Trie字典树及内存占用优化
概念
Trie又叫字典树、前缀树,是一种数据结构。它将大量不同字符串以共享前缀的方式保存起来,形成一种树形的数据结构,由于共享字符前缀,按前缀逐级查找字符,所以检索效率极高。字典树本质上是DFA算法的一种实现。它的典型应用是文本词频统计、敏感词过滤。
举个例子
假设有一个字符串:中国人民银行,它的前缀集合为{中,中国,中国人,中国人民,中国人民银},越到后面前缀越长,对于一个有序字符串来说,我们可以简单地把每一个字符都看做后一个字符的前缀。这样,就形成了一个单链表数据结构:{中-国-人-民-银-行}。
字符串中国人民银行的结构图是:

再加一个字符串中国建设银行,两个字符串共享前缀为中、国两个字符:
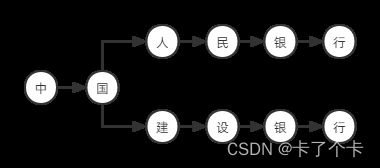
再加一个上海浦发银行,你会发现没有共同的前缀了,所以我们要用一个空白节点做根节点:
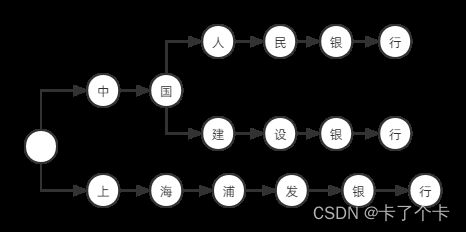
这样就形成了一个树的结构,树的每一个节点都包含一个字符,一个节点可能是上一个节点的子节点和下一个节点的父节点。每一个节点都存储它的下一个节点的引用地址,我们就可以从第一个节点开始,不断寻找其子节点,从而检索出完整的字符串。
中国人民和中国人民银行都是一个完整的词语,所以需要在词语的结尾节点(民、行)做标记isEnd=true,表示到这个节点为一个完整的词语,如果不是词语则做标记isEnd=false。从输入的字符串第一个字符开始逐级检索,检索到最后一个字符节点时,如果isEnd=true,则说明该词语在字典中存在。
Java代码实现
Trie树的数据存储方式可以用HashMap也可以用双数组,本文用HashMap。
节点
节点包含的信息为:当前字符内容、所有子节点引用、是否为词语边界。由于一个节点可能有多个子节点,所以用HashMap来保存所有子节点。
package com.test.nlp;
import java.util.HashMap;
/**
* 字典树节点
* @author administrator
* 2022年8月2日
*/
public class TrieNode {
/** 字符*/
private char word;
/** 子节点*/
private HashMap<Character, TrieNode> children;
/** 是否边界*/
private boolean isEnd;
/** 出现次数,用于词频统计*/
private int count;
public TrieNode() {
this.isEnd = false;
this.count = 1;
}
public TrieNode(char word) {
this.word = word;
this.isEnd = false;
this.count = 1;
}
/**
* 出现次数+1
* @author administrator
* 2022年8月2日
*/
public void count() {
this.count ++;
}
public char getWord() {
return word;
}
public void setWord(char word) {
this.word = word;
}
public HashMap<Character, TrieNode> getChildren() {
return children;
}
public void setChildren(HashMap<Character, TrieNode> children) {
this.children = children;
}
public boolean isEnd() {
return isEnd;
}
public void setEnd(boolean isEnd) {
this.isEnd = isEnd;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
}
Trie树
package com.test.nlp;
import java.util.HashMap;
import org.apache.commons.lang3.StringUtils;
/**
* 字典树
* @author administrator
* 2022年8月2日
*/
public class Trie {
/** 根节点*/
private TrieNode rootNode;
public Trie() {
rootNode = new TrieNode();
}
/**
* 添加树节点
* @param str
* @return
* @author administrator
* 2022年8月2日
*/
public TrieNode addTreeNodes(String str) {
if (StringUtils.isBlank(str)) {
return rootNode;
}
str = str.trim();
TrieNode current = rootNode;
char[] strArray = str.toCharArray();
for (int i = 0; i < strArray.length; i++) {
char word = strArray[i];
HashMap<Character,TrieNode> children = current.getChildren();
if (children == null) {
children = new HashMap<>(16);
current.setChildren(children);
}
TrieNode node;
if (children.containsKey(word)) {
node = children.get(word);
node.count();
} else {
node = new TrieNode(word);
children.put(word, node);
}
current = node;
}
// 最后一个字符,标记为词语边界
current.setEnd(true);
return rootNode;
}
/**
* 是否包含字符串
* @param str
* @return
* @author administrator
* 2022年8月3日
*/
public boolean contains(String str) {
if (StringUtils.isBlank(str)) {
return false;
}
TrieNode current = rootNode;
HashMap<Character,TrieNode> children;
char word;
char[] arr = str.toCharArray();
for (int i = 0; i < arr.length; i++) {
word = arr[i];
children = current.getChildren();
if (children == null || children.containsKey(word) == false) {
return false;
}
current = children.get(word);
}
// 最后一个字符的节点isEnd=true,则说明为一个完整词语
if (current.isEnd()) {
return true;
}
return false;
}
/**
* 前缀包含
* @param str
* @return
* @author administrator
* 2022年8月3日
*/
public boolean prefixContains(String str) {
if (StringUtils.isBlank(str)) {
return false;
}
TrieNode current = rootNode;
HashMap<Character,TrieNode> children;
char word;
char[] arr = str.toCharArray();
for (int i = 0; i < arr.length; i++) {
word = arr[i];
children = current.getChildren();
if (children == null || children.containsKey(word) == false) {
return false;
}
current = children.get(word);
}
return true;
}
/**
* 打印
* @param node
* @author administrator
* 2022年8月3日
*/
public void print(TrieNode node) {
System.out.print(node.getWord());
if (node.isEnd()) {
System.out.println();
}
HashMap<Character,TrieNode> children = node.getChildren();
if (children != null && children.isEmpty() == false) {
children.forEach((k,v) -> {
print(v);
});
}
}
/**
* 统计相同子节点个数的数量
* @param node
* @param count
* @author administrator
* 2022年8月5日
*/
public void countMaxChildren(TrieNode node, Map<Integer, Integer> count) {
HashMap<Character,TrieNode> children = node.getChildren();
if (children != null && children.isEmpty() == false) {
int size = children.size();
if (count.containsKey(size)) {
count.put(size, count.get(size) + 1);
} else {
count.put(size, 1);
}
children.forEach((k,v) -> {
countMaxChildren(v, count);
});
}
}
public static void main(String[] args) {
Trie trie = new Trie();
String str = "中国银行";
String str1 = "中国人民银行";
String str2 = "中国建设银行";
String str3 = "上海浦发银行";
trie.addTreeNodes(str);
trie.addTreeNodes(str1);
trie.addTreeNodes(str2);
trie.addTreeNodes(str3);
//trie.print(trie.rootNode);
System.out.println(trie.contains("中国银行"));
System.out.println(trie.prefixContains("中国银"));
}
}
内存占用
Tire树是一种空间换时间的数据结构,查询效率极高但占用内存也高。
import java.io.File;
import java.io.IOException;
import java.util.List;
import org.apache.commons.io.FileUtils;
public class TestDic {
public static void main(String[] args) {
File file = new File("src/main/resources/main2012.dic");
Trie trie = new Trie();
Runtime runtime = Runtime.getRuntime();
System.out.println("总内存:" + runtime.totalMemory());
try {
List<String> list = FileUtils.readLines(file, "UTF-8");
System.gc();
long start = runtime.freeMemory();
list.forEach(words -> {
trie.addTreeNodes(words);
});
System.gc();
long end = runtime.freeMemory();
System.out.println("占用内存:" + (start - end));
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(trie.contains("上海交大1"));
/*
// 以下代码统计并输出相同子节点数的数量
Map count = new TreeMap<>();
trie.countMaxChildren(trie.getRootNode(), count);
count.forEach((k,v) -> {
System.out.println( k + ":" + v);
});*/
}
}
用IK分词器里的字典测试,27万多个词语,共占用内存52.666954M。
有没有优化空间呢?有!统计一下测试字典文件中所有节点子节点个数,个数相同的为一组,以下是前十:
1:153040
2:18049
3:5896
4:2847
5:1659
6:1055
7:721
8:557
9:453
10:352
只有一个子节点的节点数居然有153040个,用HashMap存这一个子节点,太浪费空间了,如果子节点数量少就用数组存储,子节点数量多就用HashMap存储,会不会少占用很多内存呢?
package com.test.nlp;
import java.util.HashMap;
/**
* 字典树节点
* @author administrator
* 2022年8月2日
*/
public class TrieNode implements Comparable<TrieNode> {
/** 字符*/
private char word;
/** 子节点*/
private HashMap<Character, TrieNode> childrenMap;
/** 子节点数组*/
private TrieNode[] childrenArray;
/** 是否边界*/
private boolean isEnd;
/** 出现次数*/
private int count;
public TrieNode() {
this.isEnd = false;
this.count = 1;
}
public TrieNode(char word) {
this.word = word;
this.isEnd = false;
this.count = 1;
}
/**
* 出现次数+1
* @author administrator
* 2022年8月2日
*/
public void count() {
this.count ++;
}
public char getWord() {
return word;
}
public void setWord(char word) {
this.word = word;
}
public HashMap<Character, TrieNode> getChildrenMap() {
return childrenMap;
}
public void setChildrenMap(HashMap<Character, TrieNode> childrenMap) {
this.childrenMap = childrenMap;
}
public boolean isEnd() {
return isEnd;
}
public void setEnd(boolean isEnd) {
this.isEnd = isEnd;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public TrieNode[] getChildrenArray() {
return childrenArray;
}
public void setChildrenArray(TrieNode[] childrenArray) {
this.childrenArray = childrenArray;
}
@Override
public int compareTo(TrieNode o) {
return this.word - o.word;
}
}
package com.test.nlp;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.lang3.StringUtils;
/**
* 字典树
* @author administrator
* 2022年8月2日
*/
public class Trie {
/** 根节点*/
private TrieNode rootNode;
/** 最大子节点数组容量*/
private static final int CHILDREN_ARRAY_LIMIT = 6;
public Trie() {
rootNode = new TrieNode();
}
/**
* 添加树节点
* @param str
* @return
* @author administrator
* 2022年8月2日
*/
public TrieNode addTreeNodes(String str) {
if (StringUtils.isBlank(str)) {
return rootNode;
}
str = str.trim();
TrieNode current = rootNode;
char[] strArray = str.toCharArray();
for (int i = 0; i < strArray.length; i++) {
char word = strArray[i];
TrieNode[] childrenArray = current.getChildrenArray();
HashMap<Character,TrieNode> childrenMap = current.getChildrenMap();
TrieNode node;
// 子节点数组已存储个数
int storedSize = 0;
if (childrenArray != null) {
for (TrieNode tmp : childrenArray) {
if (tmp != null) {
storedSize ++;
}
}
}
if (childrenMap != null) {
storedSize = CHILDREN_ARRAY_LIMIT;
}
if (storedSize < CHILDREN_ARRAY_LIMIT) {
if (childrenArray == null) {
childrenArray = new TrieNode[CHILDREN_ARRAY_LIMIT];
}
node = new TrieNode(word);
int pos = Arrays.binarySearch(childrenArray, 0, storedSize, node);
if (pos > -1) {
node = childrenArray[pos];
node.count();
} else {
childrenArray[storedSize] = node;
Arrays.sort(childrenArray, 0, storedSize);
}
current.setChildrenArray(childrenArray);
} else {
if (childrenMap == null) {
childrenMap = new HashMap<>(16);
current.setChildrenMap(childrenMap);
}
// 如果子节点数组不为空,则把数组中的节点全部放到map中并把数组设置为null
if (childrenArray != null) {
for (int j = 0; j < childrenArray.length; j++) {
childrenMap.put(childrenArray[j].getWord(), childrenArray[j]);
}
current.setChildrenArray(null);
}
if (childrenMap.containsKey(word)) {
node = childrenMap.get(word);
node.count();
} else {
node = new TrieNode(word);
childrenMap.put(word, node);
}
}
current = node;
}
current.setEnd(true);
return rootNode;
}
/**
* 是否包含字符串
* @param str
* @return
* @author administrator
* 2022年8月3日
*/
public boolean contains(String str) {
if (StringUtils.isBlank(str)) {
return false;
}
TrieNode current = rootNode;
HashMap<Character,TrieNode> childrenMap;
TrieNode[] childrenArray;
char word;
char[] arr = str.toCharArray();
for (int i = 0; i < arr.length; i++) {
word = arr[i];
childrenMap = current.getChildrenMap();
childrenArray = current.getChildrenArray();
// 数组不为空则从数组中查找,否则从map中查找
if (childrenArray != null) {
int storedSize = 0;
for (TrieNode tmp : childrenArray) {
if (tmp != null) {
storedSize ++;
}
}
int pos = Arrays.binarySearch(childrenArray, 0, storedSize, new TrieNode(word));
if (pos > -1) {
current = childrenArray[pos];
} else {
return false;
}
} else if (childrenMap == null || childrenMap.containsKey(word) == false) {
return false;
} else {
current = childrenMap.get(word);
}
}
if (current.isEnd()) {
return true;
}
return false;
}
/**
* 前缀包含
* @param str
* @return
* @author administrator
* 2022年8月3日
*/
public boolean prefixContains(String str) {
if (StringUtils.isBlank(str)) {
return false;
}
TrieNode current = rootNode;
HashMap<Character,TrieNode> childrenMap;
TrieNode[] childrenArray;
char word;
char[] arr = str.toCharArray();
for (int i = 0; i < arr.length; i++) {
word = arr[i];
childrenArray = current.getChildrenArray();
if (childrenArray != null) {
int storedSize = 0;
for (TrieNode tmp : childrenArray) {
if (tmp != null) {
storedSize ++;
}
}
int pos = Arrays.binarySearch(childrenArray, 0, storedSize, new TrieNode(word));
if (pos > -1) {
current = childrenArray[pos];
} else {
return false;
}
} else {
childrenMap = current.getChildrenMap();
if (childrenMap == null || childrenMap.containsKey(word) == false) {
return false;
}
current = childrenMap.get(word);
}
}
return true;
}
/**
* 打印
* @param node
* @author administrator
* 2022年8月3日
*/
public void print(TrieNode node) {
System.out.print(node.getWord());
if (node.isEnd()) {
System.out.println();
}
HashMap<Character,TrieNode> childrenMap = node.getChildrenMap();
if (childrenMap != null && childrenMap.isEmpty() == false) {
childrenMap.forEach((k,v) -> {
print(v);
});
}
}
/**
* 统计相同子节点个数的数量
* @param node
* @param count
* @author administrator
* 2022年8月5日
*/
public void countMaxChildren(TrieNode node, Map<Integer, Integer> count) {
HashMap<Character,TrieNode> childrenMap = node.getChildrenMap();
if (childrenMap != null && childrenMap.isEmpty() == false) {
int size = childrenMap.size();
if (count.containsKey(size)) {
count.put(size, count.get(size) + 1);
} else {
count.put(size, 1);
}
childrenMap.forEach((k,v) -> {
countMaxChildren(v, count);
});
}
}
public TrieNode getRootNode() {
return rootNode;
}
public void setRootNode(TrieNode rootNode) {
this.rootNode = rootNode;
}
public static void main(String[] args) {
Trie trie = new Trie();
String str = "中国银行";
String str1 = "中国人民银行";
String str2 = "中国建设银行";
String str3 = "上海浦发银行";
trie.addTreeNodes(str);
trie.addTreeNodes(str1);
trie.addTreeNodes(str2);
trie.addTreeNodes(str3);
//trie.print(trie.rootNode);
System.out.println(trie.contains("中国银行"));
System.out.println(trie.prefixContains("中国银"));
}
}
再次测试,内存占用29.9883804M,减少了43%。至于数组最大容量为什么是6,这是反复测试的结果,数组长度为6时,占用内存最小。