python TF-IDF,LDA ,DBSCAN算法观影用户的电影推荐聚类分析
项目源码:https://download.csdn.net/download/qq_38735017/87425257
1.1 语料库的建立
进行语料处理时我们会遇到的主要问题之一就是如何将大的数据集读入内存当中然后进行相应的处理。
(图中所示的数据集是豆瓣网上 5000 部电影描述信息的分词结果,每一行的数据是一部电影的所有信息。不过从数据大小上看,该数据集属于小的数据集,大的数据集从容量上讲就是以 GB 甚至以 TB 为单位)
1.1.1Linecache 模块
对于大的数据,python 提供了很多的功能进行读取,其中之一就是 linecache 模块。Linecache 模块功能非常强大,其中包含了多种函数进行调用 linecache.getlines(filename)可以读取文件中的所有内容。linecache.getline(filename,lineno)可以读取文件中的任意行。另外,普通的文件读取方式都是类似于:m=open("F:Programming…,在 python 语言当中,这样的文件读取方式是非常不适合大型数据的读取的,因为一旦采用这种形式进行数据的读取,就会导致所读文件整体被写入内存当中,如果文件过大,内存就无法存储,读取一定会失败。不过,linecache 模块的读取是一种类似于迭代器形式的读取,从而可以使得在读取大的文件的时候不会将所有的文件一次性全部读入,导致因为内存不够产生的程序错误。
1.1.2Corpora 函数
如上图所示,将语料读入程序的数据结构中后,我们就要进行语料库的建立。语料库中所容纳的数据基本可以概括为出现的词的编号以及该词出现的次数。这个工作看似简单,但是如果让研究人员单独编写仍然会耗费非常多的时间,因此,python 其中的一个支持库 gensim 中专门提供了语料库的建立工具 gensim.corpora 函数对语料进行转换。
用 gensim.corpora 函数后进行语料转换后的结果如图所示。每个括号当中的值代表的就是一个词的信息,第一个值是该词的编号,第二个词是这个词在一条电影评论中出现的次数。词语的编号是按照整个语料库中的词语进行编制的.
1.2TF-IDF
1.2.1TF_IDF 简介
语料库建立完毕之后就需要进行对语料中词语的进一步分析。在我们的生活当中,一篇文章,一条说说,一句评语当中的词语的价值并不相同。我们说任何话一般都会用到”的”,因此像”的”这种词语对于区分不同类型的语句的价值就几乎为 0 了,但是加入一句话中出现一个词“吕克贝松“,我们可以立马分析得到这句话很有可能和某一部电影有关。因此,在进行语料的具体分析之前,我们需要对语料中词语的重要性进行分析,这就诞生了 tf-idf 方法。
1.2.2TF_IDF 应用
tf-idf 的主要思想是:如果某个词或短语在一篇文章中出现的频率(TF)很高,并且在其他文章或者评论中出现很少,则认为此词或者短语具有很好的类别区分能力,适合用来分类。很多人或许会困惑 tf 和 idf 两个词的实际意义,TF 表示的是词频(TermFrequency),词频比较好理解,即是某个词在整个文档中出现的频率。然而,光用词频来表示词在整个数据集当中的重要程度是不够科学的,比如前文中提到的“的“这个词语,出现的频率会在素有的电影评论中出现非常高,虽然高,但很明显不具有什么区分能力。因此,还需要引入另外一个概念,即 IDF。IDF 表示的含义是越少的文档(本项目中代表的是一条电影的描述信息)包含这个词,说明这个词有更好的信息区分能力。
上图所示的是用 tf-idf 对语料库进行进一步分析后的结果矩阵的一部分
1.3LDA 矩阵
1.3.1LDA 模型的介绍
LDA 模型的全称是隐含狄利克雷分配(LDA,LatentDirichletAllocation)。是一种今年来发展起来的一种非常重要的离散数据集合的建模方法。其主要的功能就是可以生成文本的主题分布向量,分析然后挖掘出文本的潜在知识。是一种非常优秀的文本聚类的预处理方法。
对于一般的语料分析:“今天下雨了”和“我今天琳湿了”一定是几乎没有相似点的两句话,然而在实际的生活当中,这两句话很有可能表示的是几乎相同的意思。这就需要引入 LDA 模型进行。其基本的思想就是先对类似的文本进行聚类,确定每个文本的隐含主题,然后进行分析。其主要的优点在于会考虑潜在的语义信息,不单纯从词频角度进行分析,还可以映射至内部的隐含主题,过滤噪音。
1.3.2LDA 语料处理的实现
如上图所示是利用 lda 模型对语料进行分析的结果,所得结果的数值的含义是。每一个列表中所有的数值组成了一条电影信息的向量。每条向量都唯一标识了一条电影的信息的各个特征。在本次实训当中,我们一共有近 5000 条电影信息,因此共生成 5000 条向量标识各个电影信息。
1.3.3LDA 模型语料的查询
建立好 LDA 矩阵后,我们就可以利用查询的语句的生成的 LDA 模型对应的向量和系统中原先就计算好的 LDA 模型中的向量进行比较。选择出和查询语句距离最小的前 10 个向量。过匹配得到的向量,利用实现编写好的 mapping 函数就可以找出这些向量对应的电影编号,最终找出匹配的电影。
1.3.4Lda 模型在使用中遇到的问题
上图所示的 LDA 矩阵有一个非常明显的特点,就是非常稀疏,矩阵中的向量绝大都是以 0 为元素的,这就会导致一个非常严重的问题。维度灾难。随着维度的增加,高维空间的体积成几何倍增长,空间非常巨大。因此,对于高维空间的数据,并且向量的差异程度较小(很多维的数据都是 0),那么就会导致这些向量非常非常相似。很难以进行区分。因此,最终分析得到的结果就不容乐观了。关于优化的方法可以有各类型的降维方法。
1.4LSI 矩阵
1.4.1LSI 模型的介绍
LSI 模型的英文全称是:LatentSemanticIndexing,中文意译是潜在语义索引,主要指的是通过海量文献(整个语料集)找出词汇之间的关系从而进行分析。当两个词或一组词大量出现在一条评论,介绍信息或者文档中时,这些词之间就可以被认为是语义相联系的,从而我们可以通过词语和词语之间的联系来建立评论向量,描述每条语句的隐含主题。
1.4.2LSI 模型语料处理的实现
上图是利用 LSI 模型进行语料处理后生成的矩阵,从该矩阵中我们可以发现,不同于 LDA 矩阵,该矩阵不是一种稀疏矩阵,因而每条向量直接的相似度更加低,最后处理的结果也更加好。
下图是通过描述电影风暴最后搜索得到的结果:
可见利用 lsi 进行语料分析最终得到的结果准确度还是非常不错的。
1.5 数据可视化
1.5.1 扇形图
利用 python 进行数据处理的一个很大的优点就是有很多支持它进行画图的库。其中使用得最多的就是 matplotlib 库,利用 matplotlib 可以绘制各种类型的图表,实现数据的可视化。在此次实训当中,我们小组主要利用了基于 matplotlib 库中的 pylab 库进行绘图。

对电影进行匹配后每个电影相关性大小的匹配结果可以使用扇形图进行表示。
1.5.2 点状图
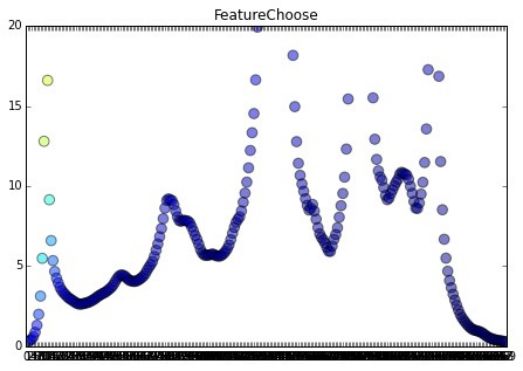
在进行特征提取的时候可以使用点状图来描述各个向量特征的权重。
其他图形比如箱图,3 维图等都可以在 matplotlib 官网上寻找到相应的素材,略加修改后就可以绘制非常美观的图片了。
1.6 组后呈现结果

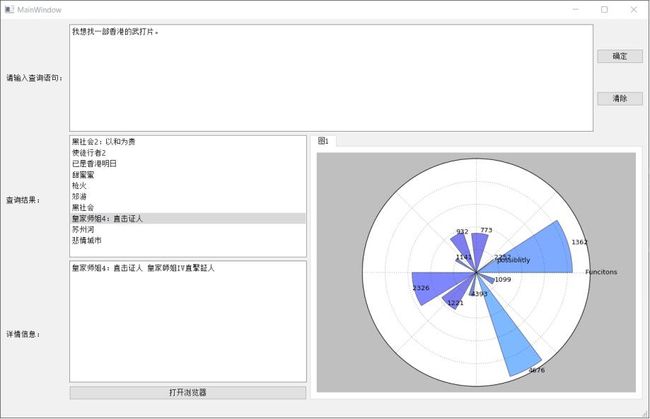
上图所示是小组所编写的 GUI 程序的最终界面。
1.7 关联分析
1.7.1 关联分析简介

上图是一个非常普通的食品交易单。虽然看似简单,但其中却包含了许多的关系。在关联分析当中,我们将上图所示的商品交易列表抽象为频繁项集。
当寻找频繁项集时,有两个概念比较重要:支持度和可信度。一个项集的支持度被定义为数据集中包含该项集的记录所占的比例。可信度或置信度(confidence)是针对关联规则来定义的。可被定义为可信度(B)=支持度({A,B})/支持度({A})。
1.7.2Apriori 算法:

上图所示的是{0,1,2,3}中所有可能的项集组合 Apriori 算法的本质其实是一种频繁集的优化算法,算法的核心思想在于,如果一个集合的某一个子集是频繁的,那么这个集合一定是频繁的。
1.7.3 采用关联分析进行电影的推荐
Python 的支持库非常强大,在本次实训当中,我么小组采用的是 orange 库中的 rules=Orange.associate.AssociationRulesSparseInducer(data,confidence=0.4,support=0.23,max_item_sets=1000000)该函数进行关联分析。Orange 库中的关联函数默认使用的是 Apriori 算法。另外,需要注意的是,进行关联分析数据格式需要是 basket 为后缀名的数据。
2 利用 DBSCAN 算法进行观影用户的聚类
2.1 对 K-means 算法的学习
使用 K 均值聚类算法对数据进行聚类的过程很简单,只需要人为指定 K 的值即可。这里的 K 值表示将要把数据聚成 K 个簇。
基本算法:
人为设置 k 的值。
随机选择 k 个初始点作为初始质心(可以认为是每个簇的中心),计算每个数据点距离这些质心的距离,对每个数据点找出距离最近的那个质心,把这个数据点指派给这个质心,所有被指派给同一个质心的所有数据点形成一个簇。然后根据指派给簇的点,重新确定每个簇新的质心点。重复这个计算距离,指派质心,更新簇的质心的过程,直到质心不再发生变化为止。
伪码描述:
选择 k 个点作为初始质心
Repeat
将每个点指派给最近的质心,形成 k 个簇重新计算每个族的质心
Untill 质心 k 不再变化
判断每个数据点到底被指派给哪个质心可采用不同的距离,比如:欧氏距离。欧式距离就是两点之间的欧式空间直线距离。我这里使用了欧式距离。
最终判断聚类质量,我使用了老师上课讲的方法来判断。通过计算实际聚类结果出来的类标序列和真实的类标序列带入到老师提供的公式中来衡量聚类的质量。
2.2K-means 算法的性质
Figure1
如上图所示,使用 K-means 算法的对球状簇的聚类往往会有一个比较好的效果。但是,如下图所示:
如果是像图中的条状数据,K-means 算法就会显现出它本身的局限性。即无法对于非球状的数据集进行符合其自身形状的聚类。从图中的聚类结果我们可以发现,原本应该聚为一类的数据在 k-means 算法的结果中被拆分了。在此基础之上,我们小组对观影人员的习惯进行调查,发现用户的观影习惯很有可能不会呈现一种球状的分布。
如上图所示,用户的观影习惯的分布往往是对某一类型的电影有着很大的兴趣,因此,聚出的簇的形状很有可能会变成中类似长条形的形状。
2.3 解决非球状簇的聚类问题---DBSCAN 算法的学习
DBSCAN 算法是一种代表性的基于密度的聚类算法,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
DBScan 需要二个参数:扫描半径(epsilon)和最小包含点数(minPoints)。算法的步骤可以划分为:
1.任选一个未被访问的点开始,找出与其距离在 epsilon 之内(包括 eps)的所有附近点,对每一个点的附近点的个数进行记录。
2.统计好每个点的附近点个数后就可以对所有的点进行划分了。DBSCAN 算法中共可以划分出三种类型的点:
i. 核心点:指的是附近点的个数超过了给定阈值(minPoints)的点。这些点再基于密度的簇内部。
ii. 边界点:不是核心点,但是落在核心点的邻域内。
iii. 噪声点:噪声点是非核心点也非边界点的任何点。
3.删除所有的噪声点
4.为距离在 Eps 之内的所有核心点之间赋予一条边。
5.每组联通的核心点形成一个簇
6.将每个边界点只拍到一个与之关联的核心点的簇中,形成最终的结果。
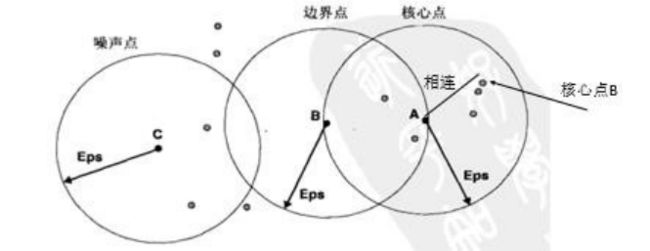
在确定点的类别的时候,是利用点的扫描半径以及扫描半径内点的数数目和 minpoints 的值的比较得出的。
2.4K-means 算法和 DBSCAN 算法的比较
利用 DBSCAN 进行聚类的效果可以如下图所示:

从图中我们可以发现,DBSCAN 聚类可以产生如图中所示的效果,即条状数据的聚类。相比于 DBSCAN,K-means 算法只能产生球状的簇,因此会对一些形状的数据集运行出非常不竟如人意的效果。
2.5 利用 Sklean 和 pandas 实现 DBSCAN 算法
对 DBSCAN 算法的学习之处,我们小组对 dbscan 算法的实现方式是纯粹自己更具算法来进行编写,不过,后来我们小组发现利用 python 进行数据聚类的好处之一就是 python 中有很强大的 sklearn 库。Sklearn 中的 dbscan 算法功能非常强大,支持多个参数,eps,min_samples,metricalgorithm 等:。Eps 参数就是代表的就是点的扫描半径的大小。Min_samples 代表的是最小包含点数。而 metrc 是 sklearn 库中几乎每个算法都带有的距离方式,在其中可以设置距离为欧式距离,余弦距离,或者为自定义的距离(precomputed)。
(以往需要大量代码完成的 DBSCAN 算法,利用 sklearn 库只需要一行代码)
2.6 聚类数据的格式

如上图所示,在本次实训当中,我们小组对豆瓣网上各个用户的观影情况进行了爬取,得到关于各个用户的观影情况数据。上图所示的每一行数据代表每一个用户关于“爱情类”,“动作类”,”科幻类“,”恐怖类“,”喜剧类”,“动画类”电影的历史观看情况。将这 6 类电影作为 6 个维度,使用 dbscan 算法进行用户的观影的习惯分析。
3 对支持向量机的学习
支持向量机(SupportVectorMachine)是 Cortes 和 Vapnik 于 1995 年首先提出的基于统计学习理论的 VC 维理论和结构风险最小原理基础上的机器学习方法,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy)和学习能力(即无错误地识别任意样本的能力),通过结构化风险最小来提高学习机泛化能力,经验风险和置信范围的最小化,从而达到在统计样本量较少的情况,亦能获得良好统计规律的目的。从而在小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化(最大间隔分类器),最终可转化为一个凸二次规划问题的求解。
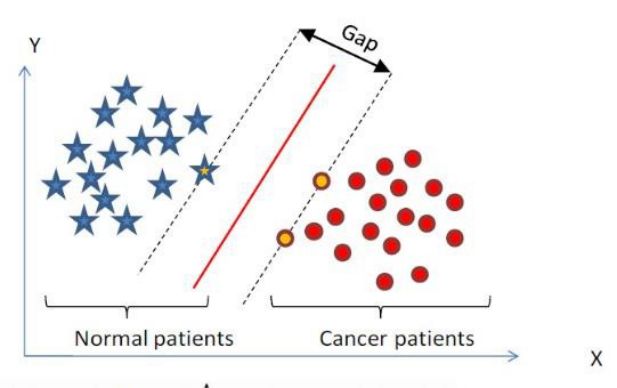
函数间隔 functionalmargin 和几何间隔 geometricalmargin 相差一个 ||w|| 的缩放因子。对一个数据点进行分类,当它的 margin 越大时候,分类 confidence 越大。对于一个包含 n 个点的数据集,我们可以很自然地定义它的 margin 为所有这 n 个点的 margin 值中最小的那个。于是,为了使得分类的 confidence 高,我们希望所选择的超平面 hyperplane 能够最大化这个 margin 值。
实际中,我们会经常遇到线性不可分的样例,此时,我们常用做法是把样例特征映射到高维空间中去(如下图)以此使数据重新线性可分。这转化的关键便是核函数:

在新的维上,搜索最优分离超平面。SVM 通过搜索最大间隔超平面来处理最佳超平面问题,分离超平面:
由最优超平面定义的分类决策函数为:
3.1VC 维:
所谓 VC 维是对函数类的一种度量,可以简单的理解为问题的复杂度,VC 维越高,一个问题就越复杂。因为 SVM 关注的是 VC 维,后面我们可以看到,SVM 解决问题时候,和样本的维数无关(甚至样本是上万维的都可以,引入了核函数,这使得 SVM 很适合用来解决文本分类问题)。
4 对各类距离的学习
4.1 余弦距离:
余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。余弦距离的主要作用在于可以对高维空间中的数据进行更好的衡量。
4.2 杰卡德相似性度量:
两个集合 A 和 B 交集元素的个数在 A、B 并集中所占的比例,称为这两个集合的杰卡德系数,用符号 J(A,B)表示。杰卡德相似系数是衡量两个集合相似度的一种指标(余弦距离也可以用来衡量两个集合的相似度)。
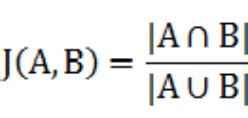
4.3 杰卡德距离
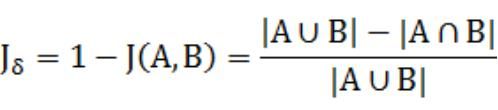
5 傅里叶变换的学习与应用
5.1 傅里叶变化简介
信号的一种最为自然的表达方式,就是看成自变量为时间,因变量为强度的函数形式,但事实上,这里还存在第二种方式,就是把信号分解成不同频率的三角函数。傅立叶变换就是将原来难以处理的时域信号转换成了易于分析的频域信号

(任何一种波形的信号都可以认为是无数正弦波信号的无穷叠加),以我们所学过的傅里叶级数(类似傅里叶变换)公式表述:

Figure 错误!文档中没有指定样式的文字。-2 傅里叶级数

Figure 错误!文档中没有指定样式的文字。-3 傅里叶变换上面两张图大致阐释了傅里叶级数和傅里叶变换之间的不同之处通过对信号的分解,我们可以得到该信号所包含的各种正弦波信号的权重 an,bn,而这些权重其实就是原有信号在另外一个空间当中的映射,因此,我们可以采集信号分解后在不同频率上的权重来进行处理,比如特征提取,另外还可以过滤不必要的噪声。

如上图所示,原本的时间序列式图 a,而当图 a 中的序列加入噪声后(图 b),会产生非常复杂的时间序列。但是,通过傅里叶变化,我们可以发现,原本的时域空间中的时间序列在频域空间中的映射会非常突显原本的时间序列的形式。如上图所示,频率为 10 和 20 的波的权重非常非常大。在这种情况下,我们就可以忽略权重较小的频段的波,只选取权重大的频率的波,这样可以达到一种去除噪声的作用。
5.2 利用傅里叶变化处理时间序列
用 python 实现傅里叶变换:
Python 中的 numpy 库中的 np.fft.fft 可以将时域空间中的时间序列直接通过傅里叶变换得到频域空间中的数据。在得到的结果 transWave 中,我们可以得到原先波在各个频率上的权值.
5.3 傅里叶变换的优点

某数据集中的第 1 条时间序列(时域序列)
某个数据集中的第 2 条时间序列(时域序列)
上面两张图中我们可以发现,虽然两条序列都属于同一类,但是如果对每个时域上的维度进行一一对比,两条时间序列有着很大的差距。
某数据集中的第 1 条时间序列(傅里叶变换后)
某个数据集中的第 2 条时间序列(傅里叶变换后)
上图如果使用了傅里叶变换,时域上的序列转换成了频域上的序列,两条时间序列的频域波形就可以发现是非常相似的。
因此,利用傅里叶变换可以消除因为时间序列的相位不同导致的聚类问题。
6 对于 Pyhon 语言的学习:
6.1Pandas:大规模数据读取的必备数据结构
如上图所示是利用 Python 中的 pandas 中的 DataFrame 功能对数据进行读取之后的结果。DataFrames 是一款非常强大的 pandas 数据结果。其本身的性质非常类似于一种二维表格,不过,它的功能绝对不限制于表格那么简单。
如上图所示,Pandas 的航标比仅仅可以用普通的数字表示,还可以使用日期来进行标识。
DataFrame 显示的数据的都会具有一定的数据格式。用
DataFrame 的数据结构如果调用.T 就会将原有的矩阵进行转置。

另外,DataFrame 还支持直接对数据进行图像的绘制。不过,最重要的是 DataFrame 类对大规模数据的读取速度非常非常快。
6.2Sklearn 库-最强大的 pyhon 机器学习库

Sklearn 是所有使用 python 进行机器学习研究的人所比不可少的一个重要的代码库。在本次本学的学习当中,我们小组主要使用到了其中的两个库函数 k-means 和 DBSCAN。但是,sklearn 中的库函数远远不止于这些,就拿聚类算法举例:
图中所示的就是 sklean 库中的各种类型的聚类算法。使用 sklean 中的库函数可以较大程度减轻在机器学习代码编写过程中编写的代码的负担,因而可以在现有算法的基础之上对更新的算法进行研究。
上图是本小组原先实现 DBSCAN 算法的具体过程。
导入 sklearn 包后只需要一行代码即可完成 DBSCAN。如下图所示:
并且在 sklearn 中的 DBSCAN 算法的功能更加强大,不仅可以使用普通的欧式距离,还可以使用例如余弦距离,马氏距离,曼哈顿距离等等。另外,最让我感觉有用的是可以通过“precomputed”将距离设置成自己定义的类型。如下图所示:
上图所示是通过点和点之间共享最邻近点数 SNN 定义出来的 SNN 距离。使用当基于图中的
SNN 距离的 DBSCAN 时,我们可以通过如下实现:即可。
6.3 函数式编程,一种高效率 Python 编程方法
Lambda 函数:
lambda 的主体是一个表达式,而不是一个代码块。仅仅能在 lambda 表达式中封装有限的逻辑进去。该表达式是起到一个函数速写的作用。允许在代码内嵌入一个函数的定义。
reduce()函数:
python 中的 reduce 内建函数是一个二元操作函数,他用来将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 func()(必须是一个二元操作函数)
先对集合中的第 1,2 个数据进行操作,得到的结果再与第三个数据用 func()函数运算,最后得到一个结果。
Filter 函数:
Filter 函数类似于一种过滤器函数,其本质就是去除一个数据结构中符合要求的数据。
7 Python 爬虫学习
7.1 结果截图:
爬虫的原理:
爬虫做的事情和浏览器(如果是为了扒取网页的话)是类似的。访问 http://www.163.com 这个网页,首先在浏览器输入这个 URL,URL 定位到这个需要访问的 HTML 文件(默认的 index.html 文件),然后发出请求,获得请求,将获得的 HTML 文件进行解析展示在用户面前。
爬虫需要做的就是通过 URL 访问需要扒取的网页,获得返回的 HTML 文件。但是不需要解析。
爬虫除了扒取 HTML 文件,还需要分析网页的链接结构,通过循环的方式来扒取整个网站的内容(浏览器则不需要,用户需要访问那个 URL 标识的资源才会发出请求)
一个简易的爬虫:
importurllib2
content=urllib2.urlopen('http://www.163.com').read();
println(content);
1.python 内置的 urllib2 包可以通过 url 来扒取资源。
2.url 是 uri 的一种细化,子集。uri 可以认为就是用来唯一标识网络上资源的标号(主机号 + 路径 + 文件名称),url 还需要标识出访问的方式,是 http,ftp 还是其他的应用层协议。
3.通过 url 访问资源,返回的数据包通过 read()来获得字符串。可以获得 HTML 文件,也可以是其他的。可以是 http 也可以是 ftp 的。
4.urlopen()函数接受一个 URL 字符串或者一个 Request,通过传递 Request 可以实现更多的请求。
1.request=urllib2.Request(URL 字符串)。
2.request=urllib2.Request(URL 字符串,form 表单)。
3.request=urllib2.Request(URL 字符串,Header)。
可以模拟浏览器通过 URL 访问资源,浏览器通过 post 或者 get 发送 form 数据,浏览器发送自己的类型(IE,Chrome 版本号)。
有的请求是将 form 传递给后台某个 PHP 文件,需要 post 或者 get 一个 form 给 PHP 文件。
添加 header 也可以通过 request 的 add_header()来实现。
import urllib
import urllib2
url='XXX';
values={'name':'fenghe',
'grade':60
};
form=urllib.urlencode(values);
request=urllib.Request(url,form);
content=urllib2.urlopen(request,form).read();有的网站可能需要识别浏览器的版本,python 爬虫默认的是
user_agent='xxx';
headers={'User-Agent':user_agent};
...
request=urllib2.Request(url,form,headers);使用 python 编写爬虫:
1.python 内置的 urllib2 包可以通过 url 来扒取资源。
2.通过 url 访问资源,返回的数据包通过 read()来获得字符串。可以获得 HTML 文件,也可以是其他的。可以是 http 也可以是 ftp 的。
3.urlopen()函数接受一个 URL 字符串或者一个 Request,通过传递 Request 可以实现更多的请求。
4.可以模拟浏览器通过 URL 访问资源,浏览器通过 post 或者 get 发送 form 数据,浏览器发送自己的类型(IE,Chrome 版本号)
5.添加 header 也可以通过 request 的 add_header()来实现。6.有的网站可能需要识别浏览器的版本,python 爬虫默认的是 Python-urllib/x.y。可以伪
装成 IE,Chrome。
7.2 使用豆瓣 API 获得豆瓣电影数据
Python 可以很方便的实现爬虫。爬虫模拟浏览器,通过循环来扒取网页。但是,似乎也没有多么神奇,目前无法分析一个网页里面有哪些超链接,如果是扒取一个网页之后,通过解析 HTML 找到所有超链接的话,似乎可以实现。但是目前的扒取方式是找到网页之间的关联,比如贴吧的地址,第 1 页和第 n 页之间只有一个数字的差别,并且是满足倍数关系的,所以直接循环即可。
豆瓣提供了 API 来访问豆瓣的数据,通过豆瓣账号登陆,获得豆瓣的数据,这些都提供有 API,但是目前只对企业开发,所以个人无法获得 APIKey。
就算有 APIKey,对访问频率也有要求,每分钟不超过 50 次,如果没有,每分钟不超过 10 次。
通过访问豆瓣提供的 API(GETURL),豆瓣返回 JSON 格式的数据,比如电影的详细信息。
豆瓣上的电影页面,都是 https://movie.douban.com/subject/id/格式的 url。(如果是通过某个标签进入的话,后面会加入其他的)问题是 id 的数目过于庞大,id 为 8 位,至少有 300W 中可能。并且豆瓣电影的 id 不是连续的,而且找不到规律。所以,从 00000001 到 30000000 挨着试不可能,豆瓣似乎还会检测同一个 IP 的访问是否频率过快。
通过 API 访问,还是需要 ID,我们并不知道电影和 ID 之间的关系,还是需要一个一个试,显然不合适大规模的数据扒取。
id 和年份,种类无关。都是 8 位 id。
通过年份 TAG 扒取所有电影的纵览之后,解析里面的超链接,即可获得对应 ID。
1.通过年份 TAG 扒取所有的页面,注意设置时间间隔,每分钟 10 个就好。
2.扒取页面后,对所有页面中电影的超链接进行解析,提取后,再提取里面的 id,获得所有电影的 id。
3.有了 ID 后,通过豆瓣 API 获取所有电影的 JSON 信息。
大概步骤:
1.根据豆瓣网提供的,根据 Tag 查找电影的功能,将所有 Tag=年份的网页都爬下来。start 总是 20 的倍数,不同的年份也只是更改 tag 后的文件夹名称。所以,需要做的事情和扒取贴吧网页一样了,注意豆瓣检测 IP 访问的频率,所以最好一分钟不要超过 10 次。年份是固定的,写成 for 循环即可,每个年份内部的电影数目未知,while 循环直到返回 status 为 404 为止。
2.扒取所有 Tag 为年份的网页后,通过 HTMLparse 来提取出所有 class 为 nbg 的 tag 里面的超链接。这样,获得豆瓣网所有电影的 id。
3.获得 id 后,通过豆瓣网提供的 API 直接访问对应的 URI,电影的信息会以 JSON 的格式返回。但是频率有限制,每分钟不超过 50 次。
扒取单个年份网页并通过 beautifulsoup4 来 parseHTML 的代码:
import string
import urllib2
from bs4 import BeautifulSoup
content =
urllib2.urlopen(u'https://movie.douban.com/tag/2016?start=0&type=T'). read();
f = open('douban0ID.txt', 'w+')
soup = BeautifulSoup(content, 'html.parser')
for link in soup.find_all('a', class_='nbg'):
resultTemp = string.replace(link.get('href'), 'https://movie.douban.com/subject/', '')
result = string.replace(resultTemp, '/', '')
result = result + ' '
print(result)
f.write(result)
f.close() 1.bs4 很强大啊,HTML 和 XML 都可以 parse。
2.bs4parseHTML,可以直接通过 TAG 操作,可以通过 ID,可以通过 CLASS,获取所有超链接也是直接提供的功能,所以 soup.find_all('a',class_='nbg')直接搞定。
通过 ID 获得电影数据:
url1 = u'http://api.douban.com/v2/movie/subject/25986180'
content = urllib2.urlopen(url1).read() 豆瓣网专门的 API 获得 movie,book...的数据,访问 http://api.douban.com/v2/XXX/XXX/ID 来获得返回的 JSON 数据。
2.movie 可以替换成 book 或者其他。
3.subject 表示获得基本信息,也可以获得其他信息,具体参见 DOC。
处理返回的 JSON 数据:
1.JSON:一种从 JS 的对象字面量表示法中启发得到的轻量级数据传输格式,其实功能和 XML 一样。
2.JSON 分为{}和[]两种格式。前一种就是 CPP 里的 struct,js 里的 object,
python 里的 dictionary,lua 里的 map,C#里的关联数组,就是键值对的集合,键只能是字符串,值可以是任何数据类型,包括{}和[]。后一种就是数组,数组在 lua 这些脚本语言中是作为一种特殊的 map 处理的,只不过值必须是连续的脚标值。
3.JSON 的 encode 过程表示将 JSON(map,array。。。)dump 成对应的 string 类型,因为数据传输必须是 string。
4.JSON 的 decode 过程表示将 string 类型转换成语言对应的数据结构(不同语言有不同的数据结构,js 就是获得 object,python 就是获得 dictionary).5.通过访问豆瓣 API 获得就是 string 存储的 JSON 数据。需要通过 decode 编程 python 中的 dictionary。
python 语言处理 JSON:
python 有专门的 JSON 包来处理 JSON 数据。
1.encode:json.dumps(dictionary/array)。返回 string 类型的数据。2.decode:json.loads(string)。返回 dictionary 或者 list。代码实现:
doubanMovieJson = json.loads(content)
print(doubanMovieJson['summary'])
//通过返回的 dictionary 直接访问需要的数据。 获取豆瓣电影的 ID 列表:
豆瓣反爬虫,但是提供豆瓣 API,通过 API 可以访问豆瓣上电影的信息。但是 id 是未知的,需要首先获取所有电影的 ID 信息。(豆瓣电影的 ID 有 8 位和 9 位的,没有规律,并且爬虫限制频率,所以遍历不可行。通过扒取 TAG 下所有网页,parse 出 ID 的方式可以获得 ID 列表)
import string
import urllib2
from bs4 import BeautifulSoup #python 一个很好用的 HTML/XML parse 库。
import time #爬虫需要限制频率,豆瓣会检测 IP 的访问频率,过快会 封 IP。
f = open('doubanMovieID.txt', 'w+')
i = 1949
while(i < 2017):
urlToOpen0 = 'https://movie.douban.com/tag/'
urlToOpen1 = str(i)
urlToOpen2 = '?start='
urlToOpen3 = 0
urlToOpen4 = '&type=T'
index = 0
#这里做的事情,和扒取百度贴吧是一样的。
f.write(str(i) + " : ")
while (True):
#获取网页。
urlToOpen3 = 20 * index
content = urllib2.urlopen(urlToOpen0 + urlToOpen1 + urlToOpen2 + str(urlToOpen3) + urlToOpen4).read()
#通过 bs4parse 出 ID 信息。
soup = BeautifulSoup(content, 'html.parser')
hrefList = soup.find_all('a', class_='nbg')
# ‘nbg’这个 class 正好对应所有链接。
if(hrefList):
for link in soup.find_all('a', class_='nbg'):
resultTemp = string.replace(link.get('href'), 'https://movie.douban.com/subject/', '')
result = string.replace(resultTemp, '/', '')
result = result + ' '
print(result)
f.write(result)
time.sleep(5)
index = index + 1
else:
i = i + 1
break
f.close()
记录:
1.最后一共扒取了大概 4.5W 到 5W 个 id 数据。写到了 txt 中,用空格分开,方便后期直接 split 变成 list。
2.豆瓣通过年份分类的电影信息存在错误,有 1950 年的电影被分配到 1949 年的情况。所以 ID 是会出现重复的。
3.豆瓣通过年份分类页面访问所有电影信息是不完全的。通过网页下方的标签来访问只能访问这一年的部分电影。似乎是存在 bug,比如一个页面显示只有 1-25 个标签。但是通过 URL 中的 start=XXX,可以访问到第 26 个页面,同时开启隐藏的 26-50 页面(--)b。
4.扒取的过程中,本来打算通过 404 来判断这一年已经扒取完了,但是豆瓣的设计是就算是 start 超过了,也不会返回 404.所以通过判断解析出的 list 是否
为空来判断是否扒取完了。但是存在扒取中途突然出现 null 异常的问题。导致这一年的扒取不完。不清楚是什么问题。
5.代码没有做异常处理,有的时候会出现 URLError。
根据 ID 获取电影信息:
上一步只扒取了部分的 id 信息,一方面是因为只设置了 1949-2016.另一方面,上面的代码存在 bug,有的时候会出现没有异常,但是就是无法继续扒取下去的问题。
有了 ID 之后,split 处理成 list。遍历所有 list 通过豆瓣 API 获取电影条目信息。
import string
import urllib2 #get 请求不需要使用 httplib,urllib2 内部也是使 用 httplib 实现的。
import time #访问限制为 40 次/min。等待 2 秒钟。
itemCount = 0
for i in range(1949, 2017):
fIdName = 'doubanMovieId/doubanMovieID' + str(i) + '.txt' #读取存储了 id 的文件。
fId = open(fIdName, 'r').read()
fIdStringArray = fId.split(' ') #获得 ID list。
del fIdStringArray[len(fIdStringArray) - 1] #最后会多 出一个空格。去掉它。
fDetial = open('doubanMovieDetial/doubanMovieDetial'
+ str(i) + '.txt', 'w+')
for i in fIdStringArray:
urlHeader = 'http://api.douban.com/v2/movie/subject/' #豆瓣 API 前缀。获得 subject 里的信息。(subject 是电影条目信息,还有 celebrity,这个是电影人信息)
urlToOpen = urlHeader + i
try:
movieDetial = urllib2.urlopen(urlToOpen).read()
fDetial.write(movieDetial + '\n')
itemCount = itemCount + 1
print 'get ' + str(itemCount) + 'th itme!'
except URLError, e:
print 'There is an error!'
time.sleep(10000)
finally:
time.sleep(2)
fDetial.close() 记录:
1.对扒取下来的数据不是很满意,因为豆瓣 subject 中有的信息,比如演员和导演,是只给了 id 的,还需要在扒取演员的信息。
2.和扒取 id 的时候一样,使用 API 的时候有的时候会出现就是获取不到下一条数据,然后程序就停在那里。不报错,也不说出现异常。所以,没有把所有 id 放在一起,而是分块的进行扒取。难道说扒取 40 分钟就需要休息一下?
3.通过 subject 可以获得的,感觉有用的信息(通过用户的 query 进行匹配的数据):评分,想看人数,在看人数,收藏人数,条目分类,国家,日期,年代。4.演员,导演这个只有 id,需要另外扒取。
5.扒取的数据通过 string 存储在 txt 中,读取之后,通过'n'来 spilt,loads 之后获得对应的 list。
小结:
1.豆瓣对于爬虫,似乎会检测 IP 的访问频率是否过高。
2.豆瓣提供了 API 来访问豆瓣的数据。通过豆瓣账号登陆,获得豆瓣的数据,这些都提供有
API,但是目前只对企业开发,所以个人无法获得 APIKey。
3.就算有 APIKey,对访问频率也有要求,每分钟不超过 50 次,如果没有,每分钟不超过 10
次。
4.通过访问豆瓣提供的 API(GETURL),豆瓣返回 JSON 格式的数据,比如电影的详细信息。5.豆瓣上的电影页面,都是 https://movie.douban.com/subject/id/格式的 url。(如果是通过某个标签进入的话,后面会加入其他的)问题是 id 的数目过于庞大,id 为 8 位,至少有 300W 中可能。并且豆瓣电影的 id 不是连续的,而且找不到规律。所以,从 00000001 到 30000000 挨着试不可能,豆瓣似乎还会检测同一个 IP 的访问是否频率过快。
6.不使用 id 访问每个电影的明细页面,通过 TAG 来扒取数据,为了扒取所有的电影,最好使用年份 TAG 来扒取。
7.通过年份 TAG 扒取所有电影的纵览之后,解析里面的超链接,即可获得对应 ID。
8.通过年份 TAG 扒取所有的页面,注意设置时间间隔,每分钟 10 个就好。
9.扒取页面后,对所有页面中电影的超链接进行解析,提取后,再提取里面的 id,获得所有电影的 id。
10.有了 ID 后,通过豆瓣 API 获取所有电影的 JSON 信息。
11.最后总共扒取了豆瓣网上 2.4W 条电影的信息,应付专业实训估计足够了。
12.本次扒取因为豆瓣网虽然提供了 API,但是限制 API 频率,而且当访问总次数很高的时候,也会被限制。所以开了 4 台电脑。感觉就像手动分布式一样。分布式可以提高效率,毕竟同时开了好几台电脑。
13.豆瓣网会检测 IP 的访问次数,所以这次准备了 6 个 IP。每个 IP 最多扒取的数据个数在 2000 到 7000 左右。之后就会 403.
14.添加 header 的方法不可行,直接用 fiddler 截包获得的 header 也不行。15.如果一个 IP 被封了,那过一段时间就可以恢复,但是这次一般 200 左右就会再次被封。
7.2 遇到的问题:
1.豆瓣通过年份分类的电影信息存在错误,有 1950 年的电影被分配到 1949 年的情况。所以 ID 是会出现重复的。
2.豆瓣通过年份分类页面访问所有电影信息是不完全的。通过网页下方的标签来访问只能访问这一年的部分电影。似乎是存在 bug,比如一个页面显示只有 1-25 个标签。但是通过 URL 中的 start=XXX,可以访问到第 26 个页面,同时开启隐藏的 26-50 页面(--)b。
3.扒取的过程中,本来打算通过 404 来判断这一年已经扒取完了,但是豆瓣的设计是就算是 start 超过了,也不会返回 404.所以通过判断解析出的 list 是否为空来判断是否扒取完了。但是存在扒取中途突然出现 null 异常的问题。导致这一年的扒取不完。不清楚是什么问题。
4.对扒取下来的数据不是很满意,因为豆瓣 subject 中有的信息,比如演员和导演,是只给了 id 的,还需要在扒取演员的信息。
5.和扒取 id 的时候一样,使用 API 的时候有的时候会出现就是获取不到下一条数据,然后程序就停在那里。不报错,也不说出现异常。所以,没有把所有 id 放在一起,而是分块的进行扒取。难道说扒取 40 分钟就需要休息一下?
6.通过 subject 可以获得的,感觉有用的信息(通过用户的 query 进行匹配的数据):评分,想看人数,在看人数,收藏人数,条目分类,国家,日期,年代。
7.演员,导演这个只有 id,需要另外扒取。
8.扒取的数据通过 string 存储在 txt 中,读取之后,通过'n'来 spilt,loads 之后获得对应的 list。
1.?看来就算是用 API 访问,如果超过次数,或者访问次数很多。那还是会被封掉。
2.?可能需要对 header 进行模拟或者需要模拟登陆。(浏览器提示该网站可能需要登录。)
3.?添加 headers 的中 user-agent 是不行的。
4.?看来 IP 直接被封了。使用 API 还是不行,可能豆瓣提供 API 并不是给爬虫用的。链接不同的网络,更换 IP 吧。
7.4 总结:
1.最后总共扒取了豆瓣网上 2.4W 条电影的信息,估计足够了。
2.本次扒取因为豆瓣网虽然提供了 API,但是限制 API 频率,而且当访问总次数很高的时候,也会被限制。所以开了 4 台电脑。感觉就像手动分布式一样。分布式可以提高效率,毕竟同时开了好几台电脑。
3.豆瓣网会检测 IP 的访问次数,所以这次准备了 6 个 IP。每个 IP 最多扒取的数据个数在 2000 到 7000 左右。之后就会 403.
4.添加 header 的方法不可行,直接用 fiddler 截包获得的 header 也不行。
5.如果一个 IP 被封了,那过一段时间就可以恢复,但是这次一般 200 左右就会再次被封。