如何在自定义数据集上训练 YOLOv8 实例分割模型
在本文中,我们将介绍微调 YOLOv8-seg 预训练模型的过程,以提高其在特定目标类别上的准确性。Ikomia API简化了计算机视觉工作流的开发过程,允许轻松尝试不同的参数以达到最佳结果。
使用 Ikomia API 入门
通过 Ikomia API,我们只需几行代码就可以训练自定义的 YOLOv8 实例分割模型。要开始,请在虚拟环境中安装 API。
pip install ikomia在本教程中,我们将使用 Roboflow 的珊瑚数据集。您可以通过以下链接下载此数据集:https://universe.roboflow.com/ds/Ap7v6sRXMc?key=ecveMLIdNa
使用几行代码运行训练 YOLOv8 实例分割算法
您还可以直接加载我们准备好的开源笔记本。
from ikomia.dataprocess.workflow import Workflow
# Initialize the workflow
wf = Workflow()
# Add the dataset loader to load your custom data and annotations
dataset = wf.add_task(name='dataset_coco')
# Set the parameters of the dataset loader
dataset.set_parameters({
'json_file': 'Path/To/Mesophotic Coral/Dataset/train/_annotations.coco.json',
'image_folder': 'Path/To/Mesophotic Coral/Dataset/train',
'task': 'instance_segmentation',
})
# Add the YOLOv8 segmentation algorithm
train = wf.add_task(name='train_yolo_v8_seg', auto_connect=True)
# Set the parameters of the YOLOv8 segmentation algorithm
train.set_parameters({
'model_name': 'yolov8m-seg',
'batch_size': '4',
'epochs': '50',
'input_size': '640',
'dataset_split_ratio': '0.8',
'output_folder':'Path/To/Folder/Where/Model-weights/Will/Be/Saved'
})使用 NVIDIA GeForce RTX 3060 Laptop GPU(6143.5MB),50个时期的训练过程大约需要1小时。
什么是 YOLOv8 实例分割?
在进行具有所有参数详细信息的逐步方法之前,让我们更深入地了解实例分割和 YOLOv8。
什么是实例分割?
实例分割是计算机视觉任务,涉及在图像中识别和描绘单个对象。与语义分割不同,后者将每个像素分类为预定义的类别,实例分割旨在区分和分离对象的各个实例。
在实例分割中,目标不仅是对每个像素进行分类,还要为每个不同的对象实例分配一个唯一的标签或标识符。这意味着将同一类别的对象视为单独的实体。例如,如果图像中有多个汽车实例,实例分割算法将为每辆汽车分配一个唯一的标签,以实现精确的识别和区分。

实例检测、语义分割和实例分割之间的比较
与其他分割技术相比,实例分割提供了有关对象边界和空间范围的更详细和精细的信息。它广泛用于各种应用,包括自动驾驶、机器人技术、目标检测、医学图像和视频分析。
许多现代实例分割算法,如 YOLOv8-seg,采用深度学习技术,特别是卷积神经网络(CNN),以同时执行像素级分类和对象定位。这些算法通常结合了目标检测和语义分割的优势,以实现准确的实例级分割结果。
YOLOv8概述
发布和优势
由Ultralytics开发的YOLOv8是一种专门用于目标检测、图像分类和实例分割任务的模型。它以其准确性和紧凑的模型大小而闻名,成为YOLO系列的显着补充,该系列在YOLOv5方面取得了成功。凭借其改进的架构和用户友好的增强功能,YOLOv8为计算机视觉项目提供了一个出色的选择。
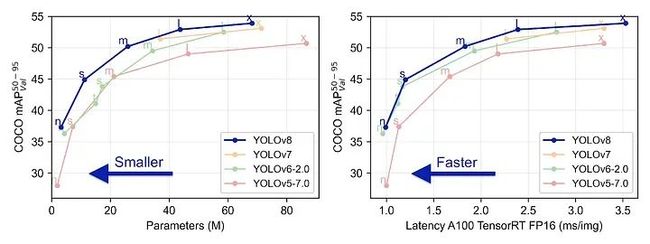
与其他实时目标检测器的比较:YOLOv8实现了最先进(SOTA)的性能
架构和创新
虽然YOLOv8的官方研究论文目前不可用,但对存储库和可用信息的分析提供了有关其架构的见解。YOLOv8引入了无锚检测,该方法预测对象中心而不依赖锚框。这种方法简化了模型并改善了后处理步骤,如非最大抑制。
该架构还包含新的卷积和模块配置,倾向于ResNet样式的结构。有关网络架构的详细可视化,请参阅GitHub用户RangeKing创建的图像。
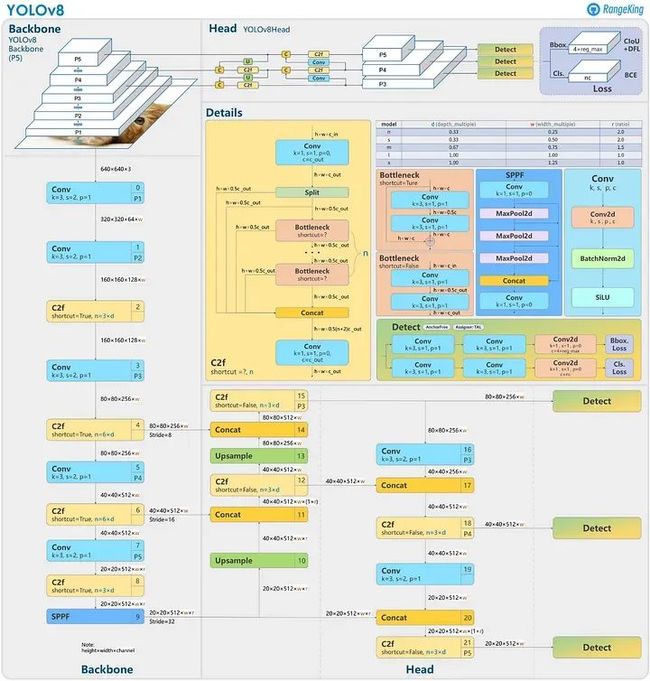
YOLOv8模型结构(非官方)
训练例程和数据增强
YOLOv8的训练例程包括马赛克增强,其中多个图像被组合在一起,使模型暴露于对象位置、遮挡和周围像素的变化。但是,在最终训练时关闭此增强以防止性能降低。
准确性和性能
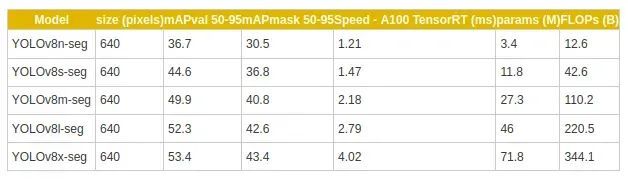
YOLOv8的准确性改进已在广泛使用的COCO基准测试上得到验证,在该基准测试中,该模型实现了令人印象深刻的平均精度(mAP)分数。例如,YOLOv8m-seg模型在COCO上实现了令人瞩目的49.9% mAP。以下表格提供了YOLOv8-seg不同变体的模型大小、mAP分数和其他性能指标的摘要:
以下是使用YOLOv8x检测和实例分割模型的输出示例:
YOLOv8x检测和实例分割模型
逐步操作:使用Ikomia API微调预训练的YOLOv8-seg模型
使用您下载的航拍图像数据集,您可以使用Ikomia API训练自定义的YOLO v7模型。
第1步:导入并创建工作流
from ikomia.dataprocess.workflow import Workflow
wf = Workflow()Workflow是创建工作流的基本对象。它提供了设置输入(如图像、视频和目录)、配置任务参数、获取时间度量和访问特定任务输出(如图形、分割掩码和文本)的方法。我们初始化一个工作流实例。然后,“wf”对象可用于向工作流实例添加任务,配置它们的参数,并在输入数据上运行它们。
第2步:添加数据集加载器
下载的COCO数据集包括两种主要格式:.JSON和图像文件。图像被分成train、val、test文件夹,每个文件夹都有一个包含图像注释的.json文件:
图像文件名
图像大小(宽度和高度)
具有以下信息的对象列表:对象类别(例如“person”、“car”);边界框坐标(x、y、宽度、高度)和分割掩码(多边形)
我们将使用Ikomia API提供的dataset_coco模块加载自定义数据和注释。
# Add the dataset loader to load your custom data and annotations
dataset = wf.add_task(name='dataset_coco')
# Set the parameters of the dataset loader
dataset.set_parameters({
'json_file': 'Path/To/Mesophotic Coral/Dataset/train/_annotations.coco.json',
'image_folder': 'Path/To/Mesophotic Coral/Dataset/train,
'task': 'instance_segmentation'
})第3步:添加YOLOv8分割模型并设置参数
我们向工作流添加'train_yolo_v8_seg'任务,用于训练自定义的YOLOv8-seg模型。为了自定义我们的训练,我们指定以下参数:
# Add the YOLOv8 segmentation algorithm
train = wf.add_task(name='train_yolo_v8_seg', auto_connect=True)
# Set the parameters of the YOLOv8 segmentation algorithm
train.set_parameters({
'model_name': 'yolov8m-seg',
'batch_size': '4',
'epochs': '50',
'input_size': '640',
'dataset_split_ratio': '0.8',
'output_folder':'Path/To/Folder/Where/Model-weights/Will/Be/Saved'
})这是可配置的参数及其相应的描述:
batch_size:在更新模型之前处理的样本数。
epochs:在训练数据集上的完整通过次数。
input_size:训练和验证期间的输入图像大小。
dataset_split_ratio:算法自动将数据集分为训练和评估集。值为0.8表示使用80%的数据进行训练,20%进行评估。
您还可以修改以下参数:
workers:数据加载的工作线程数。当前设置为'0'。
optimizer:要使用的优化器。可用的选择包括SGD、Adam、Adamax、AdamW、NAdam、RAdam、RMSProp和auto。
weight_decay:优化器的权重衰减。当前设置为'5e-4'。
momentum:SGD动量/Adam beta1值。当前设置为'0.937'。
lr0:初始学习率。对于SGD,设置为1E-2,对于Adam,设置为1E-3。
lrf:最终学习率,计算为lr0 * lrf。当前设置为'0.01'。
第4步:运行您的工作流
最后,我们运行工作流以开始训练过程。
wf.run()您可以使用Tensorboard或MLflow等工具监视培训的进度。一旦训练完成,train_yolo_v8_seg任务将在output_folder中的时间戳文件夹内保存最佳模型。您可以在时间戳文件夹的weights文件夹中找到您的best.pt模型。
测试微调的YOLOv8-seg模型
首先,我们可以在预训练的YOLOv8-seg模型上运行珊瑚图像:
from ikomia.dataprocess.workflow import Workflow
from ikomia.utils.displayIO import display
# Initialize the workflow
wf = Workflow()
# Add the YOLOv8 segmentation alrogithm
yolov8seg = wf.add_task(name='infer_yolo_v8_seg', auto_connect=True)
# Set the parameters of the YOLOv8 segmentation algorithm
yolov8seg.set_parameters({
'model_name': 'yolov8m-seg',
'conf_thres': '0.2',
'iou_thres': '0.7'
})
# Run on your image
wf.run_on(path="Path/To/Mesophotic Coral Identification.v1i.coco-segmentation/valid/TCRMP20221021_clip_LBP_T109_jpg.rf.a4cf5c963d5eb62b6dab06b8d4b540f2.jpg")
# Inspect your results
display(yolov8seg.get_image_with_mask_and_graphics())
瑚检测使用YOLOv8-seg预训练模型
我们可以观察到,infer_yolo_v8_seg默认的预训练模型将珊瑚错误地识别为熊。这是因为该模型是在COCO数据集上进行训练的,该数据集不包含任何珊瑚对象。
要测试我们刚刚训练的模型,我们使用'model_weight_file'参数指定路径到我们的自定义模型。然后在先前使用的相同图像上运行工作流。
# Set the path of you custom YOLOv8-seg model to the parameter
yolov8seg.set_parameters({
'model_weight_file': 'Path/To/Output_folder/[timestamp]/train/weights/best.pt',
'conf_thres': '0.5',
'iou_thres': '0.7'
}) 珊瑚检测使用自定义模型
珊瑚检测使用自定义模型
将我们的结果与地面实况进行比较,我们成功地识别了Orbicella spp.的物种。然而,我们观察到一些假阴性的情况。为了提高我们自定义模型的性能,进一步训练更多的时期并使用更多图像进行数据增强可能会有益处。另一个展示有效检测结果的示例是用Agaricia agaricites物种演示的:
 YOLOv8检测珊瑚物种:Agaricia agaricites
YOLOv8检测珊瑚物种:Agaricia agaricites
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除