微博数据采集,微博爬虫,微博网页解析,完整代码(主体内容+评论内容)
如果失效了,可以私信我 保证及时更新
- 2023年9月12号更新版
-
- 完整代码
-
- 微博主体内容
- 微博评论内容
-
- 一级评论内容
- 二级评论内容
- 微博主体内容获取流程
- 微博评论内容获取流程
-
- 一级评论内容
- 二级评论内容
2023年9月12号更新版
参加新闻比赛,需要获取大众对某一方面的态度信息,因此选择微博作为信息收集的一部分
完整代码
微博主体内容
import time
import requests
import os
from bs4 import BeautifulSoup
import pandas as pd
def get_the_list_response(q='话题', n='1', p='页码'):
cookies = {
'_s_tentry': 'weibo.com',
'Apache': '1278126679099.0298.1694199077980',
'SINAGLOBAL': '1278126679099.0298.1694199077980',
'ULV': '1694199078024:1:1:1:1278126679099.0298.1694199077980:',
'WBtopGlobal_register_version': '2023090902',
'SUB': '_2A25J_x3DDeRhGeFO61AY8i_NwzyIHXVqjQgLrDV8PUNbmtAGLVCskW9NQYCXlgzxtb2agpoRvT9bg0g36mETgKHx',
'SUBP': '0033WrSXqPxfM725Ws9jqgMF55529P9D9W5mzQcPEhHvorRG-l7.BSsy5JpX5KzhUgL.FoM7ehz4eo2p1h52dJLoI0qLxK-LBKBLBKMLxKnL1--L1heLxKnL1-qLBo.LxK-L1KeL1KzLxK-L1KeL1KzLxK-L1KeL1Kzt',
'ALF': '1725735187',
'SSOLoginState': '1694199187',
'PC_TOKEN': '5a0a002501',
}
headers = {
'authority': 's.weibo.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'referer': 'https://s.weibo.com/weibo?q=%23%E6%96%B0%E9%97%BB%E5%AD%A6%E6%95%99%E6%8E%88%E6%80%92%E6%80%BC%E5%BC%A0%E9%9B%AA%E5%B3%B0%23&nodup=1',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
}
params = {
'q': q,
'nodup': n,
'page': p,
}
response = requests.get('https://s.weibo.com/weibo', params=params, cookies=cookies, headers=headers)
return response
def parse_the_list(text):
soup = BeautifulSoup(text, 'lxml')
divs = soup.select('div[action-type="feed_list_item"]')
lst = []
for div in divs:
mid = div.get('mid')
time = div.select('div.card-feed > div.content > div.from > a:first-of-type')
if time:
time = time[0].string.strip()
else:
time = None
p = div.select('div.card-feed > div.content > p:last-of-type')
if p:
p = p[0].strings
content = '\n'.join([para.replace('\u200b', '').strip() for para in list(p)]).strip()
else:
content = None
star = div.select('ul > li > a > button > span.woo-like-count')
if star:
star = list(star[0].strings)[0]
else:
star = None
lst.append((mid, content, star, time))
df = pd.DataFrame(lst, columns=['mid', 'content', 'star', 'time'])
return df
def get_the_list(q, p):
df_list = []
for i in range(1, p+1):
response = get_the_list_response(q=q, p=i)
if response.status_code == 200:
df = parse_the_list(response.text)
df_list.append(df)
print(f'第{i}页解析成功!', flush=True)
return df_list
if __name__ == '__main__':
q = '#华为发布会#'
p = 20
df_list = get_the_list(q, p)
pd.concat(df_list).to_excel(f'{q}.xlsx', index=False)
微博评论内容
一级评论内容
import requests
import pandas as pd
import json
page_num = 0
def get_content_1(uid, mid, the_first=True, max_id=None):
cookies = {
'SINAGLOBAL': '1278126679099.0298.1694199077980',
'SUBP': '0033WrSXqPxfM725Ws9jqgMF55529P9D9W5mzQcPEhHvorRG-l7.BSsy5JpX5KMhUgL.FoM7ehz4eo2p1h52dJLoI0qLxK-LBKBLBKMLxKnL1--L1heLxKnL1-qLBo.LxK-L1KeL1KzLxK-L1KeL1KzLxK-L1KeL1Kzt',
'XSRF-TOKEN': 'F2EEQZrINBfzB2HPPxqTMQJ_',
'ALF': '1697089355',
'SSOLoginState': '1694497354',
'SCF': 'ApDYB6ZQHU_wHU8ItPHSso29Xu0ZRSkOOiFTBeXETNm72ymhw36b_mHClr0ewNZN4ShIPpOcL0IcsUXxdc8Hjcc.',
'SUB': '_2A25J-4obDeRhGeFO61AY8i_NwzyIHXVrcPzTrDV8PUNbmtAGLW7NkW9NQYCXlkwnjDGcFQsKW0YQuGxnZHHUKcwL',
'_s_tentry': 'weibo.com',
'Apache': '9940157047236.127.1694497456654',
'ULV': '1694497456684:5:5:1:9940157047236.127.1694497456654:1694273044323',
'WBPSESS': 'X5DJqu8gKpwqYSp80b4XokKvi4u4_oikBqVmvlBCHvGwXMxtKAFxIPg-LIF7foS715Sa4NttSYqzj5x2Ms5ynFwkvQws-CZ4L-m6NLVjmDKUuHrZR3UM90hhPWHorFbkpQx1WZuZ2yCA73LeWLQYNA==',
}
headers = {
'authority': 'weibo.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'client-version': 'v2.43.30',
'referer': 'https://weibo.com/1762257041/NiSAxfmbZ',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'server-version': 'v2023.09.08.4',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'x-requested-with': 'XMLHttpRequest',
'x-xsrf-token': 'F2EEQZrINBfzB2HPPxqTMQJ_',
}
params = {
'is_reload': '1',
'id': f'{mid}',
'is_show_bulletin': '2',
'is_mix': '0',
'count': '20',
'uid': f'{uid}',
'fetch_level': '0',
'locale': 'zh-CN',
}
if not the_first:
params['flow'] = 0
params['max_id'] = max_id
else:
pass
response = requests.get('https://weibo.com/ajax/statuses/buildComments', params=params, cookies=cookies, headers=headers)
return response
def get_content_2(get_content_1_url):
cookies = {
'SINAGLOBAL': '1278126679099.0298.1694199077980',
'SUBP': '0033WrSXqPxfM725Ws9jqgMF55529P9D9W5mzQcPEhHvorRG-l7.BSsy5JpX5KMhUgL.FoM7ehz4eo2p1h52dJLoI0qLxK-LBKBLBKMLxKnL1--L1heLxKnL1-qLBo.LxK-L1KeL1KzLxK-L1KeL1KzLxK-L1KeL1Kzt',
'XSRF-TOKEN': 'F2EEQZrINBfzB2HPPxqTMQJ_',
'ALF': '1697089355',
'SSOLoginState': '1694497354',
'SCF': 'ApDYB6ZQHU_wHU8ItPHSso29Xu0ZRSkOOiFTBeXETNm72ymhw36b_mHClr0ewNZN4ShIPpOcL0IcsUXxdc8Hjcc.',
'SUB': '_2A25J-4obDeRhGeFO61AY8i_NwzyIHXVrcPzTrDV8PUNbmtAGLW7NkW9NQYCXlkwnjDGcFQsKW0YQuGxnZHHUKcwL',
'_s_tentry': 'weibo.com',
'Apache': '9940157047236.127.1694497456654',
'ULV': '1694497456684:5:5:1:9940157047236.127.1694497456654:1694273044323',
'WBPSESS': 'X5DJqu8gKpwqYSp80b4XokKvi4u4_oikBqVmvlBCHvGwXMxtKAFxIPg-LIF7foS715Sa4NttSYqzj5x2Ms5ynFwkvQws-CZ4L-m6NLVjmDKUuHrZR3UM90hhPWHorFbkpQx1WZuZ2yCA73LeWLQYNA==',
}
headers = {
'authority': 'weibo.com',
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'multipart/form-data; boundary=----WebKitFormBoundaryNs1Toe4Mbr8n1qXm',
'origin': 'https://weibo.com',
'referer': 'https://weibo.com/1762257041/NiSAxfmbZ',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'x-xsrf-token': 'F2EEQZrINBfzB2HPPxqTMQJ_',
}
s = '{"name":"https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4944997453660231&is_show_bulletin=2&is_mix=0&max_id=139282732792325&count=20&uid=1762257041&fetch_level=0&locale=zh-CN","entryType":"resource","startTime":20639.80000001192,"duration":563,"initiatorType":"xmlhttprequest","nextHopProtocol":"h2","renderBlockingStatus":"non-blocking","workerStart":0,"redirectStart":0,"redirectEnd":0,"fetchStart":20639.80000001192,"domainLookupStart":20639.80000001192,"domainLookupEnd":20639.80000001192,"connectStart":20639.80000001192,"secureConnectionStart":20639.80000001192,"connectEnd":20639.80000001192,"requestStart":20641.600000023842,"responseStart":21198.600000023842,"firstInterimResponseStart":0,"responseEnd":21202.80000001192,"transferSize":7374,"encodedBodySize":7074,"decodedBodySize":42581,"responseStatus":200,"serverTiming":[],"dns":0,"tcp":0,"ttfb":557,"pathname":"https://weibo.com/ajax/statuses/buildComments","speed":0}'
s = json.loads(s)
s['name'] = get_content_1_url
s = json.dumps(s)
data = f'------WebKitFormBoundaryNs1Toe4Mbr8n1qXm\r\nContent-Disposition: form-data; name="entry"\r\n\r\n{s}\r\n------WebKitFormBoundaryNs1Toe4Mbr8n1qXm\r\nContent-Disposition: form-data; name="request_id"\r\n\r\n\r\n------WebKitFormBoundaryNs1Toe4Mbr8n1qXm--\r\n'
response = requests.post('https://weibo.com/ajax/log/rum', cookies=cookies, headers=headers, data=data)
return response.text
def get_once_data(uid, mid, the_first=True, max_id=None):
respones_1 = get_content_1(uid, mid, the_first, max_id)
url = respones_1.url
response_2 = get_content_2(url)
df = pd.DataFrame(respones_1.json()['data'])
max_id = respones_1.json()['max_id']
return max_id, df
# 自定义
uid = '2557129567'
mid = '4945149706373161'
page = 10
# 初始化
df_list = []
max_id = ''
for i in range(page):
if i == 0:
max_id, df = get_once_data(uid=uid, mid=mid)
else:
max_id, df = get_once_data(uid=uid, mid=mid, the_first=False, max_id=max_id)
if df.shape[0] == 0:
break
else:
df_list.append(df)
print(f'第{i}页解析完毕!max_id:{max_id}')
df = pd.concat(df_list).astype(str).drop_duplicates()
df.to_excel(f'{mid}.xlsx', index=False)
二级评论内容
import requests
import pandas as pd
import json
import os
page_num = 0
cookies = {
'SINAGLOBAL': '1278126679099.0298.1694199077980',
'SUBP': '0033WrSXqPxfM725Ws9jqgMF55529P9D9W5mzQcPEhHvorRG-l7.BSsy5JpX5KMhUgL.FoM7ehz4eo2p1h52dJLoI0qLxK-LBKBLBKMLxKnL1--L1heLxKnL1-qLBo.LxK-L1KeL1KzLxK-L1KeL1KzLxK-L1KeL1Kzt',
'XSRF-TOKEN': '47NC7wE7TMhcqfh1K-4bacK-',
'ALF': '1697384140',
'SSOLoginState': '1694792141',
'SCF': 'ApDYB6ZQHU_wHU8ItPHSso29Xu0ZRSkOOiFTBeXETNm7IJXuI95RLbWORIsozuK4Ohxs_boeOIedEcczDT3uSAI.',
'SUB': '_2A25IAAmdDeRhGeFO61AY8i_NwzyIHXVrdHxVrDV8PUNbmtAGLU74kW9NQYCXlmPtQ1DG4kl_wLzqQqkPl_Do1sZu',
'_s_tentry': 'weibo.com',
'Apache': '3760261250067.669.1694792155706',
'ULV': '1694792155740:8:8:4:3760261250067.669.1694792155706:1694767801057',
'WBPSESS': 'X5DJqu8gKpwqYSp80b4XokKvi4u4_oikBqVmvlBCHvGwXMxtKAFxIPg-LIF7foS715Sa4NttSYqzj5x2Ms5ynKVOM5I_Fsy9GECAYh38R4DQ-gq7M5XOe4y1gOUqvm1hOK60dUKvrA5hLuONCL2ing==',
}
def get_content_1(uid, mid, the_first=True, max_id=None):
headers = {
'authority': 'weibo.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'client-version': 'v2.43.32',
'referer': 'https://weibo.com/1887344341/NhAosFSL4',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'server-version': 'v2023.09.14.1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'x-requested-with': 'XMLHttpRequest',
'x-xsrf-token': '-UX-uyKz0jmzbTnlkyDEMvSO',
}
params = {
'is_reload': '1',
'id': f'{mid}',
'is_show_bulletin': '2',
'is_mix': '1',
'fetch_level': '1',
'max_id': '0',
'count': '20',
'uid': f'{uid}',
'locale': 'zh-CN',
}
if not the_first:
params['flow'] = 0
params['max_id'] = max_id
else:
pass
response = requests.get('https://weibo.com/ajax/statuses/buildComments', params=params, cookies=cookies, headers=headers)
return response
def get_content_2(get_content_1_url):
headers = {
'authority': 'weibo.com',
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'multipart/form-data; boundary=----WebKitFormBoundaryNs1Toe4Mbr8n1qXm',
'origin': 'https://weibo.com',
'referer': 'https://weibo.com/1762257041/NiSAxfmbZ',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'x-xsrf-token': 'F2EEQZrINBfzB2HPPxqTMQJ_',
}
s = '{"name":"https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4944997453660231&is_show_bulletin=2&is_mix=0&max_id=139282732792325&count=20&uid=1762257041&fetch_level=0&locale=zh-CN","entryType":"resource","startTime":20639.80000001192,"duration":563,"initiatorType":"xmlhttprequest","nextHopProtocol":"h2","renderBlockingStatus":"non-blocking","workerStart":0,"redirectStart":0,"redirectEnd":0,"fetchStart":20639.80000001192,"domainLookupStart":20639.80000001192,"domainLookupEnd":20639.80000001192,"connectStart":20639.80000001192,"secureConnectionStart":20639.80000001192,"connectEnd":20639.80000001192,"requestStart":20641.600000023842,"responseStart":21198.600000023842,"firstInterimResponseStart":0,"responseEnd":21202.80000001192,"transferSize":7374,"encodedBodySize":7074,"decodedBodySize":42581,"responseStatus":200,"serverTiming":[],"dns":0,"tcp":0,"ttfb":557,"pathname":"https://weibo.com/ajax/statuses/buildComments","speed":0}'
s = json.loads(s)
s['name'] = get_content_1_url
s = json.dumps(s)
data = f'------WebKitFormBoundaryNs1Toe4Mbr8n1qXm\r\nContent-Disposition: form-data; name="entry"\r\n\r\n{s}\r\n------WebKitFormBoundaryNs1Toe4Mbr8n1qXm\r\nContent-Disposition: form-data; name="request_id"\r\n\r\n\r\n------WebKitFormBoundaryNs1Toe4Mbr8n1qXm--\r\n'
response = requests.post('https://weibo.com/ajax/log/rum', cookies=cookies, headers=headers, data=data)
return response.text
def get_once_data(uid, mid, the_first=True, max_id=None):
respones_1 = get_content_1(uid, mid, the_first, max_id)
url = respones_1.url
response_2 = get_content_2(url)
df = pd.DataFrame(respones_1.json()['data'])
max_id = respones_1.json()['max_id']
return max_id, df
if __name__ == '__main__':
# 得到的一级评论信息
df = pd.read_csv('信息汇总.csv')
df = df[df['评论数']>0]
for i in range(df.shape[0]):
mid = df.iloc[i].mid
uid = df.iloc[i].uid
name = df.iloc[i]['话题']
page = 100
if not os.path.exists(f'./二级评论数据/{mid}-{uid}.csv'):
print(f'不存在 ./二级评论数据/{mid}-{uid}.csv')
df_list = []
max_id = ''
for j in range(page):
if j == 0:
max_id, df_ = get_once_data(uid=uid, mid=mid)
else:
max_id, df_ = get_once_data(uid=uid, mid=mid, the_first=False, max_id=max_id)
if df_.shape[0] == 0 or max_id == 0:
break
else:
df_list.append(df_)
print(f'{mid}第{j}页解析完毕!max_id:{max_id}')
if df_list:
outdf = pd.concat(df_list).astype(str).drop_duplicates()
outdf['话题'] = name
print(f'文件长度为{outdf.shape[0]},文件保存为 ./二级评论数据/{mid}-{uid}.csv')
outdf.to_csv(f'./二级评论数据/{mid}-{uid}.csv', index=False)
else:
pass
else:
print(f'存在 ./二级评论数据/{mid}-{uid}.csv')
微博主体内容获取流程
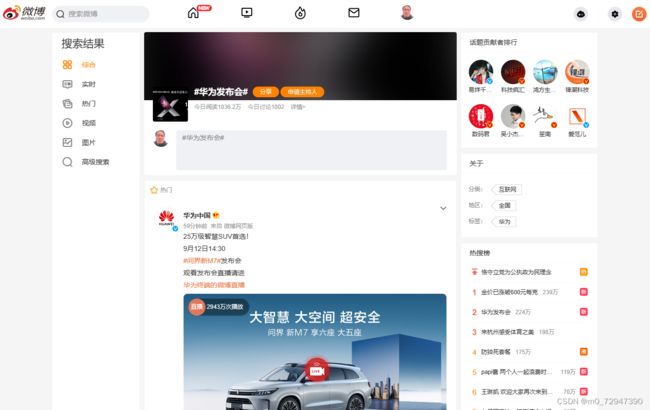
以华为发布会这一热搜为例子,我们可以通过开发者模式得到信息基本都包含在下面的 div tag中
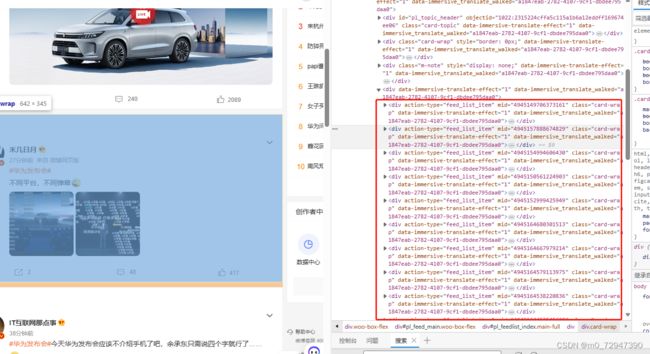
我们通过网络这一模块进行解析,发现信息基本都存储在 %23 开头的请求之中,接下来分析一下响应内容
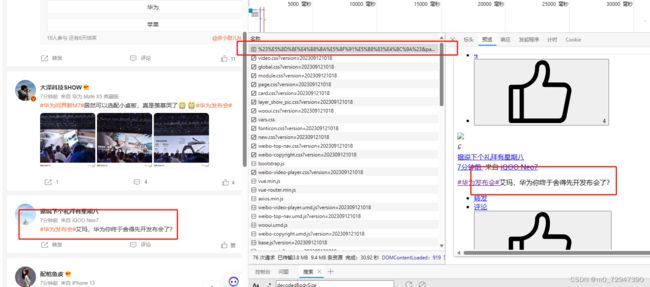
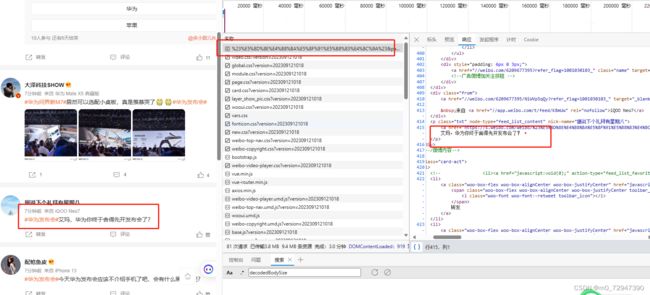
这里可以看出响应内容为 html 格式,因此我们可以用xpath或者css来进行解析,这里我们使用BeautifulSoup来解析,解析代码如下:
soup = BeautifulSoup(response.text, 'lxml')
divs = soup.select('div[action-type="feed_list_item"]')
lst = []
for div in divs:
mid = div.get('mid')
uid = div.select('div.card-feed > div.avator > a')
if uid:
uid = uid[0].get('href').replace('.com/', '?').split('?')[1]
else:
uid = None
time = div.select('div.card-feed > div.content > div.from > a:first-of-type')
if time:
time = time[0].string.strip()
else:
time = None
p = div.select('div.card-feed > div.content > p:last-of-type')
if p:
p = p[0].strings
content = '\n'.join([para.replace('\u200b', '').strip() for para in list(p)]).strip()
else:
content = None
star = div.select('ul > li > a > button > span.woo-like-count')
if star:
star = list(star[0].strings)[0]
else:
star = None
lst.append((mid, uid, content, star, time))
pd.DataFrame(lst, columns=['mid', 'uid', 'content', 'star', 'time'])
我们可以获得如下结果:

这里的 mid , uid 两个参数是为了下一节获取微博评论内容需要用到的参数,这里不多解释,如果不需要删除就好,接下来我们看一下请求内容。在开始之前,为了对请求解析方便,在这里我们点击一下 查看全部搜索结果
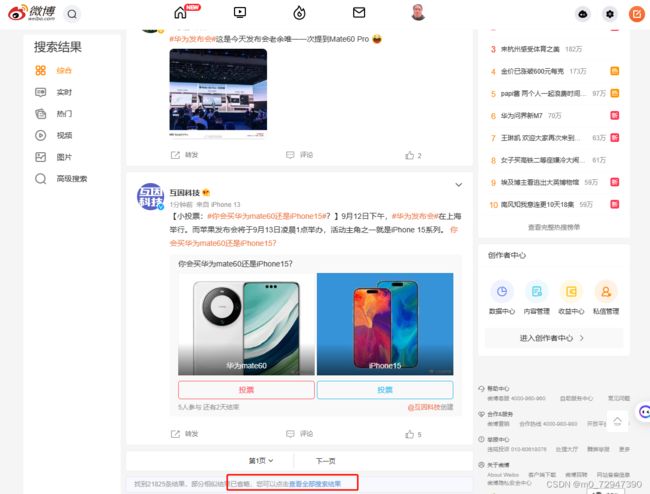
可以发现一个以 weibo 开头的新的请求,和 %23 开头的请求内容类似,但是带了参数 q 和nodup ,再翻页之后我们可以得到 page 这一个参数

我的解析如下:
1. q:话题
2. nudup:是否展示完整内容
3. page:页码
然后可以对这个请求进行模拟,写入 python 代码中,结合之前的解析,发现内容获取 成功!
完整代码如下:
import time
import requests
import os
from bs4 import BeautifulSoup
import pandas as pd
def get_the_list_response(q='#华为发布会#', n='1', p='2'):
cookies = {
'_s_tentry': 'weibo.com',
'Apache': '1278126679099.0298.1694199077980',
'SINAGLOBAL': '1278126679099.0298.1694199077980',
'ULV': '1694199078024:1:1:1:1278126679099.0298.1694199077980:',
'WBtopGlobal_register_version': '2023090902',
'SUB': '_2A25J_x3DDeRhGeFO61AY8i_NwzyIHXVqjQgLrDV8PUNbmtAGLVCskW9NQYCXlgzxtb2agpoRvT9bg0g36mETgKHx',
'SUBP': '0033WrSXqPxfM725Ws9jqgMF55529P9D9W5mzQcPEhHvorRG-l7.BSsy5JpX5KzhUgL.FoM7ehz4eo2p1h52dJLoI0qLxK-LBKBLBKMLxKnL1--L1heLxKnL1-qLBo.LxK-L1KeL1KzLxK-L1KeL1KzLxK-L1KeL1Kzt',
'ALF': '1725735187',
'SSOLoginState': '1694199187',
'PC_TOKEN': '5a0a002501',
}
headers = {
'authority': 's.weibo.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'referer': 'https://s.weibo.com/weibo?q=%23%E6%96%B0%E9%97%BB%E5%AD%A6%E6%95%99%E6%8E%88%E6%80%92%E6%80%BC%E5%BC%A0%E9%9B%AA%E5%B3%B0%23&nodup=1',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
}
params = {
'q': q,
'nodup': n,
'page': p,
}
response = requests.get('https://s.weibo.com/weibo', params=params, cookies=cookies, headers=headers)
return response
def parse_the_list(text):
soup = BeautifulSoup(text, 'lxml')
divs = soup.select('div[action-type="feed_list_item"]')
lst = []
for div in divs:
mid = div.get('mid')
time = div.select('div.card-feed > div.content > div.from > a:first-of-type')
if time:
time = time[0].string.strip()
else:
time = None
p = div.select('div.card-feed > div.content > p:last-of-type')
if p:
p = p[0].strings
content = '\n'.join([para.replace('\u200b', '').strip() for para in list(p)]).strip()
else:
content = None
star = div.select('ul > li > a > button > span.woo-like-count')
if star:
star = list(star[0].strings)[0]
else:
star = None
lst.append((mid, content, star, time))
df = pd.DataFrame(lst, columns=['mid', 'content', 'star', 'time'])
return df
def get_the_list(q, p):
df_list = []
for i in range(1, p+1):
response = get_the_list_response(q=q, p=i)
if response.status_code == 200:
df = parse_the_list(response.text)
df_list.append(df)
print(f'第{i}页解析成功!', flush=True)
return df_list
if __name__ == '__main__':
q = '#华为发布会#'
p = 20
df_list = get_the_list(q, p)
df_list.to_excel(f'{q}.xlsx', index=False)
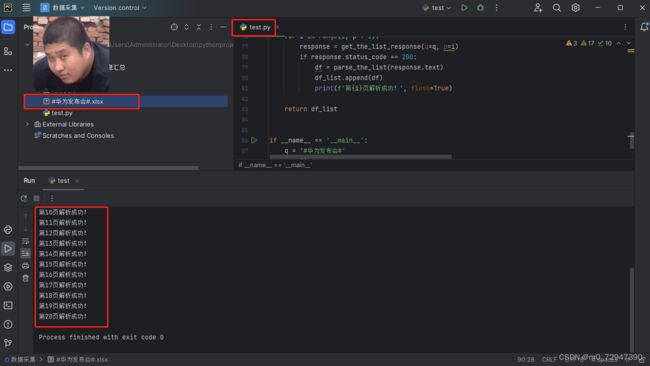
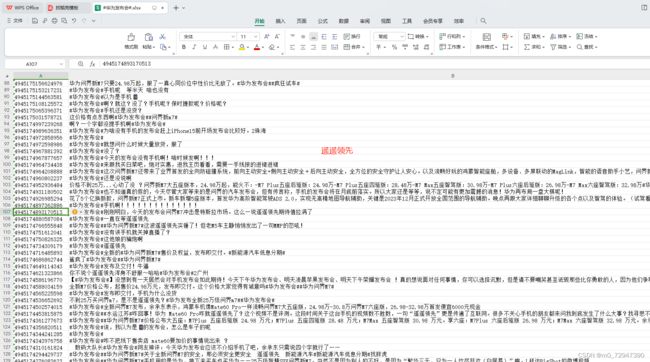
微博评论内容获取流程
一级评论内容
上一节内容获取了微博主题内容,可以发现并没有什么难点,本来我以为都结束了,队长偏要评论内容,无奈我只好继续解析评论内容,接下来我们来获取微博评论内容,有一点点绕。
首先我们点开评论数较多的微博, 然后点击 后面还有552条评论,点击查看

看到 < div class=“vue-recycle-scroller__item-wrapper” > 这个内容是我们想要的

和上一节一样来查找请求, 发现 buildComments?is_reload=1&id= 这个请求包含了我们想要的信息,而且预览内容为 json 格式,省去了解析 html 的步骤,接下来只需要解析请求就ok了。
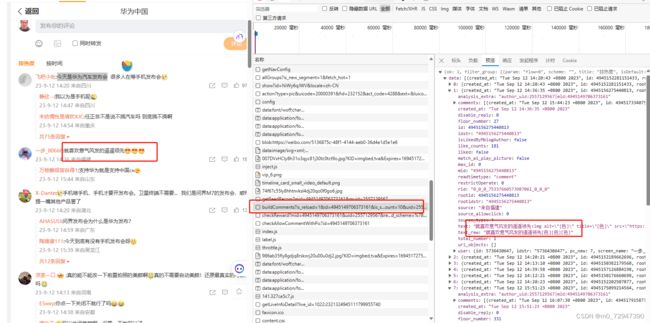
话不多说,往下滑动,多获得几个请求,对得到的请求,分析如下:
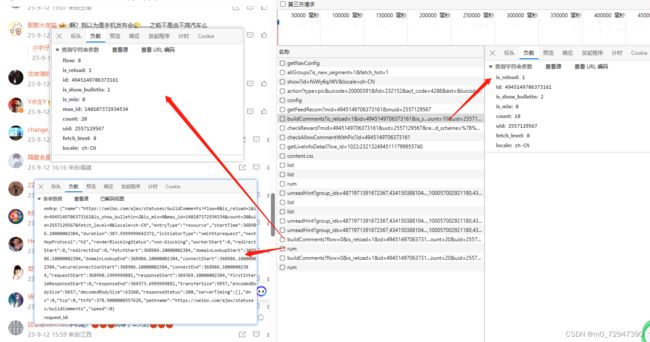
每次往下滑动都会出现两个请求,一个是 buildComments?flow=0&is_reload=1&id=49451497063731… ,一个是 rum 。同时 buildComments?flow=0&is_reload=1&id=49451497063731… 请求的参数发生了变化,第一次请求里面没有 flow 和 max_id 这两个参数,经过我一下午分析可以得到以下结果:
1. flow:判断是否第一次请求,第一次请求不能加
2. id:微博主体内容的id 上一节获取的mid
3. count:评论数
4. uid:微博主体内容的用户id 上一节获取的uid
5. max_id:上一次请求后最后一个评论的mid,第一次请求不能加
6. 其他参数保持不变
7. rum在buildComments之后验证请求是否人为发出,反爬机制
8. rum的参数围绕buildComments展开
9. rum构造完全凑巧,部分参数对结果无效,能用就行!
完整代码如下:
import requests
import pandas as pd
import json
page_num = 0
def get_content_1(uid, mid, the_first=True, max_id=None):
cookies = {
'SINAGLOBAL': '1278126679099.0298.1694199077980',
'SUBP': '0033WrSXqPxfM725Ws9jqgMF55529P9D9W5mzQcPEhHvorRG-l7.BSsy5JpX5KMhUgL.FoM7ehz4eo2p1h52dJLoI0qLxK-LBKBLBKMLxKnL1--L1heLxKnL1-qLBo.LxK-L1KeL1KzLxK-L1KeL1KzLxK-L1KeL1Kzt',
'XSRF-TOKEN': 'F2EEQZrINBfzB2HPPxqTMQJ_',
'ALF': '1697089355',
'SSOLoginState': '1694497354',
'SCF': 'ApDYB6ZQHU_wHU8ItPHSso29Xu0ZRSkOOiFTBeXETNm72ymhw36b_mHClr0ewNZN4ShIPpOcL0IcsUXxdc8Hjcc.',
'SUB': '_2A25J-4obDeRhGeFO61AY8i_NwzyIHXVrcPzTrDV8PUNbmtAGLW7NkW9NQYCXlkwnjDGcFQsKW0YQuGxnZHHUKcwL',
'_s_tentry': 'weibo.com',
'Apache': '9940157047236.127.1694497456654',
'ULV': '1694497456684:5:5:1:9940157047236.127.1694497456654:1694273044323',
'WBPSESS': 'X5DJqu8gKpwqYSp80b4XokKvi4u4_oikBqVmvlBCHvGwXMxtKAFxIPg-LIF7foS715Sa4NttSYqzj5x2Ms5ynFwkvQws-CZ4L-m6NLVjmDKUuHrZR3UM90hhPWHorFbkpQx1WZuZ2yCA73LeWLQYNA==',
}
headers = {
'authority': 'weibo.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'client-version': 'v2.43.30',
'referer': 'https://weibo.com/1762257041/NiSAxfmbZ',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'server-version': 'v2023.09.08.4',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'x-requested-with': 'XMLHttpRequest',
'x-xsrf-token': 'F2EEQZrINBfzB2HPPxqTMQJ_',
}
params = {
'is_reload': '1',
'id': f'{mid}',
'is_show_bulletin': '2',
'is_mix': '0',
'count': '20',
'uid': f'{uid}',
'fetch_level': '0',
'locale': 'zh-CN',
}
if not the_first:
params['flow'] = 0
params['max_id'] = max_id
else:
pass
response = requests.get('https://weibo.com/ajax/statuses/buildComments', params=params, cookies=cookies, headers=headers)
return response
def get_content_2(get_content_1_url):
cookies = {
'SINAGLOBAL': '1278126679099.0298.1694199077980',
'SUBP': '0033WrSXqPxfM725Ws9jqgMF55529P9D9W5mzQcPEhHvorRG-l7.BSsy5JpX5KMhUgL.FoM7ehz4eo2p1h52dJLoI0qLxK-LBKBLBKMLxKnL1--L1heLxKnL1-qLBo.LxK-L1KeL1KzLxK-L1KeL1KzLxK-L1KeL1Kzt',
'XSRF-TOKEN': 'F2EEQZrINBfzB2HPPxqTMQJ_',
'ALF': '1697089355',
'SSOLoginState': '1694497354',
'SCF': 'ApDYB6ZQHU_wHU8ItPHSso29Xu0ZRSkOOiFTBeXETNm72ymhw36b_mHClr0ewNZN4ShIPpOcL0IcsUXxdc8Hjcc.',
'SUB': '_2A25J-4obDeRhGeFO61AY8i_NwzyIHXVrcPzTrDV8PUNbmtAGLW7NkW9NQYCXlkwnjDGcFQsKW0YQuGxnZHHUKcwL',
'_s_tentry': 'weibo.com',
'Apache': '9940157047236.127.1694497456654',
'ULV': '1694497456684:5:5:1:9940157047236.127.1694497456654:1694273044323',
'WBPSESS': 'X5DJqu8gKpwqYSp80b4XokKvi4u4_oikBqVmvlBCHvGwXMxtKAFxIPg-LIF7foS715Sa4NttSYqzj5x2Ms5ynFwkvQws-CZ4L-m6NLVjmDKUuHrZR3UM90hhPWHorFbkpQx1WZuZ2yCA73LeWLQYNA==',
}
headers = {
'authority': 'weibo.com',
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'multipart/form-data; boundary=----WebKitFormBoundaryNs1Toe4Mbr8n1qXm',
'origin': 'https://weibo.com',
'referer': 'https://weibo.com/1762257041/NiSAxfmbZ',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'x-xsrf-token': 'F2EEQZrINBfzB2HPPxqTMQJ_',
}
s = '{"name":"https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4944997453660231&is_show_bulletin=2&is_mix=0&max_id=139282732792325&count=20&uid=1762257041&fetch_level=0&locale=zh-CN","entryType":"resource","startTime":20639.80000001192,"duration":563,"initiatorType":"xmlhttprequest","nextHopProtocol":"h2","renderBlockingStatus":"non-blocking","workerStart":0,"redirectStart":0,"redirectEnd":0,"fetchStart":20639.80000001192,"domainLookupStart":20639.80000001192,"domainLookupEnd":20639.80000001192,"connectStart":20639.80000001192,"secureConnectionStart":20639.80000001192,"connectEnd":20639.80000001192,"requestStart":20641.600000023842,"responseStart":21198.600000023842,"firstInterimResponseStart":0,"responseEnd":21202.80000001192,"transferSize":7374,"encodedBodySize":7074,"decodedBodySize":42581,"responseStatus":200,"serverTiming":[],"dns":0,"tcp":0,"ttfb":557,"pathname":"https://weibo.com/ajax/statuses/buildComments","speed":0}'
s = json.loads(s)
s['name'] = get_content_1_url
s = json.dumps(s)
data = f'------WebKitFormBoundaryNs1Toe4Mbr8n1qXm\r\nContent-Disposition: form-data; name="entry"\r\n\r\n{s}\r\n------WebKitFormBoundaryNs1Toe4Mbr8n1qXm\r\nContent-Disposition: form-data; name="request_id"\r\n\r\n\r\n------WebKitFormBoundaryNs1Toe4Mbr8n1qXm--\r\n'
response = requests.post('https://weibo.com/ajax/log/rum', cookies=cookies, headers=headers, data=data)
return response.text
def get_once_data(uid, mid, the_first=True, max_id=None):
respones_1 = get_content_1(uid, mid, the_first, max_id)
url = respones_1.url
response_2 = get_content_2(url)
df = pd.DataFrame(respones_1.json()['data'])
max_id = respones_1.json()['max_id']
return max_id, df
# 自定义
uid = '2557129567'
mid = '4945149706373161'
page = 10
# 初始化
df_list = []
max_id = ''
for i in range(page):
if i == 0:
max_id, df = get_once_data(uid=uid, mid=mid)
else:
max_id, df = get_once_data(uid=uid, mid=mid, the_first=False, max_id=max_id)
if df.shape[0] == 0:
break
else:
df_list.append(df)
print(f'第{i}页解析完毕!max_id:{max_id}')
df = pd.concat(df_list).astype(str).drop_duplicates()
df.to_excel(f'{mid}.xlsx', index=False)
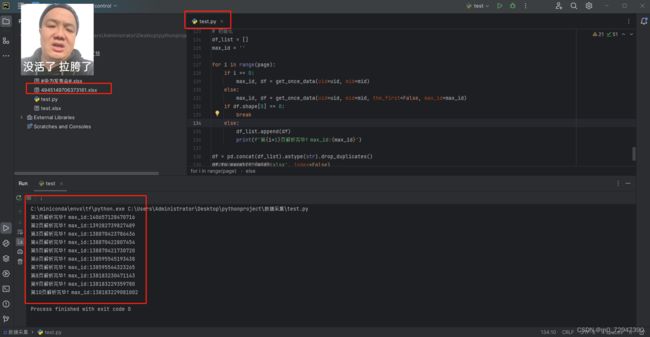
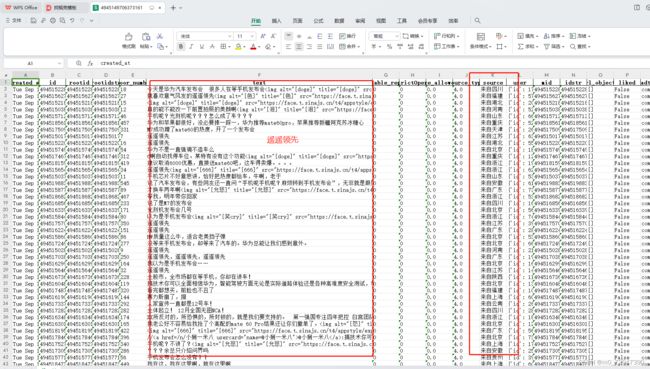
结束!
二级评论内容
二级评论的流程和一级评论一样,不同的是参数
一级评论的参数
params = {
'is_reload': '1',
'id': f'{mid}',
'is_show_bulletin': '2',
'is_mix': '0',
'count': '20',
'uid': f'{uid}',
'fetch_level': '0',
'locale': 'zh-CN',
}
二级评论的参数
params = {
'is_reload': '1',
'id': f'{mid}',
'is_show_bulletin': '2',
'is_mix': '1',
'fetch_level': '1',
'max_id': '0',
'count': '20',
'uid': f'{uid}',
'locale': 'zh-CN',
}
二级评论参数的uid指的是微博主体内容的作者uid,而mid指的是评论者的mid
完整代码如下:
import requests
import pandas as pd
import json
import os
page_num = 0
cookies = {
'SINAGLOBAL': '1278126679099.0298.1694199077980',
'SUBP': '0033WrSXqPxfM725Ws9jqgMF55529P9D9W5mzQcPEhHvorRG-l7.BSsy5JpX5KMhUgL.FoM7ehz4eo2p1h52dJLoI0qLxK-LBKBLBKMLxKnL1--L1heLxKnL1-qLBo.LxK-L1KeL1KzLxK-L1KeL1KzLxK-L1KeL1Kzt',
'XSRF-TOKEN': '47NC7wE7TMhcqfh1K-4bacK-',
'ALF': '1697384140',
'SSOLoginState': '1694792141',
'SCF': 'ApDYB6ZQHU_wHU8ItPHSso29Xu0ZRSkOOiFTBeXETNm7IJXuI95RLbWORIsozuK4Ohxs_boeOIedEcczDT3uSAI.',
'SUB': '_2A25IAAmdDeRhGeFO61AY8i_NwzyIHXVrdHxVrDV8PUNbmtAGLU74kW9NQYCXlmPtQ1DG4kl_wLzqQqkPl_Do1sZu',
'_s_tentry': 'weibo.com',
'Apache': '3760261250067.669.1694792155706',
'ULV': '1694792155740:8:8:4:3760261250067.669.1694792155706:1694767801057',
'WBPSESS': 'X5DJqu8gKpwqYSp80b4XokKvi4u4_oikBqVmvlBCHvGwXMxtKAFxIPg-LIF7foS715Sa4NttSYqzj5x2Ms5ynKVOM5I_Fsy9GECAYh38R4DQ-gq7M5XOe4y1gOUqvm1hOK60dUKvrA5hLuONCL2ing==',
}
def get_content_1(uid, mid, the_first=True, max_id=None):
headers = {
'authority': 'weibo.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'client-version': 'v2.43.32',
'referer': 'https://weibo.com/1887344341/NhAosFSL4',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'server-version': 'v2023.09.14.1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'x-requested-with': 'XMLHttpRequest',
'x-xsrf-token': '-UX-uyKz0jmzbTnlkyDEMvSO',
}
params = {
'is_reload': '1',
'id': f'{mid}',
'is_show_bulletin': '2',
'is_mix': '1',
'fetch_level': '1',
'max_id': '0',
'count': '20',
'uid': f'{uid}',
'locale': 'zh-CN',
}
if not the_first:
params['flow'] = 0
params['max_id'] = max_id
else:
pass
response = requests.get('https://weibo.com/ajax/statuses/buildComments', params=params, cookies=cookies, headers=headers)
return response
def get_content_2(get_content_1_url):
headers = {
'authority': 'weibo.com',
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'multipart/form-data; boundary=----WebKitFormBoundaryNs1Toe4Mbr8n1qXm',
'origin': 'https://weibo.com',
'referer': 'https://weibo.com/1762257041/NiSAxfmbZ',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'x-xsrf-token': 'F2EEQZrINBfzB2HPPxqTMQJ_',
}
s = '{"name":"https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4944997453660231&is_show_bulletin=2&is_mix=0&max_id=139282732792325&count=20&uid=1762257041&fetch_level=0&locale=zh-CN","entryType":"resource","startTime":20639.80000001192,"duration":563,"initiatorType":"xmlhttprequest","nextHopProtocol":"h2","renderBlockingStatus":"non-blocking","workerStart":0,"redirectStart":0,"redirectEnd":0,"fetchStart":20639.80000001192,"domainLookupStart":20639.80000001192,"domainLookupEnd":20639.80000001192,"connectStart":20639.80000001192,"secureConnectionStart":20639.80000001192,"connectEnd":20639.80000001192,"requestStart":20641.600000023842,"responseStart":21198.600000023842,"firstInterimResponseStart":0,"responseEnd":21202.80000001192,"transferSize":7374,"encodedBodySize":7074,"decodedBodySize":42581,"responseStatus":200,"serverTiming":[],"dns":0,"tcp":0,"ttfb":557,"pathname":"https://weibo.com/ajax/statuses/buildComments","speed":0}'
s = json.loads(s)
s['name'] = get_content_1_url
s = json.dumps(s)
data = f'------WebKitFormBoundaryNs1Toe4Mbr8n1qXm\r\nContent-Disposition: form-data; name="entry"\r\n\r\n{s}\r\n------WebKitFormBoundaryNs1Toe4Mbr8n1qXm\r\nContent-Disposition: form-data; name="request_id"\r\n\r\n\r\n------WebKitFormBoundaryNs1Toe4Mbr8n1qXm--\r\n'
response = requests.post('https://weibo.com/ajax/log/rum', cookies=cookies, headers=headers, data=data)
return response.text
def get_once_data(uid, mid, the_first=True, max_id=None):
respones_1 = get_content_1(uid, mid, the_first, max_id)
url = respones_1.url
response_2 = get_content_2(url)
df = pd.DataFrame(respones_1.json()['data'])
max_id = respones_1.json()['max_id']
return max_id, df
if __name__ == '__main__':
# 得到的一级评论信息
df = pd.read_csv('信息汇总.csv')
df = df[df['评论数']>0]
for i in range(df.shape[0]):
mid = df.iloc[i].mid
uid = df.iloc[i].uid
name = df.iloc[i]['话题']
page = 100
if not os.path.exists(f'./二级评论数据/{mid}-{uid}.csv'):
print(f'不存在 ./二级评论数据/{mid}-{uid}.csv')
df_list = []
max_id = ''
for j in range(page):
if j == 0:
max_id, df_ = get_once_data(uid=uid, mid=mid)
else:
max_id, df_ = get_once_data(uid=uid, mid=mid, the_first=False, max_id=max_id)
if df_.shape[0] == 0 or max_id == 0:
break
else:
df_list.append(df_)
print(f'{mid}第{j}页解析完毕!max_id:{max_id}')
if df_list:
outdf = pd.concat(df_list).astype(str).drop_duplicates()
outdf['话题'] = name
print(f'文件长度为{outdf.shape[0]},文件保存为 ./二级评论数据/{mid}-{uid}.csv')
outdf.to_csv(f'./二级评论数据/{mid}-{uid}.csv', index=False)
else:
pass
else:
print(f'存在 ./二级评论数据/{mid}-{uid}.csv')
代码运行结果

完成!