通过logstash消费kafka数据到elasticsearch
logstash是什么?
Logstash是一个开源数据收集引擎,具有实时管道功能。 Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。 数据往往以各种各样的形式,或分散或集中地存在于很多系统中。
关于logstash的介绍官网写的非常详细,这里就不再过多介绍了,感兴趣的小伙伴可以自行去官网查看,我们今天的主要目的是如果通过logstash从kafka消费数据,并对数据进行简单的处理然后写入到elasticsearch中
一、运行kafka并写入测试数据
我们直接通过docker在我们的本地运行一个kafka服务端,执行下面的命令即可:
docker run -d --name kafka -p 9092:9092 -e ALLOW_PLAINTEXT_LISTENER=yes -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=192.168.0.66:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.0.66:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t bitnami/kafka:2.8
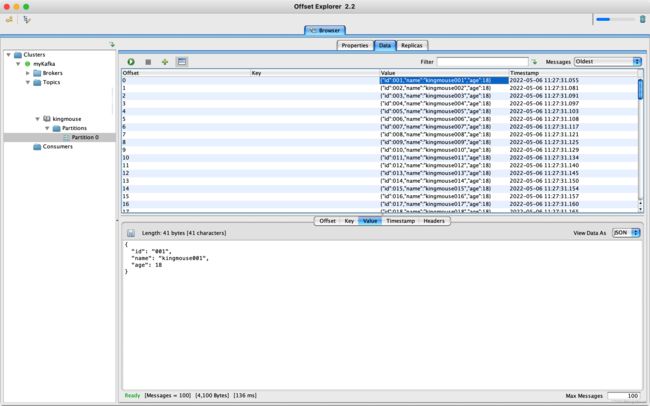
kafka运行起来之后我们向kfka中写入测试数据,我这里直接通过kafka tools工具添加了一些测试数据,写入完毕之后我们可以使用kafka tools工具来查看kafka中数据写入是否正常
二、运行elasticsearch
还是和运行kafka一样的方法,我们直接通过docker来快速运行一个elasticsearch服务端,执行下面的命令即可:
docker run --name elasticsearch -d -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -e discovery.type=single-node -e network.host=0.0.0.0 -p 9200:9200 -p 9300:9300 elasticsearch:7.16.2
elasticsearch运行起来之后我们可以通过Google浏览器,安装ElasticSearch Head插件,通过插件直接输入我们的elasticsearch地址,查看当前elasticsearch运行是否正常
三、编写logstash.conf文件
到这里我们今天的主角就要登场了,在我们运行logstash之前,我们先要创建一个logstash.conf文件,为什么需要创建这文件呢?我们之前说了,我们需要把kafka中的数据消费到elasticsearch中,那么我们总的告诉logstash从哪里消费,IP端口这些信息吧,所以我们需要来配置这些东西,关于logstash.conf中的语法,很简单,我这里就不再细说,如果有不懂的小伙伴可以直接查看官方文档,写的也非常的详细。下面是logstash.conf的完整配置
input{
kafka{
bootstrap_servers => "192.168.0.66:9092"
client_id => "consumer_id"
group_id => "consumer_group"
auto_offset_reset => "latest"
consumer_threads => 1
decorate_events => true
topics => ["kingmouse","kingmouse01"]
}
}
output {
if [@metadata][kafka][topic] == "kingmouse" {
elasticsearch {
hosts => "http://192.168.0.66:9200"
index => "kingmouse-data"
timeout => 300
}
}
if [@metadata][kafka][topic] == "kingmouse01" {
elasticsearch {
hosts => "http://192.168.0.66:9200"
index => "kingmouse01-data"
timeout => 300
}
}
stdout {}
}
input:就是我们的数据源,我们需要从kafka消费数据,我这里就写kafka就ok了,我这里给大家演示的是消费多个topic,所以topics中写了两个
output: 就是我们要输出的地方,这里我们需要写入elasticsearch中,所以我们直接判断当前消费的数据属于哪个topic中,然后写入不通的elasticsearch索引中。
stdout:控制台打印日志,我们这里加上主要为了调试,生产环境可以不加
四、启动logstash
编写完logstash.conf之后我们就可以启动我们的logstash了,这里我们依然使用docker来启动,所以我们需要将我们刚刚编写的配置文件通过挂卷的方式挂在到容器内部,执行下面的命令即可:
docker run --name logstash -d -e xpack.monitoring.enabled=false -v /Users/kingmouse/docker/logstash:/config-dir logstash:7.17.0 -f /config-dir/logstash.conf
五、验证
进入logstash容器内查看启动日志,如果看到下面这些信息,说明logstash已经从kafka中消费到了数据
我们进入elasticsearch看是否有新建了索引

我们可以查看对应的数据是否正确
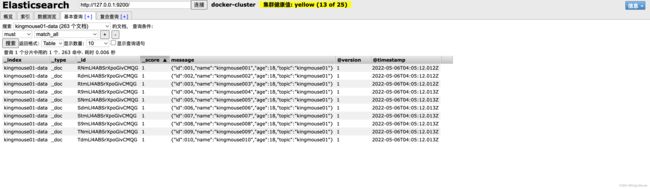
到这里我们我们通过logstash从kafka消费数据到elasticsearch就已经完成了,但是,还有一个小问题,我们发现写入elasticsearch的数据是一个json串,这个不便于我们去查看、搜索,所以我们希望能够按照json的字段来展示,这个也很简单,我们删除当前的索引,然后在logstash.conf中添加如下代码即可:
type => "json"
codec => json {
charset => "UTF-8"
}
最终完整如下:
input{
kafka{
bootstrap_servers => "192.168.0.66:9092"
client_id => "consumer_id"
group_id => "consumer_group"
auto_offset_reset => "latest"
consumer_threads => 1
decorate_events => true
topics => ["kingmouse","kingmouse01"]
type => "json"
codec => json {
charset => "UTF-8"
}
}
}
output {
if [@metadata][kafka][topic] == "kingmouse" {
elasticsearch {
hosts => "http://192.168.0.66:9200"
index => "kingmouse-data"
timeout => 300
}
}
if [@metadata][kafka][topic] == "kingmouse01" {
elasticsearch {
hosts => "http://192.168.0.66:9200"
index => "kingmouse01-data"
timeout => 300
}
}
stdout {}
}
配置完成我们重启logstash(记得修改消费组和消费者id哟),重启完成我们再次查看elasticsearch中数据
六、结束语
是不是很简单,logstash功能非常的强大,今天只是给大家简单聊一下logstash一些基础使用,后续还会继续补充关于logstash的更多用法