图推理:忠实且可解释的大型语言模型推理11.29
推理:忠实且可解释的大型语言模型推理
- 摘要
- 1 引言
- 2 相关工作
- 3 准备工作
- 4 方法
-
- 4.1 图推理:规划-检索-推理
- 4.2 优化框架
- 4.3 规划模块
- 4.4 检索推理模块
- 5 实验
-
- 5.1 实验设置
- 5.2 RQ1:KGQA 性能比较

摘要
大型语言模型(LLM)在复杂任务中表现出了令人印象深刻的推理能力。然而,他们在推理过程中缺乏最新的知识和经验幻觉,这可能导致错误的推理过程并降低他们的表现和可信度。知识图谱(KG)以结构化格式捕获大量事实,为推理提供了可靠的知识来源。然而,现有的基于KG的LLM推理方法仅将KG视为事实知识库,而忽视了其结构信息对于推理的重要性。在本文中,我们提出了一种称为图推理(Reasoning on Graph 即RoG)的新颖方法,它将 LLM 与 KG 相结合,以实现忠实且可解释的推理。具体来说,我们提出了一个planning-retrieval-reasoning 框架,其中 RoG 首先生成以知识图谱为基础的关系路径作为忠实的计划。然后使用这些计划从 KG 中检索有效的推理路径,供LLM进行忠实的推理。此外,RoG不仅可以从KG中提取知识,通过训练来提高LLM的推理能力,而且还可以在推理过程中与任意LLM无缝集成。对两个基准 KGQA 数据集的大量实验表明,RoG 在 KG 推理任务上实现了最先进的性能,并生成忠实且可解释的推理结果。
1 引言
大型语言模型 (LLM) 在许多 NLP 任务中表现出了出色的性能。尤其引人注目的是他们通过推理处理复杂任务的能力。为了进一步释放LLM的推理能力,提出了计划与解决范式,其中提示LLM生成计划并执行每个推理步骤。通过这种方式,LLM将复杂的推理任务分解为一系列子任务并逐步解决。尽管LLM取得了成功,但他们仍然受到知识缺乏的限制,在推理过程中容易出现幻觉,这可能导致推理过程中的错误。例如,如图1所示,LLM没有最新的知识,会产生错误的推理步骤:“有一个女儿”。这些问题很大程度上降低了在高风险场景(例如法律判断和医疗诊断)中的表现和可信度。

为了解决这些问题,人们引入知识图谱(KG)来提高LLM的推理能力。知识图谱以结构化格式捕获丰富的事实知识,为推理提供了可靠的知识源。作为一个典型的推理任务,知识图谱问答(KGQA)旨在根据知识图谱中的知识获取答案。之前联合使用 KG 和 LLM 进行 KGQA 推理的工作大致可分为两类:
1)语义解析方法,该方法使用 LLM 将问题转换为逻辑查询,在 KG 上执行以获得答案;
2)检索增强方法,从 KG 中检索三元组作为知识上下文,并使用 LLM 获得最终答案。
尽管语义解析方法可以通过利用知识图谱推理来生成更准确和可解释的结果,但由于语法和语义的限制,生成的逻辑查询通常是不可执行的并且无法产生答案。检索增强方法更加灵活,可以利用LLM的推理能力。然而,他们只将知识图谱视为事实知识库,而忽视了其结构信息对于推理的重要性。例如,如图 1 所示,关系路径(即关系序列“child of→has son”)可用于获取问题“谁是 Justin Bieber 的兄弟?”的答案。因此,让LLM能够直接在KG上进行推理,以实现忠实且可解释的推理是至关重要的。
在本文中,我们提出了一种称为图推理(RoG)的新颖方法,该方法将 LLM 与 KG 协同进行忠实且可解释的推理。为了解决幻觉和缺乏知识的问题,我们提出了一个规划-检索-推理框架,其中 RoG 首先通过规划模块生成以 KG 为基础的关系路径作为忠实的计划。然后,这些计划用于从知识图谱中检索有效的推理路径,以通过检索推理模块进行忠实的推理。这样,我们不仅可以从知识图谱中检索最新的知识,还可以考虑知识图谱结构对推理和解释的指导。此外,RoG的规划模块在推理过程中可以与不同的LLM即插即用,以提高其性能。基于这个框架,RoG通过两个任务进行优化:
1)规划优化,我们将知识从KG中提取到LLM中,以生成忠实的关系路径作为规划;
2)检索推理优化,我们使LLM能够基于检索路径进行忠实推理并生成可解释的结果。
我们在两个基准 KGQA 数据集上进行了广泛的实验,结果表明 RoG 在 KG 推理任务上实现了最先进的性能,并生成了忠实且可解释的推理结果。
2 相关工作
LLM 推理提示。
已经提出了许多研究来利用LLM的推理能力通过提示来处理复杂的任务。计划与解决(Plan-and-solve)促使LLM制定计划并据此进行推理。 DecomP提示LLM将推理任务分解为一系列子任务并逐步解决。然而,幻觉和缺乏知识的问题影响了LLM们推理的忠实性。 ReACT将 LLM 视为代理,它与环境交互以获得推理的最新知识。为了探索忠实的推理,FAME引入了蒙特卡洛规划产生忠实的推理步骤。 RR和 KD-CoT Wang 等人进一步从KG中检索相关知识,为LLM制定忠实的推理计划。
知识图谱问答(KGQA)。
传统的基于嵌入的方法表示嵌入空间中的实体和关系,并设计特殊的模型架构(例如键值存储网络、顺序模型和图神经网络)来推理答案。为了将 LLM 集成到 KGQA,检索增强方法旨在从 KG 中检索相关事实以提高推理性能。最近,UniKGQA将图检索和推理过程统一到具有 LLM 的单一模型中,实现了 STOA 性能。语义解析方法通过 LLM 将问题转换为结构查询(例如 SPARQL),该查询可以由查询引擎执行以推理 KG 上的答案。然而,这些方法严重依赖于生成的查询的质量。如果查询不可执行,则不会生成任何答案。 DECAF结合语义解析和 LLM 推理来联合生成答案,这在 KGQA 任务上也达到了显着的性能。
3 准备工作
知识图谱
KG以一组三元组的形式包含丰富的事实知识:G = {(e, r, e′)|e, e′ ∈ E, r ∈ R},其中 E 和 R 分别表示实体和关系的集合。
关系路径
关系路径是一系列关系:z = {r1, r2,…, rl},其中 ri∈ R 表示路径中的第 i 个关系,l 表示路径的长度。
推理路径
推理路径是 KG 中关系路径 z 的实例: wz= e0—r1—→ e1—r2—→… —rl→ el,其中 ei∈ E 表示第 i 个实体,ri表示关系路径 z 中的第 i 个关系。
**例 1. ** 给定一个关系路径:z = marry_to → father_of,推理路径实例可以是: wz = Alice -----marry_to-----→ Bob -----father_of-----→ Charlie,表示“ “爱丽丝”与“鲍勃”结婚,“鲍勃”是“查理”的父亲。
知识图问答(KGQA)
KBQA 是典型的基于知识图谱的推理任务。给定自然语言问题 q 和 知识图谱 G,该任务旨在设计一个函数 f 来根据 G 的知识预测答案 a ∈ Aq,即 a = f(q, G)。根据之前的工作,我们假设 q 中提到的实体 eq∈ Tq和答案 a ∈ Aq被标记并链接到 G 中的相应实体,即 Tq, Aq⊆E。
4 方法
在本节中,我们介绍我们的方法:图推理(RoG)。我们提出了一种新颖的规划检索推理框架,该框架可以协同 LLM 和 KG 为 KGQA 进行忠实且可解释的推理。 RoG的整体框架如图所示。

4.1 图推理:规划-检索-推理
最近,人们探索了许多通过规划来提高LLM推理能力的技术,首先促使LLM生成推理计划,然后基于该计划进行推理。然而,众所周知,LLM存在幻觉问题,很容易产生错误的计划并导致错误的答案。为了解决这个问题,我们提出了一种新颖的规划-检索-推理框架,该框架使推理计划以 KG 为基础,然后为 LLM 推理检索忠实的推理路径。
关系路径捕获实体之间的语义关系,已被用于知识图谱的许多推理任务中。此外,与动态更新的实体相比,知识图谱中的关系更加稳定。通过使用关系路径,我们总是可以从 KG 中检索最新的知识进行推理。因此,关系路径可以作为推理 KGQA 任务答案的忠实计划。
例2
给定一个问题“谁是 Alice 的孩子”,我们可以生成一条关系路径作为计划:
z =marry_to → father_of。该关系路径表达了计划:
1)找到以下人:“爱丽丝”结婚了;
2)找到那个人的孩子。
我们可以通过从 KG 中检索推理路径来执行计划(关系路径):![]()
最后,我们可以根据推理路径来回答问题,那就是“查理”。
通过将关系路径视为计划,我们可以确保计划以知识图谱为基础,这使得LLM能够在图上进行忠实且可解释的推理。简而言之,我们将 RoG 表述为一个优化问题,旨在通过生成关系路径 z 作为计划,最大化从知识图 G 与问题 q 推理答案的概率:

其中θ表示LLM的参数,z表示LLM生成的关系路径(计划),Z表示可能的关系路径的集合。后一项 Pθ(z|q) 是在给定问题 q 的情况下,生成基于 KG 的忠实关系路径 z 的概率,这由规划模块实现。前一项 Pθ(a|q, z, G) 是在给定问题 q、关系路径 z 和 KG G 的情况下推理答案的概率,由检索推理模块计算。
4.2 优化框架
尽管按照计划生成关系路径具有优势,但LLM对知识图谱中包含的关系的了解为零。因此,LLM 不能直接生成以 KG 为基础的关系路径作为忠实的计划。此外,LLM可能无法正确理解推理路径并据此进行推理。为了解决这些问题,我们设计了两个指令调优任务:
1)规划优化,将知识图谱中的知识提炼到LLM,以生成忠实的关系路径作为规划;
2)检索推理优化,使LLM能够根据检索到的推理路径进行推理。
方程 1 中的目标函数可以通过最大化证据下界 (ELBO) 来优化,其公式为
![]()
其中 Q(z) 表示基于 KG 的忠实关系路径的后验分布。后一项最小化了后验和先验之间的 KL 散度,这鼓励 LLM 生成忠实的关系路径(规划优化)。前一项最大化了检索推理模块根据关系路径和 KG 生成正确答案的期望(检索推理优化)。
**规划优化。**在规划优化中,我们的目标是将 KG 中的知识提炼到 LLM 中,以生成忠实的关系路径作为规划。这可以通过使用忠实关系路径 Q(z) 的后验分布最小化 KL 散度来实现,该分布可以通过 KG 中的有效关系路径来近似。
给定问题 q 和答案 a,我们可以找到路径实例 wz(eq, ea) = eq— r1→ e1— r2→ … —rl→ ea 连接 KG 中的 eq 和 ea。对应的关系路径z = {r1, r2,…, rl} 可以被认为是有效的,并且可以作为回答问题 q 的忠实计划。因此,后验分布 Q(z) 可以正式近似为:

其中 ∃wz(eq, ea) ∈ G 表示 G 中存在连接问题 eq 和答案 ea 实体的路径实例。为了减少有效关系路径的数量,我们只考虑 KGs 中 eq 和 ea 之间的最短路径。因此,KL散度可以计算为:

通过优化方程 4,我们通过从知识图谱中提取知识,最大化了LLM生成忠实关系路径的概率。
检索推理优化。 在检索推理优化中,我们的目标是使法学硕士能够根据检索到的推理路径进行推理。对于检索推理模块,我们遵循 FiD 框架,该框架允许在多个检索推理路径上进行推理,公式为

通过用K个采样计划ZK来逼近期望,推理优化的目标函数可以写为
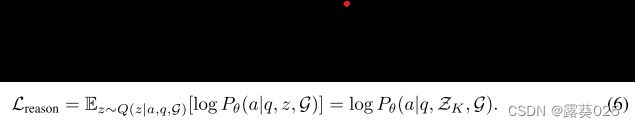
这最大限度地提高了LLM根据检索到的推理路径生成正确答案的概率。
RoG的最终目标函数是规划优化和检索推理优化的结合,可以表示为

从等式7中,我们可以看到我们对规划和推理采用相同的LLM,它们在两个指令调整任务上联合训练,即(规划和检索推理)。我们将在下面的小节中讨论这两项任务的实现细节。
4.3 规划模块
规划模块旨在生成忠实的关系路径作为回答问题的计划。为了利用 LLM 的指令跟踪能力,我们设计了一个简单的指令模板,提示 LLM 生成关系路径:

因此,Lplan的优化可以实现为

其中 Pθ(z|q) 表示生成忠实关系路径 z 的先验分布,Pθ(ri|r
4.4 检索推理模块
恢复。给定问题 q 和作为计划 z 的关系路径,检索模块旨在从 KG G 检索推理路径 wz。检索过程可以通过在 G 中查找从问题实体 eq 开始并遵循关系路径 z 的路径来进行,公式为
![]()
我们采用约束广度优先搜索来从 KG 中检索推理路径 wz。在实验中,所有检索到的路径都用于推理。详细的检索算法见附录A.2。
尽管我们可以利用检索到的推理路径并通过多数投票直接获得答案。检索到的推理路径可能充满噪音并且与问题无关,从而导致错误的答案。因此,我们提出了一个推理模块来探索LLM识别重要推理路径并据此回答问题的能力。
推理。 推理模块采用问题q和一组推理路径Wz来生成答案a。同样,我们设计一个推理指令提示来指导LLM根据检索到的推理路径Wz进行推理:

其中<推理路径>表示检索到的推理路径Wz,其也被格式化为一系列结构句子。详细提示信息参见附录A.9。
Lreason的优化可以写为

其中Pθ(a|q, ZK, G)表示基于K条关系路径ZK推理出正确答案a的概率,t*表示答案a的标记。
5 实验
在我们的实验中,我们旨在回答以下研究问题:
- RQ1:RoG 能否在 KGQA 任务上实现最先进的性能?
- RQ2:RoG 的规划模块能否与其他LLM集成以提高其绩效?
- RQ3:RoG 可以微调并有效转移到其他知识图谱吗?
- RQ4:RoG 能否进行忠实推理并生成可解释的推理结果?
5.1 实验设置
数据集。
我们在两个基准 KGQA 数据集上评估 RoG 的推理能力:最多包含 4 跳问题。数据集的统计数据如表1所示。Freebase是这两个数据集的背景知识图,其中包含约8800万个实体、2万个关系和1.26亿个三元组。数据集的详细信息在附录 A.3 中描述。

基准。
我们将 RoG 与 21 个基线进行比较,分为 5 类:
1)基于嵌入的方法,
2)检索增强方法,
3)语义解析方法,
4)LLM 和
5)LLM+KG 方法。
每个基线的详细信息在附录 A.4 中描述。
评估指标。
继之前的工作之后,我们使用 Hits@1 和 F1 作为评估指标。 Hits@1 衡量排名第一的预测答案正确的问题的比例。由于一个问题可能对应多个答案,因此F1考虑所有答案的覆盖率,从而平衡了预测答案的精确度和召回率。
实施。
对于 RoG,我们使用 LLaMA2-Chat-7B作为 LLM 主干,它是在 WebQSP 和 CWQ 以及 Freebase 的训练分割上进行了 3 个时期的微调的指令。我们使用波束搜索为每个问题生成前 3 个关系路径。由于 UniKGQA 和 DECAF 是最先进的方法,我们直接参考他们的结果和他们论文中报告的其他基线的结果进行比较。对于LLM,我们使用零样本提示来进行 KGQA。详细设置参见附录A.5。
5.2 RQ1:KGQA 性能比较
主要结果。
在本节中,我们将 RoG 与 KGQA 任务的其他基线进行比较。结果如表 2 所示。我们的方法在两个数据集上的大多数指标上都实现了最佳性能。具体来说,与 WebQSP 上的 SOTA 方法 DECAF相比,我们的方法将 Hits@1 提高了 4.4%。在由于多跳问题而更具挑战性的 CWQ 数据集上,我们的方法相对于 SOTA 模型 UniKGQA 将 Hits@1 和 F1 提高了 22.3% 和 14.4%。这些结果证明了我们的方法在 KGQA 中的卓越推理能力。
