【ESP32】手势识别实现笔记:红外温度阵列 | 双三次插值 | 神经网络 | TensorFlow | ESP-DL
目录
- 一、开发环境搭建与新建工程模板
-
- 1.1、开发环境搭建与卸载
- 1.2、新建工程目录
- 1.3、自定义组件
- 二、驱动移植与应用开发
-
- 2.1、I2C驱动移植与AMG8833应用开发
- 2.2、SPI驱动移植与LCD应用开发
- 2.3、绘制温度云图
- 2.4、启用PSRAM(可选)
- 2.5、画面动静和距离检测
- 2.6、图像放大之双三次插值法:权重计算 | 插值计算 | 程序设计
- 四、数据集获取
- 五、CNN模型训练
-
- 5.1、环境配置:Anconda3 | TF2.1.0 | Pycharm
- 5.2、生成数据集 | 预处理
-
- 5.2.1、生成数据集:统计数据集 | 数据集随机化 | 数据集划分
- 5.2.2、预处理:string类型转换为float | 数据标准化 | one-hot encoding
- 5.3、构建训练模型
- 5.4、训练结果保存和准确率
- 5.5、ONNX模型转换和校准集导出
- 六、模型量化与部署
-
- 6.1、模型量化
- 6.2、ESP-DL组件添加
- 6.3、ESP 数据标准化(网络输入)
- 6.4、构建模型与优化
- 6.5、ESP硬件加速:修改sdkconfig配置
- 七、应用逻辑设计
-
- 7.1、获取静止状态手势 | 定时器引入
- 7.2、交互方式选择:交互方式1
- 7.3、交互方式选择:交互方式2
- 八、others
-
- 8.1、跑一下示例程序(MNIST)
- 8.2、数据集补充程序
开发板:ESP32-S3-DevKitC-1(ESP32-S3-WROOM-1-N16R8模块)
开发软件:VS Code(Espressif IDF插件) + Anaconda3 + PyCharm
开发框架:ESP-IDF (版本v5.0.4)
训练框架:TensorFlow 2.1.0
部署框架:ESP-DL
: 在STM32上跑神经网络做手势识别
仓库:https://gitee.com/npc-gitee/esp_dl_for_bixin
如理解有误,望不吝指正,感谢。
说明:
- 不同手势姿态之间需要具有明显的不同,在使用过程中,手势姿态需要做到位;(可能数据集不足)
- 影响体表温度的因素比较多,由于影响因素的变化,存在部分位置接近环境温度情况,所以即使加入了数据标准化,依然存在推理不准问题;(可能数据集不足)
- 在使用测试中,某个动作出现判断出错,可以将该动作添加到数据集中,在上一次权重文件基础上再训练,修修补补;
- 距离传感器较远,细节难以捕捉,不同手势差异较小,已经无法通过增加数据集来提高预测正确率;
- 该数据集动作主要在中心位置,所以使用过程中动作保持在中心;
- 本示例通过分类任务实现手势识别,如果出现新的手势类别,预测结果就很迷,采用RNN、LSTM等的方式,使用效果应该会较好。
一、开发环境搭建与新建工程模板
1.1、开发环境搭建与卸载
考虑 ESP-DL 库所支持的版本为 ESP-IDF v5.0,所以这里安装的不是最新版本。
在安装 VS Code插件 (Espressif IDF) 后,可以选择两种安装方式:
- 在线安装+自动配置
- 离线安装+手动配置 (该教程使用的编译操作为 cmd 的方式)
这里采用离线安装+手动配置(VS Code下完成程序编辑和编译操作) 。
① ESP-IDF 开发环境搭建:
- 下载ESP-IDF离线版本:ESP-IDF Windows Installer Download
- 离线安装
ESP-IDF,安装完成后,安装路径下有三个重要的目录;- frameworks/esp-idf-v5.0.4:内含示例代码和组件源代码等;
- tools:编译器等程序;
- python_env/idf5.0_py3.11_env:python虚拟运行环境,内含python.exe、pip.exe以及依赖的库等。
- 打开
VS Code,安装插件Espressif IDF; - VS Code 手动配置;
a) 打开vscode左侧的插件管理页 => 找到espressif idf => 点击该插件旁边的小齿轮 => 扩展设置,就能看到 ESP-IDF 的配置属性;
b) 将路径信息添加到这些变量中:Custom Extra Paths、Custom Extra Vars、Esp Idf Path Win、Esp Idf Path Win、Git Path、Python Bin Path、Tools Path Win;(参考:esp32 开发环境:windows10 + esp-idf v4.4 + vscode + 插件 espressif idf 搭建踩坑 ) - 重启一下VS Code。
② 打开一个Example进行测试:
- 按住
Ctrl+Shift+p打开命令行,这里输入ESP-IDF show,点击ESP-IDF: Show Eaxmples Projects,点击需要使用的 ESP-IDF 路径; - 左边栏中选择 hello word 工程,点击
Create project using example hello_world。
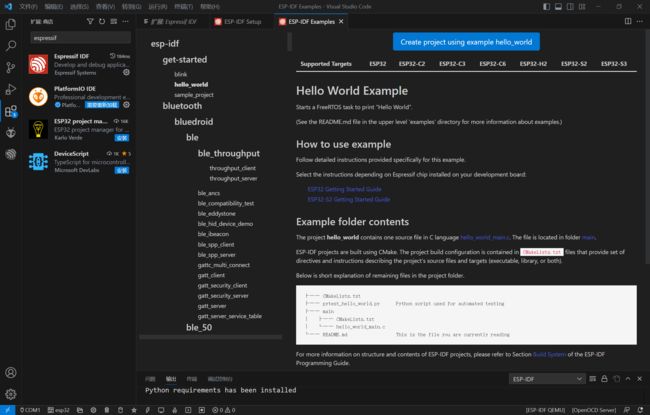
- 选择这个项目的保存路径,任意路径均可;
- 烧录过程配置;
- COM 口的配置,选择对应的COM口;
- ESP32芯片选择,这里选ESP32s3;
- 烧录方式选择串口转USB:
ESP32-S3 chip(via ESP-PROG)- 设置波特率:File => Preferences => Settings => 输入ESP-IDF,然后往下滑找到 Flash Baud Rate,输入115200。(波特率不同,会导致终端输出乱码)

- 点击编译,成功后就可以进行烧录了。
③ 卸载ESP-IDF: 控制面板 => 卸载程序 => ESP-IDF Tools Offline 5.0.4 右键卸载。(VS Code 下的配置直接重置就好)
1.2、新建工程目录
- 打开
VS Code,此时界面可能是很干净,没有打开项目;这里需要随便打开一个目录(不然第二步操作完发现没响应); - 按住
Ctrl+Shift+p打开命令行,输入ESP-IDF: Create project from extension template,点击;然后就按照提示操作就可以了; - 选择项目保存目录;
- 这里选择
template-app,接着就弹出了一个新的VS Code界面,关掉前一个VS Code界面; - 这时候指定目录下就有一个生成的文件夹,修改文件夹名称,方便以后管理(该操作不影响编译);
- 打开该目录根目录下的
CmakeLists.txt,将project(template-app)修改为project(xxx),这样之后生成的可执行文件的名称就是xxx.bin,而不是template-app.bin。点击一下编译查看是否有问题。
1.3、自定义组件
到这一步就可以开发了,为了项目条理更加清晰,还需要引入【自定义组件】。
一般而言,自定义组件可以简单理解为一个目录,里面存放一些功能函数,提供给main函数进行调用。
- 打开
ESP-IDF 5.0 CMD终端,切换到待创建的目录,输入idf.py -C components create-component led;(当然可以手动创建目录和文件)

- components:创建的组件(目录),位于那个目录下,如果没有这个目录就创建,Cmake管理默认的目录名称叫
components,如果起了其它名称,需要用EXTRA_COMPONENT_DIRS变量进行说明。
- 在所在项目根目录下的CmakeLists.txt 中加入这条语句:
set(EXTRA_COMPONENT_DIRS ./新名字)- led:组件的名称。
生成后项目目录树如下:
---Test
|---.devcontainer
|---.vscode
|---build
|---CMakeLists.txt
|---sdkconfig
|---components
|---led
|---include
|---led.h
|---CmakeLists.txt
|---led.c
|---key
|---include
|---key.h
|---CmakeLists.txt
|---key.c
|---main
|---CmakeLists.txt
|---main.c
-
将组件中的头文件添加到main.c中,这样就可以进行编译了。
-
如果led组件需要key组件的函数,则:
- led.h 中加入
#include "key.h" - 方式一:led 组件中的 CmakeLists.txt 中加入头文件路径:
INCLUDE_DIRS "include" "../key/include"(注意这里可是没指定链接路径,但还是能找到) - 方式二:led 组件中的 CmakeLists.txt 中加入依赖组件:
REQUIRES driver key(这里led依赖两个组件:driver和key)
- led.h 中加入
-
在 IDF 5.0 的版本之后,driver 组件不作为公共依赖项,所以使用的时候,必须在 CmakeLists.txt 中声明依赖 driver 组件后才能使用:
idf_component_register(SRCS "led.c"
INCLUDE_DIRS "include"
REQUIRES driver)
如果没有添加这个组件,则会报错:driver/gpio.h: No such file or directory
REQUIRES 和 PRIV_REQUIRES 的区别:组件依赖示例
参考:
[1]: ESP-IDF编程指南
[2]: ESP—IDF开发(1)创建模板工程
[3]: ESP32学习笔记(21)——构建自己的工程和组件库
[4]: ESP32 ESP-IDF自定义组件
[5]: ESP32开发 CMakeLists包含同级目录.h文件,error: gpioX.h: No such file or directory
二、驱动移植与应用开发
管脚布局:
I2C0引脚资源使用情况: 支持任意 GPIO 管脚
------------------------------------
| AMG8833 | ESP32 |
------------------------------------
| VIN | 3.3V |
| GND | GND |
| SCL | GPIO2 |
| SDA | GPIO1 |
| INT | / |
| AD0 | GND |
------------------------------------
SPI3引脚资源使用情况: 支持任意 GPIO 管脚
------------------------------------
| LCD Screen | ESP32 |
------------------------------------
| GND | GND |
| VCC | VCC(3.3v) |
| SCL | GPIO5(SCLK) |
| SDA | GPIO6(MOSI) |
| RES | GPIO7 |
| DC | GPIO15 |
| CS | GPIO16 |
| BLK | GPIO17 |
------------------------------------
2.1、I2C驱动移植与AMG8833应用开发
ESP32-S3 有2个 I2C 控制器,每个控制器都可以设置为主机或从机,本次示例中作为主机使用。
- 当 8x8 中某个测点出现超过极限值就会触发INT引脚电平变化,ESP32 通过 INT 引脚触发外部中断;ESP32 通过读取寄存器的值就可以确定哪个矩阵测点触发电平变化。
- AMG8833 SCL最大支持
400kHz。 AD0(AD_SELECT)为 I2C设备地址选择脚。拉低,设备地址为110 1000,即0x68。拉高,设备地址为110 1001,即0x69。- EPS32-S3 的 I2C 引脚原则上可选择任意引脚,在 I2C 初始化的时候指定即可,并将引脚设置为
Enable GPIO pull-up resistor。
“ ESP32-S3 的内部上拉电阻范围为几万欧姆,因此在大多数情况下,它们本身不足以用作 I2C 上拉电阻。建议用户使用阻值在 I2C 总线协议规范规定范围内的上拉电阻。计算阻值的具体方法,可参考 TI 应用说明 ” —— ESP-IDF 编程指南(API参考=>外设API=>I2C驱动程序)
对于AMG8833而言,可以直接使用而不用外接上拉电阻。
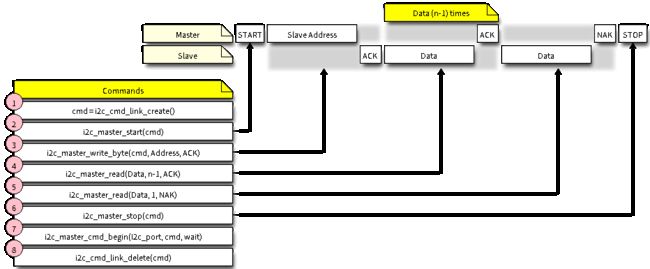
主机写入数据:
- 使用
i2c_cmd_link_create()创建一个命令链接。然后,将一系列待发送给从机的数据填充命令链接:
a. 启动位 -i2c_master_start()
b. 从机地址 -i2c_master_write_byte()。提供单字节地址作为调用此函数的实参。
c. 数据 - 一个或多个字节的数据作为i2c_master_write()的实参。 - 通过调用
i2c_master_cmd_begin()来触发 I2C 控制器执行命令链接。一旦开始执行,就不能再修改命令链接。(一般报错出现在该语句) - 命令发送后,通过调用
i2c_cmd_link_delete()释放命令链接使用的资源。

主机读取数据的步骤基本相似。
ESP-IDF 对这两个过程进行了封装:
- 主机读取数据:
i2c_master_write_read_device() - 主机写入数据:
i2c_master_write_to_device()
基本过程同上面一致,本示例依据这两个函数源代码,进行简单修改。
AMG8833 需要进行初始化寄存器:正常读取前需要进行初始化操作。
- Power Control寄存器:设置AMG8833的工作模式;
- Reset寄存器:进行软复位;
- Frame Rate寄存器:设定帧率;
- Interrupt Control寄存器:配置中断功能;
AMG8833 Temperature寄存器:红外点阵测量的温度值。

两个寄存器的数据组合起来获得一个测点的温度值。有12位数据,最高位为符号位,0为正,1为负。最小变化单位为0.25℃。
在读取64个像素点温度值时候,I2C只需要指定第一个寄存器地址以及读取的字节数量,AMG8833自动发送后面地址的数据。
- amg8833的初始化程序、读写程序等功能函数参考Arduino框架下的程序。
- ESP32-S3-Devkitc-1 开发板在Arduino IDE 中找不到对应的板子,此时更新一下即可。(工具 => 开发板: “xxx” => 开发板管理器…)
/* Arduino框架下测试代码, 用于对比在ESP-IDF框架下驱动与应用是否正常
* 这里在测试代码的基础上增加/修改了两条语句:
* => Wire.setPins(1,2); // 设置新的I2C引脚
* => status = amg.begin(0x68, &Wire); //amg8833初始化, 0x68为amg8833设备地址
*/
#include 参考:
[1]: ESP_IDF—I2C 驱动程序
[2]: ESP32 之 ESP-IDF 教学(六)——硬件I2C总线外设(I²C)
[3]: AMG8833的使用与stm32驱动代码
[4]: ESP32 I2C自定义引脚
[5]: ESP32-S3入门Arduino开发(一)–Arduino环境搭建
2.2、SPI驱动移植与LCD应用开发
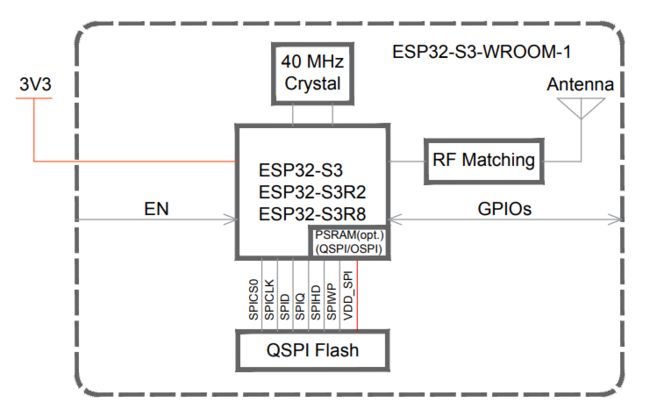
ESP32-S3-DevKitC-1 开发板采用 ESP32-S3-WROOM-1/1U 或 ESP32-S3-WROOM-2/2U 模组,而这些模组采用 ESP32-S3芯片。
ESP32-S3 芯片集成了四个 SPI 控制器:
- SPI0
- SPI1
- 通用 SPI2,即GP-SPI2
- 通用 SPI3,即GP-SPI3
SPI0 和 SPI1 控制器主要供内部使用以访问外部 flash 及 PSRAM,如上图所示。这里采用 SPI3 作为 LCD 通信控制器。
SPI有多种模式:为兼容LCD通信规范,这里采用普通 SPI 模式。
- 普通 SPI 模式
- 双线输出模式
- 双线输出模式
- 四线输出模式
- 四线 I/O 模式
- 八线输出模式
- OPI 模式
- MOSI:主机输出,从机输入,也写作SPID;
- MISO:主机输入,从机输出,也写作SPIQ;
- CS:片选,表示设备被选中;
- SCLK:串行时钟,由主机产生的振荡信号,使数据位的传输保持同步;
- QUADWP:写保护信号。只用于 4 位 (qio/qout) 传输;
- QUADHD:保持信号。只用于 4 位 (qio/qout) 传输。
LCD驱动和应用编写:
- SPI初始化:引脚指定、频率、最大传输数据大小、是否开启DMA等,主要配置
spi_bus_config_t和spi_device_interface_config_t结构体;通过spi_bus_initialize和spi_bus_add_device函数完成配置;
spi_bus_config_t结构体成员max_transfer_sz表示最大传输大小,以字节为单位。
- 若一次传输超过
max_transfer_sz设置的大小,则会出现:txdata transfer > host maximum 错误;- 若
max_transfer_sz设置的大小过大(测试过程中使用大于36000),出现 SPI 传输不完全。
根据 ESP32-S3 系列芯片技术规格书,SPI3 可指定为任意 GPIO 管脚。
按照 Arduino 框架驱动程序,LCD 采用的 SPI 时钟频率为 27Mhz。
- 普通GPIO初始化:DC、RST、BCK引脚不在SPI协议所规定的引脚,所以需要单独进行初始化;
对于SPI协议本身而言,传输信息不区分命令和数据,LCD从设备收到信息的时候,需要区分命令和数据,这里通过 DC 引脚电平信号加以区分,当DC为低电平时,SPI传输的是命令,当DC为高电平时,SPI 传输的数据。
- 编写命令/数据SPI发送函数;
- 编写LCD初始化;
- 编写矩形绘制和图片显示函数,验证程序工作正常。
xxx.h: No such file or directory
跳转能正常,但是编译的时候提示没有这个文件,通过清除一下编译的中间文件,然后再编译就可以了。
AMG8833/LCD与ESP32之间采用杜邦线连接,杜邦线受到外界扰动会影响I2C和SPI的通信。
参考:
[1]: ESP32-IDF开发笔记 | 03 - 使用SPI外设驱动ST7789 SPILCD
[2]: 【ESP32-IDF】 02-4 外设-SPI
[3]: ESP-IDF 编程指南:SPI 主机驱动程序
2.3、绘制温度云图
camColors全局变量数组,里面保存颜色数据(RGB565),共有256种颜色,0索引保存为蓝色,255索引保存为红色。
最大温度记作: T m a x T_{max} Tmax;最小温度记作: T m i n T_{min} Tmin;当前温度记作: T c u r T_{cur} Tcur。
最小索引值记作: i d x idx idx。
建立温度和颜色的映射关系:
T m a x − T m i n 255 − 0 = T c u r − T m i n x − 0 \frac{T_{max}-T_{min}}{255-0}=\dfrac{T_{cur}-T_{min}}{x-0} 255−0Tmax−Tmin=x−0Tcur−Tmin
转换为:
x = 255 ∗ T c u r − T m i n T m a x − T m i n x=255*\dfrac{T_{cur}-T_{min}}{T_{max}-T_{min}} x=255∗Tmax−TminTcur−Tmin
Arduino 框架官方提供了映射函数——map函数,主题思想一致的,细节上有些差异,具体表示如下:
x = 255 ∗ ( T c u r − T m i n ) + ( T m a x − T m i n ) / 2 T m a x − T m i n + i d x = 255 ∗ T c u r − T m i n T m a x − T m i n + 0.5 + i d x x=\dfrac{255*{(T_{cur}-T_{min})}+(T_{max}-T_{min})/2}{T_{max}-T_{min}}+idx=255*\dfrac{T_{cur}-T_{min}}{T_{max}-T_{min}}+0.5+idx x=Tmax−Tmin255∗(Tcur−Tmin)+(Tmax−Tmin)/2+idx=255∗Tmax−TminTcur−Tmin+0.5+idx
浮点型赋值给整型,小数部分舍去,这里加上0.5,实现四舍五入。
最大温度和最小温度选择?
假设待测温度区间为20-25℃,若设置最大温度为30℃、最小温度0℃,那么对于256种颜色,用于表示20-25℃区间的颜色约为(30-0)/256*5=43种;若设置最大温度为30℃、最小温度15℃,用于20-25℃区间的颜色约为(30-15)/256*5=85种,用于显示的颜色越多,显示跨度越大,越能显示温度的细微变化,显示效果更好,所以最大温度和最小温度的跨度不要太大。
温度云图显示上下颠倒问题
从AMG8833读入ESP32内存的时候,点阵的左右顺序没有打乱,上下顺序倒了一下,所以在LCD显示的时候出现了上下翻转,这里另外写一个功能函数将点阵顺序调整为amg8833原先的顺序。

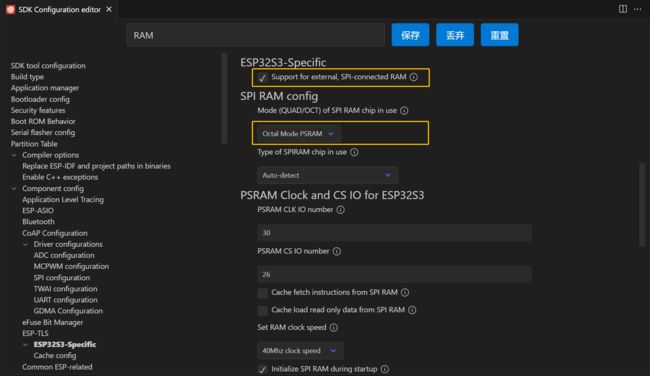
2.4、启用PSRAM(可选)
选用的芯片 ESP32-S3 N16R8(片内PSRAM 8MB + 片外FLASH 16MB),内部 SRAM 只有 512 KB,考虑显示一张 240x240 的图片需要的内存大小为 240x240x2=115200 Bytes=112.5KB,所以这里可以考虑采用PSRAM作为显存。(本示例中显示区域较小,所以没有使用)
- 点击齿轮

- 输入 RAM查找一下两项,勾选
Support for external, SPI-connected RAM以及模式选择Octal Mode PSRAM。
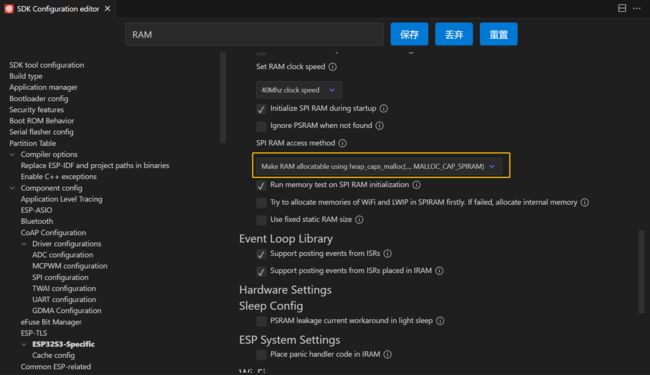
- 选择
Make RAM alloctable using heap_caps_malloc(...,MALLOC_CAP_SPIRAM),也可以选择Make RAM allocatable using malloc() as well,之所以选择前者是从存储器的使用上考虑:若从片上 SRAM 分配空间,则使用malloc函数,若从片外 PSRAM 上分配空间,则使用heap_caps_malloc函数。
- 其它参数可使用默认。
- 保存,然后编译。
报错: psram: PSRAM ID read error: 0x00ffffff
\, \, \, \, \, \, \, \, \, \, \, cpu_start: Failed to init external RAM!
解决:模式选择Octal Mode PSRAM
参考:ESP32 s3 PSRAM ID read error: 0x00ffffff 已解决。
问题:assert failed: block_trim_free heap_tlsf.c:377 (block_is_free(block) && “block must be free”)
解决: 如果较快的申请资源和释放资源可能会出现这个问题(ESP-IDF4.4),可以尝试增加一下延时函数vTaskDelay(100 / portTICK_PERIOD_MS)。
2.5、画面动静和距离检测
为什么要做画面动静判断?
1.在不使用 RNN/LSTM 的情况下,如果一个动作一直保持,那么就会认为做了多个相同的动作,那么就会根据这个结果执行多次;
2. 如果使用 RNN/LSTM ,数据集创建工作量较大。 所以综合考虑,结合画面动静判断和CNN网络实现手势识别。
这里画面动静判断采用帧间差分法,以目标温度较小值为分界点,区分背景和目标,将两帧温度矩阵(24x24)的对应点进行相减,并取其绝对值,若大于阈值(目标和背景采用不同阈值)则计数值加1,当计数值大于某个值(距离不同,检测到目标的大小也不同,这个值是实时调整)后,则认为画面中存在运动目标。
在实现过程中,由于对比两帧数据,所以需要保存前一帧温度矩阵数据,一帧数据大小为24x24x4(float) = 2.25KB,这里采用 异步内存拷贝(Asynchronous Memory Copy),其核心技术在于DMA,通过给DMA发送命令,实现内存拷贝,此时不需要CPU参与,当传输完成后通过回调函数发送信号通知被阻塞的任务。
异步内存拷贝:
/*-------------------> 安装 <-------------------*/
config = ASYNC_MEMCPY_DEFAULT_CONFIG();
config.backlog = 16; // update the maximum data stream supported by underlying DMA engine
async_memcpy_t mem_driver = NULL;
ESP_ERROR_CHECK(esp_async_memcpy_install(&config, &mem_driver)); // install driver with default DMA engine
SemaphoreHandle_t my_semphr = xSemaphoreCreateBinary(); // Create a semaphore used to report the completion of async memcpy
/*--------------> 发送内存拷贝请求 <--------------*/
ESP_ERROR_CHECK(esp_async_memcpy(mem_driver, out_img_buf_pre, out_img_buf, COPY_LEN, my_async_memcpy_cb, &myflags));
/*-----------> 拷贝完成后调用回调函数 <-----------*/
// Callback function, running in ISR context
static bool my_async_memcpy_cb(async_memcpy_t mcp_hdl, async_memcpy_event_t *event, void *cb_args)
{
/*可自定义标志*/
BaseType_t high_task_wakeup = pdFALSE;
xSemaphoreGiveFromISR(my_semphr, &high_task_wakeup); // high_task_wakeup set to pdTRUE if some high priority task unblocked
return high_task_wakeup == pdTRUE;
}
/*-----------> 阻塞等待内存拷贝完成 <-----------*/
xSemaphoreTake(my_semphr, portMAX_DELAY); // Wait until the buffer copy is done
画面动静判断逻辑:
//获取第一帧24x24温度矩阵
readPixels{}
//保存第一帧数据
mem2mem{
1.发送内存拷贝请求
2.sigflag = 1
}
while(1){
readPixels{} //获取24x24温度矩阵
motion_detection{
if(sigflag == 1){
1.阻塞等待内存拷贝完成
2.sigflag == 0
}
/*画面动静判断*/
if(运动){
mem2mem{} // 如果运动, 保存当前帧数据
}
else{ // 静止, 不保存数据
}
}
}
- 获取第一帧24x24温度矩阵;
- 保存第一帧数据;
- 获取第二帧24x24温度矩阵;
- 因为是第一帧,所以等待第一帧保存完成;
- 判断是否运动,若为运动,保存当前帧(第二帧),下一次和第二帧做比较,若为静止,不用保存,下一次和第一帧做比较;
- 开始第二次循环,获取第三帧24x24温度矩阵;
- 是否之前有保存操作,没有就不用阻塞等待,有就阻塞等待;
- 判断是否运动,继续循环往复。
为什么运动时候保存当前帧,静止时候不保存当前帧?
如果每一帧都保存,当动~~~作~~~比~~~较~~~慢~~~时,那么连续两帧比较的时候就会认为没有运动,保存当前帧,之后获取下一帧,同样变化小,认为没有运动,导致最后动作很大了,还是认为没有运动;若静止的不保存,前一帧保存的是最原先的一帧数据,虽然动作慢,但幅度达到一定大小后,就会认为运动了。
考虑自适应参数:如果距离比较远,那么目标比较小,动作也会不容易捕捉,如果距离比较近,捕捉比较敏感,所以考虑引入自适应参数,动态调整阈值和点阵数量(通过大于某个温度的像素点个数确定目标大小,从而判断远近)。
参考:
[1]: 运动目标检测——帧间差分法(Temporal Difference)简介
[2]: winform 画面关闭返回值_opencv+python判断画面动静
[3]: The Async memcpy API
为什么要做目标距离判断?
这里的距离指的是远近,若捏住+近距离的特征表示左移,若捏住+远距离的特征表示右移,那么在使用过程中需要自己把握这个距离,因此,考虑引入距离检测,当发现用户捏住行为,然后捕捉动作,若为靠近,则认为左移,若为远离,则认为右移。
目标距离检测实现原理:靠近传感器温度高,远离传感器温度低。
这种方式存在一个问题:如果目标远离检测范围那么温度也会下降,进入检测范围那么温度也会上升,更复杂是前后左右平移+上下平移的复合动作,这里暂时不考虑,只考虑上下平移。
2.6、图像放大之双三次插值法:权重计算 | 插值计算 | 程序设计
对于低分辨图像在高分辨率的设备上显示,如果不做任何处理,那么实际显示区域会很小,为了扩大显示区域,就需要对低分辨率的图像进行数值图像放大处理,就是将低分辨率的图像变成高分辨率的图像,多出来的像素怎么获得?—— 插值算法。
虽然变成了高分辨率图像,但是这是由低分辨率的数据生成的,所以不会很高清。
常见的插值算法:自适应和非自适应。
非自适应算法:最近邻,双线性,双三次,样条等。双三次插值效果较好,但是时间开销比较大。
基本步骤:
- 计算权重
- 计算放大图像后的像素值
1、权重计算
原图片:8x8
放大后的图片:16x16
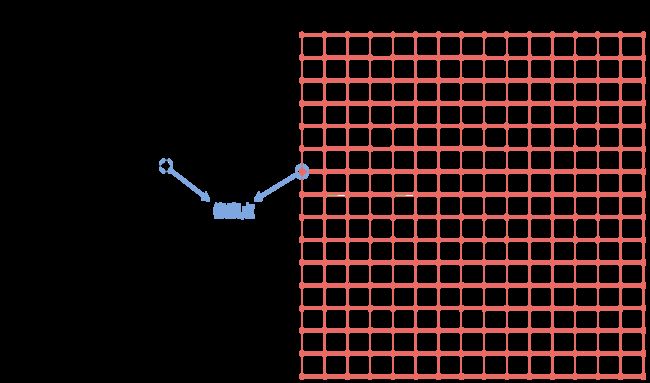
将【放大后的图片】缩小到【原图片】的大小,如下图所示:
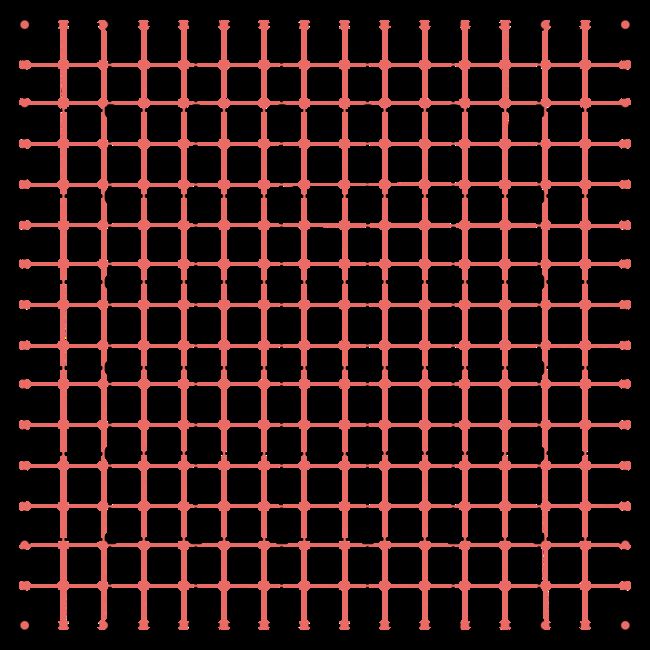
缩小后,每个像素(共16x16个)都需要计算权值。当计算某个像素权值时,取该像素上下左右邻近的四个点,在这四个点为基础,向外再扩充一圈,总共取16个点,如下图所示:

将上面的距离数据代入权重计算公式:
W ( x ) = { ( a + 2 ) ∣ x ∣ 3 − ( a + 3 ) ∣ x ∣ 2 + 1 f o r ∣ x ∣ ≤ 1 a ∣ x ∣ 3 − 5 a ∣ x ∣ 2 + 8 a ∣ x ∣ − 4 a f o r 1 ≤ ∣ x ∣ ≤ 2 0 o t h e r s W(x)= \begin{cases} (a+2)|x|^3-(a+3)|x|^2+1 \,\,\,\,\,\,\,\,\,for\,\,\, |x|≤1\\ a|x|^3-5a|x|^2+8a|x|-4a \,\,\,\,\,\,\,\,\,\,\,\, for \,\,\, 1≤|x| ≤2\\ 0 \,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,others \end{cases} W(x)=⎩ ⎨ ⎧(a+2)∣x∣3−(a+3)∣x∣2+1for∣x∣≤1a∣x∣3−5a∣x∣2+8a∣x∣−4afor1≤∣x∣≤20others
式中, x x x 为目标像素点距离邻近像素点的距离; a a a 一般取 − 0.5 -0.5 −0.5。
对于【米黄色】的点,X轴方向距离为0.6,Y轴方向距离为1.3。
-
X轴方向:
W ( x ) = ( a + 2 ) ∣ x ∣ 3 − ( a + 3 ) ∣ x ∣ 2 + 1 = ( − 0.5 + 2 ) ∗ ∣ 0.6 ∣ 3 − ( − 0.5 + 3 ) ∗ ∣ 0.6 ∣ 2 + 1 = 0.424 \begin{aligned} W(x) &= (a+2)|x|^3-(a+3)|x|^2+1 \\ &= (-0.5+2)*|0.6|^3-(-0.5+3)*|0.6|^2+1\\ &= 0.424 \end{aligned} W(x)=(a+2)∣x∣3−(a+3)∣x∣2+1=(−0.5+2)∗∣0.6∣3−(−0.5+3)∗∣0.6∣2+1=0.424 -
Y轴方向:
W ( y ) = a ∣ x ∣ 3 − 5 a ∣ x ∣ 2 + 8 a ∣ x ∣ − 4 a = ( − 0.5 ) ∗ ∣ 1.3 ∣ 3 − 5 ∗ ( − 0.5 ) ∗ ∣ 1.3 ∣ 2 + 8 ∗ ( − 0.5 ) ∗ ∣ 1.3 ∣ − 4 ∗ ( − 0.5 ) = − 0.0735 \begin{aligned} W(y) &= a|x|^3-5a|x|^2+8a|x|-4a \\ &= (-0.5)*|1.3|^3-5*(-0.5)*|1.3|^2+8*(-0.5)*|1.3|-4*(-0.5)\\ &= -0.0735 \end{aligned} W(y)=a∣x∣3−5a∣x∣2+8a∣x∣−4a=(−0.5)∗∣1.3∣3−5∗(−0.5)∗∣1.3∣2+8∗(−0.5)∗∣1.3∣−4∗(−0.5)=−0.0735
对于【浅绿色】的点,X轴方向距离为1.6,Y轴方向距离为1.3。
-
X轴方向:
W ( x ) = a ∣ x ∣ 3 − 5 a ∣ x ∣ 2 + 8 a ∣ x ∣ − 4 a = ( − 0.5 ) ∗ ∣ 1.6 ∣ 3 − 5 ∗ ( − 0.5 ) ∗ ∣ 1.6 ∣ 2 + 8 ∗ ( − 0.5 ) ∗ ∣ 1.6 ∣ − 4 ∗ ( − 0.5 ) = − 0.048 \begin{aligned} W(x) &= a|x|^3-5a|x|^2+8a|x|-4a \\ &= (-0.5)*|1.6|^3-5*(-0.5)*|1.6|^2+8*(-0.5)*|1.6|-4*(-0.5)\\ &= -0.048 \end{aligned} W(x)=a∣x∣3−5a∣x∣2+8a∣x∣−4a=(−0.5)∗∣1.6∣3−5∗(−0.5)∗∣1.6∣2+8∗(−0.5)∗∣1.6∣−4∗(−0.5)=−0.048 -
Y轴方向:
W ( y ) = a ∣ x ∣ 3 − 5 a ∣ x ∣ 2 + 8 a ∣ x ∣ − 4 a = ( − 0.5 ) ∗ ∣ 1.3 ∣ 3 − 5 ∗ ( − 0.5 ) ∗ ∣ 1.3 ∣ 2 + 8 ∗ ( − 0.5 ) ∗ ∣ 1.3 ∣ − 4 ∗ ( − 0.5 ) = − 0.0735 \begin{aligned} W(y) &= a|x|^3-5a|x|^2+8a|x|-4a \\ &= (-0.5)*|1.3|^3-5*(-0.5)*|1.3|^2+8*(-0.5)*|1.3|-4*(-0.5)\\ &= -0.0735 \end{aligned} W(y)=a∣x∣3−5a∣x∣2+8a∣x∣−4a=(−0.5)∗∣1.3∣3−5∗(−0.5)∗∣1.3∣2+8∗(−0.5)∗∣1.3∣−4∗(−0.5)=−0.0735
若插值的像素点落在原图内部网格上,16个点怎么取?
对于这种情况,可以有两种选择,要么认为位于左侧网格,要么认为位于右侧网格,在做插值处理的时候,需要做到统一。(落在上下网格也有相同的情况,也需要做到统一)
这里统一为左上。
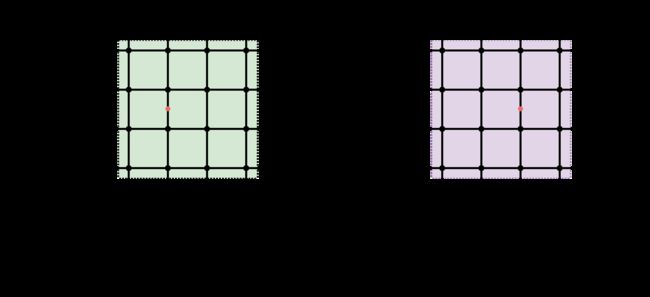
若插值的像素点落在原图边界上,16个点怎么取?
将原图进行padding处理,往外部扩两层,像素值与原图边界值相同。
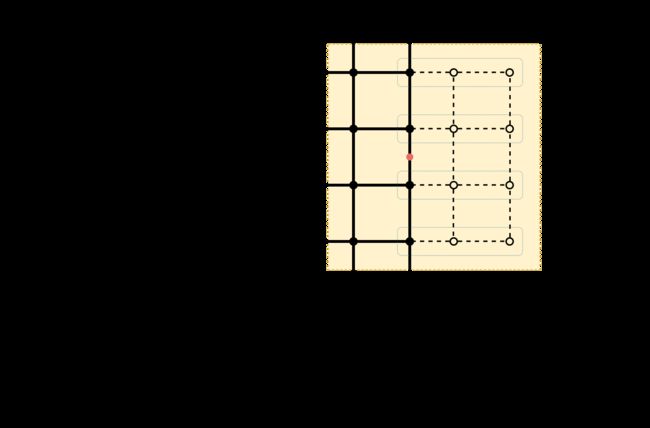
每个插值的像素都是由16个原图中像素加权计算所得,每一行X轴方向权重相同,每一列Y轴方向权重相同,所以一个插值的像素需要进行8次权重计算。
2、插值计算
计算红点位置的像素值,取4x4区域中的16个点。
然后计算原图像素和权重的Hadamard积:

Hadamard积:矩阵相同位置元素相乘,数学符号 ⊙ \odot ⊙。

最后,将矩阵中所有元素相加得到了插值的像素值。


由上图可知:
- 当距离为0的时候, W = 1 W=1 W=1
- 当距离为-1或1的时候, W = 0 W=0 W=0
- 当距离为-2或2的时候, W = 0 W=0 W=0
所以当【放大后的图片】像素点与【原图片】像素点重合的时候,距离绝对值取值可能为0、1和2,那么最后插值计算的结果就是重合原图片像素点。
参考:
[1]: 用于数字成像的双三次插值技术
[2]: 插值算法 | 双三次插值算法 (视频中a = -0.75)
3、程序设计
按照上述基本原理进行程序实现,具体函数在 gesture_display.cpp 文件中,其中有两个主要接口:
interpolate_image函数:实现8x8温度值放大成24x24温度值;temp_cloud_map_display函数:将温度值通过云图方式在LCD上显示;
+----------------------------------------------------------------------------+
| +-------------------------------+|
| ==> getW_x() ==> weight_xy_adjust2D() ==> | matrix_hadamard_pruduct() ||
| ==> getW_y() ==> weight_xy_adjust2D() ==> | img_matrix_hadamard_pruduct() ||
| ==> img8x8_pad_to_img12x12() ===========> | matrix_elem_sum() ||
| +-------------------------------+|
|----------------------------------------------------------------------------|
| ************************* interpolate_image() ************************* |
+----------------------------------------------------------------------------+
img8x8_pad_to_img12x12():将8x8矩阵通过padding的方式变成12x12矩阵。

报错:A stack overflow in task main has been detected.
在 app_main 主函数中调用函数A,正常运行,再函数A之后加入函数B后,在函数A调用的时候出现了上述报错。
解决:增加 app_main 任务的栈空间大小。
点击齿轮 => 输入Main task stack size => 修改为10240(10K)
上面是一种方式,当然menuconfig的方式也是可以的。
手动修改sdkconfig是无效的。
参考:
[1]: idf v4.3 uses libmad,***ERROR*** A stack overflow in task main has been detected (IDFGH-6020) #7706
[2]: how to set app_main stack size? (IDFGH-2318) #2824
[3]: ESP32 之 ESP-IDF 教学(十八)—— 组件配置(KConfig)
报错:assert failed: tlsf_free heap_tlsf.c:872 (!block_is_free(block) && “block already marked as free”)
原因:在C代码改写成C++代码过程中,col_buf缓冲区在构造函数中申请堆空间,按正常来说在析构函数中释放堆空间,但是在LCD显示函数中释放掉了,所以第二次访问col_buf空间的时候报错了。
(本示例中没采用)
设想1:优化处理速度:采用双核运行,创建任务后不销毁,当处理完成一个任务后,将这个任务挂起,当下一次任务来的时候再恢复调度。
设想2:权重的计算可以提前算好,保存起来PSRAM,但是如果计算速度比PSRAM读写速度快,就没有必要。
参考:
[1]: 图像的放大:双三次插值算法(C++实现)
四、数据集获取
上位机程序(PC):get_data/get_data.py
下位机程序(ESP32):get_data/esp_dl_for_bixin
使用逻辑:
- LCD显示采集温度云图,若符合要求,按下键盘
任意键+回车; - 按下后,通过串口发送给ESP32,ESP32收到命令后,申请互斥锁,阻塞温度采集和插补计算,绘制当前温度云图,确认温度云图是否符合预期;
- 上位机输入标签或者放弃该数据,若输入数字标签(
0-背景,1-放大,2-捏住,3-减小),则将命令发送给ESP32,等待ESP32将点阵数据发送;若放弃,输入数字4,则将命令发送给ESP32,重新进行温度采样; - PC设备在收到串口数据后,复原图像,然后根据标签将数据和图片保存到对应目录下,文件名自动加1;(若上位机程序中途退出,下次运行时候,需要将当前的文件数量覆盖num1/num2/num3/num3变量)
- 然后重新开始第一步。
对于一组动作,当采集第一个动作,然后进行插补计算,之后的动作可能就没有采集到,只要单片机处理速度够快,这种漏采的帧数就较少。
数据保存到 txt 文件中,24行24列,由8行8列数据插补而来,其对应AMG8833的点阵序号为:
|---------------------------------------| | 58 | 59 | 60 | 60 | 61 | 62 | 63 | 64 | | ... | | ... | | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |数据采集过程中,动作可以考虑从不同角度、不同距离采集。
get_data.py 编程注意点:
- windows环境下路径为:D:/xxx/1.jpg
- 不允许一个串口被多个进程使用,所以如果使用多进程编程,串口在创建多进程前打开,子进程会继承父进程的所有文件描述符,那么就会出现报错。
- python语法中,除法 ‘ / ’ 总是返回一个浮点数,除法 ‘ // ’ 若除数和被除数存在浮点,则返回浮点,否则返回整数。
- for i in range(0, 24) # 0开始到23结束。
- image.putpixel 其中一个参数为xy,表示往图像xy位置写入RGB,所以代码中传入的参数为(j,i)。
- ser.flushInput() 的用途是再接收温度数据前,防止串口接收缓冲区中存在其它数据,导致接收错误数据,通过这个函数清空串口输入缓冲区。
对于插补结果上锁考虑:
- 插补的结果作为临界资源呢,防止将数据发送给PC过程中,数据被更改;
- 既然要发送,那么在发送过程中,不需要进行数据采集、插补计算、LCD显示,这个任务可以暂时停止,通过上锁的方式实现任务阻塞等待。
【get_data.py 报错】 fp = builtins.open(filename, “w+b”) PermissionError: [Errno 13] Permission denied: ‘c:/xxx/1.jpg’
原因:C盘读写权限较高,可以尝试将图片保存到D盘。
五、CNN模型训练
5.1、环境配置:Anconda3 | TF2.1.0 | Pycharm
Python:3.7(Anaconda3)
开发框架:TensorFlow 2.1.0
IDE:PyCharm
① Python安装:
Anaconda:python编译器和python包管理工具合在一起的一个软件。
安装配置教程:anaconda的安装和使用(管理python环境看这一篇就够了)
# 虚拟环境常用命令
conda info -e # 查看已经创建的所有虚拟环境
conda create -n xxx python=3.7 # 创建一个python3.7 名为xxx的虚拟环境
conda activate xxx # 切换/激活到xx虚拟环境
② TensorFlow安装:
// GPU 版本
pip install --upgrade tensorflow-gpu==2.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
// CPU 版本
pip install --upgrade tensorflow-cpu==2.1.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
检测是否安装成功:切换到虚拟环境——>输入python ——> 载入tensorflow (import tensorflow as tf) ——> 查看版本号(print(tf.__version__))
对于英伟达CUDA安装配置环境相对较为繁琐,该模型较为简单,可以直接使用CPU进行训练。
③ PyCharm安装:
可以直接从 PyCharm 官网下载,但是可能由于 Anaconda 版本比较老,添加 python 解释器比较麻烦,所以这里采用这位博主提供的版本,具体软件安装、解释器添加教程可参考该篇博客 。
5.2、生成数据集 | 预处理
由第四章中所构建的数据集,*.txt 文件中保存的数据为温度值,数据的排布格式如上所示,将*.txt文件中的数据变成数据集需要考虑以下事情:
- 【生成数据集】保存的数据按照分类分别保存在不同的目录下,所以需要统计数据集目录下所有的数据,将数据打乱,按照60%训练-20%测试-20%验证的比例划分。
- 【预处理】
*.txt文件中的数据类型为字符串,而训练时候所需要的数据为 float。
5.2.1、生成数据集:统计数据集 | 数据集随机化 | 数据集划分
- 创建数字编码表,即手势行为与数字的对应关系,
background=0,increase=1,pinch=2,reduce=3; - 遍历文件夹下的所有文件,以列表的方式保存所有文件的路径;
- 通过 random.shuffle 打乱顺序;
- 读取列表每个元素值然后拆解,由于原先存放的顺序以类别分别存放在对应的目录下,所以从拆解的结果可以知道该数据对应的标签,将【数据路径(*.txt)】和【标签】保存到 csv 文件中;
- 从 csv 文件中读出数据,按【数据路径】和【标签】分别保存到两个变量中,返回;
- 按照比例,以切片的方式,得到训练集、测试集、验证集,注意这里的数据还只是数据的路径,后面输入到神经网络需要将数据提取处出来,这部分工作交给预处理来完成。
目录结构:
---xxx
|---dataset
|---background
|---1.jpg
|---1.txt
|---...
|---increase
|---1.jpg
|---1.txt
|---...
|---pinch
|---1.jpg
|---1.txt
|---...
|---reduce
|---1.jpg
|---1.txt
|---...
|---tmp_data.csv
|---geture_train.py
代码如下:
# 作用:将文件统计存入csv文件,然后读出csv文件内容
# root:数据集根目录
# filename:csv文件名
# name2label:类别名编码表
def load_csv(root, filename, name2label):
if not os.path.exists(os.path.join(root, filename)):
tmp_data = []
for name in name2label.keys():
# 'dataset\\increase\\1.txt
tmp_data += glob.glob(os.path.join(root, name, '*.txt'))
# 200, 'dataset\increase\\1.txt'...
print(len(tmp_data), tmp_data)
random.shuffle(tmp_data)
with open(os.path.join(root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img in tmp_data: # 'dataset\\increase\\1.txt'
name = img.split(os.sep)[-2]
label = name2label[name]
# 'dataset\\increase\\1.png', 1
writer.writerow([img, label])
print('written into csv file:', filename)
# read from csv file
tmp_data, labels = [], []
with open(os.path.join(root, filename)) as f:
reader = csv.reader(f)
for row in reader:
# 'dataset\\increase\\1.txt', 1
tmp, label = row
label = int(label)
tmp_data.append(tmp)
labels.append(label)
assert len(tmp_data) == len(labels)
return tmp_data, labels
# root:数据集根目录
def load_gesture(root, mode='train'):
# 创建数字编码表
name2label = {} # "sq...":0
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root, name)):
continue
# 给每个类别编码一个数字
# 如: name2label['increase'] = 1
name2label[name] = len(name2label.keys())
print(name2label)
# 读取Label信息
# [file1,file2,], [3,1]
images, labels = load_csv(root, 'tmp_data.csv', name2label)
if mode == 'train': # 60%
images = images[:int(0.6 * len(images))]
labels = labels[:int(0.6 * len(labels))]
elif mode == 'val': # 20% = 60%->80%
images = images[int(0.6 * len(images)):int(0.8 * len(images))]
labels = labels[int(0.6 * len(labels)):int(0.8 * len(labels))]
else: # 20% = 80%->100%
images = images[int(0.8 * len(images)):]
labels = labels[int(0.8 * len(labels)):]
return images, labels, name2label
5.2.2、预处理:string类型转换为float | 数据标准化 | one-hot encoding
预处理工作通过map的方式实现,将每个路径的 txt 加载进来替换掉,变成 txt 本身的内容,即 x x x 由原先路径,变成 [24, 24] 温度矩阵数据, y y y 为标签数据。
- 读取
*.txt中的数据,该数据为一个字符串; - 删除字符串中的
空格和\r\n字符,然后以这些字符,分割字符串,产生 576 个字符串,以列表的方式保存; - 将 576 个字符串转换为 float 类型,此时列表为 576 个 float 类型元素,shape为 [576];
- 将 [576] shape 转换为 [24, 24] shape,并进行扩展维度,将 [24, 24] shape 转变为 [24, 24, 1];
- 采用
最大最小标准化(Min-Max Normalization): x ′ = x − m i n ( x ) m a x ( x ) − m i n ( x ) x^{'}=\dfrac{x-min(x)}{max(x)-min(x)} x′=max(x)−min(x)x−min(x) (对 x x x 数据进行标准化处理); - 将 label 数据( y y y)转换为 tensor 类型,并进行
one-hot encoding处理(共 4 种类型,数字0,编码后变成 [1,0,0,0]); - 导出 x x x 和 y y y 两种 tensor 数据。
代码如下:
def preprocess(x, y): # 这个顺序和from_tensor_slices中的 x,y 对应
# 读入txt数据
data = tf.io.read_file(x)
# 分割每行数据
data = tf.strings.split(data) # "22.11 22.11 ...\r\n22.11 22.11...\r\n" => ["22.11" "22.11" ...]
data = tf.strings.to_number(data) # ["22.11" "22.11" ...] (string) => [22.11 22.11 ...] (float32)
data = tf.reshape(data, [24, 24]) # shape [576] => shape [24, 24]
data = tf.expand_dims(data, axis=2) # shape [24, 24] => shape [24, 24, 1]
# data数据归一化
max_data = tf.reduce_max(data) # 标量
min_data = tf.reduce_min(data) # 标量
data = (data - min_data)/(max_data-min_data) # broadcat 张量维度扩张
y = tf.convert_to_tensor(y)
y = tf.one_hot(y, depth=4) # one-hot encoding
return data, y
问题: Input 0 of layer conv2d is incompatible with the layer: expected ndim=4, found ndim=3. Full shape received: [24, 24, 1]
Conv2d的输入需要 4 维数据,所以预处理数据导出为[24, 24, 1],当训练的时候,经过数据集batch,Conv2d输入的数据为[b, 24, 24, 1],其中 b 就是 batch 的值。
参考:卷积计算输入要求
5.3、构建训练模型

模型参考:我复现了稚晖君的热成像手!语!识!别!
conv_layers = [
# kernel_size:3x3, 卷积核个数:4
layers.Conv2D(4, input_shape=(24, 24, 1), kernel_size=[3, 3], padding="valid", activation=tf.nn.relu), # [b, 24, 24, 1] => [b, 22, 22, 4]
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='valid'), # [b, 22, 22, 4] => [b, 11, 11, 4]
layers.Flatten(), # [b, 11, 11, 4] => [b, 484]
layers.Dense(128, activation=tf.nn.relu), # [b, 484] => [b, 128]
layers.Dense(64, activation=tf.nn.relu), # [b, 128] => [b, 64]
layers.Dense(4, activation=tf.nn.softmax), # [b, 64] => [b, 4]
]
def main():
print(tf.__version__)
train_images, train_labels, train_table = load_gesture('.\\dataset', 'train')
val_images, val_labels, val_table = load_gesture('.\\dataset', 'val')
train_db = tf.data.Dataset.from_tensor_slices((train_images, train_labels))
train_db = train_db.map(preprocess).batch(300)
val_db = tf.data.Dataset.from_tensor_slices((val_images, val_labels))
val_db = val_db.map(preprocess).batch(300)
# [b, 24, 24, 1] => [b, 4]
network = Sequential(conv_layers)
# network.build(input_shape=[None, 24, 24, 1])
network.compile(optimizer=optimizers.Adam(lr=1e-4), # Adam优化器配置
loss=tf.losses.CategoricalCrossentropy(from_logits=False), # 损失函数: 交叉熵
metrics=['accuracy']) # 准确率计算
# 打印网络信息
network.summary()
# 模型训练和验证
network.fit(train_db, epochs=200, validation_data=val_db, validation_freq=1)
构建模型的时候,输入张量设置方式有多种,上面的是直接在模型conv_layers 中添加,或者可以使用model.build(input_shape=[None, 24, 24, 1]),这两种方式存在一定的差异,至少在ONNX模型转换的时候,第二种方式会报错:‘Sequential’ object has no attribute ‘output_names’;并且二者的ckpt权值文件也是不通用的,提示:Shapes (128,) and (64,) are incompatible。
5.4、训练结果保存和准确率
在构建模型的基础上,添加权值保存语句:
checkpoint_path = "gesture_train-{epoch:02d}.ckpt" # ckpt保存文件名, 占位符将会被epoch值和传入on_epoch_end的logs所填入
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path, # 保存文件名
save_best_only=True, # 当设置为True时,将只保存在验证集上性能最好的模型
save_weights_only=True, # 若设置为True,则只保存模型权重,否则将保存整个模型(包括模型结构,配置信息等)
verbose=1, # 为1表示输出epoch模型保存信息,默认为0表示不输出该信息
save_freq='epoch' # CheckPoint之间的间隔的epoch数
)
network.fit(train_db, epochs=200, validation_data=val_db, validation_freq=1, callbacks=[cp_callback])
训练结果准确率: 有部分数据集在采集过程中,距离传感器较远,相关特征不能很好的采集,所以验证集中若包含该数据,那么准确率不是很高,差不多在80%。若验证集中不包含该部分数据,准确率能到100%。

参考:
[1]: Tensorflow 2.1 完成权重或模型的保存和加载
[2]: ModelCheckpoint详解
5.5、ONNX模型转换和校准集导出
【ONNX模型】和【校准集】用于模型量化,校准集可以是训练集或验证集的子集,这里取训练集和验证集的集合作为校准集。
① ONNX模型转换:
这一步开始参考 ESP-DL 示例程序中的代码,下载:https://github.com/espressif/esp-dl (解压后目录名称为 esp-dl-master);
参考esp-dl-master\tools\quantization_tool\examples\tensorflow_to_onnx 提供的代码,做简单的修改,应用于本模型。
其余不用修改,注释掉main(),添加下列代码:
if __name__ == '__main__':
# main()
model = Sequential(conv_layers)
model.load_weights('gesture_train-06.ckpt')
model.summary()
# export model to onnx format
spec = (tf.TensorSpec((None, 24, 24, 1), tf.float32, name="input"),) # 函数签名
output_path = "gesture.onnx"
model_proto, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=13, output_path=output_path)
# checker.check_graph(model_proto.graph)
- –opset 11:ONNX是一个不断发展的标准,它将添加更多的新操作并增强现有的操作,因此不同的opset版本将包含不同的操作,它们可能会有些不同 。这里参考示例程序,选择
opset 13。
② 校准集导出: 训练集 + 验证集
- .pkl数据文件 :Python中,Pickle模块将任意一个Python对象转换成一系统字节。
import pickle
# obj: 序列化对象
# file: 保存到的待写入的文件对象
# protocol: 序列化模式,默认是0(最原始的人类可读版本)
pickle.dump(obj, file, protocol=None, *, fix_imports=True, buffer_callback=None)
pickle.load() # 反序列化
查看 ESP-DL 示例中的 pickle 文件(esp-dl-master\tools\quantization_tool\examples\mnist_test_data.pickle),本数据集参考该方式转换;
f = open('mnist_test_data.pickle', 'rb') # 打开pickle文件
info = pickle.load(f)
print('type', type(info), len(info))
print(info[0])
print(info[1])
f.close() # 关闭pickle文件
示例中的 pickle 文件的保存类型为list,info[0] 为图像数据,info[1] 为label数据。
注意, 保存类型需保存一致,如果采用字典类型,就会出现报错:‘str’ object has no attribute ‘astype’。
导出 pickle 文件:
# loc_train_db: 用于训练的数据集
# loc_val_db: 用于验证的数据集
def pkl_dataset_create(loc_train_db, loc_val_db):
global pkl_train_savePath, pkl_cal_savePath
loc_train_sample = [[], []]
loc_val_sample = [[], []]
for step, (x, y) in enumerate(loc_train_db):
if step == 0:
loc_train_sample[0] = x
loc_train_sample[1] = y
else:
loc_train_sample[0] = tf.concat([loc_train_sample[0], x], axis=0) # shape [300,24,24,1] + shape [300,24,24,1] => shape [600, 24, 24, 1]
loc_train_sample[1] = tf.concat([loc_train_sample[1], y], axis=0) # shape [300,4] + shape [300, 4] => shape [600, 4]
for step, (x, y) in enumerate(loc_val_db):
if step == 0:
loc_val_sample[0] = x
loc_val_sample[1] = y
else:
loc_val_sample[0] = tf.concat([loc_val_sample[0], x], axis=0)
loc_val_sample[1] = tf.concat([loc_val_sample[1], y], axis=0)
print('train:', 'x-', loc_train_sample[0].shape, 'y-', loc_train_sample[1].shape)
print('val:', 'x-', loc_val_sample[0].shape, 'y-', loc_val_sample[1].shape)
loc_train_sample[0] = tf.concat([loc_train_sample[0], loc_val_sample[0]], axis=0)
loc_train_sample[1] = tf.concat([loc_train_sample[1], loc_val_sample[1]], axis=0)
print('train:', 'x-', loc_train_sample[0].shape, 'y-', loc_train_sample[1].shape)
pkl_train_db = [loc_train_sample[0].numpy(), loc_train_sample[1].numpy()]
with open(pkl_train_savePath, 'wb') as f:
pickle.dump(pkl_train_db, f, -1)
print('pkl save done!')
函数参数传递进来后,进入取训练集的数据循环,若训练集总数为720,验证集总数为80,则:
- 第一次循环后,loc_train_sample[0] 的 shape 为 [300, 24, 24, 1],loc_train_sample[1] 的 shape 为 [300, 4];(300是因为训练的时候batchsize取300)
- 第二次循环后,loc_train_sample[0] 的 shape 为 [300, 24, 24, 1],loc_train_sample[1] 的 shape 为 [300, 4],和上一次循环结果进行合并;
- 第三次循环后,loc_train_sample[0] 的 shape 为[120, 24, 24, 1],loc_train_sample[1] 的 shape 为[120, 4],和上一次循环结果进行合并;
loc_train_sample[0][0]:第一张热成像图片数据(已经完成归一化的数据)
loc_train_sample[1][0]:第一张热成像label数据(已经完成one-hot)
上述数据的类型为 Tensor,存储为pickle后,在后续量化中出现:‘Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2’(主机为AMD处理器)。因此这里使用loc_val_sample[0].numpy()语句,将Tensor类型转换为Numpy类型。
参考:
[1]: 手写图像数据集MNIST下载,处理为Numpy格式后存为.pkl格式
[2]: Python中 pickle 模块的 dump() 和 load() 方法详解
[3]: pickle — Python object serialization
六、模型量化与部署
6.1、模型量化
顺利到这一步,已经有如下文件:gesture_train.pickle 和 gesture.onnx。
参考 tools/quantization_tool/examples/example.py,示例目录如下,
---quantization_tool
|---examples
|---example.py
|---optimizer.py
|---windows
|---calibrator.pyd
|---calibrator_acc.pyd
|---evaluator.pyd
复制上述文件,创建如下目录,
---quantization
|---examples
|---quantization.py(原example.py)
|---gesture_train.pickle
|---gesture.onnx
|---optimizer.py
|---windows
|---calibrator.pyd
|---calibrator_acc.pyd
|---evaluator.pyd
① 进入虚拟环境
conda activate mt_for_esp
其中,mt_for_esp是<虚拟环境名称>。
② 安装 python 依赖包
pip install numba==0.53.1
pip install --upgrade onnx==1.9.0 # 环境中若已安装可以直接更新
pip install onnxruntime==1.7.0
pip install onnxoptimizer==0.2.6
③ ESP-DL组件下载:https://github.com/espressif/esp-dl
④ 进行修改quantization.py
1.修改pickle和onnx文件名;
2.删除test_images = test_images / 255.0, 数据集已经完成标准化;
3.calib_dataset = test_images[0:5000:50] => calib_dataset = test_images[0:1040:10];
4.batch_size = 10;
5.test_labels外层增加np.argmax, 原版本label没有one-hot, 这里 pickle 文件中label完成one-hot;
⑤ 输入 python quantization.py,输出如下文件和信息

- gesture_cal.pickle
- gesture_coefficient.cpp
- gesture_coefficient.hpp
- gesture_optimized.onnx
参考:手动部署模型
6.2、ESP-DL组件添加
- ESP-DL组件下载:https://github.com/espressif/esp-dl (解压后目录名称为
esp-dl-master); - 创建组件,这里叫做
esp-dl; - 将
esp-dl-master/include目录下的文件复制到esp-dl组件中的include目录下;(有些文件不是很必要可以根据需求调整) - 将
esp-dl-master/lib/esp32s3目录下的libdl.a复制到esp-dl组件根目录下,组件结构如下;
---esp-dl
|---include
|---detect
|---image
|---layer
|---math
|---nn
|---tool
|---tvm
|---typedef
|---dl_define.hpp
|---CMakeLists.txt
|---libdl.a
- 修改
esp-dl组件下的CMakeLists.txt,如下
idf_component_register(SRCS
INCLUDE_DIRS "include" "include/detect" "include/image" "include/layer" "include/math" "include/nn" "include/tool" "include/tvm" "include/typedef")
target_link_libraries(${COMPONENT_LIB} INTERFACE "${CMAKE_CURRENT_LIST_DIR}/libdl.a")
- (可选)到上面这一步就可以了,这里通过官方示例提供的 MNIST 测试添加
esp-dl组件是否编译正常,(example:esp-dl-master/tutorial/quantization_tool_example); - (可选)创建
model组件,文件结构如下:
---|---esp-dl
|---model
|---include
|---mnist_coefficient.hpp
|---mnist_model.hpp
|---mnist_coefficient.cpp
|---CMakeLists.txt
- (可选)
model组件下的CMakeLists.txt如下,该组件依赖于 esp-dl 组件,所以需要添加REQUIRES esp-dl,
idf_component_register(SRCS "mnist_coefficient"
INCLUDE_DIRS "include"
REQUIRES esp-dl)
- (可选)
main.app文件替换一下,替换前注意备份老版本,直接编译即可。(若运行的时候发现推理时间官方示例不同,可考虑将sdkconfig配置的同官方一致)
参考:使用 ESP-IDF 生成第三方的 .a 静态库并使用的流程
6.3、ESP 数据标准化(网络输入)
数据集为关于温度的矩阵(24x24),在训练的时候有一个预处理的过程,其中包含归一化,对于网络而言,输入是归一化后的结果,所以推理的时候,输入网络中的数据也应该是归一化后的数据。
// 寻找最大值和最小值
template<typename T>
void max_min(T *ptr, uint16_t count, T *max, T *min)
{
*max = ptr[0];
*min = ptr[0];
for(int i=1; i<count; i++){
if(*max < ptr[i]){
*max = ptr[i];
}
if(*min > ptr[i]){
*min = ptr[i];
}
}
}
__attribute__((aligned(16))) float example_element[576];
__attribute__((aligned(16))) float tmp[576];
int main(void){
float max, min;
max_min(example_element, &max, &min);
for(int i = 0; i<576; i++){
// normalization
tmp[i] = (example_element[i]-min)/(max-min);
}
}
6.4、构建模型与优化
创建 model 组件,将 gesture_coefficient.cpp 和 gesture_coefficient.hpp 加入到该组件中,目录如下,
---model
|---include
|---gesture_coefficient.hpp
|---gesture_model.hpp
|---CmakeLists.txt
|---gesture_coefficient.cpp
CmakeLists.txt 内容如下,
idf_component_register(SRCS "gesture_coefficient.cpp"
INCLUDE_DIRS "include"
REQUIRES esp-dl)
在 gesture_model.hpp 中完成模型构建,主要步骤如下,
- 模型类派生一个新类,由于量化时配置的为
int16量化,故模型以及之后的层均继承 - 将层声明为成员变量;
- 用构造函数初始化层;
- 实现
void build(Tensor;&input) - 实现
void call(Tensor;&input)
「 例如定义卷积层 “l2”,根据打印得知输出的指数位为 “-11”,该层的名称为 “fused_gemm_0”。您可调用
get_fused_gemm_0_filter()获取改卷积层权重,调用get_fused_gemm_0_bias()获取该卷积层偏差,调用get_fused_gemm_0_activation()获取该卷积层激活参数。」 —— from ESP
说明:
- 层的名称在哪里看?
- 有些层不需要模型参数,也就不需要存储模型参数,即在构造函数初始化层的时候,传入上述参数。

【注意】卷积输入shape的要求
通过量化工具,生成两个gesture_ccoefficient.cpp、gesture_coefficient.hpp,当中有一个参数是卷积核的shape(3,3,1,4),分别表示卷积核的宽度、高度、通道、卷积核数。
在conv2D.build中有一条语句:assert(input.shape[2]==filter.shape[2]),这对输入的shape提出了要求,而filter.shape[2]就是(3,3,1,4)中的1,所以input的shape为(24,24,1)。
【注意】softmax输入shape的要求
在Softmax.build中有一条语句:this->channel = input.shape[2],如果Softmax的input为[4](shape为1),那么input.shape[2]是越界访问,其值为随机数,所以input的维度必须是3维;若shape[2]为1,则Softmax只会取一个数据计算,所以input的shape为(1,1,4)。
按照量化工具优化后的网络模型,构建网络模型如下:
Reshape<int16_t> l1; // shape(24,24,1) => shape(24,24,1)
Conv2D<int16_t> l2; // shape(24,24,1) => shape(22,22,4)
MaxPool2D<int16_t> l3; // shape(22,22,4) => shape(11,11,4)
Transpose<int16_t> l4; // shape(11,11,4) => shape(11,11,4)
Reshape<int16_t> l5; // shape(11,11,4) => shape(1,484)
FullyConnected<int16_t, int16_t> l6; // shape(1,484) => shape(128)
FullyConnected<int16_t, int16_t> l7; // shape(128) => shape(64)
FullyConnected<int16_t, int16_t> l8; // shape(64) => shape(4)
Reshape<int16_t> l9; // shape(4) => shape(1,1,4)
Softmax<int16_t> l10; // shape(1,1,4) => shape(1,1,4)
优化:删除不必要的层
- l 1 l1 l1层在刚开始设置数据集的时候可以指定,所以这一层可以删除;
- l 4 l4 l4层之后的 l 5 l5 l5层直接打平,可以选择直接从 l 3 l3 l3到 l 5 l5 l5,所以删除 l 4 l4 l4;
l 8 l8 l8层之后可以直接得到预测结果,之所以用到softmax是在训练的时候用于构造损失函数,在推理的时候, l 8 l8 l8层输出结果可以查看当前类别可能性概率有多大,但是如果有一个新的类别,也可能出现类别可能性概率很大的情况,所以,可以考虑删除 l 9 l9 l9层和 l 10 l10 l10层。
优化后的模型如下:
Conv2D<int16_t> l1; // shape(24,24,1) => shape(22,22,4)
MaxPool2D<int16_t> l2; // shape(22,22,4) => shape(11,11,4)
Reshape<int16_t> l3; // shape(11,11,4) => shape(1,484)
FullyConnected<int16_t, int16_t> l4; // shape(1,484) => shape(128)
FullyConnected<int16_t, int16_t> l5; // shape(128) => shape(64)
FullyConnected<int16_t, int16_t> l6; // shape(64) => shape(4)
Reshape<int16_t> l7; // shape(4) => shape(1,1,4)
Softmax<int16_t> l8; // shape(1,1,4) => shape(1,1,4)
6.5、ESP硬件加速:修改sdkconfig配置
ESP32-S3的存储器如下:
-
内部存储器
- 片内ROM(384KB):存放系统底层软件的ROM代码,如一级引导程序。
- 片内SRAM(512KB):用于保存data段、bss段、堆栈等,以及部分text段(IRAM_ATTR修饰的函数)和ICache、DCache。
- RTC 快速存储器(8KB)
- RTC 慢速存储器(8KB)
- 片内PSRAM(8MB)
-
外部存储器
- 片外FLASH(16MB):用于保存二级引导程序(bootloader)和应用启动程序,加之链接脚本设置data/bss/(部分)text的地址空间为IRAM,所以在执行主函数之前需要完成data/(部分)text搬运。
外部存储器:CPU 借助高速缓存 (ICache/DCache) 来访问外部存储器,若地址能命中Cache,那么直接从Cache中取数据,若没有命中,则根据内存管理单元 (MMU) 中的信息把 CPU 指令总线或数据总线的地址变换为访问片外 flash 与片外 RAM 的实地址。
ICache最大为32KB,DCache最大为64KB。ICache 和 DCache 物理存储空间从片内SRAM获得,两种 Cache 均可映射到片外FLASH。
主要加速点:
-
提高DCache大小和访问速率:CPU通过SPI得到FLASH上的代码和数据的速度不及来自Cache(片内SRAM),根据CPU从FLASH取数据的原理,如果Cache足够大,那么地址命中率提高,有效减少片外FLASH访问。
-
提高SPI通讯速率:如果将SPI通讯速率提升,也能提高FLASH访问速度。
-
提高CPU主频:若CPU的主频足够快,理论上计算速度也足够快。(该网络主要性能瓶颈在存储器读写,所以160MHz提高到240MHz提升不明显)
sdkconfig主要配置如下:【idf.py menuconfig】
-
修改CPU主频,160MHz => 240MHz
- Component config —> ESP System Settings —> CPU frequency (160 MHz) —> (x) 240 MHz
-
修改片外FLASH
- SPI 模式,QIO:SPISerial flasher config —> Flash SPI mode (DIO) —> (x) QIO;
- SPI 速度,80MHz:SPISerial flasher config —> Flash SPI speed (80 MHz) ;
- FLASH 大小,4MB:SPISerial flasher config —> Flash size (2MB) —> (x) 4MB;
-
修改片内PSRAM
- SPI 模式为8线(Octal Mode):Component config —> ESP PSRAM —> Support for external, SPI-connected RAM —> SPI RAM config —> Mode (QUAD/OCT) of SPI RAM chip in use (Quad Mode PSRAM) —> (x) Octal Mode PSRAM
- SPI 频率为80MHz:Component config —> ESP PSRAM —> Support for external, SPI-connected RAM —> SPI RAM config —> Set RAM clock speed (40Mhz clock speed) —> (x) 80MHz
-
修改Data Cache
- 设置 DATA Cache size为64KB:Component config —> ESP System Settings —> Cache config —> Data cache size (32KB) —> (x) 64KB
- 设置 DATA Cache Line size为64B:Component config —> ESP System Settings —> Cache config —> Data cache line size (32 Bytes) —> (x) 64 Bytes
ICache 由16KB调整到32KB没怎么提升,所以依然配置为16KB。
【无softmax层】推理耗时:7020us

【有softmax层】推理耗时:7262us

参考:
[1]: ESP32/ESP32-S2 CPU加速建议
[2]: esp32 CPU时钟设置 240Mhz
[3]: 【ESP32-IDF】03-1 系统-内存管理
[4]: ESP32 程序的内存模型
七、应用逻辑设计
7.1、获取静止状态手势 | 定时器引入
① 获取静止状态手势程序逻辑:

② 定时器引入
对于ESP32-S3部署平台,该模型推理过程约7ms,这对于实际应用过程中,能保持较好的实时性,然而,由于该模型未采用RNN/LSTM等时序处理模型,所以只能针对某一个动作进行推理。试想一下,当手指由交叉状变成捏住状态,在这个改变过程中的某一个状态,可能被采集被推理为增大,但是实际应该是减小。基于此,通过引入定时器,当某个动作保持一定时间后,才对这个动作进行推理。
esp_timer 内部使用 52 位硬件定时器,对于 ESP32-S3 使用的是 SYSTIMER。其 API 集支持单次定时器和周期定时器、微秒级的时间分辨率。
定时器回调可通过以下两种方式调度:
ESP_TIMER_TASK:定时器回调函数是从高优先级的esp_timer任务中调度的,如果有优先级高于esp_timer的其他任务正在运行,则回调调度将延迟,直至esp_timer能够运行。ESP_TIMER_ISR:定时器回调由定时器中断处理程序直接调度。对旨在降低延迟的简单回调,建议使用此途径。
定时器可以以单次模式和周期模式启动。
- 单次模式:定时器计时结束,调用回调函数,随后停止;
- 周期模式:定时器计时结束,调用回调函数,随后重新开始,周而复始。
这里采用单次模式+ESP_TIMER_TASK配置,API接口如下:
esp_timer_create:创建定时器;esp_timer_delete:删除定时器;esp_timer_start_once:启动单次模式定时器;esp_timer_stop:停止定时器,下一次启动使用esp_timer_start_once;esp_timer_get_time:获取从boot开始时间,单位为微秒。
多任务中存在对临界资源的访问,这里通过【互斥锁】加以保护。
测试代码:
#include "esp_timer.h"
esp_timer_handle_t oneshot_timer;
volatile char stillness_time_flag = 0; // 临界资源
SemaphoreHandle_t xSemaphore = NULL;
static const char* TAG = "example";
static void oneshot_timer_callback(void* arg)
{
xSemaphoreTake(xSemaphore, portMAX_DELAY);
stillness_time_flag = 1;
xSemaphoreGive(xSemaphore);
}
const esp_timer_create_args_t oneshot_timer_args = {
.callback = &oneshot_timer_callback,
/* argument specified here will be passed to timer callback function */
.arg = NULL,
.name = "one-shot"};
extern "C" void app_main(void)
{
ESP_ERROR_CHECK(esp_timer_create(&oneshot_timer_args, &oneshot_timer)); //定时器
xSemaphore = xSemaphoreCreateMutex(); //创建互斥量
assert(xSemaphore != NULL);
ESP_LOGI(TAG, "time since boot: %lld us", esp_timer_get_time());
esp_timer_stop(oneshot_timer);
usleep(2000000); 休眠2s
esp_timer_start_once(oneshot_timer, 200000);
ESP_LOGI(TAG, "time since boot: %lld us", esp_timer_get_time());
}
参考:
[1]: 高分辨率定时器(ESP 定时器)
[2]: esp_timer_example_main.c
7.2、交互方式选择:交互方式1
到这一步,通过上述动作设定,只需要最后静止的动作是训练的那些动作,就能完成捏住/增加/减小/松开的操作。
- 捏住状态: 选中操作对象;
- 捏住+上移:向右移动,选择操作对象;
- 捏住+下移:向左移动,选择操作对象;
- 交叉状态:操作对象增加;
- 松开状态:操作对象减小;
- 背景状态:取消对象选中。
7.3、交互方式选择:交互方式2
- 捏住=>交叉:操作对象增加;【判断逻辑同交互方式1】
- 交叉=>捏住:操作对象减小;
- 捏住=>松开:操作对象取消选择;【只需要判断最后一个动作即可】
- 松开=>捏住:选中操作对象;
- 捏住+上移:向右移动,选择操作对象;【判断逻辑同交互方式1】
- 捏住+下移:向左移动,选择操作对象。【判断逻辑同交互方式1】
如何区别【交叉=>捏住】和【松开=>捏住】
【交叉=>捏住】的操作序列可能为:1-1-2-...-2-2或者2-2-...-2-2-2
【松开=>捏住】的操作序列可能为:3-3-2-...-2-2或者2-2-...-2-2-2
【捏住=>捏住】的操作序列可能为:2-2-...-2-2-2
若操作序列为:2-2-...-2-2-2,如何区分?
- 这里考虑【交叉=>捏住】为减少,若前一组动作为【增加】,则判断当前操作为【减小】。
- 【松开=>捏住】和【捏住=>捏住】最后的状态为捏住,可不加以区分。
对于交互方式2,在运动过程中,边采集数据边推理,一些动作未加入训练集中训练,所以存在推理错误的情况,然而该组动作最后的操作结果依据这些操作序列得出,就可能导致判断出错。所所所所所以,上面的逻辑是理想的推理!
交互方式切换使用条件编译的方式进行选择:gesture_display.h文件下
#define INTERACTIVE_METHODS 1 // 1表示交互方式1, 2表示交互方式2
八、others
8.1、跑一下示例程序(MNIST)
- 下载 ESP-DL,可以使用以下命令,当然也可以直接在 github 网页中下载;
git clone https://github.com/espressif/esp-dl.git
- 打开终端
ESP-IDF 5.0 CMD,进入tutorial/convert_tool_example文件夹:
C: # windows下切换到C盘
dir # 查看当前路径下的文件列表
cd ~/esp-dl/tutorial/convert_tool_example # 切换路径
- 使用以下命令设置目标芯片:(当前芯片为 esp32s3)
idf.py set-target esp32s3
-
将PSRAM模式设置为
Octal Mode PSRAM:终端输入idf.py menuconfig => Component config => ESP PSRAM => SPI RAM config => Moda (QUAD/OCT) of SPI RAM chip in use (Quad Mode PSRAM) => Octal Mode PSRAM -
烧录固件,打印结果
idf.py flash monitor
参考:获取 ESP-DL 并运行示例
8.2、数据集补充程序
对于分类任务,或多或少有些类别没有被添加到数据集,且当前网络无法做到正确推理,所以在前面的基础上写了个数据集补充程序。
程序分为:PC端上位机(python)和 ESP32端下位机(C/C++)
程序操作步骤:
- 运行上位机程序,马上重启ESP32;
- ESP32采集手势数据(只要一直在运动就不停止数据采集,当停止采集后,就开始推理,并将推理结果发送到上位机);
- 上位机中输入label(0-背景/1-增加/2-捏住/3-减小)或者放弃(4-不添加该数据);
- 下位机收到数字后,若为标签数值,则将手势数据上传,若为放弃,则丢弃数据;
- 然后,开始新一轮的循环。