pytorch gru rnn lstm 整理
其他人的博客里对于参数之类的讲解已经很详细了,这里汇总一下我看到的可能有用的资源,首先是lstm等的pytorch实现的直观理解,然后是gru的手动实现,rnn和lstm类似。rnn类似的网络,并不是一次输入1句话,而是每次输入一个单词。例如[[11,12,13,14],[21,22,23,24]],每个数字代表一个单词,输入的时候,是按照(11,21),(12,22),(13,23),(14,24)的顺序输入的。
1.pytorch
(参考AI有道:https://zhuanlan.zhihu.com/p/64185153)
如下图所示,输入是[1,100,100]的,第一个100代表序列长度,第二个100代表维度,输出包含3部分,ht代表了100步上的所有输出,是[1,100,512]的;ht和ct是最后一步的状态,是(1,1,512)的,如果想获取每一步的ht和ct,可以参考第二部分的实现过程。
rnn的用法类似:
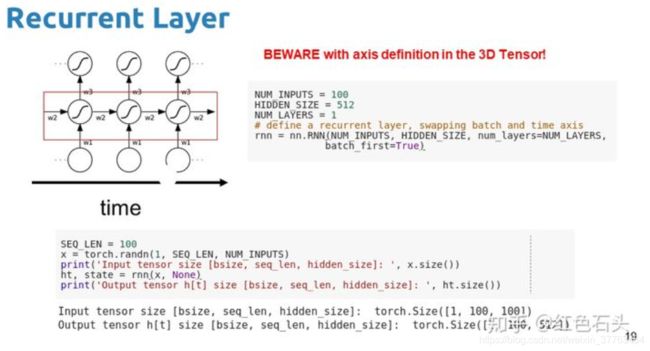
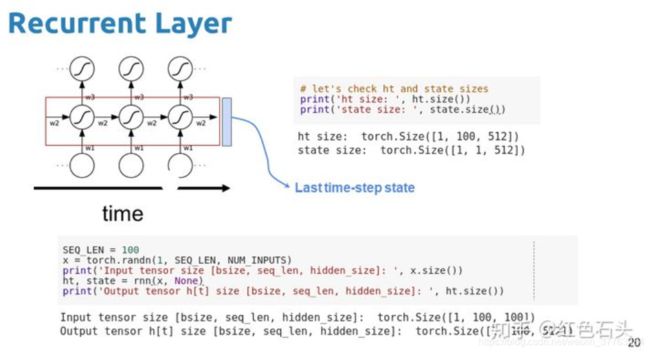
2.手动实现
手动实现1:https://www.pythonf.cn/read/12872,其中的gru实现部分能够帮助理解gru的工作原理,第一部分提到的问题也可以在这里解决。
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
#准备数据
sys.path.append("../input/")
import d2l_jay9460 as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
print('will use', device)
#初始化参数
def get_params():
def _one(shape):
ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32) #正态分布
return torch.nn.Parameter(ts, requires_grad=True)
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
torch.nn.Parameter(torch.zeros(num_hiddens, device=device, dtype=torch.float32), requires_grad=True))
W_xz, W_hz, b_z = _three() # 更新门参数
W_xr, W_hr, b_r = _three() # 重置门参数
W_xh, W_hh, b_h = _three() # 候选隐藏状态参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, dtype=torch.float32), requires_grad=True)
return nn.ParameterList([W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q])
def init_gru_state(batch_size, num_hiddens, device): #隐藏状态初始化
return (torch.zeros((batch_size, num_hiddens), device=device), )
# gru实现,核心代码
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid(torch.matmul(X, W_xz) + torch.matmul(H, W_hz) + b_z)
R = torch.sigmoid(torch.matmul(X, W_xr) + torch.matmul(H, W_hr) + b_r)
H_tilda = torch.tanh(torch.matmul(X, W_xh) + R * torch.matmul(H, W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H,)
#模型训练
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
d2l.train_and_predict_rnn(gru, get_params, init_gru_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
手动实现2:https://zhuanlan.zhihu.com/p/240144570,请注意里面的初始化的参数范围,官方实现有一个上下范围,也可以在这里做出自己的改变。
class GRUCell(nn.Module):
"""自定义GRUCell"""
def __init__(self, input_size, hidden_size):
super(TestGRUCell, self).__init__()
# 输入变量的线性变换过程是 x @ W.T + b (@代表矩阵乘法, .T代表矩阵转置)
# in2hid_w 的原始形状应是 (hidden_size, input_size), 为了编程的方便, 这里改成(input_size, hidden_size)
lb, ub = -sqrt(1/hidden_size), sqrt(1/hidden_size)
self.in2hid_w = nn.ParameterList([self.__init(lb, ub, input_size, hidden_size) for _ in range(3)])
self.hid2hid_w = nn.ParameterList([self.__init(lb, ub, hidden_size, hidden_size) for _ in range(3)])
self.in2hid_b = nn.ParameterList([self.__init(lb, ub, hidden_size) for _ in range(3)])
self.hid2hid_b = nn.ParameterList([self.__init(lb, ub, hidden_size) for _ in range(3)])
@staticmethod
def __init(low, upper, dim1, dim2=None):
if dim2 is None:
return nn.Parameter(torch.rand(dim1) * (upper - low) + low) # 按照官方的初始化方法来初始化网络参数
else:
return nn.Parameter(torch.rand(dim1, dim2) * (upper - low) + low)
def forward(self, x, hid):
r = torch.sigmoid(torch.mm(x, self.in2hid_w[0]) + self.in2hid_b[0] +
torch.mm(hid, self.hid2hid_w[0]) + self.hid2hid_b[0])
z = torch.sigmoid(torch.mm(x, self.in2hid_w[1]) + self.in2hid_b[1] +
torch.mm(hid, self.hid2hid_w[1]) + self.hid2hid_b[1])
n = torch.tanh(torch.mm(x, self.in2hid_w[2]) + self.in2hid_b[2] +
torch.mul(r, (torch.mm(hid, self.hid2hid_w[2]) + self.hid2hid_b[2])))
next_hid = torch.mul((1 - z), n) + torch.mul(z, hid)
return next_hid