达达集团智能弹性伸缩架构的设计与落地实践
文章来源:架构头条,嘉宾 | 杨森,编辑 | 李忠良
面对节假日常规促销、618/ 双 11 购物节等配送业务订单量的暴增,达达集团通过智能弹性伸缩架构和精细化的容量管理,有效地做到了业务系统对配送全链路履约和服务体验的保驾护航。在 2021 年 4 月 25 日 ArchSummit 全球架构师峰会(上海站)上,达达集团云平台 DevOps & SRE 负责人杨森,发表了以《左手 VM ,右手 Container Serverless ,云原生智能弹性伸缩架构和实践》主题分享,希望对正在进行弹性扩缩容的你有所启发。本文为演讲内容整理。
大家好,我是杨森,2019 年加入达达集团,目前负责 DevOps 和 SRE 两个团队,日常工作专注于分布式系统的稳定性和观察性以及容量、容器架构等。今天分享的主题是弹性容量。
首先介绍一下达达集团,达达集团去年在纳斯达克上市,目前有两个业务线,达达快送和京东集团的京东到家。去年达达快送共有 11 亿的包裹量,每天有数十万的骑士来配送,配送范围覆盖全国 2700 个城市,单日峰值大概近千万。
1架构设计——故障驱动
达达决定做弹性扩缩容,是由故障引发的。时间回到 2019 年的 8 月 7 号,那天是七夕节,当时鲜花单量比较多,大概在上午 9:20 的时候,线上已经出现问题,鲜花的派送需要优质的骑士,但是当时优质的骑士不多。在九点多的时候,已经有一定程度的单量积压。
算法工程师先后扩展了 A、B 算法派单的服务,结果这两个服务扩容之后,它以高于 N 倍的日常力量请求了 C 服务,结果把 C 服务 CPU 打爆了。
这时候,大家开始联系运维,耗费了 19 分钟运维上线,但是上线之后仅仅扩容了两台,并且还失败了一台。这个时候,这一台的失败是压死骆驼的最后一根稻草。
整个 C 服务对内、对外的响应都开始变得糟糕,整个 CPU 使用率已经达到了百分之九十几,业务已经开始受损,接下来运维只能依靠手工扩展了 X 台,然后又全部失败了,最后又花了 11 分钟手动拉起这些服务,这才解决整个问题。整个过程非常糟糕。
痛定思痛,达达决定解决这个问题。这次故障给达达带来了以下两方面的思考。
第一,当线上遇到问题的时候,应该扩容哪些服务?什么时间点?扩容多少?需要多少时间?
第二,对于节日促销,如果没有压测的话,怎样做容量评估?
显然如果有了弹性,似乎可以解决这两个问题。
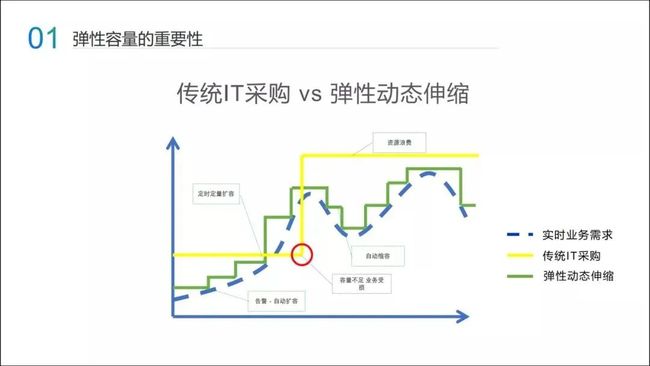
在这张图中,黄色这条线是传统的 IT 采购流程,不过这根线的结果和预期有偏差,常常导致在红色的圆圈的时候,我们才联系去扩容,那个时候业务已经受损了。扩容上去之后,真实业务量下来了,资源又是浪费的。
这显然并不是大家希望的,我们希望的系统容量是图中绿色这条线。它可以随着业务的需求变化,业务量上涨的时候直接扩容上去,业务量下来的时候,可以把成本相应地降低。
2万事开头难——扩缩容初探
从简单的地方先做起来,是我们的策略。
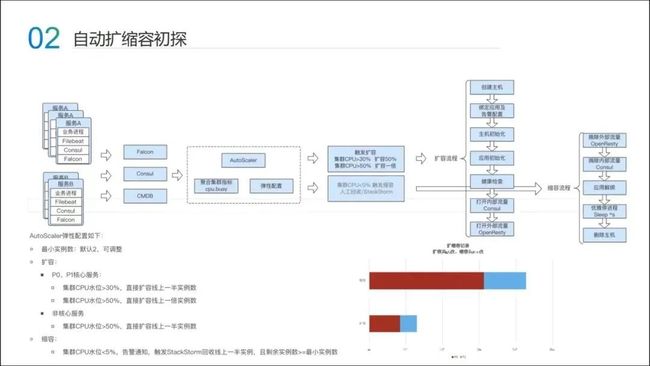
大概花了一两个月的时间,我们先进行了扩容。实际过程很简单,我们很好地利用了 CPU 指标。CPU 打爆了,就观察 CPU 的指标,观察每个服务的集群指标,我们开发了 AutoScaler 的弹性系统。
根据这个指标,达达制定了一些简单粗暴的规则。例如核心服务,当它的集群 CPU 水位大于 30%,直接扩容一半,如果它大于 50%,直接扩容一倍,这个方案似乎是可以解决这个问题的。
第一版上线,扩容可以直接自动完成。整个过程非常简单——输入、决策与执行。
不过上线第一版之后,我们意外地发现,并不是所有的线上服务都需要立马扩容,大部分服务的容量是冗余的,从上图右下部分,我们可以看到,红色的部分显示的缩容比正常的扩容要多。由此可以发现,我们对容量管控还没有做到精细化。
这样的做法显然不足够好。业务指标方面,仅仅考虑了单个 CPU 的指标,其他指标完全缺失,另外当前这个系统非常不够灵活,显然这不是很好的弹性系统。
怎么样做的更好?什么样的架构是更好的弹性架构呢?先来思考一个问题:我们做弹性扩缩容,为了解决什么问题?
实际上我们是因为线上业务的供需匹配关系发生了变化。就达达具体的场景来讲,在同城配送线上的订单量和当前运力的匹配关系下,同时又要做到对业务稳定性负责;对即时体验以及对商家履约的保证情况下,底层业务系统、相关组件的容量能否承担业务的需求。
3跨界思考——自动驾驶与弹性伸缩

我们在思考弹性伸缩时,常常会类比自动驾驶。汽车自动驾驶的时候,每时每刻路况都不一样,它需要有很多输入源,不管是激光雷达、红外线还是高精地图,同时它对这些数据进行融合,然后加上自己的决策,所以说自动驾驶系统一定有决策层和执行层。
对于做弹性伸缩,其实也是类似的。CPU 不是唯一的指标,还有其他的指标——单机的 PDS、对业务响应的时长、熔断报错日志等,这些都可以作为输入源。感知层是这些数据库,这些数据库存储在线上业务的一些系统;
决策层,AutoScaler 需要对这些数据做融合,然后配置一些规则。
最后是执行层,对于执行层面,我们适配了不同的环境。像自动驾驶一样,自动驾驶有汽油车、燃油车、混动以及新能源,对应再弹性伸缩的执行层面,有虚机、容器以及 Severless Pod 等,在执行层面,我们做了很多适配的工作。
总的来讲,整个从自动驾驶到弹性伸缩的过程,达达进行了相应的思考——感知、决策与执行。
4弹性架构——感知、决策与执行
接下来,我会详细地介绍 AutoScaler 在感知、决策及执行过程,都做了哪些工作?

首先是感知层面,我们如何了解业务是否有突增和离群?
很多时候是监控系统承担了这样的工作。在实际的工作中,我们不管机器某个服务的实例数量以及 CPU Memory Disk Network 有没有突增,甚至包括错误的日志(熔断、相应的 Exception ),我们把所有的业务监控数据做一层聚合,统一转换格式为 Open TSDB ,然后生成 metric。
右侧下方这张图很简单,我们把单一服务分成了不同的 Group,每个 Group 有集群 CPU 的一些指标,这是我们进行的一些聚合,我们做到了业务线的分流。这是感知层,我们汇聚了这些观测指标,统一成 Open TSDB。当然这个指标可以通过 SQL 进行用户自定义。
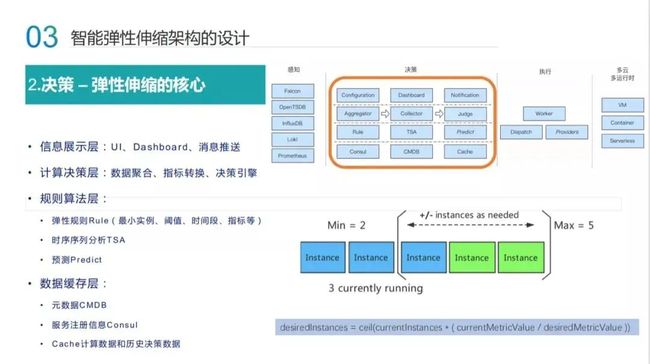
第二层决策层,架构共分为了四层。
最上面是信息展示层,用户可以自定义配置弹性规则和观看弹性每日报表,包括实时消息通知;
第二层是决策执行层,这层分为聚合层,信息收集层以及决策层,主要做数据聚合、格式转换、结合弹性的策略做执行;
第三层是规则算法层,规则应该是怎么样去配置?如何做时序序列的分析以及做预测等;
最后一层是线上业务的数据,Consul 结合 CMDB 服务元数据,供 Aggregator 和 Collector 计算和生产 metric ,还有一些数据环境层,它会保留历史的决策数据辅助下一次决策下发和算法预测。
前几天网友还问我:“你开发的系统是不是过于复杂,你仅仅比 K8S 的 HPA (容器水平伸缩)增加了一些指标而已”。
的确是这样的,但是我做这个架构,它是在没有 K8s 完全式生产情况下,并且对弹性有苛刻需求的情况下做出来的。它是做了统一化,不同的指标,当然它的核心算法确实是 HPA 。

如果大家了解 HPA,一定可以看懂上图。上图显示,现在有正在运行的三个实例,然后最小实例数需要保证两个。弹性的公式也很简单。比如现在线上有 4 台机器,它的 CPU 使用率是 50%,现在 4×50%,那就是算力是 200%。但是如果规定服务 CPU 大于 40% 就要扩容,这样的话 200% 除以 40% ,其实就是 5 台机器,那就需要增量的一台机器,也就是这个公式所表达的。
不过我将所有的指标都转换成相应的格式,然后通过这个公式做计算,并且可以多指标做计算。这就是今天做的弹性和 HPA 不一样的地方。
我们整个弹性扩缩容平台配有统一的面板,研发可以自助配置它相应的服务。例如,是否需要自动扩容打开、是否需要将极限送容打开,以及相应的时间段、相应的云、相应的链路以及它的指标是 CPU 还是某个队列,都可以在这个地方配置。整个自动扩缩容的面板,研发可以自助配置,配置之后可以立刻生效,非常方便。
第三是执行层面,执行层面相对容易。

第一,当需要扩容的时候,需要做到单个服务的扩容,也要做到单个业务线上下游链路的同时扩容。我们在 Worker 设置了两个模块——Despatch 和 Providers。
Despatch 把服务能并行地扩容,保证它的幂等性,以及缩容的时候配有一些保护机制。Providers 统一了扩缩容的接口,然后适配了不同的发布系统。例如自行开发的 Deployng、Tars、K8s,还有云厂商的 Severless,这是在这层做了一层对接。

为大家展示一下弹性伸缩架构的实际运行情况,最左边这张图是扩缩容情况展示,这里有消息通知机制;中间这张图,线上扩缩容的每日报表会发到每一位研发 Leader;右下角这张图是真实的服务扩缩容,我们从最后一张图可以看出,业务在 11 点的时候开始抖动,达达扩容的实例数与上升趋势拟合得较好,准确地捕捉到了业务量的抖动。
5架构演练——弹性扩缩容演练
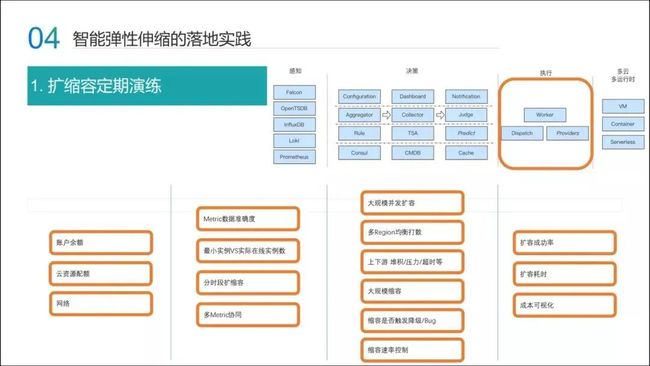
弹性系统需要保证全自动运行,所以我们会定期做一些弹性扩缩容演练。接下来与大家分享扩缩容时候遇到的一些问题。
第一,当你扩缩容的时候,肯定不是只有几个服务扩缩容,可能是批量地进行扩缩容,然后去验证上下游扩容的系统是否 OK。这其中的问题是——你有没有足够的钱影响到限额?其次是扩缩容会带来内部流量的突增,这会不会对其他业务有影响?
第二,针对弹性本身,Metric 的收集和聚合的数据是否准确?观测的指标是最重要的,但是它的准确度要保证的;同时它的最小实例数、在线实例数,这是两个问题——真实的场景中,我把服务扩进去的,我会把机器绑到了应用组里,但事实上,他没有对线上服务做承接流量,它仍然是占了一个名额,这种情况其实它是扩容是失败的。这个时候我们的最小实例数定位是真正在线上为业务服务的机器。
第三,分时段扩容,比如说 6 点到 10 点之间是白天的高峰期,然后晚上 10 点到早上的 6 点是低峰期,我可以做极限缩容。但是它会带来另外的问题——多 Metric 的协同,当多个规则在一起的时候,可能需要注意这些规则逻辑上是否正确。
网上有个段子——程序员的老婆吩咐程序员下班的时候,去购买 10 个包子,如果看到卖西瓜的就买一个,结果程序员就买了一个包子回家。这背后就是一个多 Metric 协同,这样的结果肯定是不合理的。弹性也是这样,设置多 Metric 时候,一定要考虑它的合理性。如果设置不合理,常常会因为逻辑没有达成一致,而导致频繁地扩缩容。
第四,大规模扩缩容演练需要考虑到机器多 Region 均衡打散。全扩容到一个区了,另外一个区域却很少,这是不合理的;同时在缩容的时候,不能把机器缩容到只有一个 Region,其他的没有,这样做无法保证高可用。
第五,如果扩缩容规模很大的话,需要注意对其他组件的依赖。比如 DB 缓存是不是有流量的压力,因为在达达的业务场景里面,有很多缓存是多个业务资源共享。这时候要注意一下 Redis 是否会有一些流量的突增,会导致其他业务受损。包括还有 DB 的连接数一定要确认好,一定和业务确认好哪些事需要提前完成。
第六,在缩容的时候常常会触发一些 Bug。一些服务的 IP 写死,会导致业务直接报错。
第七,缩容速率,缩容并没有立马就缩小下来,而是一条缓慢的下降曲线,这个地方是有策略的。因为如果接下来迎来流量高峰的话,扩容可能会出问题,我们做了一种折中的考量——缩容的时候必须得慢一些,达达加入了缩容速率,缩容速率是刚才扩缩容的个数再乘一个比例。
弹性系统,达达内部叫弹性降本项目,我们做弹性还有另一个目的——降本。所以在降本方面给大家提供一些经验。扩容成功率、扩容耗时以及成本的可视化,可以作为核心的指标来跟踪弹性带来的效果和收益。

针对弹性,我们做了很多指标。核心指标主要有扩容和扩容成功率以及成本可视化。
扩容成功率,扩容时长是必须要保障的。成本方面,针对单个应用,我们根据不同的原因、不同的厂商以及不同的部门,计算出来耗费的成本,并且做到追踪。针对部门,达达也会做到每个服务做排行,当前的资产负债情况;应用级别以及部门级别均可以做到成本的可追踪,这样可以衡量弹性扩缩容的效果。
最后是极限缩容,为了降低成本,肯定要做到一定的平衡。极限缩容是为了达成容量和成本之间的平衡的桥梁。达到派送业务有时间效应,晚上的时候比较空闲。达达极限缩容的时间是晚上 10 点到早上 6 点之间,只保留两台机器;早上 6:00~10:00 之间,它的最小数是 12 台机器,因此晚上可以降低一定的成本。
但是进行极限缩容必须非常谨慎,我们必须确保在早上 6 点的时候必须扩容 10 台上来,否则的话,业务可能会有一些问题。为了做到这一点,达达必须要保证扩容成功率是百分百。
6弹性降本——极限缩容

这里带大家看看达达是如何拆分扩容成功率的。
首先把扩容的流程每一步做梳理,同时对每一步进行优化。比如,环境初始化固定到镜像里面,然后做镜像加速;甚至把服务拉上线之后,做一些预 ping,防止一上来就报错;还会有接口的一些预热,但是这时候仍然在 VM 情况下是保证不了百分百成功的,然后我们又引入了 K8s 和 Serverless 的一些安全容器。
安全容器方面,达达除了使用虚机之外,还使用了很多产品。那么怎么样保证事情能在多个环境下运行?
在真实的场景下,首先服务发现需要全网打通的,在 IP 层面要打 Ping;其次,和 VM 的标准化需要统一,简单来讲就是多进程的管理。
我们的服务是依赖于 Cousul 进程,只有 Cousul 进程先行起来,服务才能再起来。真实的场景是这样——刚开始是基于 Dumb 写了个 Sheele 脚本,但是这样做不好进程、子进程的管理,后来基于 CSMD 的原理,然后用 C 语言写了 entrypoint,可以去支持服务前后依赖顺序的启动和节点筛选。
后来又用 Golang 写了 Dinit,这样可以很好地管控容器以及副容器运行,保证了在 VM 肯定的 Severless 上面可以正常地运行。
同时我们还做到了原地重启,因为 K8s Pod 它是不支持服务原地重启的,然后我们自己在 Dinit 层做了一次重启,可以很好地支持原地重启,这里面用到了 VM、以及 VM 上面装 Docker 这种形式以及包括 Severless 也用了 Firecracker 与 Kata 这两种。
还有 Dinit 进行了一个配置。
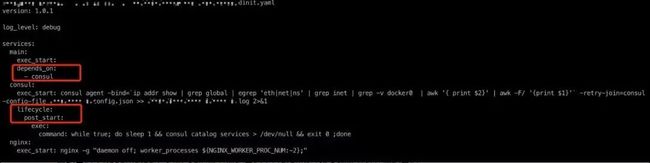
首先,服务有一些进程依赖,我们做了简单的一些语法。比如 main: excu_start 是它的主进程,但是它要依赖于 Consul 进程,Consul 进程的启动命令是 Consul 里面做执行,但是 Consul 有 post_start check,Consul 是不是真正地用到集群里?K8s 里边会有 life cycle,life cycle 里面会有一些 post_start、pre_stop 这个动作,但这不是很灵活。我们类似地做这种事,可以支持 post_start、pre_start,可以做到进程层面的管理。

在我们的发布平台上,研发可以看到,比如这次服务有虚机,同时它有两个在运行的 Pod,达达在发布层面也做了统一适配,对于研发来讲,它发布的每个版本或回归版本或者重启两个版本,操作是一模一样的。
这是简单的发布平台,它支持多个云原生,因为我们做到了 Dinit 的多进程管理,所以我们能够做到流程的统一化。这其中的问题是 VM 无法保证百分百地缩容,因此我们引入了一些东西。

第一种,正常 VM 发布脚本基于 Ansible playbook 做的,同时 Severless Pod,如果把 SSD 集群建立起来,也可以当做去用。
第二种,虚机上装配 Docker,算法基本上全是这样做。
第三种, K8s 以及云厂商的 Severless 都支持 K8s 的 Pod 这种方式,通过统一的模板做这个事情,这边做了一些初始化的操作。比如升级一些版本,通过 Volumes 共享,通过 Dinit 方式控制整个流量。
所有的这些安全容器,它背后都是两个开源技术——Firecracker 和 Kata,当然还有 Google 的 gVisor,对于 Kata 其实云厂商都有弹性实力,它其实就是托管的 K8s,然后以安全的、具备容器速度的、又有 VM 层面隔离的这些容器实例,可以直接扩容。
另外一种支线是 AWS 的 Firegate 以及 Ucloud,这些都是基于 Firecrackers 去做的。如果大家没有上容器,但是需要容器速度的话,这可能是比较好的方式。
7总结与展望

总结一下,图中从左到右是整个问题的拆解,从业务的订单量和运力以及对服务承载的承诺,我们需要对系统的容量做评估,然后把这个问题的分析拆解成汇聚 Metrix,然后传递给弹性系统,系统需要感知到这些变化,以及相应的策略的配置,最终触发执行。在执行层面,为了保证扩容百分百,引入了很多技术,做到了这些扩容和缩容的流程的统一。总体来讲,这个过程是从上至下的思考、从下至上的执行。
最后展望未来,这个系统是在 2019 年开发的,目前已经稳定运行了 20 多个月,有将近 18000 次的扩缩容记录。整个系统也对接了多种云原生,包括全程全自动的,当然也做到了双云的支持。但是还有很多值得探索的地方,比如以下两方面。
第一,引入 Facebook 的框架,结合历史数据进行预测,目前带宽已经做到 20% 的成本降低了。
第二,在 TSA 这块进行优化。目前我们只是做时序的分析,并没有对一些异常点做检出,之后会在这方面下功夫。
今天的分享就到这里,感谢大家。
嘉宾介绍:
杨森:现就职于达达集团云平台部,负责 DevOps 团队和 SRE 团队,专注于提升分布式系统的稳定性和可观测性、容量弹性、故障自愈、多云容器架构及效能平台建设。曾供职于朗讯、英特尔、众安保险等公司。