KDE之实操代码练习
随机数据KDE
使用 Scipy 库中的 gaussian_kde 函数对随机生成的正态分布数据进行了核密度估计,并使用 Matplotlib 进行了可视化,完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gaussian_kde
# Scipy 库中的 gaussian_kde 函数对随机生成的正态分布数据进行了核密度估计
# 并使用 Matplotlib 进行了可视化。
# 生成随机数据
data = np.random.normal(0, 1, 1000)
# 进行 KDE
# 选择带宽 (bw_method) 时,可以使用如 'silverman' 或 'scott' 等启发式方法
# 也可以尝试不同的固定带宽值以查看其对 KDE 影响。
kde = gaussian_kde(data, bw_method='silverman')
x = np.linspace(min(data), max(data), 1000)
density = kde(x)
# 绘制 KDE 结果
plt.plot(x, density)
plt.title('Kernel Density Estimation')
plt.xlabel('Value')
plt.ylabel('Density')
plt.show()
简单理解
- 一般是对一维数据进行KDE分析的,bw_method表示启发式方法,除了有'silverman'之外,也有‘scott’,也可以尝试不同的固定带宽值以查看其对 KDE 影响。不同的启发式方法代表不同的带宽计算方法,而不同的带宽能够使得密度曲线发生一点点改变,展现不同的细节。
- x则表示一维数组,这个一维数组的范围与data的范围保持一致,我们通过以该数组作为密度曲线的横轴。
结果分析
通过上面代码,我们可以得到结果:
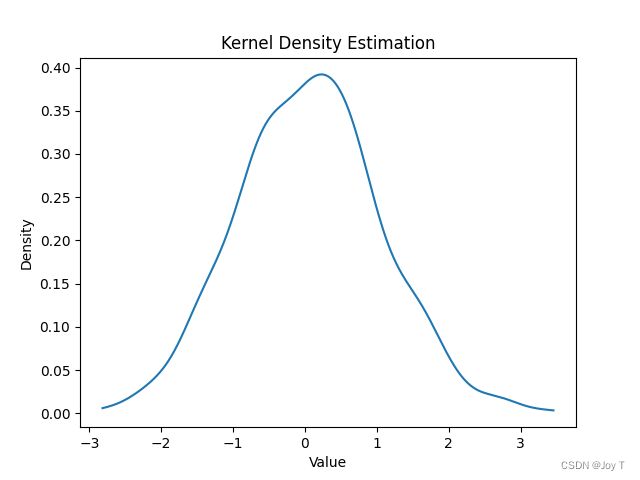
这个KDE画出的概率密度函数有什么用?它是不是就是直方图的一个更好的替代品?
核密度估计(KDE)生成的概率密度函数具有多种用途,并且确实可以视为直方图的一种改进或替代品。以下是 KDE 的主要用途和它与直方图的比较:
KDE 的用途
-
展现数据分布:KDE 提供了一种平滑的方式来查看数据的分布,这在探索性数据分析中特别有用。它可以揭示数据的分布特性,比如是否对称、是否有多个峰值等。
-
与理论分布比较:KDE 可用于判断数据分布是否符合某些理论分布,例如正态分布。通过比较 KDE 曲线和理论分布曲线,可以直观地判断数据是否近似于特定的分布。
-
数据清洗和预处理:KDE 可以用于识别数据中的异常值和噪声。异常的峰值或不寻常的分布形状可能表明数据质量问题或数据录入错误。
-
非参数测试:在统计推断中,KDE 作为一种非参数方法,可以用来估计概率密度函数,这在没有关于数据分布的先验知识时特别有用。
KDE 与直方图的比较
-
平滑性:KDE 提供了比直方图更平滑的分布估计。直方图的形状很大程度上取决于箱体(bin)的选择,而 KDE 通过平滑核函数减少了这种依赖。
-
连续性:直方图是离散的,而 KDE 提供了连续的密度估计。这使 KDE 在可视化和解释上更为灵活和准确。
-
参数依赖:尽管 KDE 减少了对箱体大小的依赖,但它引入了对带宽选择的依赖。不恰当的带宽选择可能导致过度平滑或过度粗糙的估计。
结论
KDE 是一种强大的工具,用于可视化和分析数据分布。它确实可以视为直方图的更加精细和灵活的替代品。然而,理解和适当选择 KDE 的参数(如带宽)是关键。尽管 KDE 提供了有关数据分布的直观理解,但可能还需要更多统计测试和分析来支持任何具体的结论。
尽管 KDE 和直方图都用于展示数据的分布,但 KDE 在揭示分布的平滑特征和细节方面更具优势。直方图更直观地展示了频率分布,而 KDE 提供了一种更为精细的数据分布视图。选择哪种方法取决于数据的特性和分析的具体目标。在实际应用中,它们经常被同时使用,以提供更全面的数据分布视角。
读取.csv文件
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gaussian_kde
import pandas as pd
# Scipy 库中的 gaussian_kde 函数对随机生成的正态分布数据进行了核密度估计
# 并使用 Matplotlib 进行了可视化。
# 读取 CSV 文件
file_path = 'C:\\Users\\26498\\Desktop\\污染物浓度数据.csv' # 替换为您的文件路径
data = pd.read_csv(file_path)
# 显示数据的前几行,以了解其结构
print(data.head(2))
# 选择进行 KDE 的列
column_of_interest = 'AQI' # 替换为您要分析的列名
selected_data = data[column_of_interest].dropna() # 删除 NaN 值
# 进行 KDE
kde = gaussian_kde(selected_data, bw_method='silverman')
x = np.linspace(min(selected_data), max(selected_data), 1000)
density = kde(x)
# 绘制 KDE 结果
plt.plot(x, density)
plt.title('Kernel Density Estimation for ' + column_of_interest)
plt.xlabel(column_of_interest)
plt.ylabel('Density')
plt.show()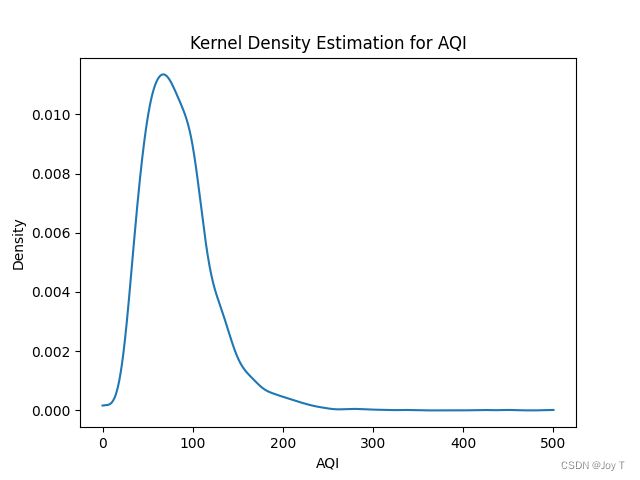
核密度估计(KDE)展示的密度是一个抽象值,不直接代表具体的数量或频率。它的用途在于提供数据分布的一个平滑、连续的视图。让我们更详细地探讨问题:
KDE 中的密度值
-
抽象密度:KDE 图展示的是在每个点上的估计密度值,这个密度是相对于整个数据集的。它不直接对应于数据中的实际数量,而是展示了数据在该点附近的集中程度。
-
用途:KDE 的主要用途是可视化和理解数据的分布特征,比如数据是集中还是分散、是否有峰值、数据分布是否对称等。这对于初步数据分析和假设的生成是非常有帮助的。
代码中的 x 和 data 的关系
-
data:这是正在进行 KDE 的实际数据集。它可以是任何连续的数据集,如一组测量值或观察值。 -
x:这是一个定义在数据分布范围内的数值序列,用于计算和绘制 KDE 曲线。可以将其视为用于评估 KDE 函数的点的集合。 -
关系:
x的范围应涵盖data的整个范围,以便在数据的整个分布区域内估计密度。例如,如果data是一组介于 -3 和 3 之间的数值,那么x通常会在这个范围或稍微更广的范围内选择,以确保覆盖所有重要的数据区域。
在例子中:
-
x = np.linspace(min(selected_data), max(selected_data), 1000)创建了一个在selected_data的最小值和最大值之间的均匀间隔的数值序列,这保证了 KDE 曲线覆盖了selected_data的全部范围。
x 的值用于计算在这些点上的密度估计,并最终用于绘制 KDE 曲线。这个曲线提供了数据分布的平滑视图,有助于理解数据的概貌。
KDE 的工作原理
-
数据点:首先有一组一维的数据点,这些点代表希望分析其分布的实际观测或测量值。
-
评估点:然后创建一个均匀分布的点集(在例子中是1000个点),这些点用于评估和可视化密度。这些点通常覆盖了数据的整个范围,以确保对整个分布的良好估计。
-
核函数:对于每一个评估点,KDE 会计算其上的密度估计值。这是通过将每个实际数据点对评估点的贡献加总来完成的。这个贡献是根据核函数计算的,核函数根据实际数据点与评估点之间的距离来确定权重。
-
加权和:每个实际数据点对评估点的贡献(即核函数的值)被加总,然后通常需要除以总的数据点数和核函数的带宽,从而得到每个评估点上的密度估计。
-
可视化:最后,这些密度估计值被用来绘制一条平滑的曲线,显示数据在整个范围内的分布情况。
核函数
在 KDE 中,核函数是一种数学函数,用于估计数据点周围的概率密度。核函数的关键特性是它在某个中心点附近具有高值,并随着与中心点距离的增加而减少。高斯(或正态)核是最常用的核函数之一,其形状类似于正态分布曲线,但也可以使用其他类型的核,如均匀核、三角核等。
核函数的作用
-
每个数据点上的核:在 KDE 中,每个实际数据点都会放置一个核函数。
-
核函数的中心:每个核函数的中心放置在对应的数据点上。这意味着每个数据点都有一个核函数以它为中心。
-
密度估计:对于想要估计密度的每个位置(比如创建的
x数组中的点),KDE 会计算所有核函数在该位置的累加值。换句话说,x数组中的每个点都会接收来自所有数据点核函数的“贡献”。
x 数组中的点
x 数组中的点不是核函数本身,而是用来评估和可视化密度的位置。可以将这些点视为观察和测量核函数累加效果的位置。
核函数如何收集信息
对于 x 数组中的每个评估点,KDE 会计算所有核函数在该点的值,并将它们相加。这个累加过程实际上是在收集所有数据点对该评估点的“影响”。
不同点对应的核函数
每个数据点对应的核函数是相同类型的(比如都是高斯核),但核函数的中心位置根据数据点的位置而变化。这意味着,尽管所有核函数的形状相同,但它们分别以不同的数据点为中心。
为什么使用核函数
核函数使我们能够以一种平滑且连续的方式估计数据的概率密度。直接使用数据点(比如直方图)可能无法有效地揭示数据的细微结构,特别是在数据量较少或分布不均匀时。核函数通过在每个数据点周围提供平滑的权重分布,帮助我们更好地理解数据的整体分布特征。
过程类比
也就是说x上的评估点相当于信号收集站,而每个实际数据点在加上核函数之后就可以发送自身数据密度这种信号,x的最终值就是平均数据密度根据核函数带宽进行变化后的值。
信号收集站(评估点)
- 评估点:
x数组中的点可以被看作是分布在整个数据范围内的信号接收站。这些点用于评估和绘制整个数据集的概率密度分布。
发送信号的数据点
- 数据点和核函数:每个实际数据点都有一个核函数与之关联,这个核函数确定了该数据点周围的密度贡献。核函数的形状(如高斯核)决定了这个贡献如何随距离变化。
信号的处理和累加
- 密度估计:在每个评估点上,所有数据点发送的密度信号被累加起来。具体来说,就是计算每个数据点的核函数在该评估点的值,并将它们相加。
最终的密度估计
- 平均化和归一化:将所有数据点在每个评估点的核函数值相加之后,还需要进行平均化(即除以数据点总数),并考虑核函数的带宽进行适当的缩放。这样做确保最终的概率密度函数在整个定义域上的积分等于 1,符合概率密度函数的标准。
归一化
加权和:每个实际数据点对评估点的贡献(即核函数的值)被加总,然后通常需要除以总的数据点数和核函数的带宽,从而得到每个评估点上的密度估计。这个除法就涉及到了归一化处理。
核密度估计的归一化过程
-
核函数的积分:核密度估计中使用的核函数,如高斯核,通常本身就是归一化的。这意味着每个核函数在其整个定义域上的积分等于 1。
-
除以数据点数:在 KDE 中,每个数据点位置放置一个核函数,并将这些核函数的贡献相加。由于每个核函数的积分都是 1,若有 N 个数据点,直接相加这些核函数的贡献会导致总积分等于 N。因此,需要将和除以数据点的总数 N,以确保最终的密度估计在定义域上的总积分为 1。
也就是说,无论离的有多近还是多远,一个实际数据点上只有一个核函数,并且这个核函数发出的信号都能被x上的信号接收点接收,虽然信号在不同的位置上有多有少,但是一个核函数的整个信号量在x数组中是可以完全被接收的(因为x数组包含了data的整个范围,所以能够完全接收到每个实际数据点发送的数据密度),每个核函数的总贡献(面积)本身就等于 1,所以面积1被接收。当所有核函数的贡献在评估点上累加时,得到的总面积实际上是数据点数 N 的倍数。接下来,通过除以 N 来平均这些贡献,确保最终的密度估计在整个定义域上的积分等于 1。
进一步解释:
核函数的信号接收
-
单个核函数:每个实际数据点都有一个核函数与之关联,并且这个核函数在
x数组的每个评估点上都发出了信号。 -
信号强度:核函数在距离其中心(即数据点位置)越远的地方发出的信号越弱。这意味着距离核函数中心较近的评估点会接收到更强的信号。
-
完全接收:每个核函数在
x数组的所有评估点上的信号总量是可以被完全接收的。这是因为核函数通常设计为在整个定义域上积分为 1,所以每个核函数对整个密度估计的贡献是“完整”的。
总面积为 1 的概念
-
多个核函数的累加:当所有数据点的核函数在
x数组的每个评估点上的信号被累加时,如果不进行任何调整,总面积将是数据点数 N 的倍数。 -
除以数据点数 N:为了保证 KDE 生成的密度估计符合概率密度函数的定义(即在整个定义域上的积分等于 1),我们需要将累加的总信号量除以数据点数 N。、
-
无论带宽如何,每个核函数的总贡献(面积)保持不变。
归一化的重要性
- 归一化确保了 KDE 提供的是概率密度估计。在概率论中,一个概率密度函数(PDF)的特征是其在整个定义域上的积分等于 1,这表明它描述了一个完整的概率分布。
带宽
为什么要除以带宽呢?带宽是什么呢?
核函数与带宽示例


带宽的作用
在核密度估计(KDE)中,带宽的主要作用是控制估计密度曲线的平滑程度,而保持其基本形状大体相似。让我们详细解释一下:
带宽对平滑程度的影响
-
小带宽:当带宽较小时,核函数比较狭窄,这导致每个数据点在其附近产生较尖锐的峰值。结果是一个比较“崎岖”的密度曲线,它更多地反映了数据中的局部特征和细微差异。
-
大带宽:相反,当带宽较大时,核函数更宽泛,每个数据点对更广区域的密度估计产生影响。这会生成一个更加平滑的密度曲线,它更多地展示了数据的整体分布特征,但可能会掩盖一些局部细节。
维持核函数的基本形状(答案!)
- 调整带宽实质上是在改变核函数的宽度和高度,但核函数的基本形状(例如,对于高斯核,是正态分布的形状)保持不变。这意味着无论带宽如何,每个核函数都保持着同样的概率分布特征。
结果
- 带宽的调整影响着密度估计曲线的平滑程度,但不会改变其反映数据基本分布特征的能力。因此,不同带宽下的 KDE 曲线可以被视为数据分布的不同“视角”,其中细节和整体特征的展示取决于所选择的平滑级别。
不同核函数
选择不同的核函数确实会对核密度估计(KDE)生成的密度曲线产生影响,但通常这种影响主要体现在曲线的平滑程度和尖锐特征上,而不会显著改变其基本形状。不同核函数的主要区别在于它们的形状和如何随距离变化。
常见的核函数
-
高斯核:最常用的核函数,其形状类似于正态分布。它在每个点处都是平滑的,因此产生的密度估计也是平滑的。
-
Epanechnikov核:这是一个凸二次核,通常比高斯核计算效率更高。它在核的边缘处不如高斯核平滑。
-
均匀核:在其宽度范围内具有恒定的值,然后突然下降到零。它产生的密度估计比高斯核更“棱角分明”。
-
三角核:类似于均匀核,但在边缘处更平滑。
核函数对密度曲线的影响
-
平滑度:不同的核函数影响密度曲线的平滑程度。例如,高斯核通常产生非常平滑的曲线,而均匀核或三角核可能产生较为“锯齿状”的曲线。
-
局部特征:某些核函数(如高斯核)对数据中的局部特征更为敏感,而其他核函数(如均匀核)可能在展现局部细节时不那么精确。
-
尖锐特征:不同的核函数对数据中尖锐特征的表现也不同。某些核函数可能更好地突出显示数据中的尖峰,而其他核则可能使这些特征更平滑。
核函数的带宽对密度曲线的影响
-
平滑程度:带宽决定了核函数对数据点的“敏感程度”。较小的带宽会产生更尖锐、更细节的密度估计,而较大的带宽则会产生更平滑的估计。
-
可比性:当使用不同的核函数对同一数据集进行密度估计时,选择适当的带宽可以帮助使这些估计结果更具可比性。例如,较尖锐的核可能需要较大的带宽来与较平滑的核产生的估计相匹配。
总结
- 不同的核函数在密度估计中的选择可以根据数据的特性和分析的目标来决定。虽然不同的核函数会影响密度估计曲线的平滑程度和局部特征的展示,但它们通常不会显著改变曲线的基本形状或整体分布的识别。在实践中,高斯核由于其平滑特性和数学方便性,往往是默认的选择。
- 在比较不同核函数的密度估计时,调整带宽是一个重要的步骤。这不仅影响单个核函数的估计结果,也影响在不同核函数间进行比较时的一致性和公平性。
不同带宽代码示例
scipy.stats 模块中似乎没有直接提供 uniform 和 epanechnikov 核函数的实现。目前 scipy.stats.gaussian_kde 默认只提供高斯(或正态)核的实现。故展示不同带宽对高斯核密度估计的影响。我们将比较 silverman 和 scott 带宽规则下的高斯核密度估计结果:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gaussian_kde
import pandas as pd
# 读取 CSV 文件
file_path = 'C:\\Users\\26498\\Desktop\\污染物浓度数据.csv' # 替换为您的文件路径
data = pd.read_csv(file_path)
# 显示数据的前几行,以了解其结构
print(data.head())
# 选择进行 KDE 的列
column_of_interest = 'AQI' # 替换为您要分析的列名
selected_data = data[column_of_interest].dropna() # 删除 NaN 值
# 设定评估点
x = np.linspace(min(selected_data), max(selected_data), 1000)
# 使用不同的带宽规则进行高斯核密度估计
kde_silverman = gaussian_kde(selected_data, bw_method='silverman')
density_silverman = kde_silverman(x)
kde_scott = gaussian_kde(selected_data, bw_method='scott')
density_scott = kde_scott(x)
# 绘制结果
plt.figure(figsize=(12, 8))
plt.plot(x, density_silverman, label='Gaussian Kernel (Silverman BW)')
plt.plot(x, density_scott, label='Gaussian Kernel (Scott BW)')
plt.title('Kernel Density Estimation for ' + column_of_interest)
plt.xlabel(column_of_interest)
plt.ylabel('Density')
plt.legend()
plt.show()
这两种带宽选择方法在理论上根据数据的分布和样本大小来自动选择带宽,但它们的具体计算方法有所不同,从而可能产生略有不同的密度估计曲线(仔细看能看到蓝色不重合的线):
