DINO-DETR论文学习记录
摘要
我们介绍了DINO(带有改进的去噪器box的DETR),一种最先进的端到端对象检测器。DINO 通过使用对比方式进行去噪训练、混合查询选择方法进行锚点初始化以及用于框预测的ook forward twice方案,在性能和效率方面比以前的类似 DETR 模型有所改进。DINO在COCO上实现了12个时期的49.4AP,在24个时期内实现了51.3AP,具有ResNet-50骨干和多尺度特征,与之前最好的类似DETR的模型DN-DETR相比,分别产生了+6.0AP和+2.7AP的显着改善。DINO 在模型大小和数据大小方面都具有良好的扩展性。在没有花里胡哨的情况下,在使用SwinL主干对Objects365数据集进行预训练后,DINO在COCO val2017(63.2AP)和test-dev(63.3AP)上都获得了最佳结果。与排行榜上的其他模型相比,DINO 显著减小了其模型大小和预训练数据大小,同时获得了更好的结果。我们的代码将在https://github.com/IDEACVR/DINO 提供。
1 介绍
对象检测是计算机视觉中的一项基本任务。基于卷积的经典目标检测算法取得了显著进展。尽管此类算法通常包括手动设计的组件,如锚点生成和非最大抑制 (NMS),但它们会产生最好的检测模型,例如 DyHead [7]、Swin [23] 和 SwinV2 [22] 以及 HTC++ [4],如 COCO 测试开发排行榜所示:
与传统的检测算法相比,DETR [3] 是一种新颖的基于Transformer的检测算法。它消除了对手工设计组件的需求,并实现了与优化的经典探测器(如 Faster RCNN [31] )相当的性能。与以前的检测器不同,DETR将目标检测建模为集合预测任务,并通过二分图匹配分配标签。它利用可学习的查询来探测对象的存在,并组合图像特征图中的特征,其行为类似于软ROI池化[21]。
尽管性能有希望,但 DETR 的训练收敛速度很慢,查询的含义也不清楚。为了解决这些问题,已经提出了许多方法,例如引入可变形注意力[41],解耦位置和内容信息[25],提供空间先验[11,39,37]等。最近,DAB-DETR [21] 提出将 DETR 查询表述为动态锚盒 (DAB),这弥合了经典的基于锚的检测器和类似 DETR 的检测器之间的差距。DN-DETR [17] 通过引入去噪 (DN) 技术进一步解决了二分匹配的不稳定性。DAB 和 DN 的结合使类似 DETR 的模型在训练效率和推理性能方面都与经典检测器竞争。
目前最好的检测模型是基于改进的经典探测器,如DyHead [8]和HTC [4]。例如,SwinV2 [22] 中呈现的最佳结果是使用 HTC++ [4,23] 框架进行训练的。造成这种现象的主要原因有两个:1)以前的类似DETR的模型不如改进的经典探测器。大多数经典探测器都经过充分研究和高度优化,与新开发的类似DETR的模型相比,性能更好。例如,如今性能最好的类似 DETR 的模型在 COCO 上仍低于 50 AP。2)类DETR模型的可扩展性尚未得到很好的研究。没有关于类似 DETR 的模型在扩展到大型主干和大规模数据集时如何执行的报告结果。我们旨在在本文中解决这两个问题。
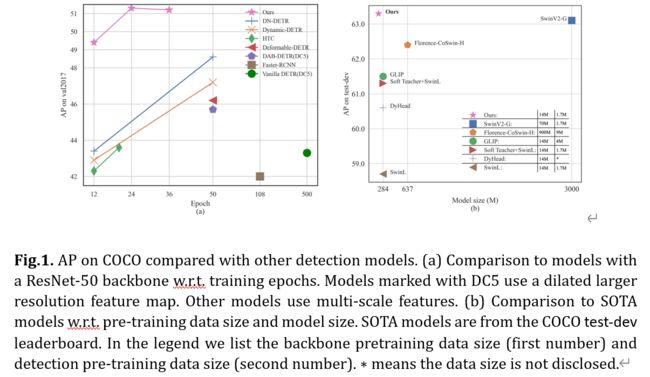
具体来说,通过改进去噪训练、查询初始化和框预测,我们设计了一个基于 DN-DETR [17]、DAB-DETR [21] 和可变形 DETR [41] 的类似 DETR 的新模型。我们将我们的模型命名为 DINO(带有改进的去噪 anchOr 框的 DETR)。如图1所示。对COCO的比较显示了DINO的优越性能。特别是,DINO展示了出色的可扩展性,在COCO测试开发排行榜上创造了63.3 AP的新记录[1]
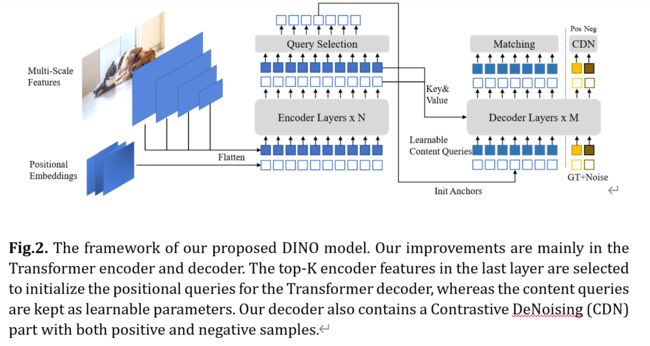
作为一个类似DETR的模型,DINO包含一个主干网、一个多层Transformer编码器、一个多层Transformer解码器和多个预测头。遵循 DAB-DETR [21],我们将解码器中的查询表述为动态锚框,并跨解码器层逐步优化它们。在 DN-DETR [17] 之后,我们将真实标签和带有噪声的框添加到转换器解码器层中,以帮助在训练期间稳定二分匹配。我们还采用了可变形注意力[41]的计算效率。此外,我们提出了以下三种新方法。首先,为了改善一对一匹配,我们提出了一种对比去噪训练,方法是同时添加相同地面事实的正样本和负样本。在将两个不同的噪声添加到同一个真实方框后,我们将噪声较小的框标记为正,另一个标记为负。对比去噪训练有助于模型避免同一目标的重复输出。其次,查询的动态锚框公式将类DETR模型与经典的两阶段模型联系起来。因此,我们提出了一种混合查询选择方法,这有助于更好地初始化查询。我们从编码器的输出中选择初始锚框作为位置查询,类似于 [41,39]。但是,我们像以前一样使内容查询可学习,鼓励第一个解码器层专注于空间先验。第三,为了利用后几层的细化box信息来帮助优化其相邻早期层的参数,我们提出了一种新的look forward twice方案,以修正后期层梯度的更新参数。
我们通过对COCO [20]检测基准的广泛实验来验证DINO的有效性。如图所示。1、DINO在ResNet-50和多尺度特征下,在12个时期内达到49.4AP,在24个时期内达到51.3AP,与之前最好的DETR类模型相比,分别产生了+6.0AP和+2.7AP的显着提高。此外,DINO 在模型大小和数据大小方面都能很好地扩展。在具有SwinL [23]主干的Objects365 [33]数据集上进行预训练后,DINO在COCO val2017(63.2AP)和测试开发(63.3AP)基准测试中都取得了最佳结果,如表 3 所示。与排行榜 [1] 上的其他模型相比,与 SwinV2-G [22] 相比,我们将模型大小减小到 1/15。与Florence [40]相比,我们将预训练检测数据集减少到1/5,将骨干预训练数据集减少到1/60,同时取得了更好的结果。
我们总结我们的贡献如下。
- 我们设计了一种新的端到端类似DETR的对象检测器,具有几种新技术,包括对比DN训练,混合查询选择,并针对DINO模型的不同部分进行了look forward twice。
- 我们进行了密集的消融研究,以验证DINO中不同设计选择的有效性。因此,DINO通过ResNet-50和多尺度功能在12个时期内实现了49.4AP,在24个时期内实现了51.3AP,明显优于以前最好的类似DETR的模型。特别是,在12个时期训练的DINO在小物体上显示出更显着的改进,产生了+7.5AP的改进。
- 我们表明,在没有花里胡哨的情况下,DINO可以在公共基准测试中实现最佳性能。在使用 SwinL [23] 主干对 Objects365 [33] 数据集进行预训练后,DINO 在 COCO val2017 (63.2AP) 和测试开(63.3AP) 基准测试中都取得了最佳结果。据我们所知,这是端到端变压器检测器首次在COCO排行榜上优于最先进的(SOTA)模型[1]。
2 相关工作
2.1 经典目标检测器
早期基于卷积的对象检测器是基于手工制作的锚点或参考点的两阶段或单阶段模型。两阶段模型[30,13]通常使用区域建议网络(RPN)[30]来提出潜在的box,然后在第二阶段对其进行细化。YOLO v2 [28] 和 YOLO v3 [29] 等单阶段模型直接输出相对于预定义锚点的偏移量。最近,一些基于卷积的模型,如HTC++ [4]和Dyhead [7],在COCO 2017数据集[20]上取得了最佳性能。然而,基于卷积的模型的性能取决于它们生成锚点的方式。此外,他们需要像NMS这样的手工设计的组件来删除重复的盒子,因此无法执行端到端的优化。
2.2 DETR及其变体
Carion等人[3]提出了一种基于变压器的端到端对象检测器,名为DETR(DEtection TRansformer),而无需使用锚点设计和NMS等手工设计的组件。许多后续论文试图解决解码器交叉注意力引入的DETR训练收敛缓慢的问题。例如,Sun等人[34]设计了一个仅编码器的DETR,而不使用解码器。Dai 等人 [7] 提出了一种动态解码器,从多个特征级别关注重要区域。
另一条工作线是更深入地理解 DETR 中的解码器查询。许多论文从不同的角度将查询与空间位置联系起来。Deformable DETR [41]预测2D锚点并设计一个可变形注意力模块,该模块仅关注参考点周围的某些采样点。Efficient DETR [39] 从编码器的密集预测中选择前 K 个位置,以增强解码器查询。DAB-DETR [21] 进一步将 2D 锚点扩展到 4D 锚框坐标,以表示查询并动态更新每个解码器层中的框。最近,DN-DETR [17] 引入了一种降噪训练方法来加速 DETR 训练。它将噪声添加的地面实况标签和框输入解码器,并训练模型以重建原始标签和框。本文对DINO的工作基于DAB-DETR和DN-DETR,并且由于其计算效率也采用了可变形注意力。
2.3 针对目标检测的大规模预训练
大规模的预训练对自然语言处理[10]和计算机视觉[27]都产生了重大影响。如今,性能最好的检测器大多是通过在大规模数据上预先训练的大型骨干来实现的。例如,Swin V2 [22] 将其主干大小扩展到 30 亿个参数,并使用 70M 私人收集的图像预训练其模型。Florence [40] 首先用 900M 私人策划的图像文本对预训练其主干,然后用带有注释或伪框的 9M 图像预训练其探测器。相比之下,DINO仅通过公开可用的SwinL [23]主干和公共数据集Objects365 [33](1.7M注释图像)来实现SOTA结果。
3 DINO:带有改进的去噪anchor的 DETR
3.1 前言
正如在Conditional DETR [25] 和 DAB-DETR [21] 中所研究的,很明显,DETR [3] 中的查询由两部分组成:位置部分和内容部分(位置编码与content query),在本文中称为位置查询和内容查询。DAB-DETR [21] 显式地将 DETR 中的每个位置查询表述为 4D 锚框 (x,y,w,h),其中 x 和 y 是框的中心坐标,w 和 h 对应于其宽度和高度。这种显式锚框公式使得在解码器中逐层动态优化锚框变得容易。
DN-DETR [17] 引入了一种去噪 (DN) 训练方法来加速类 DETR 模型的训练收敛。结果表明,DETR中的慢收敛问题是由二分匹配的不稳定性引起的。为了缓解这个问题,DN-DETR建议将噪声的地面实况(GT)标签和框额外馈送到变压器解码器中,并训练模型以重建真实地表。增加的噪声 (∆x,∆y,∆w,∆h) 受![]()
和 |∆y|< λh限制,其中 (x,y,w,h) 表示GT 框, λ 是控制噪声尺度的超参数。由于 DN DETR 遵循 DAB-DETR 将解码器查询视为锚点,因此噪声 GT 框可以是被视为一个特殊的锚点,附近有一个 GT 框,因为 λ 通常很小。除了原始的 DETR 查询之外,DN-DETR 还增加了一个 DN 部分,该部分将噪声的 GT 标签和框馈送到解码器中,以提供辅助 DN 损失。DN 损耗有效地稳定和加速了 DETR 训练,并且可以插入任何类似 DETR 的模型中。
Deformable DETR [41]是加速DETR收敛的另一项早期工作。为了计算可变形注意力,它引入了参考点的概念,以便可变形注意力可以关注参考周围的一小组关键采样点。参考点概念使得开发几种技术来进一步提高DETR性能成为可能。第一种技术是查询选择,它从编码器中选择功能和引用框作为直接解码器的输入。第二种技术是迭代边界框细化,在两个解码器层之间仔细设计梯度分离。我们在论文中称这种梯度分离技术为“向前看一次”。
遵循DAB-DETR和DN-DETR,DINO将位置查询表述为动态锚框,并使用额外的DN损失进行训练。请注意,DNDETR 还采用了可变形 DETR 的几种技术来实现更好的性能,包括其可变形注意力机制和层参数更新中的“向前看一次”实现。DINO进一步采用了可变形DETR的查询选择思想,以更好地初始化位置查询。基于这一强有力的基线,DINO引入了三种新方法来进一步提高检测性能,将分别在第3.3节、第3.4节和第3.5节中描述。
3.2 模型概述
作为一个类似DETR的模型,DINO是一个端到端的架构,包含一个主干网、一个多层Transformer[36]编码器、一个多层Transformer解码器和多个预测头。整个流水线如图2所示。给定一个图像,我们提取具有 ResNet [14] 或 Swin Transformer [23] 等骨干的多尺度特征,然后将它们输入具有相应位置嵌入的Transformer编码器。在对编码器层进行特征增强后,我们提出了一种新的混合查询选择策略,将锚点初始化为解码器的位置查询。请注意,此策略不会初始化内容查询,但会让它们可学习。有关混合查询选择的更多详细信息,请参见第 3.4 节。通过初始化的锚点和可学习的内容查询,我们使用可变形的注意力[41]来组合编码器输出的特征并逐层更新查询。最终输出由精细化锚框和精细化内容特征预测的分类结果形成。与DN-DETR [17]一样,我们有一个额外的DN分支来执行去噪训练。除了标准的DN方法之外,我们还提出了一种新的对比降噪训练方法,该方法考虑了硬负样本,该方法将在第3.3节中介绍。为了充分利用后面层的细化框信息来帮助优化相邻早期层的参数,该文提出了一种新的look forward twice方法,在相邻层之间传递梯度,这将在第3.5节中描述。
3.3 对比去噪训练
DN-DETR在稳定训练和加速收敛方面非常有效。在 DN 查询的帮助下,它学会根据附近有 GT 框的锚点进行预测。但是,它缺乏预测附近没有对象的锚点“无对象”的能力。为了解决这个问题,我们提出了一种对比降噪(CDN)方法来拒绝无用的锚点。
具体实现:DN-DETR具有一个超参数λ来控制噪声标度。生成的噪声不大于 λ,因为 DN-DETR 希望模型从中等噪声查询中重建真实值 (GT)。在我们的方法中,我们有两个超参数 λ1 和 λ2,其中 λ1 < λ2。如图3的同心正方形所示。我们生成两种类型的CDN查询:正查询和负查询。内方格内的正查询具有小于λ1的噪声标度,并有望重建其相应的地面实况框。内方块和外方块之间的负查询具有大于 λ1 且小于 λ2 的噪声标度。他们被期望预测“没有对象”。我们通常采用较小的λ2,因为硬负样本更接近GT box 对提高性能更有帮助。如图3所示,每个CDN组都有一组正面查询和负面查询。如果图像有 n 个 GT 框,则 CDN 组将有 2×n 个查询,每个 GT 框生成一个正查询和一个负查询。与DN-DETR类似,我们也使用多个CDN组来提高我们方法的有效性。重建损失为box回归的 l1 和 GIOU 损失以及分类损失[19]。将负样本分类为背景的损失也是 focal loss。

分析:我们的方法之所以有效,是因为它可以抑制混淆,选择高质量的锚点(查询)来预测边界框。当多个定位点靠近一个对象时,就会发生混淆。在这种情况下,模型很难决定选择哪个定位点。这种混乱可能会导致两个问题。首先是重复预测。尽管类似DETR的模型可以在基于集合的损失和自我注意的帮助下抑制重复的盒子[3],但这种能力是有限的。如下图8左图所示。

用DN查询替换我们的CDN查询时,箭头指的男孩有3个重复的预测。通过 CDN 查询,我们的模型可以区分锚点之间的细微差异,避免重复预测,如图8右图所示 。第二个问题是可能会选择离 GT 框更远的不需要的锚点。尽管降噪训练 [17] 改进了模型选择附近定位点的能力,但 CDN 通过教导模型拒绝更远的定位点来进一步提高此功能。
有效性证明:为了证明 CDN 的有效性,我们定义了一个称为平均 Top-K 距离 (ATD(k)) 的指标,并使用它来评估匹配部分中锚点与其目标 GT 框的距离。
与 DETR 一样,每个锚点对应于一个预测,该预测可能与 GT 框或背景匹配。我们在这里只考虑那些与 GT box 匹配的 box。假设我们在验证集中有 N 个 GT 边界框 b0,b2,…,bN−1,其中 bi = (xi,yi,wi,hi)。对于每个 bi,我们可以找到其对应的锚点并将其表示为 ai = (x′i,yi′,wi′,h′i)。ai是解码器的初始锚框,在匹配过程中,最后一个解码器层之后的细化框分配给 bi。然后我们有
![]()
其中 ∥bi−ai∥1 是 bi 和 ai 之间的 l1 距离,topK(x,k) 是一个函数,它返回 x 中 k 个最大元素的集合。我们之所以选择 top-K 元素,是因为当 GT 框与更远的锚点匹配时,更容易发生混淆问题。如图 4 中(a)和(b)所示。DN足以选择整体好的锚点。但是,CDN 为小型对象找到了更好的定位点。图4 (c) 表明,在具有 ResNet-50 和多尺度功能的 12 个时期内,CDN 查询比对小对象的 DN 查询提高了 +1.3 AP。

3.4 混合查询选择
在 DETR [3] 和 DN-DETR [17] 中,解码器查询是静态嵌入,不从单个图像中获取任何编码器特征,如图 5 所示(a)所示。它们直接从训练数据中学习定位点(在 DN-DETR 和 DAB-DETR 中)或位置查询(在 DETR 中),并将内容查询设置为所有 0 向量。Deformable DETR [41] 学习位置查询和内容查询,这是静态查询初始化的另一种实现。为了进一步提高性能,Deformable DETR [41]有一个查询选择变体(在[41]中称为“两阶段”),它从最后一个编码器层中选择前K个编码器特征作为先验,以增强解码器查询。如图5 (b)所示,位置查询和内容查询都是通过所选要素的线性变换生成的。此外,这些选定的特征被馈送到辅助检测头以获得预测框,这些预测框用于初始化参考框。同样,Efficient DETR [39] 也根据每个编码器特征的客观性(类)得分选择前 K 个特征。
我们模型中查询的动态 4D 锚框公式使其与解码器位置查询密切相关,可以通过查询选择来改进。我们遵循上述做法,提出了一种混合查询选择方法。如图 5 (c)所示,我们仅使用与所选 top-K 特征关联的位置信息初始化锚框,但像以前一样将内容查询保持静态。请注意,Deformable DETR [41] 利用 top-K 功能不仅增强了位置查询,还增强了内容查询。由于所选特征是未经进一步优化的初步内容特征,因此它们可能会模棱两可并误导解码器。例如,所选要素可能包含多个对象或仅是对象的一部分。相比之下,我们的混合查询选择方法仅增强了具有top-K所选功能的位置查询,并使内容查询像以前一样可学习。它有助于模型使用更好的位置信息来汇集编码器中更全面的内容特征。

3.5 Look Forward Twice
在本节中,我们提出了一种 box prediction的新方法。Deformable DETR [41] 中的迭代框细化阻止了梯度反向传播以稳定训练。我们将该方法命名为look forward one,因为层 i 的参数仅基于框 bi 的辅助损失进行更新,如图 6(a)所示。然而,我们推测,来自后面层的改进的 box 信息可能更有助于纠正其相邻早期层中的 box 预测。因此,我们提出了另一种称为“look forward twice”的方式来执行 box 更新,其中层 i 的参数受层 i 和层 (i+1) 的损失的影响,如图 6(b)所示。对于每个预测偏移量 ∆bi,它将用于更新两次框,一个 for b′i ,另一个 for b (pred)i+1,因此我们将我们的方法命名为向前看两次。
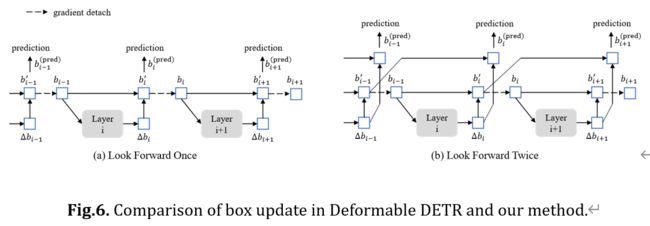
预测框的最终精度由两个因素决定:初始框 b i−1 的质量和框的预测偏移量 ∆b i 。“向前看一次”方案仅优化后者,因为梯度信息从第 i 层分离到第 i 层 (i−1)。相比之下,我们改进了初始框 b i−1 和预测框偏移量 ∆b i。提高质量的一种简单方法是监督第 i 层的最后一个box,并输出下一层 ∆b i+1。因此,我们使用b’i 和 ∆b i+1 的总和作为层-(i + 1)的预测框。
更具体地说,给定第 i 层的输入框 bi−1,我们通过以下方式获得最终预测框:
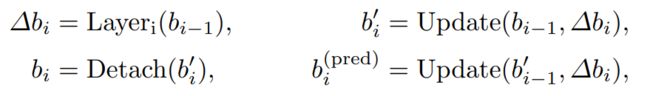
这里b’i是未分离的bi。Update () 是一个函数,它通过预测的框偏移量 ∆bi 来细化框 bi−1。我们对box更新采用与Deformable DETR [41] 中相同的方式。
4 实验
4.1 设置
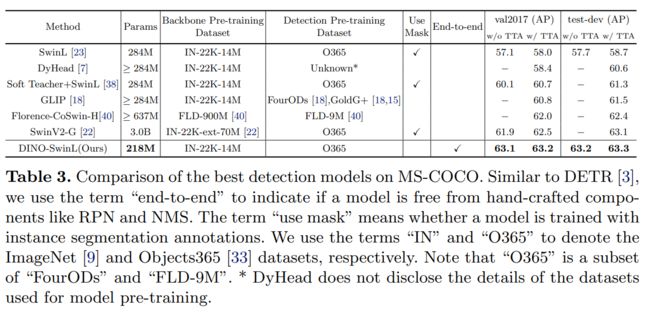
数据集和骨干:我们对COCO 2017对象检测数据集[20]进行评估,该数据集分为train2017和val2017(也称为minival)。我们报告了两个不同主干的结果:在ImageNet-1k [9]上预训练的ResNet-50 [14]和在ImageNet-22k [9]上预训练的SwinL [23]。使用ResNet-50的DINO在train2017上训练,没有额外的数据,而带有SwinL的DINO首先在Object365上预先训练[33],然后在train2017上进行微调。我们报告了不同 IoU 阈值和对象尺度下 val2017 的标准平均精度 (AP) 结果。我们还使用 SwinL 报告了 DINO 的测试开发结果。
实现细节:DINO由一个主干网、一个Transformer编码器、一个Transformer解码器和多个预测头组成。在附录D中,我们提供了更多的实现细节,包括我们的模型中使用的所有超参数和工程技术,供那些想要重现我们结果的人使用。我们将在盲审后发布代码。
4.2 主要结果
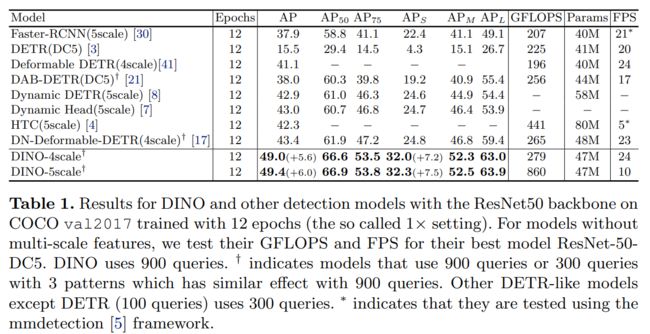
12 周期设置:通过我们改进的box降噪和训练损失,可以显着加快训练过程。如表1所示,我们将我们的方法与强基线进行了比较,包括基于卷积的方法[30,4,7]和类似DETR的方法[3,41,8,21,17]。为了进行公平比较,我们报告了表1中列出的所有型号在相同的A100 NVIDIA GPU上测试的GFLOPS和FPS。除 DETR 和 DAB-DETR 之外的所有方法都使用多尺度特征。对于那些没有多尺度特征的方法,我们使用ResNet-DC5报告他们的结果,该图在使用膨胀的更大分辨率特征图时具有更好的性能。由于有些方法采用 5 个尺度的特征图,有些采用 4 个尺度的特征图,所以我们用 4 个和 5 个尺度的特征图报告我们的结果。
如表1所示,我们的方法在相同设置下使用具有 4 scale 特征图的ResNet-50和具有5 scale 特征图分别提高了+6.0 AP与+5.6 AP。我们的 4 scale 模型不会在计算和参数数量方面引入太多开销。此外,我们的方法在小物体上表现特别好,在 4 scale下获得 +7.2 AP,在 5 scale下获得 +7.5 AP。请注意,由于工程技术的原因,具有ResNet-50主干的模型的结果高于我们论文第一版的结果。
与具有 ResNet-50 主干的最佳型号的比较:
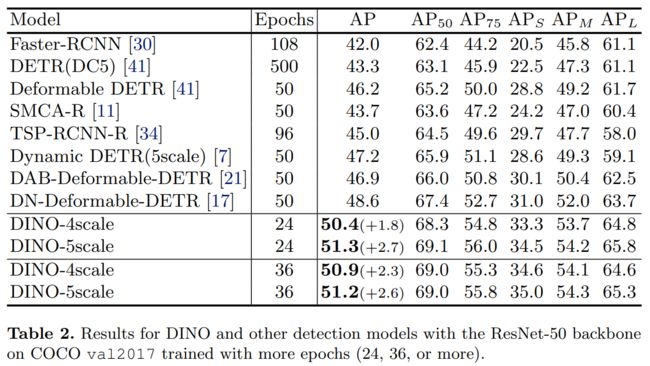
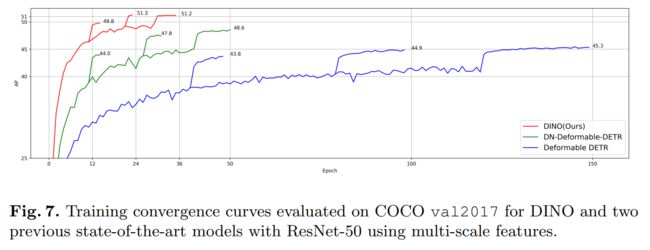
验证了我们的方法在提高收敛速度和性能方面的有效性,我们将我们的方法与使用相同的 ResNet-50 主干的几个强基线进行了比较。尽管最常见的 50 个 epoch 设置,但我们采用 24 (2×) 和 36 (3×) 个 epoch 设置,因为我们的方法收敛得更快,并且在 50 个 epoch 训练中只产生较小的额外增益。表2中的结果表明,仅使用24个epoch,我们的方法分别在4和5个刻度下实现了+1.8 AP和+2.7 AP的改进。此外,在 3× 设置中使用 36 个 epoch,改进分别增加到 +2.3 和 +2.6 AP,具有 4 和 5 个刻度。详细的收敛曲线比较如图 7 所示。
4.3 与SOTA模型的比较
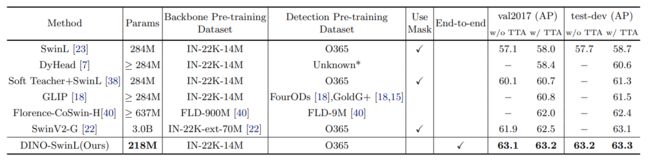
为了与SOTA结果进行比较,我们使用在ImageNet-22K上预先训练的公开可用的SwinL [23]骨干网。我们首先在 Objects365 [33] 数据集上预训练 DINO,然后在 COCO 上对其进行微调。如表3所示,DINO在COCO val2017和test-dev上取得了63.2AP和63.3AP的最佳结果,证明了其对更大模型大小和数据大小的强大可扩展性。请注意,表 3 中所有以前的 SOTA 型号都不使用基于Transformer解码器的检测头(HTC++ [4] 和 DyHead [7])。这是第一次在排行榜上将端到端Transformer检测器建立为SOTA模型[1]。与以前的SOTA模型相比,我们使用更小的模型大小(与SwinV2-G相比为1/15参数[22]),骨干预训练数据大小(与Florence相比为1/60图像)和检测预训练数据大小(与Florence相比为1/5图像),同时取得了更好的结果。此外,我们报告的没有测试时间增强(TTA)的性能是一个没有花里胡哨的整洁结果。这些结果有效地表明了DINO与传统探测器相比具有优越的检测性能。
4.4 消融实验
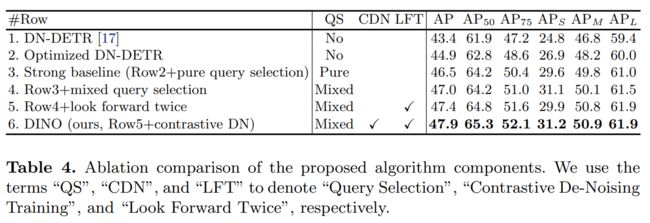
新算法组件的有效性:为了验证我们提出的方法的有效性,我们建立了一个强大的基线,具有优化的DN-DETR和纯查询选择,如第3.1节所述。我们将所有管道优化和工程技术(见第4.1节和附录D)纳入强基线。强基线的结果可在表 4 第 3 行中找到。我们还展示了优化 DN-DETR 的结果,而无需从表 4 第 2 行的可变形 DETR [41] 中选择纯查询。虽然我们强大的基线优于所有以前的模型,但我们在DINO中的三种新方法进一步显着提高了性能。
5 结论
在本文中,我们提出了一种强大的端到端Transformer检测器DINO,具有对比去噪训练、混合查询选择和look forward twice,显著提高了训练效率和最终检测性能。因此,DINO 在 COCO val2017 上使用多尺度特征的 12 个epochs和 36 个epochs设置中都优于之前所有基于 ResNet-50 的模型。在改进的推动下,我们进一步探索了在更大的数据集上训练具有更强大主干的DINO,并在COCO 2017测试开发中实现了最先进的63.3 AP。本结果确立了类DETR模型作为主流检测框架的地位,不仅因其新颖的端到端检测优化,还因其优越的性能。
其他
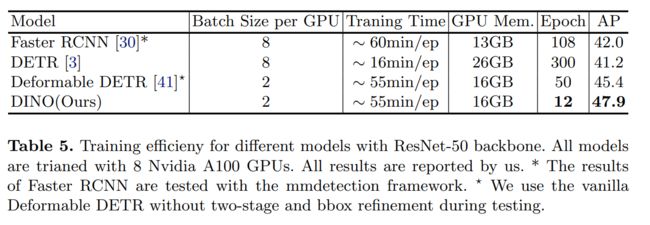
我们在表 5 中提供了基本模型的 GPU 内存和训练时间。所有结果均在 8 个配备 ResNet-50 的 Nvidia A100 GPU 上实验[14]。结果表明,我们的模型不仅有效,而且训练效率高。
参考文献
- Papers with code - coco test-dev benchmark (object detection).
- Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934, 2020.
- Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In European conference on computer vision, pages 213–229. Springer, 2020.
- Kai Chen, Jiangmiao Pang, Jiaqi Wang, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jianping Shi, Wanli Ouyang, et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4974–4983, 2019.
- Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, et al. Mmdetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155, 2019.
- Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174, 2016.
- Xiyang Dai, Yinpeng Chen, Bin Xiao, Dongdong Chen, Mengchen Liu, Lu Yuan, and Lei Zhang. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7373–7382, 2021.
- Xiyang Dai, Yinpeng Chen, Jianwei Yang, Pengchuan Zhang, Lu Yuan, and Lei Zhang. Dynamic detr: End-to-end object detection with dynamic attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 2988–2997, October 2021.
- Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pretraining of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Peng Gao, Minghang Zheng, Xiaogang Wang, Jifeng Dai, and Hongsheng Li. Fast convergence of detr with spatially modulated co-attention. arXiv preprint arXiv:2101.07448, 2021.
- Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430, 2021.
- Kaiming He, Georgia Gkioxari, Piotr Dolla´r, and Ross Girshick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961– 2969, 2017.
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016.
- Aishwarya Kamath, Mannat Singh, Yann LeCun, Ishan Misra, Gabriel Synnaeve, and Nicolas Carion. Mdetr – modulated detection for end-to-end multi-modal understanding. arXiv: Computer Vision and Pattern Recognition, 2021.
- Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M Ni, and Lei Zhang. Dndetr: Accelerate detr training by introducing query denoising. arXiv preprint arXiv:2203.01305, 2022.
- Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al.
Grounded language-image pre-training. arXiv preprint arXiv:2112.03857, 2021. - Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(2):318–327, 2020.
- Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dolla´r, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
- Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. DAB-DETR: Dynamic anchor boxes are better queries for DETR. arXiv preprint arXiv:2201.12329, 2022.
- Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, et al. Swin transformer v2: Scaling up capacity and resolution. arXiv preprint arXiv:2111.09883, 2021.
- Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021.
- Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, and Jingdong Wang. Conditional detr for fast training convergence. arXiv preprint arXiv:2108.06152, 2021.
- Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh
Venkatesh, and Hao Wu. Mixed precision training, 2018. - Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, 2021.
- Joseph Redmon and Ali Farhadi. Yolo9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7263– 7271, 2017.
- Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
- Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28, 2015.
- Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6):1137–1149, 2017.
- Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 658–666, 2019.
- Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8430–8439, 2019.
- Zhiqing Sun, Shengcao Cao, Yiming Yang, and Kris Kitani. Rethinking transformer-based set prediction for object detection. arXiv preprint arXiv:2011.10881, 2020.
- Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional onestage object detection. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9627–9636, 2019.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, L ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
- Yingming Wang, Xiangyu Zhang, Tong Yang, and Jian Sun. Anchor detr: Query design for transformer-based detector. arXiv preprint arXiv:2109.07107, 2021.
- Mengde Xu, Zheng Zhang, Han Hu, Jianfeng Wang, Lijuan Wang, Fangyun Wei, Xiang Bai, and Zicheng Liu. End-to-end semi-supervised object detection with soft teacher. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3060–3069, 2021.
- Zhuyu Yao, Jiangbo Ai, Boxun Li, and Chi Zhang. Efficient detr: Improving endto-end object detector with dense prior. arXiv preprint arXiv:2104.01318, 2021.
- Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, et al. Florence: A new foundation model for computer vision. arXiv preprint arXiv:2111.11432, 2021.
- Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. In ICLR 2021: The Ninth International Conference on Learning Representations, 2021.