Suricata/Snort规则参考
Suricata/Snort规则参考
文章目录
- Suricata/Snort规则参考
-
- 限制
- 优势
- 6. Suricata 规则
-
- 6.1. 规则格式
-
- 6.1.1. 动作(Action)
- 6.1.2. 协议(Protocol)
- 6.1.3. 源和目的(Source and destination)
- 6.1.4. 端口(Source and destination)
- 6.1.5. 方向(Direction)
- 6.1.6. 规则选项(Rule options)
- 6.1.6.1. 修饰器关键词(Modifier Keywords)
- 6.1.6.2. 规范化的缓冲区(Normalized Buffers)
- 6.2. Meta Keywords
-
- 6.2.1. msg (message)
- 6.2.2. sid (签名ID)
- 6.2.3. rev (版本)
- 6.2.4. gid (组ID)
- 6.2.5. classtype (类别)
- 6.2.6. reference (引用/参考)
- 6.2.7. priority (优先级)
- 6.2.8. metadata (元数据)
- 6.2.9. target (目标)
- 6.3. IP Keywords
-
- 6.3.1. ttl
- 6.3.2. ipopts
- 6.3.3. sameip
- 6.3.4. ip_proto
- 6.3.5. ipv4.hdr
- 6.3.6. ipv6.hdr
- 6.3.7. id
- 6.3.8. geoip
- 6.3.9. fragbits (IP fragmentation)
- 6.3.10. fragoffset
- 6.3.11. tos
- 6.4. TCP Keywords
-
- 6.4.1. seq
- 6.4.2. ack
- 6.4.3. window
- 6.4.4 tcp.mss
- 6.4.5 tcp.hdr
- 6.5. UDP Keywords
-
- 6.5.1. udp.hdr
- 6.6. ICMP Keywords
-
- 6.6.1. itype
- 6.6.2. icode
- 6.6.3. icmp_id
- 6.6.4. icmp_seq
- 6.6.5. icmpv6.hdr
- 6.6.6. icmpv6.mtu
- 6.7. Payload Keywords
-
- 6.7.1. content
- 6.7.2. nocase
- 6.7.3. depth
- 6.7.4. startsWith
- 6.7.5. endswith
- 6.7.6. offset
- 6.7.7. distance
- 6.7.8. within
- 6.7.9. isdataat
- 6.7.10. bsize
- 6.7.11. dsize
- 6.7.12. byte_test
- 6.7.13. byte_math
- 6.7.14. byte_jump
- 6.7.15. byte_extract
- 6.7.16. rpc
- 6.7.17. replace
- 6.7.18. pcre (Perl Compatible Regular Expressions)
-
- 6.7.18.1. Suricata’s modifiers
- 6.8. Transformations(转换)
- 6.9. Prefiltering Keywords(前置筛选关键词)
- 6.10. Flow Keywords
-
- 6.10.1. flowbits
- 6.10.2. flow
- 6.10.3. flowint
- 6.10.4. stream_size
- 6.11. Bypass 关键词
-
- 6.11.1. bypass
- 6.12. HTTP 关键词
- 6.13. 文件关键词
- 6.13.1. filename
- 6.13.2. fileext
- 6.13.3. filemagic
- 6.13.4. filestore
- 6.13.5. filemd5
- 6.13.6. filesha1
- 6.13.7. filesha256
- 6.13.8. filesize
- 6.14. DNS 关键词
Suricata是一款开源IDS/IPS/NSM引擎,兼容Snort规则
限制
截至Suricata 6.0.0
- 不支持请求-响应双向匹配,单条规则只支持请求或者响应
- 不支持复杂的逻辑运算,只支持并且
优势
- 规则支持众多协议类型
- 规则支持多种解码、编码匹配方式
- 规则支持多种预定义函数转换方式
6. Suricata 规则
6.1. 规则格式
攻击特征在Suricata中扮演了一个非常重要的角色。在大多数场景下,使用现有的规则库即可满足大多数场景需求。
官方安装规则库的方式参照:Rule Management with Suricata-Update
Suricata规则文档解释了如何读懂规则、按需调整规则以及创建一个新规则等所有特征相关的方面。
一条规则/特征包括如下部分:
- 动作(action),用来决定当特征匹配成功后如何处理。
- 头信息(header),定义应用规则的协议、IP地址、端口和方向。
- 规则选项(rule options),定义规则的特征。
如下是一条规则示例:
drop tcp $HOME_NET any -> $EXTERNAL_NET any (msg:"ET TROJAN Likely Bot Nick in IRC (USA +..)"; flow:established,to_server; flowbits:isset,is_proto_irc; content:"NICK "; pcre:"/NICK .*USA.*[0-9]{3,}/i"; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
将上面的示例拆解:
1. 动作 -> drop
2. 头信息 -> tcp $HOME_NET any -> $EXTERNAL_NET any
3. 规则选项 -> (msg:"ET TROJAN Likely Bot Nick in IRC (USA +..)"; flow:established,to_server; flowbits:isset,is_proto_irc; content:"NICK "; pcre:"/NICK .*USA.*[0-9]{3,}/i"; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
在本节中,我们将使用上述规则签名作为示例,突出解释签名的不同部分。它是从Emerging Threats数据库中提取的签名,这是一个开放数据库,具有许多规则,您可以免费下载并在您的Suricata实例中使用。
6.1.1. 动作(Action)
drop <————
tcp $HOME_NET any -> $EXTERNAL_NET any (msg:"ET TROJAN Likely Bot Nick in IRC (USA +..)"; flow:established,to_server; flowbits:isset,is_proto_irc; content:"NICK "; pcre:"/NICK .*USA.*[0-9]{3,}/i"; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
示例中为:drop
有效的动作取值为:
- alert - 生成一条告警
- pass - 停止对数据包的进一步检查
- drop - 弃数据包并生成告警
- reject - 发送RST/ICMP unreach 错误到匹配数据包的发送方。
- rejectsrc - 与 reject 含义相同
- rejectdst - 发送RST/ICMP错误数据包到匹配数据包的接收方。
- rejectboth - 向对话双方发送RST/ICMP错误数据包。
!注意 在IPS模式中, 使用任何的
reject动作,同时也会触发drop动作。
更多关于动作(Action)的详细信息请参阅:Action-order
6.1.2. 协议(Protocol)
drop
tcp <————
$HOME_NET any -> $EXTERNAL_NET any (msg:"ET TROJAN Likely Bot Nick in IRC (USA +..)"; flow:established,to_server; flowbits:isset,is_proto_irc; content:"NICK "; pcre:"/NICK .*USA.*[0-9]{3,}/i"; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
示例中为:tcp
规则中的协议关键词告诉Suricata该规则应该应用哪种协议。你可以在四个基础协议中选择:
- tcp (for tcp-traffic)
- udp
- icmp
- ip (ip stands for ‘all’ or ‘any’)
还有一些叫做应用层协议,或者7层协议的选择项:
- http
- ftp
- tls (this includes ssl)
- smb
- dns
- dcerpc
- ssh
- smtp
- imap
- modbus (disabled by default)
- dnp3 (disabled by default)
- enip (disabled by default)
- nfs
- ikev2
- krb5
- ntp
- dhcp
- rfb
- rdp
- snmp
- tftp
- sip
- http2
这些协议的可用性取决于配置文件suricata.yaml中是否启用了该协议。
如果您有一个协议标记为http的规则,Suricata确保规则只有在涉及http流量时才能匹配。
6.1.3. 源和目的(Source and destination)
drop tcp
$HOME_NET <————
any ->
$EXTERNAL_NET <————
any
(msg:"ET TROJAN Likely Bot Nick in IRC (USA +..)"; flow:established,to_server; flowbits:isset,is_proto_irc; content:"NICK "; pcre:"/NICK .*USA.*[0-9]{3,}/i"; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
示例中为:$HOME_NET $EXTERNAL_NET
第一个强调的部分$HOME_NET是源,第二个是目的$EXTERNAL_NET(注意方向箭头的方向)。
通过设置源和目的,可以分别指定网络通信的源和目的。你可以为源和目的分配IP地址(IPv4和IPv6都支持)和IP地址段,并且可以通过操作符进行组合:
| 操作符 | 描述 | 示例 |
|---|---|---|
| …/… | IP段 (CIDR记号法) | 192.168.1.1/24 |
| ! | 除去/取反 | !192.168.1.125 |
| […, …] | 组合 | [192.168.1.2, 192.168.1.3] |
你也可以使用变量来设置,例如:$HOME_NET、$EXTERNAL_NET。这些变量表示预定义的IP地址,预定义的内容可以在suricata-yaml配置文件中修改。详情参考:Rule-vars
示例:
| 示例 | 含义 |
|---|---|
| !1.1.1.1 | 除1.1.1.1之外的所有IP |
| ![1.1.1.1, 1.1.1.2] | 除1.1.1.1 和 1.1.1.2之外的所有IP |
| $HOME_NET | 在yaml配置文件中配置的 HOME_NET 变量 |
| [ E X T E R N A L N E T , ! EXTERNAL_NET, ! EXTERNALNET,!HOME_NET] | EXTERNAL_NET 和 非 HOME_NET |
| [10.0.0.0/24, !10.0.0.5] | 除去10.0.0.5之外的10.0.0.0/24 IP段 |
| […, [….]] | |
| […, ![……]] |
!警告
如何你的配置像这样:
HOME_NET: any
EXTERNAL_NET: ! $HOME_NET
您不能使用$EXTERNAL_NET编写签名,因为它代表“not any”。这是一个无效的设置。
6.1.4. 端口(Source and destination)
drop tcp $HOME_NET
any <————
-> $EXTERNAL_NET
any <————
(msg:"ET TROJAN Likely Bot Nick in IRC (USA +..)"; flow:established,to_server; flowbits:isset,is_proto_irc; content:"NICK "; pcre:"/NICK .*USA.*[0-9]{3,}/i"; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
第一个强调的部分是源端口,第二个是目的端口(注意方向箭头的方向)。
通信通过端口进出。不同的端口有不同的端口号。例如,HTTP的默认端口是80,而443通常是HTTPS的端口。但是请注意,端口并不规定在通信中使用哪个协议。相反,它确定哪个应用程序正在接收数据。
上述提到的端口通常是目的端口。源端口是应用程序用来发送数据的端口,一般由操作系统随机分配。当你需要为你的HTTP服务写一个规则时,你通常可以写any -> 80,它表示当任何源端口发送到80端口的数据才会进行规则匹配。
在设置端口时,你也可以操作符,如下所示:
| 操作符 | 描述 |
|---|---|
| : | 端口范围 |
| ! | 除去/取非 |
| […, …] | 组合 |
示例:
| 示例 | 含义 |
|---|---|
| [80, 81, 82] | 端口 80, 81 和 82 |
| [80: 82] | 端口范围 80 到 82 |
| [1024: ] | 从1024 到 最大的端口 |
| !80 | 除去80之外的所有端口 |
| [80:100,!99] | 端口范围 80 到 100,除去 99 |
| [1:80,![2,4]] | 端口范围 1-80, 除去 2 和 4 |
| […, […,…]] |
6.1.5. 方向(Direction)
drop tcp $HOME_NET any
-> <————
$EXTERNAL_NET any (msg:"ET TROJAN Likely Bot Nick in IRC (USA +..)"; flow:established,to_server; flowbits:isset,is_proto_irc; content:"NICK "; pcre:"/NICK .*USA.*[0-9]{3,}/i"; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
方向说明以何种方式匹配签名。几乎每个签名都有一个向右的箭头(->)。这意味着只有方向相同的数据包才能匹配。当然,也有一个规则匹配的两个方向(<>):
source -> destination
source <> destination (both directions)
!警告
没有反方向的方向表示,也就是说,没有<-。
下面的示例说明了这一点。假设,有一个客户端,IP地址为1.2.3.4,端口为1024,还有一个服务器,IP地址为5.6.7.8,监听端口为80(通常是HTTP)。客户机向服务器发送一条消息,服务器返回了响应信息。

现在,假设我们有一个规则,它的头信息如下:
alert tcp 1.2.3.4 1024 -> 5.6.7.8 80
只有第一个数据包会被这个规则匹配,因为方向指定了,所有我们不匹配响应包。
6.1.6. 规则选项(Rule options)
规则的其余部分由选项组成。它们用圆括号括着,用分号分隔着。有些选项具有设置(如msg),由选项的关键字、冒号和设置指定。其他的没有设置,只是关键字(如nocase):
: ;
;
规则选项具有特定的顺序,更改它们的顺序将改变规则的含义。
!注意
字符;和"在Suricata规则语言中具有特殊意义,在规则选项值中使用时必须转义。例如:
msg:"Message with semicolon\;";
因此,还必须转义反斜杠,因为它是转义字符。
本章的其余部分在文档中记录了各种关键字的使用。
下面是一些关于关键词的通用细节。
6.1.6.1. 修饰器关键词(Modifier Keywords)
一些关键字的功能作为修饰语。修饰语有两种类型。
- 旧样式的“内容修饰符”在
content:"";后面,例如:
alert http any any -> any any (content:"index.php"; http_uri; sid:1;)
在上面的例子中,模式'index.php'被修饰用来检测HTTP uri缓存区。
也就是说,当http数据包的uri部分包括
index.php关键词时,才会触发告警。
- 最近的一种被称为“粘性缓冲”。它将缓冲区名称放在首位,然后所有紧随它后面的关键字应用到该缓冲区,例如:
alert http any any -> any any (http_response_line; content:"403 Forbidden"; sid:1;)
在上面的例子中,当模式'403 Forbidden'在HTTP response line中出现时触发告警,因为它紧随http_response_line关键词。
6.1.6.2. 规范化的缓冲区(Normalized Buffers)
数据包由原始数据组成。HTTP和reassembly复制了这些类型的数据包数据。它们清除异常内容,组合数据包等等。剩下的就是所谓的“标准化缓冲区”:
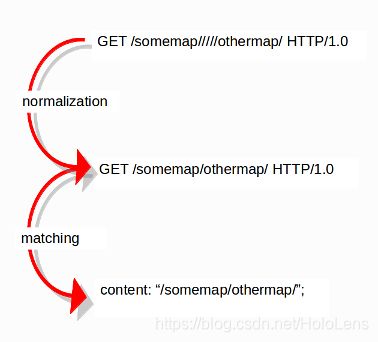
因为数据被标准化了,它不再是以前的样子了;这是一种解释。规范化的缓冲区是:所有http关键字、重新组装的流、TLS-、SSL-、SSH-、FTP-和dcerpc-缓冲区。
注意有一些例外,例如http_raw_uri关键字。参见:http.uri and http.uri.raw获取更多信息。
6.2. Meta Keywords
Meta Keywords不会影响任何Suricata规则检测行为;它们只影响Suricata的告警事件输出格式。
6.2.1. msg (message)
关键字msg给出关于规则和告警的合理的文本信息。
msg的格式为:
msg: "some description";
例子:
msg:"ATTACK-RESPONSES 403 Forbidden";
msg:"ET EXPLOIT SMB-DS DCERPC PnP bind attempt";
继续上一章的例子,这是关键字在实际规则的行动:
drop tcp $HOME_NET any -> $EXTERNAL_NET any (msg:”ET TROJAN Likely Bot Nick in IRC (USA +..)”; flow:established,to_server; flowbits:isset,is_proto_irc; content:”NICK “; pcre:”/NICK .*USA.*[0-9]{3,}/i”; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
msg:”ET TROJAN Likely Bot Nick in IRC (USA +..)”;
惯例是将msg作为规则选项的第一个关键字,并且这部分以大写表示,突出显示签名的类别。
这些字符如出现在msg中必须进行转义:; \ "
6.2.2. sid (签名ID)
关键字sid为每个签名提供自己的id。这个id规定使用数字进行声明。sid的格式如下:
sid:123;
sid在一个规则中的例子:
drop tcp $HOME_NET any -> $EXTERNAL_NET any (msg:”ET TROJAN Likely Bot Nick in IRC (USA +..)”; flow:established,to_server; flowbits:isset,is_proto_irc; content:”NICK “; pcre:”/NICK .*USA.*[0-9]{3,}/i”; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
按照惯例,签名sid作为签名的最后一个关键字(如果有rev,则倒数第二)提供。
6.2.3. rev (版本)
sid关键字几乎每次都伴随着rev。rev代表签名的版本。如果签名被修改,rev的数量将由签名作者增加。rev格式为:
rev:123;
一个规则中包含rev的例子:
drop tcp $HOME_NET any -> $EXTERNAL_NET any (msg:”ET TROJAN Likely Bot Nick in IRC (USA +..)”; flow:established,to_server; flowbits:isset,is_proto_irc; content:”NICK “; pcre:”/NICK .*USA.*[0-9]{3,}/i”; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
按照惯例,sid出现在rev之前,并且两者都是所有关键字中的最后一个。
6.2.4. gid (组ID)
gid关键字可用于提供另一个id值来表示不同的签名组(就像sid)。Suricata默认使用gid 1。这是可以修改的。通常情况下,它不会被改变,而且改变它没有技术含义。您只能在告警中观察到它的变化。
如下是一个有gid的告警示例,此告警打印在fast.log文件中。在[1:2008124:2]部分,1 是 gid,2008124是 sid,2 是 rev。
10/15/09-03:30:10.219671 [**] [1:2008124:2] ET TROJAN Likely Bot Nick in IRC (USA +..) [**] [Classification: A Network Trojan was Detected] [Priority: 3] {TCP} 192.168.1.42:1028 -> 72.184.196.31:6667
6.2.5. classtype (类别)
classtype关键字提供了关于规则和告警的分类信息。它包括一个短名称,一个长名称和一个优先级。它可以分辨出一个规则是仅仅提供信息还是匹配攻击行为等等。对于每个classtype,classification.config中有一个优先级可以在规则中被使用。
classtype定义示例:
config classification: web-application-attack,Web Application Attack,1
config classification: not-suspicious,Not Suspicious Traffic,3
现在当我们在配置中定义了如上配置之后,我们就可以在规则中使用这些classtype。一个使用web-application-attackclasstype的规则将被分配优先级1,并且告警将包含’Web Application Attack’:
| classtype | Alert | Priority |
|---|---|---|
| web-application-attack | Web Application Attack | 1 |
| not-suspicious | Not Suspicious Traffic | 3 |
我们接下来的例子也有一个classtype,这个是trojan-activity:
drop tcp $HOME_NET any -> $EXTERNAL_NET any (msg:”ET TROJAN Likely Bot Nick in IRC (USA +..)”; flow:established,to_server; flowbits:isset,is_proto_irc; content:”NICK “; pcre:”/NICK .*USA.*[0-9]{3,}/i”; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
按照惯例,classtype出现在sid和rev之前,并出现在其他关键字之后。
6.2.6. reference (引用/参考)
reference关键字指向可以找到关于签名和签名试图解决的问题的信息的位置。reference关键字可以在签名中出现多次。这个关键字是为研究签名匹配原因的签名作者和分析人员设计的。它的格式如下:
reference: type, reference
一个典型的指向www.info.com的reference可以这么写:
reference: url, www.info.com
但是,还有一些系统可以作为参考。一个常见的例子是CVE-database,它为漏洞分配了唯一的ID。为了防止你一遍又一遍地输入相同的URL,你可以使用这样的写法:
reference: cve, CVE-2014-1234
这种写法可以自动生成一个指向http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2014-1234的引用。所有的引用类型在reference.config配置文件中定义。
我们接下来的例子也有一个引用:
drop tcp $HOME_NET any -> $EXTERNAL_NET any (msg:”ET TROJAN Likely Bot Nick in IRC (USA +..)”; flow:established,to_server; flowbits:isset,is_proto_irc; content:”NICK “; pcre:”/NICK .*USA.*[0-9]{3,}/i”; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
6.2.7. priority (优先级)
priority关键字的值必须使用数字,范围从1到255。数字1到4是最常用的。优先级较高的签名将首先被检查。最高优先级是1。通常,配置了classtype的签名已经有了优先级。但是我们可以用关键字priority来重新设置。优先级的形式是:
priority:1;
6.2.8. metadata (元数据)
元数据关键字允许将附加的、非功能的信息添加到签名中。尽管它的格式没有限制,但建议坚持使用键、值对,因为Suricata可以将它们包含在eve告警中。格式是:
metadata: key value;
metadata: key value, key value;
6.2.9. target (目标)
target关键字允许规则编写人员指定警报的哪一边是攻击的目标。如果指定,告警事件将增强为包含有关源和目标的信息。
格式是:
target:[src_ip|dest_ip]
如果值是src_ip,那么生成事件中的源IP (JSON格式的src_ip字段)就是攻击的目标。如果target被设置为dest_ip,那么目的IP就是生成事件中的目标IP。
6.3. IP Keywords
6.3.1. ttl
ttl关键字用于检查包头中的特定IP生存时间(time-to-live)值。格式是:
ttl:
例如:
ttl:10;
在ttl关键字的末尾,您可以输入想要匹配的值。生存时间值决定了数据包在网络传输中可以存在的最大时间。如果该字段被设置为0,则必须销毁该数据包。生存时间基于跳数。数据包通过的每一跳/路由器减去一个数据包TTL计数器。这个机制的目的是限制数据包的存在,防止数据包不能在无限的路由循环中结束。
ttl关键字在规则中的例子:
alert ip $EXTERNAL_NET any -> $HOME_NET any (msg:”GPL MISC 0 ttl”; ttl:0; reference:url,support.microsoft.com/default.aspx?scid=kb#-#-EN-US#-#-q138268; reference:url,www.isi.edu/in-notes/rfc1122.txt; classtype:misc-activity; sid:2101321; rev:9;)
6.3.2. ipopts
使用ipopts关键字,您可以检查是否设置了特定的IP选项。Ipopts必须在规则的开头使用。每个规则只能匹配一个选项。有几个选项可以匹配。它们是:
| IP Option | Description |
|---|---|
| rr | Record Route |
| eol | End of List |
| nop | No Op |
| ts | Time Stamp |
| sec | IP Security |
| esec | IP Extended Security |
| lsrr | Loose Source Routing |
| ssrr | Strict Source Routing |
| satid | Stream Identifier |
| any | any IP options are set |
ipopts关键词格式:
ipopts:
例子:
ipopts: lsrr;
规则中的ipopts示例:
alert ip $EXTERNAL_NET any -> $HOME_NET any (msg:”GPL MISC source route ssrr”; ipopts:ssrr; reference:arachnids,422; classtype:bad-unknown; sid:2100502; rev:3;)
6.3.3. sameip
每个包有一个源ip地址和一个目的ip地址。源IP可能与目标IP相同。使用sameip关键字,您可以检查源的IP地址是否与目标的IP地址相同。sameip关键字的格式为:
sameip;
规则中的sameip示例:
alert ip any any -> any any (msg:”GPL SCAN same SRC/DST”; sameip; reference:bugtraq,2666; reference:cve,1999-0016; reference:url,www.cert.org/advisories/CA-1997-28.html; classtype:bad-unknown; sid:2100527; rev:9;)
6.3.4. ip_proto
您可以使用关键字ip_proto匹配包头中的IP协议。您可以使用协议的名称或编号。例如,您可以匹配以下协议:
1 ICMP Internet Control Message
6 TCP Transmission Control Protocol
17 UDP User Datagram
47 GRE General Routing Encapsulation
50 ESP Encap Security Payload for IPv6
51 AH Authentication Header for Ipv6
58 IPv6-ICMP ICMP for Ipv6
有关协议及其编号的完整列表,请参阅:http://en.wikipedia.org/wiki/List_of_IP_protocol_numbers
规则中的ip_proto示例:
alert ip any any -> any any (msg:”GPL MISC IP Proto 103 PIM”; ip_proto:103; reference:bugtraq,8211; reference:cve,2003-0567; classtype:non-standard-protocol; sid:2102189; rev:4;)
该示例的ip_proto也可以使用名称表示为:
ip_proto:PIM
6.3.5. ipv4.hdr
匹配整个IPv4 header的Sticky buffer。
示例规则:
alert ip any any -> any any (ipv4.hdr; content:”|3A|”; offset:9; depth:1; sid:1234; rev:5;)
这个例子检查IPv4 header的第9个字节的值是否为3A。它表示IPv4 protocol是ICMPv6。
6.3.6. ipv6.hdr
匹配整个IPv6 header的Sticky buffer。
6.3.7. id
通过id关键词,你可以匹配一个特定的IP ID值。这个ID标识主机发送出去的每个packet,并且每次发送ID都递增1。IP ID可以用来作为碎片标识数字。每个packet都有一个IP ID,并且当一个packet在网络中传输变成一些碎片时,所有这个packet的碎片都有相同的ID。通过这种方式,packet的接收者可以知道哪些碎片属于相同的packet。(IP ID不关心顺序,这种情况需要使用offset,它可以帮助分清碎片的顺序。)
id的格式:
id:;
规则中的id示例:
alert tcp $EXTERNAL_NET any -> $HOME_NET any (msg:”ET DELETED F5 BIG-IP 3DNS TCP Probe 1”; id: 1; dsize: 24; flags: S,12; content:”|00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00|”; window: 2048; reference:url,www.f5.com/f5products/v9intro/index.html; reference:url,doc.emergingthreats.net/2001609; classtype:misc-activity; sid:2001609; rev:13;)
6.3.8. geoip
geoip关键字允许(您)匹配网络流量的源、目的地或源和目的地IPv4地址,并查看它属于哪个国家。为了能够做到这一点,Suricata使用MaxMind的GeoIP2 API。
geoip语法:
geoip: src,RU;
geoip: both,CN,RU;
geoip: dst,CN,RU,IR;
geoip: both,US,CA,UK;
geoip: any,CN,IR;
因此,您可以使用以下内容来明确您想要匹配的方向:
| Option | Description |
|---|---|
| both | Both directions have to match with the given geoip(s) |
| any | One of the directions has to match with the given geoip(s). |
| dest | If the destination matches with the given geoip. |
| src | The source matches with the given geoip. |
关键字只支持IPv4。由于使用MaxMind的GeoIP2 API,libmaxminddb必须编译进来。您必须下载并安装所需的GeoIP2或GeoLite2数据库版本。访问MaxMind网站https://dev.maxmind.com/geoip/geoip2/geolite2/获取详细信息。
您还必须在本地yaml配置文件中提供GeoIP2或GeoLite2数据库文件的位置(例如):
geoip-database: /usr/local/share/GeoIP/GeoLite2-Country.mmdb
6.3.9. fragbits (IP fragmentation)
使用fragbits关键字,可以检查碎片和保留位是否在IP header中设置。fragbits关键字应该放在规则的开头。fragbits用于修饰碎片机制。在将消息从一个Internet模块路由到另一个Internet模块时,可能会出现包大于网络所能处理的最大包大小的情况。在这种情况下,数据包可以以片段的形式发送。这个数据包大小的最大值称为最大传输单元(MTU)。
你可以匹配以下位:
M - More Fragments
D - Do not Fragment
R - Reserved Bit
匹配在这个位可以更指定以下修饰器:
+ match on the specified bits, plus any others
* match if any of the specified bits are set
! match if the specified bits are not set
格式:
fragbits:[*+!]<[MDR]>;
规则中的fragbits示例:
alert tcp $EXTERNAL_NET any -> $HOME_NET any (msg:”ET EXPLOIT Invalid non-fragmented packet with fragment offset>0”; fragbits: M; fragoffset: >0; reference:url,doc.emergingthreats.net/bin/view/Main/2001022; classtype:bad-unknown; sid:2001022; rev:5; metadata:created_at 2010_07_30, updated_at 2010_07_30;)
6.3.10. fragoffset
使用fragoffset关键字,您可以匹配IP片段偏移字段的特定十进制值。如果您想要检查会话的第一个片段,您必须结合fragoffset 0和More Fragment(fragbits: M)选项。碎片偏移量字段便于重新组装。id用于确定哪个片段属于哪个包,而碎片偏移字段澄清了片段的顺序。
你可以使用以下修饰词:
< match if the value is smaller than the specified value
> match if the value is greater than the specified value
! match if the specified value is not present
fragoffset格式:
fragoffset:[!|<|>];
规则中的fragoffset示例:
alert tcp $EXTERNAL_NET any -> $HOME_NET any (msg:”ET EXPLOIT Invalid non-fragmented packet with fragment offset>0”; fragbits: M; fragoffset: >0; reference:url,doc.emergingthreats.net/bin/view/Main/2001022; classtype:bad-unknown; sid:2001022; rev:5; metadata:created_at 2010_07_30, updated_at 2010_07_30;)
6.3.11. tos
tos关键字可以匹配IP头tos字段的特定十进制值。tos关键字的值可以是0 - 255。IP报头的这个字段已经被rfc2474更新,以包含用于差异化服务功能。注意,字段的值被定义为最右边的2位的值为0。当为tos指定一个值时,确保该值符合这个规则。
例如,不是指定十进制值34(十六进制22),而是右移两次并使用十六进制88)。
可以用前导x指定十六进制值,例如x88。
tos的格式:
tos:[!];
规则中的tos示例:
alert ip any any -> any any (msg:”Differentiated Services Codepoint: Class Selector 1 (8)”; flow:established; tos:8; classtype:not-suspicious; sid:2600115; rev:1;)
带有否定值的tos示例:
alert ip any any -> any any (msg:”TGI HUNT non-DiffServ aware TOS setting”; flow:established,to_server; tos:!0; tos:!8; tos:!16; tos:!24; tos:!32; tos:!40; tos:!48; tos:!56; threshold:type limit, track by_src, seconds 60, count 1; classtype:bad-unknown; sid:2600124; rev:1;)
6.4. TCP Keywords
6.4.1. seq
seq关键字可以在签名中用于检查特定的TCP序列号。序列号是tcp连接的两个端点实际上随机生成的数字。客户端和服务器都创建一个序列号,序列号每发送一个字节就增加一个。所以两边的序号都不一样。这个序列号必须由连接的双方确认。通过序列号,TCP处理acknowledgement(确认), order(顺序)和 retransmission(重传)它的数字随着发送方发送的每一个数据字节而增加。seq帮助跟踪一个字节在数据流中的位置。如果SYN标志被设置为1,那么数据的第一个字节的序列号就是这个数字加上1(所以是2)。
例子:
seq:0;
签名中的seq示例:
alert tcp $EXTERNAL_NET any -> $HOME_NET any (msg:”GPL SCAN NULL”; flow:stateless; ack:0; flags:0; seq:0; reference:arachnids,4; classtype:attempted-recon; sid:2100623; rev:7;)
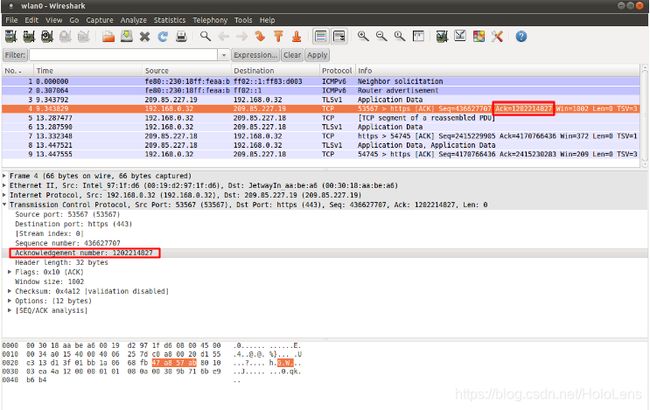
数据包中的seq示例(Wireshark):

6.4.2. ack
ack是tcp连接的另一端收到之前发送的所有(数据)字节的确认。在大多数情况下,TCP连接的每个包在第一个SYN之后都有一个ACK标志,并且ack-number随着每个新数据字节的接收而增加。ack关键字可以在签名中用于检查特定的TCP确认号。
ack的格式:
ack:1;
签名中的ack示例:
alert tcp $EXTERNAL_NET any -> $HOME_NET any (msg:”GPL SCAN NULL”; flow:stateless; ack:0; flags:0; seq:0; reference:arachnids,4; classtype:attempted-recon; sid:2100623; rev:7;)
包中的ack的例子(Wireshark):
6.4.3. window
window关键词用来指定TCP窗口大小。TCP窗口大小是一个用来控制数据流的机制。这个窗口大小由接收者设定(receiver advertised window size),并且表明了它可以接收的字节数量。在发送方可以发送相同数量的新数据之前,接收方必须首先确认此数据量。这种机制是用来防止接收器被数据溢出。窗口大小的值被限制在2到65.535字节。为了更好地利用带宽,可以使用更大的TCP窗口。
窗口关键字的格式:
window:[!];
一个规则中的窗口的例子:
alert tcp $EXTERNAL_NET any -> $HOME_NET any (msg:”GPL DELETED typot trojan traffic”; flow:stateless; flags:S,12; window:55808; reference:mcafee,100406; classtype:trojan-activity; sid:2182; rev:8;)
以上规则用于病毒检测:参考https://blog.csdn.net/richerg85/article/details/25079865
病毒名称:Trojan.Linux.Typot.a
类别: 木马病毒
破坏方法:
该病毒是在Linux操作系统下的木马,木马运行后每隔几秒就发送一个TCP包,其目的IP和源IP地址是随机的,这个包中存在固定的特征,包括 TCP window size等<在这里为55808>,同时,病毒会嗅探网络,如果发现TCP包的window size等于55808,就会在当前目录下生成一个文件<文件名为:r>,每隔24小时,病毒检测是否存在文件 “r”,如果存在,就会试图连接固定的IP地址<可能为木马的客户端>,如果连接成功,病毒就会删除文件:/tmp/……/a并退出
6.4.4 tcp.mss
匹配TCP MSS选项值。如果选项不存在,将不匹配。
关键字格式:
tcp.mss:-;
tcp.mss:[<|>];
tcp.mss:;
示例规则:
alert tcp $EXTERNAL_NET any -> $HOME_NET any (flow:stateless; flags:S,12; tcp.mss:<536; sid:1234; rev:5;)
6.4.5 tcp.hdr
粘贴缓冲区来匹配整个TCP报头。
示例规则:
alert tcp $EXTERNAL_NET any -> $HOME_NET any (flags:S,12; tcp.hdr; content:”|02 04|”; offset:20; byte_test:2,<,536,0,big,relative; sid:1234; rev:5;)
This example starts looking after the fixed portion of the header, so into the variable sized options. There it will look for the MSS option (type 2, option len 4) and using a byte_test determine if the value of the option is lower than 536. The tcp.mss option will be more efficient, so this keyword is meant to be used in cases where no specific keyword is available.
6.5. UDP Keywords
6.5.1. udp.hdr
粘贴缓冲区匹配整个UDP头。
示例规则:
alert udp any any -> any any (udp.hdr; content:”|00 08|”; offset:4; depth:2; sid:1234; rev:5;)
这个例子匹配UDP头部的length字段。在这里length字段的值是8,意思是没有payload。也可以使用dsize:0;来达到同样的效果。
6.6. ICMP Keywords
ICMP (Internet Control Message Protocol) 是IP的一部分。在传输数据时,IP本身并不可靠(datagram数据报)。ICMP在出现问题时给予反馈。它不能阻止问题的发生,但是可以帮助搞清楚何时发生了什么问题。如果可靠性是必须的,那么建立在IP之上的协议就得自己考虑可靠性。ICMP消息被发送的情况有多种。例如,当目的不可达时,当没有足够的缓存去转发数据时,或者当一个数据报被分片发送但是不应该被分片发送时,等等,更多请参见message-types列表。
ICMP消息中有4个重要内容可以与对应的ICMP关键字进行匹配。它们是:type,code,id和sequence。
6.6.1. itype
itype关键字用于匹配特定的ICMP类型(数字)。ICMP有几种类型的消息,并且使用编号来表示每种消息。不同的消息因不同的名称而不同,但更重要的是数字值。有关更多信息,请参见带有消息类型和代码的表。
itype关键词的格式:
itype:min<>max;
itype:[<|>];
例子:(这个例子寻找一个大于10的ICMP类型)
itype:>10;
规则实例(Smurf攻击):
alert icmp $EXTERNAL_NET any -> $HOME_NET any (msg:”GPL SCAN Broadscan Smurf Scanner”; dsize:4; icmp_id:0; icmp_seq:0; itype:8; classtype:attempted-recon; sid:2100478; rev:4;)
以上规则用于病毒检测,参考:https://baike.baidu.com/item/Smurf%E6%94%BB%E5%87%BB/9112141?fr=aladdin
下面列出了撰写本文时已知的所有ICMP类型。最新的表格可以在IANA的网站上找到。
| ICMP Type | Name |
|---|---|
| 0 | Echo Reply |
| 3 | Destination Unreachable |
| 4 | Source Quench |
| 5 | Redirect |
| 6 | Alternate Host Address |
| 8 | Echo |
| 9 | Router Advertisement |
| 10 | Router Solicitation |
| 11 | Time Exceeded |
| 12 | Parameter Problem |
| 13 | Timestamp |
| 14 | Timestamp Reply |
| 15 | Information Request |
| 16 | Information Reply |
| 17 | Address Mask Request |
| 18 | Address Mask Reply |
| 30 | Traceroute |
| 31 | Datagram Conversion Error |
| 32 | Mobile Host Redirect |
| 33 | IPv6 Where-Are-You |
| 34 | IPv6 I-Am-Here |
| 35 | Mobile Registration Request |
| 36 | Mobile Registration Reply |
| 37 | Domain Name Request |
| 38 | Domain Name Reply |
| 39 | SKIP |
| 40 | Photuris |
| 41 | Experimental mobility protocols such as Seamoby |
6.6.2. icode
你可以使用icode关键字匹配特定的ICMP code。ICMP消息的code阐明了该消息。它与icmp类型一起指示您正在处理的问题类型。每个icmp类型的代码都有不同的用途。
icode关键字格式:
icode:min<>max;
icode:[<|>];
示例:本示例查找大于5的ICMP code:
icode:>5;
规则中的icode关键字示例:
alert icmp $HOME_NET any -> $EXTERNAL_NET any (msg:”GPL MISC Time-To-Live Exceeded in Transit”; icode:0; itype:11; classtype:misc-activity; sid:2100449; rev:7;)
下面列出了所有ICMP类型的含义。表格中没有列举的ICMP code,表示只有一种ICMP type是0,它的含义如上表定义,意思是Echo Reply。最新的表格可以在IANA的网站上找到。
| ICMP Code | ICMP Type | Description |
|---|---|---|
| 3 | 0 | Net Unreachable |
| 3 | 1 | Host Unreachable |
| 3 | 2 | Protocol Unreachable |
| 3 | 3 | Port Unreachable |
| 3 | 4 | Fragmentation Needed and Don’t Fragment was Set |
| 3 | 5 | Source Route Failed |
| 3 | 6 | Destination Network Unknown |
| 3 | 7 | Destination Host Unknown |
| 3 | 8 | Source Host Isolated |
| 3 | 9 | Communication with Destination Network is Administratively Prohibited |
| 3 | 10 | Communication with Destination Host is Administratively Prohibited |
| 3 | 11 | Destination Network Unreachable for Type of Service |
| 3 | 12 | Destination Host Unreachable for Type of Service |
| 3 | 13 | Communication Administratively Prohibited |
| 3 | 14 | Host Precedence Violation |
| 3 | 15 | Precedence cutoff in effect |
| 5 | 0 | Redirect Datagram for the Network (or subnet) |
| 5 | 1 | Redirect Datagram for the Host |
| 5 | 2 | Redirect Datagram for the Type of Service and Network |
| 5 | 3 | Redirect Datagram for the Type of Service and Host |
| 9 | 0 | Normal router advertisement |
| 9 | 16 | Doesn’t route common traffic |
| 11 | 0 | Time to Live exceeded in Transit |
| 11 | 1 | Fragment Reassembly Time Exceeded |
| 12 | 0 | Pointer indicates the error |
| 12 | 1 | Missing a Required Option |
| 12 | 2 | Bad Length |
| 40 | 0 | Bad SPI |
| 40 | 1 | Authentication Failed |
| 40 | 2 | Decompression Failed |
| 40 | 3 | Decryption Failed |
| 40 | 4 | Need Authentication |
| 40 | 5 | Need Authorization |
6.6.3. icmp_id
你可以使用icmp_id关键字匹配特定的ICMP id值。每个icmp包在发送时都得到一个id。在接收方收到数据包的那一刻,它将使用相同的id发送回复,以便发送方能够识别它并将其与正确的icmp请求连接起来。
icmp_id关键字的格式:
icmp_id:;
示例:这个示例查找ICMP ID为0:
icmp_id:0;
规则中的icmp_id关键字示例:
alert icmp $EXTERNAL_NET any -> $HOME_NET any (msg:”GPL SCAN Broadscan Smurf Scanner”; dsize:4; icmp_id:0; icmp_seq:0; itype:8; classtype:attempted-recon; sid:2100478; rev:4;)
6.6.4. icmp_seq
你可以使用icmp_seq关键字检查ICMP序列号。ICMP消息都有序列号。这对于检查哪条回复消息属于哪条请求消息非常有用(与id一起)。
icmp_seq关键字的格式:
icmp_seq:;
示例:这个示例查找ICMP序列为0:
icmp_seq:0;
规则中的icmp_seq示例:
alert icmp $EXTERNAL_NET any -> $HOME_NET any (msg:”GPL SCAN Broadscan Smurf Scanner”; dsize:4; icmp_id:0; icmp_seq:0; itype:8; classtype:attempted-recon; sid:2100478; rev:4;)
6.6.5. icmpv6.hdr
粘贴缓冲区,以匹配整个ICMPv6报头。
6.6.6. icmpv6.mtu
匹配ICMPv6 MTU可选值。如果MTU不存在,将不匹配。
关键字格式:
icmpv6.mtu:-;
icmpv6.mtu:[<|>];
icmpv6.mtu:;
示例规则:
alert ip $EXTERNAL_NET any -> $HOME_NET any (icmpv6.mtu:<1280; sid:1234; rev:5;)
6.7. Payload Keywords
Payload关键词检查一个包或流的payload内容。
6.7.1. content
content关键字在签名中非常重要。在引号之间,你可以写上你希望签名匹配的内容。最简单的内容格式是:
content: "............";
可以在签名中使用多个content。
内容在字节上匹配。一个字节有256个不同的值(0-255)。你可以匹配所有字符; 从a到z,大写和小写以及所有特殊符号。但并不是所有的字节都是可打印字符。对于这些字节,可以使用十六进制表示法。许多编程语言使用0x00作为符号,其中0x表示它与二进制值有关,但是我们的规则语言使用|00|作为符号。这种表示法也可用于可打印字符。
例子:
|61| is a
|61 61| is aa
|41| is A
|21| is !
|0D| is carriage return
|0A| is line feed
有些字符不能在内容中使用,因为它们在签名中已经作为重要的标识符了。为了匹配这些字符,应该使用十六进制表示法。这些是:
" |22|
; |3B|
: |3A|
| |7C|
用大写字母书写十六进制表示法是一种惯例。
例如,要在签名的内容中写http://,你应该这样写:content:“http|3A|//”; 如果在签名中使用十六进制表示法,请确保始终将其放在管道符(|)之间。否则,符号将被视为内容的一部分。
举例:
content:"a|0D|bc";
content:"|61 0D 62 63|";
content:"a|0D|b|63|";
可以让签名检查整个有效负载是否与内容匹配,或者让签名检查有效负载的特定部分。这种情况我们稍后再谈。如果没有向签名添加任何特殊内容,它将尝试在有效负载的所有字节中查找匹配项。
drop tcp $HOME_NET any -> $EXTERNAL_NET any (msg:”ET TROJAN Likely Bot Nick in IRC (USA +..)”; flow:established,to_server; flowbits:isset,is_proto_irc; content:”NICK “; pcre:”/NICK .*USA.*[0-9]{3,}/i”; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
默认情况下,模式匹配是区分大小写的。内容必须准确,否则将没有匹配。

图例:

可以使用!除去content的例外情况:
alert http $HOME_NET any -> $EXTERNAL_NET any (msg:"Outdated Firefox on
Windows"; content:"User-Agent|3A| Mozilla/5.0 |28|Windows|3B| ";
content:"Firefox/3."; distance:0; content:!"Firefox/3.6.13";
distance:-10; sid:9000000; rev:1;)
可以看到以上例子中的content:!"Firefox/3.6.13";。它表示匹配到Firefox/3.但不包括Firefox/3.6.13时告警。
!注意:必须在内容中对下列字符进行转义:
;\"
6.7.2. nocase
如果不想区分大写和小写字符,可以使用nocase。关键字nocase是一个content修饰符。
这个关键字的格式是:
nocase;
你必须把它放在你想修改的内容之后,比如:
content: "abc"; nocase;
nocase示例:

对签名中的其他content不产生影响。
6.7.3. depth
depth关键词是一个绝对位置content修饰符。它在content之后出现。depth修饰符的值强制使用数字类型,例如:
depth:12;
depth之后的数字指定了从有效负载开始检查的字节数。
例子:

6.7.4. startsWith
关键字startswith类似于depth。它不接受参数,并且必须紧随content关键字。它修饰content,以精确匹配缓冲区的开始位置。
例子:
content:"GET|20|"; startswith;
startswith是一个简写符号,等同于:
content:"GET|20|"; depth:4; offset:0;
startswith不能与depth,offset,within或者distance在同一pattern中混用。
6.7.5. endswith
endswith关键字类似于isdataat:!1,relative;。它不接受参数,并且必须跟在content关键字之后。它修饰content以精确匹配缓冲区的末尾。
例子:
content:".php"; endswith;
endswith是一个简写符号,等同于:
content:".php"; isdatat:!1,relative;
endswith不能和offset, within 或者 distance 在同一pattern中混用。
6.7.6. offset
offset关键字指定将从哪个字节检查有效负载以查找匹配。例如:offset:3; 检查第四个以及之后的字节。

关键字偏移和深度可以结合使用,经常一起使用。
例如:
content:"def"; offset:3; depth:3;
如果在签名中使用了它,它将检查从第3字节到第6字节的有效负载。

6.7.7. distance
TODO
6.7.8. within
TODO
6.7.9. isdataat
TODO
6.7.10. bsize
TODO
6.7.11. dsize
使用dsize关键字,你可以匹配数据包有效负载的大小。例如,你可以使用关键字来查找有效载荷的异常大小。这可以方便地检测缓冲区溢出。
格式:
dsize:;
规则中dsize的例子:
alert udp $EXTERNAL_NET any -> $HOME_NET 65535 (msg:”GPL DELETED EXPLOIT LANDesk Management Suite Alerting Service buffer overflow”; dsize:>268; reference: bugtraq,23483; reference: cve,2007-1674; classtype: attempted-admin; sid:100000928; rev:1;)
6.7.12. byte_test
TODO
6.7.13. byte_math
TODO
6.7.14. byte_jump
TODO
6.7.15. byte_extract
TODO
6.7.16. rpc
rpc关键字可用于在SUNRPC调用中匹配rpc过程号和rpc版本。
你可以通过使用通配符修改关键字,用*定义,使用这个通配符你可以匹配所有版本号和/或过程号。
远程过程调用(Remote Procedure Call)是允许计算机程序在另一台计算机(或地址空间)上执行过程的应用程序。它用于进程间通信。参见:http://en.wikipedia.org/wiki/Inter-process_communication
格式:
rpc:, [|*], [|*]>;
规则中rpc关键字的例子:
alert udp $EXTERNAL_NET any -> $HOME_NET 111 (msg:”RPC portmap request yppasswdd”; rpc:100009,*,*; reference:bugtraq,2763; classtype:rpc-portmap-decode; sid:1296; rev:4;)
6.7.17. replace
TODO
6.7.18. pcre (Perl Compatible Regular Expressions)
TODO
6.7.18.1. Suricata’s modifiers
TODO
6.8. Transformations(转换)
TODO
6.9. Prefiltering Keywords(前置筛选关键词)
TODO
6.10. Flow Keywords
6.10.1. flowbits
Flowbits由两部分组成。第一部分描述了它将要执行的动作,第二部分是flowbit的名称。
有多个包属于一个流。Suricata将这些流保存在内存中。有关更多信息,请参见Flow Settings。例如,当两个不同的包匹配时,Flowbits可以确保生成警报。只有当两个数据包匹配时,才会生成警报。因此,当第二个数据包匹配时,Suricata必须知道第一个数据包是否也匹配。Flowbits在包匹配时标记流,因此Suricata“知道”在第二个包匹配时也应该生成警报。
flowbits有不同的action。它们是:
- flowbits: set, name
将设置流中的条件/“name”(如果存在)。 - flowbits: isset, name
可以在规则中使用,以确保在规则匹配并在流中设置条件时生成警报。 - flowbits: toggle, name
反转当前设置。例如,如果一个条件被设置,它将被取消设置,反之亦然。 - flowbits: unset, name
可用于在流中取消设置条件。 - flowbits: isnotset, name
可以在规则中使用,以确保在匹配时生成警报,并且在流中没有设置条件。 - flowbits: noalert
此规则不会生成任何警报。
例子:
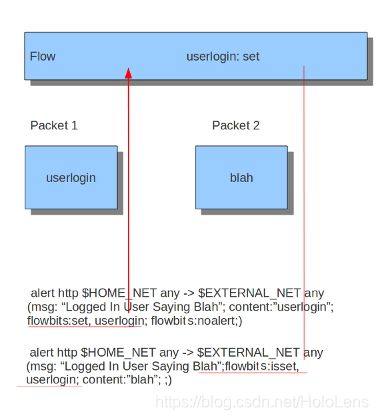
当你看第一个规则时,你会注意到当它匹配时,如果它不是以“flowbits: noalert”结尾的话,就会生成一个警告。这个规则的目的是检查’ userlogin '上的匹配,并在流中标记它,因此不需要生成警报。如果没有第一条规则,第二条规则就不起作用。如果第一个规则匹配,则流位将该特定条件设置为出现在流中。现在有了第二个规则,可以检查前一个数据包是否满足第一个条件,如果此时第二个规则匹配,将生成一个警告。
可以在规则中多次使用flowbits,并组合不同的函数。
6.10.2. flow
flow关键词可以用来匹配flow的方向,例如:to/from client or to/from server。它还可以匹配是否建立了流。flow关键字还可以用来表示签名只能在流(only_stream)或数据包(no_stream)上匹配。
所以,通过flow关键字你可以匹配:
- to_client
匹配从服务器到客户端的数据包。 - to_server
匹配从客户端到服务器的数据包。 - from_client
匹配从客户机到服务器的数据包(与to_server相同)。 - from_server
匹配从服务器到客户机的数据包(与to_client相同)。 - established
匹配已建立的连接。 - not_established
匹配不属于已建立连接的包。 - stateless
匹配属于或不属于已建立连接的数据包。 - only_stream
匹配已由流引擎重新组装的数据包。 - no_stream
匹配未被流引擎重新组装的数据包。将不匹配已重新组装的包。 - only_frag
匹配从片段中重新组装的包。 - no_frag
匹配没有从片段中重新组装的包。
可以组合多个流选项,例如:
flow:to_client, established
flow:to_server, established, only_stream
flow:to_server, not_established, no_frag
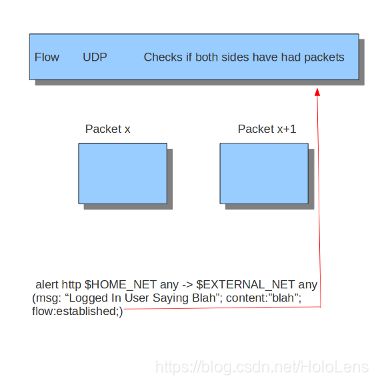
连接是否建立的评定依赖于具体协议:
- 对于TCP,在三次握手之后将建立连接。

- 对于其他协议(例如UDP),在看到来自连接两端的流量后,将认为连接已经建立。
6.10.3. flowint
Flowint允许使用变量进行存储和数学操作。它的操作方式很像flowbits,但是增加了数学能力,而且可以存储和操作整数,而不仅仅是标记集。我们可以将其用于许多非常有用的事情,比如计数出现次数、添加或减去出现次数,或者在一个流中针对多个因素进行阈值设定。这将很快扩展到全局上下文,因此用户可以在流之间执行这些操作。
语法如下:
flowint: name, modifier[, value];
定义一个变量(不是必需的),或者检查是否设置了它。
flowint: name, < +,-,=,>,<,>=,<=,==, != >, value;
flowint: name, (isset|isnotset);
比较或更改一个变量。可用操作包括:添加,减去,比较大于或小于,大于或等于,和小于或等于。要比较的项可以是整数或另一个变量。
例如,如果您想计算用户名在特定流中出现的次数,并在超过5时发出警报。
alert tcp any any -> any any (msg:"Counting Usernames"; content:"jonkman"; \
flowint: usernamecount, +, 1; noalert;)
这将计算每次出现的次数,并增加变量 usernamecount,而不会为每次出现生成警告。
现在,假设我们想在流中出现超过5次点击时生成一个警报。
alert tcp any any -> any any (msg:"More than Five Usernames!"; content:"jonkman"; \
flowint: usernamecount, +, 1; flowint:usernamecount, >, 5;)
只有当usernamecount超过5时,我们才会得到警告。
现在,我们想要得到如上警告,但考虑到在统计的期间如果用户名退出的情况更多,就不会出现。假设这个特定的协议使用“jonkman logout”字样指示登出,让我们试试:
alert tcp any any -> any any (msg:"Username Logged out"; content:"logout jonkman"; \
flowint: usernamecount, -, 1; flowint:usernamecount, >, 5;)
此时,只有当用户名的活动登录超过5时,我们才会收到警告。
这是一个相当简单的示例,但我相信它展示了这样一个简单函数对于编写规则的强大功能。我看到过很多类似于登录跟踪、IRC状态机、恶意软件跟踪和暴力登录检测的应用程序。
假设我们正在跟踪一个通常允许每个连接5次登录失败的协议,但是我们有一个漏洞,攻击者可以在尝试5次之后继续登录,我们需要知道这一点。
alert tcp any any -> any any (msg:"Start a login count"; content:"login failed"; \
flowint:loginfail, notset; flowint:loginfail, =, 1; noalert;)
以上,我们检测如果变量尚未设置,就将其设置为1。这是我们的第一次命中。
alert tcp any any -> any any (msg:"Counting Logins"; content:"login failed"; \
flowint:loginfail, isset; flowint:loginfail, +, 1; noalert;)
如果已经设置好了,我们现在就对计数器进行递增。
alert tcp any any -> any any (msg:"More than Five login fails in a Stream"; \
content:"login failed"; flowint:loginfail, isset; flowint:loginfail, >, 5;)
现在,如果在同一流中出现5次登录失败,我们将生成一个警报。
但是,如果有两次成功的登录和一次失败的登录,我们还需要警告。
alert tcp any any -> any any (msg:"Counting Good Logins"; \
content:"login successful"; flowint:loginsuccess, +, 1; noalert;)
这里我们计算了良好的登录次数,现在我们将计算与失败相关的良好登录次数:
alert tcp any any -> any any (msg:"Login fail after two successes"; \
content:"login failed"; flowint:loginsuccess, isset; \
flowint:loginsuccess, =, 2;)
以下是一些常见的例子:
alert tcp any any -> any any (msg:"Setting a flowint counter"; content:"GET"; \
flowint:myvar, notset; flowint:maxvar,notset; \
flowint:myvar,=,1; flowint: maxvar,=,6;)
alert tcp any any -> any any (msg:"Adding to flowint counter"; \
content:"Unauthorized"; flowint:myvar,isset; flowint: myvar,+,2;)
alert tcp any any -> any any (msg:"when flowint counter is 3 create new counter"; \
content:"Unauthorized"; flowint:myvar, isset; flowint:myvar,==,3; \
flowint:cntpackets,notset; flowint:cntpackets, =, 0;)
alert tcp any any -> any any (msg:"count the rest without generating alerts"; \
flowint:cntpackets,isset; flowint:cntpackets, +, 1; noalert;)
alert tcp any any -> any any (msg:"fire this when it reach 6"; \
flowint: cntpackets, isset; \
flowint: maxvar,isset; flowint: cntpackets, ==, maxvar;)
6.10.4. stream_size
流大小选项根据按序列号注册的字节量匹配流量。这个关键字有几个修饰词:
> greater than
< less than
= equal
!= not equal
>= greater than or equal
<= less than or equal
格式:
stream_size:, , ;
规则中的流大小关键字示例:
alert tcp any any -> any any (stream_size:both, >, 5000; sid:1;)
6.11. Bypass 关键词
Suricata有一个bypass关键字,可以在签名中使用,以从进一步的计算中排除流量。
bypass关键字在大流量的环境下(如Netflix, Spotify, Youtube)很有用。
bypass关键字被认为是一个赛后关键字。
6.11.1. bypass
绕过匹配http流量的流。
例子:
alert http any any -> any any (content:"suricata-ids.org"; \
http_host; bypass; sid:10001; rev:1;)
6.12. HTTP 关键词
TODO
6.13. 文件关键词
Suricata提供了几个规则关键字来匹配不同的文件属性。它们依赖于正确配置的File Extraction。
6.13.1. filename
匹配文件名。
语法:
filename:;
例子:
filename:"secret";
6.13.2. fileext
匹配文件名的扩展名。
语法:
fileext:;
例子:
fileext:"jpg";
6.13.3. filemagic
匹配libmagic返回的关于文件的信息。
语法:
filemagic:;
例子:
filemagic:"executable for MS Windows";
注意:由于不同安装的libmagic版本不同,返回的信息也可能略有变化。参见#437。
6.13.4. filestore
如果签名匹配,则将文件存储到磁盘。
语法:
filestore:,;
direction(方向)可以是:
- request/to_server: store a file in the request / to_server direction
- response/to_client: store a file in the response / to_client direction
- both: store both directions
scope(范围)可以是:
- file: only store the matching file (for filename,fileext,filemagic matches)
- tx: store all files from the matching HTTP transaction
- ssn/flow: store all files from the TCP session/flow.
如果省略方向和范围,方向将与规则相同,范围将是每个文件。
6.13.5. filemd5
使用MD5校验和列表里匹配文件MD5。
语法:
filemd5:[!]filename;
这个filename被扩展用以包含特定的规则文件夹,它的默认值是:/etc/suricata/rules/filename。在filename前加感叹号表示取反匹配。这可以用做白名单。
例子:
filemd5:md5-blacklist;
filemd5:!md5-whitelist;
规则文件格式:
这个MD5规则文件的格式简单。它是文本类型,在每行的顶头使用md5哈希表示一条规则,如果这一行中还有其他的附加信息,会被忽略。
规则文件内容使用md5sum工具的输出结果是可以的:
2f8d0355f0032c3e6311c6408d7c2dc2 util-path.c
b9cf5cf347a70e02fde975fc4e117760 util-pidfile.c
02aaa6c3f4dbae65f5889eeb8f2bbb8d util-pool.c
dd5fc1ee7f2f96b5f12d1a854007a818 util-print.c
只有MD5也是可以的:
2f8d0355f0032c3e6311c6408d7c2dc2
b9cf5cf347a70e02fde975fc4e117760
02aaa6c3f4dbae65f5889eeb8f2bbb8d
dd5fc1ee7f2f96b5f12d1a854007a818
内存要求:
每个MD5使用16字节内存。2000万个MD5大约需要使用310MIB内存。
参见:https://blog.inliniac.net/2012/06/09/suricata-md5-blacklisting/
6.13.6. filesha1
使用SHA1校验和列表里匹配文件SHA1。
语法:
filesha1:[!]filename;
这个filename被扩展用以包含特定的规则文件夹,它的默认值是:/etc/suricata/rules/filename。在filename前加感叹号表示取反匹配。这可以用做白名单。
例子:
filesha1:sha1-blacklist;
filesha1:!sha1-whitelist;
文件格式:
跟上述md5文件格式相同
6.13.7. filesha256
使用SHA256校验和列表里匹配文件SHA256 。
语法:
filesha256:[!]filename;
这个filename被扩展用以包含特定的规则文件夹,它的默认值是:/etc/suricata/rules/filename。在filename前加感叹号表示取反匹配。这可以用做白名单。
例子:
filesha256:sha256-blacklist;
filesha256:!sha256-whitelist;
文件格式:
跟上述md5文件格式相同
6.13.8. filesize
匹配正在传输的文件的大小。
语法:
filesize:;
可能的单位是KB, MB和GB。如果没有任何单位,默认是字节。
例子:
filesize:100; # exactly 100 bytes
filesize:100<>200; # greater than 100 and smaller than 200
filesize:>100MB; # greater than 100 megabytes
filesize:<100MB; # smaller than 100 megabytes
对于那些由于 丢包或者达到了stream.reassembly.depth规定的上限 而没有被完全跟踪的文件,此时只会使用大于进行检查。这是因为Suricata可以知道一个文件大于一个值(它已经看到了其中的一些),但它不能知道最终大小是否在一个范围内,一个确切的值或小于一个值。
6.14. DNS 关键词
未完待续。。。