csapp-深入理解计算机系统学习记录
文章目录
- csapp 学习记录一
- 第1章:计算机系统漫游
-
-
- 信息就是位+上下文
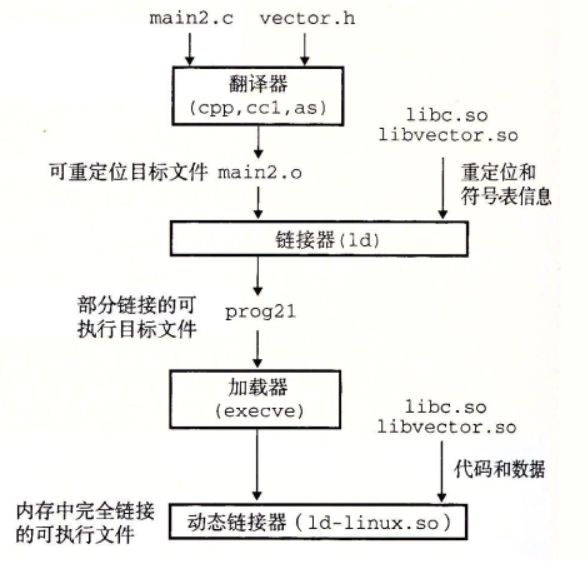
- 从一个c文件,到可执行目标文件整个翻译过程分为4个阶段
- 程序执行的过程:
- 摩尔定律:
- HELLO WORLD 可执行程序的产生
- 理解编译过程及原理的意义何在
- 可执行程序hello在计算机上执行的过程
- 程序执行过程中的几点启示
- 系统的硬件组成
- 高速缓存
- 存储设备形成层次结构
- 操作系统管理硬件
-
- 进程
- 线程
- 虚拟内存
- 并发和并行
- 线程级并发
- 指令级并行
- 第2章:信息表示和处理
-
- 2.1 信息存储
-
- 2.1.1 十六进制表示法
- 2.1.2 字
- 2.1.3 数据大小
- 2.1.4 寻址和字节顺序
- 2.1.5 表示字符串
- 2.1.6 表示代码
- 2.1.7 布尔代数简介
- 2.1.8 C语言中的位级运算
- 2.1.9 C语言中的逻辑运算
- 2.1.10 C语言中的移位运算
- 2.2 整数表示
-
- 2.2.1整数数据类型
- 2.2.2 无符号数编码
- 2.2.3 补码编码
- 2.2.4 有符号数和无符号数之间的转换
- 2.2.5 C语言中的有符号数和无符号数
- 2.2.6 扩展一个数字的位表示
- 2.2.7 截断数字
- 2.3 整数运算
-
- 2.3.1 无符号加法
- 2.3.2 补码加法
- 2.3.3 补码的非
- 2.3.4 无符号乘法
- 2.3.5 补码乘法
- 2.3.6 乘以常数
- 2.3.7 除以2的幂
- 2.3.8 关于整数运算的思考
- 2.4 浮点数
-
- 2.4.1 二进制小数
- 2.4.2 IEEE浮点表示
- 2.4.3 数字示例
- 第 3 章:程序的机器级表示
- 3.1 历史观点
- 3.2 程序编码
-
- 3.2.1 机器级代码
- 3.2.2 代码示例
- 3.2.3 关于格式的注解
- 3.3 数据格式
- 3.4访问信息
-
- 3.4.1操作数指示符
- 3.4.2数据传送指令
- 3.4.3数据传送示例
- 3.4.4压入和弹出栈数据
- 3.5算术和逻辑操作
-
- 3.5.1加载有效地址
- 3.5.2一元和二元操作
- 3.5.3移位操作
- 3.5.4特殊的算术操作
- 3.6控制
-
- 3.6.1条件码
- 3.6.2访问条件码
- 3.6.3跳转指令
- 3.6.4跳转指令的编码
- 3.6.5用条件控制来实现条件分支
- 3.6.6用条件传送来实现条件分支
- 3.6.7循环
- 3.6.8switch
- 3.7过程
-
- 3.7.1运行时栈
- 3.7.2转移控制
- 3.7.3数据传送
- 3.7.4栈上的局部存储
- 3.7.5寄存器中的局部存储空间
- 递归过程
- 3.8数据的分配和访问
- 3.9异质的数据结构
-
- 3.9.1结构
- 3.9.2联合
- 3.9.3数据对齐
- 3.10在机器级程序中将控制与数据结合起来
-
- 3.10.1理解指针
- 3.10.2使用GDB调试器
- 3.10.3内存越界引用和缓冲区溢出
- 3.10.4对抗缓冲区溢出攻击
- 3.10.5支持可变栈帧
- 3.11 浮点代码
-
- 3.11.1 浮点传送和转化操作
- 3.11.2 过程中的浮点代码
- 3.11.3 浮点运算操作
- 3.11.4 定义和使用浮点常数
- 3.11.5 在浮点代码中使用位级操作
- 3.11.6 浮点比较操作
- 第6章 存储器层次结构
-
- 6.1存储技术
- 6.1.1随机访问存储器
-
- SRAM
- DRAM
- SRAM 与 DRAM 比较
- 传统的 DRAM
- 内存模块
- 增强的 DRAM
- 非易失性存储器
- 访问主存
- 6.2磁盘存储
-
- 磁盘构造
- 磁盘容量
- 磁盘操作
- 逻辑磁盘块
- 连接 I/O 设备
- 6.1.3固态硬盘
- 6.1.4存储技术趋势
- 6.2局部性
-
- 6.2.1对程序数据引用的局部性
- 6.2.2取指令的局部性
- 6.2.3局部性小结
- 6.3存储器层次结构
-
- 6.3.1存储器层次结构中的缓存
- 6.4高速缓存存储器
-
- 6.4.1通用的高速缓存存储器组织结构
- 6.4.2直接映射高速缓存
- 6.4.3组相联高速缓存
- 6.4.4全相联高速缓存
- 6.4.5有关写的问题
- 6.4.6一个真实的高速缓存层次结构的解剖
- 6.4.7高速缓存参数的性能影响
- 第7章 链接
-
-
- 概念
- 为什么需要了解链接器
- 7.1编译器驱动程序
- 7.2静态链接
- 7.3目标文件
- 7.4可重定位目标文件
- 7.5符号和符号表
- 7.6符号解析
-
- 7.6.1如何解析多重定义的全局符号
- 7.6.2与静态库链接
- 7.6.3链接器如何解析引用
- 7.7重定位
-
- 7.7.1重定位条目
- 7.7.2重定位符号引用
- 7.8可执行目标文件
- 7.9加载可执行目标文件
- 7.10**动态链接共享库**
- 7.11从应用程序中加载和链接共享库
- 7.12位置无关代码
- 7.13库打桩机制
- 7.14处理目标文件的工具
- 7.15总结
-
- lab1 Data Lab
-
- 题目列表
-
- 准备
- 题解
-
- bitXor(x,y)
- tmin()
- isTmax(x)
- allOddBits(x)
- negate(x)
- isAsciiDigit(x)
- conditional(x, y, z)
- isLessOrEqual(x,y)
- logicalNeg(x)
- howManyBits(x)
- floatScale2(f)
- floatFloat2Int(f)
- floatPower2(x)
- lab2 Bomb Lab
-
-
- 准备
- 题解
-
- **phase_1**
- **phase_2**
- phase_3
- **phase_4**
- **phase_5**
- **phase_6**
- Secret_phase
- Secret_phase
-
csapp 学习记录一
第1章:计算机系统漫游
信息就是位+上下文
系统中的所有信息,都是一串比特组成的。区分不同数据对象的唯一方法是联系他们的上下文。
从一个c文件,到可执行目标文件整个翻译过程分为4个阶段

-
预处理阶段 预处理器 cpp 根据字符# 开头的命令,修改原始的C程序。
比如include
命令告诉预处理器,读取系统头文件 stdio.h的内容。并把它插入到程序中。结果得到了另一个c程序。通常为.i作为文件拓展。 -
编译阶段。 编译器(ccl)将hello.i 翻译成文本文件 hello.s 翻译是将.i 转为汇编。
-
汇编阶段, 汇编器(as)将hello.s 翻译成机器语言指令,将这些指令打包成可重定位目标程序的格式。并将结果保存至目标 hello.o中(改文件为二进制文件,它包含的17个字节是main的执行编码)。如果文本编辑器打开,则为一堆乱码
-
链接阶段 : 比如说hello程序调用了printf函数,是每个C编译器都提供的标准C库中的一个函数,printf 函数保存在一个名为printf.o 的单独预编译完成的目标文件中。 这个文件必须以某种方式合并到我们程序中。链接器(ld)就负责这种合并,于是得到hello文件,它是一个可执行文件,可以直接加载到内存中执行。
程序执行的过程:
shell程序执行指令,等待我们的命令,输入命令并回车之后, shell将字符都逐一读进寄存器。再把它放到内存中。
(利用DMA:直接存储器读取)技术可以数据不经过处理器而直接从磁盘到达主存。
一旦目标文件hello的代码和数据被加载到内存,处理器就开始执行。hello程序中main程序中的机器语言指令。再从寄存器文件中复制到显示设备,最终显示在屏幕上。

摩尔定律:

HELLO WORLD 可执行程序的产生
hello.c 文本文件的创建:
#include
int main()
{
printf("hello world\n");
return 0;
}
对源代码进行编译,生成可执行文件hello
理解编译过程及原理的意义何在
整体来看有三个方面的原因:
1、优化程序性能
2、理解程序链接时的错误,有助于我们解决各种奇奇怪怪的错误
3、避免安全漏洞,比如缓冲区溢出漏洞等
可执行程序hello在计算机上执行的过程
此过程用几副抽象出来图片来说明一下
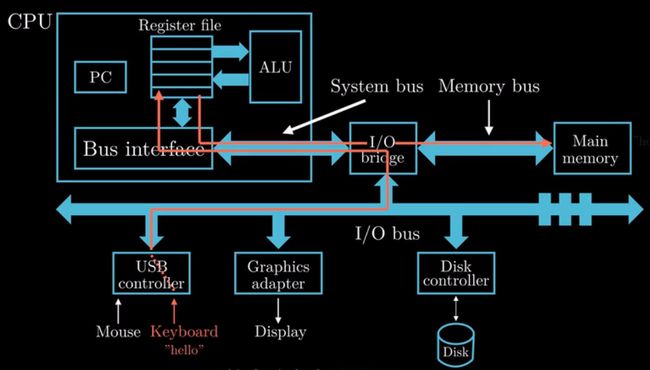 图中“hello”由usb键盘输入,通过I/O总线传递给cpu,其处理后将获得的数据存至内存中
图中“hello”由usb键盘输入,通过I/O总线传递给cpu,其处理后将获得的数据存至内存中
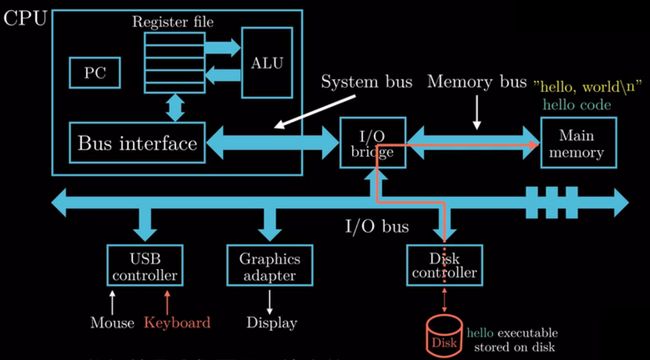 图中磁盘与内存之间通过DMA(Direct Memory Access)直接存储器存取技术将需要的hello程序数据,从磁盘中读入内存中
图中磁盘与内存之间通过DMA(Direct Memory Access)直接存储器存取技术将需要的hello程序数据,从磁盘中读入内存中
 图中CPU读取内存中的程序指令及数据,处理后将计算后的数据交给显示设备,显示设备收到数据后进行显示
图中CPU读取内存中的程序指令及数据,处理后将计算后的数据交给显示设备,显示设备收到数据后进行显示
程序执行过程中的几点启示
1、程序执行时数据需要进行多点交换,整个过程需要消耗“大量”时间。
2、按照目前大部分计算机来说,计算机数据存储单元按照读写速度由大到小比较:寄存器>高速缓存L1>高速缓存L2>高速缓存L3>内存>磁盘,而按照数据存储大小来看正好相反。
3、本例中,hello程序的执行并非是自己将自己交给处理器进行执行,而是通过shell程序将各种参数交给操作系统,操作系统再对计算机资源进行调度,然后将hello程序交给计算机组件进行处理输出。
4、计算机在进行资源调度时,会为新的程序创建一个进程,而每个进程看到的内存都是一样的,因为程序在链接的时候会对内存地址进行分配,所以操作系统为每个进程统一内存,还原一个程序所需要的内存环境,我们称之为虚拟地址空间。如下图(虚拟地址空间)的分布。
系统的硬件组成
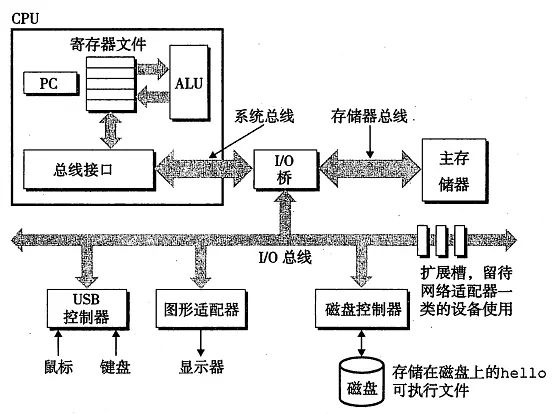
典型系统的硬件构成
-
总线
贯穿整个系统的是一组电子管道,称为总线 ,它携带信息字节,并负责在各个部件之间传递,通常总线被设计成传送定长的字节块,就是字(word),字中的字节数(字长)是一个基本的系统参数,现在大多数机器字长有4个字节(32位)或8字节(64位)
-
I/O设备
每个I/O设备都通过一个控制器或者适配器和I/O总线相连,控制器是I/O设备本身或者系统的主印制电路板(主板)上的芯片组,而适配器则是一块插在主板插槽上的卡,无论如何,它们的功能都是为了在I/O总线和I/O设备之间传输数据
-
主存
主存是一个临时存储设备,在处理器执行程序的时候,用来存放程序和程序处理的数据,从物理上说,主存是由一组动态随机存取存储器(DRAM)芯片组成的。从逻辑上说,存储器是一个线型的字节数组,每个字节都有其唯一的索引(数组索引),这些地址是从零开始的,一般来说,组成程序的每条机器指令都由不同数量的字节构成,比如在运行Linux的x86-64机器上,short类型的数据需要2个字节,int和float类型需要4个字节,而long和double需要8个字节
-
处理器
中央处理单元(CPU),简称处理器,是解释(或运行)存储在主存中指令的引擎。处理器的核心是一个大小为一个字的存储设备(或寄存器),称为程序计数器(PC)。在任何时刻,PC都指向主存中某条机器语言指令(即含有该条指令的地址)
处理器看上去是一个非常简单的指令执行模型来操作的,这个模型是由指令集架构决定的,在这个模型中,指令按照严格的顺序执行,而执行一条指令包含一系列的步骤,处理器从程序计数器指向的内存处读取指令,解释指令中的位,执行该指令指示的简单操作,然后更新PC,使其指向下一条指令,而这条指令并不一定和在内存中刚刚执行的指令相邻
这样简单的操作并不多,它们围绕着主存、寄存器文件和算数/逻辑单元(ALU)进行。寄存器文件是一个小的存储设备,由一些单个字长的寄存器组成,每个寄存器都有唯一的名字, ALU计算新的数据和地址值。下面是一些简单操作的例子,CPU在指令的要求下可能会执行这些操作
- 加载:从主存复制一个字节或者一个字到寄存器,以覆盖寄存器原来内容
- 存储:从寄存器赋值一个字节或者一个字到主存的某个位置,以覆盖这个位置上原来的内容
- 操作:把两个寄存器的内容复制到ALU,ALU对这两个字做算术运算,并将结果存放到一个寄存器中,以覆盖该寄存器中原来的内容
- 跳转:从之灵本身中抽取一个字,并将这个字复制到程序计数器(PC)中,以覆盖PC中原来的值
高速缓存
系统化了大把时间把信息从一个地方挪动到另一个地方,hello程序从最初的在磁盘上,当程序加载时,它们被复制到主存,当处理器运行程序的时候,指令又从主存复制到了处理器上,这些复制就是开销,减慢了程序真正的工作
根据机械原理,较大的存储设备要比较小的存储设备运行得慢,而快速设备的造价远高于同类的低速设备,类似的,一个典型的寄存器文件只存储几百字节的信息,而主存中可存放几十亿字节,然而,处理器从寄存器文件中读数据比从主存中读取数据快乐至少100倍
高速缓存存储器:作为暂时的集结区域,存放处理器近期可能会需要的信息
位于处理器芯片上的L1高速缓存的容量可以达到数万字节,访问速度几乎和访问寄存器文件一样快,一个容量为数十万的到数百万的L2高速缓存通过一条特殊的总线连接到处理器,进程访问L2高速缓存的时间要比访问L1高速缓存的时间长5倍,但是这仍比访问主存的时间快5~10倍,L1和L2高速缓存是用一种叫做静态随机访问存储器(SRAM)的硬件技术实现的,这些高速缓存的速度快是因为利用了高速缓存的局部性原理,即程序具有访问局部区域里的代码和数据的趋势,通过让高速缓存里存放尽可能经常访问的数据,大部分的内存操作都能在快速的高速缓存中完成
存储设备形成层次结构
在处理器和一个较大较慢的设备(例如主存)之间插入一个更小更快的存储设备(例如高速缓存)的想法已经成为了一个普遍的观念。
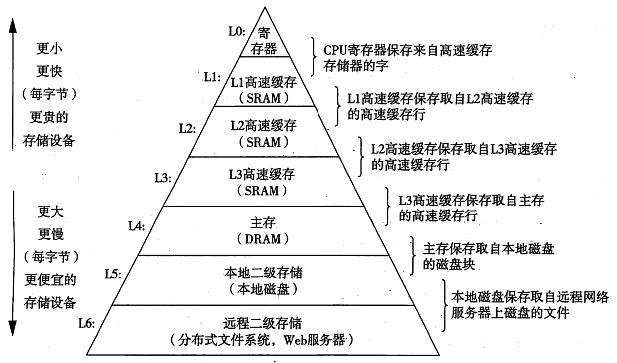
存储层次结构
在这个层次结构中,从上至下,设备的访问速度越来越慢,但是容量越来越大,并且每字节的造价也越来越便宜,寄存器文件在层次结构中位于最顶部,也就是第0级或者记为L0
存储器层次结构的主要思想是上一层的存储器作为第一层存储器的高级缓存,比如寄存器文件就是L1的高速缓存,L1就是L2的高速缓存以此类推
操作系统管理硬件
当shell加载和运行hello的时候,以及hello程序输出自己的信息的时候,shell和hello程序都没有直接访问键盘、显示器、磁盘或者主存,取而代之的是,它们依靠操作系统提供的服务,我们可以把操作系统看成是应用程序和硬件之间插入的一层软件,所有应用程序对硬件的操作尝试,都必须经过操作系统
操作系统的两个基本功能
- 防止硬件被失控的应用程序滥用
- 向应用程序提供简单一致的机制来控制复杂而又通常大不相同的低级硬件设备
操作系统通过几个基本的抽象概念(进程、虚拟内存和文件)来实现这两个功能,文件是对I/O设备的抽象表示,虚拟内存是对主存和磁盘I/O的抽象表示,进程则是对处理器、主存和I/O设备的抽象表示

操作系统的抽象表示
进程
像hello这样的程序在现代系统上运行的时候,操作系统会提供一种假象,就好像系统上只有这个程序在运行。程序看上去是独占地使用处理器、主存和I/O设备,处理器看上去就像在不间断地处理一条接一条地执行程序中的指令,即改程序的代码和数据是系统内存中唯一的对象
进程是操作系统对一个正在进行的程序的一种抽象,在一个系统上可以同时运行多个进程,而每个进程都好像在独占地使用硬件,而并发运行,则是说一个进程的指令和另一个进程的指令是相互交替执行的,在大多数系统中,需要运行的进程数量是多于可以运行它们的CPU个数的,传统系统在一个时刻只能执行一个程序,而现今的多核处理器同时可以执行多个程序,无论是在单核还是多核的系统中,一个CPU看上去都像是在并发地执行多个经常,这是通过处理器在进程间切换来实现的,操作系统实现这种交错执行的机制称为上下文切换
操作系统保持跟踪进程运行所需的所有状态信息,这种状态就是上下文,包括许多信息,比如PC和寄存器文件的当前值,以及主存的内容。在任何一个时刻,单处理器系统都只能执行一个进程的代码,当操作系统决定要把控制权从当前进程转移到某个新进程的时候,就会进行上下文切换,即保存当前的进程上下文,恢复新进程的上下文,然后将控制权传递到新进程,新进程就会从它上次停止的地方开始
举一个shell和hello两个进程并发的例子,最开始,只有shell进程在运行,即等待命令行上的输入,当我们让他运行hello程序时,shell通过调用一个专门的函数,即系统调用
系统调用会将控制权传递给操作系统,操作系统保存shell进程的上下文,创建一个新的hello进程及其上下文,然后将控制权传递给hello进程,hello进程终止后,操作系统恢复shell进程的上下文,并将控制权传回给它,shell进程会继续等待下一个命令行输入
从一个进程到另一个进程的转换是由操作系统内核管理的。内核是操作系统代码常驻主存的部分,当应用程序需要操作系统的某些操作的时候,比如读写文件,它就执行一条特殊的系统调用(system call)命令,将控制权传递给内核,然后内核执行被请求的操作并返回应用程序,内核不是一个独立的进程。相反它是系统管理全部进程所用代码和数据结构的集合
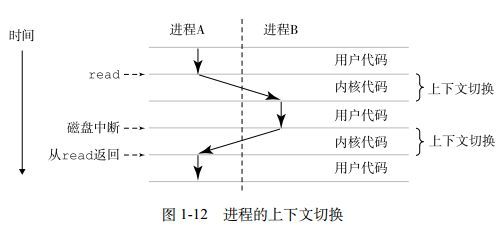
进程的上下文切换
线程
一个进程实际可以由多个称为线程的执行单元构成,每个线程运行在进程的上下文中,并共享同样的代码和全局数据,县城成为越来越重要的编程模型,因为多线程之间比多进程之间更容易共享数据,也因为线程一般来说都比进程更高效,当有多处理器可用的时候,多线程也是一种使得程序可以运行得更快的方法
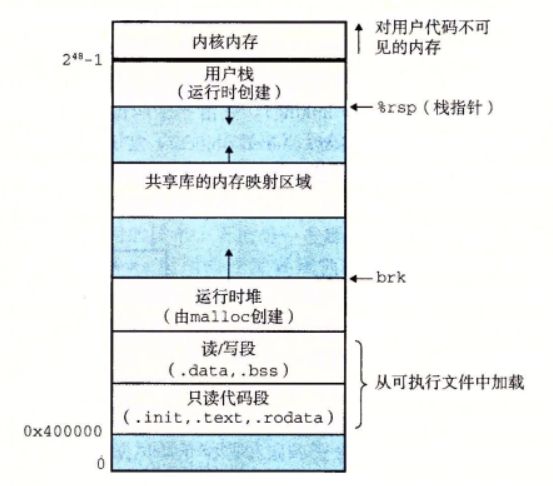
虚拟内存
虚拟内存是一个抽象概念,它为每个进程提供了一个假象,即每个进程都在独占的使用主存。每个进程看到的内存都是一致的,称为虚拟地址空间
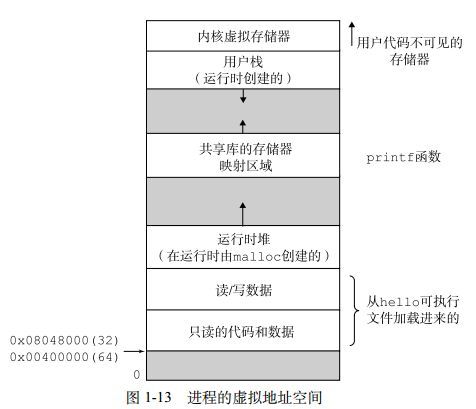
进程的虚拟地址空间
在Linux系统中,地址空间最上面的区域是保留给操作系统中代码和数据的,这对所有进程来说都是一样,地址空间底部区域存放用户进程定义的代码和数据,上图中地址是从下向上增大的
- 程序代码和数据
对所有进程来说,代码是从同一固定的地址开始,紧接着的适合C区安居变量相对应的数据位置,代码和数据区是直接是直接按照可执行目标文件的内容初始化的 - 堆
代码和数据区在进程一开始运行时就被指定了大小,与此不同,当调用像malloc和free这样的C标准函数的时候,堆可以在运动时动态的拓展和收缩 - 共享库
大约在地址空间的中间部分是一块用来存放C标准库和数学库这样的共享库的代码和数据的区域 - 栈
位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数调用,和堆一样,栈在程序执行期间可以动态扩展和收缩,当调用一个函数的时候栈就会被扩展,一个函数返回的时候栈就会收缩 - 内核虚拟内存
地址空间顶部是为内核保留的,不允许应用程序读写这个区域的内容或者直接调用内核代码定义的函数,它们必须通过内核来执行这些操作,虚拟内存的运作基本思想是把一个进程虚拟内存的内容存储在磁盘上,然后用主存作为磁盘的高速缓存
并发和并行
我们用的术语并发是一个通用的概念,指一个同时具有多个活动的系统;而术语并行指的是用并发来使一个系统运行得更快,并行可以在计算机系统的多个抽象层次上运用
线程级并发
传统意义上线程级别上的并发只是模拟出来的,是通过是一台计算机在它正在执行的进程间快速切换来实现的,就好像一个杂耍艺人保持多颗杂技球在空中飞舞一样
指令级并行
在较低的抽象层次上,现代处理器可以同时执行多条指令的属性叫做指令级并行,如果处理器可以达到比一个周期一个指令更快的执行速率就称之为超标量处理器
第2章:信息表示和处理
2.1 信息存储
前言:大致的数的表示,数的运算在机组课上已经有老师带领全部学习了一遍,这里主要以复习提升为主。
- 重要概念
1)
字节:大多数计算机使用8位的块(字节),作为最小的可寻址的内存单位,而不是访问内存中单独的位。
2)虚拟内存:机器级程序将内存视作一个很大的字节数组,称作虚拟内存。
\3)地址:内存的每一个字节都有一个唯一的数字来标识,称为它的地址。
4)虚拟地址空间:所有可能的地址的集合称为虚拟地址空间。
- 这个虚拟地址空间只是一个展示给机器级程序的概念性映像。
- 实际的实现(见第9章)是将动态随机访问存储器(DRAM)、闪存、磁盘存储器、特殊硬件和操作系统软件结合起来,为应用程序提供一个看上去统一的字节数组。
5)
程序对象:程序数据、指令和控制信息。
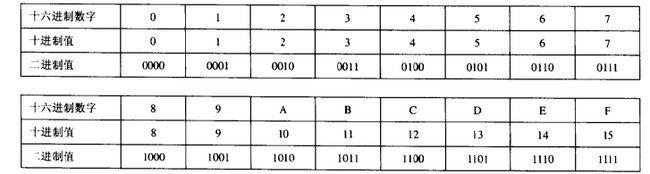
2.1.1 十六进制表示法
- 为什么选择十六进制
1)一个字节由8位组成,在二进制表示法中,它的值域是 0000000 0 2 ∼ 1111111 1 2 00000000_2\sim 11111111_2 000000002∼111111112,如果看成十进制就是 0 10 ∼ 25 5 10 0_{10}\sim 255_{10} 010∼25510.
2)两种表示法对于描述位模式都十分不方便。二进制表示法太冗长,十进制表示法与位模式的转化十分麻烦。
- 十六进制表示法
1)十六进制数:
十六进制使用0~9,以及字符A ~ F来表示16个可能的值, 一个字节的值域为 0 0 16 ∼ F F 16 00_{16}\sim FF_{16} 0016∼FF16 在C语言中,以0x或者0X开头的数字常量被认为是十六进制的数。字符‘A’ ~ ‘F’既可以是大写也可以是小写,例如我们可以将 F A 1 D 37 B 16 FA1D37B_{16} FA1D37B16写作 0 x F A 1 D 37 B 0xFA1D37B 0xFA1D37B,或者 0 x f a 1 d 37 b 0xfa1d37b 0xfa1d37b2)十六进制和二进制之间的转换
注意:将二进制数字转化为十六进制的时候,要把二进制数字分割为每四个一组,如果总数不是四的倍数,最左边一组可以少于四位,前面用零补足。然后将每个四位组转化为相应的十六进制数字。 当值x是2的幂时,也就是,对于某个n,x= 2 n 2^n 2n,我们可以很容易地将x写成十六进制形式。只要记住x的二进制表示就是1后面跟n个零。十六进制数字О代表四个二进制0。所以,对于被写成i+4j形式的n来说,其中0≤i≤3,我们可以把x写成开头的十六进制数字为1(i=0)、2(=1)、4 ( i=2)或者8(i=3),后面跟随着j个十六进制的0。比如,x=2048= 2 11 2^{11} 211,我们有n=11 =3+4·2,从而得到十六进制表示0x800。3)十六进制和十进制之间的转换
十进制和十六进制表示之间的转换需要使用乘法或者除法来处理一般情况。将一个十进制数字x转换为十六进制,我们可以反复地用16除x,得到一个商q和一个余数r,也就是x=q· 16+r。然后,我们用十六进制数字表示的r作为最低位数字,并且通过对q反复进行这个过程得到剩下的数字。例如,考虑十进制314156的转换: 314156 = 19634 ⋅ 16 + 12 ( C ) 19634 = 1227 ⋅ 16 + 2 ( 2 ) 1227 = 76 ⋅ 16 + 11 ( B ) 76 = 4 ⋅ 16 + 12 ( C ) 4 = 0 ⋅ 16 + 4 ( 4 ) 314156196341227764=19634⋅16+12(C)=1227⋅16+2(2)=76⋅16+11(B)=4⋅16+12(C)=0⋅16+4(4)314156196341227764=19634⋅16+12©=1227⋅16+2(2)=76⋅16+11(B)=4⋅16+12©=0⋅16+4(4)
从这里,我们能读出十六进制表示为0x4CB2C.
反过来,将一个十六进制数字转换为十进制数字,我们可以用相应的16的幂乘以每个十六进制数字。比如,给定数字Ox7AF,我们计算它对应的十进制值为716+ 1016+ 15=7256+1016+ 15= 1792+ 160+ 15= 1967。
2.1.2 字
每台计算机都有一个字长( word size),指明整数和指针数据的标称大小( nominal size)。因为虚拟地址是以这样的字来编码的,所以字长决定的最重要的系统参数就是虚拟地址空间的最大大小。也就是说,对于一个字长为n位的机器而言,虚拟地址的范围为0~ 2 n 2^n 2n-1,程序最多访问 2 n 2^n 2n字节。
2.1.3 数据大小

2.1.4 寻址和字节顺序
1.地址
- 在几乎所有的机器上,多字节对象被存储为连续的字节序列,对象的地址为所使用的的字节序列的最小地址。
- 例如,假设一个类型为int 的变量x的地址为0x100,也就是说,地址表达式&x的值为0x100。那么,x的四字节将被存储在存储器的0x100、0x101、0x102和0x103位置。
2.字节排序的两个通用规则:小端法&大端法
- 对表示一个对象的字节序列排序,有两个通用的规则。考虑一个w位的整数,有位表示 [ x w − 1 , x w − 2 , ⋯ , x 1 , x 0 ] [\left.x_{w-1},x_{w-2}, \cdots, x_{1}, x_{0}\right] [xw−1,xw−2,⋯,x1,x0],其中 x w − 1 x_{w-1} xw−1是最高有效位,而 x 0 x_{0} x0是最低有效位。假设w是8的倍数,这些位就能被分组成为字节,其中最高有效字节包含位 [ x w − 1 , x w − 2 , ⋯ , x w − 8 ] \left[x_{w-1}, x_{w-2}, \cdots, x_{w-8}\right] [xw−1,xw−2,⋯,xw−8],而最低有效字节包含位 [ x 7 , x 6 , ⋯ x 0 ] \left[x_{7}, x_{6}, \cdots x_0\right] [x7,x6,⋯x0],其他字节包含中间的位。某些机器选择在存储器中按照从最低有效字节到最高有效字节的顺序存储对象,而另一些机器则按照从最高有效字节到最低有效字节的顺序存储。前一种规则—–最低有效字节在最前面的方式被称为小端法(little endian)。大多数源自以前的Digital Equipment 公司(现在是Compaq公司的一部分)的机器,以及 Intel的机器都采用这种规则。后一种规则(最高有效字节在最前面的方式)被称为大端法(big endian)。IBM、Motorola和Sun Microsystems 的大多数机器都采用这种规则。注意我们说的是“大多数”。这些规则并没有严格按照企业界限来划分。比如,IBM制造的个人计算机使用的是Intel兼容的处理器,因此就是小端法。许多微处理器芯片,包括Alpha和Motorola的 PowerPC,能够运行在任一种模式中,其取决于芯片加电启动时确定的字节顺序规则。
- 继续我们前面的示例,假设变量x类型为int,位于地址0x100 处,有一个十六进制值为0x01234567。地址范围0x100~0x103的字节顺序依赖于机器的类型:
注意,在字0x01234567中,高位字节的十六进制值为0x01,而低位字节值为0x67。

3.字节顺序变得重要的三种情况
1)小端法机器产生的数据被发送到大端法机器或者反之时,接收程序会发现,字里的字节变成了反序。为了避免这类问题,网络应用程序必须建立关于字节顺序的规则,以确保发送机器将它的内部表示转换为网络标准,而接收方机器则将网络标准转换为它的内部表示。
2)字节顺序变得重要的第二种情况是当阅读表示整数数据的字节序列时。这通常发生在检查机器级程序时。作为一个示例,从某个文件中摘出了下面这行代码,该文件给出了一个针对Intel 处理器的机器级代码的文本表示: 80483 b d : 01 05 64 94 04 08 add % eax, 0 × 8049464
80483bd:010564940408 add % eax, 0×8049464
80483bd:010564940408 add % eax, 0×8049464这一行是由反汇编器((disassembler)生成的,反汇编器是一种确定可执行程序文件所表示的指令序列的工具。我们将在下一章中学习有关这些工具的更多知识,以及怎样解释像这样的行。而现在,我们只是注意这行表述了十六进制字节串01 05 64 94 04 08是一条指令的字节级表示,这条指令是增加一个字宽的数据到存储在主存地址Ox8049464的值上。如果我们取出这个序列的最后四字节:64940408,并且按照相反的顺序写出,我们得到08049464。去掉开头的零,我们就得到值Ox8049464,就是右边写着的数值。当阅读像此例中一样的小端法机器生成的机器级程序表示时,经常会将字节按照相反的顺序显示。书写字节序列的自然方式是最低位字节在左边,而最高位字节在右边,但是这和书写数字时最高有效位在左边,最低有效位在右边的通常方式是相反的。
3)字节顺序变得重要的第三种情况是当编写规避正常的类型系统的程序时。在C语言中,可以通过使用强制类型转换或者联合来允许以一种数据类型来引用一个对象,而这种数据类型与创建这个对象时的定义的数据类型不同。
2.1.5 表示字符串
- C语言中的字符串被编码成一个以null(其值为零)字符结尾的字符数组。每个字符都由某个标准编码来表示,最常见的是ASCII编码。
- 在使用ASCII码作为字符码的任何系统上运行show_bytes程序,都将得到相同的结果,与字节顺序和字的大小规则无关。
-因而文本数据比二进制数据具有更强的平台独立性。
2.1.6 表示代码
- 指令编码是不同的。
- 不同的机器类型使用不同的且不兼容的指令和编码类型。
- 完全一样的进程,运行在不同的操作系统上也有不同的编码规则。因此二进制代码是不兼容的。
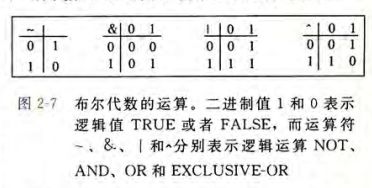
2.1.7 布尔代数简介
布尔代数:围绕数值0和1的数学知识体系。- 0和1的运算:
位向量的运算:
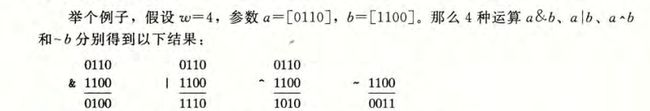
用位向量表示有限集合:
a = [ 01101001 ] 可 以 表 示 A = { 0 , 3 , 5 , 6 } a=[01101001]可以表示A=\{0,3,5,6\} a=[01101001]可以表示A={0,3,5,6} b = [ 01010101 ] 可 以 表 示 B = { 0 , 2 , 4 , 6 } b=[01010101]可以表示B=\{0,2,4,6\} b=[01010101]可以表示B={0,2,4,6} 布尔运算 ∣ | ∣和 & \& &分别对应于集合的并和交,而 ∼ \sim ∼对应于集合的补
2.1.8 C语言中的位级运算
- 示例

- 掩码运算:
- 例如: x = 0 x 89 A B C D E F 做 掩 码 运 算 x & 0 x F F = 0 x 000000 E F x=0x89ABCDEF做掩码运算x& 0xFF=0x000000EF x=0x89ABCDEF做掩码运算x&0xFF=0x000000EF
2.1.9 C语言中的逻辑运算
- 逻辑运算容易与位级运算混淆,注意比较以下例子:
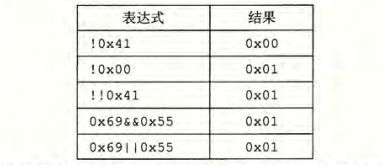
- 位级运算与逻辑运算的区别:
- 逻辑运算认为所有非零的参数都表示TRUE,参数零表示FALSE,返回值为1或者0.
- 逻辑运算符如果对第一个参数求值就能确定表达式的值,那么逻辑运算符就不会对第二个参数求值。
2.1.10 C语言中的移位运算
- 示例

- 移位运算从左往右可结合
- 右移运算包括
逻辑右移和算数右移
2.2 整数表示
2.2.1整数数据类型

2.2.2 无符号数编码

无符号编码属于相对较简单的格式,因为它符合我们的惯性思维,上述定义其实就是对二进制转化为十进制的公式而已,只不过在一向严格的数学领域来说,是要给予明确的含义的。
2.2.3 补码编码
最常见的有符号数的计算机表示方式就是补码形式。在这个定义中,将字的最高有效位解释为负权,我们用函数B2T来表示。java中使用的就是补码。

我们观察这个公式,不难看出,补码格式下,对于一个w位的二进制序列来说,当最高位为1,其余位全为0时,得到的就是补码格式的最小值,即
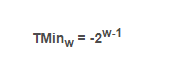
而当最高位为0,其余位全为1时,得到的就是补码格式的最大值,根据等比数列的求和公式,即
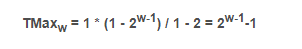
2.2.4 有符号数和无符号数之间的转换
在C语言当中,我们经常会使用强制类型转换,而在之前的章节中,也提到过强制类型转换。强制类型转换不会改变二进制序列,但是会改变数据类型的大小以及解释方式,那么考虑相同整数类型的无符号编码和补码编码,数据类型的大小是没有任何变化的,变化的就是它们的解释方式。比如1000这个二进制序列,如果用无符号编码解释的话就是表示8,而若采用补码编码解释的话,则是表示-8。
一、补码转换为无符号数:
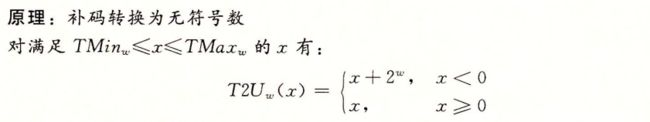
二、无符号数转换为补码:

2.2.5 C语言中的有符号数和无符号数
有符号数和无符号数的本质区别其实就是采用的编码不同,前者采用补码编码,后者采用无符号编码。
在C语言中,有符号数和无符号数是可以隐式转换的,不需要手动实施强制类型转换。不过也正是因为如此,可能你不小心将一个无符号数赋给了有符号数,就会造成出乎意料的结果,就像下面这样。
#include 输出结果为-12345,53191。一个不小心,一个负数就变成正数了。
再看下面这个程序,它展示了在进行关系运算时,由于有符号数和无符号数的隐式转换所导致的违背常规的结果。
#include 两个结果都为0,也就是false,这与我们直观的理解是违背的,由于C语言对同时包含有符号和无符号数表达式的这种处理方式,出现了一些奇特的行为。当执行一个运算时,如果它的一个运算数是有符号的而另一个是无符号的,那么C语言会隐式地将有符号参数强制类型转换为无符号数,并假设这两个数都是非负的,来执行这个运算。就像我们将要看到的,这种方法对于标准的算术运算来说并无多大差异,但是对于像<和>这样的关系运算符来说,它会导致非直观的结果。
2.2.6 扩展一个数字的位表示
当我们将一个短整型的变量转换为整型变量时,就涉及到了位的扩展,此时由两个字节扩充为四个字节。
在进行位的扩展时,最容易想到的就是在高位全部补0,也就是将原来的二进制序列前面加入若干个0,也称为零扩展。还有一种方式比较特别,是符号扩展,也就是针对有符号数的方式,它是直接扩展符号位,也就是将二进制序列的前面加入若干个最高位。
- 无符号数的零扩展:要将一个无符号数转换为一个更大的数据类型,我们只要简单地在表示的开头添加0。这种运算被称为零扩展。
- 补码数的符号扩展:要将一个补码数字转换为一个更大的数据类型,可以执行一个符号扩展,在表示中添加最高有效位的值。
对于零扩展来说,很明显扩展之后的值与原来的值是相等的,而对于符号扩展来说,也是一样,只不过没有零扩展来的直观。我们在计算补码时有一个比较简单的办法,就是符号位若为0,则与无符号是类似的。若符号位为1,也就是负数时,可以将其余位取反最终再加1即可。因此当我们对一个有符号的负数进行符号扩展时,前面加入若干个1,在取反之后都为0,因此依旧会保持原有的数值。
总之,在对位进行扩展时,是不会改变原有数值的。
2.2.7 截断数字
截断与扩展相反,它是将一个多位二进制序列截断至较少的位数,也就是与扩展是相反的过程。截断可能会导致数据的失真。
一、对于无符号编码来说,截断后就是剩余位数的无符号编码数值

二、 对于补码编码来说,截断后的二进制序列与无符号编码是一样的,因此我们只需要多加一步,将无符号编码转换为补码编码就可以了。

不难看出,具有有符号和无符号数的语言,可能会因此引起一些不必要的麻烦,而且无符号数除了能表示的最大值更大以外,似乎并没有太大的好处。因此有很多语言是不支持无符号数的。如Java语言,就只有有符号数,这样省去了很多不必要的麻烦。无符号数很多时候只是为了表示一些无数值意义的标识,比如我们的内存地址,此时的无符号数就有点类似于数据库主键或者说键值对中的键值的概念,仅仅是一个标识而已。
2.3 整数运算
2.3.1 无符号加法
考虑两个非负整数x和y,满足0<=x,y<2w-1。每个数都能表示为w位无符号数字。然而,如果计算它们的和,我们就有一个可能的范围0<=x+y<=2w+1-2。表示这个和可能需要w+1位。例如,图示展示了当x和y有4位表示时,函数x+y的坐标图。参数(显示在水平轴上)的取值范围为015,但是和的取值范围为030。如果保持和为一个w+1位的数字,并且把它加上另外一个数值,我们可能需要w+2个位,以此类推。这种持续的“字长膨胀”意味着,要想完整的表示算术运算的结果,我们不能对字长做任何限制。一些编程语言,例如Lisp,实际上就支持无限精度的运算,允许任意的(在机器的内存限制内)整数运算。更常见的是,编程语言支持固定精度的运算,因此像“加法”和“乘法”这样的运算不同于它们在整数上的相应运算。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DT43C3A8-1645022218653)(https://img2020.cnblogs.com/blog/988894/202005/988894-20200509234110363-652310600.png)]
让我们为参数x和y定义运算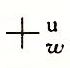 ,其中0<=x,y<2w,该操作是把整数和x+y截断为w位得到的结果,再把这个结果看做是一个无符号数。这可以被视为一种形式的模运算,对x+y的位级表示,简单丢弃任何权重大于2w-1的位就可以计算出和模2w。比如,考虑一个4位数字表示,x=9和y=12的位表示分别为[1001]和[1100]。它们的和是21,5位的表示为[10101]。但是如果丢弃最高位,我们就得到[0101],也就是说,十进制值的5。这就和值21mod16=5一致。
,其中0<=x,y<2w,该操作是把整数和x+y截断为w位得到的结果,再把这个结果看做是一个无符号数。这可以被视为一种形式的模运算,对x+y的位级表示,简单丢弃任何权重大于2w-1的位就可以计算出和模2w。比如,考虑一个4位数字表示,x=9和y=12的位表示分别为[1001]和[1100]。它们的和是21,5位的表示为[10101]。但是如果丢弃最高位,我们就得到[0101],也就是说,十进制值的5。这就和值21mod16=5一致。
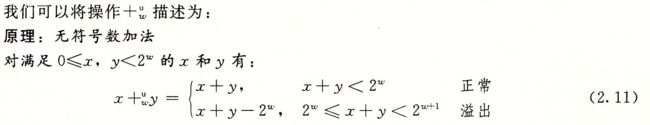
说明公式两种情况,左边的和x+y映射到右边的无符号w位的和x+ 。正常情况下x+y的值保持不变,而溢出情况则是该和数减去2w的结果。
。正常情况下x+y的值保持不变,而溢出情况则是该和数减去2w的结果。
推导:无符号数加法
一般而言,我们可以看到。如果 x+y<2w,和的w+1位表示中的最高位会等于0,因此丢弃它不会改变这个数值。另一方面,如果2w<=x+y<2w+1,和的w+1位表示中的最高位会等于1,因此丢弃它就相当于从和中减去了2w。
当执行C程序是,不会将溢出作为错误而发信号。不过有的时候,我们可能希望判定是否发生了溢出。
原理:检测无符号数加法中的溢出
对在范围0<=x,y<=UMaxw中的x和y,令s=x+ 作为说明,在前面的示例中,我们看到9+412=5。由于5<9,我们可以看出发生了溢出。 对于补码加法,我们必须确定当结果太大(为正)或者太小(为负)时,应该做些什么。给定在范围-2w-1<=x,y<2w-1-1之内的整数值x和y,它们的和范围-2w 当和x+y超过TMaxw时,我们说发生了正溢出。在这种情况下,截断的结果是从和数中减去2w。当和x+y小于TMinw时,我们说发生了正溢出。在这种情况下,截断的结果是把和数加上2w。 两个数的w位补码之和与无符号之和有完全相同的位级表示。实际上,大多数计算机使用同样的机器指令来执行无符号或者有符号加法。 我们看到范围在TMinw<=x<=TMaxw中的每个数字x都有 也就是说,对w位的补码加法来说,Tminw是自己的加法的逆,而对其他任何数值x都有-x作为其加法的逆。 推导:补码的非 观察发现TMinw+TMinw = -2w-1+(-2w-1)=-2w。这就导致负溢出,因此TMinw+ 范围在0 <=x,y<=2w-1内的整数x和y可以被表示为w位的无符号数,但是它们的乘积x*y的取值范围为0到(2w-1)2=22w-2w+1+1之间。这可能需要2w位来表示。不过,C语言中的无符号乘法被定义为产生W位的值,就是2W位的整数乘积的低w位表示的值。 将一个无符号数截断为w位等价于计算该值模2w,得到: 范围在-2w-1<=x,y<=2w-1-1内的整数x和y可以被表示为w位的补码数字,但是它们的乘积xy的取值范围为-2w-1(2w-1-1)=-22w-2+2w-1到-2w-1 *-2w-1 = -22w-2之间。要想用补码来表示这个乘积,可能需要2w位。然而,C语言中的有符号乘法是通过将2w位的乘积截断为w位来实现的。我们将这个数值表示为 以往,在大多数机器上,整数乘法指令相当慢,需要10个或者更多的时钟周期,然而其他整数运算(例如加法、减法、位级运算和移位)只需要一个时钟周期。即使在Inter Core i7上,其整数乘法也需要三个时钟周期。因此,编译器使用了一项重要的优化,试着用移位和加法运算的组合来代替乘以常数因子的乘法。首先,我们会考虑乘以2的幂的情况,然后再概况成乘以任意常数。 因此,比如,当w=4时,11可以被表示为[1011]。k=2时将其左移得到6位向量[101100],即可编码为无符号数11*4=44。 注意,无论是无符号运算还是补码运算,乘以2的幂都可能会导致溢出。结果表明,即使溢出的时候我们通过移位得到的结果也是一样的,如上例,我们将4位模式1011左移两位得到101100。将这个值截断为4位得到[1011](数值为12=44mod16)。 由于整数乘法比移位和加法的代价要大得多,许多C语言编译器试图以移位、加法和减法的组合来消除很多整数常数的情况。例如,假设一个程序包含表达式x*14。利用14=23+22+21,编译器会将乘法重写为(x<<3)+(x<<2)+(x<<1),将一个乘法替换为三个移位和两个加法。无论x是无符号的还是补码,甚至当乘法会导致溢出时,两个计算都会得到一样的结果。(根据整数运算的熟悉可以证明)。更好的是,编译器还可以利用属性14=24-21,将乘法重写为(x<<4)-(x<<1),这时只需要两个移位和一个减法。 在大多数机器上,整数除法要比整数乘法更慢–需要30个或者更多的时钟周期。除以2的幂也可以用移位运算来实现。只不过用的是右移,而不是左移。无符号和补码数分别使用逻辑移位和算术移位来达到目的。 计算机执行的“整数”运算实际上是一种模运算形式。表示数字的有限字长限制了可能的值的取值范围,结果运算可能溢出。我们还看到,补码表示提供了一种既能表示负数也能表示正数的灵活方法,同时使用了与执行无符号算术相同的位级实现,这些运算包括像加法、减法、乘法,甚至除法,无论运算数是以无符号形式还是以补码形式表示的,都有完全一样或者非常类似的位级行为。 我们看到了C语言中的某些规定可能会产生令人意想不到的结果,而这些结果可能是难以察觉或理解的缺陷的源头。我们特别看待了unsigned数据类型,虽然它概念上很简单,但可能导致即使资深程序员都意想不到的行为。 理解浮点数的第一步是考虑含有小数值的二进制数字。首先,我们来看看更熟悉的十进制表示法。十进制表示法使用如下形式的表示:dmdm-1…d1d0.d-1d-2d-n。其中每个十进制数di的取值范围是0~9。这个表达描述的数值d定义如下: 数字权的定义与十进制小数点符号(’.’ ),这意味着小数点左边的数字的权是10的正幂,得到整数值,而小数点右边的数字的权是10的负幂,得到小数值。例如,12.3410表示数字1101+2100+310-1+410-2= 类似,考虑一个形如bmbm-1…b1b0.b-1b-2…b-n-1b-n的表示法,其中每个二进制数字,或者成为位,bi的范围是0和1,这种表示方法表示的数b的定义如下: 符号’.’ 现在变成了二进制的点,点左边的位的权是2的正幂,点右边的权是2的负幂。例如,101.112表示数字122+021+120+12-1+1*2-2= 从上式可以看出,二进制小数点向左移动一位相当于这个数被2除。例如,101.112表示数 注意,形如0.11…12的数表示的是刚好小于1的数。例如,0.1111112表示 假定我们仅考虑有限长度的编码,那么十进制表示法不能准备地表达像1/3和5/7这样的数。类似,小数的二进制表示法只能表示那些能够被写成x*2y的数。其他的值只能够被近似地表示。例如,数字1/5可以用十进制小数0.20精确表示。不过,我们并不能把它准备地表示为一个二进制小数,我们只能近似的表示它,增加二进制的长度可以提高表示的精度。 练习题2.45 填写下表中的缺失的信息 回到顶部 定点表示法不能很有效的表示非常大的数字。例如,表达式52100是用101后面跟随100个零的位模式来表示。相反,我们希望通过给定x和y的值,来表示形如x2y的数。 IEEE浮点标准用V=(-1)sM2E的形式来表示一个数: 图示给出了将三个装进字中最常见的格式。在单精度浮点格式(C语言中的float)中,s、exp、和frac字段分别为1位、k=8和n=23位,得到一个32位的表示。在双进度浮点格式(C语言的double)中,s、exp和frac字段分别为1位、k=11位和n=52位,得到一个64位的表示 给定位表示,根据exp的值,被编码的值可以分成三种不同的情况(最后一种情况有两个变种) 情况1:规格化的值 当exp的位模式即不全是0(数值0),也不全为1(单精度数值为255,双精度数值为2047)时,都属于这类情况。在这种情况下,阶码字段被解释为以偏置(biased)形式表示的有符号整数。也就是说,阶码的值是E=e-Bias,其中e是无符号数,其位表示为ek-1…e1e0,而Bias是一个等于2k-1-1(单精度是127,双精度是1023)的偏置值。由此产生指数的取值范围,对于单精度是-126+127,而对于双精度是-1022+1023。 小数字段frac被解释为描述小数值f,其中0<=f<1,其二进制表示为0.fn-1…f1f0,也就是二进制小数点在最高有效位的左边。尾数定义为M=1+f。有时,这种方式也叫做隐含的以1开头的表示,因此我们可以把M看成一个二进制表达式为1.fn-1fn-2…f0的数字。既然我们总是能够调整阶码E,使得尾数M在范围1<=M<2之中,那么这种表示方法是一种轻松获得额外精度位的技巧。既然第一位总是等于1,那么我们就不需要显示地表示它。 情况2:非规格化的值 当阶码域为全0时,所表示的数是非规格化形式。在这种情况下,阶码值是E=1-Bias,而尾数的值是M=f,也就是小数字段的值,不包含隐含的开头的1。 非规格化数有两个用途。首先,它们提供了一种表示数值0的方法,因为使用规格化数,我们必须总是使M>=1,因此我们就不能表示0。实际上,+0.0的浮点表示的位模式为全0;符号位是0,阶码字段全是0(表明是一个非规格化值),而小数域也全是0,这就是得到M=f=0。令人奇怪的是,当符号位位1,而其他域全是0时,我们得到值-0.0。根据IEEE的浮点格式,值+0.0和-0.0在某些方面被认为是不同的,而在其他方面是相同的。 非规格化的另外一个功能是表示那些非常接近于0.0的数。它们提供一种熟悉,称为逐渐溢出,其中,可能的数值分布均匀的接近于0.0。 情况3:特殊值 最后一类数值时当指阶码全为1的时候出现的。当小数域全为0时,得到的值表示无穷,当s=0时是+* 回到顶部 图示展示了一组数值,它们可以用假定的6位格式来表示,有k=3的阶码位和n=2的尾数位。偏置量是23-1-1=3。图示a部分显示了所有可表示的值(除了NaN)。两个无穷值在两个末端。最大数量值的规格化数 图示展示了假定的8位浮点格式的示例,其中有k=4的阶码位和n=3的小数位。偏置量是24-1-1=7。图被分成了三个区域,来描述三类数字。不同的列给出了阶码字段是如何编码阶码E的,小数字段是如何编码尾数M的,以及它们一起是如何形成要表示的值V=2EM的。从0自身开始,最靠近0的是非规格化数。这种格式的非规格化数的E=1-7=-6,得到权2E=1/64。小数f的值范围是0,1/8,…,7/8,从而得到数V的范围是0~1/647/8=7/512。 这种形式的最小规格化数同样有E=1-7=-6,并且小数取值范围也是0,1/8,…7/8。然而,尾数在范围1+0=1和1+7/8=15/8之间,得出数V在范围8/512=1/16和15/512之间。 可以观察到最大非规格化数7/512和最小非规格化数8/512之间的平滑转变。这种平滑性归功于我们对非规格化数的E的定义。通过将E定义为1-Bias,而不是-Bias,我们可以补偿非规格化数的尾数没有隐含的开头1。 当增大阶码时,我们成功地得到更大的规格化值,通过1.0后得到最大的规格化数。这个数具有阶码E=7,得到一个权2E=128。小数等于7/8得到尾数M=15/8。因此,数值是V=240。超过这个值就会 溢出到+ 图示展示了一些重要的单精度和双精度浮点数的表示和数字值。 当我们用以下命令编译C语言程序时: 上面代码通过以下命令编译: 会生成汇编文件mstore.s,内容如下: mstore.s 可以使用"-c"选项再将其汇编成二进制目标文件: 生成的.o文件中对应汇编指令的目标代码实际上只是一个字节序列,也就是说机器对存储在内存中的指令和数据都是一无所知的。 使用objdump工具对.o文件进行反汇编处理: objdump反汇编结果 可以看到每一组的1-5个十六进制字节值对应了一个汇编指令。 如果要生成实际可执行的代码,需要对目标代码文件运行链接器,而目标代码文件中必须得有main函数。 对上面的代码进行编译后再反汇编 生成的汇编代码包括下面这段: objdump -d prog反汇编可执行程序代码段 C语言数据类型在X86-64中的大小,64位机器中指针占8个字节。 C语言数据类型在X86-64中的大小 一个x86-64 位的中央处理单元(CPU )中包含一组 16 个存储 64 位值的通用目的寄存器,用来存储整数和指针。 备注:调用参数超过6个,就需要在栈上申请空间存储参数。 低位操作的规则: 16个寄存器的作用 指令的操作数有三种类型: 操作数格式如下: 加深理解: 假设下面的值存放在指明的内存地址和寄存器中: 答案: 最简单形式的数据传送指令——MOV类,将数据从源位置复制到目的位置,不做任何变化。 mov 类有 5 种: 规则: movz类 局部变量通常保存在寄存器中。 栈向下增长,栈顶的地址是栈中元素地址中最低的。栈指针 rsp 保存栈顶元素的地址。 x86-64 的每个指令类都有对应四种不同大小数据的指令。 算术和逻辑操作共有四组: leaq 实际上是 movq 指令的变形。操作是从内存读数据地址到寄存器。 leaq 在实际应用中常常不用来取地址,而用来计算加法和有限形式的乘法 leaq 7(%rdx, %rdx, 4), %rax;//将设置寄存器%rax的值为5x + 7 进一步,举例说明: 一元操作中的操作数既是源又是目的。 移位操作的移位量可以是一个立即数或放在单字节寄存器 %cl 中。 两个 64 位数的乘积需要 128 位来表示,x86-64指令集可以有限的支持对 128 位数的操作,包括乘法和除法,Intel把16字节的数称为八字(oct word)。(乘积存放在寄存器%rdx(高64位)和%rax(低64位)中) 128 位数需要两个寄存器来存储,移动时也需要两个 movq 指令来移动。 这种情况对于有符号数和无符号数采用了不同的指令。 支持产生两个64位数字的全128位乘积以及整数除法的指令: 条件语句、循环语句、分支语句都要求有条件的执行。 机器代码提供两种低级机制来实现有条件的行为: 条件码寄存器都是单个位的,是不同于整数寄存器的另一组寄存器。 条件码描述了最近的算术或逻辑操作的属性,可以通过检测这些寄存器来执行条件分支指令。 常用条件码: 除了 leaq 指令外,其余的所有算术和逻辑指令都会根据运算结果设置条件码。 此外还有两类特殊的指令,他们只设置条件码不更新目的寄存器: 条件码一般不直接读取,常用的使用方法有 3 种: set 指令类 set 指令的目的操作数是低位单字节寄存器元素或一个字节的内存位置。set 会将该字节设置为 0 或 1 set 指令类的后缀指明了所考虑的条件码的组合,如 setl (set less) 表示“小于时设置”。 set指令集合如下: 注意到上图中,set 指令对于大于、小于的比较分为了有符号和无符号两类。 大多数时候,机器代码对无符号和有符号两种情况使用一样的指令。 使用不同指令来处理无符号和有符号操作的情况: 汇编语言中数据本身不区分有符号和无符号,通过不同的指令来区分有符号操作和无符号操作。 跳转指令会导致执行切换到程序中一个全新的位置,这些跳转的目的地通常用一个标号指明。 示例代码: jmp 可以是直接跳转,即操作数为标号。也可以间接跳转,即操作数是寄存器或内存引用,这种情况下跳转到寄存器中存储的地址处。 跳转指令分为有条件跳转和无条件跳转,只有 jmp 是无条件跳转。有条件跳转都只能是直接跳转。 有条件跳转类似 set 指令系列,根据条件码寄存器的值来判断是否进行跳转。 jump的指令集合如下: 跳转指令的机器编码(就是纯粹数字表示的机器语言)有几种方式,其中两种如下: PC 相对跳转:使用目标地址与跳转指令之后下一条指令的地址之间的差来编码。可以用 1、2 或 4 个字节来编码。 绝对地址编码:使用目标的绝对地址。用 4 个字节直接指出。 汇编器和链接器会自己选择适当的编码方式。 汇编代码层面的条件控制类似于 c 语言的 goto 语句。 汇编语言使用条件码和条件跳转来起到和 c 语言中 if 相似的作用 实现条件操作的传统方法是通过使用控制的条件转移。当条件满足时,程序沿着一条执行路径执行,而当条件不满足时,就走另外一条路径。这种机制简单而通用,但是在现代处理器上,它可能会非常低效。 一种替代的策略是使用数据的条件转移。这种方法计算一个条件操作的两种结果,然后根据条件是否满足从中选取一个。 为了理解为什么基于条件数据传送的代码会比条件控制转移的代码性能要好? —— 处理器通过使用流水线来获得高性能,在流水线中,一条指令的处理要经过一系列的阶段,每个阶段执行所需操作的一小部分(例如,从内存取指令、确定指令类型、从内存读数据、执行算术运算、向内存写数据,以及更新程序计数器)。这种方法通过重叠连续指令的步骤来获取高性能。 当机器遇到条件跳转,只有当分支条件求值完成后,才能决定分支往哪边走。(分支预测错误会带来性能的严重下降) 在一个典型的应用中,x < y 的结果非常地不可预测,仅有50%概率,从而导致每次调用的平均时钟周期会变大。 条件传送指令集如下: C 语言提供了多种循环结构,即 do-while、while 和 for,汇编中没有相应的指令存在,可以用条件测试和跳转组合起来实现循环的效果。 如通用 do-while 形式 可以通过下面组合完成 switch 通过一个整数索引值进行多重分支,处理具有多种可能结果的测试时特别有用: 跳转表是一个数组,表项 i 是一个代码段的地址,当开关索引等于 i 时进行此部分代码段的操作。 过程是软件中一种很重要的抽象。它提供了一种封装代码的方式,用一组指定的参数和一个可选的返回值实现了某种功能。 然后,可以在程序中不同的地方调用这个函数。设计良好的软件用过程作为抽象机制,隐藏某个行为的具体实现,同时又提供清晰简洁的接口定义,说明要计算的是哪些值,过程会对程序状态产生什么样的影响。 不同编程语言中,过程的形式多种多样:函数(function)、方法(method)、子例程(subroutine)、处理函数(handler)等等。 假设过程P调用过程Q,Q执行完后返回到P: 程序可以用栈来管理它的过程所需要的存储空间,栈和程序寄存器存放着传递控制和数据、分配内存所需要的信息。 Q栈帧:Q的代码可以保存寄存器的值,分配局部变量空间 P中定义的变量要放在P的栈帧里。如果调用Q,把这些值再复制到寄存器中。 P最多传递六个整数值,如果多了,可以在调用Q之前把参数放在自己的栈帧里 将控制从函数P转移到函数Q只需要简单地把程序计数器PC设置为Q的代码的起始位置。不过,当稍后从Q返回的时候,处理器必须记录好它需要继续P的执行的代码位置。 在X86-64机器中,这个信息是用 call Q 调用过程Q来记录的。该指令会把地址A压入栈中,并将PC设置为Q的起始地址。压入的地址A被称为返回地址,是紧跟在call指令后面的那条指令的地址。对应的指令ret会从栈中弹出地址A,并把PC设置为A。 下面给出的是call和ret指令的一般形式: 当调用一个过程时,除了要把控制传递给它并在过程返回时再传递回来之外,过程调用还可能包括把数据作为参数传递,而从过程返回还有可能包括返回一个值。 在x86-64中,大部分过程间的数据传送是通过寄存器实现的,例如当过程P调用过程Q时,P的代码要把参数复制到适当的寄存器,多于6个放在自己栈帧里。类似地,当Q返回到P时,P的代码可以访问寄存器%rax中的返回值。 大部分过程示例都不需要超出寄存器大小的本地存储区域。不过有些时候,局部数据必须存放在内存中,常见的情况包括: 示例如下: 当P调用Q传递参数的时候,使用leaq语句,传递的是%rsp代表的地址 寄存器组是唯一被所有过程共享的资源。虽然在给定时刻只有一个过程是活动的,但是我们必须确保:调用者调用被调用者时,被调用者不会覆盖稍后调用者会使用的寄存器。 被调用者保护寄存器,%rbx,%rbp,%r12~15, 实现方法:要么不去改变那个寄存器,要么把原始值压入栈中,改变寄存器,最后弹出原始值。 每个过程调用在栈中都有它自己的私有空间,因此多个未完成调用的局部变量不变相互影响。此外,栈的原则很自然地就提供了适当的策略,当过程被调用时分配局部存储,当返回时释放存储。 递归的阶乘函数示例如下: 对于数组 T A[N], L 为数据类型 T 的大小,首先它在存储器中分配一个 L * N 字节的连续区域,用 Xa 指向数组开头的指针,数组元素 i 会被存放在地址为 Xa + L* i 的地方。 一维数组: 二维数组 T D [R] [C]; 访问数组: Xd+(i * C + j )* L C 语言中用 struct 声明创建一个数据类型,将可能不同类型的对象聚合在一个对象中,结构的各个组成部分用名字来引用。 类似于数组,结构的所有组成部分都存放在存储器的一段连续区域内,而指向结构的指针就是结构第一个字节的地址。编译器维护关于每个结构类型的信息,指示每个字段的偏移。机器代码不包含关于字段声明或字段名字的信息。 struct字节对齐示例如下: b之所以要字节填补7个字节,是因为c是8字节。 允许以多种类型来引用一个对象。联合声明的语法与结构的语法一样,只不过语义相差比较大。它们是用不同的字段来引用相同的存储器块。 一个联合的总的大小等于它最大字段的大小。 许多计算机系统对基本数据类型的合法地址做出了一些限制,要求某种类型对象的地址必须是某个值K(通常是2、4或8)的倍数。这种对齐限制简化了形成处理器和内存系统之间接口的硬件设计。 对齐原则如下: 指针是C语言的核心特殊,以一种统一的方式,对不同数据结构中的元素产生引用。 指针的原则: GNU的调试器GDB提供了许多有用的特性,支持机器级程序的运行时评估和分析。 使用以下命令启动GDB 内存越界访问: c对于数组指针引用不进行任何边界检查,且局部变量和状态信息都存放在栈中。此两种情况结合在一起可能导致严重的程序错误,对越界的数组元素的写操作会破坏存储在栈中的状态信息。当程序使用这个被破坏的状态,试图重新加载寄存器或执行ret指令,就会出现严重的错误。 缓冲区溢出: 在栈中分配某个字符数组来保存一个字符串,但是字符串的长度超过了为数组分配的空间。 程序示例: gets()函数的问题是无法确定是否为保存整个字符串分配了足够的空间。 echo的汇编代码: 该程序在栈上分配了24个字节,字符数组buf位于栈顶,%rep被复制到%rdi作为调用gets和puts的参数。调用的参数和存储的返回指针之间的16个字节未被使用,根据用户输入字符大小,可得到一下表格: 如果存储的返回地址的值被破坏了,那么ret指令会导致程序跳转到一个意想不到的位置,会出现缓冲区漏洞。有时会使程序执行它本来不愿意执行的函数,从而对计算机网络系统进行攻击。 对抗这种攻击有几种常用方法: 1.栈随机化,即程序开始时,在栈上随机分配一段0-n字节间的随机大小的空间(可用alloca实现),程序不使用这段空间,这样,通过浪费一段空间,可以使程序每次执行时后续的栈位置发生变化。然而这种方式仍有着被破解的可能,攻击者可以在攻击代码前放许多nop指令,这些指令唯一的作用就是指向下一条指令,假设本来栈随机化后栈空间地址的变化范围达到了223个字节,本来要精确地将返回地址改到攻击代码入口的对应的地址需要“精确投放”,即要尝试枚举223种可能,现在攻击代码加上这一堆nop指令,假设达到了28=256个字节,代表只要返回地址指向这些指令中的任何一条,都会导致最后进入攻击代码,因此只要枚举215种可能就行了,因此栈随机化不大保险。 2.栈破坏检测,基本思路是在栈的局部缓冲区插入一个哨兵值(金丝雀值),它在程序每次运行时随机产生(比如可以从内存中某个地方取得),在函数返回以及恢复寄存器的值之前,程序会先检测哨兵值是否被改变,若改变了则程序异常终止。 3.限制可执行代码区域,即限制只有保存编译器产生的代码的那部分内存才是可执行的,其他内存区域被限制为只允许读和写。 当声明一个局部变长数组时,编译器无法一开始就确定栈帧的大小,要为之分配多少内存空间,因此需要用变长栈帧。 下面看一个实例,比较难: 变长数组意味着在编译时无法确认栈帧的大小。 处理器的浮点系统结构包括多个方面,会影响对浮点数据操作的程序如何被映射到机器上,包括: 如图所示,AVX 浮点体系结构允许数据存储在 16 个 YMM 寄存器中,名字是 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MF9DIKj9-1645022218680)(https://raw.githubusercontent.com/xingyys/myblog/main/posts/images/20210913085612.png)] 浮点数和整数数据类型之间以及不同浮点格式之间进行转换的指令集合。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EgP9ECTI-1645022218681)(https://raw.githubusercontent.com/xingyys/myblog/main/posts/images/20210913091445.png)] 把一个从 XMM 寄存器或内存中读出的浮点值进行转换,并将结果写入一个通用寄存器。把浮点值转换成整数时,指令会执行截断(truncation),把值向 0 进行舍入。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mDPNedvV-1645022218682)(https://raw.githubusercontent.com/xingyys/myblog/main/posts/images/20210913091717.png)] 在 当函数包含指针、整数和浮点数混合的参数时,指针和整数通过通用寄存器传递,而浮点值通过 XMM 寄存器传递。也就是说,参数到寄存器的映射取决于它们的类型和排列的顺序。例如: 下图描述了一组执行算术运算的标量 AVX2 浮点指令。每条指令有一个(S1S_1S1)或两个(S1,S2S_1, S_2S1,S2),和一个目的操作数 D。第一个源操作数 S1S_1S1 可以是一个 XMM 寄存器或一个内存位置。第二个源操作数和目的操作数都必须是 XMM 寄存器。每个操作多有一条针对当精度的指令和一条针对双精度的指令。结果存放在目的寄存器中。 和整数运算操作不同,AVX 浮点操作不能以立即数值作为操作数。相反,编译器必须为所有的常量值分配和初始化存储空间。然后代码再把这些值从内存读入。 浮点比较指令会设置三个条件码: 零标志位 ZF, 进位标志位 CF 和奇偶标志位 PF。 概念:多个具有不同容量、成本和访问时间。的存储设备构成了存储器层次结构,称为存储器系统。 执行指令时访问数据所需的周期数: CPU寄存器:0个周期 因为访问数据在各个存储器层次中的所需时间差异,促使使用者理解数据是如何在存储器层次结构中上下移动的,这样编写应用程序时,使得它们的数据项存储在层次结构较高的地方,CPU就能更快地访问。 几种基本的存储技术: SRAM 将每个位存储在一个双稳态的存储器单元内。每个单元由六个晶体管电路来实现的。 DRAM 将每个位存储为对一个电容的充电。每个 DRAM 单元由一个电容和一个访问晶体管组成。 只要有供电,SRAM就会保持不变,与DRAM不同,它不需要刷新。SRAM的存取比DRAM快。SRAM对诸如光和电噪声这样的干扰不敏感。代价是SRAM单元比DRAM单元使用更多的晶体管,因而密集度低,而且更贵,功耗更大。 DRAM 芯片被分为 d 个超单元,每个超单元包含 w 个 DRAM 单元,w 一般为 8。当从 DRAM 中读取数据时,一次可以读取一个超单元的数据(可以近似的将超单元理解为一个字节)。 一个16X8的DRAM芯片的组织结构体如下: DRAM 中的超单元按行列组织,DRAM 中还包含一个行缓冲区。 电路设计者将DRAM组织成二维阵列而不是线性数组的一个原因是降低芯片上地址引脚的数量。例如,128位DRAM被组织成一个16个超单元的线性数组,地址为0-15,那么芯片会需要4个地址引脚而不是2个。二维阵列组织的缺点是必须分两步发送地址,这增加了访问时间。 许多 DRAM 芯片封装在内存模块中,插到主板的扩展槽上。 主存由多个内存模块连接到内存控制器聚合成。 有一些经过优化的 DRAM: 现在计算机使用的大多数都是 DDR3 SDRAM。 DRAM 和 SRAM 会在断电后丢失信息,因此是易失性存储器。ROM 是非易失性存储器,在断电后仍保存着信息。 几种常见的非易失性存储器: 存储在 ROM 设备中的程序通常称为固件,当计算机系统通电后,会运行存储在 ROM 中的固件。 数据流通过总线在处理器与主存间来往,每次处理器和主存间的数据传送的一系列步骤称为总线事务。 总线是一组并行的导线,能携带地址、数据和控制信号。 系统总线连接 CPU 和 IO 桥接器,内存总线连接 IO 桥接器和主存。IO 桥同时也连接着 I/O 总线。 读事务的三个步骤: 写事务的三个步骤: 磁盘由盘片组成,每个盘片有两个表面,表面上覆盖着磁性记录材料。一个磁盘包含一个或多个盘片。 决定磁盘容量的因素: 磁盘容量公式: DRAM 和 SRAM 相关的单位中 K = 2^10,磁盘、网络、速率、吞吐量相关的单位中 K=10^3。 磁盘用读写头来读写存储在磁性表面的位。每个表面都有一个读写头,任何时候所有的读写头都位于同一个柱面上。 旋转时间一般和寻道时间差不多,而传送时间相对可以忽略不计,因此从磁盘读取一个扇区的时间约为 10 ms。 系统总线与内存总线都是与 CPU 相关的,而 IO 总线与 CPU 无关。Intel 的外部设备互连总线(PCI)就是一种 IO 总线。 连接到 IO 总线的三种设备: 6、访问磁盘 假设磁盘控制器映射到端口 0xa0,读一个磁盘扇区的步骤如下: CPU从磁盘读取数据: 固态硬盘 (Solid State Disk,SSD) 是一种基于闪存的存储技术。 一个闪存由 B 个块的序列组成,每个块由 P 页组成,页的大小为 512byte~4kb。数据以页为单位进行读写。 SSD 相比于旋转磁盘的优点:由半导体存储器构成,没有移动部件,所以更结实,随机访问也更快,能耗更低。 性能上:SRAM > DRAM > SSD > 旋转磁盘 局部性是程序的一个基本属性。具有良好局部性的程序倾向于重复地访问相同的数据 (时间局部性),或倾向于访问邻近的数据 (空间局部性),因此运行更快。 局部性有两种形式:时间局部性和空间局部性。 程序员应该理解局部性原理,因为一般而言,有良好局部性的程序比局部性差的程序运行得更快。现代计算机系统的各个层次,从硬件到操作系统,到应用程序,它们的设计都利用了局部性。 上例中,sum 具有好的时间局部性,向量 v 具有好的空间局部性。 程序指令存放在内存中,CPU 需要读这些指令,因此取指令也有局部性。比如 for 循环中的指令具有好的时间局部性和空间局部性。 存储技术:不同存储技术的访问时间差异很大。速度较快的技术每字节的成本要比速度较慢的技术高,而且容量较小。CPU和主存之间的速度差距在增大。 计算机软件:一个编写良好的程序更倾向于展示良好的局部性。 典型的存储器层次结构: 存储器层次结构的核心思想:第 k 层作为第 k+1 层存储设备的缓存。 缓存的具体实现:第 k+1 层的存储器被划分为连续的块,每个块有唯一的地址或名字。第 k 层的存储器被划分为较少的块的集合,每个块的大小与 k+1 层的块大小一样。数据以块为传输单元在不同层之间复制。 层次结构中更低的层,因为访问时间更长,为了补偿访问时间,使用的块更大。 缓存命中 当需要 k+1 层的某个数据对象 d 时,如果 d 恰好缓存在 k 层中,就称为缓存命中。 缓存不命中 缓存不命中的种类 缓存管理 寄存器文件的缓存由编译器管理,L1,L2,L3 的缓存由内置在缓存中的硬件逻辑管理,DRAM 主存作为缓存由操作系统和 CPU 上的地址翻译硬件共同管理。 L1 高速缓存的访问速度约为 4 个时钟周期,L2 约 10 个周期,L3 约 50 个周期。 当 CPU 执行一条读内存字 w 的指令,它首先向 L1 高速缓存请求这个字,如果 L1 没有就向 L2,依此而下。 假设一个计算机系统中的存储器地址有 m 位,形成 M =2^m 个不同的地址。m 个地址为划分为 t 个标记位,s 个组索引位,b 个块偏移位。 高速缓存被组织成 S=2^s 个高速缓存组,每个组包含 E 个高速缓存行,每个行为一个数据块,包含一个有效位,t=m-(b+s) 个标记位,和 B=2^b 字节的数据块。高速缓存的容量 = S * E * B。高速缓存可以通过简单地检查地址位来找到所请求的字。 当 CPU 要从地址 A(由m个地址位组成) 处读一个字时: 高速缓存参数标识: 根据每个组的高速缓存行数E,高速缓存有以下几类: 假设一个系统中只有 CPU、L1 高速缓存和主存。当 CPU 执行一条从内存读字 w 的指令,如果 L1 有 w 的副本,就得到 L1 高速缓存命中;如果 L1 没有,就是缓存不命中。当缓存不命中,L1 会向主存请求包含 w 的块(L1 中的块就是它的高速缓存行)的一个副本。当块从内存到达 L1,L1 将这个块存在它的一个高速缓存行里,然后从中抽取出字 w,并返回给 CPU。 高速缓存确定一个请求是否命中,然后抽取出被请求的字的过程分为三步: 6.4.2 直接映射高速缓存 1、直接映射高速缓存中的组选择 从 w 的 m 位地址中抽取出 s 个组索引位,并据此选择相应的高速缓存组。 2、直接映射高速缓存中的行匹配 因为直接映射高速缓存每个组只有一行,只要这一行设置了有效位且标记位相匹配,就说明想要的字的副本确实存储在这一行中。 3、直接映射高速缓存中的字抽取 从 w 的地址中抽取出 b 个块偏移位,块偏移位提供了所需的字的第一个字节的偏移。 4、直接映射高速缓存不命中时的行替换 缓存不命中时需要从下一层取出被请求的块,然后将其存储在组索引位指示的组中的高速缓存行中。 因为直接映射高速缓存每个组只有一行,所以替换策略很简单:用新取出的行替换当前行。 5、运行中的直接映射高速缓存 标记位和索引位连接起来标识了整个内存中的所有块,而高速缓存中的高速缓存组(块)是少于内存中的块数的。因此位于不同标记位,相同组索引位的块会映射到高速缓存中的同一个高速缓存组。 在一个高速缓存组中存储了哪个块,可以由标记位唯一地标识。 理解:对于主存中的整个地址空间,根据标记位不同将其分为了若干个部分,每个部分可以单独且完整地映射到高速缓存中,且刚好占满整个直接映射高速缓存。 6、直接映射高速缓存中的冲突不命中 冲突不命中在直接映射高速缓存中很常见。因为每个组只有一行,不同标记位的块会映射到同一行,发生冲突不命中。 为什么用中间的位来做索引? 如果用高位做索引,那么一些连续的内存块就会被映射到相同的高速缓存块。顺序访问数组元素时,任意时刻,高速缓存都只能保存一个块大小的数据内容。相比较而言,以中间位作为索引,相邻的块总是映射到不同的高速缓存行。 1、组相联高速缓存中的组选择 与直接映射高速缓存一样,组索引位标识组。 2、组相联高速缓存中的行匹配 组相联高速缓存中的行匹配更复杂,因为要检查多个行的标记位和有效位,以确定其中是否有所请求的字。 注意:组中的任意一行都可能包含映射到这个组的内存块,因此必须搜索组中的每一行,寻找一个有效且标记位相匹配的行。 3、组相联高速缓存中的字抽取 与直接映射高速缓存一样,块偏移位标识所请求的字的第一个字节。 4、组相联高速缓存中不命中时的行替换 几种替换策略 因为存储器层次结构中越靠下,不命中开销越大,好的替换策略越重要。 全相联高速缓存由一个包含所有高速缓存行 (E=C/B) 的组组成。 因为高速缓存电路必须并行地搜索不同组已找到相匹配的标记,所以全相联高速缓存只适合做小的高速缓存。 DRAM 主存采用了全相联高速缓存,但是因为它采用了虚拟内存系统,所以在进行类似行匹配的页查找时不需要对一个个页进行遍历。 1、全相联高速缓存中的组选择 全相联高速缓存中只有一个组,所以地址中没有组索引位,只有标记位和块偏移位。 2、全相联高速缓存中的行匹配和字抽取 与组相联高速缓存一样。与组相联高速缓存的区别在于规模大小 写相比读要复杂一些。 写命中(写一个已经缓存了的字 w)的情况下,高速缓存更新了本层的 w 的副本后,如何处理低一层的副本有两种方法: 写不命中情况下的两种方法: 直写一般与非写分配搭配,两者都更适用于存储器层次结构中的较高层。 写回一般与写分配搭配,两者都更适用于存储器层次结构中的较低层,因为较低层的传送时间太长。 因为硬件上复杂电路的实现越来越容易,所以现在使用写回和写分配越来越多。 三种高速缓存: 现代处理器一般包括独立的 i-cache 和 d-cache,其中两个原因如下: Core i7 的高速缓存层次结构及其特性: Core i7 高速缓存层次结构的特性: 可以看到 Core i7 中的高速缓存采用的都是组相联高速缓存。 高速缓存的性能指标 几个影响因素 链接( linking)是将各种代码和数据片段收集并组合成为一个单一文件的过程,这个文件可被加载(复制)到内存并执行。 链接在以下三个阶段都可以执行: 现代系统中,链接是由 链接器 自动执行的。链接器使 分离编译 成为可能,而分离编译正是大型项目所必不可缺的。 后续讨论基于这样的环境:一个运行Linux的X86-64系统,使用标准的 ELF-64 (简称ELF)目标文件格式。 编译器驱动程序可以使用户根据需要调用语言预处理器、编译器、汇编器和链接器。 使用GNU编译系统构建上述的示例程序: 具体执行内容为: 要运行可执行文件prog,直接在Linux shell命令行输入它的名称即可 shell调用操作系统中一个叫做 加载器(loader)的函数,它可以将可执行文件prog中的代码和数据复制到内存,然后将控制转移到这个程序的开头 。 像 Linux LD程序这样的静态链接器 以一组可重定位目标文件和命令行参数作为输入,生成一个完全链接的、可以加载和运行的可执行目标文件作为输出 。 为了构造可执行文件,链接器必须完成两个主要任务: 。 符号定义:目标文件定义和引用符号,每个符号对应于一个函数、一个全局变量或一个静态变量。 符号解析的目的:将每个符号引用正好和一个符号定义关联起来。 重定位( relocation) 。 一个目标文件又称目标模块。目标文件纯粹是字节块的集合。目标文件本身是一个字节序列。这些字节块中有些包含程序代码或程序数据,其他的则包含引导链接器和加载器的数据结构。链接器把这些块连接起来,确定被连接块的运行时位置,并修改代码和数据块中的各种位置。 目标文件有三种形式: 可重定位目标文件由多个不同的节组成,每一节都是一个连续的字节序列。指令、初始化了的全局变量、未初始化的的变量分别位于不同的节。 ELF可重定位目标文件的格式如下: 一个 ELF 可重定位文件中包含以下节(按位置顺序排列): 注意局部变量在运行时保存在栈中,既不出现在 .data 节中,也不出现在 .bss 节中。 重定位的核心就是对符号表进行符号解析 每个可重定位目标模块 m 都有一个符号表(即 .symtab 节),包含着 m 定义和引用的符号的信息。 在链接器的上下文中,有三种不同的符号: 对照 C++ 的语法来理解什么是全局符号和局部符号(static 对全局变量和函数的隐藏效果是一样的): **注意:**符号表中没有非 static 局部变量的符号,非 static 局部变量在运行时在栈中被管理。这里的局部符号和程序中的局部变量是不同的。 编译器在 .data 或 .bss 中为每个全局变量和 static 变量的定义分配空间,并在符号表中创建一个有唯一名字的符号。 符号表中的条目 对应各个字段的中文含义: 符号表实际上是一个条目的数组,每个条目描述一个符号的信息。符号表中的条目除了符号外,还可以包含各个节的条目,对应原始源文件的路径名的条目。 **链接器解析符号引用的方法:**将每个引用和它输入的可重定位文件的符号表中的一个确定的符号定义关联起来。 符号解析可以分为对局部符号的解析和对全局符号的解析: 链接器的输入是一组可重定位目标模块。每个模块定义一组符号,有些是局部的(只对定义该符号的模块可见),有些是全局的(对其他模块也可见)。如果多个模块定义同名的全局符号,会发生什么呢? 下面是 Linux编译系统采用的方法。 在编译时,编译器向汇编器输出每个全局符号,或者是强( strong)或者是弱(weak),而汇编器把这个信息隐含地编码在可重定位目标文件的符号表里。 根据强弱符号的定义, Linux链接器使用下面的规则来处理多重定义的符号名: 规则1:不允许有多个同名的强符号。 规则2:如果有一个强符号和多个弱符号同名,那么选择强符号。 规则3:如果有多个弱符号同名,那么从这些弱符号中任意选择一个。 注意:vs 的链接器并未遵守规则2,规则3:如果定义了同名的全局变量,链接器会直接报错,不论是强符号还是弱符号。 静态库:将所有相关的目标模块打包成一个单独的文件。 通过静态库,相关的函数可以被编译为独立的目标模块,然后封装成一个单独的静态库文件。然后,应用程序可以通过在命令行上指定单独的文件名称来使用这些在库中定义的函数。 例如: 在链接时,链接器将只复制被程序引用的目标模块,减少了可执行文件在磁盘和内存中所占用的空间。 在 Linux 系统中,静态库以一种称为存档的特殊文件格式存放磁盘中。存档文件是一组连接起来的可重定位目标文件的集合,有一个头部用来描述每个成员目标文件的大小和位置。存档文件后缀名为 .a 。 理解:静态库和存档文件可以当作一个东西。存档是文件层面的描述,静态库是模块层面的描述。 在 linux 中,静态链接库是 .a 文件,动态链接库是 .so 文件。在windows 中,静态链接库是 .lib 文件,动态链接库是 .dll 文件。 静态库的应用实例: 通过如下命令创建静态库: 为了使用这个库,编写程序如下: 创建可执行文件: 当链接器运行时,能自动判别出main2.o使用了addvec.o定义的addvec符号和printf.o使用的printf符号,因此复制addvec.o和printf.o到可执行文件。 符号解析的过程 在符号解析阶段,链接器从左到右按照它们在编译器驱动程序命令行上出现的顺序来扫描可重定位目标文件和存档文件。 在扫描中,链接器会维护一个可重定位目标文件的集合 E,一个未解析的符号 (即引用了但尚未定义的符号) 集合 U,已定义的符号集合 D。初始时, E, U, D 都为空。 库在命令行中放在什么位置 在命令行中,如果定义一个符号的库出现在引用这个符号的目标文件前,引用就不能被解析,链接会失败。因为初始时 U 是空的。 一般把库放在命令行的结尾。如果库之间相互依赖,则依赖者在前,被依赖者在后。如果双向引用,可以在命令行上重复库。 符号解析完成后,每个符号引用就和一个符号定义(即一个输入目标模块中的一个符号表条目)关联起来了。 此时,链接器已经知道它的输入模块中的代码节和数据节的确切大小(存储在节头部表中),接下来就是重定位步骤了。 重定位将合并输入模块并为每个符号分配运行时地址。 重定位分为两步: 重定位条目用来解决符号引用和符号定义的运行时地址的关联问题。 当汇编器遇到对最终位置的目标引用时,就会生成一个重定位条目,告诉链接器在合并目标文件为可执行文件时如何修改这个引用。 代码的重定位条目放在 .rel.text 中,已初始化数据的重定位条目放在 .rel.data 中。 每个重定位条目都代表了一个必须被重定位的引用 ELF重定位条目的格式: 具体含义: ELF 定义了32种不同的重定位类型。以下是其中最基本的两种: 这两种类型都使用了 x86-64 小型代码模型,该模型假设可执行目标文件中的代码和数据的总体大小小于 2GB,因此可以通过 32 位地址来访问。GCC 默认使用小型代码模型。此外还有中型代码模型和大型代码模型。 重定位 PC 相对引用 PC 相对引用的机制:在引用中存放着与 PC 的值偏移量。这实际上是符号定义的地址与符号引用的地址差。在实际运行时,当执行到了符号引用的指令时,PC 中的值就是符号引用的地址,加上 与 PC 的偏移量(即符号定义与符号引用的地址差)就得到了符号定义的地址。 重定位绝对引用 绝对引用的机制:引用中存放的就是符号定义的绝对地址 可执行目标文件是一个二进制文件,包含加载程序到内存并运行它所需的所有信息 可执行目标文件的格式与可重定位目标文件的格式类似。 其中 ELF头 描述了文件的总体格式,还包括程序的入口点(entry point),即程序运行时要执行的第一条指令的地址。 段头部表和节头部表描述了可执行文件中的片到内存映像中的段的映射关系。它描述了各节在可执行文件中的偏移、长度、在内存映射中的偏移等。 Linux shell 命令行中执行如下: 因为 prog 不是一个内置的 shell 命令,所以 shell 会认为 prog 是一个可执行目标文件,通过调用加载器(是操作系统中的一个程序)来运行它。任何 Linux 程序都可以通过 execve 函数来调用加载器。 加载:加载器将可执行目标文件的代码和数据从磁盘复制到内存,然后跳转到程序的第一条指令或入口点来运行程序。 每个 Linux 程序都有一个运行时内存映像,如下图所示。代码段总是从 0x400000 处开始,后面是数据段,然后是运行时堆段,通过调用 malloc 库往上增长。堆后面的区域是为共享模块保留的。用户栈总是从最大的用户地址 2^48-1 开始,向较小内存地址增长。从地址 2^48 开始是留给内核的。 在分配栈、共享库、堆的运行时地址的时候,链接器还会使用地址空间布局随机化,所以每次程序运行时这些区域的地址都会改变。 加载器的工作过程 加载器运行时,创建一个内存映像(虚拟地址空间),在程序头部表的引导下,将可执行文件的片复制到代码段和数据段。然后加载器跳转到程序的入口点,即 _start 函数的地址(函数在系统目标文件 ctrl.o 中定义),_start 函数调用系统启动函数 __libc_start_main(定义在 libc.o 中),__libc_start_main 初始化执行环境,调用用户层的 main 函数,处理 main 函数的返回值,并在需要时把控制返回给内核。 加载器实际工作流程: 虽然静态库解决了如何让大量相关函数对应用程序可用的问题。但是,仍然存在很多明显的缺点: 共享库是为了解决静态库缺陷的产物,其主要目的是: 共享库是一个目标模块,在运行或加载时,可以加载到任意的内存地址,并和内存中的程序链接起来。 动态链接:在程序运行或加载时,动态链接器将共享库加载到内存中并和程序链接起来。 共享库在 Linux 中以 .so 后缀表示,在 Windows 中以 .dll 表示。Windows 操作系统中大量使用了共享库。 共享库的共享方式: 共享库实例 生成共享库的方式,以构建向量共享库为例: 然后,以这个共享库为基础生成可执行目标文件: 将 main2.o 和 libvector.so 链接并不是将 libvector.so 中的内容拷贝到了可执行文件 prog21 中,而是链接器复制了一些 libvector.so 中的重定位和符号表信息,以便运行时可以解析对 libvector.so 中代码和数据的引用。 理解: 动态链接器完成链接的操作: 上述操作完成后,共享库的位置就固定了,且程序执行的过程中都不会改变。 动态链接:应用程序在运行时要求动态链接器加载和链接某个共享库(共享库即动态链接库)。 动态链接的应用: dlopen 函数 Linux 系统为动态链接器提供了一个简单接口dlopen 函数,允许应用程序在运行时加载和链接共享库 。 共享库的一个主要目的就是允许多个正在运行的进程共享内存中相同的库代码,从而节约宝贵的内存资源。 多个进程如何共享动态库的同一个副本,两种方法: 位置无关代码(Position-Independent Code,PIC)可以加载而无需重定位。 用户可以对 GCC 使用 -fpic 选项来生成 PIC 代码。共享库的编译必须总是使用此选项。 库打桩(library interpositioning):允许用户截获对共享库函数的调用,取而代之执行自定义的代码。 编译时打桩——访问程序的源代码 链接时打桩——访问程序的可重定位对象文件 运行时打桩——访问可执行目标文件 在Linux系统中有大量可用的工具可以帮助我们理解和处理目标文件。特别地,GNU binutils包尤其有帮助,而且可以运行在每一个Linux平台上 链接可以在编译时由静态编译器完成(静态库的链接),也可以在加载和运行时由动态链接器完成(动态库的链接)。 链接器处理的文件是目标文件,目标文件是一种二进制文件,有 3 种不同形式: 链接器的两个主要任务: 静态链接器是由 GCC 这样的编译驱动程序调用的。它们**将多个可重定位目标文件合并成一个单独的可执行目标文件。**多个目标文件可以定义相同的符号,链接器可以按照一定规则来解析这些相同的符号。 多个目标文件可以被连接到一个单独的静态库中。链接器用库来解析其他目标模块中的符号引用。许多链接器都是通过从左到右的顺序扫描库来解析符号引用。 加载器将可执行文件的内容映射到内存,并运行这个程序。链接器还可能生成部分链接的可执行目标文件,这样的文件中有对定义在共享库中的例程和数据的为解析的引用。在加载时,加载器将部分链接的可执行文件映射到内存,然后调用动态链接器,动态链接器通过加载共享库和重定位程序中的引用来完成链接任务。 **被编译为位置无关代码的共享库可以加载到任何地方,也可以在运行时被多个进程共享。**为了加载、链接和访问共享库的函数和数据,应用程序也可以在运行时使用动态链接器。 快速开始请访问 开始做 第一次实验流程还不是很熟练,跟着大佬的操作在一步步尝试ing~ 这里使用了ubuntu 64位的操作系统来做这个实验。 安装过程省略,贴上几个拉库和安装依赖的命令 只使用两种位运算实现异或操作。这个算是一个比较简单的问题了,难度系数 1。学数电和离散二布尔代数的时候了解过。 根据布尔代数,可以通过 使用位运算获取对 2 补码的最小 C 语言中 通过位运算计算是否是补码最大值。 做这个题目的前提就是必须知道补码最大值是多少,这当然是针对 判断所有奇数位是否都为1,这里的奇数指的是位的阶级是2的几次幂。重在思考转换规律,如何转换为对应的布尔值。 这个题目比较简单的,采用掩码方式解决。首先要构造掩码,使用移位运算符构造出奇数位全1的数 不使用 补码实际上是一个 计算输入值是否是数字 0-9 的 通过位级运算计算 使用位级运算实现C语言中的 如果我们根据 使用位级运算符实现 通过位运算实现比较两个数的大小,无非两种情况:一是符号不同正数为大,二是符号相同看差值符号。 使用位级运算求逻辑非 逻辑非就是非0为1,非非0为0。利用其补码(取反加一)的性质,除了0和最小数(符号位为1,其余为0),外其他数都是互为相反数关系(符号位取位或为1)。0和最小数的补码是本身,不过0的符号位与其补码符号位位或为0,最小数的为1。利用这一点得到解决方法。 求值:“一个数用补码表示最少需要几位?” 如果是一个正数,则需要找到它最高的一位(假设是n)是1的,再加上符号位,结果为n+1;如果是一个负数,则需要知道其最高的一位是0的(例如4位的1101和三位的101补码表示的是一个值:-3,最少需要3位来表示)。 求2乘一个浮点数 首先排除无穷小、0、无穷大和非数值NaN,此时浮点数指数部分( 将浮点数转换为整数 首先考虑特殊情况:如果原浮点值为0则返回0;如果真实指数大于31(frac部分是大于等于1的,1<<31位会覆盖符号位),返回规定的溢出值0x80000000u;如果 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L5jM9bTu-1645022218692)(https://www.zhihu.com/equation?tex=exp%3C0)] (1右移x位,x>0,结果为0)则返回0。剩下的情况:首先把小数部分(23位)转化为整数(和23比较),然后判断是否溢出:如果和原符号相同则直接返回,否则如果结果为负(原来为正)则溢出返回越界指定值0x80000000u,否则原来为负,结果为正,则需要返回其补码(相反数)。 C语言的浮点数强转为整数怎么转的? 利用位级表示进行强转! 求 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KvEyodWb-1645022218692)(https://www.zhihu.com/equation?tex=2.0%5Ex)] 这个比较简单,首先得到偏移之后的指数值e,如果e小于等于0(为0时,结果为0,因为2.0的浮点表示frac部分为0),对应的如果e大于等于255则为无穷大或越界了。否则返回正常浮点值,frac为0,直接对应指数即可。 附上战果图 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SOCcLkc6-1645022218693)(…/…/…/AppData/Roaming/Typora/typora-user-images/image-20220212235053295.png)] phase_1要求输入一个字符串,二进制炸弹会判断输入的字符串是否与目标字符串相等。 观察框架源文件bomb.c: 从上可以看出: 1、首先调用了read_line()函数,用于输入炸弹秘钥,输入放置在char* input中。 2、调用phase_1函数,输入参数即为input,可以初步判断,phase_1函数将输入的input字符串与程序内部的炸弹秘钥进行比较。 因此下一步的主要任务是从asm.txt中查找在哪个地方调用了readline函数以及phase_1函数。 打开asm.txt,在其中搜索phase_1: 从上图可以看出一些信息: 1、第330行:调用了read_line函数;read_line的返回结果(char* input)放置在eax**(累加器)**寄存器中。(从函数返回的结果一般都放置在eax寄存器中) 2、第331行:将read_line函数的返回结果放置在当前**esp****(栈指针寄存在)**指针指向的栈顶。 3、第332行:在逻辑地址0x8048b47位置调用了phase_1函数。同时也说明了phase_1函数的入口地址为0x8048c00。 4、结合前面bomb.c的分析,从上可以看出第331行,是在为调用phase_1准备参数,我们可以分析出此时函数调用栈的情况: 5、从上面可以看出,phase_1函数入口在虚拟地址0x8048c00,下一步需要分析phase_1函数。 在asm.txt中寻找8048c00(或者继续寻找phase_1)。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4S5onp82-1645022218695)(https://s2.loli.net/2022/02/13/iEg4lMwONQV6TGh.jpg)] 从上图可以看出一些信息: 1、第378行:sub $0x1c, %esp,将函数栈空间扩展了0x1c字节(28个字节) 函数栈帧变成如下: 6、第384行:test %eax %eax,是对eax寄存器里的内容(string_not_equal函数的返回内容)进行位与操作,如果为0,则置zf标志(零标志)为1; 7、第385行:是一个je指令,je指令判断zf标志(零标志)为1时(也即strings_not_equal函数返回的是0的情况下),跳转到phase_2 + 0x20的地方,即0x8048c20的地方,说明炸弹拆除成功。否则,call 804939b 8、从上面的分析来看,上图中显示的栈帧中,esp的内容是输入的字符串的首地址,而esp + 4的内容是0x804a3ec,应该是在程序中保存的被比较的字符串(即拆弹字符串)的首地址,而按照strings_not_equal的名字来看,如果是不等,则返回1,等则返回0。如果等,代表输入的拆弹字符串是正确的。 C语言伪代码: [ [ 所以下一步应该在运行的时候,查看0x804a3ec地址的内容,这即是我们要输入的拆弹字符串。 但为进一步判断我们上面的分析,下面再大致分析一下strings_not_equal函数。 根据上面的代码,可以看出strings_not_equal函数的地址在0x80490ba的地方。搜索80490ba或者strings_not_equal。 执行第762 - 765行之后,函数栈帧为: 注意: 1、第766行,将esp + 0x14的内容(input(输入字符串首地址))送入到了ebx寄存器,第767行,将esp + 0x18的内容(0x804a3ec)送入到了esi寄存器。验证了我们前面所介绍的0x804a3ec地址所在的地方应该是拆弹字符串所在的首地址。 2、768-770行:求input字符串的长度,结果送入到edi寄存器。 3、771-772行:求0x804a3ec字符串的长度,结果保存在eax寄存器中。 4、773行:将1送入edx,通过后面的分析,可以知道edx存放的是返回结果,也即默认返回结果为1,即不等。 5、774-775行:比较edi和eax的内容,**即input字符串与0x804a3ec为首地址的字符串长度进行比较,**如果不等,则跳转到strings_not_equal + 0x63的地方:0x80490ba + 0x63 = 0x804911d(此地的指令是将edx的内容送入到eax,并返回,注意第773行,edx的内容被赋值为1),也即返回1,代表两个字符串不等。 6、后面的汇编代码,是逐一比较两个字符串的内容,如果相等,则返回0,如果不等则返回1。 综合前面的分析,以C语言来表示strings_not_equal,其大致含义是: [ [ 以上C语言代码基本和汇编代码相对应,可以对照理解。 使用objdump --start-address=0x804a3ec -s bomb,即可查看以0x804a3ec开头的段信息。下图是一个示例,我们可以看出0x804a3ec开头的字符串,正是前面找到的拆弹字符串! 从这里我们也可以看出,所有直接硬编码进入代码的字符串,以只读数据的形式存放在只读数据段中。 phase_2要求输入包含6个整数的字符串。phase_2函数从中读取6个整数,并判断其正确性,如果不正确,则炸弹爆炸。phase_2主要考察学生对C语言循环的机器级表示的掌握程度。 观察框架源文件bomb.c: 从上可以看出: 1、首先调用了read_line()函数,用于输入炸弹秘钥,输入放置在char* input中。 2、调用phase_2函数,输入参数即为input,可以初步判断,phase_2函数将输入的input字符串作为参数。 因此下一步的主要任务是从asm.txt中查找在哪个地方调用了readline函数以及phase_2函数。 打开asm.txt,寻找phase_2函数。 和phase_1类似分析: 1、当前栈的位置存放的是read_line函数读入的一串输入; 2、phase_2的函数入口地址为0x8048c24。 此时的函数栈为: 寻找8048c24,或者继续寻找phase_2,可以寻找到phase_2函数,如下图所示: 分析上面的代码: 1、390 ~ 392行:进行一些压栈,并扩展了函数栈帧。 2、第394-395行:lea 0x18(%esp) %eax、mov %eax 4(%esp),将esp + 18指向的栈的内容的地址放置到esp+4指向的地方。简单的说,当前esp + 4指针指向的空间的内容为esp + 18。(实际上,根据后面的分析,可以知道esp + 4的内容,放的是num[0]的地址esp + 18) 3、第396行:将0x40(%esp)的内容放置到esp指向的栈。0x40(%esp)里面的内容实际上就是input字符串首地址。 4、第397行:调用了read_six_numbers函数(顾名思义,从字符串中解析出六个整数),可以猜测实际上第394行到第396行,是在为read_six_numbers函数准备参数。 5、在调用read_six_numbers之前,函数栈帧为: 7、上图所示的函数栈帧中,从esp + 18 ~ esp+2c,共6个栈空间,标记为保存6个整数,实际上从当前的地方并不能完全看出来,可以有些猜测,到后来阅读read_six_numbers时,证实了当前的猜测是正确的。 8、依据以上的分析,read_six_numbers函数的定义:void read_six_numbers(char* input, num);其中第二个参数,是num数组的地址。在后面,会剖析read_six_numbers函数,来证实以上的猜测,下面的分析以以上的栈帧图为基础。 9、第399行:cmp $0x1, 0x18(%esp),0x18(%esp)中是num[0],该语句判断num[0]是否应等于1,如果等,则跳转到phase_2 + 0x3e(第400行),如果不等,则call explode_bomb(第401行),从此处,可以猜测:num[0] = 1。 10、第412行(8048c62(phase_2 + 0x3e)),将0x1c + esp --> ebx寄存器,即将num[1]的地址送入到ebx寄存器,第413行,将0x30 + esp -->esi,0x30(%esp)是num[5]上面的栈空间,将该栈空间的地址送入到esi。 11、第415行:跳转到8048c4b(即第403行)。 12、第403行:将-0x4(%ebx)的内容送入到eax,-0x4(%ebx)的内容实际上指的是0x18(%esp),也即num[0]送入到eax。 13、第404行:eax = eax + eax,即: 2 * num[0]; 14、第405行:比较ebx所指的地址的内容和eax的内容,据前面分析,当前ebx的内容即为num[1]的地址。 15、第406行:如果相等,则跳转到8048c59。 16、第408行(8048c59):ebx += 4,当前ebx为num[1]的地址,加4之后,正好是num[2]的地址。 17、第409行:ebx与esi(num[5]之上的地址)比较,如果不等则跳转到8048c4b(第403行),继续从前面第11继续开始。如果相等,则跳转到8048c6c(第415行),退出函数。实际上如果ebx与esi相等,说明前面已经处理完了num[5],也即处理完了第6个数。如果不等,则说明num[5]没有处理,继续循环。 18、总结前面的分析,以上显然是一个循环表示的机器级表示的处理过程,从上面的分析来看: 1)num[0] = 1; 2)num[i] = 2 * num[i-1]。(i > 0) **因此,phase_2炸弹秘钥应该是:**1 2 4 8 16 32。 以上所有的分析是建立在六个输入数字是放置在esp + 0x18开始的地址中的前提下的。为确认这一个问题,下面对read_six_numbers函数进行详细分析。 根据前面分析,read_six_numbers的入口地址为80493da,如下图所示: 1、第996行:扩展栈帧,增加了44。 2、第997行:将0x34(%esp)的内容送到eax,0x34(%esp)的内容正好是num[0]的地址,也即num的首地址,也即eax内容为num[0]的地址。(参见后面的栈帧图) 3、第998行:将eax + 0x14的地址(即为eax + 0x14)送到edx,eax+0x14正好是num[5]的地址。(参见后面栈帧图) 4、第999行:将edx的内容送到esp + 0x1c的地方,即将num[5]的地址送到esp+0x1c的地方; 5、第1000行 ~1008行: 1)num[4]地址,送到esp + 0x18 2)num[3]地址,送到esp + 0x14 3)num[2]地址,送到esp + 0x10 4)num[1]地址,送到esp + 0xc 6、第1009行:num[0]地址,送到esp + 8 7、第1010行:0x804a725送入到esp + 4的地方 8、第1011/1012行:0x30(%esp)内容送入到esp,0x30(%esp)内容为input输入首地址。 9、第1013行:调用scanf函数,用于从input中读入6个整数。可以认为前面都是在为scanf函数调用准备参数,包括第1009行,0x804a67d实际上是指向一个字符串的首地址,这个字符串为“%d %d %d %d %d %d”(这点将在后面分析),因此,我们可以判断scanf的函数定义/使用为:scanf(input, “%d %d %d %d %d %d”, &num[0], &num[1], &num[2], &num[3], &num[4], &num[5],); 返回的是读取的整数的个数。 10、此时的栈帧为: 11、第1014行:将eax的值与5比较,eax应该是scanf函数返回的输入数字的个数; 12、第1015行:如果大于5,则函数正确返回; 13、第1016行:如果小于等于5,则引爆炸弹。 14.为了查看0x804a67d地址的内容,可以使用objdump --start-address= 0x804a67d -s bomb命令查看,如下图所示: phase_3要求输入包含1个小于10的整数,一个整数的字符串。phase_2函数从中读取这些信息,并判断其正确性,如果不正确,则炸弹爆炸。 phase_3主要考察学生对C语言条件/分支的机器级表示的掌握程度。 观察框架源文件bomb.c: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-344747Ok-1645022218701)(https://s2.loli.net/2022/02/13/2KxOqivIHnjQgSG.png)] 从上可以看出: 1、首先调用了read_line()函数,用于输入炸弹秘钥,输入放置在char* input中。 2、调用phase_3函数,输入参数即为input,可以初步判断,phase_3函数将输入的input字符串作为参数。 因此下一步的主要任务是从asm.txt中查找在哪个地方调用了readline函数以及phase_3函数。 打开asm.txt,寻找phase_3函数。 和phase_1类似分析: 1、当前栈的位置存放的是read_line函数读入的一串输入; 2、phase_3的函数入口地址为0x8048c72。 此时的函数栈为: 寻找8048c72,或者继续寻找phase_3,可以寻找到phase_3函数,如下图所示: 1、第421~431行:初始化函数栈帧,同时为调用sscanf准备参数。之后,函数栈帧如下所示: 1)esp + 4的地方,存放的是0x804a689,其对应的字符串为“%d%d”(其分析过程参见phase_2,不再赘述); 2)esp + 8的地方实际的内容是esp + 0x18(是esp + 0x18地址的内容的地址),esp + c内容是esp + 0x1c。 3)参考phase读取6个整数的分析,可以认为前面几个参数都是为调用sscanf准备参数:sscanf(input, “%d %d”, &d1, &d2),其中&d1对应18(%esp),&c对应1c(%esp)。 4)因此,可以看出18(%esp)、1c(%esp)分别对应于d1、d2。也即sscanf最终读取的数据分别放置于栈帧中的这两个个地方,在后面的代码分析中,均以d1以及d2来代替这三个地址的内容。 2、第431-433行:判断sscanf返回结果是否大于1,如果不是,则explode_bomb。如果大于,则认为输入正确,跳转到 3、第434行(phase_3 + 0x39)及435行:d1与7相比较,大于则跳转到 4、第436-437行:将d1送给eax,跳转到0x804a450 + d1 * 4的内容所指示的地址。使用objdump --start-address=0x804a450 -s bomb查看0x804a450的内容,如下图所示: 显然,后面连续的8个32位的数值分别指向的地址是08048cbc、08048cb5、08048cc8、08048cd4、08048ce0、08048cec、08048cf8、08048d04(注意:IA32为小端表示*低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。*),分别对应于d1为0~7。显然这一块应该是一个swich-case的机器级表示。(参见袁春风老师《选择及循环语句的机器级表示》) 这里以d1等于3为例,d2初值赋为0,然后-18c,之后不断跳转+18c,-18c,+18c,-18c,最终结果是-18c,也就是-396 第446行初始d2赋值为0。 第447行进行-18c。 第478行执行跳转到地址8048ce5,即第450行的位置。 第450行执行+18c。 第451行执行跳转到地址8048cf1,即第453行的位置。 第453行执行-18c 第454行执行跳转到地址8048cfd,即第456行的位置。 第456行执行+18c 第457行执行跳转到地址8048d09,即第459行的位置。 第459行执行-18c 第460行执行跳转到地址8048d1a,即第463行的位置。 第463行先确定d1不大于5,之后第465行比较判断此时的d2,此时d2为-18c,即-396 phase_4要求输入2个整数,phase_4函数从中获取信息,并判断其正确性,如果不正确,则炸弹爆炸。 phase_4主要考察学生对递归的机器级表示的掌握程度。 观察框架源文件bomb.c: 从上可以看出: 1、首先调用了read_line()函数,用于输入炸弹秘钥,输入放置在char* input中。 2、调用phase_4函数,输入参数即为input,可以初步判断,phase_3函数将输入的input字符串作为参数。 因此下一步的主要任务是从asm.txt中查找在哪个地方调用了readline函数以及phase_4函数。 打开asm.txt,寻找phase_4函数。 和phase_1类似分析: 1、当前栈的位置存放的是read_line函数读入的一串输入; 2、phase_4的函数入口地址为0x8048d8e。 此时的函数栈为: 寻找8048d8e,或者继续寻找phase_4,可以寻找到phase_4函数,如下图所示: 1、510-518行:准备phase_4函数栈帧,并为调用sscanf函数准备参数。经过这些语句后,函数栈帧如下图所示。 **注意:**0x804a689位置的内容为“%d %d”,可以判断是输入两个整数。其分析过程参见前面阶段分析,这里不再赘述。 2、519行:调用sscanf函数,读取两个整数,得到的两个数据d1和d2,放置在如上图中的栈中,函数返回结果在eax寄存器中。(根据前面的分析,应该知道返回结果代表读取的数据的数量) 3、520-521行:如果读取的数量不等于2,则跳转到8048dc1 4、522-524行:d1与14(0xe)比较,大于,则引爆炸弹。显然,这里的判断是要求d1 <= 14。小于则跳转到8048dc6 6、525行(8048e5d)- 530行,是在为调用8048d31这个函数做准备。531行执行后,函数栈帧变为: 可以看出,为func4函数准备了3个参数,调用顺序为(d1,0,14)。 7、531行:调用func4(d1, 0, 14),返回结果在eax中。 8、532行:将func4的返回结果与0xf(10进制15)相比较,如果不等,则跳转到8048e85 9、534-535行:将d2与15(0xf)相比较,如果不等,则引爆炸弹。如果相等,则过关。 10、从上面分析来看,输入的两个数中,d1 <= 14,而d2=15。d1目前看来暂时不能确定,如果要确定d1的值,需分析func4函数(其逻辑空间地址为8048d31)。 在asm.txt中寻找func4,在8048d31处,为func4函数定义: 1、根据前面分析,func4的定义应为:int func4(int x, int y, int z),后面的分析均以此为基础进行分析。 2、473-474行:准备函数栈帧。执行后,函数栈帧如下图所示: 3、476-478行:x --> edx,y --> eax,z --> esi。 4、479-481行:ecx = ebx = z - y; 5、482行:ebx逻辑右移0x1f位(shr:逻辑右移指令),即逻辑右移31位,即将z-y的最高位(符号位)移到了最低位。逻辑右移的结果送到ebx,此时ebx 为z - y的符号位。即如果z >= y,则ebx = 0,否则ebx = 1;(前面给的参数z = 14, y = 0, ebx = 0) 6、483-484行:ecx = ebx + ecx = z - y + sign(z-y) ;然后ecx算术右移一位,即ecx = (z-y + sign(z-y))/2 = 7。(sar:算术右移指令,只有一个参数,意味着只右移1位,这里sign(z-y)代表取z-y的符号,当z>=y时,sign(z-y) = 0 否则sign(z-y) = 1) 7、485行:lea是一个地址传送指令,但这里借用该指令,执行的是将ecx + eax -->ebx,也即ebx = y + [(z-y) + sign(z-y)]/2。(这里应该是求z和y的中间的值,分为负数和正数的处理方法不一样,为方便后面描述,这里设置mid = y + [(z-y) + sign(z-y)]/2) 8、486-487行:将ebx与edx相比较,也即mid与x相比较,如果mid <= x(jle为小于等于),则跳转到8048d6d 9、495-497行:8048d6d 10、498-502行:将esi的内容(z),送入到esp+8的位置,ebx + 1 -->esp + 4(ebx为mid), x–>esp,然后调用func4,显然这里是递归调用func4,此时调用func4(x, mid + 1, z)。如果该函数返回,将ebx(mid)与eax(func4的返回结果)相加(第504行),进行返回。 11、根据前面8~10分析:如果mid 等于x,则返回mid,如果mid < x,则调用func4(x, mid+1, z)。 12、第488-492行:上面第8步,如果第487步没有跳转,则继续执行488行,此时mid > x。此时的过程: 1)将ebx -1 -->ecx,即ecx=mid-1,ecx->esp+8(esp+8为mid-1),eax->esp+4(eax为y),edx->esp(edx为x)。 2)调用func4:func4(x, y, mid-1)。 3)显然,以上代码含义是当mid > x时,调用func4(x, y, mid-1)。 4)如果func4返回,将ebx(mid)与eax(func4的返回结果)相加(第493行),进行返回。 根据以上分析,func4显然是一个递归调用函数,其大致c语言代码为: [ [ 显然,上面代码为一个二叉排序/搜索树,phase_4调用时的参数是func4(d1, 0, 14),最后的返回结果是15。 根据前面分析,当给定d1时,func4返回结果是搜索路径上的所有值之和。例如: 假设d1 = 7, func4返回7。如果d1=1,func4返回7+3+1 = 11。 当要求func4返回15时,d1应该等于5,即7 + 3 + 5 = 15。 因此,phase_4的答案应该是:“5 15” phase_5要求输入一个包含6个字符的字符串。phase_5函数从中读取这些信息,并判断其正确性,如果不正确,则炸弹爆炸。 phase_5主要考察学生对指针(数组)机器级表示的掌握程度。 观察框架源文件bomb.c: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gwsBuNxR-1645022218707)(…/…/…/AppData/Roaming/Typora/typora-user-images/image-20220216214856524.png)] 从上可以看出: 1、首先调用了read_line()函数,用于输入炸弹秘钥,输入放置在char* input中。 2、调用phase_5函数,输入参数即为input,可以初步判断,phase_5函数将输入的input字符串作为参数。 因此下一步的主要任务是从asm.txt中查找在哪个地方调用了readline函数以及phase_5函数。 打开asm.txt,寻找phase_5函数。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rlC5VgSP-1645022218707)(…/…/…/AppData/Roaming/Typora/typora-user-images/image-20220216214750948.png)] 和phase_1类似分析: 1、当前栈的位置存放的是read_line函数读入的一串输入; 2、phase_5的函数入口地址为0x8048df7。 此时的函数栈为: 继续寻找phase_5,或搜索8048df7,可以找到phase_5函数入口。 1、541-547行:初始化函数栈帧,并为调用string_length做准备(此时ebx的内容为input字符串首地址:543行)。函数栈帧如下图所示: 注: 1)544-545行:mov %gs:0x14, %eax mov %eax, 0x1c(%esp),将gs(全局段寄存器)+0x14偏移位置的内容放置到eax,然后将其放置到esp + 0x1c的地方。从这里看不出这段代码什么含义,但据后面的分析,这里应该是起到一个“哨兵”的作用,防止数组访问越界。 2)546行:xor %eax, %eax,似乎没有什么用,得出来的结果是0,应该只是影响zf标志寄存器(zf为零标志寄存器,即zf=1)。 2、548行:判断input字符串的长度(esp指向的地方为input的首地址,参见上图),返回结果在eax寄存器中。 3、549-551行:判断input的长度是否为6,如果不是,则炸弹爆炸(551行),如果是,跳转到8048e62 4、572-573行(8048e62 5、554行(<8048e22> 6、555行:将edx的内容(input[0])与0x0f位与,相当于取低4位(edx内容为input[eax]的低四位)。 7、556行:将edx + 0x804a470指向的地址的内容送入到edx。0x804a470的内容(使用objdump --start-address=0x804a470 -s bomb,参见phase_1分析过程)为: 从上面来看,0x804a470应该是指向一个字符串,此时edx的内容应该是0x804a470加上input[eax]低4位的偏移的内容。 8、557行:将dl(edx的低8位,为(0x804a470 +input[eax]) & 0xf)的内容送入到esp + eax * 1 + 0x15的地方。 9、558-560行:eax += 1,然后判断eax的内容是否等于6,如果不等,则跳转到8048e22 10、以上代码,以类c语言来简要说明: for(int i = 0; i < 6; i++){ //将0x804a470 + input[i] & 0x0f这个地址的内容送入到堆栈esp + i + 0x15地址中。 (0x804a470 + input[i] & 0x0f) --> (esp + i + 0x15) } 经过6次循环后,函数栈帧如下: 显然,从esb + 0x15开始,是根据input的输入的每个字符的低四位,得出来的一个新的字符串。 11、561行:以上循环结束后,跳出循环,执行该语句:esp + 0x1b的内容改变为0; 12、562行:将0x804a446送入到:esp+0x4。0x804a446的内容为(objdump --start-address=0x804a446 -s bomb): 也即当前esp+0x4指向的是一个字符串首地址,字符串为**“sabres”**。 13、564-565行:eax的内容变为esp + 0x15,即通过上面循环形成的新的字符串的首地址,然后将其送入到esp。 14、调用strings_not_equal函数,显然,前面11~13均在为调用strings_not_equal做准备,调用strings_not_equal前,函数栈帧为: 15、显然,strings_not_equal函数判断以(esp + 0x15)为首地址的字符串与0x804a446为首地址的字符串(“*sabres*”)相比较,如相等,eax返回0,如不相等eax返回1。(参见phase_1分析) 16、567行:判断eax是否为0(eax与eax位与),如果为0,0标志寄存器为1。 17、568-569行:如果eax=0,则跳转到8048e69 18、574-577行:将esp + 0x1c地址处的内容送入到eax(574行,esp+0x1c的内容应为%gs:0x14的内容),然后与%gs:0x14的内容相异或,如果相等(为0),则跳转到0x8048e7b,正常结束,否则调用__stack_chk_fail函数(应该是栈检查失败); 根据上面分析,%gs:0x14的值送入到esp+0x1c的地方(第544-545行),应该是起到一个“哨兵”的作用,防止数组的访问越界。 根据前面分析,显然phase_5函数的作用(以类C语言进行描述): [ [ 那么根据上面的代码反推,如果需要使构成的new_str==“sabres”,那么输入的input[i]的低4位对应的十进制数分别是array[]数组中字符’s’,‘a’,‘b’,‘r’,‘e’,'s’的下标。 根据以上分析,要形成"sabres"字符串: array[] = {‘m’, ‘a’, ‘d’, ‘u’, ‘i’, ‘e’, ‘r’, ‘s’, ‘n’, ‘f’, ‘o’, ‘t’, ‘v’, ‘b’, ‘y’, 'l '}; 1)‘s’:对应于array第7个 (从0开始),也即input[0]的低4位应该为7,符合条件的可显示字符有:’’’,'7 ',‘G’,‘W’,‘g’,‘w’(参见附后的ASCII码表): 2)‘a’:对应于array第1个 (从0开始),也即input[1]的低4位应该为2,符合条件的可显示字符有:’!’,'1 ‘,‘A’,‘Q’,a’,‘q’ 3)‘b’:对应于array第13个(从0开始),也即input[2]的低4位应该为13,符合条件的可显示字符有:’-’,’=’,‘M’,’]’,‘m’, ‘}’ 4)‘r’:对应于array第6个 (从0开始),也即input[3]的低4位应该为6,符合条件的可显示字符有:’&’,'6 ',‘F’,‘V’,‘f’,‘v’ 5)‘e’:对应于array第5个 (从0开始),也即input[4]的低4位应该为5,符合条件的可显示字符有:’%’,‘5’,‘E’,‘U’,‘e’,‘u’ 6)‘s’:对应于array第7个 (从0开始),也即input[5]的低4位应该为7,符合条件的可显示字符有:’’’,'7 ',‘G’,‘W’,‘g’,‘w’ phase_6要求输入6个1~6的数,这6个数不能重复。phase_6根据用户的输入,将某个链表按照用户的输入的值(进行某种计算后)进行排序,如果最终能排成降序,则解题成功。 phase_6主要考察学生对C语言指针、链表以及结构的机器级表示的掌握程度。 观察框架源文件bomb.c: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-58uKRt3G-1645022218712)(…/…/…/AppData/Roaming/Typora/typora-user-images/image-20220216220136727.png)] 从上可以看出: 1、首先调用了read_line()函数,用于输入炸弹秘钥,输入放置在char* input中。 2、调用phase_6函数,输入参数即为input,可以初步判断,phase_6函数将输入的input字符串作为参数。 因此下一步的主要任务是从asm.txt中查找在哪个地方调用了readline函数以及phase_6函数。 打开asm.txt,寻找phase_6函数。 和phase_1类似分析: 1、当前栈的位置存放的是read_line函数读入的一串输入; 2、phase_6的函数入口地址为0x8048e81。 此时的函数栈为: 在asm.txt中继续寻找phase_6,或者寻找0x8048e81,找到phase_6函数入口 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w8c0a1vB-1645022218712)(…/…/…/AppData/Roaming/Typora/typora-user-images/image-20220216220537284.png)] 584-591行:初始化函数栈帧,然后调用read_six_numbers函数。调用之后,从input中读取了6个数num[0] ~ num[5](read_siz_numbers函数分析参见前面),位于esp+0x10 ~esp+0x24,此时函数栈帧如下图所示: 2、592行:0 --> esi 3、593-597行:判断(esp + esi*4 + 0x10)是否小于等于6以及大于等于1,如果不满足,则引爆炸弹(625行);也即输入的数(esi=0时,为num[0],esi=1时,为num[1]…)应该大于等于1,同时小于等于6。注意,比较时,先将该值减1(594行),然后与5进行比较(595行),比较时用的jbe(无符号整数比较),也即,如果该输入值小于1,减1之后变成一个很大的无符号数(负数),肯定是大于5的。因此这几行就实现了判断num[esi] >=1 && num[esi] <=6。(这应该是编译器做的优化) 4、598行:esi += 1 5、599-602行:esi与6进行比较,如果等于,则意味着6个数已经比较完毕,跳转到8048ef7。 6、603行:如果602行没有跳转,也即6个数还没有判断完毕,则继续执行,将esi赋值给ebx 7、604-607行:判断num[ebx]是否与num[esi-1]相等,如果相等,则引爆炸弹; 8、608-610行:ebx+=1,然后判断ebx是否小于等于5,如果是,则跳转到8048ec1,即604行,也即跳转到第7步。 9、611行:跳转到8048e9f,进行num[esi]的比较(注意num[esi]在第608行加1) 10、综合以上分析,可以判断出以上代码的作用是: 1)判断每个输入的数应小于等于6,大于等于1; 2)num[i]不等于它的后续的每个数; 3)也即输入的6个数,应是1/2/3/4/5/6,但顺序不一定。 使用类c语言描述: [ [ 14、622行(0x8048fa2 15、617行(0x8048f91 16、618行:将edx内容送入到esp + esi*4 + 0x28。 17、619-621行:ebx += 1,然后与6相比较,如果等于6,则跳转到0x8048f0e 。 18、如果不等于6,则继续执行622行,对于本文,即跳转到第14步,前面分析了ecx=1的情况,如果ecx不等于1,则应继续执行626-628行。 19、626-628行:eax赋值为1,edx赋值为0x804c174,跳转到8048eda 20、612-615行:这是一个循环。判断ecx(num[ebx])是否等于eax,如果不是,则将edx + 8的内容送入到edx,然后继续判断, edx +8的内容应该是指向的是一个地址。如果相等,则跳转到 8048eda 21、根据前面的分析,13~20步的代码,是根据处理后的num值(参见第10步分析),将相关信息压栈(从esp+28开始压栈):(注意:IA32是小端方式) 1)当num[i] == 1时,将0x804c174(node1)压入到esp + 0x28 + i * 4; 2)当num[i] == 2时,将0x804c180(node2)压入到esp + 0x28 + i * 4; 3)当num[i] == 3时,将0x804c18c(node3)压入到esp + 0x28 + i * 4; 4)当num[i] == 4时,将0x804c198(node4)压入到esp + 0x28 + i * 4; 5)当num[i] == 5时,将0x804c1a4(node5)压入到esp + 0x28 + i * 4; 6)当num[i] == 6时,将0x804c1b0(node6)压入到esp + 0x28 + i * 4; 7)观察压入栈的内容,每个内容地址实际上是指向12(例如:0x804c180-0x804c174)字节的一段数据,该数据的末尾又是指向一个地址,因此,可以判断0x804c174开始的地方指向的是一个链表(但这些链表的存空间是连续分配的),每个节点包括12个字节,其中最后一个是指向下一个的指针,猜测每个节点的定义: [ [ 6个节点,分别为: node1 = {0x6d, 0x01, 0x804c180}; (&node1 = 0x804c174) node2 = {0x69, 0x02, 0x804c18c }; (&node2 = 0x804c180) node3 = {0x3b2, 0x03, 0x804c198}; (&node3 = 0x804c18c) node4 = {0x299, 0x04, 0x804c1a4}; (&node4 = 0x804c198) node5 = {0xc7, 0x05, 0x804c1b0}; (&node5 = 0x804c1a4) node6 = {0x285b, 0x06, 0}; (&node6 = 0x804c1b0) 链接关系为: node1 --> node2 --> node3 --> node4 --> node5 --> node6 --> 0 8)假设当前6个num的值为6/5/4/3/2/1,则经过6次循环后,函数栈帧如下图所示。 注:后面分析,均假设6个num的值为6/5/4/3/2/1。 22、以上操作结束,则跳转到 8048f0e 23、629(8048fb9 1)629行:0x28(%esp)的内容(num[0]这个值指向的节点的地址) --> ebx 2)630行:esp+0x2c --> eax,esp+0x2c这个地址的内容为num[1]这个值对应的节点的地址 3)631行:esp + 0x40 --> esi,esp + 0x40,根据后面的分析,这个值是作为“哨兵”,防止访问越界 4)632行:ebx --> ecx(此时ebx以及ecx都是num[0]这个值指向的节点的地址) 5)633行:eax所指向的地址的内容(num[1]这个值对应的节点的地址)–> edx 6)634行:将edx的内容赋值给8(%ecx)的地址,注意,此时ecx为num[0]指向的节点的地址,8(%ecx)正好是num[0]这个值所对应的next,即node6.next = &node5 7)635行:eax += 4,即eax所指向的地址的内容变成了num[2]所指向的节点的地址; 8)636行:将eax与esi(哨兵)相比较,如果等于,则说明循环结束,跳转到 8048f2c 9)638行:edx --> ecx:根据前面分析,edx为num[1]值指向的节点的地址。 10)639行:跳转到8048f1c 11)如此循环,最后的结果是: node6.next = &node5,node5.next = &node4,node4.next = &node3,node3.next = &node2,node2.next = &node1 12)如果以上都做完,跳转到8048fd7 13)640行:将0赋值给8(%edx)指向的地址,此时edx为node1的地址,即将node1.next=0; 14)显然,以上步骤,根据num的值重新构成了一个链表,此时的链接关系变成了: node6 --> node5 --> node4 --> node3 --> node2 --> node1 --> 0。(注:以上分析均是基于6个num的值为6/5/4/3/2/1) 24、641 - 行: 1)641行:5 --> esi 2)642行:将ebx+8这个地址的内容送给eax,注意, ebx为node6的地址,ebx+8为node6->next这个值的地址,这个地址的内容即为node5的地址。也即eax的内容为node5的地址。 3)643行:将eax指向的地址的内容赋值为eax,也即eax的内容为node5.d1 4)644行:将node5.d1与ebx指向的地址的内容相比较;(显然,此处是整数的比较,因此,也可以判断struct node中第一个元素应该是int),此时ebx的内容为node6的地址,node6的地址的内容为node6.d1,即node5.d1与node6.d1相比较。 5)645-646行:如果node6.d1 >= node5.d1,则跳转到8048f46 6)647行:ebx的内容变为其指向的节点的next,即ebx=node6-next,指向了node5 7)648行:esi-= 1 8)649行:如果esi不为0,则跳转到642行,按以上的2)继续分析,应注意,此处ebx的值为node5的地址了。 9)显然,此时会判断node5.d1是否大于等于node4.d1,如果是,则继续,如果不是,则引爆炸弹 10)后续会依次判断node4.d1是否大于等于node3.d1,node3.d1是否大于等于node2.d1,…,综合起来,就是判断按照num值排序之后的节点是否降序排列,如果是,则解题成功,如果不是,则引爆炸弹。 根据以上分析,phase_6的功能: 1)phase_6定义了一个包含6个节点的链表,每个节点中包含两个整型(d1,d2),以及指向下一个节点的指针;6个节点依次的链接顺序为node1->node2->node3->node4->node5->node6 2)要求用户输入6个数,这6个数应为1~6,而且不能重;为便于以后说明,假设这6个数为6/5/4/3/2/1。 3)按照num[i]的值重新排列链表,此时链表变为: node6->node5->node4->node3->node2->node1 4)判断以上链表是否降序排列(按分量d1),如果是,则拆弹成功,否则,引爆炸弹。 也即phase_6会给出一个链表,链表中的节点的d1分量含有一个整数值,需要用户输入一个序列号,按照这个顺序重新排列链表中的节点,如果链表是按照降序排列,则输入的这个序列号是正确的。 对于前面的炸弹,其初始化的节点值为: node1 = {0x6d, 0x01, 0x804c180}; (&node1 = 0x804c174) node2 = {0x69, 0x02, 0x804c18c }; (&node2 = 0x804c180) node3 = {0x3b2, 0x03, 0x804c198}; (&node3 = 0x804c18c) node4 = {0x299, 0x04, 0x804c1a4}; (&node4 = 0x804c198) node5 = {0xc7, 0x05, 0x804c1b0}; (&node5 = 0x804c1a4) node6 = {0x285b, 0x06, 0}; (&node6 = 0x804c1b0) 显然,使得这个链表按降序排列的序列是:3 4 6 5 1 2,因此,输入的序列号应为:3 4 6 5 1 2,此即为本关答案。 上课提示有一个隐藏关,并且在phase_defused中,作为一种锻炼,我们还是继续深入看看 1.这是调用sscanf函数前的栈帧情况: 2.这是调用strings_not_equal前的栈帧 3.这是调用secret_phase前的栈帧 6个节点,分别为: node1 = {0x6d, 0x01, 0x804c180}; (&node1 = 0x804c174) node2 = {0x69, 0x02, 0x804c18c }; (&node2 = 0x804c180) node3 = {0x3b2, 0x03, 0x804c198}; (&node3 = 0x804c18c) node4 = {0x299, 0x04, 0x804c1a4}; (&node4 = 0x804c198) node5 = {0xc7, 0x05, 0x804c1b0}; (&node5 = 0x804c1a4) node6 = {0x285b, 0x06, 0}; (&node6 = 0x804c1b0) 链接关系为: node1 --> node2 --> node3 --> node4 --> node5 --> node6 --> 0 8)假设当前6个num的值为6/5/4/3/2/1,则经过6次循环后,函数栈帧如下图所示。 [外链图片转存中…(img-XrUuY81H-1645022218716)] 注:后面分析,均假设6个num的值为6/5/4/3/2/1。 22、以上操作结束,则跳转到 8048f0e 23、629(8048fb9 1)629行:0x28(%esp)的内容(num[0]这个值指向的节点的地址) --> ebx 2)630行:esp+0x2c --> eax,esp+0x2c这个地址的内容为num[1]这个值对应的节点的地址 3)631行:esp + 0x40 --> esi,esp + 0x40,根据后面的分析,这个值是作为“哨兵”,防止访问越界 4)632行:ebx --> ecx(此时ebx以及ecx都是num[0]这个值指向的节点的地址) 5)633行:eax所指向的地址的内容(num[1]这个值对应的节点的地址)–> edx 6)634行:将edx的内容赋值给8(%ecx)的地址,注意,此时ecx为num[0]指向的节点的地址,8(%ecx)正好是num[0]这个值所对应的next,即node6.next = &node5 7)635行:eax += 4,即eax所指向的地址的内容变成了num[2]所指向的节点的地址; 8)636行:将eax与esi(哨兵)相比较,如果等于,则说明循环结束,跳转到 8048f2c 9)638行:edx --> ecx:根据前面分析,edx为num[1]值指向的节点的地址。 10)639行:跳转到8048f1c 11)如此循环,最后的结果是: node6.next = &node5,node5.next = &node4,node4.next = &node3,node3.next = &node2,node2.next = &node1 12)如果以上都做完,跳转到8048fd7 13)640行:将0赋值给8(%edx)指向的地址,此时edx为node1的地址,即将node1.next=0; 14)显然,以上步骤,根据num的值重新构成了一个链表,此时的链接关系变成了: node6 --> node5 --> node4 --> node3 --> node2 --> node1 --> 0。(注:以上分析均是基于6个num的值为6/5/4/3/2/1) 24、641 - 行: 1)641行:5 --> esi 2)642行:将ebx+8这个地址的内容送给eax,注意, ebx为node6的地址,ebx+8为node6->next这个值的地址,这个地址的内容即为node5的地址。也即eax的内容为node5的地址。 3)643行:将eax指向的地址的内容赋值为eax,也即eax的内容为node5.d1 4)644行:将node5.d1与ebx指向的地址的内容相比较;(显然,此处是整数的比较,因此,也可以判断struct node中第一个元素应该是int),此时ebx的内容为node6的地址,node6的地址的内容为node6.d1,即node5.d1与node6.d1相比较。 5)645-646行:如果node6.d1 >= node5.d1,则跳转到8048f46 6)647行:ebx的内容变为其指向的节点的next,即ebx=node6-next,指向了node5 7)648行:esi-= 1 8)649行:如果esi不为0,则跳转到642行,按以上的2)继续分析,应注意,此处ebx的值为node5的地址了。 9)显然,此时会判断node5.d1是否大于等于node4.d1,如果是,则继续,如果不是,则引爆炸弹 10)后续会依次判断node4.d1是否大于等于node3.d1,node3.d1是否大于等于node2.d1,…,综合起来,就是判断按照num值排序之后的节点是否降序排列,如果是,则解题成功,如果不是,则引爆炸弹。 根据以上分析,phase_6的功能: 1)phase_6定义了一个包含6个节点的链表,每个节点中包含两个整型(d1,d2),以及指向下一个节点的指针;6个节点依次的链接顺序为node1->node2->node3->node4->node5->node6 2)要求用户输入6个数,这6个数应为1~6,而且不能重;为便于以后说明,假设这6个数为6/5/4/3/2/1。 3)按照num[i]的值重新排列链表,此时链表变为: node6->node5->node4->node3->node2->node1 4)判断以上链表是否降序排列(按分量d1),如果是,则拆弹成功,否则,引爆炸弹。 也即phase_6会给出一个链表,链表中的节点的d1分量含有一个整数值,需要用户输入一个序列号,按照这个顺序重新排列链表中的节点,如果链表是按照降序排列,则输入的这个序列号是正确的。 对于前面的炸弹,其初始化的节点值为: node1 = {0x6d, 0x01, 0x804c180}; (&node1 = 0x804c174) node2 = {0x69, 0x02, 0x804c18c }; (&node2 = 0x804c180) node3 = {0x3b2, 0x03, 0x804c198}; (&node3 = 0x804c18c) node4 = {0x299, 0x04, 0x804c1a4}; (&node4 = 0x804c198) node5 = {0xc7, 0x05, 0x804c1b0}; (&node5 = 0x804c1a4) node6 = {0x285b, 0x06, 0}; (&node6 = 0x804c1b0) 显然,使得这个链表按降序排列的序列是:3 4 6 5 1 2,因此,输入的序列号应为:3 4 6 5 1 2,此即为本关答案。 上课提示有一个隐藏关,并且在phase_defused中,作为一种锻炼,我们还是继续深入看看 1.这是调用sscanf函数前的栈帧情况: 2.这是调用strings_not_equal前的栈帧 3.这是调用secret_phase前的栈帧 。则对计算s,当且仅当s
。则对计算s,当且仅当s2.3.2 补码加法
![]() 为整数和x+y被截断为w位的结果,并将这个结果看做是补码数。
为整数和x+y被截断为w位的结果,并将这个结果看做是补码数。
2.3.3 补码的非
![]() 下的加法逆元,我们将
下的加法逆元,我们将 表示如下。
表示如下。
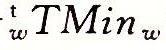 =-2w+2w=0。对满足x>TMinw的x,数值-x可以表示为一个w位的补码,它们的和-x+x=0。
=-2w+2w=0。对满足x>TMinw的x,数值-x可以表示为一个w位的补码,它们的和-x+x=0。2.3.4 无符号乘法

2.3.5 补码乘法
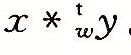 。将一个补码数截断为w为相当于先计算该值模2w,再把无符号数转换为补码,得到:
。将一个补码数截断为w为相当于先计算该值模2w,再把无符号数转换为补码,得到:
2.3.6 乘以常数

2.3.7 除以2的幂
2.3.8 关于整数运算的思考
2.4 浮点数
2.4.1 二进制小数
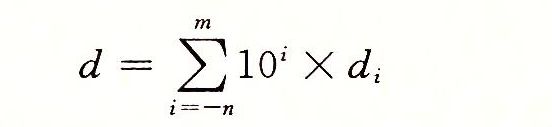
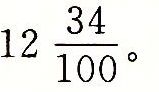
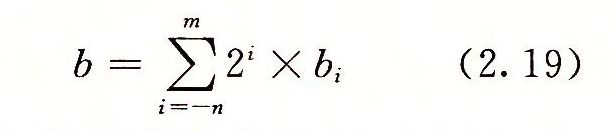
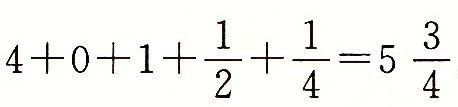 。
。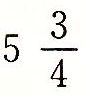 ,而10.1112表示数
,而10.1112表示数 。类似,二进制小数点像右移动一位相当于该值乘2。例如1011.12表示数
。类似,二进制小数点像右移动一位相当于该值乘2。例如1011.12表示数 。
。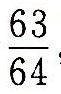 ,我们将用简单的表达法1.0-
,我们将用简单的表达法1.0-![]() 来表示这样的数值。
来表示这样的数值。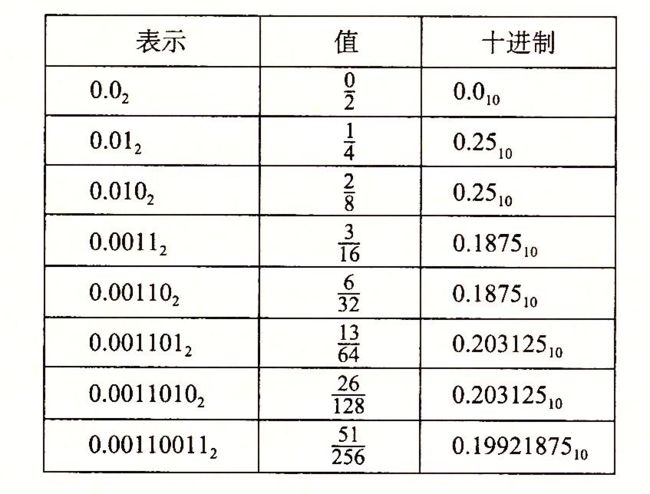
小数值
二进制表示
十进制表示
1/8
0.001
0.125
3/4
0.11
0.75
25/16
1.1001
1.5625
43/16
10.1011
2.6785
9/8
1.001
1.125
47/8
101.111
5.875
51/16
11.0011
3.1875
2.4.2 IEEE浮点表示
![]() 。
。
![]() ,或者当s=1时是-
,或者当s=1时是-![]() 。*当我们把两个非常大的数相乘,或者除以0时,无穷能够表示溢出的结果。当小数域为非零时,结果值被称为"NaN",(Not aNumber)。一些运算的结果不能是实数或无穷,就会返回这样的NaN值,比如计算
。*当我们把两个非常大的数相乘,或者除以0时,无穷能够表示溢出的结果。当小数域为非零时,结果值被称为"NaN",(Not aNumber)。一些运算的结果不能是实数或无穷,就会返回这样的NaN值,比如计算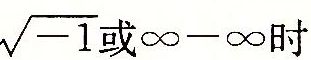 。在某些应用中,表示未初始化的数据是,还是很有用处的。
。在某些应用中,表示未初始化的数据是,还是很有用处的。2.4.3 数字示例
![]() 14。非规格化数聚集在0的附近。图的b部分中,我们只展示了介于-1.0~+1.0之间的数值,这样就能看得更清楚了。两个零是特殊的非规格化数。可以观察到,那些可表示的数并不是均匀分布的–越靠近原点处它们越稠密。
14。非规格化数聚集在0的附近。图的b部分中,我们只展示了介于-1.0~+1.0之间的数值,这样就能看得更清楚了。两个零是特殊的非规格化数。可以观察到,那些可表示的数并不是均匀分布的–越靠近原点处它们越稠密。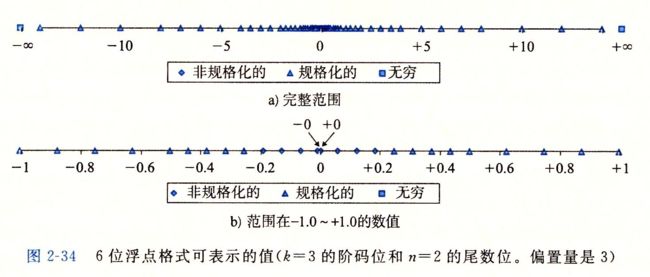
![]() 。
。

![]() )和阶码值E=-2k-1+2。因此,数值
)和阶码值E=-2k-1+2。因此,数值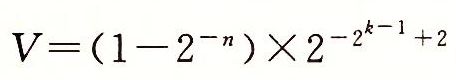 ,这仅比最小的规格化值小一点。
,这仅比最小的规格化值小一点。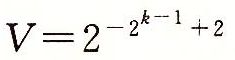
![]() )。它的阶码值E=2k-1-1,得到数值
)。它的阶码值E=2k-1-1,得到数值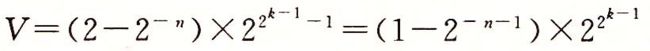 。
。第 3 章:程序的机器级表示
3.1 历史观点
3.2 程序编码
gcc -Og -o p p1.c p2.c
3.2.1 机器级代码
1.程序计数器(PC,%rip表示):指出将要执行的下一条指令的内存地址。
2.整数寄存器
3.条件码寄存器
4.向量寄存器3.2.2 代码示例
// mstore.c
long mult2(long, long);
void multstore(long x, long y, long *dest) {
long t = mult2(x, y);
*dest = t;
}
gcc -Og -S mstore.c
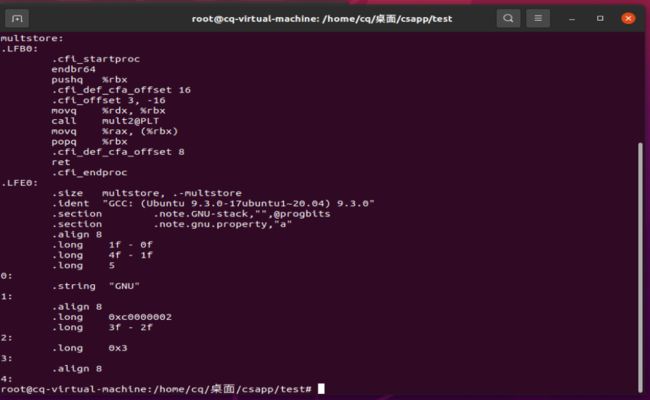
gcc -Og -c mstore.s
objdump -d mstore.o

#include gcc -Og -o prog main.c mstore.c
objdump -d prog
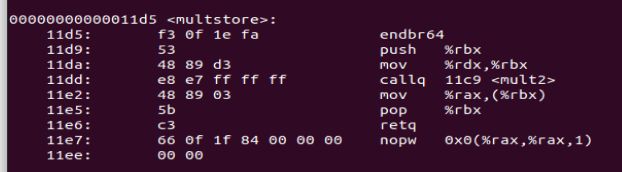
3.2.3 关于格式的注解
3.3 数据格式

3.4访问信息

3.4.1操作数指示符
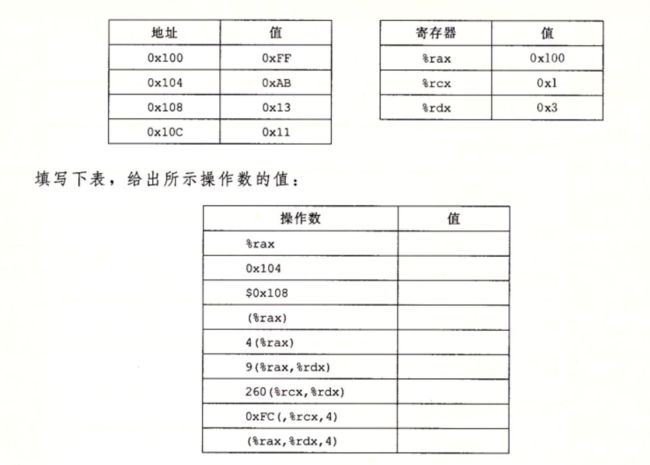
%rax对应0x100, 0x104对应0xAB, $0x108对应0x108, (%rax)对应0xFF, 4(%rax)对应0xAB, 9(%rax,%rdx)对应0x11
260(%rcx,%rdx)对应0x13, 0xFC(,%rcx,4)对应0xFF, (%rax,%rdx,4)对应0x11
讲解一下260(%rcx,%rdx),因为260=0x104,所以操作数是0x104+0x1+0x3=0x108地址对应的值,是0x13
12345
3.4.2数据传送指令
3.4.3数据传送示例

函数返回指令 ret 返回的值为寄存器 rax 中的值3.4.4压入和弹出栈数据
出入栈指令:
3.5算术和逻辑操作
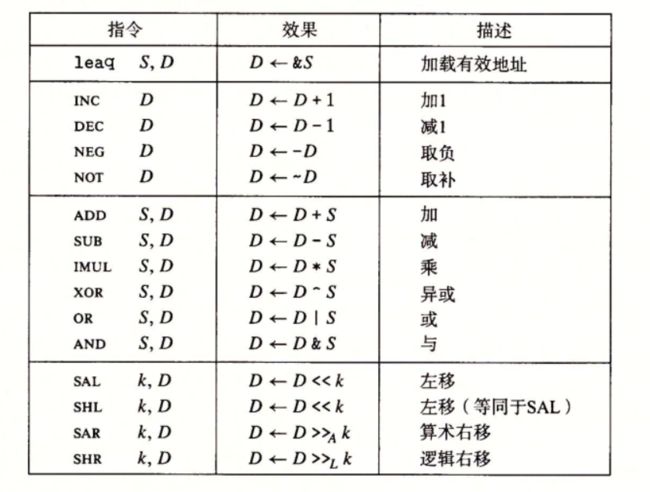
3.5.1加载有效地址

3.5.2一元和二元操作
二元操作中的第二个操作数既是源又是目的。
因为不能从内存到内存,因此当第二个操作数是内存地址时,要先从内存读出值,执行操作后再把结果写回去。3.5.3移位操作
当移位量大于目的数的长度时,只取移位量低字节中的值(小于目的数长度)来作为真实的移位量。3.5.4特殊的算术操作

3.6控制
3.6.1条件码
3.6.2访问条件码

3.6.3跳转指令
movq $0,%rax
jmp .L1 ;
movq (%rax),%rdx
.L1:
popq %rdx
12345
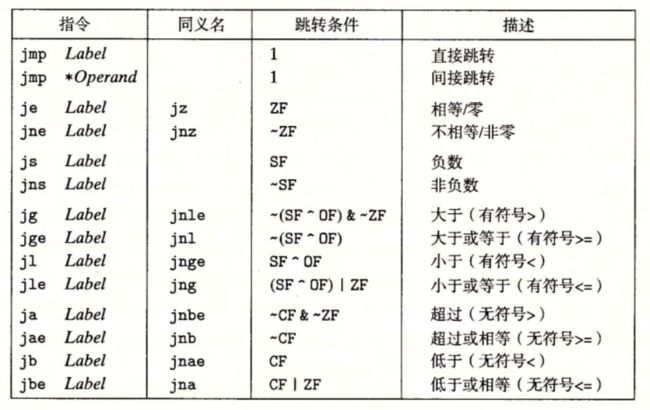
3.6.4跳转指令的编码
3.6.5用条件控制来实现条件分支

3.6.6用条件传送来实现条件分支


3.6.7循环
do
body-statement
while(test-expr)
123
loop:
body-statement
t = test-expr;
if (t)
goto loop;
12345
3.6.8switch
3.7过程
3.7.1运行时栈

3.7.2转移控制

3.7.3数据传送
3.7.4栈上的局部存储

3.7.5寄存器中的局部存储空间
递归过程

3.8数据的分配和访问
3.9异质的数据结构
3.9.1结构
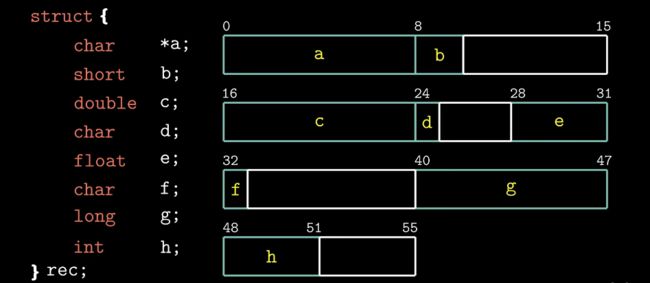
3.9.2联合
3.9.3数据对齐

3.10在机器级程序中将控制与数据结合起来
3.10.1理解指针
int fun(int x, int y)
int (*fp)(int,int)
fp = fun
123
3.10.2使用GDB调试器
linux> gdb prog
1

3.10.3内存越界引用和缓冲区溢出
//库函数gets()的实现
char *gets(char *s)
{
int c;
char *dest=s;
//从标准输入读入一行,在遇到一个回车换行字符或某个错误情况时停止
while((c=getchar())!='\n' && c!=EOF)
{
*dest++=c;
}
//将字符串复制到参数s指明的位置后,在字符串的末尾加上NULL字符
if(c==EOF && dest==s)
{
retuen NULL;
}
*dest++='\0';
return s;
}
//从标准行输入中读入一行,再将其送回到标准输出
void echo()
{
char buf[8];//设置8字节的缓冲区,任何长度超过7个字符的字符串都会导致写越界
gets(buf);
puts(buf);
}
12345678910111213141516171819202122232425
void echo()
echo:
subq $24,%rsp
movq %rsp,%rdi
call gets
movq %rsp,%rdi
call puts
addq $24,%rsp
ret
123456789

3.10.4对抗缓冲区溢出攻击
3.10.5支持可变栈帧

3.11 浮点代码
x86-64 浮点体系结构的历史: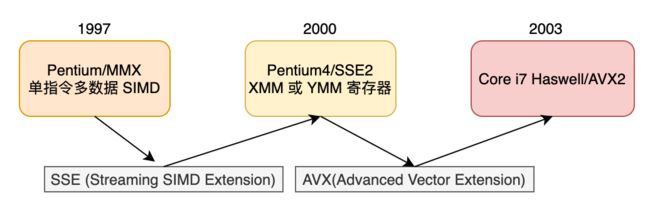
%ymm0~%ymm15。每个 YMM 寄存器都是 256(32 字节)。当对标量数据操作时,这些寄存器值保存浮点数,而且只使用低 32 位(对于 float) 或 64 位(对于 double)。汇编代码用寄存器的 SSE XMM 寄存器名字 %xmm0~%xmm15 来引用它们,每个 XMM 寄存器都是对应的 YMM 寄存器的低 128 位(16字节)。3.11.1 浮点传送和转化操作
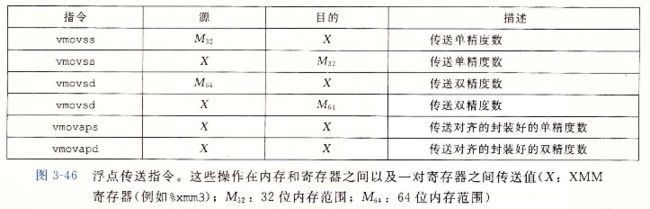
GCC 只用标量传送操作从内存传送数据到 XMM 寄存器或从 XMM 寄存器传送数据到内存。对于在两个 XMM 寄存器之间传送数据,GCC 会使用两种指令之一,即用 vmpovaps 传送单精度数,用 vmovapd 传送双精度数。对于这些情况,程序复制整个寄存器还是只复制低位值。既不会影响程序功能,也不会影响执行速度,所以使用这些指令还是针对标量数据的人指令没有实质上的差别。指令名字中的字母 ‘a’ 表示 “aligned(对齐的)"。当用于读写内存是,如果地址不满足16字节对齐,它们会导致异常。在两个寄存器之间传送数据,绝不会出现错误对齐的状况。3.11.2 过程中的浮点代码
x86-64 中,XMM 寄存器用来向函数传递浮点参数,以及从函数返回浮点值。具有以下规则:
%xmm0~%xmm7 最多可以传递 8 个浮点参数。按照参数列出的顺序使用这些寄存器。可以通过栈传递额外的浮点参数。
1 2 3 4 5 6// 这个函数会把 x 存放在 %edi 中,y 放在 %xmm0 中,z 放在 %rsi 中。 double f1(int x, double y, long z); // 这个函数的寄存器分配与函数 f1 相同。 double f2(double y, int x, long z); // 这个函数会将 x 放在 %xmm0 中,y 放在 %rdi 中,z 放在 %rsi 中。 double f1(float x, double *y, long *z);
3.11.3 浮点运算操作

3.11.4 定义和使用浮点常数
3.11.5 在浮点代码中使用位级操作

3.11.6 浮点比较操作
第6章 存储器层次结构
L1L3高速缓存:475个周期
主存:上百个周期
磁盘:几千万个周期6.1存储技术
 6.1.1随机访问存储器
6.1.1随机访问存储器SRAM
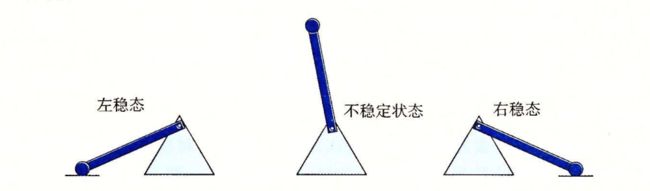 对于 SRAM,只要有双双稳态即该电路无限期地稳定保持在两个不同的电压状态。只要有电,就永远地保持它的值。即使有干扰,当干扰消除,电路也会恢复到稳定值。
对于 SRAM,只要有双双稳态即该电路无限期地稳定保持在两个不同的电压状态。只要有电,就永远地保持它的值。即使有干扰,当干扰消除,电路也会恢复到稳定值。DRAM
DRAM 对干扰非常敏感。当电容的电压被扰乱后,就永远不会恢复了。SRAM 与 DRAM 比较

传统的 DRAM
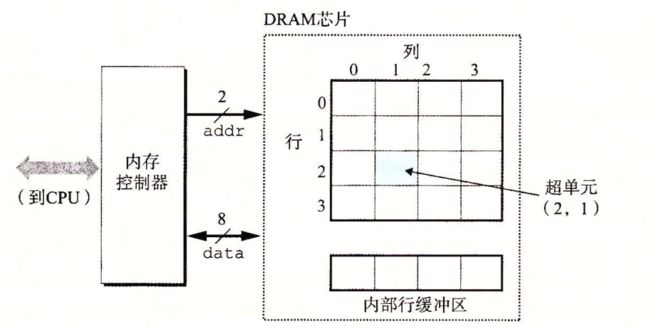
内存控制器依次将行地址和列地址发送给 DRAM,DRAM 将对应的超单元的内容发回给内存控制器以实现读取数据。
行地址和列地址共享相同的 DRAM 芯片地址引脚。
从 DRAM 中读取超单元的步骤:
内存控制器发来行地址 i,DRAM 将整个第 i 行复制到内部的行缓冲区。
内存控制器发来列地址 i,DRAM 从行缓冲区中复制出超单元 (i,j) 并发送给内存控制器。
内存模块
常用的是双列直插内存模块 (DIMM),以 64 位为块与内存控制器交换数据。
比如,一个内存模块包含 8 个 DRAM 芯片,每个 DRAM 包含 8M 个超单元,每个超单元存储一个字节。使用 8 个 DRAM 芯片上相同地址处的超单元来表示一个 64 位字,DRAM 0 存储第一个字节,DRAM 1 存储第 2 个字节,依此类推。
要取出内存地址 A 处的一个字,内存控制器先将 A 转换为一个超单元地址 (i,j),然后内存模块将 i,j 广播到每个 DRAM。作为响应,每个 DRAM 输出它的 (i,j) 超单元的 8 位内容,合并成一个 64 位字,再返回给内存控制器。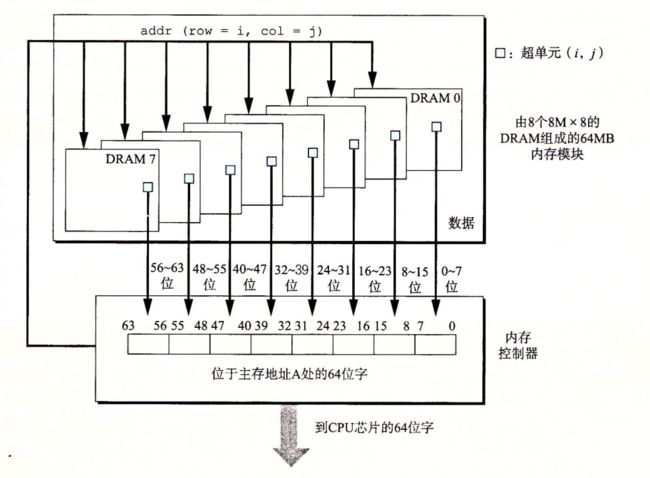
增强的 DRAM
非易失性存储器
ROM 是只读存储器,但是实际上有些 ROM 既可以读也可以写。
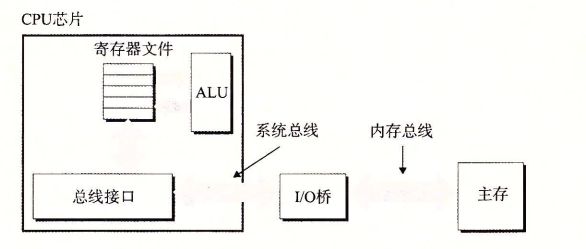
访问主存
6.2磁盘存储
磁盘构造
盘片以固定速率旋转,通常为 5400~15000,单位是转每分钟 (RPM)。
每个表面由多个同心圆(称为磁道)组成,每个磁道被划分为一组扇区,每个扇区包含相同的数据位(一般为512字节)。
扇区之间由间隙分隔开,间隙中不存储数据位,而存储用来标识扇区的格式化位。
名词柱面用来表示距离主轴相等的磁道的集合。比如一个磁盘有 3 个盘片,那么每个柱面就有 6 个磁道。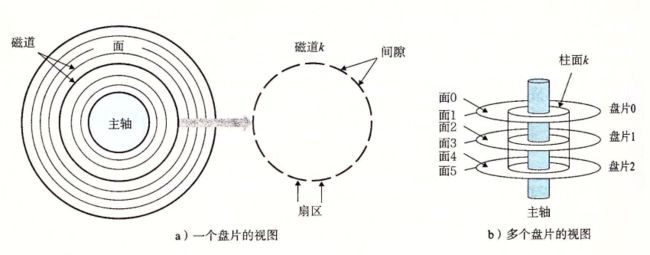
磁盘容量

注:磁盘格式化会填写间隙、标识出有故障的柱面、在每个区中预留出一组柱面作为备用。所以格式化容量要比最大容量小。磁盘操作
读写头位于传动壁的末端,读写头的速度约为 80km/h,距磁盘表面约 1um,因此磁盘是很脆弱的,开机时不要挪动主机更不要拍主机。
磁盘读写数据时以扇区为单位,即一次读写一个扇区大小的块。
对扇区的访问时间包括三部分:
逻辑磁盘块
现代磁盘呈现为一个逻辑块的序列,每个逻辑块大小为一个扇区,即 512 字节。
当操作系统读写磁盘时,发送一个逻辑块号到磁盘控制器,控制器上的固件将逻辑块号翻译为一个(盘面、磁道、扇区)的三元组。
12
连接 I/O 设备
IO 总线速度相比于系统总线和内存总线慢,但是可以容纳种类繁多的第三方 IO 设备。
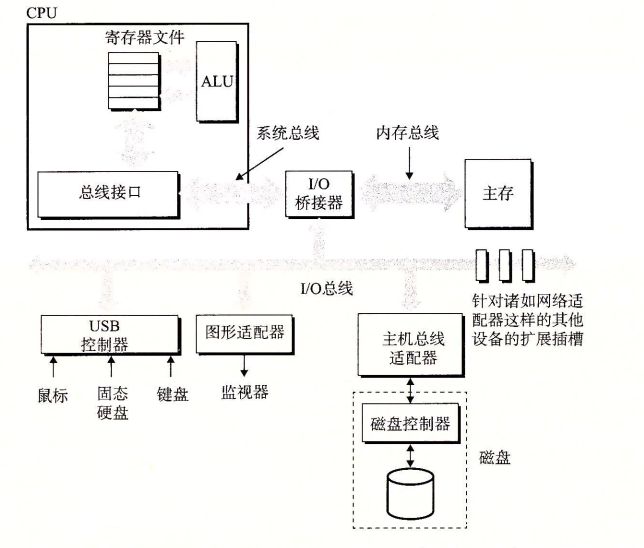
CPU 使用内存映射 IO 技术来向 IO 设备发射命令。在使用内存映射 IO 的系统中,地址空间中有一块地址是专为与 IO 设备通信保留的,每个这样的地址称为一个 IO 端口。当一个设备连接到总线时,它与一个或多个端口相关联。
CPU 依次发送命令字、逻辑块号、目的内存地址到 0xa0,发起一个磁盘读。因为磁盘读的时间很长,所以此后 CPU 会转去执行其他工作。
磁盘收到读命令后,将逻辑块号翻译成一个扇区地址,读取该扇区的内容,并将内容直接传送到主存,不需要经过 CPU (这称为直接内存访问(DMA))。
DMA 传送完成后,即磁盘扇区的内容安全地存储在主存中后,磁盘控制器给 CPU 发送一个中断信号来通知 CPU。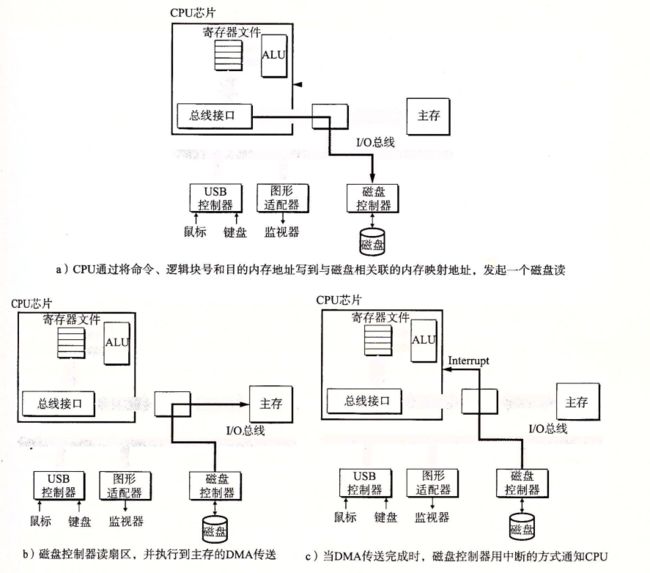
6.1.3固态硬盘
一个固态硬盘中封装了一个闪存翻译层和多个闪存芯片。闪存翻译层是一个硬件/固件设备,功能类似磁盘控制器,将对逻辑块的请求翻译成对底层物理设备的访问。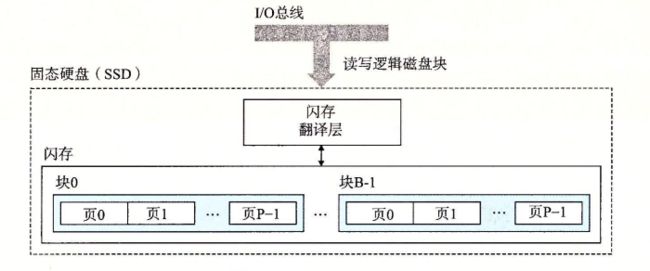
对于 SSD 来说,读比写快。因为只有在一页所属的块整个被擦除后,才能写这一页。重复写十万次后,块就会磨损,因此固态硬盘寿命较低。
随机写 SSD 很慢的两个原因:
缺点:更容易磨损,不过现在的 SSD 已经可以用很多年了。6.1.4存储技术趋势
发展速度上:增加密度(降低成本) > 降低访问时间
DRAM 和 磁盘的性能滞后于 CPU 的性能提升速度,两者之间的差距越来越大。6.2局部性
6.2.1对程序数据引用的局部性
int sumvec(int v[N])
{
int i = 0, sum = 0;
for(i=0; i
这里对向量 v 中元素的访问是顺序访问的,称为步长为 1 的引用模式。在空间局部性上,步长为 1 的引用模式是最好的。6.2.2取指令的局部性
6.2.3局部性小结
6.3存储器层次结构
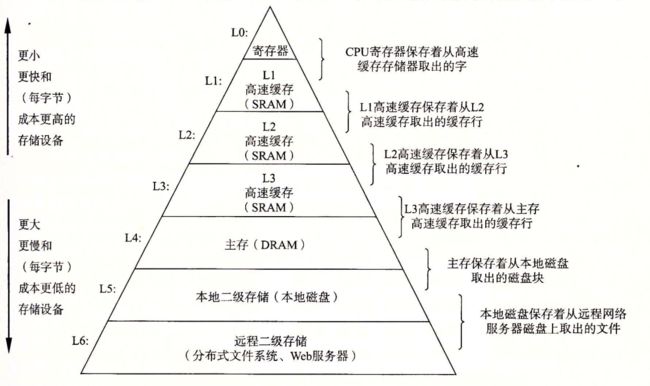
6.3.1存储器层次结构中的缓存
缓存不命中时,第 k 层的缓存从 第 k+1 层缓存中取出包含 d 的块。
如果第 k 层缓存已经满了,需要根据替换策略选择一个块进行覆盖 (替换),未满的话需要根据放置策略来选择一个块放置。
6.4高速缓存存储器
6.4.1通用的高速缓存存储器组织结构
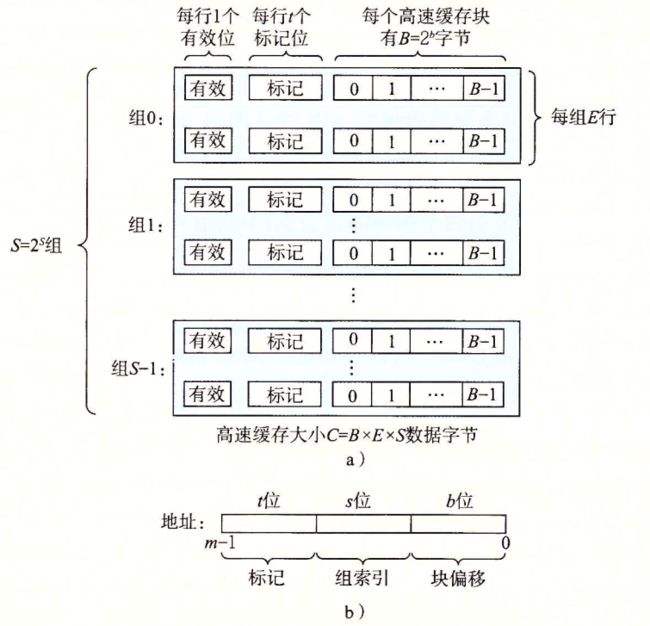

6.4.2直接映射高速缓存
1、直接映射高速缓存中的组选择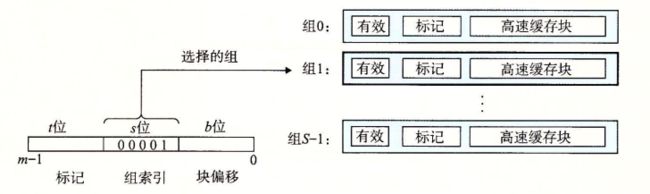

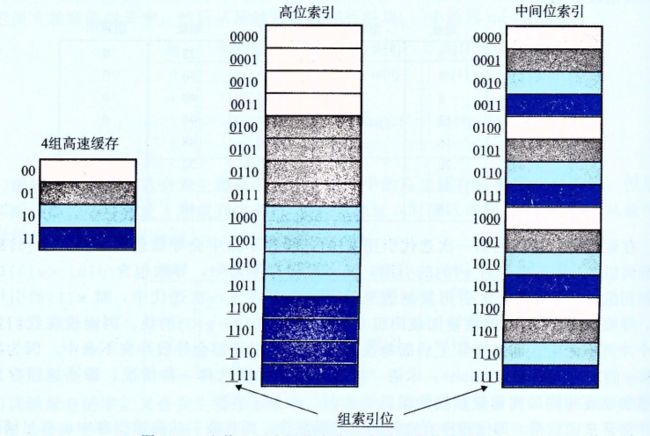
6.4.3组相联高速缓存
6.4.4全相联高速缓存
6.4.5有关写的问题
6.4.6一个真实的高速缓存层次结构的解剖
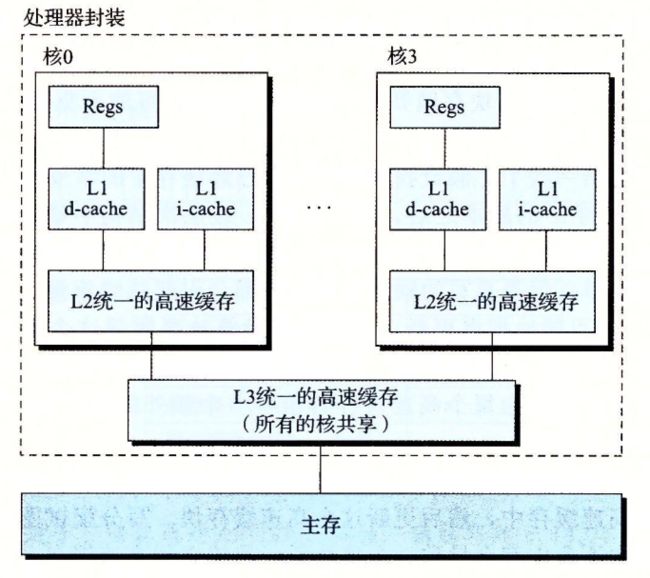

6.4.7高速缓存参数的性能影响
第7章 链接
概念
为什么需要了解链接器
ELF (Executable and Linkable Format)是一种为可执行文件,目标文件,共享链接库和内核转储(core dumps)准备的标准文件格式。 Linux和很多类Unix操作系统都使用这个格式。
1
7.1编译器驱动程序

linux> gcc -Og -o prog main.c sum.c
1
linux> ./prog
1
7.2静态链接
7.3目标文件
7.4可重定位目标文件
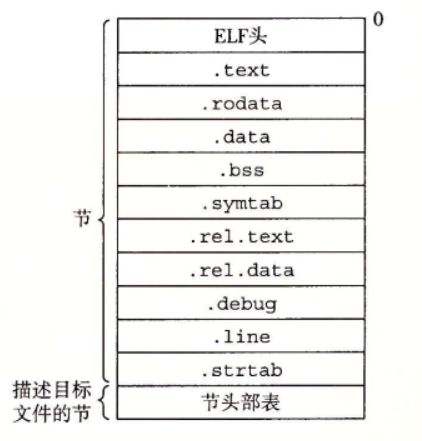
7.5符号和符号表

typedef struct{
int name;//name 是一个字符串表(.strtab节)中的字节偏移,指向符号的名字(用一个以 null 结尾的字符串表示)
char type:4;//表明符号的类型:数据或函数(4 bits)
binding:4;//表明符号是本地的还是全局的(4 bits)//这里的意思似乎是 type 和 binding 分别是一个 char 类型的高四位和低四位
char reserved;//
short section;//表明符号位于文件的哪个节中,section 是一个到节头部表的索引。
long value;//对于可重定位文件而言,value 是距定义目标的节的起始位置的偏移;对于可执行文件而言,value 是一个绝对运行时地址
long size;//对象的大小,以字节为单位
}
123456789
7.6符号解析
7.6.1如何解析多重定义的全局符号
7.6.2与静态库链接
linux> gcc main.c /usr/lib/libm.a /usr/lib/libc.a //使用C标准库和数学库中的函数
1

linux> gcc -c addvec.c multvec.c //将 addvec.c 和 multvec 两个文件编译成两个可重定位目标文件
linux> ar rcs libvector.a addvec.o multvec.o //采用 ar 工具将上一步生成的两个可重定位目标文件 addvec.o 和 multvec.o 封装到静态库 libvector.o 中。
12

linux> gcc -c main2.c
linux> gcc -static -o prog2c main2.o ./libvector.a
12

7.6.3链接器如何解析引用
7.7重定位
7.7.1重定位条目

typedef struct{
long offset; //需要被修改的引用的节偏移(即该符号引用距离所在节的初始位置的偏移)。
long type:32, //重定位类型,不同的重定位类型会用不同的方式来修改引用
symbol:32; //symbol table index,指向被修改引用应该指向的符号
long addend; //一个有符号常数,一些类型的重定位要使用它对被修改引用的值做偏移调整
}
123456
7.7.2重定位符号引用

7.8可执行目标文件

7.9加载可执行目标文件
linux > ./prog
1

7.10动态链接共享库
linux> gcc -shared -fpic -o libvector.so addvec.c multvec.c //将 addvec.c 和 multvec.c 封装到动态库 libvector.so 中
// -fpic 选项指示编译器生成与位置无关的代码。
// -shared 选项指示链接器创建一个共享的目标文件。
123
linux> gcc -o prog21 main2.c ./libvector.so //创建了一个可执行目标文件 prog21
1
7.11从应用程序中加载和链接共享库
#include 7.12位置无关代码
7.13库打桩机制
linux> gcc -DCOMPILETIME -c mymalloc.c
linux> gcc -I. -o intc int.c mymalloc.o
linux> ./intc
malloc(32)=0x9ee010
free(0x9ee010)
123456
7.14处理目标文件的工具
命令
说明
AR
创建静态库,插入、删除、列出和提取成员
STRING
列出一个目标文件中所有可以打印的字符串
STRIP
从目标文件中删除符号表信息
NM
列出一个目标文件中符号表中定义的符号
SIZE
列出目标文件中节的名字和大小
READELF
显示一个目标文件的完整结构,包括ELF头中编码的所有信息,包含SIZE和NM的功能
OBJDUMP
所有二进制工具之母,能够显示目标文件中的所有信息。它最大的作用是反汇编.text节中的二进制指令
LDD
列出一个可执行文件在运行时所需的共享库
7.15总结
lab1 Data Lab
CSAPP https://link.zhihu.com/?target=http%3A//csapp.cs.cmu.edu/3e/labs.html官网CSAPP 的实验了,这次是第一次实验,内容是关于计算机信息的表示,主要是位操作、整数题和浮点数相关的题。题目列表
名称
描述
难度
指令数目
bitXor(x,y)
只使用
~ 和 & 实现 ^1
14
tmin()
返回最小补码
1
4
isTmax(x)
判断是否是补码最大值
1
10
allOddBits(x)
判断补码所有奇数位是否都是 1
2
12
negate(x)
不使用负号
- 实现 -x2
5
isAsciiDigit(x)
判断
x 是否是 ASCII 码3
15
conditional(x, y, z)
类似于 C 语言中的
x?y:z3
16
isLessOrEqual(x,y)
x<=y3
24
logicalNeg(x)
计算
!x 而不用 ! 运算符4
12
howManyBits(x)
计算表达
x 所需的最少位数4
90
floatScale2(uf)
计算
2.0*uf4
30
floatFloat2Int(uf)
对于浮点参数 f,返回 (int) f 的位级等价数
4
30
floatPower2(x)
对于整数 x,返回 2.0^x
4
30
准备
sudo apt-get update
sudo apt-get install git
拉csapp实验的库
git clone https://github.com/ScarboroughCoral/CSAPP-Lab.git
安装make,用来编译c
sudo apt -y install make
安装gcc依赖
sudu apt -y install gcc
发现64位系统并不能成功编译会报错,国外论坛查阅后用下面命令安装32位依赖
sudo apt-get install gcc-multilib
题解
bitXor(x,y)
/*
* bitXor - x^y using only ~ and &
* Example: bitXor(4, 5) = 1
* Legal ops: ~ &
* Max ops: 14
* Rating: 1
*/
int bitXor(int x, int y) {
return ~(~x&~y)&~(x&y);
}
~ 和 & ,即非和与操作实现异或操作。所谓异或就是当参与运算的两个二进制数不同时结果才为 1,其他情况为 0。C 语言中的位操作对基本类型变量进行运算就是对类型中的每一位进行位操作。所以结果可以使用 “非” 和 “与” 计算不是同时为 0 情况和不是同时为 1 的情况进行位与,即 ~(~x&~y)&~(x&y) 。
tmin()
int 值。这个题目也是比较简单。/*
* tmin - return minimum two's complement integer
* Legal ops: ! ~ & ^ | + << >>
* Max ops: 4
* Rating: 1
*/
int tmin(void) {
return 0x1<<31;
}
int 类型是 32 位,即 4 字节数。**补码最小值就是符号位为 1,其余全为 0。**所以只需要得到这个值就行了,我采用的是对数值 0x1 进行移位运算,得到结果。isTmax(x)
/*
* isTmax - returns 1 if x is the maximum, two's complement number,
* and 0 otherwise
* Legal ops: ! ~ & ^ | +
* Max ops: 10
* Rating: 1
*/
int isTmax(int x) {
int i = x+1;//Tmin,1000...
x=x+i;//-1,1111...
x=~x;//0,0000...
i=!i;//exclude x=0xffff...
x=x+i;//exclude x=0xffff...
return !x;
}
int 类型来说的,最大值当然是符号位为 0,其余全是 1,这是补码规则,不明其意则 Google。在此说一下个人理解,最终返回值为 0 或 1,要想判断给定数 x 是不是补码最大值(0x0111,1111,1111,1111),则需要将给定值 x 向全 0 值转换判断,因为非 0 布尔值就是 1,不管你是 1 还是 2。根据我标注的代码注释理解,如果 x 是最大值,将其转换为全 0 有很多方法,不过最终要排除转换过程中其他的数值,比如本例子中需要排除 0xffffffffffffffff 的情况:将 x 加 1 的值再和 x 相加,得到了全 1(函数第二行),然后取反得到全 0,因为补码 - 1 也有这个特点,所以要排除,假设 x 是 -1,则 +1 后为全 0,否则不为全 0,函数 4-5 行则是排除这种情况。allOddBits(x)
/*
* allOddBits - return 1 if all odd-numbered bits in word set to 1
* where bits are numbered from 0 (least significant) to 31 (most significant)
* Examples allOddBits(0xFFFFFFFD) = 0, allOddBits(0xAAAAAAAA) = 1
* Legal ops: ! ~ & ^ | + << >>
* Max ops: 12
* Rating: 2
*/
int allOddBits(int x) {
int mask = 0xAA+(0xAA<<8);
mask=mask+(mask<<16);
return !((mask&x)^mask);
}
mask ,然后获取输入 x 值的奇数位,其他位清零(mask&x),然后与 mask 进行异或操作,若相同则最终结果为0,然后返回其值的逻辑非。negate(x)
- 操作符,求 -x 值。这个题目是常识。/*
* negate - return -x
* Example: negate(1) = -1.
* Legal ops: ! ~ & ^ | + << >>
* Max ops: 5
* Rating: 2
*/
int negate(int x) {
return ~x+1;
}
阿贝尔群,对于 x,-x 是其补码,所以 -x 可以通过对 x 取反加1得到。isAsciiDigit(x)
ASCII 值。这个题刚开始还是比较懵的,不过这个题让我认识到了位级操作的强大。/*
* isAsciiDigit - return 1 if 0x30 <= x <= 0x39 (ASCII codes for characters '0' to '9')
* Example: isAsciiDigit(0x35) = 1.
* isAsciiDigit(0x3a) = 0.
* isAsciiDigit(0x05) = 0.
* Legal ops: ! ~ & ^ | + << >>
* Max ops: 15
* Rating: 3
*/
int isAsciiDigit(int x) {
int sign = 0x1<<31;
int upperBound = ~(sign|0x39);
int lowerBound = ~0x30;
upperBound = sign&(upperBound+x)>>31;
lowerBound = sign&(lowerBound+1+x)>>31;
return !(upperBound|lowerBound);
}
x 是否在 0x30 - 0x39 范围内就是这个题的解决方案。那如何用位级运算来操作呢?我们可以使用两个数,一个数是加上比0x39大的数后符号由正变负,另一个数是加上比0x30小的值时是负数。这两个数是代码中初始化的 upperBound 和 lowerBound,然后加法之后获取其符号位判断即可。conditional(x, y, z)
x?y:z三目运算符。又是位级运算的一个使用技巧。/*
* conditional - same as x ? y : z
* Example: conditional(3,4,5) = 4
* Legal ops: ! ~ & ^ | + << >>
* Max ops: 16
* Rating: 3
*/
int conditional(int x, int y, int z) {
x = !!x;
x = ~x+1;
return (x&y)|(~x&z);
}
x 的布尔值转换为全0或全1是不是更容易解决了,即 x==0 时位表示是全0的, x!=0 时位表示是全1的。这就是1-2行代码,通过获取其布尔值0或1,然后求其补码(0的补码是本身,位表示全0;1的补码是-1,位表示全1)得到想要的结果。然后通过位运算获取最终值。isLessOrEqual(x,y)
<=
/*
* isLessOrEqual - if x <= y then return 1, else return 0
* Example: isLessOrEqual(4,5) = 1.
* Legal ops: ! ~ & ^ | + << >>
* Max ops: 24
* Rating: 3
*/
int isLessOrEqual(int x, int y) {
int negX=~x+1;//-x
int addX=negX+y;//y-x
int checkSign = addX>>31&1; //y-x的符号
int leftBit = 1<<31;//最大位为1的32位有符号数
int xLeft = x&leftBit;//x的符号
int yLeft = y&leftBit;//y的符号
int bitXor = xLeft ^ yLeft;//x和y符号相同标志位,相同为0不同为1
bitXor = (bitXor>>31)&1;//符号相同标志位格式化为0或1
return ((!bitXor)&(!checkSign))|(bitXor&(xLeft>>31));//返回1有两种情况:符号相同标志位为0(相同)位与 y-x 的符号为0(y-x>=0)结果为1;符号相同标志位为1(不同)位与x的符号位为1(x<0)
}
logicalNeg(x)
!/*
* logicalNeg - implement the ! operator, using all of
* the legal operators except !
* Examples: logicalNeg(3) = 0, logicalNeg(0) = 1
* Legal ops: ~ & ^ | + << >>
* Max ops: 12
* Rating: 4
*/
int logicalNeg(int x) {
return ((x|(~x+1))>>31)+1;
}
howManyBits(x)
/* howManyBits - return the minimum number of bits required to represent x in
* two's complement
* Examples: howManyBits(12) = 5
* howManyBits(298) = 10
* howManyBits(-5) = 4
* howManyBits(0) = 1
* howManyBits(-1) = 1
* howManyBits(0x80000000) = 32
* Legal ops: ! ~ & ^ | + << >>
* Max ops: 90
* Rating: 4
*/
int howManyBits(int x) {
int b16,b8,b4,b2,b1,b0;
int sign=x>>31;
x = (sign&~x)|(~sign&x);//如果x为正则不变,否则按位取反(这样好找最高位为1的,原来是最高位为0的,这样也将符号位去掉了)
// 不断缩小范围
b16 = !!(x>>16)<<4;//高十六位是否有1
x = x>>b16;//如果有(至少需要16位),则将原数右移16位
b8 = !!(x>>8)<<3;//剩余位高8位是否有1
x = x>>b8;//如果有(至少需要16+8=24位),则右移8位
b4 = !!(x>>4)<<2;//同理
x = x>>b4;
b2 = !!(x>>2)<<1;
x = x>>b2;
b1 = !!(x>>1);
x = x>>b1;
b0 = x;
return b16+b8+b4+b2+b1+b0+1;//+1表示加上符号位
}
floatScale2(f)
/*
* floatScale2 - Return bit-level equivalent of expression 2*f for
* floating point argument f.
* Both the argument and result are passed as unsigned int's, but
* they are to be interpreted as the bit-level representation of
* single-precision floating point values.
* When argument is NaN, return argument
* Legal ops: Any integer/unsigned operations incl. ||, &&. also if, while
* Max ops: 30
* Rating: 4
*/
unsigned floatScale2(unsigned uf) {
int exp = (uf&0x7f800000)>>23;
int sign = uf&(1<<31);
if(exp==0) return uf<<1|sign;
if(exp==255) return uf;
exp++;
if(exp==255) return 0x7f800000|sign;
return (exp<<23)|(uf&0x807fffff);
}
真正指数+bias)分别存储的的为0,0,,255,255。这些情况,无穷大和NaN都只需要返回参数( [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kx81MpJq-1645022218691)(https://www.zhihu.com/equation?tex=2%5Ctimes%5Cinfty%3D%5Cinfty%2C2%5Ctimes+NaN%3DNaN)] ),无穷小和0只需要将原数乘二再加上符号位就行了(并不会越界)。剩下的情况,如果指数+1之后为指数为255则返回原符号无穷大,否则返回指数+1之后的原符号数。floatFloat2Int(f)
/*
* floatFloat2Int - Return bit-level equivalent of expression (int) f
* for floating point argument f.
* Argument is passed as unsigned int, but
* it is to be interpreted as the bit-level representation of a
* single-precision floating point value.
* Anything out of range (including NaN and infinity) should return
* 0x80000000u.
* Legal ops: Any integer/unsigned operations incl. ||, &&. also if, while
* Max ops: 30
* Rating: 4
*/
int floatFloat2Int(unsigned uf) {
int s_ = uf>>31;
int exp_ = ((uf&0x7f800000)>>23)-127;
int frac_ = (uf&0x007fffff)|0x00800000;
if(!(uf&0x7fffffff)) return 0;
if(exp_ > 31) return 0x80000000;
if(exp_ < 0) return 0;
if(exp_ > 23) frac_ <<= (exp_-23);
else frac_ >>= (23-exp_);
if(!((frac_>>31)^s_)) return frac_;
else if(frac_>>31) return 0x80000000;
else return ~frac_+1;
}
floatPower2(x)
/*
* floatPower2 - Return bit-level equivalent of the expression 2.0^x
* (2.0 raised to the power x) for any 32-bit integer x.
*
* The unsigned value that is returned should have the identical bit
* representation as the single-precision floating-point number 2.0^x.
* If the result is too small to be represented as a denorm, return
* 0. If too large, return +INF.
*
* Legal ops: Any integer/unsigned operations incl. ||, &&. Also if, while
* Max ops: 31
* Rating: 4
*/
unsigned floatPower2(int x) {
int INF = 0xff<<23;
int exp = x + 127;
if(exp <= 0) return 0;
if(exp >= 255) return INF;
return exp << 23;
}

lab2 Bomb Lab
准备

1:将下载的炸弹包拷贝到Linux主机上;
2:使用tar -xvf “bomb名”进行解压;
解压后生成3个文件:
README:炸弹所属的用户信息;
bomb:二进制炸弹文件;
bomb.c:二进制炸弹文件的框架源文件,供解题者参考。
3:使用objdump -d bomb对二进制炸弹进行反汇编,并将其保存到一个文本文件中。
题解
phase_1

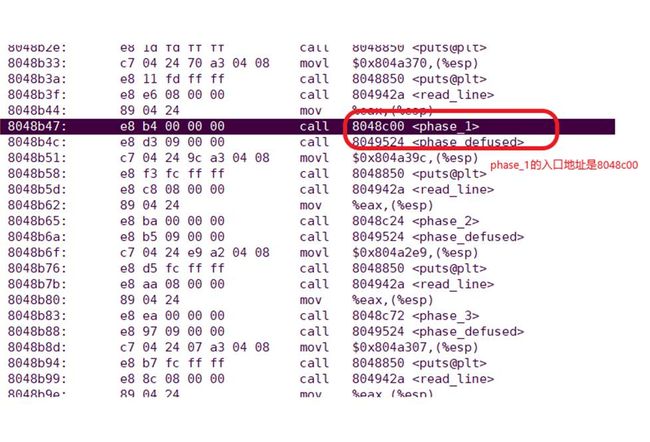

2、第379行:将0x804a3ec 放置到了esp+4的地方。
3、第381/382行:将input的内容放置到了esp的地方。注:20(%esp)正好是栈中存放input的内容。
4、第383行:调用strings_not_equal函数。
5、显然,第379行以及第381/382行是在为调用strings_not_equal函数准备参数。在调用strings_not_equal函数之前(即382行执行之后,383行执行之前),

![]() ](javascript:void(0)
](javascript:void(0)int32_t strings_not_equal(int32_t a1, int32_t a2);
void explode_bomb(int32_t a1, int32_t a2);
void phase_1(int32_t a1) {
int32_t eax2;
int32_t v3;
eax2 = strings_not_equal(a1, "Why make trillions when we could make... billions?");
if (eax2 != 0) {
explode_bomb(v3, a1);
}
return;
}
![]() ](javascript:void(0)
](javascript:void(0)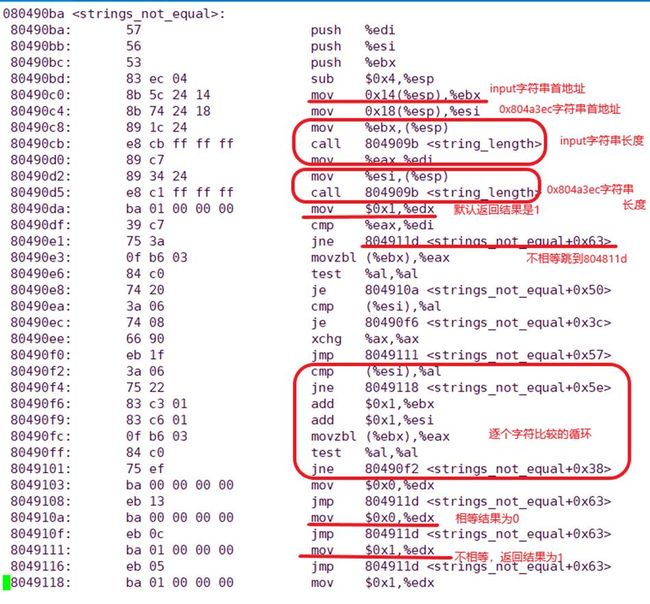

![]() ](javascript:void(0)
](javascript:void(0)int32_t string_length(signed char* a1);
int32_t strings_not_equal(signed char* a1, signed char* a2) {
signed char* ebx3;
signed char* esi4;
int32_t eax5;
int32_t eax6;
int32_t edx7;
int32_t eax8;
int32_t eax9;
ebx3 = a1;
esi4 = a2;
eax5 = string_length(ebx3);
eax6 = string_length(esi4);
edx7 = 1;
if (eax5 != eax6) {
addr_0x804911d_2:
return edx7;
} else {
eax8 = (int32_t)(uint32_t)(unsigned char)*ebx3;
if (*(signed char*)&eax8 == 0) {
edx7 = 0;
goto addr_0x804911d_2;
} else {
if (*(signed char*)&eax8 == *esi4) {
do {
++ebx3;
++esi4;
eax9 = (int32_t)(uint32_t)(unsigned char)*ebx3;
if (*(signed char*)&eax9 == 0)
break;
} while (*(signed char*)&eax9 == *esi4);
goto addr_0x8049118_8;
} else {
edx7 = 1;
goto addr_0x804911d_2;
}
}
}
edx7 = 0;
goto addr_0x804911d_2;
addr_0x8049118_8:
edx7 = 1;
goto addr_0x804911d_2;
}
![]() ](javascript:void(0)
](javascript:void(0)
phase_2



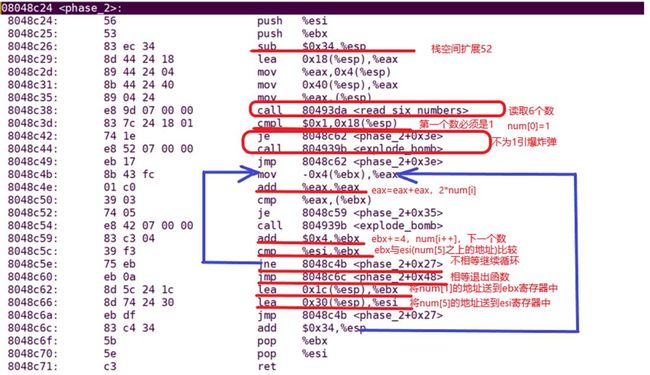
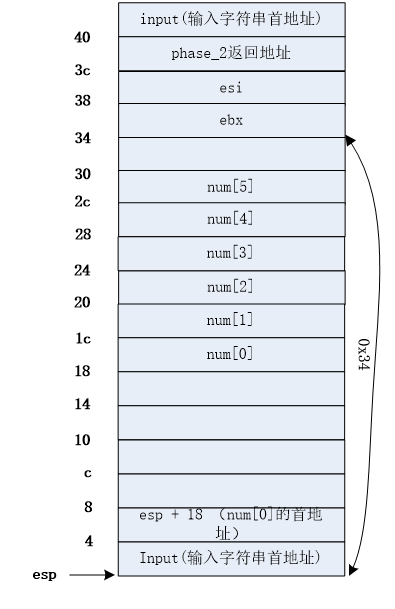

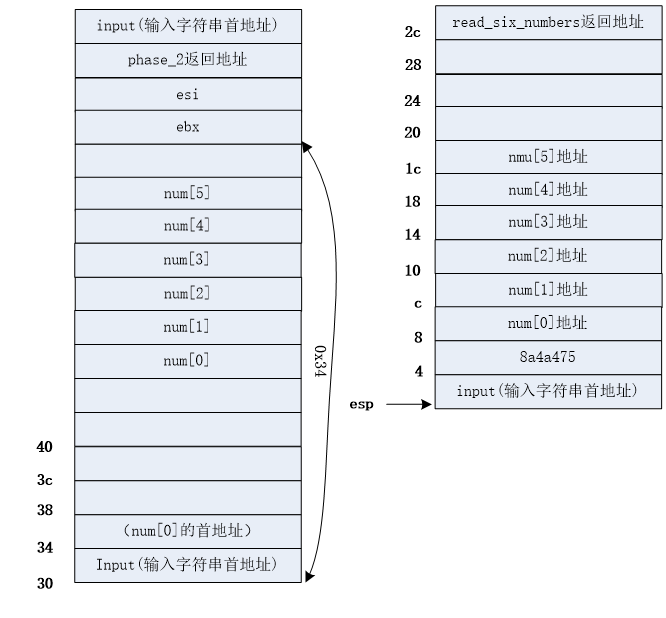
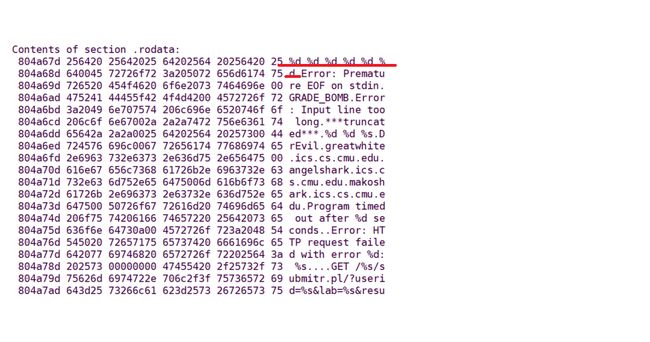
phase_3
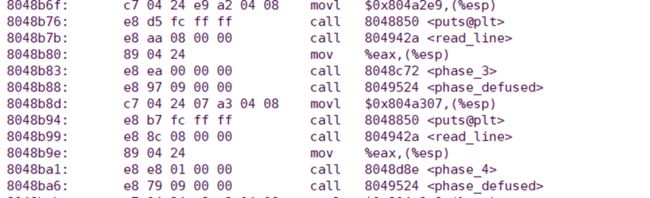




phase_4






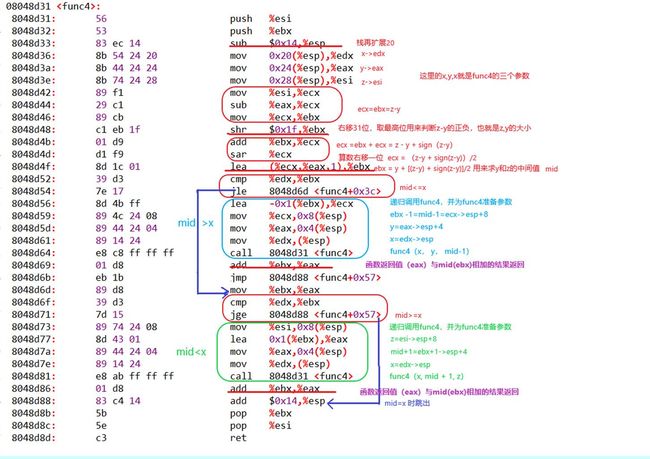

![]() ](javascript:void(0)
](javascript:void(0)int func4(int x, int y, int z)
{
int mid = 0;
if(z >= y)
{
mid = y + (z - y)/2;
}
else
{
mid = y + (z-y + 1)/2;
}
if(x == mid)
{
return mid;
}
else(if x < mid)
{
return mid + func4(x, y, mid -1);
}
else(if x > mid)
{
return mid + func(x, mid + 1, z);
}
}
![]() ](javascript:void(0)
](javascript:void(0)phase_5


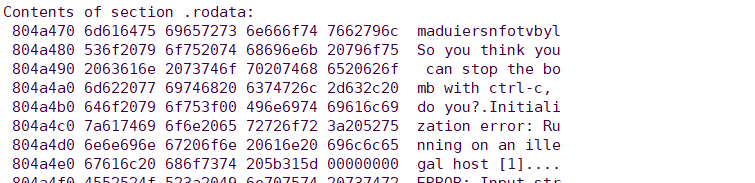


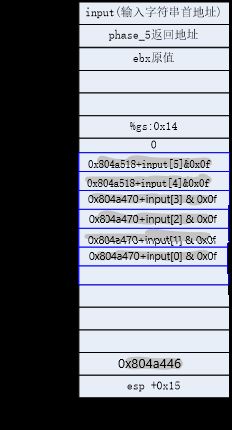
![]() ](javascript:void(0)
](javascript:void(0)char array[] = {'m','a','d','u','i','e','r','s','n','f','o','t','v','b','y','l'};
char *str = "sabres";
char new_str[7];
//根据input的每个字符的低4位,以及array,形成新的字符串。
for(int i = 0; i < 6; i ++)
{
new_str[i] = array[input[i]&0xf]);
}
new_str[6] ='\0';
//如果new_str不等于str("sabres"),则引爆炸弹。
if(strcmp(str, new_str) !=0)
{
explode_bomb();
}
![]() ](javascript:void(0)
](javascript:void(0)
phase_6



![]() ](javascript:void(0)
](javascript:void(0)for (i = 0; i < 6; i++)
{
if ((num[i] < 1) || (num[i] > 6))
{
explode_bomb();
}
for (j = i + 1; j < 6; j++)
{
if (num[i] == num[j])
{
explode_bomb();
}
}
}
![]() ](javascript:void(0)
](javascript:void(0)
![]() ](javascript:void(0)
](javascript:void(0)struct node
{
int d1;//尚不清楚含义,以4个字节的int暂替
int d2;//尚不清楚含义,以4个字节的int暂替
struct node* next;
}
![]() ](javascript:void(0)
](javascript:void(0)
Secret_phase
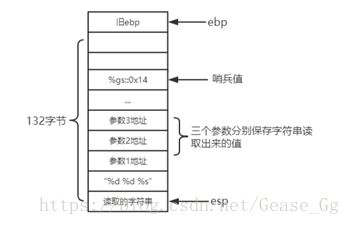
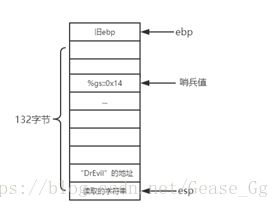

Secret_phase