多模态基础模型:从专家到通用助手第四章
第四章 统一的视觉模型
在本章中,我们讨论了视觉模型的统一。我们首先概述了视觉模型统一面临的挑战,在第4.1节中为实现这一目标所做的最新努力。接下来是关于 (i)第4.2节中,详细讨论如何将闭集模型转换为开集模型; (ii)第4.3节中,如何统一不同粒度的视觉任务; (iii)第4.4节中,如何为视觉构建一个更可提示的界面。 最后,我们在第4.5节总结了本章并讨论了未来的趋势。
4.1概述
在谈论通用统一视觉系统之前,我们重新回顾了语言模型和自然语言处理(NLP)在过去几年中的演变。在2018年之前,不同的NLP任务由不同的特定任务模型处理,例如翻译(Bahdanau等人,2015)、语义解析(Berant等人,2013)、摘要(Allahyari等人,2017)等等。随着变换器结构的出现(Vaswani等人,2017),不同NLP任务的语言模型被统一成一个只有解码器的结构,例如GPT模型(Brown等人,2020)。之后,通过学习下一个单词预测任务,GPT模型被进一步微调以遵循人类指令。这导致了ChatGPT的出现,从根本上改变了我们对AI系统能做什么的期望。图1.1中描述的演变激励我们思考是否可以用类似的方式构建通用视觉系统。

挑战
计算机视觉任务之间的巨大差异给构建统一视觉模型带来了巨大挑战。
首先,视觉任务有不同类型的输入,从静态图像(Russakovsky等人,2015)到连续视频(Miech等人,2019),从纯视觉输入(如图像去雾(He等人,2010))到多模态输入(包括视觉和语言(Antol等人,2015)等)。
其次,不同任务需要不同粒度的处理,例如图像级别的任务,如图像分类(He等人,2016)和captioning(Vinyals等人,2016),区域级别的任务,如目标检测(Girshick,2015)和grounding(Plummer等人,2015),以及像素级别的任务,如图像分割(He等人,2017)、超分辨率(Wang等人,2020)等等。
因此,视觉系统的输出也是不同格式的,如空间信息(边缘、框和掩码)、语义信息(类标签、多标签标签或详细描述)。除了建模方面的挑战之外,还存在数据方面的挑战。首先,不同类型标签的注释成本差异很大。如图4.6所示,这些标签在粒度和语义丰富性方面有所不同,从整个图像、区域(框注释)到掩码(像素注释)。其次,一般来说,收集图像数据比收集文本数据要昂贵得多。因此,视觉数据的规模通常比文本语料库小得多。
面向统一视觉模型
尽管存在这些挑战,计算机视觉社区对开发通用、统一的视觉系统越来越感兴趣,尤其是针对视觉理解任务。如图4.1所示,我们将这些努力分为三类:

1.视觉与语言之间的桥梁
通过将闭集分类扩展到开世界识别,像CLIP(Radford等人,2021)这样的对比语言-图像模型展示了对于不同视觉任务的令人印象深刻的零样本转移能力。这些模型学习了原始视觉信号和丰富语义之间的映射,并且可以支持各种开词汇视觉识别任务.
2.统一的多任务建模
传统的特定任务视觉模型是使用特定任务的数据进行训练的。开发一个新任务的模型通常是极其昂贵的。因此,开发一个能够很好地适应许多视觉任务的统一视觉模型是可取的.
3.LLM-like可提示接口
LLM可以采用不同语言和上下文提示作为输入,并生成用户所需的输出,无需微调。通用视觉模型应该具备相同的上下文学习能力,以将输出与各种用户意图对齐,而无需更改其模型参数。
在以下部分中,我们将详细阐述每个类别中的具体技术与方法。
4.2 从封闭集合到开放集合模型
传统上,视觉识别被形式化为一个分类问题,它将原始视觉数据(例如图像)映射到离散的文本标签。例如,图像分类预测整个图像的预定义封闭集合中的标签(Deng等人,2009),而目标检测则识别图像中定义的封闭集合中的对象(Lin等人,2014)。然而,这种封闭集合模型很难转移到封闭集合(或词汇)不足的其他任务上。例如,使用Microsoft COCO对象集2训练的目标检测器很难应用于检测Minecraft对象。最近,CLIP(Radford等人,2021)通过引入对比语言-图像预训练方法来训练开放集合模型,解决了封闭集合模型的局限性。如图4.2(a)所示,CLIP不是学习从输入到标签的映射,而是使用数以亿计的图像-文本对学习一个对齐的视觉-语义空间。
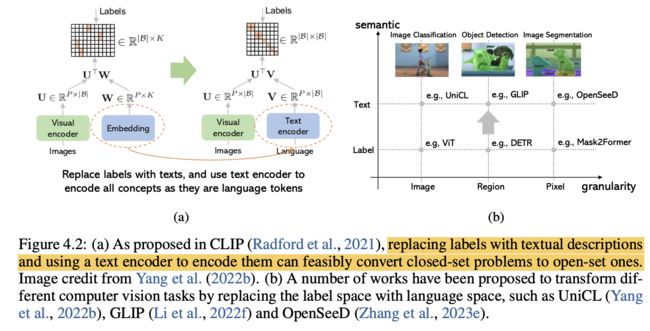
在CLIP模型(Radford等人,2021)发布后,已经开发了许多使用大量文本-图像对进行视觉理解的开放集合视觉模型,这些模型在不同粒度级别上执行不同水平的视觉理解任务(Yang等人,2022b;Zhang等人,2023e;Li等人,2022f;Ghiasi等人,2022a),这些任务从图像级任务(例如图像分类Deng等人(2009)、图像-文本检索、图像字幕陈等人(2015))、区域级定位(例如目标检测和短语接地Plummer等人(2015))到像素级分组任务(例如图像分割和指代分割Long等人(2015);Kirillov等人(2019);Hafiz和Bhat(2020))。
这些模型可以根据以下三个维度进行分类:模型初始化、设计和训练。
模型初始化
CLIP已初始化
许多最近的开放集合模型使用诸如CLIP之类的预训练模型进行初始化,因为预训练模型已经提供了一个良好对齐(但通常是粗粒度的)视觉-语义特征空间。例如,OVR-CNN(Zareian等人,2021)和RegionCLIP(Zhong等人,2022b)使用CLIP风格的预训练ResNet(He等人,2016)作为视觉编码器,并使用预训练的RPN(Ren等人,2015)提取区域特征。同样,MaskCLIP(Zhou等人,2022a)和FreeSeg(Qin等人,2023b)利用CLIP模型为像素提取密集标签。FC-CLIP(Yu等人,2023a)使用CLIP中的冻结ConvNeXt(Liu等人,2022b)卷积网络对各种分辨率的输入图像进行编码。
CLIP增强
这些方法不是使用CLIP参数初始化模型,而是使用通常的方式(例如,为模型参数设置随机值),但使用预先训练的CLIP帮助模型训练。例如,ViLD(Gu等人,2022)通过知识蒸馏将已对齐的CLIP特征增强到模型中。MaskCLIP(Ding等人,2022b)和Mask-Adapted CLIP Liang等人(2023a)在模型训练过程中分别依赖于预先训练的CLIP模型来提供特征和分数。
其他
一些作品使用有监督预训练模型或从头开始学习视觉-语义特征空间。例如,GLIP(Li等人,2022f)和OpenSeeD(Zhang等人,2023e)分别使用预训练的BERT模型(Devlin等人,2019)和CLIP文本编码器,并使用在ImageNet上预训练的视觉backbone进行图像编码。虽然这些分别预训练的图像和文本编码器没有明确地学习图像和语言之间的对齐,但事实证明这些模型仍然给出了良好的图像和文本表示,并且有助于高效模型训练。不同之处在于,GroupViT(Xu等人,2022a)从头开始使用开放集合语义分割任务和全局图像-文本对齐任务进行联合训练。ODISE(Xu等人,2023a)利用预训练的Stable Diffusion模型(Rombach等人,2022)来提取紧凑的掩码。
模型设计
两阶段模型Two-stage models
这些模型通常遵循基于DETR之前的模型设计(Ren等人,2015;He等人,2017),该设计将定位和识别解耦。对于目标检测,通常使用区域提议网络对目标进行定位(Zhong等人,2022b;Gu等人,2021),并使用掩码提议网络提取掩码(Ghiasi等人,2022a;Yao等人,2022a)。给定定位结果,使用预先训练的CLIP模型来衡量视觉内容与语言概念之间的相似性。两阶段模型的明显优势在于,它们可以继承开放集合语义理解能力而无需额外训练,因此可以将模型训练集中在要求高性能的定位网络上。
端到端模型End-to-end models
与两阶段模型不同,端到端模型遵循基于DETR的方法(Carion等人,2020;Cheng等人,2022)或其他一站式模型(Dai等人,2021)。GLIP(Li等人,2022f)是其中的代表性作品之一。GLIP将目标检测形式化为文本对齐,并使用带有检测和接地标签的图像-文本对进行端到端训练。后续工作通过实现更深层次的视觉-语言交互来增强GLIP(Liu等人,2023h)或使用DETR样式的模型设计(Zang等人,2022;Minderer等人,2022)。对于分割,ZegFormer(Ding等人,2022a)和OpenSeeD(Zhang等人,2023e)都利用了DETR样式的架构,并根据解码器的输出预测掩码和类别。
模型预训练
监督学习
通过将标签监督转换为语言监督,许多工作直接利用现有的监督注释来训练开放集模型。例如,OVR-CNN(Zareian等人,2021)使用COCO类别训练一个模型,然后评估它在新颖类别上的性能。同样,ViLD(Gu等人,2021)分别在COCO和LVIS数据集上训练和评估两个独立的模型。遵循类似的协议,许多工作在部分带注释的分割数据上训练开放集分割模型,并评估其在留出数据上的泛化能力(Ding等人,2022a,b;Zhang等人,2023e;Xu等人,2023a)。
半监督学习
人们可以使用带注释的数据和未标注或弱标注的数据。例如,RegionCLIP(Zhong等人,2022b)和GLIP(Li等人,2022f)使用教师模型从图像-文本对中提取精细的区域-文本对齐来增强训练数据,以获得更好的开放集检测性能。不同之处在于,OpenSeg(Ghiasi等人,2022b)使用Localized Narrative数据集(Pont-Tuset等人,2020)作为弱标注数据,该数据集提供语言短语和图像笔画之间的粗略对应关系。经验上,这种半监督学习方法通常有助于提高模型的泛化能力,因为它们可以有效地利用噪声数据中丰富的语义
弱监督学习
一些工作仅使用弱标注数据进行建模。例如,GroupViT(Xu等人,2022a)使用对比学习法,其中模型训练的所有监督来自正负图像-文本对。遵循相同的对比学习法,SegCLIP(Luo等人,2023b)使用收集机制来通过训练图像-文本对来学习合并图像补丁。
下面,我们将回顾为区域级和像素级任务开发的最新模型。
4.2.1 目标检测与定位
目标检测是计算机视觉中的基本任务,涉及在图像或视频序列中识别和定位感兴趣的目标(Viola和Jones,2001)。多年来,已经开发了各种技术和算法来提高目标检测的准确性和效率。在过去,基于区域的方法,如R-CNN Girshick等人(2015)、Fast R-CNN(Girshick,2015)和Faster R-CNN(Ren等人,2015),促进了先进目标检测技术的发展。为了提高实时性能,YOLO(Redmon等人,2016)提出了一种同时预测目标类别和边界框坐标的单神经网络。一些改进是通过在不同的尺度上使用多个特征图(Liu等人,2016)或引入焦点损失来解决密集目标检测场景中的类别不平衡问题(Lin等人,2017)。自从Transformer出现后(Vaswani等人,2017),DETR(Carion等人,2020)将Transformer结构应用于目标检测,将其视为一个集合预测问题。自DETR以来,已经提出了许多方法来从各个方面改进基于transformer的目标检测模型,例如DINO(Zhang等人,2022a)、Group DETR(Chen等人,2022b)和Co-DETR(Zong等人,2023)。
开放集目标检测模型旨在检测训练数据中提供的词汇之外的任意概念。文献中已经开发了三种主要的评估设置:
零样本目标检测
类似于零样本图像分类(Xian等人,2018),零样本目标检测限制用于训练的物体类别,并评估模型对新类别的迁移能力。属于这一类的方法主要关注评估模型如何利用预训练的概念嵌入(例如word2vec(Mikolov等人,2013))并学习良好的视觉语义对齐.
严格开放词汇目标检测
该设置在OV-RCNN(Zareian等人,2021)中首次引入,与零样本目标检测不同的是,只要不涵盖任何目标类别,训练词汇没有限制。在这种协议下,一些代表性作品是ViLD(Gu等人,2021)、RegionCLIP(Zhong等人,2022a)和Detic(Zhou等人,2022b),它们利用大规模语言-图像模型(Radford等人,2021;Jia等人,2021),并从图像标签数据中学习。
通用开放词汇目标检测
最近的一些作品,如GLIP(Li等人,2022f)和OWL-VIT(Minderer等人,2022),主张采用更灵活的设置来评估目标检测模型的数据集或任务可迁移性。这种设置允许训练集和测试集之间存在词汇重叠,例如用Objects365进行训练,用COCO进行评估。可以说,与上述两种设置相比,这是一个更实用的设置,因为模型可以使用任何任意训练数据集进行训练,并评估它们在野外环境中的检测性能(Li等人,2022b)。
物体定位可被视为一种广义开放集目标检测任务(Plummer等人,2015;Kazemzadeh等人,2014;Chen等人,2019;Deng等人,2018)。在此任务中,模型接受句子和图像作为输入,并对与名词短语相关的物体进行定位。
最近,M-DETR(Kamath等人,2021)采用基于变压器的架构来构建端到端调制检测器,以根据原始文本查询检测图像中的对象。与以前在特定数据集上训练模型的模型不同,该网络使用来自多模态数据集的130万对文本和图像进行预训练,其中文本短语和对应图像对象之间的连接是带标签的。受M-DETR启发,GLIP(Li等人,2022f)将目标检测视为定位问题,并联合学习用于开放集场景的目标检测和定位数据模型。沿着这一研究方向,DetCLIPv2(Yao等人,2023)提出了一种简单的联合学习方法,将多个任务转化为单词-区域对齐任务,然后在一个由目标检测数据、定位数据和图像-文本对组成语料库上端到端训练模型。Grounding-DINO(Liu等人,2023h)是一种最先进的地对地目标检测方法,其中目标检测器由组件组成:主干网络、颈部和头,并在每个阶段注入语言条件。采用组合文本和图像主干网络来提取多尺度特征,然后将其传递到颈部。颈部生成的文本和图像特征随后用于语言驱动的查询选择。Grounding-SAM是通过将Grounding-DINO与SAM(Kirillov等人,2023)结合而开发的。如图4.4所示,将图像和一组概念首先馈入Grounding-DINO以产生框,然后使用这些框作为提示来预测每个框的掩码。

4.2.2 图像分割和参考
图像分割是一个长期存在的具有挑战性的视觉问题,主要有三个子任务,包括语义分割(Long et al., 2015)、实例分割(Hafiz and Bhat, 2020)和全景分割(Kirillov et al., 2019)。语义分割关心的是图像中每个像素的语义(Long et al., 2015; Chen et al., 2017, 2022j),而实例分割将相同语义的像素分组到对象中。这两个任务的模型从CNN-based架构(Long et al., 2015)演变为transformer-based模型(Chen et al., 2022j),从两阶段模型(He et al., 2017)和单阶段模型(Bolya et al., 2019; Tian et al., 2020b)演变为最近的基于查询的方法(Dong et al., 2021; Zou et al., 2022)。具备逐像素和实例级别的理解能力之后,很自然的就可以考虑全景分割(Kirillov et al., 2019; Wang et al., 2021a; Cheng et al., 2022)。最近,Mask2Former(Cheng et al., 2022)提出了一种统一的encoder-decoder架构来解决这三个任务。然而,所有这些工作都只处理有限类别的数据。接下来,我们将回顾最近关于开放集图像分割和指代分割的研究。
开放词汇分割
最近,已经提出了一些将基础模型(Radford et al., 2021; Jia et al., 2021)的丰富视觉语义知识转移到特定分割任务的方法。突出的例子包括LSeg(Li et al., 2022a)、OpenSeg(Ghiasi et al., 2022a)和Huynh et al.(2022)。GroupViT Xu et al.(2022a)从头开始进行语言-图像预训练,使用自下而上的分组ViT(Dosovitskiy et al., 2021),而不是使用现有模型。DenseCLIP(Rao et al., 2022)证明了在微调设置中基础模型相对于监督模型的优越性。最近,MaskCLIP(Ding et al., 2022b)通过利用CLIP同时处理开放词汇的全景和语义分割,在ADE20K(Zhou et al., 2017)和PASCAL(Mottaghi et al., 2014; Everingham and Winn, 2011)上取得了令人印象深刻的性能。
最近一项工作称为FC-CLIP (Yu et al., 2023a)利用了一个卷积的CLIP后端(即通过OpenCLIP (Ilharco et al., 2021)训练的ConvNeXt)作为特征提取器和视觉编码器,而不是使用ViT主干。基于简化的管道,FC-CLIP展示了合理的效率和在各种开放词汇分割基准测试中达到领先水平。另一项新工作ODISE (Xu et al., 2023a)则利用文本到图像扩散模型,并表明预训练的UNet中的潜在特征可以提供有用的紧凑分割信息,用于开放词汇分割。
开放词汇分割面临的一个巨大挑战是缺乏带有语义标签的分割数据。迄今为止,大多数工作仍然使用COCO分割注释。一些近期的作品试图利用物体检测数据作为额外的监督来增强分割模型的训练,例如OpenSeeD (Zhang et al., 2023e)(如图4.5所示)和DataSeg (Gu et al., 2023)。除了这些新的建模技术外,还开发了新的数据集来缓解这个问题,包括多域分割数据集的整理(Lambert et al., 2020)、高质量标注的收集(Lu et al., 2023c)或扩大到数十亿个mask(Kirillov et al., 2023)。

引用分割是开放词汇的
模型通常被设计为特定地学习目标数据集,使用各种多模态融合策略(Hu et al., 2016; Liu et al., 2017; Margffoy-Tuay et al., 2018; Ye et al., 2019a; Yu et al., 2016; Wu et al., 2022a)。CLIPSeg(Lüddecke and Ecker, 2022)将文本查询扩展为视觉查询,并表现出在引用分割和语义分割上的卓越性能。自从视觉变换器出现以来,LAVT(Yang et al., 2022e)等作品从一开始就增强跨模态交互,这在RefCOCO(Yu et al., 2016)、RefCOCO+(Yu et al., 2016)和G-Ref(Mao et al., 2016; Nagaraja et al., 2016)上取得了相当不错的性能。不同的是,PolyFormer(Liu et al., 2023e)将掩码转换为多边形,并要求变换器解码器解码一系列多边形坐标。受Pix2Seq(Chen et al., 2022c)的启发,这是在目标检测中的类似方法,PolyFormer为引用分割提供了另一种表示掩码的方法。正如我们之前讨论的,也可以将Grounding DINO(Liu et al., 2023h)与SAM(Kirillov et al., 2023)组合用于引用分割。
统一分割
对于上述的开放词汇和引用分割方法,一个公开的问题是如何将所有分割任务统一在一个框架中。最近,X-Decoder (Zou et al., 2023a)使用通用的编码器-解码器架构来统一所有这些分割任务。引用分割任务被重新定义为条件全景分割,该任务将一些文本短语作为输入输入到解码器中。UNINEXT (Yan et al., 2023)是另一项尝试统一所有图像和视频中的实例级分割的工作。与X-Decoder不同,UNINEXT使用早期融合来融合各种提示和视觉特征,然后将其馈送到变换器编码器-解码器中。
4.3 从特定任务模型到统一模型
上述我们已经讨论了为进行检测和分割而将闭集模型转换为开集模型的最新努力。然而,直到最近,大多数视觉任务都是通过专门设计的模型单独解决的,这阻碍了不同粒度或领域之间的任务协同作用被充分利用。这可能是由于两个原因造成的:
视觉任务是碎片化的
如图4.6(a)所示,计算机视觉任务跨越不同的轴,包括空间、时间和模态。从空间方面来看,它可以是我们之前讨论的图像级、区域级和像素级任务。沿着时间轴,我们需要解决的不仅是静态图像,还有视频序列。关于模态,输入和输出可以是图像、文本或其他类型(例如人体姿势、深度图)。如此多样化的任务格式严重阻碍了针对所有任务的统一模型的开发。

数据尺度不同
除了复杂的任务场景,人类注释的稀缺以及不同任务的不同尺度也使得构建统一的模型具有挑战性。在图4.6(b)中,我们可以看到一个清晰的数据规模金字塔,其中不同层次的人类注释具有不同的语义。更具体地说,像LAION Schuhmann等人(2021)这样的图像文本数据集包含多达2B个样本,而像Objects365(Shao等人,2019)这样的对象检测数据集总共包含1.7M张图像。由于标注掩模的高成本,在分割数据集中观察到更大的差距。
尽管存在上述挑战,但由于Transformer的通用性(Vaswani et al.,2017),我们现在看到人们对构建统一通用模型的兴趣日益增长,这种模型可以从各种视觉和视觉-语言任务中学习并应用于这些任务。这些尝试可以归为两大类:
I/O统一
在统一大型语言模型(LLM)的发展之后,许多近期的研究将许多视觉任务重新表述为序列到序列(sequence-to-sequence)问题(Wang等人,2022b;Yang等人,2022c;Chen等人,2022d;Lu等人,2022a)。他们通常使用一个标记器(tokenizer),将各种任务中使用的原始输入和输出(I/O)的不同模态分解成连贯的序列(视觉或文本标记),然后利用一个统一的序列到序列模型。
功能统一
除了I/O统一之外,还可以通过功能统一来构建一个通用模型。扩展多任务学习方法(Lu等人,2020;Gupta等人,2022a;Hu和Singh,2021a),许多近期的工作使用一致的编码器-解码器架构(Yu等人,2022a;Zhang等人,2022b;Zou等人,2023a)。这一类工作通常不需要特定任务或特定模态的标记器,但需要一个复杂的模型设计来适应各种任务。
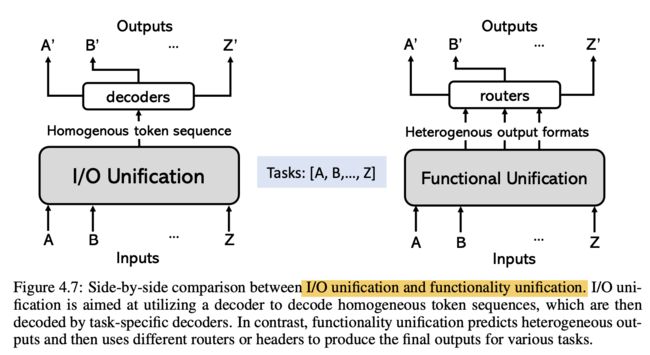
图4.7说明了两种类别统一方法的区别。对于I/O统一,I/O统一模块始终生成一个标记序列,并使用单独的解码器对不同任务的最终输出进行解码。对于功能统一,功能统一模块为不同任务生成不同类型的结果,例如语义输出和空间输出。然后,这些不同类型的结果组合产生最终特定任务的结果。这两种统一方法都努力利用不同粒度级别的任务之间的协同作用。例如,粗粒度数据有助于为细粒度任务所需的丰富语义理解做出贡献,而细粒度数据则可以增强粗粒度任务的接地能力。在以下部分中,我们将回顾这两类方法中的一些最新工作。
4.3.1 I/O统一
这一系列工作主要受到统一许多NLP任务为序列建模的大型语言模型(LLMs)的启发。在视觉领域,通过I/O统一建立通用模型的方法可以根据所关注的和输出格式的任务分为两类。
Sparse和离散输出
对于产生稀疏或离散标记输出的视觉任务,我们可以很容易地利用语言标记器,例如字节对编码(BPE)(Sennrich et al.,2016),进行I/O统一。相反,像框、掩码或人体骨架这样的空间输出可以表示为数字坐标的序列,然后被标记为离散标记(Cho et al.,2021;Yang et al.,2022c;Liu et al.,2023e)。因此,解码的输出标记与有机文本标记和数字文本标记交织在一起,以支持各种任务。
UniTab (Yang et al., 2022c)采用序列解码的方式统一处理文本和框输出。如图4.8(a)所示,框坐标以数字形式表示,并使用特殊标记来表示位置信息。通过这种方式,该模型可以统一处理多种需要文本和位置输出的任务,包括图像标注(Chen et al.,2015)、基于图像的标注(Plummer et al.,2015)、视觉定位、目标检测和视觉问答(Antol et al.,2015)。该模型的训练分为三个阶段:预训练、多任务微调和特定任务微调。
Pix2SeqV2(Chen et al.,2022d)与UniTab略有不同,它将两种不同的视觉任务统一起来:引用分割和关键点检测。遵循Pix2Seq(Chen et al.,2022c)的方法,Pix2SeqV2将图像中的目标表示为[ymin,xmin,ymax,xmax,text]。然后,它为每个任务引入了独特的任务提示,其中包含任务类型信息或任务类型和特定位置的组合。对于掩码解码,掩码轮廓被转换为多边形,然后从多边形中提取出其坐标(Castrejon et al.,2017)。对于引用分割,也采用了类似的策略,类似于Polyformer(Liu et al.,2023e)。
LLM增强
最近的研究还探索了基于LLM构建通用解码接口,LLM是在大量文本数据和人类指令上预先训练的。Kosmos-2(Peng等人,2023b)利用了Kosmos-1(Huang等人,2023b)的预训练LLM,并通过收集由9100万张图像组成的网络规模的图像-文本对数据集(GRIT),增强了基于真实场景的多模态数据。VisionLLM(Wang等人,2023h)在图像标记器上附加了一个更大的LLM(例如LLaMa(Touvron等人,2023)),如图4.9所示。由此产生的模型具有非常强大的视觉语言推理能力,以及在物体检测、分割等方面的良好定位能力。其他一些将LLM与基础相结合的工作有DetGPT(Pi等人,2023)和GPT4ROI(Zhang等人,2023k)。为了进一步使模型具备分割能力,BubaGPT(赵等人,2023c)和LISA(Lai等人,2023)都使用额外的参考分割模型,分别通过将文本或嵌入作为输入来分割图像。PaLI-X(Chen等人,2023g)是迄今为止能够应对多语言视觉和视觉语言任务的最大的统一模型。
密集和连续输出
还有一些任务需要密集和连续的输出,例如图像分割(He等人,2017)、深度估计(Mertan等人,2022)、图像修复和编辑(Elharrouss等人,2020;Brooks等人,2023)。除了分割掩码可以用多边形近似以外(Liu等人,2023e;Chen等人,2022d),大多数密集和连续输出不容易转换成离散标记,因为视觉特征空间是高维的。因此,我们必须求助于面向图像的标记器。类似于语言标记器,图像标记器对原始图像进行编码并提取跨越视觉特征空间的离散标记。最具代表性的工作是VQ-VAE(Oord等人,2017;Razavi等人,2019)。如图4.10(a)所示,VQ-VAE学习一个编码器ze和一个解码器zq以及一个由K个嵌入组成的离散码本e = {e1,..., eK}。

作为VQ-VAE的一个变体,VQ-GAN使用鉴别器和感知损失(Larsen等人,2016;Lamb等人,2016)来在输出质量和模型效率之间保持良好的平衡(通过高压缩率)。在图4.10(b)中,我们看到鉴别器在补丁级别上应用,以规范高分辨率图像的解码。下面,我们将讨论一些最近的工作,这些工作试图统一涉及密集输出的不同视觉和多模态任务。
UViM(Kolesnikov等人,2022)是首批采用密集解码过程来统一各种核心视觉任务的工作之一,这些任务包括全景分割、深度估计和彩色化。学习过程包括两个阶段:(i)学习基础编码器-解码器f和限制性Oracle Ω,以预测给定输入图像的输出,其中f将原始图像作为输入,Ω将所需输出作为输入来解码Oracle代码;(ii)模型不是将所需输出作为输入传递给Oracle Ω,而是学习一个语言模型来为输入原始图像生成Oracle代码。值得注意的是,这里使用的编码器-解码器模型是使用VQ-VAE目标进行训练的。作为使用单个模型统一视觉任务的初步尝试,UViM在三个视觉任务上展示了有希望的结果。
Unified-IO(Lu等人,2022a)是另一项代表性作品。与UViM相比,它扩展到了更多的视觉任务和数据集。与UViM的训练过程不同,Unified-IO首先为不同的任务训练不同的VQ-VAE模型,如图4.11左图所示。获得所有VQ-VAE编码器-解码器后,将90个数据集组合起来训练另一个端到端的变压器编码器-解码器,如图4.11右图所示。与之前的工作类似,它还使用语言解码器获得有机和数字文本以生成坐标输出。在第二阶段预训练之后,该模型在GRIT基准(Gupta等人,2022c)上达到了最先进水平,并表现出引人注目的组合性,尽管在常见任务上的性能仍然落后于最强的模型。作为后续工作,Ning等人(2023)提出了一种软标记策略来提高下一个标记的解码准确性。此外,还提出了一种掩码建模策略来学习稳健的表示。在实例分割和深度估计上评估,该模型在NYUv2(Silberman等人,2012)上达到了最先进的性能,在分割上具有竞争性的性能。最近的一项工作使用图像修复作为一般任务来统一不同的像素级视觉任务(Bar等人,2022)。给定VQ-GAN产生的目标离散标记,该方法利用掩码自动编码器解码缺失的图像区域,使用任务输入-输出示例作为提示。Painter(Wang等人,2023i)扩展了此管道以促进更多的视觉任务,并在各种标准基准测试中获得了具有竞争力的性能

Diffusion-augmented.
与学习自己的解码模型的上述作品不同,一些近期作品利用现成的稳定扩散模型来构建通用的视觉模型。例如,Prompt Diffusion(Wang等人,2023m)使用Stable Diffusion和ControlNet(Zhang和Agrawala,2023)初始化一个模型,并同时在包括分割、深度估计等在内的六个不同的视觉-语言任务上联合训练上下文图像到图像模型。InstructDiffusion(Geng等人,2023)也使用扩散模型,但明确地将特定任务的指令引入扩散过程中。此外,它使用特定任务的训练和人类对齐训练来为视觉任务提供通用的接口。
4.3.2 功能统一
与I/O统一不同,功能统一试图根据任务特征来统一不同的任务,同时意识到它们既不是完全隔离的,也不是完全对齐的。在高级别上,视觉任务产生三种类型的输出:(i)位置输出,(ii)语义输出,(iii)像素级输出。例如,目标检测和短语定位都需要在图像中定位目标,而通用分割和引用分割都产生掩码。另一方面,许多任务需要语义(或文本)输出来表示概念名称或文本描述。
多任务学习
早期的一些作品探索了多任务学习方法来统一不同的视觉或视觉-语言任务。
视觉模型
一些早期作品探索了使用CNN来学习不同视觉任务的不同级别。例如,Cross-stitch Networks(Misra等人,2016)开发了一种从CNN顶部不同数量层分裂的策略,以适应不同的视觉任务。结果表明,表现最佳的多任务架构取决于所关注的的任务,并且很难推广到新任务。UberNet(Kokkinos,2017)更进一步,使用单一的通用CNN架构并精心设计路由机制来节省内存和计算成本,如图4.12(a)所示。这两项工作都需要对CNN架构进行一些调整,以便能够适应不同级别的任务和损失类型。但遗憾的是,它们无法建立跨任务的协同作用,以提高模型性能。Taskonomy(Zamir等人,2018)专门研究了视觉任务之间的关系。它首先为每个单独的任务训练特定任务的模型,然后在潜在空间中执行跨任务的转移建模。然后计算任务在潜在空间中的亲缘关系,为我们提供任务图谱。结果表明,视觉任务在不同的组中具有不同的亲缘关系。例如,表面法线估计与重塑和点匹配密切相关。曲率提取与图像分割任务有关。这项研究为多任务视觉建模提供了深刻的见解(Xu等人,2018;Crawshaw,2020)。
多模态模型
Transformer的出现极大地促进了多任务多模态学习的发展。其中,12in1(Lu等人,2020)是基于BERT的单一架构结合12个视觉-语言任务的先驱作品之一。它为每个任务使用特定任务的头,并使用共享的主干ViLBERT(Lu等人,2019)。结果表明,多任务学习可以实现比单任务学习更大的改进,同时显着减少模型参数。后来,UniT(Hu和Singh,2021b)采用编码器-解码器架构,扩展到仅视觉任务,如目标检测。此外,它允许在任务池上进行端到端训练,而不需要依赖预先训练的检测器。类似于12in1,它也使用每个任务的特定头,这是由于经验结果表明共享相同的头通常会损害性能。同样,E2E-VLP(Xu等人,2021)提出了用于定位任务和文本生成的端到端管道。UniT和E2E-VLP都证明了DETR(Carion等人,2020)的编码器-解码器架构的多功能性。遵循相同的精神,GPV(Gupta等人,2022b)提出了一个针对不同视觉和视觉-语言任务的端到端任务无关架构。它使用DETR来提取框和区域特征,然后利用跨注意力模块进行融合,接着是视觉解码器和语言解码器来解码不同的输出。
上述视觉和多模式模型通过采用针对不同任务而设计的不同模块或头来统一不同的任务,并且很难实现跨任务的协同作用。在以下部分中,我们讨论了最近的模型统一研究,旨在充分利用各种视觉和多模态任务之间的协同作用。
统一学习
由于Transformer(Vaswani等人,2017)的使用和前面讨论的开放集模型的发展,跨任务的障碍逐渐模糊。现在可以将来自不同模态的输入绑定在一起,以学习共享的语义空间。最近已经提出了一些作品(Zhang等人,2022b;Zou等人,2023a;Li等人,2023g)通过使用一个模型来统一视觉和视觉-语言任务。在预训练之后,单个模型可以以零样本方式应用于解决所有任务,并且可以通过特定任务的微调进一步改进性能。需要注意的是,这种上下文中的统一学习与之前的大规模预训练工作不同。像GPT在预训练后作为通用语言接口一样,统一的视觉模型不仅是一个表示学习引擎,还是一个支持尽可能多的任务以零样本方式的接口。下面我们回顾一些有代表性的作品。
GLIPv2(Zhang等人,2022b)是通过扩展GLIP(Li等人,2022f)而提出的,以支持广泛的视觉和视觉-语言任务,包括基于图像的描述生成、视觉问答等。GLIPv2通过三个不同的预训练任务无缝地融合了定位预训练和视觉-语言预训练(VLP):(i)短语定位,作为检测任务的视觉-语言适应;(ii)区域-单词对比学习,引入了一个新颖的区域-单词级别的对比学习任务;(iii)掩码语言建模。在零样本方式下,这个预训练模型可以应用于不同的任务,并取得可观的性能。与之前的作品不同(例如GPV(Gupta等人,2022b)),它以连贯的方式合并了定位模块和视觉-语言匹配模块,这使得融合数据的模型训练更加高效和有效。
X-Decoder(Zou等人,2023a)遵循通用编码器-解码器架构设计。给定一个输入图像,它首先使用图像编码器来提取多个尺度的特征。之后,使用文本编码器将文本查询编码成一组嵌入。视觉特征、文本查询和非语义或潜在查询被送入解码器来预测输出。提出了三个关键设计来增强X-Decoder对各种视觉和视觉-语言任务的泛化能力:(i)定义了两种类型的查询和输出。具体来说,解码器的查询分为潜在查询和文本查询,分别执行通用视觉和视觉-语言任务。同样,输出也分为像素级掩码和语义嵌入;(ii)使用单个文本编码器来编码所有任务的文本语料库。通用文本编码器用于编码引用短语、文本描述和图像字幕,分别用于引用分割、图像-文本检索和图像字幕任务;(iii)完全解耦图像和文本编码器,并将所有输出用作查询。因此,它可以同时学习图像内的监督和跨图像的监督,这对于学习更强大的像素级表示和支持不同粒度的任务至关重要。如图4.13所示,预训练模型可以通过采取不同的路由来支持不同的任务,同时共享相同的参数套件。 
Uni-Perceiver-v2(Li等人,2023g)是另一个通用模型,它统一了视觉和视觉-语言任务。与X-Decoder类似,该模型利用视觉编码器、文本编码器和通用解码器。不同的是,它在视觉主干上引入了一个区域提议网络,以明确地预测框和蒙版,然后将它们编码为“查询”,供通用解码器使用。为了在具有定位和没有定位的数据集上进行联合训练,它引入了一个统一的最大似然估计策略,适用于具有定位和没有定位的任务。
4.4 从静态模型到可提示模型
大型语言模型(LLMs)如ChatGPT(OpenAI,2023b)的成功表明了现代AI模型在与人类互动中的重要性,并为AGI(Bubeck等人,2023)提供了一线希望。与人类互动需要一个用户友好的界面,该界面可以接受尽可能多种类的人类输入,并生成人类可以轻松理解响应。在NLP中,这种通用交互界面已经出现并发展了一段时间,从早期的GPT(Brown等人,2020)和T5(Raffel等人,2020)模型到更先进的提示(Shin等人,2020;Zhao等人,2021;Li和Liang,2021)和链式思维(Wei等人,2022a;Kojima等人,2022;Schick等人,2023)等技术。然而,大多数视觉模型仍然是静态的,因为它们对各种提示的灵活性不如LLMs。最近,许多工作提出了增强静态视觉模型的能力,以支持:(i)多模态提示;(ii)上下文提示。
4.4.1 多模态提示
视觉本质上不同于语言。为了实现人类与AI之间的顺畅交互,模型不仅需要语言提示,还需要其他类型的提示来补充缺失的信息或消除语言歧义。最近,许多工作探索了如何将语言提示与其他类型的提示(如空间提示(Kirillov等人,2023)、视觉提示(Zou等人,2023b)和其他模态(Girdhar等人,2023;Liu等人,2023f))结合起来或进行增强。下面我们回顾一些代表性作品。
空间提示
视觉根植于物理世界,因此它不仅具有语义性,本质上还具有空间性。空间提示可以被认为是一种通过位置信息输入来调制视觉模型的方式,这些位置信息可以是点、框或任意笔画等。这些线索在计算机(例如鼠标)和移动设备(例如触摸屏)的UI设计中得到了大量使用。在计算机视觉中,交互式分割(Mortensen和Barrett,1998;McGuinness和O’connor,2010;Chen等人,2021c,2022i)自然需要这种能力,以便模型可以接收来自用户的多个点击并逐步细化分割掩码。然而,这些工作大多数仍然是针对特定任务设计的,缺乏足够的灵活性来支持不同类型的空间提示。
SAM(Kirillov等人,2023)是提出方便的空间提示接口并学习图像分割基础模型的先驱工作之一。如图4.14所示,该模型可以以点或框作为提示,以任意粒度对图像进行分割。该模型可以根据人类的用户指令进行分割,使得其能够轻松地构建更多的模型和应用(Zhang等人,2023c)。举几个例子,许多作品(Ma和Wang,2023;Roy等人,2023)从SAM开始,为医学领域训练了一个可提示的分割模型。空间提示特别有益,因为医学图像的文本注释通常很有限且难以解释。其他行业领域也有类似的情况(Tang等人,2023a)。为了进一步改进点提示,SAMAug(Dai等人,2023a)提出使用最大熵准则和显著性图来细化点,这可以帮助确定模型应该查看的最具信息量的位置。

视觉提示
在许多情况下,物体的文本描述不一定能够清楚地传达信息。例如,对于无法识别或无法描述的物体,人们可能无法清晰地表达有关该物体的信息。在这种情况下,显示一个或几个示例将更加信息丰富和直观。基于这个想法,许多作品研究了基于示例的视觉建模,例如图像到图像检索(Yoon等人,2021;Datta等人,2008;Zhang等人,2018)、图像协同分割(Joulin等人,2010;Jerripothula等人,2016)和视觉对象跟踪(Yilmaz等人,2006;Luo等人,2021;Wu等人,2013)。最近,这种策略已经被制定为视觉提示,因为不同种类的视觉输入通常被编码为某种统一格式,然后输入到一个Transformer架构中,如图LLMs所示。

SEEM(Zou等人,2023b)是使视觉模型进行图像分割的视觉提示的代表性作品之一。如图4.15所示,SEEM与上述SAM不同,可以在目标图像或另一个参考图像上绘制点、框和笔画以获取视觉提示。它开发了一个名为视觉采样器的新模块,可以根据用户指定的位置从图像中提取视觉特征。基于视觉采样器,该模型甚至可以像没有任何训练一样将另一个参考图像作为输入。因此,它不仅在各种图像分割任务中表现出令人印象的性能,而且在零样本方式下进行视频对象分割时也表现出令人印象的性能。
PerSAM(Zhang等人,2023h)在SAM的基础上开发了一个个性化的分割模型,并以一个镜头作为输入。它学习一个特定的模型,该模型以源图像加上掩码作为输入,然后预测目标图像的掩码。为了提取视觉提示,采用了掩码池化并将其作为解码器的输入标记。它还提出了一种基于特征匹配提取正负先验的方法,以促进具有全面线索的预训练SAM模型。与LLMs中的大多数提示学习方法一样,PerSAM的一个明显特点是它可以很容易地获得一些现成的模型,如SAM。SAM-PT(Rajicˇ等人,2023)进一步将这种策略应用于视频对象分割。受到SAM中空间提示的启发,它利用点跟踪系统(Harley等人,2022)来跟踪不同的点(包括正点和负点),然后要求SAM根据给定的点对图像进行分割。它表现出强大的点跟踪性能和分割性能。
其他
其他一些作品结合了多种视觉提示类型。例如,Painter(Wang等人,2023i)将不同的视觉任务(例如,深度估计、图像分割)重新表述为提示并学习一个上下文学习方式的解码器。提示是原始图像和相应的密集注释(例如,深度或分割图)的组合。相比之下,Prismer(Liu等人,2023f)利用许多现成的视觉模型从原始图像中提取不同信息,然后将信息馈送到视觉语言模型。为了促进不同模态之间的相互作用,ImageBind(Girdhar等人,2023)学习了图像/视频、语言、音频和深度之间的通用对齐。一旦学会了嵌入空间,就可以通过简单地进行求和来组合不同类型的提示。
4.4.2上下文提示学习
许多大型语言模型(例如GPT-3(Radford等人,2019))已经观察到上下文学习能力,这使得模型可以通过提示进行配置,而无需更新任何模型参数。相比之下,到目前为止,视觉模型的上下文学习能力仍然较少被研究。Flamingo(Alayrac等人,2022)是展示多模态输入上下文语言生成的先驱工作之一,这是通过从交错图像文本对数据中学习而获得的。同样, Kosmos-1(Huang等人,2023b)是另一种采用视觉输入作为外语的工作,因此大型语言模型的上下文学习能力可以自然地转化为多模态输入。然而,这两种方法都以多模态数据为输入,但仅生成文本输出。正如我们之前讨论的,视觉任务需要不同类型的输出,而不仅仅是文本。如何赋予视觉系统上下文学习能力仍然是一个悬而未决的问题。下面,我们回顾了近期为实现这一目标所做的尝试。
Bar等人于2022年提出了通过图像修复来教授模型预测密集输出的视觉提示方法,例如边缘、掩码、深度等,如图4.16所示。给定输入图像x∈(RH×W×3)和二进制掩码m∈{0,1}H×W,图像修复模型旨在预测缺失区域y=f(x,m)。作者利用预训练的VQ-GAN将原始图像编码为离散标记,并要求另一个ViT编码器预测掩码区域。为确保模型理解图像中的视觉“上下文”,作者收集了一个名为Computer Vision Figures的新数据集,该数据集由来自Arxiv论文的88k张图像组成。预训练后,该模型用于预测右下角的图像内容。
与此同时,Painter(Wang等人,2023i)将视觉上下文学习的类似想法扩展到了更多元化的数据集和基准测试中。与Bar等人(2022)不同,Painter预测输出位于连续像素空间,而不是离散标记。对于不同的任务,作者们定义了将输出空间转换为图像空间的规则。例如,对于分割任务,它使用不同的颜色表示图像中不同的个体实例。在统一输入和输出格式后,作者们使用标准ViT作为编码器,并使用掩码图像建模(He等人,2022a)。后续工作SegGPT(Wang等人,2023j)建立在Painter的基础上,专门针对图像分割任务而设计。预训练模型可以轻松扩展到基于示例的图像分割任务中。
Hummingbird(Balazˇević等人,2023)采用了不同的方法进行上下文视觉学习。与使用掩码建模不同,作者提出利用目标图像和源图像之间的注意力来聚合信息。如图4.18所示,该模型采用多个输入图像(第一行)和相应的语义标签图(第二行)。给定查询图像,它首先找到提示图像中与查询点最近的特征位置,然后将相同的匹配项投影到语义标签图中,以便为目标查询聚合标签。这种策略类似于早期基于K-最近邻的分类模型,但应用于密集预测任务的方式不同。

讨论:
上下文学习可以说是一个吸引人的特性。一方面,有许多作品试图将视觉与大型语言模型(LLM)联系起来,以继承上下文学习的能力,如Flamingo(Alayrac等人,2022)和Kosmos-1(Huang等人,2023b)。另一方面,研究人员求助于纯视觉基础上的上下文学习,以解决视觉特定的任务,如图像分割、深度估计等。迄今为止,还没有一个单一的模型能够以上下文学习的方式同时接受多种模态输入和预测不同类型的输出,这可能会成为这个领域一个充满希望的未来发展方向。
4.5总结与讨论
最后,图4.19展示了本章所涵盖的作品的直观总结。视觉领域中有一个明显的趋势是构建开放世界、统一和交互式的视觉模型。然而,视觉与语言之间仍存在一些内在差异。首先,视觉不同于语言,它以原始信号捕捉物理世界。我们需要开发一些复杂的标记化方法,将原始数据压缩成紧凑的“标记”。在语言领域,这可以通过使用一些成熟的启发式标记器(Sennrich等人,2016)轻松完成。其次,与语言不同,视觉数据本身没有标记,因此难以传递信息或知识。它总是需要人类劳动力以语义或空间的方式注释视觉内容。第三,语言数据是同质的,而视觉数据和任务是异质的。最后但同样重要的是,存储视觉数据的成本要高得多。例如,GPT-3消耗45TB的训练数据,而包含1.3M个图像的ImageNet数据集成本超过数百千兆字节。当涉及到像Howto100M(Miech等人,2019)这样的视频数据时,存储成本已经超过了GPT-3的训练语料库。所有这些差异引发了一些需要视觉社区解决的公开问题,详见下文。 
计算机视觉在野外
由于其异构性质,我们用于训练模型当前的视觉数据几乎无法涵盖物理世界的全貌。尽管我们在构建开放集视觉模型方面做出了努力,但在应对新颖或长尾场景方面仍面临重大挑战。
视觉中的规模定律
正如Kaplan等人(2020)、Hoffmann等人(2022)所讨论的那样,随着模型大小、数据规模和计算量的增加,大型语言模型的性能稳步提高。随着规模的增加,LLM中进一步观察到一些有趣的涌现属性。相比之下,目前尚不清楚规模视觉模型的正确途径是什么,更不用说这些模型中涌现的属性了。
以视觉为中心或以语言为中心的模型
目前,视觉和语言之间的界限逐渐被消除。然而,由于视觉和语言之间的内在差异,目前尚不清楚我们是否应该进一步扩大视觉模型并整合语言模型,或者适度视觉模型和LLM的结合是否足以解决大多数(如果不是全部)问题。
综上所述,我们离能够像人类一样感知世界的高度智能化的视觉系统还有很长的路要走。我们希望本章的文献综述能够提供现有努力的全面概述,并激发对下一代视觉模型的追求。
微信公众号
如果你觉得本文对你有帮助,欢迎关注微信公众号--计算机视觉前沿,获取更多精彩。

本文由 mdnice 多平台发布