【20230416】
关于老师要求我们多输出
- 深度学习的老师要求我们多输出
-
- 所以问题到底在哪里呢?
- 老师又在讲深度学习和强化学习
-
- 强化学习
- 强化学习做的事情
- 策略
- 今日任务
- 完成任务
- 下周党课课表
- 论文阅读
-
- 论文标题
- 论文作者
- Introduction
- 图形
- 模型和结果
-
- No-promise speed
- Two-day promise speed
- One-day promise speed
- 配送时间的Marginal Effect
- 物流评级对顾客购买概率的影响
- 最后研究这样一个问题:如果将3天的配送时间改为2天,那么对销售量的影响是怎样的?
深度学习的老师要求我们多输出
老师说,我们中国的学生的特点是,只输入,不输出。我自己也觉得有这个问题,但是很多时候我都在想,是我的能力不够,所以每次都输出不畅?还是学校并没有教给我足够的输入,能让我有那个水平去输出呢?每次感觉课上完了,老师就让我们写论文,论文主题完全与上课内容无关。
所以问题到底在哪里呢?
老师让我们多看原文的论文,每次看论文就感觉自己英语并不好,英语单词真的很重要。开学以来,老师都让我们干项目,很久都没看过论文了。以后再也不干学校的翻译了,上学期都给了翻译,结果现在还是在第二轮翻译,还没发工资。这几百块钱真的难挣!优秀团员每个班的名额只有一个,我还傻兮兮去报名,充当炮灰,以后可以先问下名额再去做吧。搞竞赛不能找同级的,只能找研二的,否则根本就是充当炮灰,他们还是厉害一些呀!
发现自己就是很垃圾,大英的改错,我十分只能拿两分!大英的听力都是一空一分,我经常犯的错误就是单词写错。
老师又在讲深度学习和强化学习
强化学习
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
强化学习的常见模型是标准的马尔可夫决策过程(Markov Decision Process, MDP)。按给定条件,强化学习可分为基于模式的强化学习(model-based RL)和无模式强化学习(model-free RL) ,以及主动强化学习(active RL)和被动强化学习(passive RL) 。强化学习的变体包括逆向强化学习、阶层强化学习和部分可观测系统的强化学习。求解强化学习问题所使用的算法可分为策略搜索算法和值函数(value function)算法两类。深度学习模型可以在强化学习中得到使用,形成深度强化学习。
强化学习做的事情
因为需求的不确定(华为的手机的价格,定多少价格,会有多少人买)、分布是未知的
在探索和利用之间做一个权衡。(explore&exploit)
构建一个市场一样的环境,在里面去试,通过实验去判断什么是最优的策略。
- 探索
- 利用
策略
在某个状态下采取某个行为的一个概率
在强化学习里,一个重要的机制是:奖罚机制
神经网络就是一个函数,带参数W,把X对应到Y
学习这个函数,X和Y是已经有的数据集,要学W,W的更新公式是,W= W-损失函数对W求的导数*步长,来让损失函数最小。
强化学习:诱导agent在环境下完成任务,要给他奖励或惩罚。
return和reward
return是未来的奖励
reward是当期的奖励
用return的大小来判别哪个策略更好一些
为了避免无休止地去做一件事情,会定义一个折扣率(discount)
状态转移概率
奖罚概率
无记忆性:把之前的所有行为都归结到前一个行为
今日任务
- 完成一套英语竞赛题
- 完成英语打卡
- 完成论文阅读(第二遍)
完成任务
- 完成论文阅读(第二遍)
- 完成一套英语竞赛题
- 完成英语打卡
下周党课课表
| 党课 | 时间 | 地点 |
|---|---|---|
| 开学典礼 | 周三下午 | 四点之前海翔厅,四点之后大汉厅 |
| 党的理想信念 | 周日下午 | 大汉厅 |
论文阅读
论文标题
Logistics Performance, Ratings, and Its Impact on CustomerPurchasing Behavior and Sales in E-Commerce Platforms
论文作者
Vinayak Deshpande,a Pradeep K. Pendemb
Introduction
- 电子商务迅速发展
- 电子商务布局物流,并启用会员计划——当日达、次日达
- 如何量化物流提升对销售量的影响还没人做
- 主要研究物流提升对平台第三方的影响
- 两个步骤:将物流水平(delivery performance)和物流评级(logistics ratings)联系起来,再将物流评级(logistics ratings)和销售量( online sales)联系起来
- 提出的问题Q1a:减少配送时间如何影响物流评级(商品的质量也会影响物流评级)
- 提出的问题Q1b:物流评级如何影响消费者购买可能和销量
- 总问题Q1:减少配送时间如何影响销量
图形
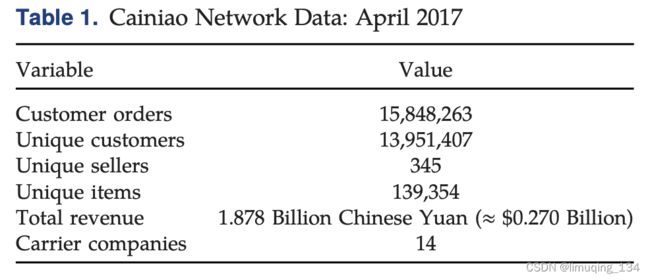
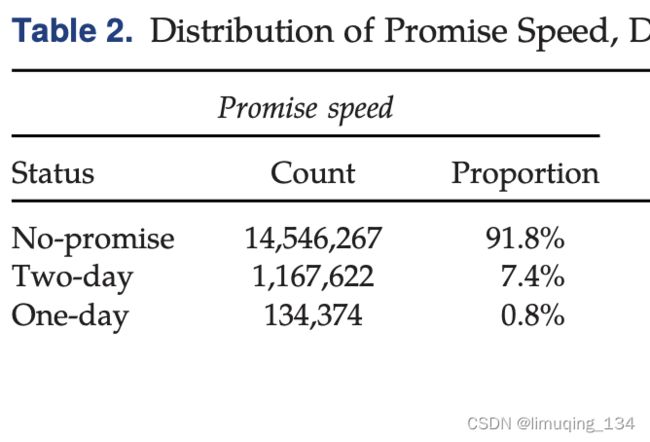


上述都是总的对数据的描述性统计的表
模型和结果
文章讲到有62.2%的客户是No response(无评价)的,所以数据样本可能会有the selection
on unobservables problem(选择的不可观测问题):是否评价和屁股那叫评级值是有关的。
用到的是一个the Probit selection model和the
Ordered Probit rating model(the Heckman Ordered Probit Regression model)的组合。
这个模型的重要的特点是:不抛弃那些不评级的点,同时在客户的评级决策和评级等级上建模(基于双变量的Probit模型)。
文章分别在三种不同类型的数据集上做了回归。
- No-promise speed
- Two-day promise speed
- One-day promise speed
No-promise speed
文章发现在No-promise speed数据集下,顾客选择评级的概率随着配送时间的增加而增加;顾客评级的等级随着配送时间的增加而降低。
在此处,作者提到了一个Expectation-disconfirmation theory 。期望-不一致理论。表中数据显示,两天配送时间的系数是不显著的,所以两天的配送时间是顾客的期望基础配送时间。而配送时间超过两天就会增加客户的不舒服感觉。
于是得出结论:没有承诺配送速度的顾客更有可能在不舒服的时候,选择评级并且低评级。
Two-day promise speed

配送时间对客户选择是否评级没有影响。
客户的评级随着配送时间的增加而降低(在期望配送速度之下)
渠道(第三方物流或者菜鸟)不影响物流评级
One-day promise speed

配送时间对客户选择是否评级没有影响。
客户的评级随着配送时间的增加而降低(在期望配送速度之下)
渠道(第三方物流或者菜鸟)不影响物流评级
配送时间的Marginal Effect
The Heckman ordered probit regression是一个非线性模型,所以系数不能直接翻译为边际效益。
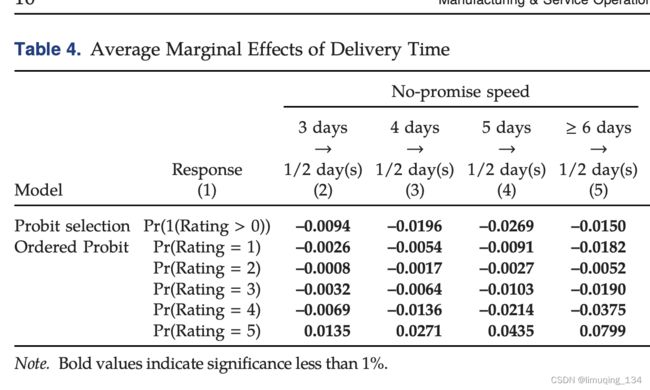
如果本应该在3天之内完成的配送,在1/2天之内完成的话,就会以0.00094的边际效果来降低评级的概率,会以0.00026、0.0008等来降低评级为1或者2的概率(3,4类似),会以0.0135来增加评级为5的概率。
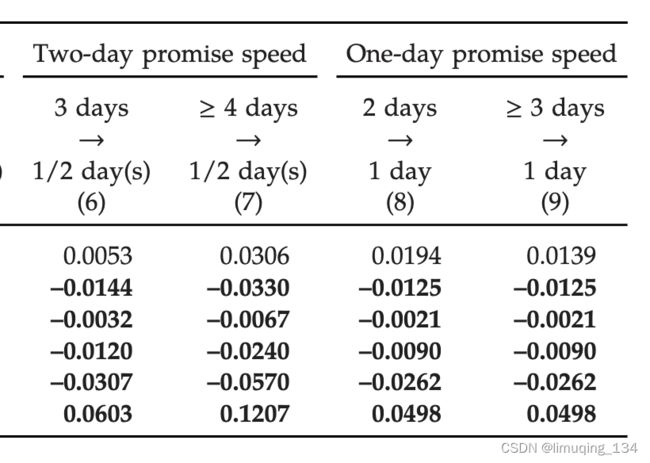
减少配送时间会降低评级低的概率,增加评级为5(最高评级)的概率。
物流评级对顾客购买概率的影响
the choice modeling framework
净效用是一系列变量(price, quality, channel preference, and additional variables)的线性组合
效用最大化理论
文章考虑到了客户从别的渠道购买的可能性(线下或者其他平台)
采用Newman提出的choice-based models,而不是标准的MNL model
Under the assumption of an independent and identical Gumbel distribution for each of
the idiosyncratic components
效用函数:
-
从seller i购买的效用
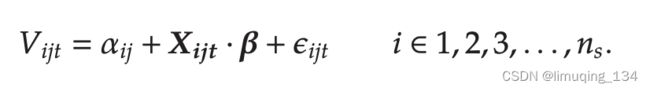
-
不购买的效用(包括不购买、从别的平台购买、线下购买)

作者得出了顾客选择从seller i购买和不购买的概率
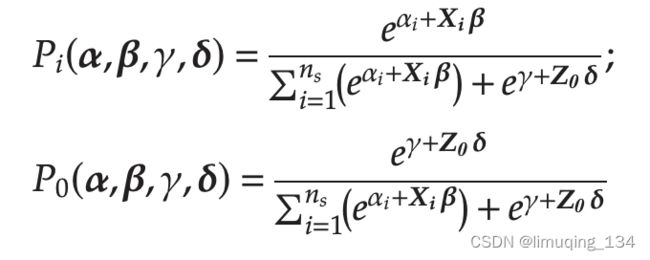
The loglikelihood function
参数估计分为两阶段估计
得到了物流评级对消费者购买可能性的影响
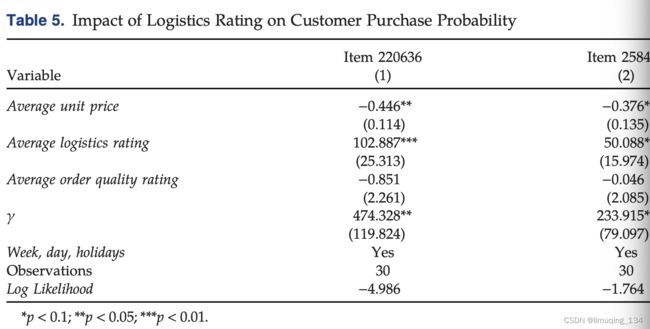
然后分析了该seller销售的所有订单,发现有一半的订单的物流评级是显著的,另外一半不是。
然后又扩展到所有item,也发现这种现象。
然后对两类(显著、不显著的订单)进行t检验,看是否价格和量上有显著区别,发现价格没区别,量有区别。
得出结论:物流评级的改善可能对高volume的订单的购买可能影响更大。
最后研究这样一个问题:如果将3天的配送时间改为2天,那么对销售量的影响是怎样的?
选了其中一个seller,他是物流评级最低的五位中的一个,并且其销量是其中最高的。
然后利用之前的结论,得出如果把3天的配送时间缩短为2天,可以提高物流评级从4.7198到4.7265。然后根据这个新的物流评级,计算其日均销量的提升水平(得到为10.3%),然后把所有的seller的提升水平计算出来,得出平台所有的提升水平为13.3%。
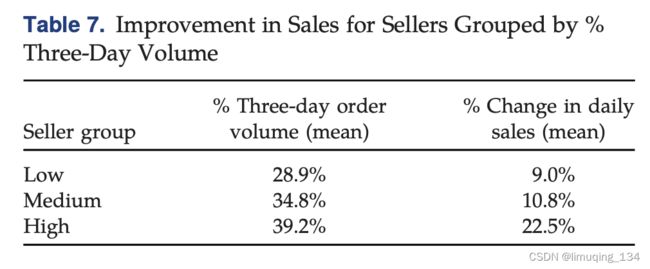
作者将所有订单按照volume分为三类,发现volume高的订单,其影响因子最大。

作者将所有订单按照price分为三类,发现price高的订单,其影响因子最大。
###结论和管理启示
- 应该关注物流配送水平和质量,这对提高销量影响很大。
- 即使没有优先权的顾客(non-priority),也会期待2天之内的配送时间,因此不应该忽视他们对配送时间的要求。
- 应该鼓励顾客评价,特别是他们比较满意的时候。这是提升物流评级的关键。
- 没必要提升有优先权的顾客的配送速度(只要按照给定的优先权完成即可)
- 将3天物流提升到2天对seller最有利
- 本文提出的方法可以用来权衡提升物流水平带来的利益和投入的成本之间孰大孰小。
局限:没有研究seller之间的物流战略互动