tx.meta.pgid))
} else if len(oldKey) <= 0 {
panic("put: zero-length old key")
} else if len(newKey) <= 0 {
panic("put: zero-length new key")
}
// Find insertion index.
index := sort.Search(len(n.inodes), func(i int) bool { return bytes.Compare(n.inodes[i].key, oldKey) != -1 })
// Add capacity and shift nodes if we don't have an exact match and need to insert.
exact := (len(n.inodes) > 0 && index < len(n.inodes) && bytes.Equal(n.inodes[index].key, oldKey))
if !exact {
n.inodes = append(n.inodes, inode{})
copy(n.inodes[index+1:], n.inodes[index:])
}
inode := &n.inodes[index]
inode.flags = flags
inode.key = newKey
inode.value = value
inode.pgid = pgid
_assert(len(inode.key) > 0, "put: zero-length inode key")
}
get
在node中,没有get(k)的方法,其本质是在Cursor中就返回了get的数据。大家可以看看Cursor中的keyValue()方法。
del
// del removes a key from the node.
func (n *node) del(key []byte) {
// Find index of key.
index := sort.Search(len(n.inodes), func(i int) bool { return bytes.Compare(n.inodes[i].key, key) != -1 })
// Exit if the key isn't found.
if index >= len(n.inodes) || !bytes.Equal(n.inodes[index].key, key) {
return
}
// Delete inode from the node.
n.inodes = append(n.inodes[:index], n.inodes[index+1:]...)
// Mark the node as needing rebalancing.
n.unbalanced = true
}
- node节点的分裂和合并
针对node节点的操作,包括put和del方法。经过这些操作后,可能会导致当前的page填充度过高或者过低。因此就引出了node节点的分裂和合并。
分裂spill(): 当一个node中的数据过多时,最简单就是当超过了page的填充度时,就需要将当前的node拆分成两个,也就是底层会将一页数据拆分存放到两页中。
合并rebalance(): 当删除了一个或者一批对象时,此时可能会导致一页数据的填充度过低,此时空间可能会浪费比较多。所以就需要考虑对页之间进行数据合并。
4、K/V操作
有了Bucket和Node,就可以对我们最关心的key/value键值对进行增删改查了。其实本质上,对key/value的所有操作最终都要表现在底层的node上。因为node节点就是用来存储真实数据的。
-
插入一个key/value对
// Put sets the value for a key in the bucket. func (b *Bucket) Put(key []byte, value []byte) error { if b.tx.db == nil { return ErrTxClosed } else if !b.Writable() { return ErrTxNotWritable } else if len(key) == 0 { return ErrKeyRequired } else if len(key) > MaxKeySize { return ErrKeyTooLarge } else if int64(len(value)) > MaxValueSize { return ErrValueTooLarge } // Move cursor to correct position. c := b.Cursor() k, _, flags := c.seek(key) // Return an error if there is an existing key with a bucket value. if bytes.Equal(key, k) && (flags&bucketLeafFlag) != 0 { return ErrIncompatibleValue } // Insert into node. key = cloneBytes(key) c.node().put(key, key, value, 0, 0) return nil } -
获取一个key/value对
// Get retrieves the value for a key in the bucket. func (b *Bucket) Get(key []byte) []byte { k, v, flags := b.Cursor().seek(key) // Return nil if this is a bucket. if (flags & bucketLeafFlag) != 0 { return nil } // If our target node isn't the same key as what's passed in then return nil. if !bytes.Equal(key, k) { return nil } return v } -
删除一个key/value对
// Delete removes a key from the bucket. func (b *Bucket) Delete(key []byte) error { if b.tx.db == nil { return ErrTxClosed } else if !b.Writable() { return ErrTxNotWritable } // Move cursor to correct position. c := b.Cursor() _, _, flags := c.seek(key) // Return an error if there is already existing bucket value. if (flags & bucketLeafFlag) != 0 { return ErrIncompatibleValue } // Delete the node if we have a matching key. c.node().del(key) return nil } -
遍历Bucket中所有的键值对
// ForEach executes a function for each key/value pair in a bucket. func (b *Bucket) ForEach(fn func(k, v []byte) error) error { if b.tx.db == nil { return ErrTxClosed } c := b.Cursor() // 遍历键值对 for k, v := c.First(); k != nil; k, v = c.Next() { if err := fn(k, v); err != nil { return err } } return nil }
四、BoltDB事务
1、事务原理
在boltdb中支持两类事务:读写事务、只读事务。同一时间有且只能有一个读写事务执行;但同一个时间可以允许有多个只读事务执行。每个事务都拥有自己的一套一致性视图。
此处需要注意的是,在boltdb中打开一个数据库时,有两个选项:只读模式、读写模式。内部在实现时是根据不同的选项来底层加不同的锁(flock)。只读模式对应共享锁,读写模式对应互斥锁。具体加解锁的实现可以在bolt_unix.go 和bolt_windows.go中找到。
事务四个特性:ACID。 事务四大特性中,事务的一致性是终极目标,而其他三大特性都是为了保证一致性而服务的手段。
A(atomic)原子性:事务的原子性主要表示的是,只要事务一开始(Begin),那么事务要么执行成功(Commit),要么执行失败(Rollback)。上述过程只会出现两种状态,在事务执行过程中的中间状态以及数据是不可见的。
C(consistency)一致性:事务的一致性是指,事务开始前和事务提交后的数据都是一致的。
I(isolation)隔离性:事务的隔离性是指不同事务之间是相互隔离、互不影响的。具体的隔离程度是由具体的事务隔离级别来控制。
D(duration)持久性:事务的持久性是指,事务开始前和事务提交后的数据都是永久的。不会存在数据丢失或者篡改的风险。
比如:在mysql中,事务的原子性由undo log来保证;事务的持久性由redo log来保证;事务的隔离性由锁来保证。 那在boltdb中呢?
首先boltdb是一个文件数据库,所有的数据最终都保存在文件中。当事务结束(Commit)时,会将数据进行刷盘。同时,boltdb通过冗余一份元数据来做容错。当事务提交时,如果写入到一半机器挂了,此时数据就会有问题。而当boltdb再次恢复时,会对元数据进行校验和修复。这两点就保证事务中的持久性。
其次boltdb在上层支持多个进程以只读的方式打开数据库,一个进程以写的方式打开数据库。在数据库内部中事务支持两种,读写事务和只读事务。这两类事务是互斥的。同一时间可以有多个只读事务执行,或者只能有一个读写事务执行,上述两类事务,在底层实现时,都是保留一整套完整的视图和元数据信息,彼此之间相互隔离。因此通过这两点就保证了隔离性。
在boltdb中,数据先写内存,然后再提交时刷盘。如果其中有异常发生,事务就会回滚。同时再加上同一时间只有一个进行对数据执行写入操作。所以它要么写成功提交、要么写失败回滚。也就支持原子性。
通过以上的几个特性的保证,最终也就保证了一致性。
2、事务源码
Tx结构体
// txid represents the internal transaction identifier.
type txid uint64
// Tx represents a read-only or read/write transaction on the database.
// Read-only transactions can be used for retrieving values for keys and creating cursors.
// Read/write transactions can create and remove buckets and create and remove keys.
// Tx 主要封装了读事务和写事务。其中通过writable来区分是读事务还是写事务
type Tx struct {
writable bool
managed bool
db *DB
meta *meta
root Bucket
pages map[pgid]*page
stats TxStats
// 提交时执行的动作
commitHandlers []func()
WriteFlag int
}
// init initializes the transaction.
func (tx *Tx) init(db *DB) {
tx.db = db
tx.pages = nil
// Copy the meta page since it can be changed by the writer.
// 拷贝元信息
tx.meta = &meta{}
db.meta().copy(tx.meta)
// Copy over the root bucket.
// 拷贝根节点
tx.root = newBucket(tx)
tx.root.bucket = &bucket{}
// meta.root=bucket{root:3}
*tx.root.bucket = tx.meta.root
// Increment the transaction id and add a page cache for writable transactions.
if tx.writable {
tx.pages = make(map[pgid]*page)
tx.meta.txid += txid(1)
}
}
Begin()
在boltdb中,事务的开启方法是绑定在DB对象上的。
前面提到boltdb中事务分为两类,它的区分就是在开启事务时,根据传递的参数来内部执行不同的逻辑。
// Begin starts a new transaction.
// Multiple read-only transactions can be used concurrently but only one
// write transaction can be used at a time.
func (db *DB) Begin(writable bool) (*Tx, error) {
if writable {
return db.beginRWTx()
}
return db.beginTx()
}
func (db *DB) beginTx() (*Tx, error) {
// Lock the meta pages while we initialize the transaction.
db.metalock.Lock()
db.mmaplock.RLock()
// Exit if the database is not open yet.
if !db.opened {
db.mmaplock.RUnlock()
db.metalock.Unlock()
return nil, ErrDatabaseNotOpen
}
// Create a transaction associated with the database.
t := &Tx{}
t.init(db)
// Keep track of transaction until it closes.
db.txs = append(db.txs, t)
n := len(db.txs)
// Unlock the meta pages.
db.metalock.Unlock()
// Update the transaction stats.
db.statlock.Lock()
db.stats.TxN++
db.stats.OpenTxN = n
db.statlock.Unlock()
return t, nil
}
func (db *DB) beginRWTx() (*Tx, error) {
// If the database was opened with Options.ReadOnly, return an error.
if db.readOnly {
return nil, ErrDatabaseReadOnly
}
db.rwlock.Lock()
db.metalock.Lock()
defer db.metalock.Unlock()
// Exit if the database is not open yet.
if !db.opened {
db.rwlock.Unlock()
return nil, ErrDatabaseNotOpen
}
// Create a transaction associated with the database.
t := &Tx{writable: true}
t.init(db)
db.rwtx = t
// Free any pages associated with closed read-only transactions.
var minid txid = 0xFFFFFFFFFFFFFFFF
// 找到最小的事务id
for _, t := range db.txs {
if t.meta.txid < minid {
minid = t.meta.txid
}
}
if minid > 0 {
// 将之前事务关联的page全部释放了,因为在只读事务中,没法释放,只读事务的页,因为可能当前的事务已经完成 ,但实际上其他的读事务还在用
db.freelist.release(minid - 1)
}
return t, nil
}
Commit()
Commit()方法内部实现中,总体思路是:
- 先判定节点要不要合并、分裂
- 对空闲列表的判断,是否存在溢出的情况,溢出的话,需要重新分配空间
- 将事务中涉及改动的页进行排序(保证尽可能的顺序IO),排序后循环写入到磁盘中,最后再执行刷盘
- 当数据写入成功后,再将元信息页写到磁盘中,刷盘以保证持久化
- 上述操作中,但凡有失败,当前事务都会进行回滚
// Commit writes all changes to disk and updates the meta page.
// 先更新数据然后再更新元信息
func (tx *Tx) Commit() error {
_assert(!tx.managed, "managed tx commit not allowed")
if tx.db == nil {
return ErrTxClosed
} else if !tx.writable {
return ErrTxNotWritable
}
// 删除时,进行平衡,页合并
// Rebalance nodes which have had deletions.
var startTime = time.Now()
tx.root.rebalance()
if tx.stats.Rebalance > 0 {
tx.stats.RebalanceTime += time.Since(startTime)
}
// 页分裂
// spill data onto dirty pages.
startTime = time.Now()
// 这个内部会往缓存tx.pages中加page
if err := tx.root.spill(); err != nil {
tx.rollback()
return err
}
tx.stats.SpillTime += time.Since(startTime)
// Free the old root bucket.
tx.meta.root.root = tx.root.root
opgid := tx.meta.pgid
// Free the freelist and allocate new pages for it. This will overestimate
// the size of the freelist but not underestimate the size (which would be bad).
// 分配新的页面给freelist,然后将freelist写入新的页面
tx.db.freelist.free(tx.meta.txid, tx.db.page(tx.meta.freelist))
// 空闲列表可能会增加,因此需要重新分配页用来存储空闲列表
// 因为在开启写事务的时候,有去释放之前读事务占用的页信息,因此此处需要判断是否freelist会有溢出的问题
p, err := tx.allocate((tx.db.freelist.size() / tx.db.pageSize) + 1)
if err != nil {
tx.rollback()
return err
}
// 将freelist写入到连续的新页中
if err := tx.db.freelist.write(p); err != nil {
tx.rollback()
return err
}
// 更新元数据的页id
tx.meta.freelist = p.id
// If the high water mark has moved up then attempt to grow the database.
// 在allocate中有可能会更改meta.pgid
if tx.meta.pgid > opgid {
if err := tx.db.grow(int(tx.meta.pgid+1) * tx.db.pageSize); err != nil {
tx.rollback()
return err
}
}
// Write dirty pages to disk.
startTime = time.Now()
// 写数据
if err := tx.write(); err != nil {
tx.rollback()
return err
}
// If strict mode is enabled then perform a consistency check.
if tx.db.StrictMode {
ch := tx.Check()
var errs []string
for {
err, ok := <-ch
if !ok {
break
}
errs = append(errs, err.Error())
}
if len(errs) > 0 {
panic("check fail: " + strings.Join(errs, "\n"))
}
}
// Write meta to disk.
// 元信息写入到磁盘
if err := tx.writeMeta(); err != nil {
tx.rollback()
return err
}
tx.stats.WriteTime += time.Since(startTime)
// Finalize the transaction.
tx.close()
// Execute commit handlers now that the locks have been removed.
for _, fn := range tx.commitHandlers {
fn()
}
return nil
}
// write writes any dirty pages to disk.
func (tx *Tx) write() error {
// Sort pages by id.
// 保证写的页是有序的
pages := make(pages, 0, len(tx.pages))
for _, p := range tx.pages {
pages = append(pages, p)
}
// Clear out page cache early.
tx.pages = make(map[pgid]*page)
sort.Sort(pages)
// Write pages to disk in order.
for _, p := range pages {
// 页数和偏移量
size := (int(p.overflow) + 1) * tx.db.pageSize
offset := int64(p.id) * int64(tx.db.pageSize)
// Write out page in "max allocation" sized chunks.
ptr := (*[maxAllocSize]byte)(unsafe.Pointer(p))
// 循环写某一页
for {
// Limit our write to our max allocation size.
sz := size
// 2^31=2G
if sz > maxAllocSize-1 {
sz = maxAllocSize - 1
}
// Write chunk to disk.
buf := ptr[:sz]
if _, err := tx.db.ops.writeAt(buf, offset); err != nil {
return err
}
// Update statistics.
tx.stats.Write++
// Exit inner for loop if we've written all the chunks.
size -= sz
if size == 0 {
break
}
// Otherwise move offset forward and move pointer to next chunk.
// 移动偏移量
offset += int64(sz)
// 同时指针也移动
ptr = (*[maxAllocSize]byte)(unsafe.Pointer(&ptr[sz]))
}
}
// Ignore file sync if flag is set on DB.
if !tx.db.NoSync || IgnoreNoSync {
if err := fdatasync(tx.db); err != nil {
return err
}
}
// Put small pages back to page pool.
for _, p := range pages {
// Ignore page sizes over 1 page.
// These are allocated using make() instead of the page pool.
if int(p.overflow) != 0 {
continue
}
buf := (*[maxAllocSize]byte)(unsafe.Pointer(p))[:tx.db.pageSize]
for i := range buf {
buf[i] = 0
}
tx.db.pagePool.Put(buf)
}
return nil
}
// writeMeta writes the meta to the disk.
func (tx *Tx) writeMeta() error {
// Create a temporary buffer for the meta page.
buf := make([]byte, tx.db.pageSize)
p := tx.db.pageInBuffer(buf, 0)
// 将事务的元信息写入到页中
tx.meta.write(p)
// Write the meta page to file.
if _, err := tx.db.ops.writeAt(buf, int64(p.id)*int64(tx.db.pageSize)); err != nil {
return err
}
if !tx.db.NoSync || IgnoreNoSync {
if err := fdatasync(tx.db); err != nil {
return err
}
}
// Update statistics.
tx.stats.Write++
return nil
}
// allocate returns a contiguous block of memory starting at a given page.
// 分配一段连续的页
func (tx *Tx) allocate(count int) (*page, error) {
p, err := tx.db.allocate(count)
if err != nil {
return nil, err
}
// Save to our page cache.
tx.pages[p.id] = p
// Update statistics.
tx.stats.PageCount++
tx.stats.PageAlloc += count * tx.db.pageSize
return p, nil
}
Rollback()
Rollback()中,主要对不同事务进行不同操作:
- 如果当前事务是只读事务,则只需要从db中的txs中找到当前事务,然后移除掉即可。
- 如果当前事务是读写事务,则需要将空闲列表中和该事务关联的页释放掉,同时重新从freelist中加载空闲页。
// Rollback closes the transaction and ignores all previous updates.
// Read-only transactions must be rolled back and not committed.
func (tx *Tx) Rollback() error {
_assert(!tx.managed, "managed tx rollback not allowed")
if tx.db == nil {
return ErrTxClosed
}
tx.rollback()
return nil
}
func (tx *Tx) rollback() {
if tx.db == nil {
return
}
if tx.writable {
// 移除该事务关联的pages
tx.db.freelist.rollback(tx.meta.txid)
// 重新从freelist页中读取构建空闲列表
tx.db.freelist.reload(tx.db.page(tx.db.meta().freelist))
}
tx.close()
}
func (tx *Tx) close() {
if tx.db == nil {
return
}
if tx.writable {
// Grab freelist stats.
var freelistFreeN = tx.db.freelist.free_count()
var freelistPendingN = tx.db.freelist.pending_count()
var freelistAlloc = tx.db.freelist.size()
// Remove transaction ref & writer lock.
tx.db.rwtx = nil
tx.db.rwlock.Unlock()
// Merge statistics.
tx.db.statlock.Lock()
tx.db.stats.FreePageN = freelistFreeN
tx.db.stats.PendingPageN = freelistPendingN
tx.db.stats.FreeAlloc = (freelistFreeN + freelistPendingN) * tx.db.pageSize
tx.db.stats.FreelistInuse = freelistAlloc
tx.db.stats.TxStats.add(&tx.stats)
tx.db.statlock.Unlock()
} else {
// 只读事务
tx.db.removeTx(tx)
}
// Clear all references.
tx.db = nil
tx.meta = nil
tx.root = Bucket{tx: tx}
tx.pages = nil
}
// removeTx removes a transaction from the database.
func (db *DB) removeTx(tx *Tx) {
// Release the read lock on the mmap.
db.mmaplock.RUnlock()
// Use the meta lock to restrict access to the DB object.
db.metalock.Lock()
// Remove the transaction.
for i, t := range db.txs {
if t == tx {
last := len(db.txs) - 1
db.txs[i] = db.txs[last]
db.txs[last] = nil
db.txs = db.txs[:last]
break
}
}
n := len(db.txs)
// Unlock the meta pages.
db.metalock.Unlock()
// Merge statistics.
db.statlock.Lock()
db.stats.OpenTxN = n
db.stats.TxStats.add(&tx.stats)
db.statlock.Unlock()
}
五、BoltDB应用:API接口
1、应用入门
package main
import (
"fmt"
"github.com/boltdb/bolt"
"log"
"time"
)
func main() {
db, err := bolt.Open("my.db", 0600, &bolt.Options{Timeout: 1 * time.Second, ReadOnly: false})
if err != nil {
log.Fatalln(err)
}
defer db.Close()
log.Println("db.String:", db.String())
// 事务 Read-write transactions
err = db.Update(func(tx *bolt.Tx) error {
return nil
})
if err != nil {
log.Fatalln("读写事务失败", err)
}
// Read-only transactions
err = db.View(func(tx *bolt.Tx) error {
return nil
})
if err != nil {
log.Fatalln("只读事务失败", err)
}
// Batch read-write transactions
err = db.Batch(func(tx *bolt.Tx) error {
return nil
})
if err != nil {
log.Fatalln("批量事务失败", err)
}
// Start a writable transaction.
tx, err := db.Begin(true)
if err != nil {
log.Fatalln("事务Begins失败", err)
}
defer tx.Rollback()
// Use the transaction...
_, err = tx.CreateBucket([]byte("MyBucket001"))
if err != nil {
log.Fatalln("事务CreateBucket失败", err)
}
// Commit the transaction and check for error.
if err := tx.Commit(); err != nil {
log.Fatalln("事务Commit失败", err)
}
// use buckets
db.Update(func(tx *bolt.Tx) error {
_, err := tx.CreateBucket([]byte("MyBucket"))
if err != nil {
return fmt.Errorf("create bucket: %s", err)
}
return nil
})
// Using key/value pairs
db.Update(func(tx *bolt.Tx) error {
b := tx.Bucket([]byte("MyBucket"))
// 新增
err := b.Put([]byte("answer"), []byte("42"))
return err
})
db.View(func(tx *bolt.Tx) error {
b := tx.Bucket([]byte("MyBucket"))
// 获取
v := b.Get([]byte("answer"))
fmt.Printf("The answer is: %s\n", v)
return nil
})
}
2、API接口源码
DB结构体
// The largest step that can be taken when remapping the mmap.
const maxMmapStep = 1 << 30 // 1GB
// The data file format version.
const version = 2
// Represents a marker value to indicate that a file is a Bolt DB.
const magic uint32 = 0xED0CDAED
const IgnoreNoSync = runtime.GOOS == "openbsd"
// Default values if not set in a DB instance.
const (
DefaultMaxBatchSize int =s 1000
DefaultMaxBatchDelay = 10 * time.Millisecond
DefaultAllocSize = 16 * 1024 * 1024 // 16k
)
// default page size for db is set to the OS page size.
var defaultPageSize = os.Getpagesize()
// DB represents a collection of buckets persisted to a file on disk.
type DB struct {
// When enabled, the database will perform a Check() after every commit.
StrictMode bool
// Setting the NoSync flag will cause the database to skip fsync()
// calls after each commit. This can be useful when bulk loading data
// into a database and you can restart the bulk load in the event of
// a system failure or database corruption. Do not set this flag for
// normal use.
//
// If the package global IgnoreNoSync constant is true, this value is
// ignored. See the comment on that constant for more details.
//
// THIS IS UNSAFE. PLEASE USE WITH CAUTION.
NoSync bool
// When true, skips the truncate call when growing the database.
NoGrowSync bool
// If you want to read the entire database fast, you can set MmapFlag to
// syscall.MAP_POPULATE on Linux 2.6.23+ for sequential read-ahead.
MmapFlags int
// MaxBatchSize is the maximum size of a batch.
MaxBatchSize int
// MaxBatchDelay is the maximum delay before a batch starts.
// Do not change concurrently with calls to Batch.
MaxBatchDelay time.Duration
// AllocSize is the amount of space allocated when the database
// needs to create new pages. This is done to amortize[缓冲] the cost
// of truncate() and fsync() when growing the data file.
AllocSize int
path string
file *os.File // 真实存储数据的磁盘文件
lockfile *os.File // windows only
dataref []byte // mmap'ed readonly, write throws SEGV
// 通过mmap映射进来的地址
data *[maxMapSize]byte
datasz int
filesz int // current on disk file size
// 元数据
meta0 *meta
meta1 *meta
pageSize int
opened bool
rwtx *Tx // 写事务锁
txs []*Tx // 读事务数组
freelist *freelist // 空闲列表
stats Stats
pagePool sync.Pool
batchMu sync.Mutex
batch *batch
rwlock sync.Mutex // Allows only one writer at a time.
metalock sync.Mutex // Protects meta page access.
mmaplock sync.RWMutex // Protects mmap access during remapping.
statlock sync.RWMutex // Protects stats access.
ops struct {
writeAt func(b []byte, off int64) (n int, err error)
}
// Read only mode.
// When true, Update() and Begin(true) return ErrDatabaseReadOnly immediately.
readOnly bool
}
Open()创建数据库接口
Open()方法主要用来创建一个boltdb的DB对象,底层会执行新建或者打开存储数据的文件,当指定的文件不存在时, boltdb就会新建一个数据文件。否则的话,就直接加载指定的数据库文件内容。
值的注意是,boltdb会根据Open时,options传递的参数来判断到底加互斥锁还是共享锁。
新建时: 会调用init()方法,内部主要是新建一个文件,然后第0页、第1页写入元数据信息;第2页写入freelist信息;第3页写入bucket leaf信息。并最终刷盘。
加载时: 会读取第0页内容,也就是元信息。然后对其进行校验和校验,当校验通过后获取pageSize。否则的话,读取操作系统默认的pagesize(一般4k)
上述操作完成后,会通过mmap来映射数据。最后再根据磁盘页中的freelist数据初始化db的freelist字段。
// Open creates and opens a database at the given path.
// If the file does not exist then it will be created automatically.
// Passing in nil options will cause Bolt to open the database with the default options.
func Open(path string, mode os.FileMode, options *Options) (*DB, error) {
var db = &DB{opened: true}
// Set default options if no options are provided.
if options == nil {
options = DefaultOptions
}
db.NoGrowSync = options.NoGrowSync
db.MmapFlags = options.MmapFlags
// Set default values for later DB operations.
db.MaxBatchSize = DefaultMaxBatchSize
db.MaxBatchDelay = DefaultMaxBatchDelay
db.AllocSize = DefaultAllocSize
flag := os.O_RDWR
if options.ReadOnly {
flag = os.O_RDONLY
db.readOnly = true
}
// Open data file and separate sync handler for metadata writes.
db.path = path
var err error
// 打开db文件
if db.file, err = os.OpenFile(db.path, flag|os.O_CREATE, mode); err != nil {
_ = db.close()
return nil, err
}
// Lock file so that other processes using Bolt in read-write mode cannot
// use the database at the same time. This would cause corruption since
// the two processes would write meta pages and free pages separately.
// The database file is locked exclusively (only one process can grab the lock)
// if !options.ReadOnly.
// The database file is locked using the shared lock (more than one process may
// hold a lock at the same time) otherwise (options.ReadOnly is set).
// 只读加共享锁、否则加互斥锁
if err := flock(db, mode, !db.readOnly, options.Timeout); err != nil {
_ = db.close()
return nil, err
}
// Default values for test hooks
db.ops.writeAt = db.file.WriteAt
// Initialize the database if it doesn't exist.
if info, err := db.file.Stat(); err != nil {
return nil, err
} else if info.Size() == 0 {
// Initialize new files with meta pages.
// 初始化新db文件
if err := db.init(); err != nil {
return nil, err
}
} else {
// 不是新文件,读取第一页元数据
// Read the first meta page to determine the page size.
// 2^12,正好是4k
var buf [0x1000]byte
if _, err := db.file.ReadAt(buf[:], 0); err == nil {
// 仅仅是读取了pageSize
m := db.pageInBuffer(buf[:], 0).meta()
if err := m.validate(); err != nil {
// If we can't read the page size, we can assume it's the same
// as the OS -- since that's how the page size was chosen in the
// first place.
//
// If the first page is invalid and this OS uses a different
// page size than what the database was created with then we
// are out of luck and cannot access the database.
db.pageSize = os.Getpagesize()
} else {
db.pageSize = int(m.pageSize)
}
}
}
// Initialize page pool.
db.pagePool = sync.Pool{
New: func() interface{} {
// 4k
return make([]byte, db.pageSize)
},
}
// Memory map the data file.
// mmap映射db文件数据到内存
if err := db.mmap(options.InitialMmapSize); err != nil {
_ = db.close()
return nil, err
}
// Read in the freelist.
db.freelist = newFreelist()
// db.meta().freelist=2
// 读第二页的数据
// 然后建立起freelist中
db.freelist.read(db.page(db.meta().freelist))
// Mark the database as opened and return.
return db, nil
}
// init creates a new database file and initializes its meta pages.
func (db *DB) init() error {
// Set the page size to the OS page size.
db.pageSize = os.Getpagesize()
// Create two meta pages on a buffer.
buf := make([]byte, db.pageSize*4)
for i := 0; i < 2; i++ {
p := db.pageInBuffer(buf[:], pgid(i))
p.id = pgid(i)
// 第0页和第1页存放元数据
p.flags = metaPageFlag
// Initialize the meta page.
m := p.meta()
m.magic = magic
m.version = version
m.pageSize = uint32(db.pageSize)
m.freelist = 2
m.root = bucket{root: 3}
m.pgid = 4
m.txid = txid(i)
m.checksum = m.sum64()
}
// Write an empty freelist at page 3.
// 拿到第2页存放freelist
p := db.pageInBuffer(buf[:], pgid(2))
p.id = pgid(2)
p.flags = freelistPageFlag
p.count = 0
// 第三块存放叶子page
// Write an empty leaf page at page 4.
p = db.pageInBuffer(buf[:], pgid(3))
p.id = pgid(3)
p.flags = leafPageFlag
p.count = 0
// Write the buffer to our data file.
// 写入4页的数据
if _, err := db.ops.writeAt(buf, 0); err != nil {
return err
}
// 刷盘
if err := fdatasync(db); err != nil {
return err
}
return nil
}
// page retrieves a page reference from the mmap based on the current page size.
func (db *DB) page(id pgid) *page {
pos := id * pgid(db.pageSize)
return (*page)(unsafe.Pointer(&db.data[pos]))
}
// pageInBuffer retrieves a page reference from a given byte array based on the current page size.
func (db *DB) pageInBuffer(b []byte, id pgid) *page {
return (*page)(unsafe.Pointer(&b[id*pgid(db.pageSize)]))
}
// mmap opens the underlying memory-mapped file and initializes the meta references.
// minsz is the minimum size that the new mmap can be.
func (db *DB) mmap(minsz int) error {
db.mmaplock.Lock()
defer db.mmaplock.Unlock()
info, err := db.file.Stat()
if err != nil {
return fmt.Errorf("mmap stat error: %s", err)
} else if int(info.Size()) < db.pageSize*2 {
return fmt.Errorf("file size too small")
}
// Ensure the size is at least the minimum size.
var size = int(info.Size())
if size < minsz {
size = minsz
}
size, err = db.mmapSize(size)
if err != nil {
return err
}
// Dereference all mmap references before unmapping.
if db.rwtx != nil {
db.rwtx.root.dereference()
}
// Unmap existing data before continuing.
if err := db.munmap(); err != nil {
return err
}
// Memory-map the data file as a byte slice.
if err := mmap(db, size); err != nil {
return err
}
// Save references to the meta pages.
// 获取元数据信息
db.meta0 = db.page(0).meta()
db.meta1 = db.page(1).meta()
// Validate the meta pages. We only return an error if both meta pages fail
// validation, since meta0 failing validation means that it wasn't saved
// properly -- but we can recover using meta1. And vice-versa.
err0 := db.meta0.validate()
err1 := db.meta1.validate()
if err0 != nil && err1 != nil {
return err0
}
return nil
}
// mmapSize determines the appropriate size for the mmap given the current size
// of the database. The minimum size is 32KB and doubles until it reaches 1GB.
// Returns an error if the new mmap size is greater than the max allowed.
func (db *DB) mmapSize(size int) (int, error) {
// Double the size from 32KB until 1GB.
for i := uint(15); i <= 30; i++ {
if size <= 1<<i {
return 1 << i, nil
}
}
// Verify the requested size is not above the maximum allowed.
if size > maxMapSize {
return 0, fmt.Errorf("mmap too large")
}
// If larger than 1GB then grow by 1GB at a time.
sz := int64(size)
if remainder := sz % int64(maxMmapStep); remainder > 0 {
sz += int64(maxMmapStep) - remainder
}
// Ensure that the mmap size is a multiple of the page size.
// This should always be true since we're incrementing in MBs.
pageSize := int64(db.pageSize)
if (sz % pageSize) != 0 {
sz = ((sz / pageSize) + 1) * pageSize
}
// If we've exceeded the max size then only grow up to the max size.
if sz > maxMapSize {
sz = maxMapSize
}
return int(sz), nil
}
View()查询接口
View()主要用来执行只读事务。事务的开启、提交、回滚都交由tx控制。
// View executes a function within the context of a managed read-only transaction.
// Any error that is returned from the function is returned from the View() method.
//
// Attempting to manually rollback within the function will cause a panic.
func (db *DB) View(fn func(*Tx) error) error {
t, err := db.Begin(false)
if err != nil {
return err
}
// Make sure the transaction rolls back in the event of a panic.
defer func() {
if t.db != nil {
t.rollback()
}
}()
// Mark as a managed tx so that the inner function cannot manually rollback.
t.managed = true
// If an error is returned from the function then pass it through.
err = fn(t)
t.managed = false
if err != nil {
_ = t.Rollback()
return err
}
if err := t.Rollback(); err != nil {
return err
}
return nil
}
Update()更新接口
Update()主要用来执行读写事务。事务的开始、提交、回滚都交由tx内部控制
// Update executes a function within the context of a read-write managed transaction.
// If no error is returned from the function then the transaction is committed.
// If an error is returned then the entire transaction is rolled back.
// Any error that is returned from the function or returned from the commit is
// returned from the Update() method.
//
// Attempting to manually commit or rollback within the function will cause a panic.
func (db *DB) Update(fn func(*Tx) error) error {
t, err := db.Begin(true)
if err != nil {
return err
}
// Make sure the transaction rolls back in the event of a panic.
defer func() {
if t.db != nil {
t.rollback()
}
}()
// Mark as a managed tx so that the inner function cannot manually commit.
t.managed = true
// If an error is returned from the function then rollback and return error.
err = fn(t)
t.managed = false
if err != nil {
_ = t.Rollback()
return err
}
return t.Commit()
}
Batch()批量更新接口
Batch的本质是: 将每次写、每次刷盘的操作转变成了多次写、一次刷盘,从而提升性能。
一个DB对象拥有一个batch对象,该对象是全局的。当我们使用Batch()方法时,内部会对将传递进去的fn缓存在calls中。
其内部也是调用了Update,只不过是在Update内部遍历之前缓存的calls。
有两种情况会触发调用Update。
- 第一种情况是到达了MaxBatchDelay时间,就会触发Update
- 第二种情况是len(db.batch.calls) >= db.MaxBatchSize,即缓存的calls个数大于等于MaxBatchSize时,也会触发Update。
// Batch calls fn as part of a batch. It behaves similar to Update,
// except:
//
// 1. concurrent Batch calls can be combined into a single Bolt
// transaction.
//
// 2. the function passed to Batch may be called multiple times,
// regardless of whether it returns error or not.
//
// This means that Batch function side effects must be idempotent and
// take permanent effect only after a successful return is seen in
// caller.
// 幂等
// The maximum batch size and delay can be adjusted with DB.MaxBatchSize
// and DB.MaxBatchDelay, respectively.
//
// Batch is only useful when there are multiple goroutines calling it.
func (db *DB) Batch(fn func(*Tx) error) error {
errCh := make(chan error, 1)
db.batchMu.Lock()
if (db.batch == nil) || (db.batch != nil && len(db.batch.calls) >= db.MaxBatchSize) {
// There is no existing batch, or the existing batch is full; start a new one.
db.batch = &batch{
db: db,
}
db.batch.timer = time.AfterFunc(db.MaxBatchDelay, db.batch.trigger)
}
db.batch.calls = append(db.batch.calls, call{fn: fn, err: errCh})
if len(db.batch.calls) >= db.MaxBatchSize {
// wake up batch, it's ready to run
go db.batch.trigger()
}
db.batchMu.Unlock()
err := <-errCh
if err == trySolo {
err = db.Update(fn)
}
return err
}
type call struct {
fn func(*Tx) error
err chan<- error
}
type batch struct {
db *DB
timer *time.Timer
start sync.Once
calls []call
}
// trigger runs the batch if it hasn't already been run.
func (b *batch) trigger() {
b.start.Do(b.run)
}
// run performs the transactions in the batch and communicates results
// back to DB.Batch.
func (b *batch) run() {
b.db.batchMu.Lock()
b.timer.Stop()
// Make sure no new work is added to this batch, but don't break
// other batches.
if b.db.batch == b {
b.db.batch = nil
}
b.db.batchMu.Unlock()
retry:
// 内部多次调用Update,最后一次Commit刷盘,提升性能
for len(b.calls) > 0 {
var failIdx = -1
err := b.db.Update(func(tx *Tx) error {
遍历calls中的函数c,多次调用,最后一次提交刷盘
for i, c := range b.calls {
// safelyCall里面捕获了panic
if err := safelyCall(c.fn, tx); err != nil {
failIdx = i
//只要又失败,事务就不提交
return err
}
}
return nil
})
if failIdx >= 0 {
// take the failing transaction out of the batch. it's
// safe to shorten b.calls here because db.batch no longer
// points to us, and we hold the mutex anyway.
c := b.calls[failIdx]
//这儿只是把失败的事务给踢出去了,然后其他的事务会重新执行
b.calls[failIdx], b.calls = b.calls[len(b.calls)-1], b.calls[:len(b.calls)-1]
// tell the submitter re-run it solo, continue with the rest of the batch
c.err <- trySolo
continue retry
}
// pass success, or bolt internal errors, to all callers
for _, c := range b.calls {
c.err <- err
}
break retry
}
}
// trySolo is a special sentinel error value used for signaling that a
// transaction function should be re-run. It should never be seen by
// callers.
var trySolo = errors.New("batch function returned an error and should be re-run solo")
type panicked struct {
reason interface{}
}
func (p panicked) Error() string {
if err, ok := p.reason.(error); ok {
return err.Error()
}
return fmt.Sprintf("panic: %v", p.reason)
}
func safelyCall(fn func(*Tx) error, tx *Tx) (err error) {
defer func() {
if p := recover(); p != nil {
err = panicked{p}
}
}()
return fn(tx)
}
附录:数据存储与检索
图片来源:jaydenwen123