NoSQL_Redis
不定期补充、修正、更新;欢迎大家讨论和指正
目录
- 前言
-
- 数据库架构演变
- NoSQL
- 分布式
-
- CAP
- BASE
- Redis
- 环境搭建
- 数据类型
- 配置文件
- 持久化
-
- RDB
- AOF
- 对比
- 淘汰策略
- 事务
- 主从复制
-
- 哨兵模式
- 去中心化
- 集群
- 缓存穿透、击穿、雪崩
- 消息订阅发布
- Jedis
-
- SpringBoot整合Redis
- Another Redis Desktop Manager
- Redis挖矿病毒
前言
数据库架构演变
- 单机MySQL的美好年代
在90年代,一个网站的访问量一般都不大,用单个数据库完全可以轻松应付。 在那个时候,更多的都是静态网页,动态交互类型的网站不多,所以大多都是使用简单的垂直MVC单点架构。
我们来看看数据存储的瓶颈是什么?
1.数据量的总大小 一个机器放不下时
2.数据的索引(B+Tree)一个机器的内存放不下时
3.访问量多了,一个数据库实例性能很低,容易崩溃(读写混合)。
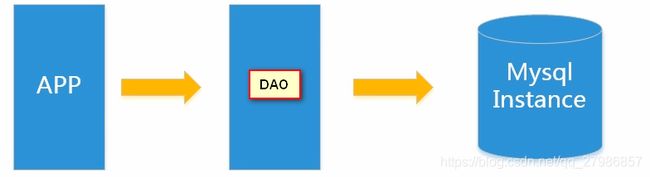
- Memcached(缓存)+MySQL+垂直拆分
后来,随着访问量的上升,几乎大部分使用MySQL架构的网站在数据库上都开始出现了性能问题,web程序不再仅仅专注在功能上,同时也在追求性能。程序员们开始大量的使用缓存技术来缓解数据库的压力,优化数据库的结构和索引。开始比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大的时候,多台web机器通过文件缓存不能共享,大量的小文件缓存也带来了比较高的IO压力。在这个时候,Memcached就自然的成为一个非常受欢迎的技术产品。 Memcached作为一个独立的分布式的缓存服务器,为多个web服务器提供了一个共享的高性能缓存服务,在Memcached服务器上,又发展了根据hash算法来进行多台Memcached缓存服务的扩展,然后又出现了一致性hash来解决增加或减少缓存服务器导致重新hash带来的大量缓存失效的弊端
但依然存在些问题:
1.缓存只能缓解读取压力,数据库的写入压力还是很大
2.且随着数据量的继续增大,性能还是很缓慢

- Mysql主从读写分离
由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。Mysql的master-slave模式成为这个时候的网站标配了。
主从复制就是将数据库分为主数据库和次数据库,每当主数据库操作时,次数据库也会进行同样操作,两者的数据内容一致,并相当于备份保证数据安全。
读写分离是在主从复制的基础上,读取时只对次数据库读取,写入操作只对主数据库操作。

- 分表分库+水平拆分+mysql集群
在Memcached的高速缓存,MySQL的主从复制,读写分离的基础之上,这时MySQL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM引擎使用表锁,在高并发下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM引擎。同时,开始流行使用分表分库来缓解写压力和数据增长的扩展问题。这个时候,分表分库成了一个热门技术。也就在这个时候,MySQL推出了还不太稳定的表分区,这也给技术实力一般的公司带来了希望。虽然MySQL推出了MySQL Cluster集群,但性能也不能很好满足互联网的要求,只是在高可靠性上提供了非常大的保证。
分表就是当一个表的数据非常多的时候,我们可以将其拆成多个表来分散数据。
分库就是将表中的部分数据拿出来放到其他的数据库中。
将数据横向切一刀,分成多份,放到其他表的其他库中,就是水平差分,同时多个库也要实现读写分离和主从复制,就形成了MySQL的集群。
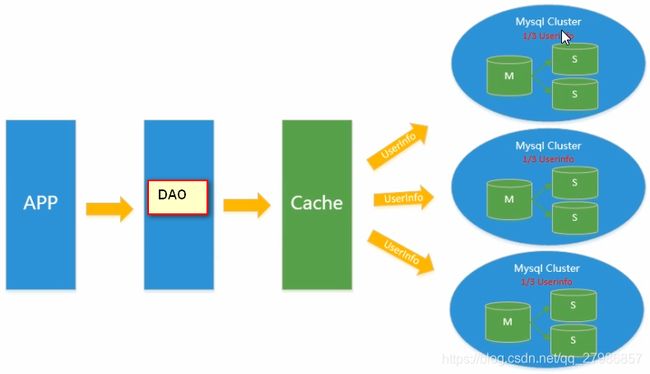
- MySQL扩展性瓶颈
MySQL数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。比如1000万4KB大小的文本就接近40GB的大小,如果能把这些数据从MySQL省去,MySQL将变得非常的小。关系数据库很强大,但是它并不能很好的应付所有的应用场景。MySQL的扩展性差(需要复杂的技术来实现),大数据下IO压力大,表结构更改困难,正是当前使用MySQL的开发人员面临的问题。
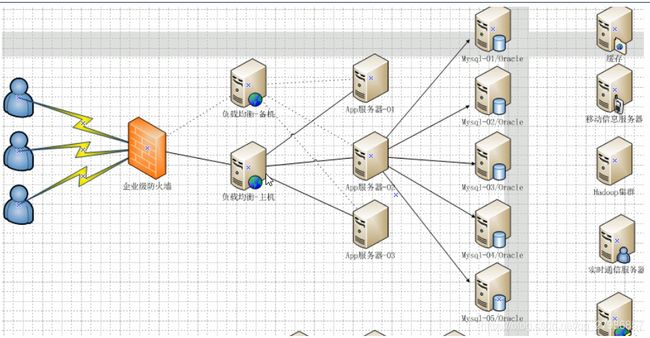
- NoSQL兴起(⭐)
随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题,因此非关系型的数据库因为其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,特别是大数据应用难题,即大数据时代特征的3V(海量Volume、多样Variety、实时Velocity)以及互联网需求的3高(高并发、高可扩、高性能)
NoSQL最常见的解释是“non-relational”, “Not Only SQL”也被很多人接受。NoSQL仅仅是一个概念,泛指非关系型的数据库,区别于关系数据库,它们不保证关系数据的ACID特性。NoSQL是一项全新的数据库革命性运动,其拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
对于NoSQL并没有一个明确的范围和定义,但是他们都普遍存在下面一些共同特征:
- 易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。无形之间,在架构的层面上带来了可扩展的能力。- 高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。一般MySQL使用Query Cache。NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说性能就要高很多。- 灵活的数据模型
NoSQL无须事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是——个噩梦。这点在大数据量的Web 2.0时代尤其明显。- 高可用
NoSQL在不太影响性能的情况,就可以方便地实现高可用的架构。比如Cassandra、HBase模型,通过复制模型也能实现高可用
传统RDBMS VS NoSQL
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- 键值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- CAP原则
- 高性能,高可用性和可伸缩性
目前数据库框架多以关系数据库和非关系数据库相结合来实现,以淘宝商品信息为例。
商品的基本信息,如名称、价格、生产厂商等这些比较固定的基本信息由关系型数据库如MySQL/Oracle存储
商品描述、详情、评价信息多文字类的数据以文档数据库(NoSQL的一种)如MongDB存储
商品的图片存储在分布式的文件系统中,如淘宝的TFS,Google的GFS
商品波段性的热点高频信息,由于经常查询一般放在缓存中,如Redis、MemCache
参考文章
数据库性能演变,NoSQL简介
数据库架构的演变
NoSQL
NoSQL可以分为四大类
以下均摘自百度百科
- 键值(Key-Value)存储数据库
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果数据库管理员(DBA)只对部分值进行查询或更新的时候,Key/value就显得效率低下了。举例如:Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB。 - 列存储数据库
这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。如:Cassandra, HBase, Riak. - 文档型数据库
文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可以看作是键值数据库的升级版,允许之间嵌套键值,在处理网页等复杂数据时,文档型数据库比传统键值数据库的查询效率更高。如:CouchDB, MongoDb. 国内也有文档型数据库SequoiaDB,已经开源。 - 图形(Graph)数据库
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。如:Neo4J, InfoGrid, Infinite Graph。
| 分类 | 软件 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value) | Tokyo Cabinet/Tyrant, Redis(⭐), Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase(⭐), Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDB(⭐) | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。 |
分布式
CAP
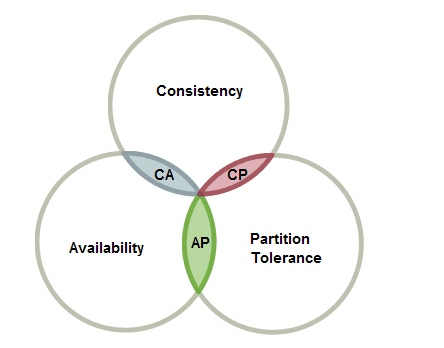
CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)
-
一致性(C):“all nodes see the same data at the same time”,即更新操作成功并返回客户端后,所有节点在同一时间的数据完全一致,这就是分布式的一致性。一致性的问题在并发系统中不可避免,对于客户端来说,一致性指的是并发访问时更新过的数据如何获取的问题。从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。
-
可用性(A):可用性指“Reads and writes always succeed”,即服务一直可用,而且是正常响应时间。好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。
-
分区容错性(P):即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务。
需要CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾
至于为什么不能三者兼顾,我们看以下的例子。
整个系统由两个节点配合组成,之间通过网络通信。
网络正常的情况下,A数据更新,B也可以马上更新,一致性满足;用户无论访问A还是B,请求都会很快得到回应,可用性满足;当某个节点宕机或者网络不通,用户依然可以访问另一个节点。
但分布式系统最大的问题就是网络传输问题,现在假设一种极端情况,A和B之间的网络完全断开,那么是什么情况呢。
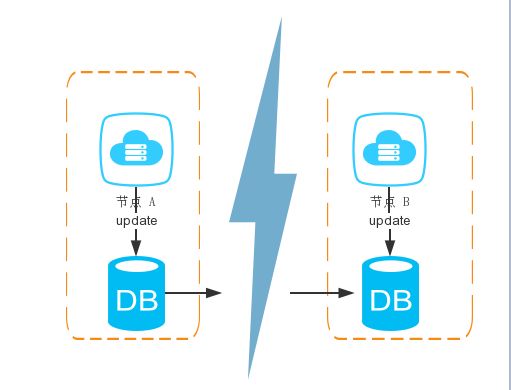
第一种情况,满足一致性和可用性;即需要数据一致,又需要能够及时响应用户请求,很显然这时A和B应该是个整体,所以分区性不能满足。
第二种情况,满足一致性和分区性;需要A和B的数据同步,同时A和B是两台不同服务器,那只有先等待网络通畅把数据更新后才能响应用户请求,所以得牺牲可用性。
第三种情况,满足可用性和分区行;即要尽快地响应用户请求,又需要A和B为两台不同服务器,那么一个节点的数据更新,另一个节点就不能够及时的更新数据,一致性得不到满足。
综上,CAP三个特性只能满足其中两个,那么取舍的策略就共有三种:
- CA,满足一致性和可用性,放弃P意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的。比如传统的RDBMS。
- CP,满足一致性和分区容错性,放弃可用性,所以用户体验和性能可能不会太好。设计成CP的系统其实不少,最典型的就是分布式数据库,如Redis、HBase等。对于这些分布式数据库来说,数据的一致性是最基本的要求,因为如果连这个标准都达不到,那么直接采用关系型数据库就好,没必要再浪费资源来部署分布式数据库。
- AP,满足可用性和分区容错性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。比如发微博,发评论,这些数据即使因为网络问题没办法及时确报数据一致性也不会造成太大影响,,目前大部分网络框架都是采用这种情况。又例如某米的抢购手机场景,可能前几秒你浏览商品的时候页面提示是有库存的,当你选择完商品准备下单的时候,系统提示你下单失败,商品已售完。这其实就是先在可用性方面保证系统可以正常的服务,然后在数据的一致性方面做了些牺牲,虽然多少会影响一些用户体验,但也不至于造成用户购物流程的严重阻塞。一些软件如CouchDB、Cassandra、DynamoDB符合AP特性。
难道真的没有办法解决这个问题吗?
CAP 理论已经提出了 13 年,也许可以做些改变。
仔细想想,分区是百分之百出现的吗?如果不出现分区,那么就能够同时满足 CAP。如果出现了分区,可以根据策略进行调整。比如 C 不必使用那么强的一致性,可以先将数据存起来,稍后再更新,实现所谓的 “最终一致性”。
这个思路又是一个庞大的问题,同时也引出了第二个理论 Base 理论。
参考文章
分布式CAP定理,为什么不能同时满足三个特性?
分布式理论(一) —— CAP 定理
BASE
BASE理论是Basically Available(基本可用),Soft State(软状态)和Eventually Consistent(最终一致性)三个短语的缩写。
它的思想是通过让系统放松对某一时刻数据一致性的要求来换取系统整体伸缩量和性能上的提高,例如双十一数据访问量极其庞大,淘宝可以暂时不要求访问量、点击量这些不太重要数据的及时更新,来保证核心功能基本可用,但是活动结束后这些数据还是要统计的。
基本可用(Basically Available)
- 分布式系统在出现故障时,允许损失 部分可用功能,保证核心功能可用。举例如下:
- 响应时间上的损失(可用,但查询比平时慢):正常情况下,搜索引擎会在0.5秒内返回查询结果给用户,但由于出现故障(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了1~2秒。
- 功能上的损失:在正常情况下,用户可以在一个电商网站上顺利完成每一笔订单。但是到了大促期间,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。比如:
软状态(Soft state):
- 软状态是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同的数据副本之间进行数据同步的过程存在延时。
最终一致性(Eventually consistent):
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
在实际工程实践中,最终一致性分为5种:
- 因果一致性(Causal consistency)
因果一致性指的是:如果节点A在更新完某个数据后通知了节点B,那么节点B之后对该数据的访问和修改都是基于A更新后的值。于此同时,和节点A无因果关系的节点C的数据访问则没有这样的限制。- 读己之所写(Read your writes)
读己之所写指的是:节点A更新一个数据后,它自身总是能访问到自身更新过的最新值,而不会看到旧值。其实也算一种因果一致性。- 会话一致性(Session consistency)
会话一致性将对系统数据的访问过程框定在了一个会话当中:系统能保证在同一个有效的会话中实现 “读己之所写” 的一致性,也就是说,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。- 单调读一致性(Monotonic read consistency)
单调读一致性指的是:如果一个节点从系统中读取出一个数据项的某个值后,那么系统对于该节点后续的任何数据访问都不应该返回更旧的值。- 单调写一致性(Monotonic write consistency)
单调写一致性指的是:一个系统要能够保证来自同一个节点的写操作被顺序的执行。原文分布式理论基础之BASE原则

Redis

Redis(Remote Dictionary Server,远程字典服务 ),是目前最火热的NoSQL之一。是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
官网:redis中文官方网站
关于Redis的命令不会一一学习,而是用到哪些才学习哪些,所以一些尽管很常用的命令不涉及的话也不学习,可以参考下面两篇文章
Redis 命令参考
redis常用命令
环境搭建
企业中Redis一般都是安装在Linux平台的,所以这里需要Linux的知识,大部分人电脑一般都是Win,也没有云服务器,所以可能还得捣鼓下VMware虚拟机装Linux,这些前置知识大家需要先熟悉。
Redis安装需要gcc版本高于5,先gcc -v 看看版本,
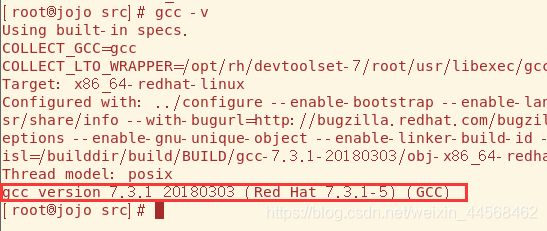
如果低于5,就得重装gcc
如果大家在centos7下编译redis6.0版本,如果出现以下错误
In file included from server.c:30:0:
server.h:1022:5: error: expected specifier-qualifier-list before ‘_Atomic’
_Atomic unsigned int lruclock; /* Clock for LRU eviction /
请先检查gcc的版本是否低于5,如果是请先升级,可以使用以下命令:
sudo yum install centos-release-scl
sudo yum install devtoolset-7-gcc
scl enable devtoolset-7 bash
接下来根据官方教程安装就行
$ wget http://download.redis.io/releases/redis-6.0.6.tar.gz
$ tar xzf redis-6.0.6.tar.gz
$ cd redis-6.0.6
$ make
安装后看到最后一行字提示你可以执行’make test’测试就算安装成功了,测试耗费时间比较长,可以自己弄弄
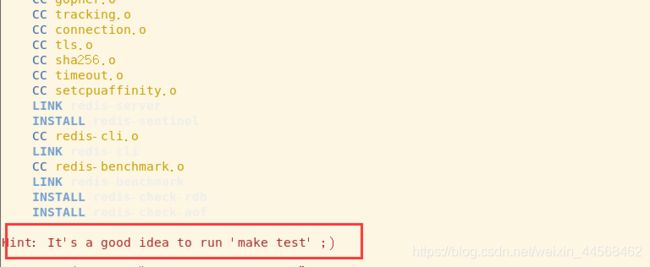
启动前先检查下防火墙有没有放行该服务,firewall-cmd --query-service=redis
![]()
如果没放行就就输入firewall-cmd --add-service=redis命令,或者firewall-config打开图形化界面勾选就行
进入到解压后的 src 目录,通过如下命令启动Redis:
$ src/redis-server
成功运行,但是服务器会一直占用前台,我们需要让它在后台运行(前台关闭服务器 Ctrl+c)
一种方法是在服务器在启动时后面加上&即 ‘redis-server &’,
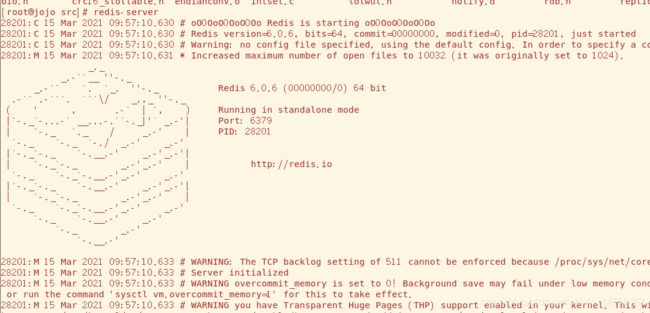
另一种是修改其配置文件redis.conf(在安装目录下,修改配置文件时记得备份一份,这是很必要的),将daemonize no 改为yes,启动服务器时指定配置文件


ps -ef | grep redis看看服务器是不是真的在启动

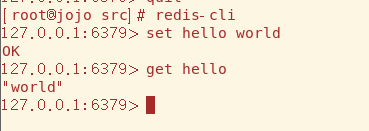
接下来就可以输入redis-cli用内置的客户端与Redis进行交互,后续的学习就在这里进行
(服务器现在跑到后台,可以通过ps找到服务器的PID 然后输入kill PID将进程终止,也可以在redis-cli里输入shutdown关闭服务器)
添加环境变量
为了后续方便使用,可以为Redis添加到环境变量,这样Redis相关的命令就不用跑到其安装目录下才能执行了(有些版本安装后会直接添加环境变量,这时就不用修改了),Linux配置环境变量有多种方式,这里在/etc/profile下修改
如下,将Redis可执行文件的所在目录路径添加在后面就行,多个环境变量之间用:隔开(切记$PATH别删掉了)

修改后需要执行source /etc/profile才能生效,这样子在其他目录一样可以直接输redis相关的命令了
添加到服务
Linux自身有服务管理功能,我们可以把redis相关的服务添加到Linux服务管理。
添加服务的脚本在Redis自身的utils目录里的redis_init_srcript,Redis已经写好了
![]()
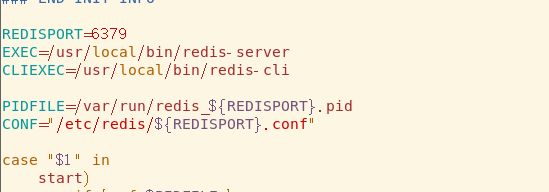
将它复制到/etc/init.d下,规范点命名为redis,打开看看脚本内容,这里声明了五个变量,例如EXEC找的是/usr/local/bin/redis-server,如果该路径下没有redis-server,那就得复制过去一份,当然也可以修改路径,我觉得复制轻松些,其他同理。
配置文件名这里${REDISPORT}表示取的REDISPORT值也就是6379,所以配置文件名不是redis.conf而要修改为6379.conf,觉得别扭就直接将CONF的值改为redis.conf
配置无误后就可以输入chkconfig --add redis将Redis添加到服务管理了。
CentOS中可以用service命令来管理服务,也可以用systemctl命令(7之后的的命令),个人比较喜欢后者



数据类型
Redis虽然是以键值对来存储数据,但是值可以有多种类型,常用的数据类型有五种
- String
- Hash
- List
- Set
- Zset
相关命令可以参考该网站,这里只使用一些常用的
Redis 命令参考
String
String相信大家都很熟悉,这种数据类型可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M
String类型的数据用set key value存储数据;用get key获取数据
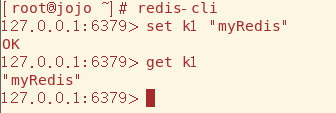
对于一个已经存在的key,对其再进行set操作,会覆盖原来的值(对于String类型数据,key和value加不加引号都行)
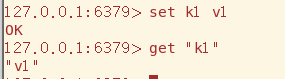
del命令用于删除key,这对后面的数据类型也是通用的
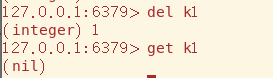
mset命令用于批量添加数据,mget命令用于批量获取数据

setex(expire)设置有过期时间的数据,单位为秒(Redis这点做的挺好,输入一个命令时就会动态显示用法)
![]()
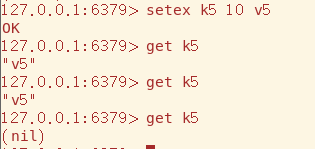
setnx命令在key存在时会返回int类型的0,不存在正常添加,该特性会运用在分布式锁上,十分重要
![]()
strlen命令用于获取该String的长度
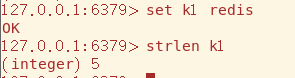
append命令在String后拼接数据
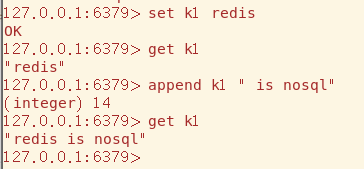
Hash
Hash类型数据就是Map,依然用key-value的形式来存储数据,所以就可以无限套娃了
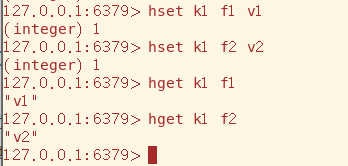
Hash用hset命令来设置数据,key为外部的键,由于value也是map,所以field为内部的key,为了方便区分用field来表示
![]()
hset命令来获取数据
![]()
hlen查看该key下field的个数
![]()
hkeys获取该key的所有field,hvals同理
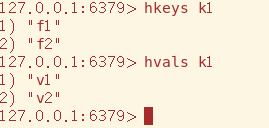
hgetall获取该key下Map的所有数据,奇数行为field,偶数行为该field的value

Hash适合存储对象
List
这里的List和Java的List并没有太大关系,更像的是双端队列Deque。
双端队列是一种可以两端存取的数据结构,根据特定的规则来存取数据就可以当作栈和队列使用
- 同侧存取:栈,比如从左向右存储数据,获取数据也从左侧完成,符合FILO
- 异侧存取:队列,比如从左向右存储数据,获取数据从右侧完成,符合FIFO

lpush从左端压入数据,rpush同理

我们可以通过lrang从左到右遍历出List指定范围内存放的数据

lpop从左端取出数据,rpop同理

现在来同侧存取来将List当作栈来使用
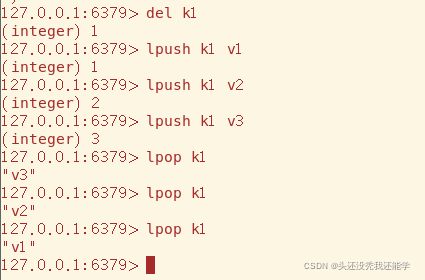
异侧存取当作队列

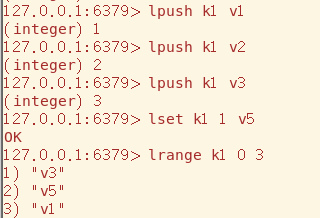
lset可以改变List中元素的值(从左向右看,下标从0开始)
![]()
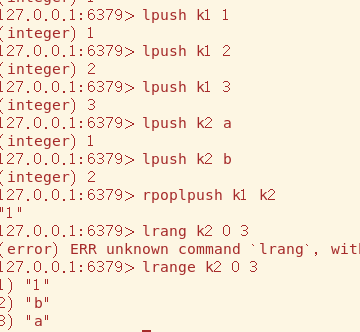
rpoplpush,从source队列的右端取出数据后压入destination队列的左端(没有lpoprpush)
![]()
List可用于最新消息排行等功能(比如朋友圈的时间线) 、消息队列等场景
Set
Set和Java的Set相似,数据不重复且存放无序
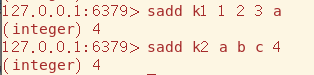
Set使用sadd添加数据(可以连续添加多个),使用spop获取数据,由于数据存放位置是不确定的(比如HashSet根据hashcode来决定存放位置),所以取出的数据也是随机的
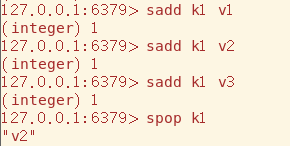
smembers用于查看Set中包含的元素

srem删除指定元素

Set元素唯一的性质提供了两个Set求交集、并集、差集的操作
-
sinter(交集)

-
sunion(并集)

-
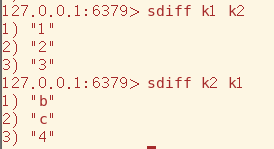
sdiff(差集):差集对于集合顺序的不同得到的结果也不同,这在高中数学学习过。
如果忘记简单来说就是(差集 集合1 集合2:集合1有而集合2没有的,或者集合1减去(集合1和集合2的交集))
Set的常用的用途有
- 共同好友
- 利用唯一性,统计访问网站的所有独立ip
- 好友推荐时,根据tag求交集,大于某个阈值就可以推荐
Zset
Sorted Set(有序集合),因为其命令都以z开头,所以也叫Zset。在Zset添加元素时需要提供一个float类型的score参数,这样元素在添加时就直接根据score进行排序了。
Zset中使用zadd添加元素,先要指定score才能指定value/member
![]()
zrange和lrange的作用相同,可以看到这些元素都是根据score来排序的

zscore查看value对应的score

zcard返回Zset元素的个数
![]()
zcount用于查询指定score范围内元素的个数
![]()
![]()
Zset可使用于排行榜 、带权重的消息队列场合
Redis除了提供在五种常用的数据类型,还提供了三种特殊的数据类型,自行了解
【Redis】三种特殊数据类型
配置文件
Redis配置文件就是安装目录下的redis.conf
Redis的配置文件有上千行(大多都是注释,真正的配置可能只有百个左右,也很多了),好在官方把配置分为了多个“模块”

后面用到哪些学习,详细讲占字数,自行了解
Redis详解(二)------ redis的配置文件介绍
redis配置文件中常用配置详解
持久化
Redis是一个内存数据库,也就是说所有的数据将保存在内存中,这与传统的MySQL、Oracle、SqlServer等关系型数据库直接把数据保存到硬盘相比,Redis的读写效率非常高。但是保存在内存中也有一个很大的缺陷,一旦断电或者宕机,内存数据库中的内容将会全部丢失。所以Redis提供了把内存数据持久化到硬盘文件,以及通过备份文件来恢复数据的功能:RDB快照文件和AOF。
RDB
RDB 即 Redis Database,是Redis的默认持久化方案,该方案会定期的将Redis中的数据写入到磁盘,生成一个当前时刻的快照文件(默认名为dump.rdb),我们称其为RDB文件。当Redis服务意外重启时,会读取最新的RDB文件,使用该文件恢复服务器中的数据
有关RDB的配置在Redis配置文件中的SNAPSHOTTING部分
################################ SNAPSHOTTING快照 ################################
#
# Save the DB on disk:
#
# save
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
# save参数是Redis触发自动备份的触发策略,seconds为统计时间(单位:秒), changes为在统计时间内发生写入的次数
# save m n的意思是:m秒内有n条写入就触发一次快照,即备份一次。
# save参数可以配置多组,满足在不同条件的备份要求。如果需要关闭RDB的自动备份策略,可以使用save ""
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
# 只要符合下面任意的条件,数据都会自动保存
# 15分钟内至少有一个key改变
# 5分钟内至少由十个key改变
# 一分钟内至少有一万个key改变
#
# Note: you can disable saving completely by commenting out all "save" lines.
# 提示:你可以将下面的save行注释来关闭保存功能,就是下面save 900 1那些
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
# 通过添加带有单个空字符串参数的save指令,也可以删除以前配置的所有保存策略,如以下示例所示:
#
# save "" # 将save ""的注释去掉也会让所有保存策略失效,即关闭保存功能
save 900 1
save 300 10
save 60 10000
# 默认的保存策略
# 这只是一部分后面还有
SNAPSHOTTING里还有几个配置,顺便学习完
stop-writes-on-bgsave-error:默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了。
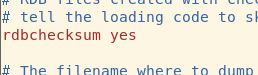
rdbcompression:默认值yes。备份数据时是否使用LZF算法压缩字符串对象。默认是开启的,这样可以节约存储空间,但是在生成备份文件时消耗部分CPU。
rdbchecksum:保存和加载rdb文件时是否使用CRC64校验,默认开启。启用此参数可以使rdb文件更加安全,提高稳定性,但是会有一定的性能(大约10%)损失。如果rdb文件创建时未使用校验和,那么校验和将被设置为0,以此告知Redis跳过校验。
快照的默认名字,dump.rdb
快照的默认保存路径,这里我改了




为了方便测试,我们可以修改保存策略,比如save 100 5(一百秒内key至少有5次变更),配置保存后别忘记重启服务器

![]()
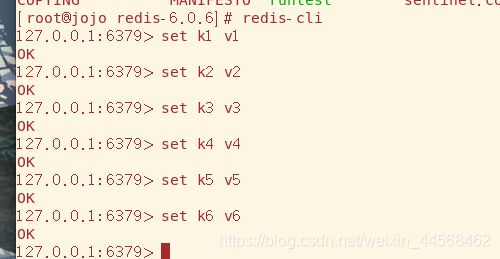
在redis-cli添加六个key
不一会就看到dump.rdb产生,dump.rdb默认的路径是和你redis-service同路径的,我觉得比较乱修改了默认路径
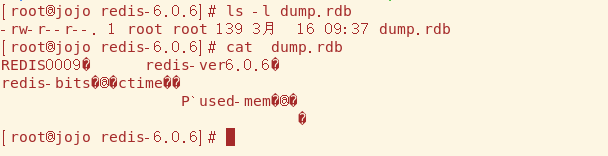
关闭redis-service,模拟服务器出故障,因为Redis是内存数据库,所以宕机后里面的数据应该是没有的
然而将服务器重启,还是能获取到之前的数据,说明数据确实持久化了
如果想手动备份直接输入save/bgsave(异步备份)命令就行
如果shutdown关闭服务器,也会自动备份数据,
值得注意的是如果你FLUSHALL清楚所有数据后,备份也是没数据的,因为FLUSHALL也算修改key

AOF
AOF(append only file),是将 redis 执行过的所有写指令(读指令没有对原数据进行修改,没有恢复的必要)记录下来,在下次 redis 重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了
AOF的配置内容在APPEND ONLY MODE内

Redis默认持久化策略是RDB,而AOF默认是关的,其默认保存的文件名为appendonly.aof

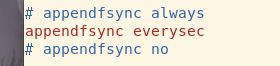
AOP提供三种不同的数据写入策略:
- appendfsync always;只有Redis有写命令就保存到磁盘,粒度最小,是最有保证的完全的持久化,显然性能也是最差的
- appendfsync everysec;每秒钟写入磁盘一次,也就是说如果服务器宕机那前一秒的数据可能会丢失,在性能和持久化方面做了很好的折中,默认策略
- appendfsync no;完全依赖OS的写入,一般为30秒左右一次,性能最好但是持久化最没有保证
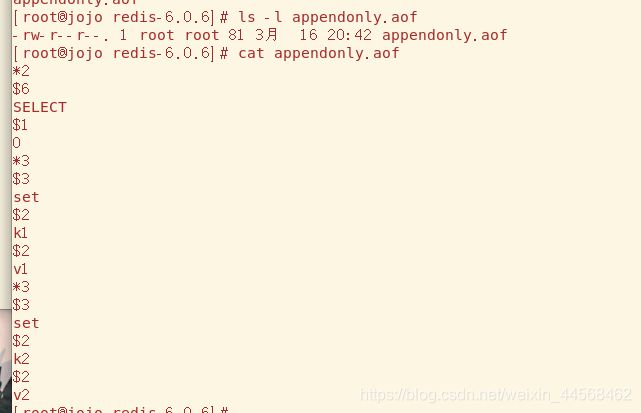
任意设置修改几个key,很快appendnoly.aof文件就生成了,里面的内容就是我们刚才的写操作
当服务器重新连接,它就会读取该文件并把所有指令重新执行一遍,以此来恢复数据
假设当服务器向appendonly.aof写入指令时出现故障,可能会造成文件损坏,这里模拟手动向后面输入乱码

同时Redis也会因为读取备份文件出问题连接失败

这里顺便提一下,现在AOF和RDB功能是都开启的,AOF备份的文件损坏导致Redis连接不上,说明Redis优先读取的是AOF的备份文件
根据官方文档所说的,AOF和RDB两种持久化策略是可以共存的,但是默认会先读取AOF的文件,因为AOF能更好地保证持久化

Redis提供文件修复工具,用redis-check-aof --fix命令就可以来修复破损的AOF文件了
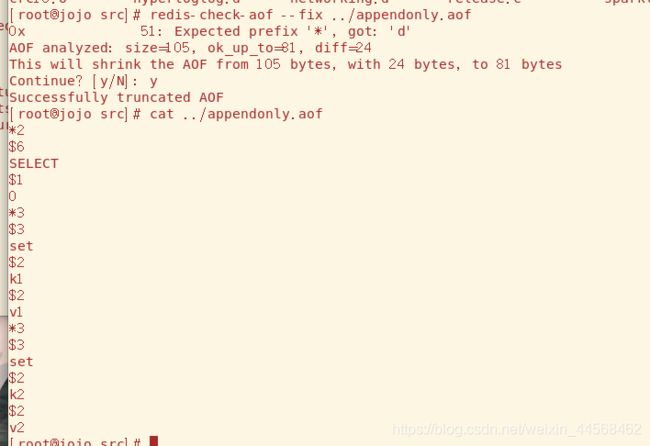
因为AOF采用文件追加地形式进行持久化,文件可想而知会随着时间越变越大,为了避免该情况提供重写机制,当文件大小到达一定阈值,Redis就会启动AOF生成地文件进行压缩,只保存足够恢复数据的最小指令集
以下为重写机制相关的配置
no-appendfsync-on-rewrite:在aof重写或者写入rdb文件的时候,会执行大量IO,此时对于everysec和always的aof模式来说,执行fsync会造成阻塞过长时间,因此no-appendfsync-on-rewrite字段设置为默认设置为no。如果对延迟要求很高的应用,这个字段可以设置为yes,否则还是设置为no,这样对持久化特性来说这是更安全的选择。 设置为yes表示rewrite期间对新的写操作不fsync,暂时存在内存中,等rewrite完成后再写入。

auto-aof-rewrite-percentage:默认值为100。aof自动重写配置,当目前aof文件大小超过上一次重写的aof文件大小的百分之多少进行重写,即当aof文件增长到一定大小的时候,Redis能够调用bgrewriteaof对日志文件进行重写。当前AOF文件大小是上次日志重写得到AOF文件大小的二倍(设置为100)时,自动启动新的日志重写过程。
auto-aof-rewrite-min-size:64mb。设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍然很小的情况还要重写。
比如说上一次AOF rewrite之后,是128mb
然后就会接着128mb继续写AOF的日志,如果发现增长的比例,超过了之前的100%,256mb,就可能会去触发一次rewrite
但是此时还要去跟min-size,64mb去比较,256mb > 64mb,才会去触发rewrite

对比
RDB
RDB持久化机制对redis中的数据执行周期性的持久化。
优点:
- 适合做冷备:RDB会生成多个数据文件,每个数据文件都代表了某一个时刻中redis的数据,这种多个数据文件的方式,非常适合做冷备。
- 读写服务影像小:RDB对redis对外提供读写服务的时候,影像非常小,因为redis 主进程只需要fork一个子进程出来,让子进程对磁盘io来进行rdb持久化
- 恢复速度更快:RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
缺点:
- 如果redis要故障时要尽可能少的丢失数据,RDB没有AOF好,例如1:00进行的快照,在1:10又要进行快照的时候宕机了,这个时候就会丢失10分钟的数据。
- RDB每次fork出子进程来执行RDB快照生成文件时,如果文件特别大,可能会导致客户端提供服务暂停数毫秒或者几秒
AOF
AOF持久化机制对每条写入命令作为日志,以append-only模式写入一个日志文件中,在redis重启的时候,可以通过AOF写入的指令来重新构建整个数据集。
优点:
- AOF可以更好的保护数据不丢失,一般AOF会以每隔1秒,通过后台的一个线程去执行一次fsync操作,如果redis进程挂掉,最多丢失1秒的数据。
- AOF以appen-only的模式写入,所以没有任何磁盘寻址的开销,写入性能非常高。
- AOF日志文件的命令通过非常可读的方式进行记录,这个非常适合做灾难性的误删除紧急恢复,如果某人不小心用flushall命令清空了所有数据,只要这个时候还没有执行rewrite,那么就可以将日志文件中的flushall删除,进行恢复。
缺点:
- 对于同一份文件AOF文件比RDB数据快照要大。
- AOF开启后支持写的QPS会比RDB支持的写的QPS低,因为AOF一般会配置成每秒fsync操作,每秒的fsync操作还是很高的
- 数据恢复比较慢,不适合做冷备。
参考文章
Redis持久化RDB和AOF原理以及优缺点
redis的 rdb 和 aof 持久化的区别
淘汰策略
当Redis的内存资源不足时,如果有新的数据需要存储,这时就要淘汰一些数据
Redis提供了以下淘汰策略(最新版本只有六种)

- volatile-lru:从已设置过期时间的数据集中挑选最近最少使用的数据淘汰。
- volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰。
- volatile-random:从已设置过期时间的数据集中任意选择数据淘汰。
- volatile-lfu:从已设置过期时间的数据集挑选使用频率最低的数据淘汰。
- allkeys-lru:从数据集中挑选最近最少使用的数据淘汰
- allkeys-lfu:从数据集中挑选使用频率最低的数据淘汰。
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据,这也是默认策略。意思是当内存不足以容纳新入数据时,新写入操作就会报错,请求可以继续进行,线上任务也不能持续进行,采用no-enviction策略可以保证数据不被丢失。
事务
关于事务的概念,什么ACID这里就不赘述了,Redis事务的命令如下
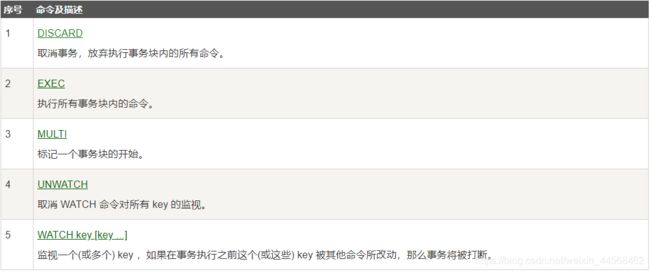
MULTI标志事务的开始,每输入一个命令如果成功都会返回QUEUED,最后输入EXEC逐条执行事务块中的每条命令,放弃事务则输入DISCARD
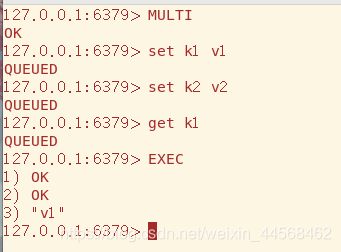
下面看一种情况,事务块中有条命令输入错误,那事务块所有命令都不会执行,意料之中

另一种情况,命令是正确的但是用法是错误的,k1的值是String类型,INCR只能自增Integer类型
结果是事务块能成功执行,所以Redis的事务并不是严格的事务,它只保证命令的原子性但不保证事务的原子性且没有回滚功能
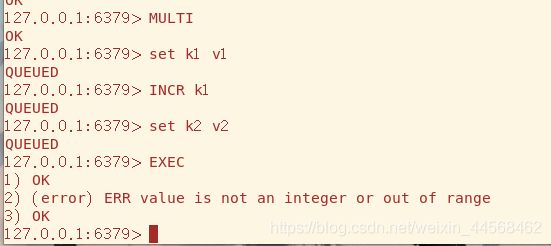

最后两个命令WATCH和UNWATCH,WATCH的作用是监视 key 是否被改动过,而且支持同时监视多个 key,只要还没真正触发事务,WATCH 都会尽职尽责的监视,一旦发现某个 key 被修改了,在执行 EXEC 时就会返回 nil,表示事务无法触发。它可以帮我们实现类似于“乐观锁”的效果,即CAS
对于悲观锁乐观锁不太了解的朋友可以看看这篇文章什么是乐观锁,什么是悲观锁

主从复制
在前面数据库演变时讲到,由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。Mysql的master-slave模式成为这个时候的网站标配了。同样的Redis也支持主从复制技术,主从复制最大的好处就是读写分离、容灾恢复。
实现主从复制技术还是相当容易的,但是细讲的东西也很多。
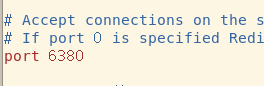
主从复制我们需要一台Master,两台Slave来进行模拟,开三台虚拟机电脑性能顶不住而且重新配置比较麻烦,我们以不同的端口来模拟不同的机器,其中默认端口6379为主,6380和6381为从。
只需要将Redis的配置文件复制一份,修改跟端口相关的配置就行

指定配置文件来启动服务器
![]()
redis-cli指定端口

ps -ef | grep redis可以看到三个端口的服务器和客户端口起来了,接下来就可以进行模拟了

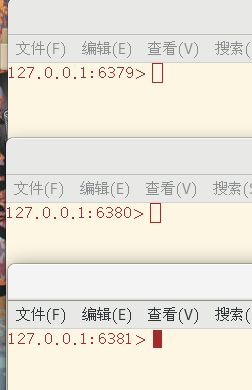
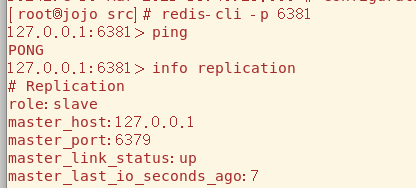
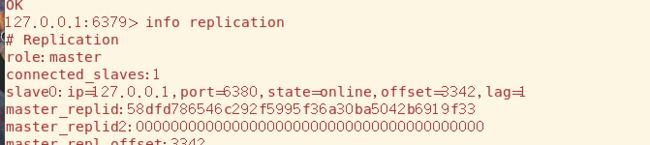
我们要学习的第一个命令是info replication,可以查看该服务器在主从复制技术中的信息,我们重点关注role角色和connected_slaves从机连接数就行。每台服务器默认的角色一开始都是Master

要让服务器变成slave,使用slaveof [host] [port] 命令,默认为Master的6381现在就变为6379的Slave了
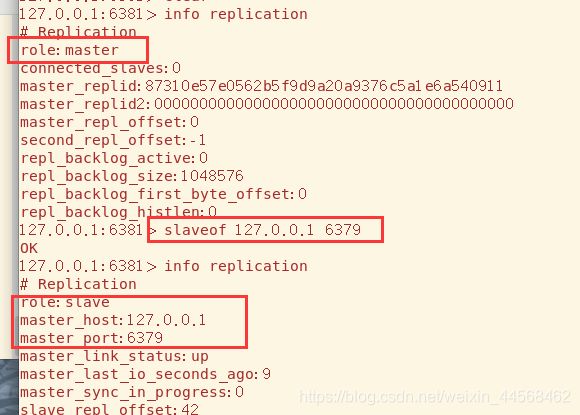
我们回到6379,可以看到两台slave的简单信息

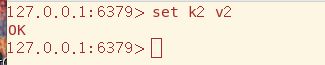
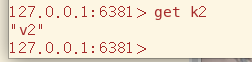
在主机上写入,从机能够顺利获取数据,现主从复制的最基础的功能
主从复制技术实现了读写分离,写由主机负责,而从机只有读功能
![]()

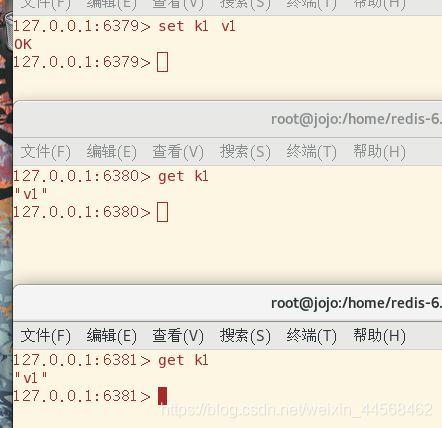
基本的主从复制功能我们可以实现了,我们现在深入一些来了解一些具体的机制,比如主机如果出故障了,从机会做出如何行为,是咸鱼翻身自己作主人还是继续等待主机的恢复。
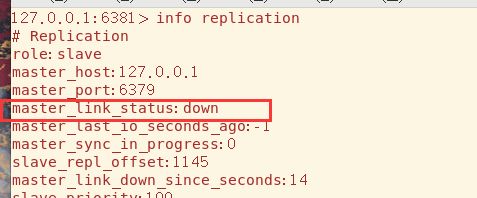
很不幸的是从机跪久了站不起来,奴性太大,它只是将主机的连接状态声明为down,身份还是slave,等待主机重新连接
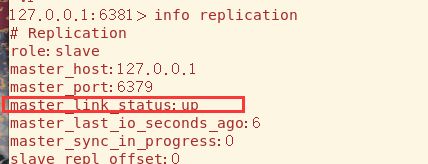
当主机恢复,连接状态也变为了up
下一个问题,从机如果宕机后重新连接,是会自动连回主机还是什么都不做
如下,结果是什么都不做,恢复master的身份

如果需要从机能够自动连回主机,需要在其配置文件中修改配置,有关主从复制技术的配置内容在REPLICATION中
我们可以看到被注释掉的一行,以前的版本是slaveof,修改保存后重启服务器就行
![]()
![]()
从机恢复后自动连接到主机
哨兵模式
从机等待主机恢复再重连是默认模式,还有另一种哨兵模式,它能够后台自动监控主机是否出故障,如果出故障将会以投票的形式将某个从机晋升为主机,从机宕机重连也会自动连上主机
哨兵模式的配置文件是与redis.conf同级目录下的sentinel.conf
我们关注这一条配置就行,它默认就帮配得差不多了(配置文件详解可以参考这篇文章:redis哨兵机制–配置文件sentinel.conf详解)
sentinel monitor固定写法,直译哨兵监控,mymaster自定义的名字,后面两个一个IP地址一个端口,最后一个2表示最低通过票数(后面我改为1)

使用redis-sentinel命令启动哨兵模式


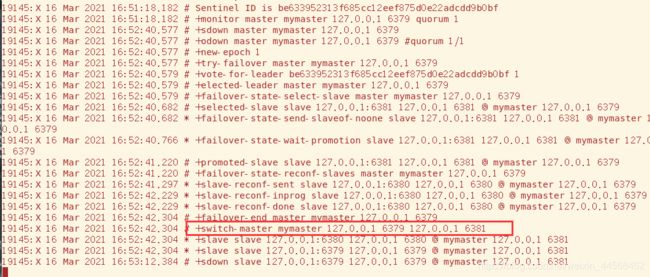
现在将6379主机关闭,可以看到哨兵输出的日志,最终选到6381当新的主机
回去看两者的身份确实也发生了改变

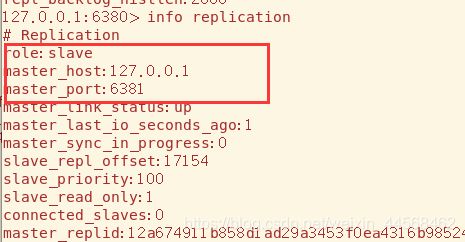
值得注意的是尽管原先的主机恢复了,哨兵不会恢复其主机的地位,而是将其转化为现主机的从机
![]()

经过后续一些折腾发现哨兵模式会修改其配置文件的配置,原来监控的是6379,当6380晋升为主机哨兵模式的配置文件也会跟着修改
![]()
甚至之前在6381配置文件中的自动成为6379的从机的整个配置都被哨兵删掉,害我找了半天没找到
不过也能理解,哨兵模式会管理所有服务器的主从关系,如果配置文件单独配置肯定会有歧义
![]()
另外值得一提的是,当主机宕机哨兵不会直接选举新主机,而是会等待一会(可以配置),从输出日志可以看到,原主机短时间内重连的话会显示重启reboot
![]()
去中心化
上面的模式过于依赖一台主机,也就是太中心化,容灾性较差,我们可以让主机的一些从机充当另一些从机的主机,即树状结构
我们让6381充当6380的从机,6380充当6379的从机
虽然6380有自己的从机,但是其身份仍然是slave,所以还是只读
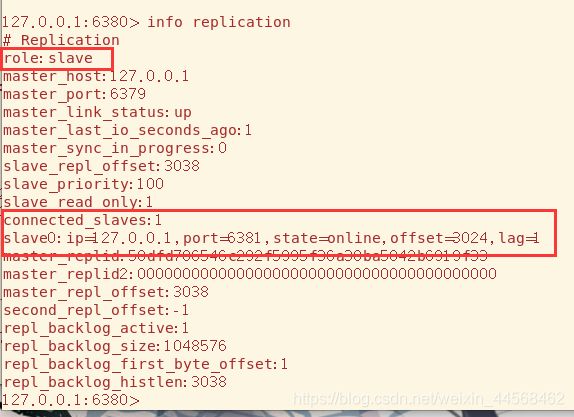
而对于最顶级的主机来说,其从机只有一个,让我想起中学学的“我的附庸的附庸不是我的附庸”
但顶级主机颁布的圣旨依然可以顺利传到最底层从机,但是缺点也明显,因为网络传输问题,层层传递的圣旨不能很快传到,所以一致性可能会差些

集群
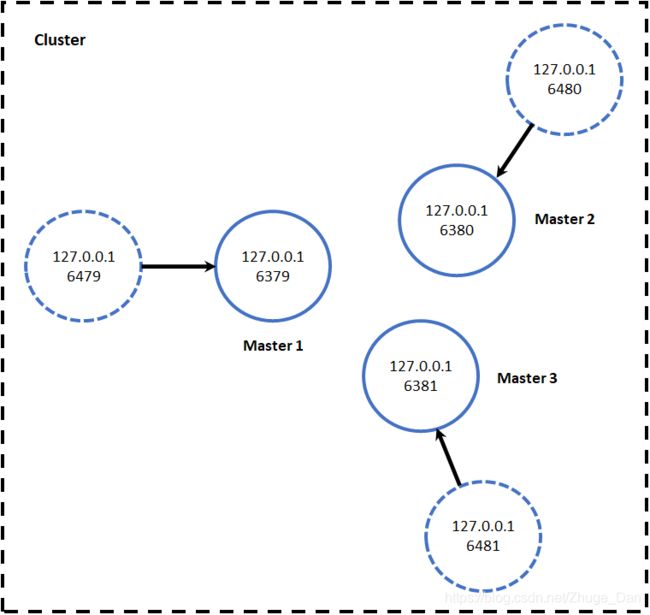
主从复制和哨兵模式可以保证Redis满足互联网中的高可用性,即使一个Redis结点宕机,其他结点也可以很快顶替上来,而对于高并发性,需要用集群来解决。
Redis集群的工作模式是由多个结点组成一个集群,比如A、B、C三个结点,集群提供cluster接口来让用户操作。
集群中每个结点的数据是共享的,这表示用户存储和取出数据由cluster来决定分配到哪个结点,这也导致一个严重的问题,如果集群中一个结点发生故障,那么数据就不完全,所以每个结点都需要有一个备用机,即A1、B1、C1。
根据上面的场景,三个工作结点的集群至少需要六个服务器,以下图为例
配置好六个服务器的配置文件(建议统一放在一个文件夹下,比如cluster-confg)
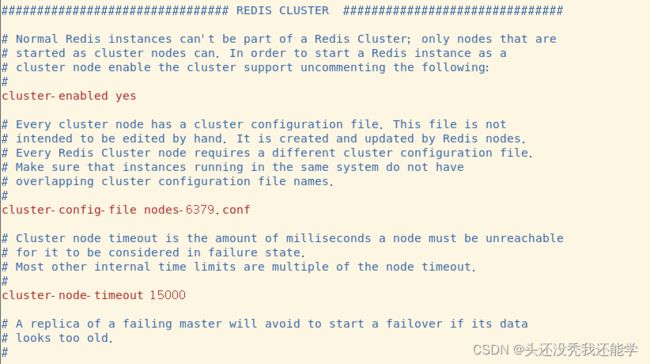
除了常规的端口,后台运行等,还要配置集群相关参数
- cluster-enabled:开启集群
- cluster-config-file:集群配置文件
- cluster-node-timeout:集群结点超时时间,超过该时间备用机就会顶上
将这六个服务器启动起来,可以看到每个进程和之前都多[cluster]标识

接下来创建集群
使用redis-cli --cluster create ip:port命令创建集群,–cluster-replicas(复制品) 来设置集群中每个结点备用服务器的数量

成功创建集群,其中M标识为主机,S标识为备机,主机和备机的分配由–cluster-replicas和输入服务器的顺序决定,之前没有注意到,所以顺序是乱的
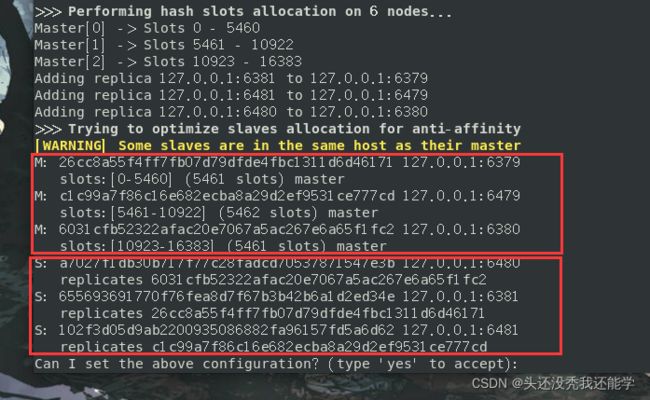
这回就顺眼多了

最后会询问是否以上面配置进行设置集群,yes确定集群就创建好了
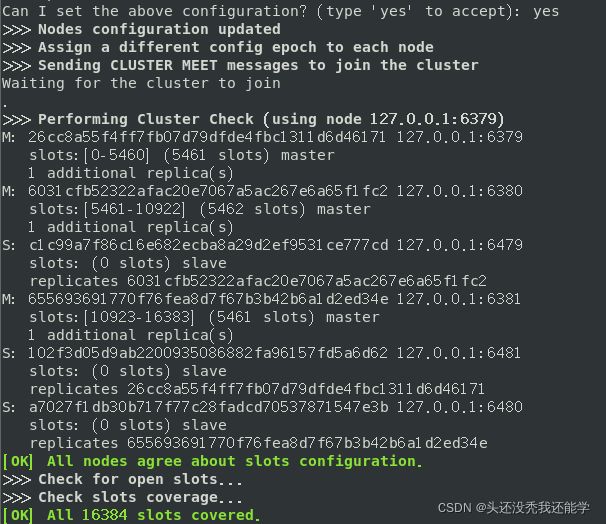
接下来使用redis-cli连接服务器,后面需要多加-c参数标识连接的是集群
![]()
正常存取数据,可以看到在集群中数据的存储时是不固定某一结点的,尽管现在在6379的服务器下,数据也会存储到其他结点
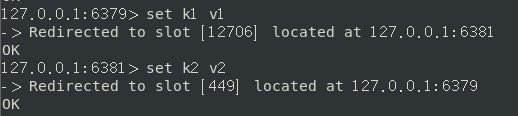
获取数据时,也是遍历所有结点直到找到该key,如果所有结点都没有则返回nil
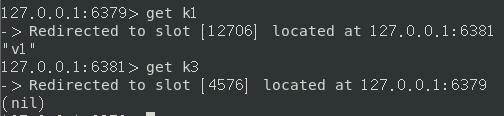
如果我们使用单节点的连接方式,是获取不到其他结点的数据的
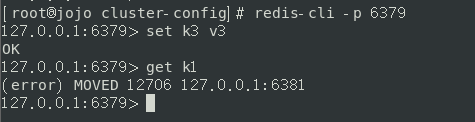
缓存穿透、击穿、雪崩
Redis在互联网中一个常用的用途是作为缓存,减轻数据库层的访问压力,既然作为缓存就不可避免地遇到三个常见问题击穿、穿透、雪崩
穿透
缓存穿透是当查询Redis中没有的数据时,该查询会下沉到数据库层,但同时数据库层也没有该数据,当这种情况大量出现或被恶意攻击时,接口的访问全部透过Redis访问数据库,而数据库中也没有这些数据。缓存穿透会穿透Redis的保护,提升底层数据库的负载压力,同时这类穿透查询没有数据返回也造成了网络和计算资源的浪费。
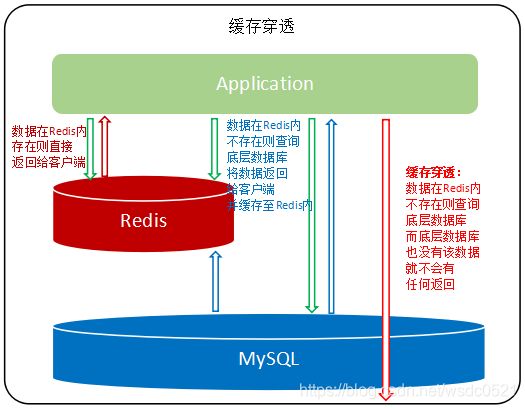
解决方法
- Redis缓存空对象,当在数据库层查询不到数据,仍将空对象存入Redis中,再次访问该数据时,Redis会直接返回空对象,空对象一定要设置过期时间,以免数据库后面有了相关的数据还是返回空对象。
- 使用布隆过滤器,将所有存在的key提前存入布隆过滤器,在访问缓存层之前,先通过过滤器拦截,若请求的是不存在的key,则直接返回空值。其原理可以看看该文章Redis系列(十九)、布隆过滤器(Bloom Filter)
(布隆过滤器有误判率,但已经可以将99.99%的穿透查询给屏蔽在Redis层了)

击穿
缓存击穿表示底层数据库有数据而缓存内没有数据。当热点数据key从缓存内失效时,大量访问同时请求这个数据,就会将查询下沉到数据库层,此时数据库层的负载压力会骤增。击穿和穿透两个词很容易混淆,概念大家应该还是能分清。

解决方案
- 延长热点key的过期时间到低峰时段
- 利用互斥锁保证同一时刻只有一个客户端可以查询底层数据库的这个数据,一旦查到数据就缓存至Redis内,避免其他大量请求同时穿过Redis访问底层数据库;
雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
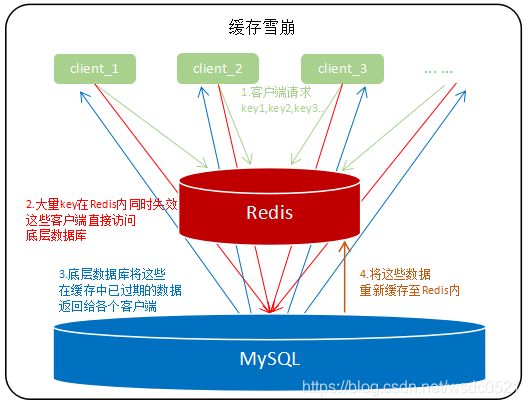
解决方案
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中。
- 像击穿一样,延长热点key的过期时间到低峰时段
参考文章Redis系列(二十)、缓存穿透、击穿、雪崩、预热、更新、降级
消息订阅发布
消息订阅发布是消息队列(Message queue)的一种模式——发送者 (pub) 发送消息,订阅者 (sub) 接收消息,就像微信公众号那样,你关注了某个公众号,更新就会推送文章给你。
Redis提供这样的功能,但是生产中很少使用Redis来充当消息中间件而更多的是使用专业的RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ、MetaMQ等,所以这里简单了解下就行。
如下图所示订阅者需要向频道发送订阅指令然后阻塞等待,发送者向该频道发送消息,订阅者就可以接受到消息了。
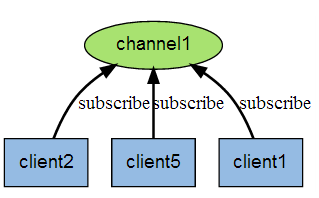
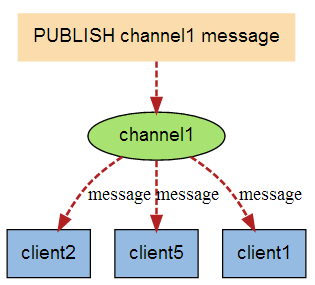
注意在Redis的顺序是订阅者先订阅某个频道,然后发布者向该频道发送消息,否则对没有订阅者的频道发送消息会失败,感觉有点奇怪,不应该是先有频道,用户才去订阅吗

开两个客户端,订阅者先订阅频道

发布者发布消息

订阅者接受到消息

Jedis
大多数主流语言都有工具支持连接操作Redis,对于Java来说Jedis是比较常用的工具。
由于机子是笔记本,IDEA和虚拟机同时开吃不消,所以用阿里云服务器来启动Redis
导入相关依赖
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>3.6.3version>
dependency>
创建Jedis实例,Jedis可选的构造器很多,这里选择连接的IP和port即可
云服务器的公网IP可以在实例下看到
云服务器方面还需要配置安全组,放行传输给redis的数据

别忘了Linux自身的防火墙

对于redis,需要将安全模式关闭(protected-mode),默认是开启的,如果想让其他主机来连接Redis,需要关闭该选项
PS:血的教训!一定要给Redis设置密码,不然会被挖矿病毒入侵,如何设置密码查看AUTH命令或者看后面 Another Redis Desktop Manager一节

配置bind,bind用于设置可以访问的IP地址,文档说了如果你确定想让所有IP地址可以访问就注释掉,这里省事些直接注释掉
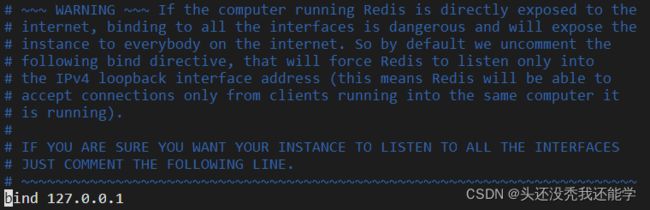
以上配置完成后重启redis,Jedis提供的API和Redis的命令一致,直接使用即可
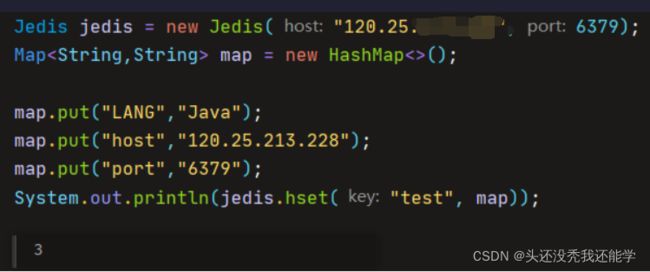
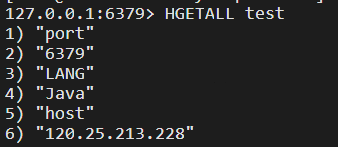
比如这里存放Hash类型的数据
SpringBoot整合Redis
在Spring的子框架中,Spring Data负责数据库的服务,Spring Data提供了操作Redis的工具——Spring Data Redis
如果是一个SpringBoot新项目,在创建时就可以添加Spring Data Redis(后面在Web中模拟,所以也把Web模块加上)

也可以手动添加依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
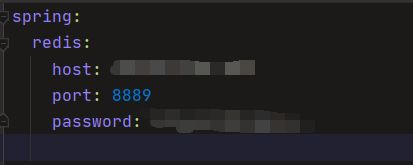
配置Redis相关配置,在Redis(我后面自己改了端口)
Spring Data Redis提供了两个模板类RedisTemplate和StringRedisTemplate(继承于前者)来操作Redis,具体用法参考以下文章
RedisTemplate操作Redis,这一篇文章就够了(一)
springboot使用redis(StringRedisTemplate的用法)
这里模拟Web项目,先创建Product实体类

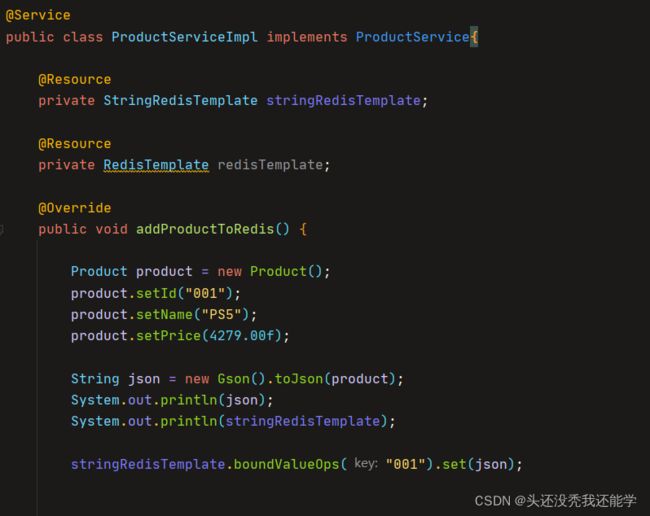
service层业务
boundValueOps(key).set(value)方法可以直接存储key-value值
controller层

项目结构如下

启动Web服务器后访问即可
![]()
在Redis中查询是否有数据

Another Redis Desktop Manager
Redis Desktop Manager是之前常用的一款Redis图形化管理工具,但是现在收费了,我们可以使用Another Redis Desktop Manager替代。直接下载安装即可
gitee下载
github下载
启动看到这样的页面
点击New Connection创建新连接

可以设置简体中文
这里还是连接阿里云服务器,在上面学习中都没有为Redis的连接设置密码,现在来设置相关功能
在配置文件中开启requirepass参数,后面添加密码即可
![]()
在设置密码后,在Redis中直接输入命令会表示没有权限

所以得使用auth命令输入密码获取权限才能正常操作
![]()
成功连接
在服务器随意存储一个数据
![]()
可以在左侧直接输入key查询

亦或者开启命令行工具直接使用Redis命令

Redis挖矿病毒
血的教训!因为一开始学习都在虚拟机上,后面转到了云服务器上,在学习Jedis时为了省事,Redis没有设置密码,bind和保护模式也关闭了,导致了挖矿病毒的入侵,前晚看CPU占用率一直为100%还不知道怎么回事,第二天阿里云就发警告过来了。
还好服务器什么都没有,直接重装系统了,这个漏洞还是很常见的,就很多就发生在刚学习Redis的同学中,不幸中招的小伙伴可以看看这些文章
Redis被pnscan病毒挟持挖矿(Linux系统)
redis因为没有配置密码而被种植了挖矿木马,附清理方法
因为Redis这个漏洞,我可怜的服务器被挖矿病毒偷袭了
防止入侵最主要的就是设置密码,其他预防步骤比如修改端口号,设置好bind可访问的地址,防火墙、安全组策略等等