【Pandas入门教程】如何选择DataFrame的子集
如何选择DataFrame的子集
来源:Pandas官网:https://pandas.pydata.org/docs/getting_started/intro_tutorials/index.html

文章目录
-
- 如何选择DataFrame的子集
-
-
- 导包
- 数据准备
- 【1】如何从DataFrame中选择特定列?
- 【2】如何从DataFrame中筛选特定行
- 【3】如何从DataFrame选择特定的行和列
- 【小结】
-
导包
import pandas as pd
数据准备
还是使用的泰坦尼克号的数据
titanic = pd.read_csv("titanic.csv")
titanic.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
【1】如何从DataFrame中选择特定列?
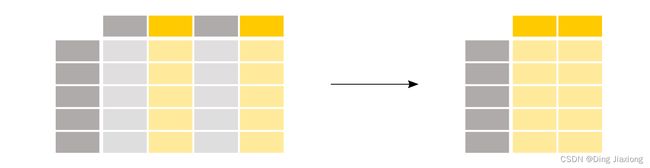
我对泰坦尼克号乘客的年龄感兴趣。
ages = titanic['Age']
ages.head()
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
Name: Age, dtype: float64
若要选择单个列,在相关列的列名称中使用方括号 []
DataFrame中的每一列都是一个Series。选择单个列时,返回的对象是pandas Series。我们可以通过检查输出的类型来验证这一点:
type(titanic['Age'])
pandas.core.series.Series
并查看输出的shape:
titanic['Age'].shape
(891,)
DataFrame.shape 是 pandas Series和数据DataFrame的属性,其中包含行数和列数:(nrows, ncolumns)。pandas Series是一维的,只返回行数。
我对泰坦尼克号乘客的年龄和性别很感兴趣。
age_sex = titanic[['Age', 'Sex']]
age_sex.head()
| Age | Sex | |
|---|---|---|
| 0 | 22.0 | male |
| 1 | 38.0 | female |
| 2 | 26.0 | female |
| 3 | 35.0 | female |
| 4 | 35.0 | male |
要选择多个列,使用选择括号内的列名称列表[].
【注意】内部方括号定义具有列名的 Python 列表,而外部方括号用于从 pandas 数据DataFrame
返回的数据类型是pandas dataframe:
type(titanic[['Age', 'Sex']])
pandas.core.frame.DataFrame
titanic[['Age', 'Sex']].shape
(891, 2)
所选内容返回了一个包含 891 行和 2 列的数据DataFrame。记住,DataFrame是二维的,具有行和列维度。
【2】如何从DataFrame中筛选特定行
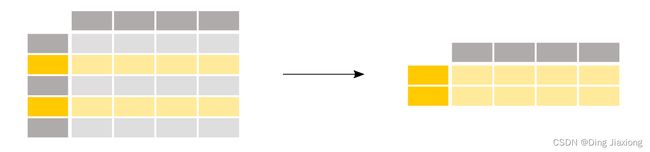
我对35岁以上的乘客感兴趣。
above_35 = titanic[titanic['Age'] > 35]
above_35.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
| 11 | 12 | 1 | 1 | Bonnell, Miss. Elizabeth | female | 58.0 | 0 | 0 | 113783 | 26.5500 | C103 | S |
| 13 | 14 | 0 | 3 | Andersson, Mr. Anders Johan | male | 39.0 | 1 | 5 | 347082 | 31.2750 | NaN | S |
| 15 | 16 | 1 | 2 | Hewlett, Mrs. (Mary D Kingcome) | female | 55.0 | 0 | 0 | 248706 | 16.0000 | NaN | S |
要基于条件表达式选择行,在选择括号内使用条件[].
选择括号 titanic[“Age”] > 35 内的条件检查 Age 列的值大于 35 的行:
titanic['Age'] > 35
0 False
1 True
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Name: Age, Length: 891, dtype: bool
条件表达式 (> 的输出,但也包括 ==、!=、<、<=,…将起作用)实际上是熊猫Series的布尔值(True或False),其行数与原始DataFrame相同。此类布尔值Series可用于筛选DataFrame,方法是将其放在选择方括号 [] 之间。将仅选择值为 True 的行。
我们从之前知道,原始的泰坦尼克号DataFrame由 891 行组成。让我们通过检查生成的DataFrame above_35 shape 属性来查看满足条件的行数above_35:
above_35.shape
(217, 12)
我对2级和3号舱的泰坦尼克号乘客感兴趣。
class_23 = titanic[titanic['Pclass'].isin([2, 3])]
class_23.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
与条件表达式类似,isin() 条件函数为提供列表中的值的每一行返回 True。要基于此类函数筛选行,请使用选择方括号 [] 内的条件函数。在这种情况下,选择括号 titanic[“Pclass”].isin([2, 3]) 中的条件检查 Pclass 列是 2 行还是 3 行。
以上等效于按类为 2 或 3 的行进行筛选,并将这两个语句与 |(或)运算符组合在一起:
class_23 = titanic[(titanic['Pclass'] == 2) | (titanic['Pclass'] == 3)]
class_23.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 5 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
组合多个条件语句时,每个条件必须用括号 () 括起来。此外,不能使用 or/and,但需要使用 or 运算符| 和 and 运算符&.
我想使用已知年龄的乘客数据。
age_no_na = titanic[titanic['Age'].notna()]
age_no_na.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
notna() 条件函数为每行返回一个 True,这些值不是 Null 值。因此,这可以与选择括号 [] 结合使用以过滤数据表。
您可能想知道实际发生了什么变化,因为前 5 行仍然是相同的值。验证的一种方法是检查形状是否已更改:
age_no_na.shape
(714, 12)
【3】如何从DataFrame选择特定的行和列
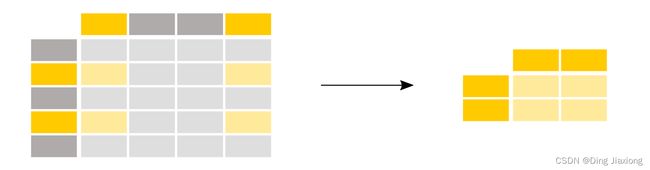
我对35岁以上乘客的姓名感兴趣。
adult_names = titanic.loc[titanic['Age'] > 35, 'Name']
adult_names.head()
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
6 McCarthy, Mr. Timothy J
11 Bonnell, Miss. Elizabeth
13 Andersson, Mr. Anders Johan
15 Hewlett, Mrs. (Mary D Kingcome)
Name: Name, dtype: object
在这种情况下,行和列的子集是一次性创建的,仅使用选择括号 [] 已不够。选择括号 [] 前面需要 loc/iloc 运算符。使用 loc/iloc 时,逗号前面的部分是所需的行,逗号后面的部分是要选择的列。
使用列名、行标签或条件表达式时,请在选择方括号 [] 前面使用 loc 运算符。对于逗号之前和之后的部分,您可以使用单个标签、标签列表、标签切片、条件表达式或冒号。使用冒号指定要选择所有行或列。
我对第 10 到 25 行和第 3 到 5 列感兴趣。
titanic.iloc[9:25, 2:5]
| Pclass | Name | Sex | |
|---|---|---|---|
| 9 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female |
| 10 | 3 | Sandstrom, Miss. Marguerite Rut | female |
| 11 | 1 | Bonnell, Miss. Elizabeth | female |
| 12 | 3 | Saundercock, Mr. William Henry | male |
| 13 | 3 | Andersson, Mr. Anders Johan | male |
| 14 | 3 | Vestrom, Miss. Hulda Amanda Adolfina | female |
| 15 | 2 | Hewlett, Mrs. (Mary D Kingcome) | female |
| 16 | 3 | Rice, Master. Eugene | male |
| 17 | 2 | Williams, Mr. Charles Eugene | male |
| 18 | 3 | Vander Planke, Mrs. Julius (Emelia Maria Vande... | female |
| 19 | 3 | Masselmani, Mrs. Fatima | female |
| 20 | 2 | Fynney, Mr. Joseph J | male |
| 21 | 2 | Beesley, Mr. Lawrence | male |
| 22 | 3 | McGowan, Miss. Anna "Annie" | female |
| 23 | 1 | Sloper, Mr. William Thompson | male |
| 24 | 3 | Palsson, Miss. Torborg Danira | female |
同样,行和列的子集是一次性完成的,仅使用选择括号 [] 已不够。当根据某些行和/或列在表格中的位置对它们特别感兴趣时,请使用选择括号前面的 iloc 运算符[].
使用 loc 或 iloc 选择特定行和/或列时,可以为所选数据分配新值。例如,要将名称anonymous分配给第三列的前 3 个元素:
titanic.iloc[0:3, 3] = "anonymous"
titanic.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | anonymous | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | anonymous | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | anonymous | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
【小结】
选择数据子集时,使用方括号 []
在这些括号内,您可以使用单个列/行标签、列/行标签列表、标签切片、条件表达式或冒号。
使用行和列名称时,使用 loc 选择特定的行和/或列。
使用表中的位置时,使用 iloc 选择特定的行和/或列。
我们可以根据 loc/iloc 为所选内容指定新值.