一. BEV感知算法介绍
目录
-
- 前言
- 1. BEV感知算法的概念
- 2. BEV感知算法数据形式
- 3. BEV开源数据集介绍
-
- 3.1 KITTI数据集
- 3.2 nuScenes数据集
- 4. BEV感知方法分类
-
- 4.1 纯点云方案
- 4.2 纯视觉方案
- 4.3 多模态方案
- 5. BEV感知算法的优劣
- 6. BEV感知算法的应用介绍
- 7. 课程框架介绍与配置
- 总结
- 下载链接
- 参考
前言
自动驾驶之心推出的《国内首个BVE感知全栈系列学习教程》,链接。记录下个人学习笔记,仅供自己参考
本次课程我们来学习下课程第一章——BEV感知算法介绍,一起去了解下 BEV 感知算法的一些基本概念、典型应用
课程大纲可以看下面的思维导图
1. BEV感知算法的概念
在讨论什么是 BEV 感知算法之前呢,我们可以对这个词去做一个拆解,拆分为三个部分,一个是 BEV,一个是感知,一个是算法

那什么是 BEV 呢?
- Bird’s-Eye-View,鸟瞰图(俯视图)
- 通俗的讲它是一种从上往下的拍摄视角,现在很多表述中习惯把 BEV 称为上帝视角
- BEV 视角空间优势:尺度变化小,遮挡小
首先 BEV 视角第一个优势尺度变化小该怎么去理解呢,那我们以上图为例,它在一个正视图的视角下存在远小近大的特点,离相机比较近的目标尺度比较大,离相机比较远的目标尺度比较小,相反,我们在 BEV 空间去看会发现尺度差异变化其实是非常小的,那尺度变化小则网络对特征一致的目标表达能力更好,所以尺度变化小是 BEV 空间的一个优势
第二个优势就是基于 BEV 感知算法的视角遮挡是比较小的,这其实也是一个很直观的理解,当前后两辆车同时出现的时候,后面的车会很自然的将前面的车遮挡,那如果我们在视觉特征丢失的情况下通过前视图的方法是很难把后面的车辆预测到的,相反,我们在 BEV 视图下可以很清晰的把遮挡的车完整的进行区分,这是 BEV 俯视图的第二个优势
那我们在了解了什么是 BEV 之后,我们讨论第二个问题,什么是感知?
通常而言我们说的感知是指从人类的角度来讲,是外界事物在人脑中的一个响应,举个简单的例子,比如告诉你现在我面前有一根香蕉,那你在脑海中会构造出一个黄色的,然后弯弯的香蕉性质,那同样我们说的 BEV 感知是什么呢,是客观世界图像去在 BEV 视角下的一个响应,比如我们在前视图上有一个车,那在对应的 BEV 视图上也应该有一个车的样子,那我们刚刚说的这个过程,其实就是一个 BEV 感知的过程,更加学术的表达是,利用感知模型将多传感输入统一到 BEV 表征,这里的多传感输入主要包括图像、毫米波雷达、激光雷达等等
我们说完了感知这个问题,那我们进入下一个方面,什么是算法?
那算法通俗意义上来讲是一种数学模型,它是试图去帮助计算机理解不同输入从而可以实现不同任务,举个简单例子,比如你想检测一个 2D 目标,那我们会设计 2D 目标检测算法,那我们想检测 3D 目标,我们就会设计 3D 目标检测算法,那同样如果我们想生成 BEV 视角的图像,那我们设计的就是 BEV 感知算法
通过对 BEV 感知算法词的拆解,我们讲解了 BEV 视角空间是什么,什么是感知,什么是算法
接下来我们考虑另一个问题,我们说的 BEV 和感知哪个更重要呢?
那明显是感知更重要,BEV 空间是一个已经提出很多年的概念,而我们提的 BEV 本身只是一个俯视视角空间的概念,通俗的讲,它就是一个壳子,那我们怎么把不同的输入数据套到这个壳子里面,这才是问题的关键,那所以说我们现在很多算法的设计是围绕我们所提到的这个感知模块去做的,我们如何设计一个比较好的感知模块是 BEV 感知算法的一个核心点。
OK!我们在了解了基本概念之后,我们再来补充下基本的 BEV 感知算法是利用哪些数据实现了哪些任务,后续可以有哪些扩展,如下图所示:
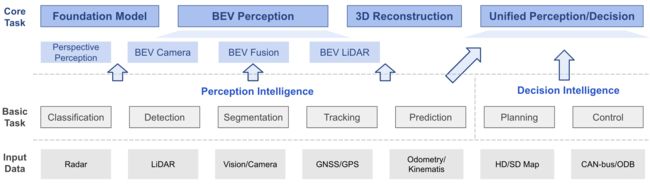
在上图中我们也做了一些标记和说明,首先我们提到的 BEV 感知任务是一个建立在多个子任务基础上的概念,这些子任务包括分类、检测、分割、跟踪、预测、控制规划等等,是一个比较综合性的概念,那我们的课程还是以自动驾驶中非常常见的检测任务去做介绍的,那如果后续涉及到一些多任务的框架时,我们也会做一个额外的讲解
其次我们所说的 BEV 感知它的输入其实也是比较广泛的,包括毫米波雷达、点云数据、相机图像、GPS数据、轨迹等等,本次课程中我们还是围绕最常见的输入展开,我们主要涉及的是雷达点云、图像数据
那按照不同的输入,我们常见的 BEV 感知算法的分类也比较清晰了,以相机图像为输入的算法我们称之为 BEV Camera,是一种纯视觉的方案,那比较具有代表性的像 BEVFormer,BEVDet 等等,我们后续会详细介绍;如果以单点云作为输入的方法我们称之为 BEV LiDAR,比如像 PV-RCNN,PV-RCNN++等等,它们一般是将处理后的点云特征映射到 BEV 平面上生成 BEV 特征;那还有一种方案是以图像和点云混合输入的方法,我们称之为融合感知的方法叫 BEV Fusion,那像这类方法同时处理图像和点云特征去生成 BEV 感知的一个多模态融合起来的特征表达,最具代表性的就是 BEVFusion,后续课程我们也会有相关框架的一个详细讲解
明白了 BEV 感知算法这个基础概念之后,那我们自然会想 BEV 感知算法到底是怎做的,它是如何处理多种数据的,是如何去生成 BEV 表征的,它如何去做不同的任务的,那这些内容我们会在余下的课程中去做一一的讲解。
2. BEV感知算法数据形式
我们在上面有提到过 BEV 感知算法主要包括两种输入,可以分为三种形式
其中的两种输入是指相机图像输入和激光雷达点云输入,那三种形式是包括纯图像形式,纯点云形式以及图像点云多模态融合的形式,无论是哪种形式均是以单独或者融合的图像或者点云作为输入的,所以我们在这节内容中会分别介绍在 BEV 感知算法当中对图像和点云处理的方式
我们先来看下什么是图像

图像从原理上来讲是由相机生成的,将三维世界中的坐标点(单位为米)映射到二维图像平面(单位像素),图像本身是会损失掉三维空间信息的,因为我们会将深度维度去进行一个压缩,将原本的三维世界坐标投影到二维平面上
那可能你会疑惑,图像既然有损失了,那为什么我们还要使用图像作为输入数据呢?
那这是因为虽然图像在深度维度上是有明显的信息损失的,但它也有明显的优势,它是一种密集型的表达,纹理信息非常丰富,比如上图中我们从图像上可以清晰的看到车窗、车轮等等,而且现在通用的相机便宜,成本低,这也就是为什么现在很多自动驾驶公司去大力推行纯视觉感知的原因之一
此外,我们基于图像任务的通用基础模型相对而言是比较成熟的,2D CV 的发展已经非常之久了,它的一些任务比如检测、分割等等性能都已经非常好了,所以我们可以有效借鉴 2D 图像算法中的一些基础框架或者基础的特征提取模块去完成我们所谓的 3D 检测任务
那最经典的 3D 检测算法比如像 FCOS3D,DETR3D 等等其实都是来源于 2D 算法,只不过将其扩展到 3D 领域而已
那对于一张图像而言我们一般用 HxWxC 来表示,其中 H 代表图像的高度,W 代表图像的宽度,C 代表图像的通道维度,通常我们处理的是包含 RGB 3 个通道的彩色图像,所以一般而言通道数 C 都是 3。图像是由一个个像素组成的,对于 RGB 彩色图像而言,每一个像素的取值范围是 0~255,每个像素位置坐标我们一般会用 (x,y) 表示或者像素平面的 (u,v) 表示,与我们后续要讲的点云数据是有本质区别的
OK!我们了解了什么是图像数据之后,我们自然会想知道通用的 BEV 感知算法中一般会用什么样的网络去处理图像数据呢?
我们这里以 BEVFormer 和 BEVFusion 两个经典网络为例,来看看他们是怎么处理图像数据的

先看 BEVFormer,它是一个典型的 BEV-Camera 的方法,也就是我们仅仅依赖于相机图像数据输入的一组图来作为我们网络的输入,那多视角图像作为 input 输入之后会通过 Backbone 网络提取得到 Multi-Camera Features 图像特征,其中的 Backbone 就是一个典型的图像处理网络,利用这个骨干网络提取原始的多视角图像数据的特征,后续拿这个特征可以生成 BEV 或者用它来做检测等等都是可以的。
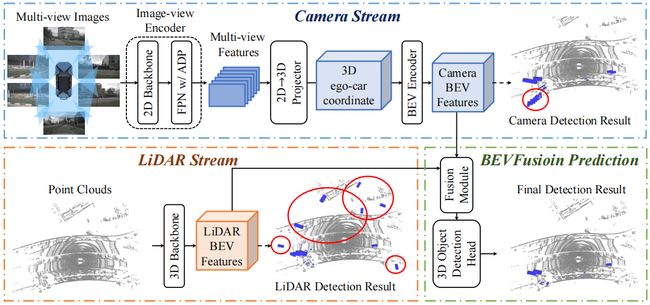
OK!我们再来看下另一种方案 BEVFusion,它是一种典型的基于融合的方法,它依赖于相机图像和点云两个输入,图像方面 Multi-view Images 多视角图像作为输入,通过 Encoder 生成 Muliti-view Features 多视角图像特征,那显然在 BEVFusion 当中图像处理模块叫做 Encoder
无论是 BEVFormer 中的骨干网络,还是 BEVFusion 中的图像编码器,他们只是图像处理网络模块的不同命名而已,使用的网络其实都是比较一致的,一般是 2D 图像处理框架中提取图像特征的一些通用网络,比如说像 ResNet,ResNet+FPN 等等
所以说对于图像处理模块我们只要明白一点,无论是基于相机图像的还是基于多模态融合方法的,它们对于图像特征的提取是大同小异的,它们都是使用已有的 2D 图像网络去做的
那我们上面说完了图像输入,那 BEV 感知算法其实还有一种常见的数据形式,那就是点云输入

我们先分析下什么是点云,点云这个概念我们一听可能很晦涩,通俗的讲,点云其实是很多点的一个集合。在上图中的场景中,我们发现它不同于我们常见的图像,这个场景其实是由一个个点组成的,有黄色的、绿色的、粉红色的等等。我们上面所展示的其实就是一个很典型的点云场景,那这个点云场景有什么特点呢?它与图像有什么区别呢?
首先第一点,它是一个稀疏性场景,稀疏性我们怎么来理解呢?从图中我们能看到除了一些颜色鲜明的前景区域外还有一些黑色区域,我们需要注意的是黑色区域是没有点云信息的,那意味着我们在特征提取的时候黑色区域是没有区域特征的,那产生这些黑色区域的原因是什么呢?通常的原因还是由于我们采集设备的限制,采集点云的时候通常是通过激活雷达传感器去进行采集的,激光雷达会发射三条射线,如果发射的射线碰到物体,它会产生一个反射,通过激光雷达采集这个反射信息,我们就可以知道哪些地方是有物体的,那如果没有反射信息,激光雷达就采集不到信息

我们按照这个思路去推导,现在如果有一个物体恰好出现在前面物体的正后方,也就是后面的物体被前面的挡住了,如上图所示,那我们可以采集到前面物体的信息,而后面物体的信息会由于遮挡导致点云缺失,这也是导致稀疏性的一个原因
另外还有一种什么情况呢,从上图中我们可以看到点云数据分布呈现出一种明显的远少近多的情况,远处相对而言它的点云数据是比较少的,而离我们激光雷达近的地方相对而言点云数据是很多的,那这又是什么原因呢?
我们还是以上面的射线发射图为例,这是由于射线的一个发散性导致的,远距离采样间隔大,相对而言近距离采样间隔是比较小的,同样的目标远距离可能会漏采,那在近距离可以很好的被捕捉到
OK!我们说完了稀疏性,那点云还有个什么特点呢?还有个无序性的特点
那这个无序性该怎么去理解呢,我们之前有说点云其实是很多点的一个集合,那假设现在有一个点云集合 {1,2,3,4,5} 包含 5 个元素,那我们将集合中的元素顺序交换对集合本身有影响吗,比如说 {2,1,4,3,5},那显然是没有影响的,这 5 个数还是五个元素,所以我们通常讲的点云的无序性,它是意味着无论我们点云集合中的点是以何种顺序排列的,它并不会对本身点云集合产生一些比较严重的影响
我们说点云它既稀疏又无序,那我们为什么还要用它呢?这是因为我们的激光点云数据是对 3D 场景一种非常好的表现形式,它是包含深度维度这个信息的,通过深度这一维度的表达,人不会是一个纸片人,车也不是纸片车,它是一种很立体很显性的表达方式。
图像数据也好,点云数据也好,它们都是有一些缺点的,任何数据其实都不会完美,我们需要考虑的是怎样扬长避短去发挥这个不同模态数据的优势。
那我们来简单总结下
什么是点云?
- 点云的基本组成单元是点,点组成的集合叫点云
点云有什么特点?
- 稀疏性
- 无序性
- 是一种 3D 表征
那说完了点云是什么,它有哪些特点后,下面我们来讲解下怎么去表示一个点云数据,那我们反复的说点云其实是点的集合,那对于一个点的集合我们一般写成 P = { P 1 , P 2 , . . . P N } P = \{P_1,P_2,...P_N\} P={P1,P2,...PN},这个点云集合里面其实包含了 N 个点,那里面每一个点怎么表示呢?由于点云是 3D 场景,所以说其中的每一个点可以用 3D 坐标进行表示,也就是 ( x , y , z ) (x,y,z) (x,y,z),有了这样的表示方法,我们就可以把点云场景转换为完整的数学表达,从而可以通过我们所说的数学模型,那也就是网络去进行后续 3D 点云特征的提取
我们讲过了点云特征是怎么表征后,我们来思考下一个问题,我们应该怎么提取点云特征呢?

那现在通用的 3D 点云特征提取方法是 Point-based 基于点或 Voxel-based 基于体素两种方式,通过这两种方式,去在一个庞大的点云数据当中提取出 3D 场景的点云表征
那一般而言基于点的方式,我们会在庞大的点云数据当中选取一些关键点,比如上图中绿色的点 ● 是一个关键点,黄色的点 ● 是我们点云场景以绿色关键点为中心提取到的附近或周围的一些特征点,这就是基于点方法的特征提取。附近周围怎么界定呢?通常 Point-based 方法是以一个球面空间作为界定的,以关键点为中心的球体中所包含的所有点,我们认为是对关键点起特征加强的一些点,它们的特征会全部聚合到我们所选取的关键点上面,这种方法我们称之为 Point-based 也就是基于点的方法。
那另一种方法是基于体素或者说网格,传统的基于点的方法是从已有点云出发挑选一些关键点,而基于体素的方法则是从场景出发,将场景划分为多个小块,比如上图中的场景被划分成了 5x5 的块,蓝色部分是场景中的一些点云数据,通过对一定区域内的点云进行一个聚合就会得到提取后的点云特征,也就是图中的绿色部分,这有点类似于卷积的过程
可以看到无论是基于点的方式也好,还是基于体素的方式也好,讨论一个独立点是没有意义的,我们都需要采用一定的聚合方法,这是因为随机采样的一个点很难区分出是属于人还是车还是其他背景物体,单独讨论一个点意义不大,需要结合其局部的空间信息进行探讨,那对于 Point-based 方法而言,我们考虑的是关键点和它附近点的一个特征,而对于 Voxel-based 方法而言,我们聚合的则是一定立体空间范围内的点
那明白了点云特征怎么提取之后,我们再来看下点云特征是怎么用在 BEV 感知中的,我们以 BEVFusion 的方法为例,流程如下图所示:

从图中可以看到 LiDAR Stream 中是以点云为输入的,通过 3D 骨干网络得到点云特征,一般来说我们得到点云特征后是可以直接处理得到 3D 检测结果的,那后面的处理我们可以先不关注,在之后的课程中我们会详细分析,目前我们主要关注常用框架中点云网络是怎么提取点云特征的就行
OK!至此,我们对 BEV 感知算法中常见的数据形式和数据处理方法做了一个基本讲解,那更为详细的框架讲解,我们会在后续涉及到相应模块时再做说明
那以上就是这小节的主要内容
那我们说了这么多数据,有没有一些实际的数据呢,那这就进入到我们下一小节的内容
3. BEV开源数据集介绍
OK,我们继续开始 1.3 小节 BEV 开源数据集的部分
通常 3D 数据集为了适配不同的任务,它的种类是非常多的,那比如一个 3D 检测数据集、3D 分割数据集还有轨迹规划数据集,还有一些地图数据等等,那我们课程中主要还是围绕自动驾驶中主流的 3D 检测任务给大家介绍两个最常见的数据集,一个是 KITTI,一个是 nuScenes 以及它们的一些格式,怎么用这个数据集
我们首先介绍一下 KITTI 数据集
3.1 KITTI数据集
官网链接:https://www.cvlibs.net/datasets/kitti/
KITTI 其实是 3D 目标检测中一个比较基于也是非常常用的一个数据集,它是 2012 年发布的,主要是针对无人驾驶任务,包括 2D 检测、3D 检测、分割、跟踪等等,那我们关注接下来几个事情,首先第一个数据是怎么采集的呢?

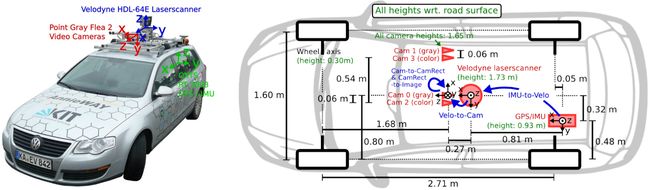
上图是 KITTI 数据集采集时所使用的汽车,该汽车搭载了许多的传感器来采集信息,包括相机、激光雷达、GPS 系统等等。KITTI 数据集针对 3D 检测任务提供了 14999 张图像和其对应的点云数据,那其中我们一般会划分出 7481 张作为训练集,7518 张作为测试集,训练测试差不多都是 7500 张图片左右
那第二个问题,KITTI 标注的哪些目标呢?
相对而言,KITTI 的标注类别是比较少的,总共是只有车、行人和骑车的人 3 个目标,那总共 80256 个标注对象,平均一张图差不多有 5-6 个目标对象,相对来说其实目标也不是很多
那接下来我们来看一下,一个比较好的 KITTI 数据可视化是什么样的,上面是 KITTI 官方的一个 demo 视频,从视频中我们也能看到随着车辆的行驶,路线中的图像数据(上半部分)和点云数据(下半部分)是同时被记录下来,那这里还有个比较细节的地方,我们能看到两侧是有两条虚线的,这个表示什么呢?它是表示前方 90° 的一个视角,可能由于透视的原因我们这里看起来不太像 90°,那这个 90° 视角表示什么呢,它其实表示的是车载相机的拍摄范围
那这里其实是体现了点云数据和图像数据的有这么一个区别的,如果我们只使用一台相机的话,我们叫单视角,它是具有视角上的一个限制的,比如 KITTI 数据集,它是一个单个采集的相机,只能提供前视图的图像信息。那相比而言,我们的点云有什么优势呢,从图中可以看到除了我们正视的前方的视角外,我们的点云是提供 360° 采集的,我们可以看到不仅仅是车辆行进方向有点云数据,包括其侧面,那甚至还没有展现出来的后方也是有采集到的点云数据的
那 KITTI 数据集在标注的时候,考虑到只有虚线范围内有图像数据,所以 KITTI 数据对于目标的标注范围全部是集中在图像能够采集到的范围内,也就是图像虚线所标注的部分,我们从图中也能看到,彩色的框框是数据集是已经标注的部分,其余的部分的有点云数据是没有标注的,那它这个其实也是一个很有意思的事情,我们如果单独利用点云数据的话,本身而言也是可以做 3D 检测的,不过 KITTI 却只提供这个正面视角的标注,是不是想要我们同时利用图像数据和点云数据去进行检测呢?那大家也可以发挥脑洞探讨一下
那如果大家想下载这个数据集,可以去上面我提供的官网链接里面去下载,或者点击 here 下载博主准备好的数据集

我们进入到下一个部分,我们进入到官网链接中,点击 3D 检测板块当中,看到上述界面里面哪些数据是需要下载的呢?一个是我们常用的左视图数据,我们还能看到下面有一个右视图的数据,那这里区分左右视图,它主要是为了提供给双目模型使用的,如果我们只考虑 3D 目标检测任务的话,我们只用下载左视图数据就好
另外我们还需要点云数据,数据稍微偏大一些,有 29G,那你可能会好奇,为什么点云数据前面还有一个 Velodyne 前缀呢,那这个前缀其实是 KITTI 数据集采用的激光雷达是这个牌子的,所以它直接就用品牌的名字取命名了
另外还需要什么呢,还需要标注和转换矩阵,标注显然是对于一个目标将其标注在 2D 图像或者 3D 点云数据中,那转换矩阵又是什么呢?我们在考虑转换矩阵之前先考虑下一个转换矩阵实现了什么样的功能,下面有一个简单的示意图:
那我们之前提到过在 KITTI 数据集中同时涉及了图像数据和点云数据,那也就是说同时包含了 2D 和 3D 数据,那我们怎么知道 2D 图像中的目标和 3D 点云的目标是一一对应的呢,那这就引出了另外一个问题,如何对两种不同模态的数据做一一对应关系,所以我们这里就涉及到一个 2D 和 3D 平面和空间坐标系转换的问题,我们如何把 2D 上的 ( x , y ) (x,y) (x,y) 转换到三维空间 ( x ′ , y ′ , z ′ ) (x',y',z') (x′,y′,z′),KITTI 数据集在做这个坐标转换的时候,主要用到了下面这个公式
y = P r e c t ( i ) R r e c t ( 0 ) T v e l o c a m x \mathbf{y}=\mathbf{P}_{rect}^{(i)}\mathbf{R}_{rect}^{(0)}\mathbf{T}_{velo}^{cam}\mathbf{x} y=Prect(i)Rrect(0)Tvelocamx
在上面的公式中 x \mathbf{x} x 表示一个点云坐标,点云坐标通过 T \mathbf{T} T 矩阵可以将点云坐标先转换到对应的相机坐标系,那为什么要做这个转换呢?那我们从上图中可以看到一个点云采集设备和图像采集设备它们俩是分开的,因此它们的坐标系在空间位置上是有差距的,所以说我们要通过这个点云坐标系到图像坐标系的一个转换,把原本在点云坐标系下的点 x \mathbf{x} x 先转换到以相机为原点的世界坐标系下
OK,我们思考下一个问题,它这个转换是一个三维量到二维量的转换,还是一个三维量到三维量的转换呢?那我们这里提到的三维量到三维量的意思就是说我们本身一个点云坐标是 ( x , y , z ) (x,y,z) (x,y,z),它是一个三维量,那我们通过这个转换之后它是由 ( x , y , z ) (x,y,z) (x,y,z) 到 ( x ′ , y ′ ) (x',y') (x′,y′) 还是到 ( x ′ , y ′ , z ′ ) (x',y',z') (x′,y′,z′) 呢?我们思考一下
本质而言,它这个转换其实是一个三维量到三维量的转换,我们的点云坐标 x \mathbf{x} x 通过 T \mathbf{T} T 矩阵的变换之后还是一个三维向量,那只不过,它这个三维向量的参考坐标系发生了变化,从原本的点云坐标系转换到了图像坐标系,那我们说清楚了矩阵 T \mathbf{T} T,我们再来看 R \mathbf{R} R 是什么
R \mathbf{R} R 从官方文档中的解释叫畸变校正矩阵,它主要是为了对图像的成像平面去进行一个校准,通过这个矩阵之后,原本的点云坐标 x \mathbf{x} x 就被转换到了已经校准后的相机坐标系下,是对原本的相机它的一个坐标去进行一个校正,通过 T \mathbf{T} T、 R \mathbf{R} R 之后呢,原本的点云坐标会被转换到已经校正好的相机坐标系下,那我们如何从这个相机坐标系到 2D 的图像坐标呢?
那这其实是我们比较熟悉的领域了,通过相机的内参矩阵,也就是公式中的 P \mathbf{P} P 矩阵,可以得到最终的图像坐标 y \mathbf{y} y 的表示 ,那这个 y \mathbf{y} y 在图像中可以通过 ( u , v ) (u,v) (u,v) 表示,也可以通过 ( x , y ) (x,y) (x,y) 来表示
OK,我们总结一下,通过上面的公式我们实现了从点云坐标的点 x \mathbf{x} x 转换到 2D 图像中的点 y \mathbf{y} y,那反过来,我们如果对 y \mathbf{y} y 按照 P \mathbf{P} P、 R \mathbf{R} R、 T \mathbf{T} T 做逆变换的话,那我们就可以轻松的将 2D 图像中的点 y \mathbf{y} y 换算到点云坐标系下的点 x \mathbf{x} x,所以实现了从 2D 图像到 3D 点云之间的一个双向转换,我们可以从点云到图像,也可以从图像到点云
上面我们主要给大家讲解了一下在 KITTI 数据集中它对转换矩阵的一个标注,下面我们再给大家对 KITTI 数据集中物体标注文件做一个详细说明

首先它的标注是按场景提供的,如上图所示,每一个文件名对应一个编号的场景,比如 000001 这个场景我们可以在图像数据文件和点云数据文件中找到其对应的图像和点云数据,它是一个场景编号。另外,我们对于每一份标注文件而言,比如图中的 000001.txt,我们打开后看到它其中是标注了很多数据的,每一行表示一个物体的标注信息,那具体每一行标注信息代表的含义是什么呢,我们拿一个实际场景的标注信息来说明,如下图所示:

我们对上面的标注信息拆开来看:
- Pedestrain:类别标签,表示当前标注物体的类别是行人
- 0.00:是否被截断(指目标并未完全出现在图像中),它是一个 [ 0 , 1 ] [0,1] [0,1] 之间的值,表示当前我们标注的目标被截断的程度,0 表示没有截断,数值越高表示截断越严重,它是一个小数值,表示的是一个比例值
- 0:被遮挡程度,取值是 0,1,2,3 一系列的离散值,和上面的截断值不同,截断是一个连续的小数值,而遮挡是一个离散值,0 表示当前目标没有遮挡,1 表示部分遮挡,2 表示严重遮挡,3 表示标注人员也不清楚是否遮挡。无论是遮挡值还是截断值,它们依赖于标注人员的主观经验,那由于标注人员主观差异所引发的标注错误也好,或者标注不准确也好,是当前 KITTI 数据集标注噪声的来源之一
- -0.20:观测角度,它是一个幅度值,介于 [ − π , π ] [-\pi,\pi] [−π,π] 之间,标注当前标注物体与相机之间呈现的一个夹角,通俗的讲就是物体在相机哪个方向
- 712.40 143.00 810.73 307.92:物体 2D 检测框的左上角和右下角坐标
- 1.89 0.48 1.20:当前目标的 3D 尺寸,物体的高度、宽度和长度,单位是 m
- 1.84 1.47 8.41:物体 3D 框的中心点坐标,加上上面的物体长宽高和角度信息,这一系列的七维量其实就是我们 3D 检测中通常需要预测的结果
- 0.01:置信度得分,表示这个目标在这个位置与这个类别存在的概率有多大,通常测试时会使用到
我们总结下对于 KITTI 数据集我们讲解了哪些信息,我们先介绍了 KITTI 数据集的规模,标注类别,标注总量,然后介绍了如何下载 KITTI 数据集以及对 KITTI 数据集中涉及到的标注规范还有转换矩阵做了一个详细的讲解
那 KITTI 数据集是 3D 目标检测中非常基础,也是非常常用的数据集,也是基于单点云和多模态融合方法经常评测的数据集之一,那接下来我们讲解另外一个在 BEV 感知算法里面非常通用,已经几乎是每天工作必做的一个数据集叫做 nuScenes 数据集
3.2 nuScenes数据集
官网链接:https://www.nuscenes.org/
那如果大家可以想下载这个数据集,可以去上面我提供的官网链接里面去下载,或者点击 here 下载博主准备好的数据集
为了突显 nuScenes 数据集和 KITTI 数据集的一个区别,我们将两个数据集去进行一个对比,如下表所示:
| KITTI | nuScense | |
|---|---|---|
| 数据怎么采集? | 通过车载相机,激光雷达等传感器采集 | 通过车载相机,激光雷达等传感器采集 |
| 数据规模有多大? | 共14999张图像及其对应点云 其中7481张作为训练集,7518张作为测试集 |
140万个相机图像、39万个激光雷达扫描结果、140万个毫米波雷达扫描结果 |
| 标注了哪些目标? | 目标类别包括:车、行人和骑车的人 共计80256个标注对象 |
目标类别包括:细分类别多达23类 约140万个标注对象 |
首先从采集方式上看,两个数据集都是采用车载模式进行采集的,传感器也是包括车载相机还有雷达等等,它们有什么区别呢,虽然采集设备的种类是一样的,但它们型号参数差距其实挺大的,nuScenes 的激光雷达采集速率是 20Hz,而 KITTI 数据集采集速率只有 2Hz,10 倍的差距,采集速率上存在明显的差异,数据规模上差异也非常明显,从相机图像的数量上来看,nuScenes 提供了 140 万张相机图像,那相比 KITTI 数据集的 15000 张图像差不多有 100 倍的差距
另外在标注种类上,nuScenes 提供了细分的类别标注,多达 23 类标注,那什么叫细分类别标注呢,比如说对于车辆这个类别,它不仅标注了车辆这个大类,还标注了车辆下面该车辆是属于轿车,还是卡车,还是救护车等等,是有非常详细的类别标注的,那我们把这个称之为细分的类别标注,那从细分的类别标注角度讲,nuScenes 提供了 23 类的标注,而相比 KITTI 数据集只提供了三类的标注,主要标注是车、人和骑车的人,所以从类别角度上来看差距也非常大
那从标注对象的数量角度看,nuScenes 提供了约 140 万个标注对象,而 KITTI 数据集只提供了 8 万多个对象,从标注对象数量角度来看也是数十倍的差异,通过对比我们能很清晰的看到 nuScenes 的数据规模比 KITTI 数据集要大非常非常多,从数据量,然后从类别,从标注量上差不多都是 10 倍以上的增量

那我们在讲解 KITTI 数据集的时候提到过 KITTI 数据集仅提供正视图的图像数据,那也就是说我们只能看到车前面有什么,而不能看到车侧面,车后面有什么,那 nuScenes 数据集总共包含 6 个相机,如上图所示,前后左右全都是覆盖住的,图中绿色的部分就是 nuScenes 的六个相机,它包含前面侧面和后面,全部都是包含的。此外,还包含一个激光雷达是放中间的,还有车身的五个毫米波雷达
那所以从采集方式上来看,我们能想象到它能提供很多数据,首先是因为相机设备的存在,而且是多视角相机设备的存在,所以 nuScenes 数据集必然会提供一个多视角的图像数据,那这与 KITTI 有着明显不同,我们讲过很多次,像 KITTI 只能提供正视图的数据,而不能提供侧面后面的数据
另外它还能提供点云数据,通过激光雷达可以采集到与 KITTI 数据集一样的点云数据,它们的区别无非是采集的速率不一样,另外一点我们在前面 KITTI 也强调过很多次了,涉及到多传感器的时候要特别注意不同传感器之间的位置关系,需要知道转换矩阵是什么,那像这类内容一般就是放在标注文件里面
另外一个我们要知道无论图像上还是点云上需要检测的目标出现在哪里,需要对于目标对象级别的一个标注,我们需要了解 nuScenes 它对于 3D 标注框是怎么去标注的,那我们带着这个初步的思考看下 nuScenes 数据集中包含了哪些内容,下载解压后的数据集目录如下图所示:

首先一个 nuScenes 数据集下面包含 4 个文件夹,第一个是 maps,这个数据其实在 3D 检测中应用是比较少的,它主要的应用场景是后期决策,所以这部分数据我们做了解即可
下一个数据是 samples,官网名称是叫 keyframes,它是一个关键帧,为什么是关键帧呢,这是因为 nuScenes 数据集采集量非常大,很多连续帧之间的数据差异比较小,这种数据差异特别小的源数据是不太适合做模型训练的,所以 nuScenes 为我们挑好了,它挑选了一些关键帧
那下一个文件夹叫 sweeps,官方的描述是说这个文件夹除了关键帧的其他帧全部都给你放 sweeps 里面了,那 sample 和 sweeps 两个文件夹还有什么区别呢?那图中标注得也很明确了,一个是已标注的数据,一个是未标注的数据,这意味着 samples 里面提供的是标注的图像,而 sweeps 里面提供的是未标注的图像,所以说 nuScenes 只提供了关键帧的标注,那对于其余帧,它给你打包放在 sweeps 里面了
那最后一个文件夹是 v1.0-,这个文件夹其实是非常重要的,它里面包含了非常多的标注数据,每一个标注数据以一个 JSON 文件的形式存在,那我们在图中可以看到有类别的 JSON 文件 category.json,有日志的 JSON 文件 log.json 等等,每个 JSON 文件里面包含了一类的数据,那这么多类别的数据里面,里面这么多 JSON 文件,我们应该怎么去理解这些 JSON 文件呢,具体各个 JSON 文件的描述可以看下图:

那这一部分其实看着是比较复杂的,我们从图中简单分析下:
- attribute.json:描述了一个实例的属性
- calibrated_sensor.json:车辆上已经校准的特定传感器(激光雷达/雷达/摄像机)的标定数据,其实就是转换矩阵
- category.json:对象类别的分类
- ego_pose.json:车辆在特定时刻的一个姿态,xy 平面的二维量,使用较少
- instance.json:一个物体的实例
- log.json:数据提取,车辆采集的日志信息
- map.json:用二值分割掩膜所保存的地图数据,3D 检测任务使用较少
- sample.json:样例,标注哪些帧是关键帧
- sample_annotation.json:关键帧的 3D 标注框
- sample_data.json:所有的传感器数据,除关键帧外的所有数据
- scene.json:场景数据
- sensor.json:传感器的种类
- visibility.json:实例的可见性
到此为止我们总结一下,对于 nuScenes 数据集而言里面提供了一个是数据,一个是标注,标注文件如上图所示,数据的话按照我们刚才讲的,里面包含了一个关键帧的数据和所有的原始数据
通过我们上面的 KITTI 和 nuScenes 数据集的讲解,大家应该对我们用到的一个基本的数据类型有了一个初步的了解了,因为内容比较多,所以评价指标这个模块就不在这里展开了,大家可以把数据集这块先消化吸收一下
那对于 KITTI 数据集和 nuScenes 数据集的评价指标,我们在后续具体论文中如果涉及到对应的数据集再做一个详细的讲解。
4. BEV感知方法分类
那之前的课程我们对 BEV 感知算法的基本概念、数据形式、数据集去做了一个详细的介绍,接下来我们会在这个小节对 BEV 感知算法做一个总述,会简单介绍一下不同的 BEV 感知方法区别和联系,我们在前面的 BEV 感知算法的基本概念中提到已知的 BEV 感知算法可以按照输入数据的不同被划分为 BEV LiDAR、BEV Camera 还有 BEV Fusion 的方法,那 BEV LiDAR 的方法是以点云作为输入的,BEV Camera 是以纯视觉的模态作为输入的,BEV Fusion 是多模态融合的框架,它主要是融合图像模态和点云模态
我们这里会在这小节按照这三种分类方式选择一些比较具有代表性的算法去给大家一一做一个介绍
4.1 纯点云方案
首先是 BEV LiDAR 的方法,这种方法的通用模式包括两种类型:
- Pre-BEV Feature Extraction:先提取特征,再生成 BEV 表征,代表算法如 PV-RCNN 等
- Post-BEV Feature Extraction:先转换到 BEV 视图,再提取特征,代表算法如 PointPillar 等
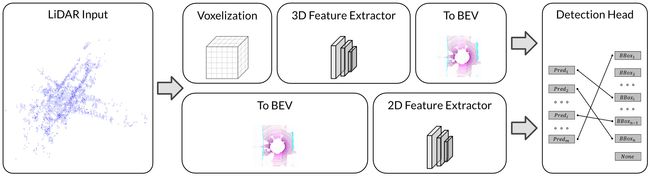
上面的框图给大家展示了两种方法的不同流程,首先我们还是从输入输出看起,对于 BEV LiDAR 这种方法而言,输入是纯点云的,也就是上图中的 LiDAR Input,输出是以检测任务为例,后面跟着一个检测头,那 Pre-BEV 和 Post-BEV 的一个主要区别在哪呢,其实是在中间的主体模块上
对于 Pre-BEV 而言,特征提取是在 BEV 之前做的,利用提取好的特征拍扁到 BEV 上生成对应的 BEV 特征图,接下来可以在这些 BEV 特征图上做一些后续的检测,那属于 Pre-BEV 这一类别的一些经典算法有 PV-RCNN、Voxel-RCNN、SA-SSD 等等
对于 Post-BEV 而言,特征提取是在 BEV 之后做的,从图中的流程也可以看到通过输入的点云数据先进行 BEV 的处理后再进行特征提取,特征提取是在 BEV 模块之后做的,所以叫做 Post-BEV,我们可以利用卷积网络提取已经拍扁的 BEV 图得到最后的 BEV 特征,那属于 Post-BEV 这一类别的经典算法有 PointPillar 等等
除了 BEV 位置不同外,我们还能看出什么区别呢,很明显两个特征提取器有着明显的不同,那对于 Pre-BVE 的方法首先要处理的是点云特征,所以说它一般都会先进入一个叫 3D 点云处理的网络,而对于 Post-BEV 的方法,由于它已经转换到了 BEV 视图,所以可以通过 2D 网络去进行特征的提取,那为什么我们一直说 PointPillar 的速度很快,很大一部分原因是它的特征提取网络是处理 2D 任务的,那它自然速度上会有成倍的一个优势
那我们这里以 PV-RCNN 的网络为例,简单介绍下 Pre-BEV 的特征提取框架是怎么做的,那本身 PV-RCNN 网络是属于基础的 3D 检测框架,所以教程里面我们只是做一个简单的流程性质的介绍,那接下来我们来看一下这个网络,其网络结构图如下:

看一个网络我们从输入输出看起,PV-RCNN 的输入是 Raw Point Cloud 原始点云,输出是最终的 3D 检测结果,包含检测框和其对应的置信度,所以从功能角度概括,PV-RCNN 网络是以点云为输入,输出 3D 检测结果的
明白了这个功能之后,我们再来看下 PV-RCNN 是怎么做的,它的流程是什么,首先从原始点云出发,我们可以从图中看到两个箭头,分别指向两个不同的模块,那这两个箭头其实表征了 PV-RCNN 的核心内容,是 Point 和 Voxel 融合的特征提取网络,它意味着 PV-RCNN 不仅使用了点特征还使用了体素特征
OK!我们再来复习一下,我们在介绍点云特征提取方法的时候讲过,一般而言 3D 点云有两种特征提取方式,一种是基于点特征的,通常提取关键点和其附近点的特征,另一种是基于体素或者说网格的,通常是对场景进行一个立体性质的划分,然后针对网格化的场景去提取特征,那这两种方法是各有优劣的,那 PV-RCNN 的作者把两种方法都用上,于是从原始点云出发,我们能看到 PV-RCNN 通过了两种处理,通过体素化的点云,利用 3D 稀疏卷积网络提取体素特征,而另一个支路通过关键点采样提取点的特征,随后将体素特征和点特征去就行一个融合得到最终的特征表达
那融合的方面会涉及到一些多尺度处理,那它的多尺度其实是在不同的 block 上面做的,因为本身 3D 稀疏卷积网络每一个 block 都提供了一些不同分辨率的特征,比如上图中的蓝色、绿色、黄色还有橘色是原本体素的一个多尺度特征,而灰色特征其实是来自于原始点的,是 Keypoints 提供的原始点特征,那最后的浅蓝色的是我们本次课程最关心的 BEV 特征,当然 PV-RCNN 的 BEV 特征很简单,它是将 3D 体素按照高度维度自上而下的拍扁得到 BEV 特征,那当然这个拍扁后的特征能不能满足我们后续检测的需要,那这就是现在很多 BEV 感知算法中需要讨论的后续问题了,那也是我们课程后续章节需要详细讲解的一个地方,那这里我们还是以 PV-RCNN 为例去给大家介绍 BEV LiDAR 中最具代表性的一个做法
4.2 纯视觉方案
那接下来我们看一看另外一种基于单模态输出的纯视觉的图像方案,它们的通用框架如下:
- 主要包括 2D 特征提取模块、视角转换模块和 3D Decoder 检测模块
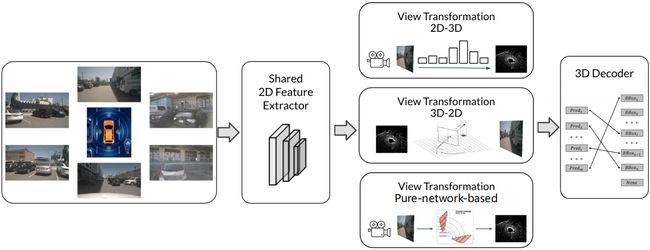
和 BEV LiDAR 的算法一样,我们在这里先对 BEV Camera 的算法做一个总结性的介绍,首先我们还是从输入输出看起,对于 BEV Camera 的方法而言,输入是相机图像,输出还是以检测任务为例,连的是一个检测头,那网络是怎么运行的呢,首先输入是多相机图像,通过 2D 特征提取网络,然后再通过视角转换模块,最后得到的特征进入 3D 检测头
那这里面存在两个细节,首先它的特征提取器为什么叫 Shared 2D Feature Extractor,我们要怎么理解这个 Shared Feature 呢,另外一个是它为什么要做 View Transformation,也就是视角转换呢
那我们先从第一个问题看起,Shared 表示什么,我们得联系输入看,输入是多张图像,那在特征提取的时候是不是一张图一个网络呢?显然不是,所以说我们这里的 Shared 它其实就意味着对于不同视角的图像采用的是相同的卷积网络,它是一个特征共享的模块
我们再来看第二个问题,我们为什么要使用视角转换呢?我们聊到视角转换的时候,我们得先明白视角转换实现了什么功能,那在上面的框图中其实是已经做了标注的,视角转换的功能实现的是从 2D 到 3D 或者从 3D 到 2D 的转换,那为什么要做这个转换呢?还是得联系输入,输入其实是一个 2D 的多视角图像,包括前视、后视、侧视等等,但它这些视角是不包含俯视视角的,所以说我们在纯视觉的方案中,如果想做 BEV 感知,首先我们需要利用这些多视角的 2D 图像先转换到俯视视角上,转换的这个过程其实就是视角转换模块去做的一个核心工作
由于 BVE Camera 的方法是我们后续整体课程的一个重点,所以我们这里再额外总结一下流程,BEV Camera 方法以多视角图像作为输入,提取图像特征,接着通过特征转换模块得到 BEV 特征再送入检测网络。按照模块划分的话,BEV Camera 方法中有 3D 特征提取、多视角转换以及检测三个模块,那这三个模块哪个更重要呢?其实是这个视角转换模块最重要,因为无论是 2D 特征提取模块还是检测模块其实都是基于已有的架构。已有的算法去做的,只有视角转换模块才是 BEV 感知算法的核心内容
那我们带着这个理解,看下经典的基于 BEV Camera 方法的 BEVFormer 是怎么做的,那像 BEVFormer 这个框架其实我们在各种各样的平台都听到过很多次了,它是 BEV 感知算法当中比较基础也是比较通用的一个框架,我们代入刚才的 BEV Camera 算法检测流程看一看这里的 BEVFormer 是不是符合我们刚才的一个讲解,BEVFormer 的网络结构如下图所示:
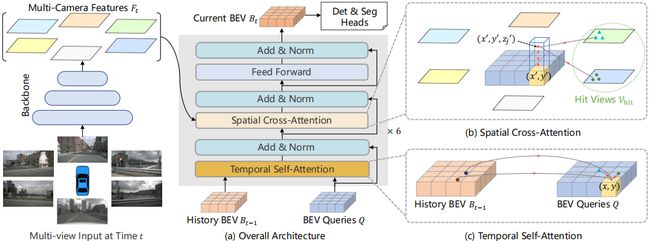
我们看一个网络还是从输入输出看起,BEVFormer 的输入是 Multi-view Input,输出是一个分割检测头模块,BEVFormer 从功能上概括就是以多视角图像为输入,输出 3D 检测结果,那这个概括非常符合 BEV Camera 方法的一个主体结构,那我们再来看看 BEVFormer 符不符合我们刚才说的模块化流程
BEV Camera 算法的主要模块是什么呢,2D 特征提取模块,视角转换模块和检测头模块,我们看看 BEVFormer 算法是怎么做的,通过 Multi-view Input 我们可以得到 Multi-Camera Feature,通过什么网络呢,通过图中的 Backbone 网络,那这个 Backbone 网络其实就是一个 2D 特征提取器,那检测头就是我们图中的分割检测头,那可能会有人说好像没看见有视角转换模块呀,那其实只是 BEVFormer 没有点名而已,从多相机特征到 BEV 特征就是通过视角转换模块实现的,也就是图中灰色区域的部分
那我们再把整体流程看一遍,那 BEVFormer 中有没有 2D 网络呢,有的就是图中的 Backbone 网络,那它有没有视角转换网络呢,有的就是图中灰色部分,那它有没有检测头呢,显然也是有的,那这个模块化的流程是不是完美符合我们前面提到的 BVE Camera 的算法整体流程
OK,我们再来看我们刚提到的三个模块,哪个模块占比最大呢,那显然是图中的灰色区域嘛,也就是视角转换模块占比最大,所以我们刚才也提到三个模块当中视角转换模块是 BEV 感知算法研究的一个重点,那不同的 BEV 感知算法往往就是在视角转换上去进行了不同的创新研究,那在 BEVFormer 中它引入的空间注意力也好,时序注意力也好,主要目的其实都是为了去通过视角转换功能实现更好的 BEV 特征,从而有利于后续的检测,我们这里的 BEVFormer 也只是给大家做一个很通俗的介绍,后续课程中会针对 BEVFormer 中各个模块做更详细的讲解
OK,我们以 BEVFormer 为例去给大家介绍了 BEV Camera 类别当中一个比较具有代表性的做法,那接下来我们再来看看利用多模态融合的方法是怎么做的
4.3 多模态方案
我们前面对 BEV LiDAR 和 BEV Camera 的方法分别做了介绍,那 BEV Fusion 顾名思义是对图像和点云的一个融合,那既然是融合,自然离不开图像处理和点云处理的基本流程,所以我们还是把 BEV LiDAR 和 BEV Camera 的流程拿过来看看 BEV Fusion 是怎么做的

那其实我们只要明白了基于单模态图像或者点云的 BEV 感知算法之后去理解 BEV Fusion 的流程会变得非常简单,那首先我们看一下融合是什么层面的,一般而言融合是特征层面的,是在我们得到 3D 特征或者 2D 特征之后对多模态特征的一个融合,其实就是 3D 点云特征和 2D 图像特征,如果设计合适的模块对这两个层面的特征进行一个融合,其实就是 BEV Fusion 方法的主体思路了,那所以如何融合特征才是这个问题的关键
接下来我们还是看一个经典案例 BEVFusion,它是基于多模态 BEV 感知的一个方法,我们代入刚才 BEV Fusion 算法的检测流程来看 BEVFusion 框架是不是符合我们的讲解,BEVFusion 网络结构如下图所示:
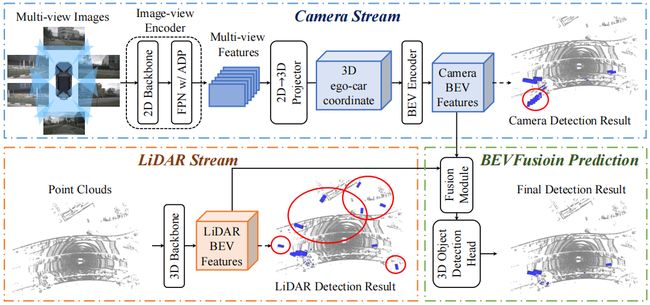
那看 BEVFusion 的框架首先看输入输出是什么,输入是一个多视角图像 Multi-view Images 和点云输入 Point Clouds,那也就是说 BEVFusion 是同时以图像和点云作为输入的,那输出是最终的检测结果 Final Detection Results
那我们再看看流程上符合融合 BEV 感知的定义吗,我们刚才归纳的是对 2D 图像特征和 3D 点云特征利用特定的融合模块进行处理可以得到最终的 BEV 特征,那我们再回到 BEVFusion 框架,其中的 2D 图像特征就是 Image-view Encoder 图像编码器,3D 点云特征就是 3D Backbone 骨干网络,所以说图中上半部分输出的 2D 图像特征和下半部分输出的 3D 点云特征会进行融合,那后续一系列的处理其实只是为了对多模态特征进行融合得到最终的 BEV 特征,我们这个流程的详细模块还是在后续课程中去做详细的讲解,这里就不展开讲了
OK!我们 1.4 小节的 BEV 感知方法的分类就讲到这里了,我们总结一下,我们主要介绍了三类的 BEV 感知方法,那 BEV LiDAR 是以纯点云作为输入的,BEV Camera 是以相机图像作为输入,BEV Fusion 是以一个多模态融合作为输出的,那也分别给大家举了一些比较经典的案例,包括 PV-RCNN、BEVFormer、BEVFusion 这些耳熟能详的算法,我们这里主要还是帮助大家去构建 BEV 感知算法的一个基本理解,有助于我们后续课程的学习
那我们这节内容就到此为止,我们接下来给大家分析一下 BEV 感知算法它到底有什么优劣
5. BEV感知算法的优劣
上一节内容我们对 BEV 感知算法进行了一个分类,对典型的算法进行了一些概念性的讲解,这节内容我们主要分析 BEV 感知算法的一个优劣,讨论 BEV 算法优劣之前我们先看下 BEV 视觉和传统的前置相机它到底有什么框架上的区别
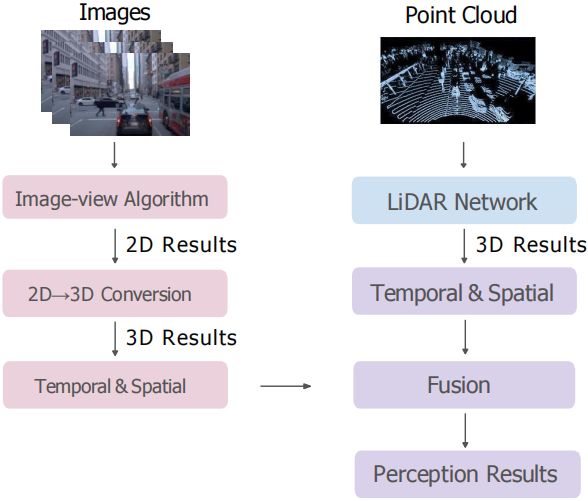

我们一再强调对入门而言看一个框架先看输入输出,那这里图 5-1 是我们常见的 3D 检测结构,图 5-2 是基于 BEV 感知算法的一个结构,那图 5-1 的输入输出是什么呢,输入是图像和点云或者两个的融合,输出是一个感知的结果,我们再看图 5-2 所讲的 BEV 感知算法的结构应该是什么样的,它的输入输出是什么呢,那同样输入也是图像或者点云或者两个的融合,输出还是一个 BEV 感知的结果,我们课程是以检测任务为例的,那 3D 场景还有很多任务包括 3D 分割,车道线检测等等,那这些任务的核心输入模块依旧是图像和点云,它只不过会针对这样不同的任务去设计不同的一个感知头去做后续的处理
OK,我们回到 3D 检测任务当中,我们看一下两种框架的功能是一样的,那它们两种方法的主要区别在哪儿呢,我们还是从流程上看,通用的 3D 检测结构可以以图像为输入,以点云为输入或者融合输入,以图像为输入通过的是图像特征提取网络,以点云为输入通过的是点云提取网络,通常点云提取框架一般是以体素的方法提取特征,那就是稀疏卷积,或者以点特征提取的方式得到一个 3D 特征,如果是融合的框架,两类特征它都是提取的,会得到一个多模态的特征,那这些特征要么是单一的可以得到 3D 检测结果,从图 5-1 可以看到图像支路是可以单一得到 3D 结果的,点云支路也是可以得到 3D 结果的,或者说两种方法去做一个融合,我们可以得到最终的一个感知结果
从上而下的流程是我们通用 3D 检测结构的一个完整流程,图像输入图像特征提取,我们可以得到结果,也可以将图像特征的结果与点云特征的结果去做一个融合,采用一些后处理或者融合的手段得到最终的输出,所以我们能看到无论是图像输入还是点云输入,通用的 3D 检测结构它都是可以直接得到 3D 检测结果的,那另外还有一点就是我们所提到的特征,无论是 2D 图像特征还是 3D 点云特征,一般是不太会经过一些复杂处理的,它是可以用来直接去做 3D 检测任务的,那我们接下来再看看 BEV 感知算法是怎么做的
同样它也是一个从上往下的一个结构,那对于图像支路而言,通过图像特征提取,对于点云支路而言,通过点云特征提取,提取图像特征是通过视角转换模块,我们可以将 2D 图像转换到 3D 下与点云去做一个融合,那这个融合一般是 BEV Features 级别的一个融合,是 BEV 特征的一个融合,后续可能会加上一些额外的时间或空间上的处理,然后得到最后的一个检测结果
那所以我们能看到的是通用的 3D 检测结构和 BEV 感知算法的结构有着明显的区别是什么呢?其实就是这个 BEV 特征的生成部分,那这是一系列 BEV 感知算法的核心内容,那为什么要做 BEV 视角下的感知呢?这就又回到了我们在第 1 小节 BEV 感知算法概念中介绍过的内容,我们再复习一遍
我们在讲概念的时候讲过我们在讨论什么是 BEV 感知算法之前是可以对 BEV 这个词做一个拆解的,那什么是 BEV 呢?那 BEV 空间其实是我们现在想要特别强调的一个空间,它翻译过来叫 Bird’s-Eye-View 鸟瞰图,那我们再通俗地表达一下其实就是俯视图,是一种从上往下的一个拍摄视角,很多算法当中会把它称之为上帝视角,那上帝能给我们带来什么好处呢,那这就是涉及到 BEV 视角空间能有一个什么样的优势了

首先 BEV 视角下尺度差异小,以上图为例,左边部分是正视图视角,右边部分是俯视图视角,在正视图视角下,我们能发现目标呈现远小近大的特点,离相机近的目标大,离相机远的目标小。那 BEV 视角物体长宽都差不多,所以尺度变化小,网络对于特征一致的目标的表达能力是更好的,所以 BEV 视角的尺度相对一致是具有明显的一个优势的。那第二点是 BEV 视角有一个比较小的遮挡,那其实这是一个很直观的理解,两辆车前后出现的时候,后面的车会被前面的车挡住,所以说这些其实是 BEV 感知算法一些显著的视觉上的优势
那对于自动驾驶而言呢,BEV 感知算法有什么意义呢?存在哪些不足呢?我们先来简单总结下
BEV 感知算法对于学术研究的意义:
- 有利于探讨 2D 到 3D 的转换过程
- 有利于利用视觉图像识别远距离物体或者颜色引导的道路
BEV 感知算法对工业应用的意义:
- 最显著的意义是降低成本。一套 LiDAR 设备的成本往往是视觉设备的 10 倍
性能差异:
- BEV感知算法在3D检测任务上,与现有的点云方案还有一定差距
首先从学术角度来讲,我们在讨论 BEV 感知算法流程的时候,我们不止一次的提到过 BEV 感知算法的核心是多视角转换模块,那也就是说我们如何利用多视角相机输入的 2D 图像生成对应的 BEV 视角结果,这个视角转换的过程非常非常重要,好的视角转换结果我们直接就可以带来后续检测任务性能上的一个提升,那所以说 BEV 感知算法对学术研究比较有意义的是它可以帮助我们理解 2D 外观输入如何到 3D 几何输入这样一个视图转换的过程
目前非常流行的 BEV 感知方案还是以纯视觉为主,也就是说我们采用图像输入为主,点云为辅这样的方式,那图像输入比点云输入的优势在于什么呢,显著的优势其实在于它有一个 RGB 的信息,有一个色彩的信息,比如在做车道线检测的时候,有黄色的,有白色的,那点云是没有办法分辨这些颜色信息的,这就是纯视觉感知的一个绝对性的优势
讨论完学术研究的意义之外呢,我们还想探讨一下目前的 BEV 感知算法对工业应用的一个意义,我们知道在常见的工业化生产环境中成本是第一考量的要素,那一套 LiDAR 设备成本是非常非常高的,它几乎是一个多视角相机的十倍左右,那十倍成本的下降这无疑对工业界诱惑是非常大的
那我们也不能忽略现在 BEV 感知算法会具有一个什么明显的问题,那就是性能差距还是比较大的,纯视觉的 BEV 感知算法性能是在 60 左右,比纯点云的 3D 检测器的性能会低 10 个点,那这是以当前的 NuScenes 数据集的结果来看的,所以从性能角度来讲 BEV 算法还是有着非常大的一个提升空间,也是后续我们无论是学术研究也好还是工业界的应用也好是可以持续挖掘的一个方向
最后我们总结一下,我们本节内容主要是从功能对比、流程对比的角度比较 BEV 感知算法和通用的 3D 检测算法的一个区别,其次,分析 BEV 空间具有显著的一个视觉优势,包括尺度变化小,遮挡小,另外纯视觉设备还具有一个明显的颜色优势和成本的优势,无论是从学术研究角度还是工业研究角度来讲,BEV 感知算法还是具有比较大的一个吸引力的,那尽管说纯视觉方案在性能上与纯点云的方案或者说融合的方案相比还有一定的差距,那我们也相信在后续的发展过程中纯视觉的 BEV 感知算法可以越做越好
我们刚刚提到既然工业界对这种成本较低的纯视觉 BEV 感知方案是非常感兴趣的,那它们有哪些具体的应用呢?那这里就进入到我们下一个小节 BEV 感知算法的应用介绍
6. BEV感知算法的应用介绍
从 1.1 节到 1.5 节我们对 BEV 感知算法的一个基本概念和基本流程做了一个详细解释,那在 1.6 节当中主要给大家介绍一下既然 BEV 感知算法这么火,那到底是谁在用呢
那 BEV 是我们一直在提的一个概念,叫鸟瞰图,用于描述我们感知到的现实世界,它的一个视角类似于一个上帝视角,那 BEV 感知算法是基于我们当前计算机视觉领域内的一种端到端的,由神经网络将图像信息从图像空间转换到 BEV 空间的一种技术
BEV 感知算法很主要的一个应用就是像我们现在常见的这种自动驾驶场景,我们知道在自动驾驶车上有很多的传感器,比如摄像头、毫米波雷达、激光雷达等等,在通用的自动驾驶系统里面,传统的图像空间感知方法是将汽车上的雷达、摄像头等不同传感器采集来的数据分别进行分析运算,然后再把各路分析结果融合到一个统一的空间坐标系,用于规划车辆的行驶轨迹
那在这个过程中,每个独立传感器收集到的数据和人眼类似,受特定视角的一个局限,那经过各自的分析运算之后,后处理融合阶段会有很多的误差叠加,很难精准的拼凑出我们道路的一个实况,给车辆决策规划会带来很严重的挑战
那 BEV 感知本身的好处就是它是一个从高处统观全局的上帝视角,车辆身上多个传感器采集到的数据会输入到一个统一模型去进行一个完整的推理,那这样生成的一个鸟瞰图也称为俯视图可以有效避免误差叠加的问题,那 BEV 方案同时还能支持时序融合,那也就是我们不仅收集我们当前时刻的数据去分析我们后续的轨迹运行,决策,我们还支持把过去一个时间片段当中的数据去融合进模型去做一个环境感知方面的建模,这样可以让系统感知很稳定,很精准,让车辆对道路的情况判断得很准确,也能让我们自动驾驶变得更安全
那从这个角度上来讲,我们的 BEV 感知算法是具有非常大的一个优势的,所以目前一些国内企业比如百度、滴滴等等,它们都组建了基于 BEV 感知的自动驾驶研发团队,那它们的一些资料其实我们是没有办法公开拿过来说的,那我们这里以三个我们可以公开获得方案的三家企业看看它们是怎么做 BEV 感知算法的,如下图所示:
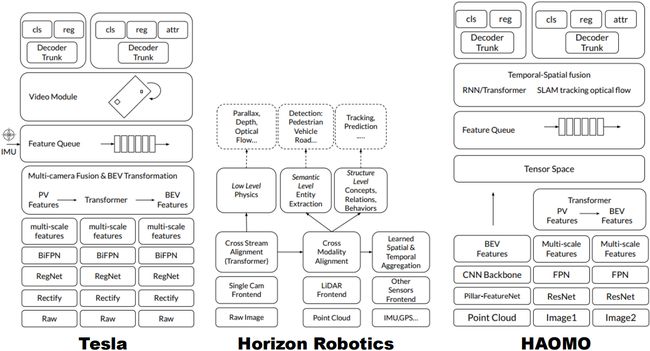
那这三家企业分别是特斯拉、地平线机器人、毫末智行,它们也是属于我们当前领域当中一些做得比较好的自动驾驶公司,我们说的 BEV 感知技术其实本身而言是特斯拉带火的,它作为业内纯视觉感知方案的鼻祖,其实很早就开始做 BEV 感知这件事情了,那我们先来看看特斯拉是怎么做的
与我们之前讲的通用 BEV 感知算法一个基础的设计流程都是一样的,无论是学术网络还是工业模型,我们看网络首先还是从输入输出看起,首先从输入开始,它是一个自下而上的一个结果,那这里的输入是原始的图像数据,通过一个图像校正模块,送入到 2D 图像特征提取网络,它的特征提取网络包含两个部分,一个是 RegNet,一个是 BiFPN。我们通过图像特征提取网络之后呢,可以得到图像级别的所对应的 multi-scale 的图像特征
那这里大家可能有个疑问,图像特征的提取为什么需要三条并行的结构呢?这三条并行的结构有没有什么区别呢?那我们知道特斯拉车身上其实有多个摄像头和毫米波雷达,它在做感知任务的时候需要把不同传感器的感知数据收集并融合起来才能得到最后的感知结果,不过特斯拉车上不同位置的摄像头参数是不一样的,相机的内外参数是不同的,那包括焦距、视野宽度、感受野等等都是不相同的,所以导致同一个物体在不同相机里面是不一样的,那所以说我们不能只从单一的相机当中去处理图像数据,而需要对不同相机的图像数据进行分开处理,那所以我们这里提到的三条并行的图像数据输入其实就是包含了不同位置摄像头拍摄到的不同图像。
那以前特斯拉在没有做 BEV 感知技术之前在每个相机上单独进行感知再将不同相机感知的结果进行融合,那这种方式融合在哪做的呢,那这种方式其实跳过了中间部分,直接通过 2D 图像网络提取的特征得到最后的结果,那这种方式的融合其实是非常困难的,因为不同的相机感知结果进行融合需要大量的超参,写起来非常复杂,并且由于深度估计的误差最终的输出结果可能会相互冲突,所以导致各特征结果并不好融合。
另外一个就是说图像空间的输出对于后续检测任务来说并不是很友好,我们现在只能用到的检测结果,而并不能使用我们在检测过程中产生的特征,它没有办法去做一系列的比如说定位、轨迹预测等任务。另外还有个问题,那就是我们单个相机有时候很难看到一个物体的全貌,那比如说有些比较大面积的物体,大卡车之类的离我们非常近,很难用一个相机很清晰的把这个物体的全貌拍下来,所以说我们仅依靠单个相机去做检测是不准确的
为了解决这些问题,特斯拉提出的解决方案是添加了中间的模块,将我们得到的特征从图像空间映射到 BEV 空间,那相对而言,它做法其实也是一样,把多个视角的图像统一通过一个公共的特征提取器投影到统一的 BEV 空间当中,那所以 PV Features ➡ Transformer ➡ BEV Features 这个模块其实就是我们之前提到过很多次,View Transformation 的视角转换模块,那有了 BEV 特征之后,我们可以引入时序信息,引入空间信息等等来增强 BEV 特征,然后再得到输出结果,这样的输出结果其实是基于 BEV 感知下的输出结果,所以自然而然地也就避免了我们上面提到的融合困难、超参较多,产生误检、容易被遮挡、无法看到物体全貌等等一系列问题。
接着我们从地平线和毫末的角度来看下它们是怎么做 BEV 感知的,我们看到特斯拉的方案是纯视觉方案,它的输入只有图像输入,而地平线和毫末属于是融合类方案,同时采用图像和点云作为输入,那融合方案我们之前也提到过,同样也是利用特征转换的方式,可以将 3D 特征和 2D 特征统一映射到一个场景中,像地平线和毫末的方案也是如此。
那大家可能会说在地平线的方案中似乎没有看到 BEV 视角转换,它其实表达的比较隐晦,那我们可以看到图像输出之后得到图像特征,点云输出之后得到点云特征,它在 Cross Stream Alignment ➡ Cross Modality Alignment 用一个箭头表示从图像特征到点云特征的转换过程,也就是说从 2D 到 3D 的一个转换过程,那这个其实也就是我们提到的一个视角转换的过程,通过一个视角转换,我们把 2D 场景下的一些特征转换到 3D 场景下,再拍扁到 BEV 上就是我们的 BEV 感知结果了,那它只不过没有明确的写出来,我们可以合理的推测出来
最后毫末的方案也是将输入的 3D 点云通过一个主干网络得到 BEV 特征,图像 1 和图像 2 分别通过图像 2D 网络得到 Multi-scale Features 多视角图像特征,然后通过 Transformer 统一映射到 BEV 场景下得到 BEV 特征,我们将点云的 BEV 特征和图像的 BEV 特征统一映射到 Tensor Space 空间中就得到了点云和图像融合的方式,它这种思路是不是跟我们之前讲的 BEVFusion 的思路是类似的呢,我们提过 BEVFusion 是怎么做的呢,有一条支路提供点云特征,一条支路提供图像特征,通过一个额外的融合模块将点云特征和图像特征融合在一起,那毫末也是这样做的
我们总结一下,特斯拉也好,地平线也好,毫末也好,无论是哪家企业的自动驾驶方案其实都跳脱不出 BEV 感知算法的一个基本流程,那比如特斯拉是一个纯视觉方案,那纯视觉方案当中比较重要的模块是什么呢,视角转换模块,怎么把不同视角下的相机图像统一映射到 BEV 空间当中是我们需要研究的一个问题。那对于地平线和毫末这种采用多模态输入的方案而言,它们其实比较重要的也是视角转换,但它们除了视角转换之外,还需要设计额外的融合模块,去融合点云特征和图像特征,它们的这个思路其实可以归纳到我们的 BEVFusion 的思路当中
所以说我们提到过无论是哪家企业的自动驾驶方案都跳不出 BEV 感知的一个基本流程,只要我们把基本思路理解清楚,那各种工业方案其实也就是迎刃而解了。而这也是该课程开设的一个初衷,我们想对常见的基本感知算法,它的一个基本模块,基本方案,基本思路进行一个讲解,来帮助大家能够构建一个完整的 BEV 感知算法的一个逻辑体系
那课程结束之后,我们希望大家可以无论是学术的方案也好还是工业的方案也好,我们看一下基本流程就可以自动的把它归纳到某一种 BEV 感知框架当中
OK!我们这个章节就以比较主流的自动驾驶方案,以它们的案例为主来给大家介绍一下 BEV 感知算法在工业应用中是怎么做的,它的流程设计是什么样的,以什么输入,以什么输出
那我们下一节就主要给大家讲一些课程的一个框架配置和一些内容安排
7. 课程框架介绍与配置
进入我们第一章的最后一节内容,前面的小节主要是给大家构建了 BEV 感知算法的基本概念和主流框架,那大家也看到 BEV 感知算法是当前众多自动驾驶公司的研究热门,所以我们开设了这门课程,我们主要从 BEV 感知的基本模块,基本算法,实战应用等方面为大家系统的讲解 BEV 感知算法的基本架构,希望帮助大家可以尽快入门,也能尽早上手
那本次课程的整体框架如下图所示:

本次课程是划分为五个章节的,主要包括:
- 第一章 BEV感知算法介绍
- 主要是基础概念、基础流程等
- 第二章 BEV感知算法基础模块讲解
- 主要是视角转换、Transformer等基础模块
- 第三章 LiDAR和Camera融合的BEV感知算法
- 主要算法和其实战应用
- 第四章 基于环视Camera的BEV感知算法
- 主要算法和其实战应用
- 第五章 BEV感知算法实战介绍
- 自己动手搭建一个感知网络
第一章是 BEV 感知算法的概念介绍,是我们目前所讲的从 1.1 到 1.7 小节的内容,那我们主要介绍了有关的基础概念来构建大家对于 BEV 感知算法它的一个基本流程的认识,除此之外,我们还介绍了一些通用数据集,典型的应用等等
第二章我们主要是围绕当前 BEV 感知算法当中通用的基础模块去进行一个讲解,我们在前几节中一再强调 BEV 感知算法的核心是视角转换模块,因此我们这里对 基本的视角转换方法做了详细的说明和讲解,包括从 2D 到 3D,从 3D 到 2D 的视角转换,我们均做了详细的讲解。除了视角转换模块,Transformer 也是 BEV 感知算法当中不可或缺的一环,因此课程也单独对 Transformer 进行一个分析,并且特别针对 BEV 感知算法场景下的 Transformer 进行一个讲解,那也就是说我们在 BEV 感知算法当中 Transformer 一般是怎么做的
那对基本流程、基本概念和基本模块有了了解之后,我们可以进一步深入学习完整的 BEV 感知框架是怎么做的,我们在第一章 1.4 小节 BEV 感知算法分类当中也提到当前的 BEV 感知算法可以划分为 BEV-LiDAR 纯点云方案,BEV-Camera 纯视觉方案以及 BEV-Fusion 多模态融合方案,那其中纯点云方案与通用的 3D 架构没有什么太大的区别,所以我们仅在第一章选取了非常具有代表性的 PV-RCNN 去进行了一个讲解
本次课程还是主要围绕 BEV-Camera 和 BEV-Fusion 的方案展开,去给大家详细介绍一下后面这两种方法是怎么做的,也就是纯视觉方案和多模态融合的方案是怎么做的
那所以第三章我们主要介绍 BEV-Fusion 的方案,选取了典型的框架 BEV-SAN 和 BEVFusion,分别利用两个小节对这两个方法做详细的分析,此外,还有针对实验设置中的一些问题,数据集的评价指标也将做进一步的解释说明。那在第三章的最后,我们对代表性的方案 BEVFusion 去做一个实战的讲解,我们对其中重要的代码模块、环境配置方案、训练过程、可视化结果去进行讲解
第四章是我们课程的一个重点,我们主要讲解基于环视视觉方案的 BEV 感知算法,纯视觉方案成本非常低,它受到非常多的自动驾驶公司的青睐,我们认为这也是今后自动驾驶发展的一个很重要的方向,所以我们这里将视觉方案做一个重点,我们会讲解 7 种主流的 BEV 感知方案,包括基础方案和其进阶的版本,比如 BEVFormer 和 BEVFormerv2,还有 BEVDet 和 BEVDet4D 等等,同样在最后我们对其中非常具有代表性的纯视觉方案 BEVFormer 有一个实战的介绍,包括 BEVFormer 代码中的一些重要模块,如何训练 BEVFormer,它的数据处理流程是怎么样的,它的训练过程又是怎么样的,还有一些可视化结果去进行分析讲解
那经过前四章的学习,我们认为大家已经对 BEV 感知算法中涉及到的基本流程有了一个清楚的认知,所以我们在第五章设计了一个独立的大作业模块去让大家自己学着去设计一套完整的 BEV 感知算法方案,来处理后续的 3D 检测任务
本次课程还是围绕 BEV 感知算法展开的,内容非常丰富,包括算法讲解、实战应用等等,也欢迎大家可以一起来学习讨论
总结
那第一章的内容学习完之后,我们能回答出三个问题就行,What、Why and How
1. BEV感知是什么?
BEV,全称 Bird’s-Eye-View 鸟瞰图也叫俯视图,我们称之为上帝视角
2. 为什么要做BEV感知?
即 BEV 感知的优势,尺度变化小,遮挡小
3. BEV感知怎么做?
即 BEV 感知的方案,以 PV-RCNN 为代表的 BEV-LiDAR 纯点云方案,以 BEVFormer 为代表的 BEV-Camera 纯视觉方案,以及以 BEVFusion 为代表的 BEV-Fusion 多模态融合方案
我们在第一章的课程中一再强调 BEV 感知中的核心模块是视角转换模块,因此下一章节我们会讲解 BEV 感知中的一些基础模块,并着重讲解其中的视角转换模块,敬请期待
下载链接
- 论文下载链接【提取码:6463】
- 数据集下载链接【提取码:data】
参考
- [1] Li et al., Delving into the Devils of Bird’s-eye-view Perception: A Review, Evaluation and Recipe.
- [2] Shi et al., PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
- [3] Li et al., BEVFormer: Learning Bird’s-Eye-View Representation from Multi -Camera Images via Spatiotemporal Transformers
- [4] Liang et al. Bevfusion: A simple and robust lidar-camera fusion framework