编译原理:设计与实现一个简单词法分析器
设计与实现一个简单词法分析。具体内容是产生一个二元式文本文件,扩展名为dyd,可将Java或C程序(测试程序)分解成为一个一个的单词及类型。
(选做:并查“单词符号与种别对照表”得出其种别,用一数字表示。)
词法编译器基本功能包括:
(1) 输入源程序:输入C/java源程序;
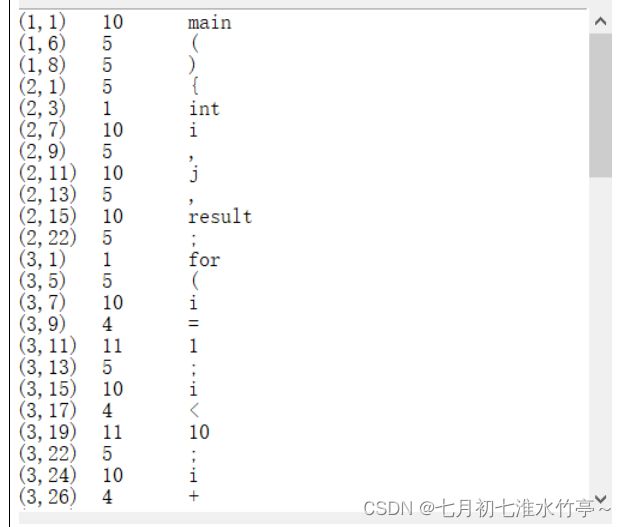
(2) 输出单词,输出形式为:(序号,类型,单词);
(3) 输出出错信息,输出形式为:(出错行号,出错列号,出错信息);
为了运行代码并进行实验,需要满足以下条件:
1.Python环境:确保计算机上安装了Python,并且可以在命令行中运行python命令。
2.输入源程序文件:创建一个名为input.java或input.c的文件,其中包含想要进行词法分析的Java/C源程序。确保源程序的语法是正确的,否则可能会导致词法分析错误。
3.下载依赖:下载需要的依赖库。
4.查看输出文件:运行成功后,将生成一个名为output.dyd的文件,其中包含了词法分析的结果,包括单词及其类型的二元式信息。
词法分析器源程序文件:(lexer.py)
import re
import tkinter as tk
from tkinter import filedialog
# 定义单词种别码
KEYWORD = 1
IDENTIFIER = 10
CONSTANT = 11
OPERATOR = 4
DELIMITER = 5
# 定义关键字列表
keywords = ["if", "int", "for", "while", "do", "return", "break", "continue"]
class LexicalAnalyzer:
def __init__(self, window):
# 窗口设置
self.window = window
self.window.title("词法分析器")
self.window.geometry("500x500")
# 顶部文件选择与运行控制区域
self.top_frame = tk.Frame(self.window)
self.top_frame.pack(side=tk.TOP, pady=10, padx=10)
# 文件选择按钮
self.select_file_button = tk.Button(self.top_frame, text="选择文件", command=self.select_file)
self.select_file_button.pack(side=tk.LEFT)
# 运行按钮
self.run_button = tk.Button(self.top_frame, text="运行", state=tk.DISABLED, command=self.run_analysis)
self.run_button.pack(side=tk.RIGHT)
# 中间的文本显示框
self.text_frame = tk.Frame(self.window)
self.text_frame.pack(pady=10)
self.scrollbar = tk.Scrollbar(self.text_frame)
self.scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
self.display_area = tk.Text(self.text_frame, wrap=tk.WORD, yscrollcommand=self.scrollbar.set)
self.display_area.pack(side=tk.LEFT, fill=tk.BOTH)
self.scrollbar.config(command=self.display_area.yview)
# 底部状态栏区域
self.status_bar = tk.Frame(self.window)
self.status_bar.pack(side=tk.BOTTOM, pady=10)
self.status_label = tk.Label(self.status_bar, text="请选择一个文件")
self.status_label.pack()
# 初始化属性
self.input_file = None
self.tokens = []
def select_file(self):
self.input_file = filedialog.askopenfilename(filetypes=[("C源程序", "*.c"), ("文本", "*.txt"), ("所有文件", "*.*")])
if self.input_file:
self.status_label.config(text=f"已选择文件:{self.input_file}")
self.run_button.config(state=tk.NORMAL)
def run_analysis(self):
if not self.input_file:
return
self.status_label.config(text="运行中,请稍候...")
self.window.update()
with open(self.input_file, 'r', encoding='utf-8') as file:
lines = file.readlines()
token_count = 0
error_count = 0
self.tokens.clear()
for line_number, line in enumerate(lines, start=1):
words = re.findall(r'[a-zA-Z_][a-zA-Z0-9_]*|\d+|&&|\|\||==|>=|<=|!=|[+\-*/=><,;(){}]', line)
column_number = 1
for word in words:
category = classify_token(word)
if category != -1:
self.tokens.append((line_number, column_number, category, word))
token_count += 1
else:
self.display_area.insert(tk.END, f'Invalid token: {word} at Line {line_number}, Column {column_number}\n')
error_count += 1
column_number += len(word) + 1
if error_count == 0:
self.status_label.config(text=f"词法分析完成,共生成 {token_count} 个二元式。")
self.display_tokens()
self.save_results() # 保存结果到文件中
else:
self.status_label.config(text=f"词法分析失败,请查看输出窗口。")
def display_tokens(self):
self.display_area.delete('1.0', tk.END)
for token in self.tokens:
line_number, column_number, category, word = token
self.display_area.insert(tk.END, f'({line_number},{column_number})\t{category}\t{word}\n')
def save_results(self):
output_file = filedialog.asksaveasfilename(defaultextension=".dyd", filetypes=[("二元式文件", "*.dyd")])
if output_file:
with open(output_file, 'w', encoding='utf-8') as file:
for token in self.tokens:
line_number, column_number, category, word = token
file.write(f"{line_number}\t{column_number}\t{category}\t{word}\n")
self.status_label.config(text=f"结果已保存至文件:{output_file}")
def show(self):
self.window.mainloop()
# 判断单词种别函数
def classify_token(word):
if word in keywords:
return KEYWORD
elif re.match(r'^[a-zA-Z_][a-zA-Z0-9_]*$', word):
return IDENTIFIER
elif re.match(r'^\d+$', word):
return CONSTANT
elif word in ['+', '-', '*', '/', '=', '>', '<', '==', '>=', '<=', '!=', '&&', '||']:
return OPERATOR
elif word in [',', ';', '(', ')', '{', '}']:
return DELIMITER
else:
return -1 # 无法分类的单词种别码
if __name__ == '__main__':
window = tk.Tk()
analyzer = LexicalAnalyzer(window)
analyzer.show()运行结果: