python-pptx库处理ppt代码示例
python-pptx模块是一个Python库,用于创建和更新Microsoft PowerPoint (.pptx)文件。
- 官网地址:https://python-pptx.readthedocs.io/en/latest/
- GITHUB: https://github.com/scanny/python-pptx
- PYPI: https://pypi.org/project/python-pptx
安装python-pptx第三方扩展
pip install python-pptx
一、 读取pptx中的内容
1.1 PPT的结构说明
在使用python操作PPT之前,首先应该清楚PPT的结构,这个对于之后代码的编写很有帮助。

1.2 PPTX提取演示文稿内容
我们可以使用Presentation()函数获取一个PPTX文件:
from pptx import Presentation
prs = Presentation("CEMS架构和中间件.pptx")
Presentation.slides获取获取所有幻灯片,文档共有27页,有27个slide
print(len(prs.slides))
for slide in prs.slides:
print(slide)

获取形状shape
# 输出第2张幻灯片的shapes 共有3个shape,标题,左侧图片,右侧文本
shapes = prs.slides[1].shapes
len(shapes),shapes
# 输出结果
(3, <pptx.shapes.shapetree.SlideShapes at 0x20c08052390>)
文本内容提取,has_text进行判断,也可通过MSO_SHAPE_TYPE判断
from pptx.enum.shapes import MSO_SHAPE_TYPE
for shape in shapes:
if shape.has_text_frame:
text_frame = shape.text_frame
print(text_frame.text)
# 也可以通过下面这种方式,更好判断每个shape的类型
if shape.shape_type == MSO_SHAPE_TYPE.TEXT_BOX:
text_frame = shape.text_frame
print(text_frame.text)
读取到ppt内容并输出

获取Shape中的某个Paragraph段落
text_frame = shape.text_frame
for paragraph in text_frame.paragraphs:
print(paragraph.text)

显示第二张幻灯片的图片内容,这里用到了cv2,numpy,matplotlib
pip install numpy
pip install opencv-python
pip install matplotlib
import cv2
import numpy as np
import matplotlib.pyplot as plt
shape = shapes[1]
if shape.shape_type == MSO_SHAPE_TYPE.PICTURE:
# shape.image.blob获取图片的blog信息
# 通过numpy的frombuffer转化
data = np.frombuffer(shape.image.blob,dtype=np.uint8)
# 将blob转换为图像
img = cv2.imdecode(data, cv2.IMREAD_COLOR)
plt.imshow(img)

二、 创建新pptx文件
2.1 PPT基本概念介绍
- 幻灯片模板及占位符的概念

- 什么是版式
我们在新增一页幻灯片的时候,会提示我们选择版式。pptx库中的slide_layouts列表数量和power point基础版式数量对应,格式对应。比如6为空模版,7为左侧图形,右侧文本的版式。
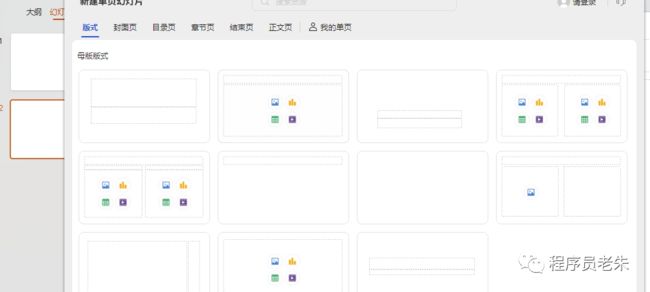
prs.slide_layouts[]传入0表示是第一个版式,传入1表示第二个版式,以此类推一直到结束48。
2.2 PPTX创建新的演示文稿代码
from pptx import Presentation
prs = Presentation()
#布局样式0-47
layout = prs.slide_layouts[0]
# 添加第一页幻灯片
slide = prs.slides.add_slide(layout)
title = slide.shapes.title
title.text = "这是第一个幻灯片"
subtitle = slide.placeholders[1]
subtitle.text = "正文框"
# 添加第2个幻灯片
layout = prs.slide_layouts[1]
slide = prs.slides.add_slide(layout)
title = slide.shapes.title
title.text = "这是第二个幻灯片"
body = slide.placeholders
body[1].text = "第二行正文"
# 添加第3个幻灯片
layout = prs.slide_layouts[2]
slide = prs.slides.add_slide(layout)
body = slide.placeholders
body[0].text = "这是第三个幻灯片"
body[1].text = "第三行正文"
prs.save("new.pptx")

通过段落添加内容,并设置相应样式
from pptx import Presentation
from pptx.util import Pt
from pptx.enum.text import PP_ALIGN
prs = Presentation()
#布局样式0-47
layout = prs.slide_layouts[0]
slide = prs.slides.add_slide(layout)
#每个layout中仅有2个占位符
body = slide.placeholders
body[0].text = "这是一个正文"
body[1].text = "第二行正文"
# 正文部分增加段落
paragraph = body[1].text_frame.add_paragraph()
paragraph.text ="要么做一个优秀的人,要么做一个懂事的人," \
"要在这世上混,没一点本事和能力还真不行的。"
# 左对齐
paragraph.alignment = PP_ALIGN.LEFT
# 粗体
paragraph.font.bold = True
# 斜体
paragraph.font.itatic = True
# 字体大小
paragraph.font.size = Pt(15)
# 下划线
paragraph.font.underline = True
prs.save('shape.pptx')

2.3 通过母版批量生成
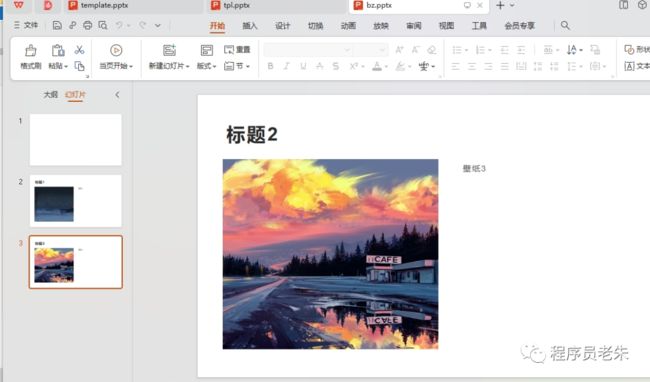
通过母版进行批量生成,新创建一个tpl.pptx的文件,格式如下:

这样我们通过爬虫,数据库等数据源获取数据,通过模版生成ppt格式,连同数据和格式写入最终ppt中了。
from pptx import Presentation
prs = Presentation('tpl.pptx')
bzs = [
{"title":"标题1","img":r"E:\美女照片\4K动态壁纸\4K动态壁纸 (1).png","content":"壁纸3"},
{"title":"标题2","img":r"E:\美女照片\4K动态壁纸\4K动态壁纸 (2).png","content":"壁纸3"}
]
for bz in bzs:
tpl_num = len(prs.slide_layouts)
# 上面的板式是7
slide = prs.slides.add_slide(prs.slide_layouts[7])
body = slide.shapes.placeholders
for index,shape in enumerate(body):
if index == 0:
shape.text = bz["title"]
if index == 1:
shape.insert_picture(bz['img'])
if index == 2:
shape.text = bz["content"]
# 保存壁纸的ppts
prs.save("bz.pptx")