C语言-指针讲解(3)
文章目录
- 1.字符指针变量
-
- 1.1 字符指针变量类型是什么
- 1.2字符指针变量的两种使用方法:
- 1.3字符指针笔试题讲解
- 1.3.1 代码解剖
- 2.数组指针变量
-
- 2.1 什么是数组指针
- 2.2 数组指针变量是什么?
-
- 2.2.3 数组指针变量的举例
- 2.3数组指针和指针数组的区别是什么?
-
- 2.3.1 数组指针和指针数组区别举例
- 2.4 数组指针变量是怎么初始化
- 3.二维数组传参的本质
- 4.函数指针变量
-
- 4.1 函数指针变量的创建
-
- 4.1.1什么是函数指针变量呢?
- 4.2 函数指针变量的使用
- 4.3 两段有趣的代码
- 4.4. typedef关键字
-
- 4.4.1 typedef关键字是什么?
- 4.4.2 typedef 关键字用法举例
-
- 4.4.2.1 举例1
- 4.4.2.1 举例2
- 4.4.2.1 举例3
- 4.4.2.1 举例4
- 5.函数指针数组
-
- 5.1 什么是函数指针数组?
-
- 5.2 如何定义函数指针数组?
- 5.3 函数指针数组举例
- 6.转移表
-
- 6.1.1用函数指针数组作为转移表实现计算器的代码逻辑
- 6.1.2用函数指针作为转移表实现计算器的代码逻辑
在上一篇博客中:
C语言-指针讲解(2)
我们更为深层地给大家介绍了指针的其他基础用法
让下面我们来回顾一下讲了什么吧:
1.野指针指向的位置是不可知的。我们只有做到:
- 对指针初始化
- 小心数组越界
- 当指针变量不再使用时,应及时置NULL,指针使用之前检查有效性。
才能在写代码避免出现野指针的情况。
2.assert.h头文件定义了宏assert(),用于在运行中确保程序符合指定程序,如果不符合,就报错运行运行。这个宏常常被称为“断言”。
3.学习指针的用处以及指针传址调用的用法
4.除了sizeof(数组名)和&数组名,其他情况下数组名都是数组首元素的地址。
5.二级指针是存放一级指针的指针,二级指针是存放一级指针的地址。二级指针的相关运算。
6.存放指针的则称作指针数组,指针数组每个元素都是用来存放地址的。
7.指针数组模拟二维数组的实例
那么这次博主会给大家介绍指针进阶的地方,具体内容看下图所示:


1.字符指针变量
1.1 字符指针变量类型是什么
我们知道,字符变量类型是char。
那同理,字符指针变量类型是char*。
1.2字符指针变量的两种使用方法:
int main()
{
char ch = 'w';
char *pc = &ch;//用指针变量pc来接收ch变量的地址
*pc = 'w';//通过对指针变量pc进行解引用操作访问到ch变量的值
return 0;
}
还有一种使用方法:
int main()
{
const char* pstr = "hello bit.";//这里是把一个字符串放到pstr指针变量里了吗?
printf("%s\n", pstr);
return 0;
}
这里需要注意的是:
这行代码:const char* pstr = "hello bit."很容易让同学以为是把字符串hello bit.放到字符指针pstr里了,但其实这是不对的。它本质上是把字符串hello bit.首字符的地址放到了pstr中。
如下图所示:
通过此图,我们更能直观地看到上面代码的意思实际上是把一个字符串的首字符h的地址存放到指针变量pstr中。

1.3字符指针笔试题讲解
下面来自一道《剑指offer》关于字符串相关的笔试题,我们来学习一下。
#include 大家不妨看看这个代码运行结果是什么,输出的是哪两条语句?
我们不妨看一下vs的运行结果:
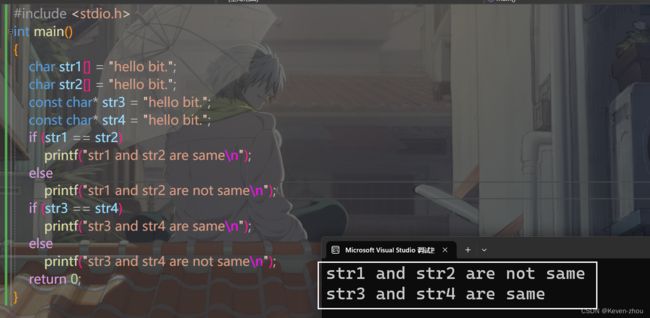
看到这里,也许有同学会有疑问为什么输出的是那两句。接下来我们给大家仔细分析一下。
1.3.1 代码解剖
如下图所示:
- 之前我们讲过,除sizeof(数组名)和&数组名,其他情况下数组名都是数组首元素的地址。 因此这行代码:if(str1==str2) 本质上就是两个地址间进行比较。虽然这里的str1和str2数组存的内容是相同的,但本质上它们都是用相同的常量字符串去初始化不同的数组,这样就会开辟出不同的内存块。所以str1和str2不同。
- 而这里的str3和str4指向的是同一个常量字符串。通常C/C++会把常量字符串存储到单独的一个内存区域, 所以当几个指针指向同一个字符串的时候,它们实际上会指向同一块内存。所以str3和str4是相同的。

2.数组指针变量
2.1 什么是数组指针
数组指针,顾名思义它就是一种指针,里面存放的是数组的地址。
2.2 数组指针变量是什么?
根据前面的指针介绍,我们知道:
1.整形指针变量:int * ptr,存放的是整型变量的地址,能够指向整形数据的指针。
2.浮点型指针变量:float * pf;存放浮点型变量的地址,能够指向浮点型数据的指针。
那数组指针变量:就是存放的是数组的地址,能够指向数组的指针变量。
2.2.3 数组指针变量的举例
我们来看一下,下面哪个代码是数组指针变量?
int *p1[10];
int (*p2)[10];
大家可以先思考一下:
这里的数组指针变量是这个:
int (*p)[10];
解释如下:
p先和*结合,说明p是一个指针变量,然后它指向的是一个大小为10个整型的数组。所以p是一个指针,指向一个数组指针,叫数组指针。
可能有同学会有疑问,为什么p要和*先结合呢?
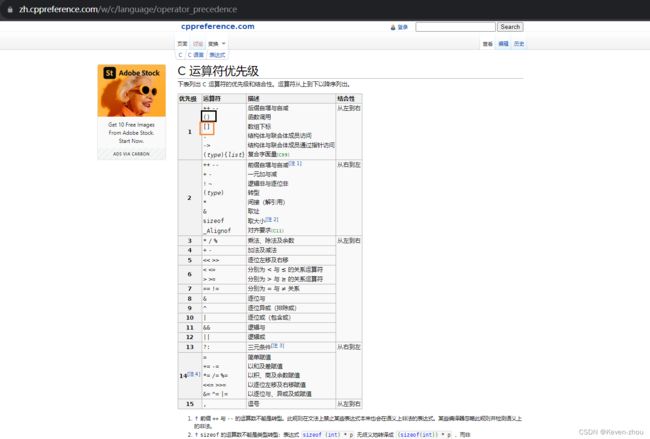
我们来看下图所示:
从图中:我们可以清晰看到,[]的优先级是比* 要高的。所以我们必须加上()来保证p先和*结合。
2.3数组指针和指针数组的区别是什么?
这两个概念在词语虽然很相近,但事实是两个不同的事实。
2.3.1 数组指针和指针数组区别举例
代码如下:
int *a[5]和int (*a)[5];
分析:**我们从上面代码,和刚刚给出操作符优先级的图可以得知,它们之前相差一个括号,根据优先级的关系(()>[]>*),如果不加括号,a会先与[]结合,加了括号,a则会和 *结合,由此可见,加括号为的是改变运算的结合顺序。
- int *a[5]没有括号,a会先与[]结合,所以它是一个数组。
- int (*a)[5]加了括号,a会与 *结合,所以它是一个指针。
根据上面分析我们得出以下结论:
- int * [5]是指针数组,它本质上是一个数组,数组里面存放的是指针,指针类型是int*,指向的是一个整形数组。
int( * a)[5]是数组指针,它本质是一个指针,里面存放的是数组的地址,指向的是数组的类型是int[5]。
2.4 数组指针变量是怎么初始化
我们知道:数组指针变量是用来存放数组地址的,那如何获取数组的地址呢,我们之前学习的&数组名,这个&数组名可以把整个数组的地址取出来。
1. int arr[10]={0};
2. &arr;//得到的是数组的地址
如果我们要存放个数组的地址,就得存放在数组指针变量中,
代码如下:
int (*p)[10] =&arr

我们在调试中也能看到&arr和p的类型是完全一致的。
因此,那个数指针组类型解析如下:

3.二维数组传参的本质
有了数组指针的理解,我们就能够讲一下二维数组传参的本质了。
过去我们有一个二维数组传参给一个函数的时候,我们是这么写的:
#include 这里实参是二维数组,形参也可以写成二维数组的形式,那还有什么其他的写法呢?
首先我们可以再次理解一下二维数组:二维数组起始可以看做每个元素是一维数组的数组,也就是二维数组的每个元素是一个一维数组。那么二维数组的首元素就是第一行,是个一维数组。
如下图所示:
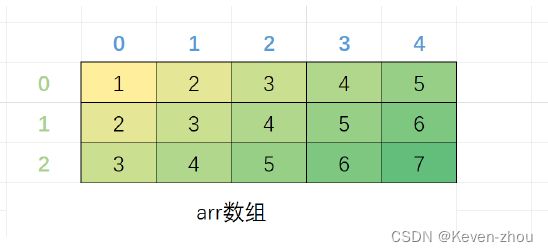
所以,我们根据数组名是数组首元素的地址这个规则,二维数组的数组名表示的就是第一行的地址,是一维数组的地址。根据上面的例子,第一行的一维数组的类型就是int[5],所以第一行的地址的类型就是数组指针类型int(*)[5]。那就意味着二维数组传参本质也是传递了地址,传递的是第一行这个一维数组的地址,那么形参也是可以写成指针形式的。
代码如下:
#include 可能有同学对上述代码不理解什么意思?
printf("%d ", *(*(p+i)+j));
我们就来解释一下吧~
- 我们知道,二维数组的数组名是第一行数组的地址。至于我们为什么要+j?
- 这是因为我们要拿到二维数组中每个元素的地址,而如果说不加j的话,我们总是拿到都是二维数组所在那行的第一个元素地址,这显然是不合理的。
- 另外,我们看到外层还有一个*,因为是( * (p+i)+j)只是拿到的是每个元素的地址,但我们目的是要拿到它每个元素的值,因此我们还要再对它进行解引用操作。也就是在最外层的括号左边,再加个 * 才能获取二维数组每个元素的值。
总结:二维数组传参,形参的部分可以写成数组,也可以写成指针形式。
4.函数指针变量
4.1 函数指针变量的创建
4.1.1什么是函数指针变量呢?
通过前面我们介绍整型指针,数组指针的时候,我们类比关系,不难的得出结论:
函数指针变量是用来存放函数地址,未来通过地址来调用函数的。
那么函数是否有地址呢?
我们不妨测试下面这几行代码:
#include 输出结果如下:

我们可以看到vs编译器确实打印出来了地址。
因此我们可以得出以下结论:
- 函数是有地址的。
- 函数名就是函数的地址
- 可以通过&函数名的方式获得函数的地址。
但如果我们要把函数的地址存放起来,那应该怎么做呢?
我们应该创建函数指针变量来存放函数的地址。
其实函数指针变量的写法其实和数组指针非常类似。
代码如下所示:
void test()
{
printf("hehe\n");
}
void (*pf1)() = &test;
void (*pf2)()= test;
int Add(int x, int y)
{
return x+y;
}
int(*pf3)(int, int) = Add;
int(*pf3)(int x, int y) = &Add;//x和y写上或者省略都是可以的
函数指针类型解析:

4.2 函数指针变量的使用
这里我们来给大家演示一下函数指针指向的函数的例子。

include <stdio.h>
int Add(int x, int y)
{
return x+y;
}
int main()
{
int(*pf3)(int, int) = Add;
printf("%d\n", (*pf3)(2, 3));
printf("%d\n", pf3(3, 5));
return 0;
}

4.3 两段有趣的代码
接下来有两段有趣的函数指针的代码,给大家讲一下代码里面的逻辑~
代码1:
(*(void (*)())0)();
这个代码的含义可能很多人都无法理解,但没事,接下来我将把代码拆解来给大家讲解一下。
我们先看下图:
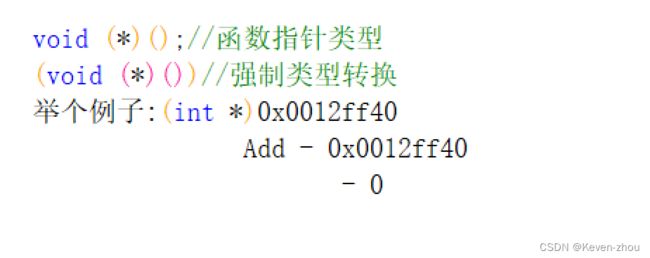
解剖代码1
- 从上图,我们知道:它其实把0这个整数强制转换为(void (*)()这种函数指针类型,想让0当做这种函数的地址。
当我们分析到这样子,这个代码的意思也就一目了然了。
它这个代码1本质的意思就是:
调用0地址处的函数,函数的参数为无参,返回的类型为void。
代码2:
void (*signal(int , void(*)(int)))(int);
我们继续来分析一下这个代码,看看它是什么意思。
同样地,我们可以把这个代码拆解成这样,方便大家可以理解。
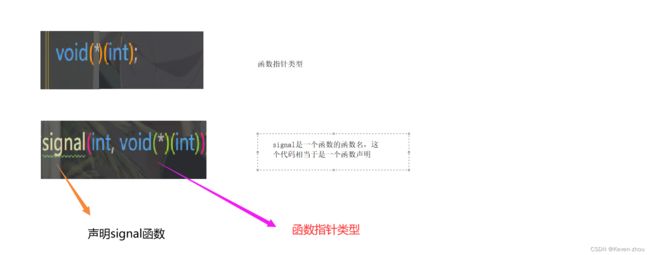
解剖代码2:
从上面我们的代码分析图可以得知:
- 声明的signal函数有2个参数,第一个参数是int类型的,第二个参数是函数指针类型的,该函数指向的是int类型,返回的类型是void。
- signal函数的返回类型也是一个函数指针,该函数指针向的函数,参数是int,返回的类型也是void。
另外,这两段代码均出自:《C陷阱和缺陷》这本书,大家有兴趣的话可以找来看看~
4.4. typedef关键字
4.4.1 typedef关键字是什么?
typedef关键字,顾名思义,就是用来类型重名名的。可以将复杂的类型,简单化。
4.4.2 typedef 关键字用法举例
4.4.2.1 举例1
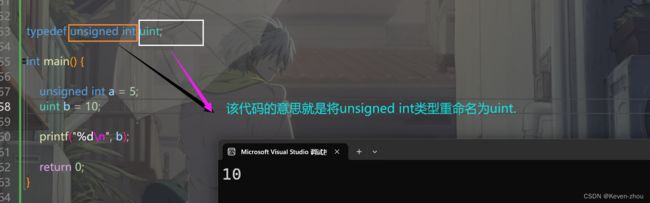
1.比如,我们觉得数据类型 unsingned int写起来不方便,如果写成uint就方便多了,那我们可以怎么写呢?
具体如下图所示:
4.4.2.1 举例2
如果是指针类型,能否重名呢?其实也是可以的,比如:将double*重命名为ptr,要怎么写呢?
具体写法如下所示:

4.4.2.1 举例3
那我们能否对数组指针和函数指针进行重命名呢,这个也是可以的。但是这个跟之前的重名稍微有点区别:
如果我们数组类型是int(*)[10],要重命名为tmp,那我们可以这样写:
typedef int(*tmp)[10];//新的类型名必须在*右边,这里就是将int(*)[10]类型重命名为tmp
int main() {
int(*arr)[10];
tmp v;
return 0;
}
如下图所示:

同时,我们通过vs调试,发现变量v也是数组指针int(*)[10]类型。
4.4.2.1 举例4
同理:函数指针类型的重命名也是一样的,比如,将void(*)(int)类型重命名为ptr_t,就可以这样写:
1 typedef void(*pfr_t)(int);//新的类型名必须在*的右边
如果说,我们要简化之前的这个代码,我们该怎么写呢?
void (*signal(int,void(*)(int)))(int);
如下图所示:
从图中,我们发现当我们把函数指针类型重命名为parr_t,vs编译器是没有发生任何报错的。
5.函数指针数组
我们已经到知道:
数组是一个存放相同类型数据的存储空间,并且我们之前也学习了指针数组。
比如:int *arr[10]; //数组的每个元素是int*
5.1 什么是函数指针数组?
如果我们把函数的地址存到一个数组中,那这个数组就叫函数指针数组。
5.2 如何定义函数指针数组?
我们来看下这行代码:
int (*parr1[3])();
代码分析:
由于我们前面介绍过,[]的优先级比*要高,因此,[]会先和parr1结合,说明parr1是数组。那数组的内容是什么呢?答案是:int(*)();
5.3 函数指针数组举例
如下图所示:
代码分析:
从图中我们发现,由于函数指针p1和p2都是相同的类型,且返回的数据类型为int。因此我们可以创建一个函数指针数组来把两个函数指针的地址存进去。
6.转移表
我们前面介绍了函数指针数组和函数指针的概念和基本用法。
那它们的用途是什么呢:转移表
接下来我将介绍用函数指针或函数指针数组作为转移表实现计算器的代码逻辑:
一般来说,我们实现计算器的逻辑是这么写的。
#include 虽然这样这个计算器代码这么写也是可以的。
但是我认为这个代码有以下不足的:
- switch语句中case子语句很多代码都是相似的,这样会显得有点冗余。
- 如果这个计算器要增加更多的计算功能,比如:
a%b,a&b,a^b,a|b。那这样的话就Switch的case子语句就会写得更多,这样整个代码逻辑就会变得复杂了。
那如何优化这个计算器的代码逻辑呢?
6.1.1用函数指针数组作为转移表实现计算器的代码逻辑
这个代码我们可以改进成这样:
#include 分析代码
从上面这行代码:
int(*ptr[5])(int x,int y) = {0,add,sub,mul,div};我们用函数指针数组ptr[5]来把add,sub,mul,div这四个函数的地址分别存进函数指针数组里面去。这里就相当于一个跳板,也就是我们说的转移表,后续根据用户输入input的值,通过函数数组指针ptr下标的值来调用所对应的函数。而那个变量x和y是调用函数时所传的参数。
6.1.2用函数指针作为转移表实现计算器的代码逻辑
代码如下:
#include 分析代码:
- 从上述代码中,我们是封装了一个calc函数。根据用户输入input的值,进到switch所对应的case的子语句中,并把对应的函数地址传给calc函数。然后在calc函数它的参数是函数指针类型,返回类型的是int。由于我们只用在calc函数内部进行打印,因此只用在calc函数中左边写上个void类型即可。
- 接着进入calc函数内部,根据用户输入变量x和y的值,将函数指针ptr的地址和参数x,y的值调用所对应的函数,并把最终计算的结果返回到ret,从而实现计算出两个操作数的结果出来。
**好了,今天的指针讲解3到这就结束了。 **
**如果觉得博主讲得不错的话,欢迎大家支持一下博主!!谢谢大家~ **