Leetcod面试经典150题刷题记录——数组 / 字符串篇
数组 / 字符串篇
-
- 1. 合并两个有序数组
-
- Python3
-
- 排序法
- 双指针法
- 2. 删除有序数组中的重复元素
- 3. H 指数
-
- Python3
-
- 排序法
- 计数排序法
- 二分查找
有个技巧,若想熟悉语言的写法,可以照着其它语言的题解,写目标语言的代码,比如有C/C++的题解,写Python的算法,这样同时可以对比两种语言,并熟悉Python代码中API的使用,并且可以增强代码的迁移能力,语言只是一种实现的工具,不被语言束缚也是一种自由。
1. 合并两个有序数组
合并两个有序数组 - leetcode
题目描述:
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
解题思路:
(1) 排序法。将nums2添加至nums1并排序,但这样的做法未利用到nums1与nums2非递减的特性,时间复杂度是排序的时间复杂度 O ( ( m + n ) l o g 2 ( m + n ) ) O((m+n)log_2(m+n)) O((m+n)log2(m+n)),空间复杂度认为是快排的空间复杂度 O ( l o g 2 ( m + n ) ) O(log_2(m+n)) O(log2(m+n))
(2) 双指针法。新建一个数组sorted用来存储,然后将nums1指向新数组的内容,用双指针比较nums1和nums2各元素的大小,存储至sorted数组中
Python3
排序法
class Solution:
def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:
"""
Do not return anything, modify nums1 in-place instead.
"""
nums1[m:] = nums2
nums1.sort()
双指针法
class Solution:
def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:
"""
Do not return anything, modify nums1 in-place instead.
"""
p1, p2 = 0,0
index_bound1, index_bound2 = m-1,n-1 # 数组下标索引边界,这和长度有区别
sorted = []
while p1 <= index_bound1 or p2 <= index_bound2:
# 1.若有某一数组下标出界,表明该数组已判断完成,应存另一数组的值
if p1 > index_bound1:
sorted.append(nums2[p2])
p2 += 1
elif p2 > index_bound2:
sorted.append(nums1[p1])
p1 += 1
# 2.比较两数大小,存更小的,以确保是非递减序列
elif (nums1[p1] <= nums2[p2]):
sorted.append(nums1[p1])
p1 += 1
else:
sorted.append(nums2[p2])
p2 += 1
nums1[:] = sorted
2. 删除有序数组中的重复元素
题目描述:
给你一个 非严格递增排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。
考虑 nums 的唯一元素的数量为 k ,你需要做以下事情确保你的题解可以被通过:
更改数组 nums ,使 nums 的前 k 个元素包含唯一元素,并按照它们最初在 nums 中出现的顺序排列。nums 的其余元素与 nums 的大小不重要。
返回 k 。
题目归纳:
首先分析该有序数组的特点
由于数组有序,且非严格递增
故对于任意 i < j,若有nums[i] = nums[j]
则有任意i <= k <= j,nums[i] = nums[k] = nums[j]
利用上述特点,使用快慢指针进行删除重复元素
解题思路:
快慢指针法。慢指针用来指向第一个(可能)遇到重复元素的位置处,而快指针寻找新元素,当快指针找到新元素,把新元素赋值给慢指针处做替换。
class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
slow_p = 1 # 数组若只有一个元素,则下标为0, 这样的数组中不会有重复项
for fast_p in range(1, len(nums), 1):
if(nums[fast_p-1] != nums[fast_p]): # 快指针找到新元素,利用了任意i <= k <= j,nums[i] = nums[k] = nums[j]特性
nums[slow_p] = nums[fast_p]
slow_p += 1 # slow_p的增加是有条件的,要找到不相同的元素
return slow_p
3. H 指数
题目描述:
给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。
根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数是指,他(她)至少发表了 h 篇论文,并且每篇论文至少被引用了 h 次。如果该 h 有多种可能的值,h 指数是最大的那个。
题目归纳:
H-index Wiki,我想,h 指数的基本思想是:论文发的越多,不一定代表水平越高,而是发的越多,也要引用的越多才行,引用数认为是质,发表数认为是量,即有质有量 h 指数才高,可以看出原始的 h 指数有个缺点,如果论文发的少引用的多,h 指数也不会很高,也就是有质无量的 h 指数低,无质无量,无质有量自然就更低了,这里把两个量的量纲统一了,就得到了下面的图。
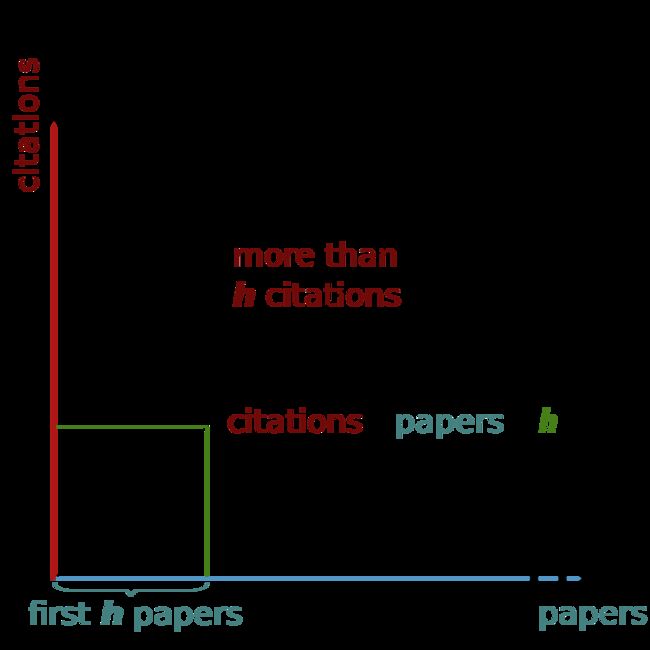
解题思路:
(1) 排序法。将数组citations从高到底排列,h不断增加,直到引用数 h 无法增大,则返回 h 。对应上图,就是寻找到虚线和数据分布的“分界点”,在papers(citations)坐标轴上的值。
(2) 计数排序法。
Python3
排序法
时间复杂度: O ( n l o g 2 n ) O(nlog_{2}{n}) O(nlog2n), n n n为数组citations长度
空间复杂度: O ( l o g 2 n ) O(log_{2}{n}) O(log2n), n n n为数组citations长度
class Solution:
def hIndex(self, citations: List[int]) -> int:
sorted_citation = sorted(citations, reverse = True)
# python里可以用分号在一行中分割语句,曾经python为了阅读的简便性,抛弃了分号,现在又拿回来了,会不会有一天,这些语言来一个大一统,赋值号居然还有:=,=这两种写法,想出:=的人我很好奇他个人的精神状态
h = 0; i = 0; n = len(citations)
while i < n and sorted_citation[i] > h:
h += 1
i += 1
return h
计数排序法
【排序算法】计数排序 - bilibili
计数排序是一种非比较排序,比较排序的复杂度下限是O(nlogn)已经得到过论文证明。
class Solution:
def hIndex(self, citations: List[int]) -> int:
# 新建并维护一个数组citation_papers,来记录当前引用次数的论文有多少篇
# 对于论文i引用次数citations[i]超过论文发表数len(citations)的情况,将其按总论文发表数len(citations)计算即可,这样排序的数的大小范围就可以降低至[0,n=len(citations)]
# 从而计数排序的时间复杂度,就降低至O(n)。现实中,一个学者一辈子能发表的论文数量顶天了也就百来篇,再夸张点,一千篇,不需要考虑n是无穷增长的,这点大小对计数排序是恰到好处的,因为计数排序就适合范围不大的排序。
n = len(citations); H_papers = 0 # H_papers: 符合H指数的论文数
citation_papers = [0] * (n+1) # 生成计数排序数组,用到了python的扩充操作,此数组下标为citation,数组内容为paper数量
# 计算计数排序数组
for c in citations:
if c >= n: # 引用次数超过论文发表数,引用次数按发表论文数计算
citation_papers[n] += 1
else:
citation_papers[c] += 1
# 倒序遍历
for citation in range(n, -1, -1): # (-1, n] step = -1,实际上的下标范围即[0,n]
H_papers += citation_papers[citation]
if citation <= H_papers:
return citation
return 0