SeaTunnel下载安装与使用
目录
1 SeaTunnel简介
1.1 SeaTunnel概述
1.2 SeaTunnel作用
1.3 SeaTunnel特点
2 SeaTunnel安装与使用
2.1 SeaTunnel安装
2.2 SeaTunnel使用
1 SeaTunnel简介
1.1 SeaTunnel概述
SeaTunnel是一个简单易用的数据集成框架,可运行于自身引擎或架构于Apache Spark 和 Apache Flink之上。数据集成是把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享。SeaTunnel支持海量数据的实时同步。它每天可以稳定高效地同步数百亿数据。SeaTunnel的前身是Waterdrop(中文名:水滴)自2021年10月12日更名为SeaTunnel。
1.2 SeaTunnel作用
SeaTunnel专注于数据集成和数据同步,主要针对解决数据集成领域的常见问题:
各种数据源:有数百个常用数据源,其版本不兼容。随着新技术的出现,更多的数据源正在出现。用户很难找到能够完全快速支持这些数据源的工具。
复杂同步场景:数据同步需要支持离线-全量同步、离线-增量同步、CDC、实时同步、数据库全量同步等多种同步场景。
资源需求高:现有的数据集成和数据同步工具往往需要大量的计算资源或JDBC连接资源来完成海量小表的实时同步。这在一定程度上加重了企业的负担。
缺乏质量和监控:数据集成和同步过程经常会遇到数据丢失或重复的情况。同步过程缺乏监控,无法直观地了解任务过程中数据的真实情况。
复杂的技术栈:企业使用的技术组件不同,用户需要针对不同的组件开发相应的同步程序来完成数据集成。
管理和维护难度大:受限于不同的底层技术组件(Flink/Spark),离线同步和实时同步往往分开开发和管理,增加了管理和维护的难度。
SeaTunnel的日常使用,就是编辑配置文件。编辑好的配置文件由SeaTunnel运行在自身引擎或Spark Flink任务引擎中。
SeaTunnel工作流程如图所示。

1.3 SeaTunnel特点
丰富且可扩展的连接器:SeaTunnel 提供了一个不依赖于特定执行引擎的连接器 API。基于此 API 开发的连接器(源、转换、接收器)可以在许多不同的引擎上运行,例如当前支持的 SeaTunnel 引擎、Flink、Spark。
连接器插件:插件设计允许用户轻松开发自己的连接器并将其集成到 SeaTunnel 项目中。目前,SeaTunnel已经支持100多个连接器,而且数量还在激增。有列表 当前支持的连接器
批量流集成:基于 SeaTunnel 连接器API开发的连接器,完美兼容离线同步、实时同步、全同步、增量同步等场景。它大大降低了管理数据集成任务的难度。
多引擎支持:SeaTunnel 默认使用 SeaTunnel 引擎进行数据同步。同时,SeaTunnel 还支持使用 Flink 或 Spark 作为连接器的执行引擎,以适应企业现有的技术组件。SeaTunnel 支持多个版本的 Spark 和 Flink。
JDBC多路复用,数据库日志多表解析:SeaTunnel支持多表或全数据库同步,解决了JDBC连接过多的问题;支持多表或全库日志读写解析,解决了CDC多表同步场景重复读取解析日志的问题。
高吞吐、低时延:SeaTunnel支持并行读写,提供稳定可靠的数据同步能力,高吞吐、低时延。
完善的实时监控:SeaTunnel支持数据同步过程中每个步骤的详细监控信息,让用户轻松了解同步任务读写的数据数量、数据大小、QPS等信息。
SeaTunnel 设计的核心是利用设计模式中的“控制翻转”或者叫“依赖注入”,主要概括为以下两点:
1.上层不依赖底层,两者都依赖抽象;
2.流程代码与业务逻辑应该分离。整个数据处理过程,大致可以分为以下几个流程:输入 -> 转换 -> 输出,对于更复杂的数据处理,实质上也是这几种行为的组合:

Env配置参数:
JobEnvConfig | Apache SeaTunnel
env : 用于添加一些引擎可选参数,无论哪个引擎(自身引擎或者Spark、Flink),此处都可以填写相应的可选参数。
Source支持插件及配置信息:
Source(V2) of SeaTunnel | Apache SeaTunnel
Source: 用于定义SeaTunnel需要从哪里获取数据,并将获取的数据用于下一步。可以同时定义多个源。每个源都有自己的特定参数来定义如何获取数据,SeaTunnel还提取了每个源将使用的参数,例如result table_name参数,用于指定当前源生成的数据的名称,方便其他模块后续使。
Transform支持插件及配置信息:
Transform V2 of SeaTunnel | Apache SeaTunnel
Transform:用来处理从源端获取的数据,也可不定义不做处理。
Copy:对列进行复制;
FieldMapper:对列进行重命名
FilterRowKind:对行类型进行过滤
include_kinds [array]:[] 中的数据操作类型进行下一步写入
exclude_kinds [array]:[] 中的数据操作类型不进行进行下一步写入
Filter:字段过滤,重新选择输出字段
Replace:对字段中的字符串进行替换
Split:字符串切分
SQL Functions:常用的sql函数
SQL UDF:sql自定义函数
SQL:sql语句
Sink插件及配置信息:
Sink(V2) of SeaTunnel | Apache SeaTunnel
Sink:用于定义SeaTunnel需要把数据写到哪里。
其他:当定义多个源、转换时,每个源和转换读取哪些数据,我们需要使用result_table_name和source_table_name两个键配置,每个源端将配置一个result_table_name,以指示生成的数据源的名称,其他转换和接收模块可以使用source_table_name来引用对应的数据源名称,表明我要读取数据进行处理,然后transform作为一个中间处理模块,可以同时使用result_table_name和source_table_name配置。在SeaTunnel中,有一个默认约定,如果没有配置这两个参数,那么将使用前一个节点的最后一个模块生成的数据。
常见错误快速参考文档:
Error Quick Reference Manual | Apache SeaTunnel
2 SeaTunnel安装与使用
2.1 SeaTunnel安装
安装jdk(需JDK1.8及以上)
seatunnel官网
https://seatunnel.incubator.apache.org/download
下载seatunnel安装包
解压下载好的tar.gz包
tar -zxvf /opt/software/apache-seatunnel-2.3.2-bin.tar.gz -C ./从 seatunnel v2.2.0开始,二进制包默认不提供连接器依赖,所以第一次使用时,我们需要下载连接器。
在 ${seatunnel_home}/config/plugin_config 文件中指定下载哪些连接器,我们可以修改这个配置指定下载对应的连接器,连接器会下载到这个目录下${seatunnel_home}/connectors/seatunnel/ 中。

下载脚本

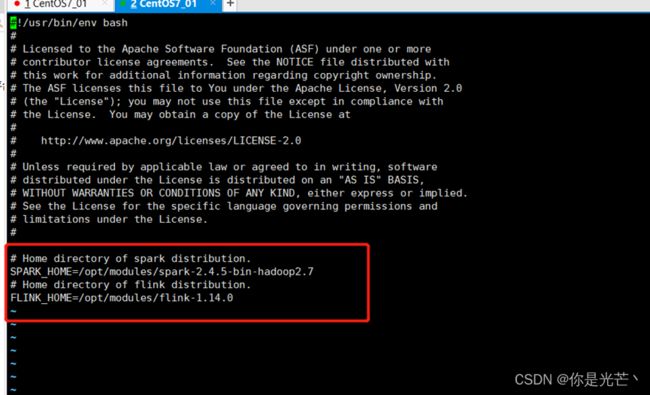
SeaTunnel的spark/flink依赖环境配置
在seatunnel安装目录下的 config/目录中有一个seatunnel-env.sh脚本。
这个脚本中声明了SPARK_HOME和FLINK_HOME两个路径。默认情况下seatunnel-env.sh中的SPARK_HOME和FLINK_HOME就是系统环境变量中的SPARK_HOME和FLINK_HOME,我们修改为自己的spark或者flink路径即可:
注意: Flink version >= 1.12.0
Spark version >= 2.4.0
2.2 SeaTunnel使用
cd ${seatunnel_home}/bin目录下查看Seatunnel使用的脚本
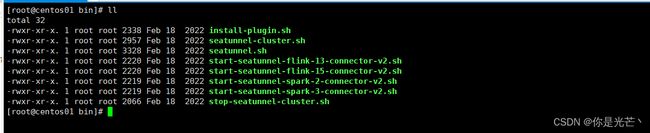
install-plugin.sh --安装连接器脚本
seatunnel-cluster.sh -–集群模式启动脚本
seatunnel-cluster.sh --本地模式启动脚本
start-seatunnel-flink-13-connector-v2.sh –-flink1.2-1.4版本引擎启动脚本
start-seatunnel-flink-15-connector-v2.sh –-flink1.5-1.6版本引擎启动脚本
start-seatunnel-spark-2-connector-v2.sh –-saprk2.x版本引擎启动脚本
start-seatunnel-spark-3-connector-v2.sh –-saprk3.x版本引擎启动脚本
stop-seatunnel-cluster.sh -–集群模式关闭脚本示例1: SeaTunnel 快速开始
1.选择任意路径,创建一个文件。这里我们选择在SeaTunnel的config路径下创建一个example01.conf
vi config/example01.conf
env {
execution.parallelism = 1
job.mode = "BATCH"
}
source {
FakeSource {
result_table_name = "fake"
row.num = 16
schema = {
fields {
name = "string"
age = "int"
}
}
}
}
transform {
}
sink {
Console {}
}
使用本地模式运行该程序并查看结果
./bin/seatunnel.sh --config ./config/example01.conf -e local

使用flink引擎运行该程序并查看结果
./bin/start-seatunnel-flink-13-connector-v2.sh --config ./config/example01.conf

使用spark引擎运行该程序并查看结果
./bin/start-seatunnel-spark-2-connector-v2.sh --master local[4] --deploy-mode client --config ./config/example01.conf

配置文件可以在本地引擎、flink、spark引擎上同时运行。
示例2 mysql to console
vi config/example02_mysql_to_console.conf
env {
execution.parallelism = 2
job.mode = "BATCH"
checkpoint.interval = 10000
}
source{
Jdbc {
url = "jdbc:mysql://192.168.110.31:3306/school"
driver = "com.mysql.cj.jdbc.Driver"
user = "wushuai"
password = "199511"
query = "select * from student"
}
}
transform {
}
sink {
Console {
}
}
./bin/seatunnel.sh --config ./config/example02_mysql_to_console.conf -e local

示例3 mysql to mysql insert模式
将 school.student的数据写入student.student表中
vi config/example03_mysql_insert.conf
env {
execution.parallelism = 2
checkpoint.interval = 10000
}
source {
jdbc {
url = "jdbc:mysql://192.168.110.31:3306/school"
driver = "com.mysql.cj.jdbc.Driver"
user = "wushuai"
password = "199511"
query = "select * from student"
}
}
transform {
}
sink {
jdbc {
# 这里配置driver参数,否则数据交换不成功
driver = "com.mysql.cj.jdbc.Driver"
url = "jdbc:mysql://192.168.110.31:3306/student",
user = "wushuai",
password = 199511
query = "insert into student(id,name) values(?,?)"
}
}
./bin/start-seatunnel-flink-13-connector-v2.sh --config ./config/example03_mysql_insert.conf
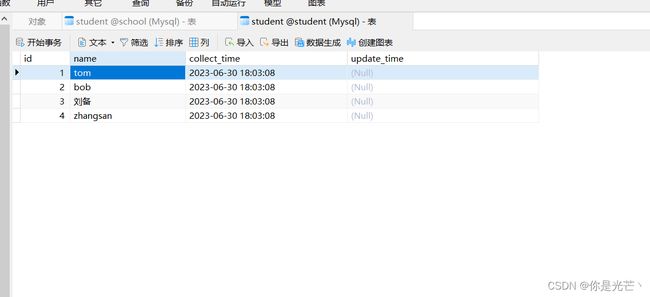
示例4 mysql to mysql update模式
vi config/example04_mysql_update.conf
env {
execution.parallelism = 2
checkpoint.interval = 10000
}
source {
jdbc {
url = "jdbc:mysql://192.168.110.31:3306/school"
driver = "com.mysql.cj.jdbc.Driver"
user = "wushuai"
password = "199511"
query = "select * from student"
}
}
transform {
}
sink {
jdbc {
# 这里配置driver参数,否则数据交换不成功
driver = "com.mysql.cj.jdbc.Driver"
url = "jdbc:mysql://192.168.110.31:3306/student",
user = "wushuai",
password = "199511"
saveMode = "update",
#dbTable = "tableName",
query = "insert into student(id,name) values(?,?) on duplicate key update name=ifnull(VALUES (name), name)"
#customUpdateStmt = "INSERT INTO student (id,name) values(?, ?) ON DUPLICATE KEY UPDATE id = IFNULL(VALUES(id), id), column2 = IFNULL(VALUES (name), column2)"
#query = "insert into student(id,name) values(?,?)"
}
}
./bin/start-seatunnel-spark-2-connector-v2.sh --master local[4] --deploy-mode client --config ./config/example04_mysql_update.conf

示例5 clickhouse to mysql update模式
vi example05_ck_to_mysql_update.conf
env {
execution.parallelism = 2
checkpoint.interval = 10000
}
source {
Clickhouse {
host = "centos01:8123"
database = "school"
sql = "select * from student "
username = "default"
password = "199511"
result_table_name = "school_1"
}
}
transform {
Replace {
source_table_name = "school_1"
result_table_name = "school_3"
replace_field = "name"
pattern = "_"
replacement = "@"
replace_first = true
is_regex = true
}
}
sink {
jdbc {
source_table_name = "school_3"
# 这里配置driver参数,否则数据交换不成功
driver = "com.mysql.cj.jdbc.Driver"
url = "jdbc:mysql://192.168.110.31:3306/student",
user = "wushuai",
password = "199511",
saveMode = "update",
#dbTable = "tableName",
query = "insert into student(id,name,sex,age) values(?,?,?,?) on duplicate key update name=ifnull(VALUES (name), name),sex=ifnull(VALUES (sex), sex),age=ifnull(VALUES (age), age)"
}
}
将clickhouse数据库下的student表插入更新到mysql数据库下,若姓名中有 “_”则替换为“@”。
Clickhouse数据库数据
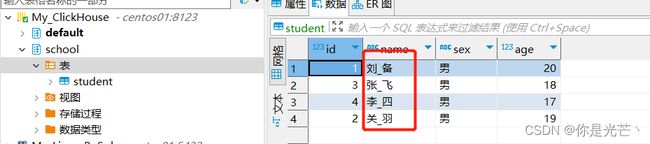
Mysql数据库数据
