python之Requests库学习笔记
文章目录
- 1,前言
- 2,Requests库的安装
-
- 2.1,官网介绍
- 2.2,Requests库的安装
- 2.3,测试安装是否成功
- 2.4,Requests库的7个主要方法
- 3,Requests库的get()方法
-
- 3.1,用法
- 3.2,终级用法
- 3.3,深入Response对象
- 3.4,Response对象的属性
- 3,爬取网页的通用代码框架
-
- 3.1,理解Requests异常
- 3.2,使用框架
- 3.3,小结
- 4,HTTP协议及Requests库方法
-
- 4.1,HTTP协议
- 4.2,HTTP协议对资源的操作
- 5,Requests库主要方法及解析
-
- 5.1,requests.request()
- 5.2,requests.get()
- 5.3,requests.head()
- 5.4,requests.post()
- 5.4,requests.put()
- 5.5,requests.patch()
- 5.4,requests.delete()
- 6,总结
1,前言
我从今天开始学习Python爬虫部分,当然学习的过程中我也会把笔记输出出来。巩固一遍
Python的流行,是有庞大的第三方库。爬虫学习的第一站,requests库的使用。
2,Requests库的安装
2.1,官网介绍
Requests库有一个官网,感兴趣的小伙伴可取访问一下。

都是英文,不过多描述了。
2.2,Requests库的安装
怎么安装呢,以Windows为例,以管理员身份打开命令行。cmd
pip install Requests
2.3,测试安装是否成功
下载完,一定很好奇吧就这样打开了Python爬虫的大门。我们做个小测试看看吧
>>> import requests
>>> r = requests.get ("http://www.baidu.com")
>>> r.status_code
200
状态码是200,证明我们已经迈进了爬虫的大门了。
打印百度的首页试试:
>>> r.encoding = "utf-8"
>>> r.text
虽然有点乱,但不妨可以看出一些字段,心中有些小成就。
2.4,Requests库的7个主要方法
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法。 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET。 |
| requests.head() | 获取网页头部信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML提交局部修改请求,对应于HTTP的PACTH |
| requests.delete() | 向HTML提交删除请求,对应于HTTP的DELETE |
看上去很难的样子,我们细细看看,一定有破绽。
3,Requests库的get()方法
3.1,用法
它的正确格式是:
r = requests.get(url)
-
什么是URL?
URL:指统一资源定位系统,简单说就是个网址。通过URL定位访问服务器上的资源。我就直接理解为网址了。
-
这条代码有什么含义吗?
通过get方法和给出的URL构造一个向服务器请求资源的Request对象,Request对象是Requests库内部自动生成的。而返回的内容赋值给了r,则r是Response对象。r里面就有从服务器里返回的所有资源。
这一部分整理一下:两个对象
- Request对象:向服务器请求资源
- Response对象:从服务器里返回所有资源
有去有回。
以上是
requests.get(url)部分用法,看到部分,所以必然有一个全
3.2,终级用法
r = requests.get(url,params=None,**kwargs)
目前可以看到有三个参数,为什么是目前,注意**是表示省略。
介绍一下叭
-
URL:拟获取页面的URL链接(大白话就是网址)
-
params:URL中的额外参数,字典或字节流格式,可选
-
kwargs:12个控制的访问参数、
可以看见会有很多
3.3,深入Response对象
前面说过Response对象就是从服务器里返回的所有资源。
先看一段代码
>>> import requests
>>> r = requests.get ("http://www.baidu.com")
>>> r.status_code
200
>>> type(r)
<class 'requests.models.Response'>
>>> r.headers
{'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Tue, 18 May 2021 14:06:13 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:27:36 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}

r.status_code()返回的状态码是200,请求成功。然后type(r)这是一个类。也可以看见他的类名。
r.headers()返回网页的头部信息。
在包含服务器所有信息的同时,也有我们请求服务器的Request信息
3.4,Response对象的属性
有五个属性是访问网页最常用,最必要的五个属性。
| 属性 | 说明 |
|---|---|
| r.status_code | http请求的返回状态,200表示链接成功,404表示失败(只要不是200,任何一个数都是失败) |
| r.text | http响应内容的字符串形式,即。URL对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP相应内容的二进制形式 |
五个不多不少,演示一下,加深记忆
我们还是以百度为例。
我们开始去敲代码
- r.status_code
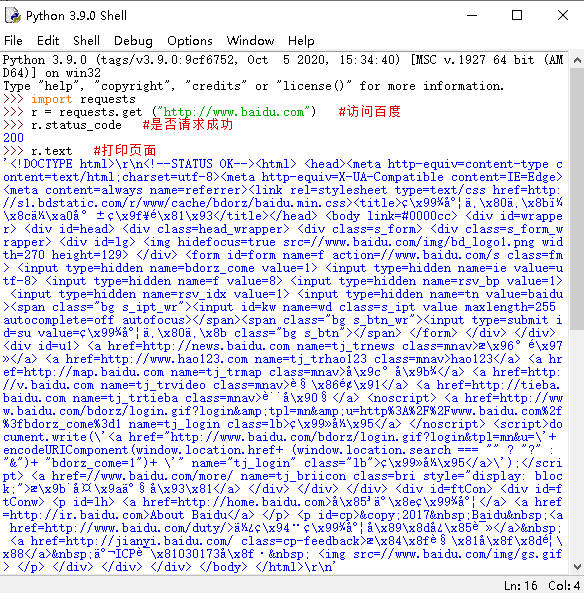
>>> import requests
>>> r = requests.get ("http://www.baidu.com")
>>> r.status_code
200
返回值是200,我们请求成功。
- r.text
>>> r.text
'\r\n ç\x99¾åº¦ä¸\x80ä¸\x8bï¼\x8cä½\xa0å°±ç\x9f¥é\x81\x93 å\x85³äº\x8eç\x99¾åº¦ About Baidu
©2017 Baidu 使ç\x94¨ç\x99¾åº¦å\x89\x8då¿\x85读 æ\x84\x8fè§\x81å\x8f\x8dé¦\x88 京ICPè¯\x81030173å\x8f· 
\r\n'

大概都是乱码,,看不懂。
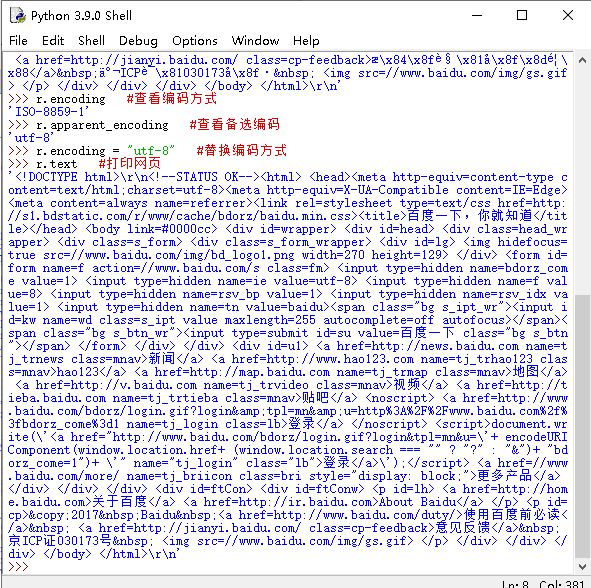
- r.encoding
此时我们就可以看一下他的编码
>>> r.encoding
'ISO-8859-1'
原来如此
-
r.apparent_encoding
他可能还有一种编码哦
>>> r.apparent_encoding 'utf-8'utf-8,有点东西
既然这样,尝试用utf-8编码替换上面的代码,输出
>>> r.encoding = "utf-8" >>> r.text '\r\n百度一下,你就知道 \r\n' >>>看见一些熟悉的汉字,是不是有一种豁然开朗的感觉
那么你们说,这两个属性有什么区别呢?
属性 说明 r.encoding 从HTTP header中猜测的响应内容编码方式 r.apparent_encoding 从内容中分析出的响应内容编码方式(备选编码方式) 可以看出的是有一个表示备选,
网络上的资源它们有各自的编码,如果没有编码,我们将看不懂。也就没办法用有效的解析方式是我们可读。所以这里就需要引入编码概念。
r.encoding是从HTTP header中的charset字段中获得编码方式。如果有charser字段,说明我们访问的服务器对资源的编码是有要求的,之后获得回来,保存到r.encoding中;但是并不是所有的服务器对资源编码都是有要求的,反之不存在charset字段,则返回ISO-8859-1,但是这样的编码并不能解析中文。所有就有了备选编码
r.apparent_encodingr.apparent_encoding是根据HTTP内容部分去分析内容中出现文本可能是的编码方式。
也阔以看出r.apparent_encoding 比r.encoding更加准确,后者是猜测。因此r.apparent_encoding 比较常用。
所以爬取一个网页的步骤是
这个里、首先看是不是200,在进行页面解析、打印等操作
3,爬取网页的通用代码框架
说起框架,什么是框架,就是一组代码,准确、方便。
3.1,理解Requests异常
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| reuqests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常。 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
| r.raise_for_status() | 返回Requests类型r是不是200,如果不是200,产生requests.HTTPError |
所以,这个代码框架长什么样呢
3.2,使用框架
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() #如果状态不是200,引发HTTPError
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
什么意思呢
看到def,定义了一个getHTMLText函数。看到
try--except想到异常处理的知识(这部分我忘了)。try里面是代码,except是异常。然后我们再分析try里面的一堆东西。请求访问一个URL,根据返回的Requests对象调佣r.raise_for_status()方法,来判断返回的内容是否正常。正常使返回内容解码也正常,打印网页信息;不正常,HTTPError,打印产生异常。
这么一来,是不是清晰了。用这个框架就可以快捷的发现早爬取网页遇到的问题。
我们对这段代码进行测试
if __name__=="__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))
>>>

修改这段代码
if __name__=="__main__":
url = "www.baidu.com"
print(getHTMLText(url))
>>>
产生异常
3.3,小结
不难发现就是用try-except对代码进行异常捕获、处理,在我们的使用中减少了大量找、改bug的时间。
4,HTTP协议及Requests库方法
我们已经知道了Requests库的七个主要方法,但是知道这个还是不够的,我们还应该了解http协议。
4.1,HTTP协议
- HTTP:HyperText Transfer Protocol,超文本传输协议
- HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。
- HTTP协议采用URL作为定位网络资源的标识。
在这三段定义中多少出现了陌生的名词,我们逐一攻克。
”请求与响应“模式:用户发起请求,服务器做出相关响应。
无状态:第一次请求与第二次请求没有相关关联。
应用层:该协议工作在TTP协议之上。
URL格式:http://host[:port][path]
- host:合法的inter主机域名或IP地址
- port:端口号,省略端口为80
- path:请求资源时到路径
URL是通过HTTP协议存取资源的inter路径,一个URL对应一个数据资源。
4.2,HTTP协议对资源的操作
或许下列的表格之前已经见过面,但还是应该在认识一下。
| 方法 | 说明 |
|---|---|
| GET | 请求获取URL位置的资源。 |
| HEAD | 请求获取URL位置资源的响应消息报告,即获取该资源的头部信息。 |
| POST | 请求向URL位置的资源后附加新的数据。 |
| PUT | 请求向URL位置存储一个资源,覆盖原来的URL位置资源。 |
| PATCH | 请求局部更新URL位置的资源,即改变该处资源的部分内容。 |
| DELETE | 请求删除URL位置存储的资源, |
是不是和2.4的很像,
怎么理解呢
我们把互联网比喻做云端,我们可以用URL对云端进行访问。想获取资源可以用
GET(全)和HEAD(头部)方法;存储资源呢?POST、PUT、PATCH或DELETE方法,每一次操作都是独立的。
put与PATCHS最大的区别就是后者节省网络带宽。
5,Requests库主要方法及解析
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法。 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET。 |
| requests.head() | 获取网页头部信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML提交局部修改请求,对应于HTTP的PACTH |
| requests.delete() | 向HTML提交删除请求,对应于HTTP的DELETE |
这张表格大家应该不会模式,甚至有一些想吐吧,但是说了这么多,我想我只会用前三个。
5.1,requests.request()
这是所有方法中的基础方法。
requests.request(method,url,**kwargs)
-
method:请求方式
requests.request(GET,url,**kwargs)请求方式可以理解为HTTP协议,与HTPP协议一一对应。
-
**kwargs:控制访问的参数,均为可选项
-
params:字典或字节序列,作为参数增加到URL中。
import requests kv = {"key1":"value1","key2":"value2"} r = requests.request('GET','http://python123.io/ws',params=kv) print(r.url) >>> https://python123.io/ws?key1=value1&key2=value2创建了一个字典,用GET方法向某一个链接请求同时提供了字典作为params相关参数。因为是可选参数,这里我们需要使用命名方式调佣。返回他的URL链接。
可以发现链接后面多了键值对。
也就是说我们在URL后面增加键值对,之后URL再去访问时,不知访问了资源,同时还带入了参数。而服务器可以接受这些资源,并经过筛选返回回来。
-
data:字典、字节序列或文件对象,作为Requests的内容
(作为向服务器提供、提交资源时使用。)
import requests kv = {"key1":"value1","key2":"value2"} r = requests.request('POST','http://python123.io/ws',data=kv)有两个键值对,用
POST方法作为data的一部分提交。我们所提交的键值对不放在链接里,而是放在URL链接对应位置地方的作为数据来存储。放一个字符串也阔以。
-
json:json格式的数据,作为Requests的内容
import requests kv = {"key1":"value1"} r = requests.request('POST','http://python123.io/ws',json=kv)这个数据格式在http中非常常用,但我并不了解。当然他也是可以作为内容部分向服务器提交。
用字典创建键值对,通过json,这个键值对就赋值到服务器的json上了
-
headres:字典,http定制头
import requests hd = {'user-agent':'chrome/10'} r = requests.request('POST','http://python123.io/ws',headers=hd)-
访问某一个URL时,所发起的http头字段。可以用这个字段来定制访问某一个URLhttp协议头
-
创建一个字段,去修改http协议中user-agent字段,改为Chrome/10。访问某一个链接时,服务器看到user-agent字段就是Chrome/10
-
Chrome/10:Chrome浏览器第10个版本
-
所以用这个可以模拟不同的浏览器去访问访问服务器
-
-
cookies:字典或CookieJar、Request中的cookie
-
auth:元组,支持HTTP认证功能。
-
files:字典类型,传输文件。
import requests fs = {"file":open("1.txt","rb")} r = requests.request('POST','http://python123.io/ws',files=fs)可以向服务器传输文件。
-
timeout:设定超时时间,单位为秒。
import requests r = requests.request('GET','http://www.baidu.com',timeout=10)如果在timeout时间内请求内容没有返回,出现报错。
-
proxise:字典类型,设定访问代理服务器,可以增加登录认证
可以防止爬虫逆追踪
-
allow_radirects:true/false,默认为false,重定向开关,
-
stream:true/false,默认为true,,获取内容立即下载开关
-
verify:true/false,默认为true,认证ssl证书开关
-
cert:本地ssl证书路径。
-
5.2,requests.get()
requests.get(url,params=None,**kwargs)
-
URL:拟获取页面的URL连接
-
params:URL额外参数,字典或字节流格式可选。
-
**kwargs:12个访问控制参数。
这12个控制参数和
requests.request()里的一样,只是没有proxise字段,其他完全一样
5.3,requests.head()
requests.head(url,**kwargs)
URL不必多说,
**kwargs:12个访问控制参数。这13个控制参数和requests.request()里的完全一样,
5.4,requests.post()
requests.post(url,data=None,josn=None,**kwargs)
URL,data,josn想必很熟悉,当然还有11个控制参数,想想也是除了data和josn好有11个
5.4,requests.put()
requests.put(url,data=None,**kwargs)
看到这里,是不是想问问是否都一样,还真一样
5.5,requests.patch()
x requests.patch(url,data=None,**kwargs)
5.4,requests.delete()
x requests.patch(url,**kwargs)
当然这些都一样啦
6,总结
从大宏观去看说了很多方法,打了很多代码,站在微观角度,说来说去基本就是那几个方法,反复出现,13个控制参数。
当然我们还应该要记住那个框架,这样节省大量时间
requests,get()是一个很常用的方法
这就是以上内容,我的笔记。
谢谢您的,文章有错误,欢迎你的指正;如果对您有帮助,是我的荣幸。