python绘制带有显著性差异的柱状图
直观认识
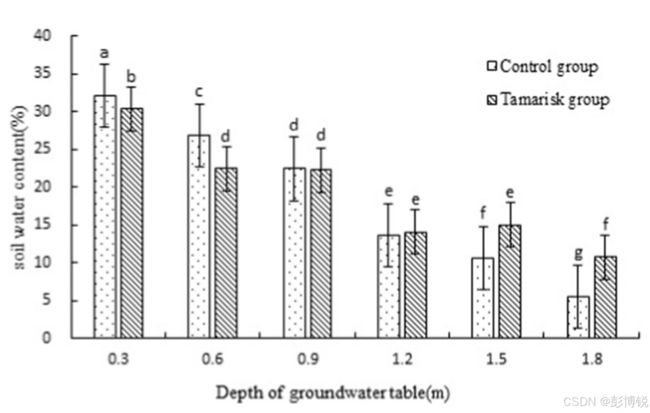
有的时候看文献会发现柱状图上标记有不同的字母,这其实是使用字母表示法来代表不同组之间的差异,不同的字母表示具有显著性的差异,相同的字母表示没有显著性差异。
图片来自文献(Li et al.,2019)
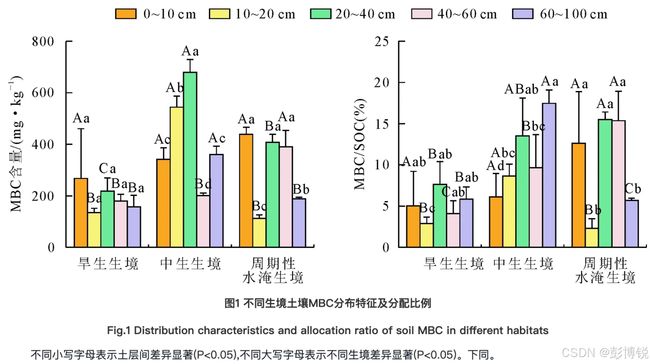
含有大小写字母的两组方差分析 参考自文献(马继龙等,2024)。
显著性差异的表示方法
常见的一般有P值、星号标记和字母标记等。
1、P值:
当P值小于或等于事先设定的显著性水平(通常是0.05)时,我们认为差异是统计显著的。
例如,如果P < 0.05,则表示差异显著;如果P < 0.01,则表示差异非常显著。
2、星号标记:
在学术论文和报告中,经常使用星号来标记显著性水平。
通常,*代表P < 0.05,**代表P < 0.01,***代表P < 0.001。
3、字母标记:字母标记法(Letter Marking Method)是一种在统计图表或表格中表明组间差异显著性的方法。它通常用于多重比较的情境,比如方差分析(ANOVA)后的多重比较测试(如Tukey’s HSD、Scheffé、LSD等)。
字母标记法的一般步骤
1、进行统计测试:首先,对数据进行适当的统计测试(如ANOVA),以确定组间是否存在显著性差异。
2、进行多重比较:如果ANOVA结果表明组间存在显著性差异,接下来进行多重比较测试,以确定哪些具体的组之间存在差异。
3、标记字母:根据多重比较的结果,对每一组数据分配一个字母。所有在统计上没有显著性差异的组会被分配相同的字母。
4、标注在图表或表格中:将分配的字母标注在图表的相应柱子上或表格的相应行或列旁边。
例子:
假设我们有三个处理组A、B、C,进行ANOVA和多重比较后得到以下结果:
组A和组B之间没有显著性差异。
组B和组C之间有显著性差异。
组A和组C之间也有显著性差异。
根据这些结果,我们可以这样标记:
组A:a
组B:a
组C:b
在图表或表格中,组A和组B旁边都会标有字母“a”,表示它们之间没有显著性差异;而组C旁边标有字母“b”,表示它与组A和组B都有显著性差异。
字母标记法直观、清晰,可以有效地在图表或表格中展示复杂的比较结果,使得读者能够快速理解哪些组之间存在显著性差异。
python实现
本次采用字母标记法来绘制带有显著性差异的柱状图。
常规的方差分析ANOVA只能识别出多个组别中(三组及以上)存在显著性差异,但不能区分具体哪两组之间存在显著性差异。可以使用事后检验(如Tukey’s HSD)来确定具体哪些组别之间存在显著差异。可参考我另一篇博客python方差分析
具体实现:
工具:借助大语言模型。
库:方差分析采用pingouin库。
思路:直接让大语言模型生成代码比较困难,所以将任务拆解。让大语言模型封装一个返回每组字母标记的函数,封装一个绘图函数。我只是给出了一个示例代码,大家可以根据自己的需求借助语言模型封装出更简洁的函数。
import pandas as pd
import pingouin as pg
from itertools import combinations
def get_tukey_letters(data, group_col, value_col):
# Perform ANOVA
anova = pg.anova(data=data, dv=value_col, between=group_col)
# Perform Tukey's HSD test
tukey = pg.pairwise_tukey(data=data, dv=value_col, between=group_col)
# Sort the Tukey results by group1 and group2
tukey = tukey.sort_values(by=['A', 'B'])
# Initialize the letter set
letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
# Create a dictionary to store the letters for each group
group_letters = {group: set() for group in data[group_col].unique()}
# Assign letters to groups based on significance
current_letter = 0
for group1, group2 in combinations(group_letters.keys(), 2):
pval = tukey.loc[(tukey['A'] == group1) & (tukey['B'] == group2), 'p-tukey'].values[0]
if pval >= 0.05:
if not group_letters[group1] & group_letters[group2]:
letter = letters[current_letter]
group_letters[group1].add(letter)
group_letters[group2].add(letter)
current_letter += 1
else:
if not group_letters[group1]:
letter = letters[current_letter]
group_letters[group1].add(letter)
current_letter += 1
if not group_letters[group2]:
letter = letters[current_letter]
group_letters[group2].add(letter)
current_letter += 1
# Convert sets to strings
group_letters = {group: ''.join(sorted(letters)) for group, letters in group_letters.items()}
return group_letters
# 示例数据
data = pd.DataFrame({
'group': ['SWC1'] * 13 + ['SWC2'] * 13 + ['SWC3'] * 13 + ['SWC4'] * 13,
'value': [3.20, 3.40, 7.00, 7.20, 7.40, 6.30, 7.00, 7.40, 7.95, 6.5, 4.85, 3.85, 6.25] +
[7.79, 7.28, 7.49, 9.08, 7.21, 7.86, 8.7, 13.84, 14.11, 9.67, 5.86, 6.45, 12.14] +
[13.4, 12.4, 5.5, 8.2, 18.6, 16.5, 14.3, 9.6, 21.2, 17.9, 12.7, 20.0, 12.2] +
[19.8, 21.9, 24.1, 25.5, 29.3, 29.3, 26.9, 24.3, 27.9, 24.5, 20.7, 15.5, 26.3]
})
# 获取显著性字母标记
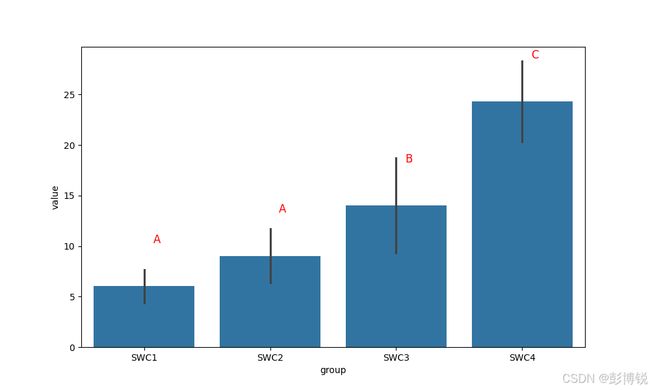
letters = get_tukey_letters(data, 'group', 'value')
print(letters)
import matplotlib.pyplot as plt
import seaborn as sns
def plot_with_significance(data, group_col, value_col, letters):
# Create the plot
plt.figure(figsize=(10, 6))
ax = sns.barplot(x=group_col, y=value_col, data=data, ci='sd')
# Add the significance letters
for i, group in enumerate(data[group_col].unique()):
y = data.loc[data[group_col] == group, value_col].mean()
ax.text(i + 0.1, y + 4.0, letters[group], ha='center', va='bottom', fontsize=12, color='red')
plt.show()
# 绘制带有显著性差异的柱状图
plot_with_significance(data, 'group', 'value', letters)
结果展示:
参考文献
Li, X., Xia, J., Zhao, X., Chen, Y., 2019. Effects of planting Tamarix chinensis on shallow soil water and salt content under different groundwater depths in the Yellow River Delta. Geoderma 335, 104–111. https://doi.org/10.1016/j.geoderma.2018.08.017
马继龙,王新英,刘茂秀,等.塔里木河中游不同生境胡杨林土壤有机碳及活性组分特征[J].西北林学院学报,2024,39(02):182-188.