DevOps之旅:运维人员阅读源代码的实用技巧
作者简介

陈晨,基础架构工程师,目前就职于中国银联。主要负责IaaS平台、容器平台以及运维管理平台的建设工作。本文将着重介绍运维人员学习源代码的一些技巧。
一、准备阶段
1.制定计划
读源码和读书一样,必须有时间计划,deadline是第一生产力。
合理的制定计划可能需要你先全局掌握一下代码的结构,以及各个函数的重要程度、难易程度。
2.选择一本好书
作为学习资料,书一定是最好的。
- 网上资料太零散,学习起来可能不系统;
- 较为系统的书一般都会将开源代码的配置、集成进行详细的讲解;然后会介绍一些通用模块,最后再对每一个组件或者流程进行代码的跟踪分析。
在选书的时候,也应该注意选择。
- 可以通过书的各个章节介绍,来看该书是否按照这样的逻辑去讲述。
例如,笔者当初学习openstack的时候,根据目录选择了这样一本书:他的四个篇幅分别是基础-安装-代码-二次开发。这就是一个非常好的循序渐进的书。
3.选择一个好的IDE
笔者除了Java以外,全部使用Vim。当然,这完全取决于每一个人的习惯。
笔者一般比较喜欢轻量级的IDE,因此推荐一些轻量级的:
- Vim
- Sublime
- SourceInsight
IDE的全称是集成开发环境。如果只是要将代码运行起来,只需要编译器或者解释器。代码完全可以在纯文本上进行编辑。
IDE提供更多的开发辅助功能,使得开发人员专注于代码的逻辑。
最常见的如自动纠错、代码补全、函数查询等功能。C的很多IDE还自动生成makefile,也省去很大的繁琐内容。
不过,IDE的功能性和简约型永远是一个悖论。
读者在选择IDE的时候,应当选择一个符合自己需求的IDE,不要过分追求功能强大。
一般来说,我们使用IDE可能有哪些辅助性的需求呢:
- 测试工具的集成
- 自动打包
- 代码定位
- 定制化、插件丰富
- 错误检查
- 调试
- 项目模板
4.下载完整版本库
完整的代码库是指反映代码迭代过程的各个历史版本。这样做有很多好处:
- 你可以获取代码的修改记录。
- 你还可以获取到完整的测试代码,当你要提交patch的时候,你可以借助版本管理工具生成针对不同版本的patch。
二、初识代码
1.阅读项目文档
大部分的开源项目都会对其架构有一定的描述,通读一下会让你项目有一个比较深入的认识。
重点关注类似Getting started、Example之类的文档,从中学习如何下载、安装、使用该项目所需要的知识。
比如openstack,官网上的网络拓扑讲解是最全面、准确的:
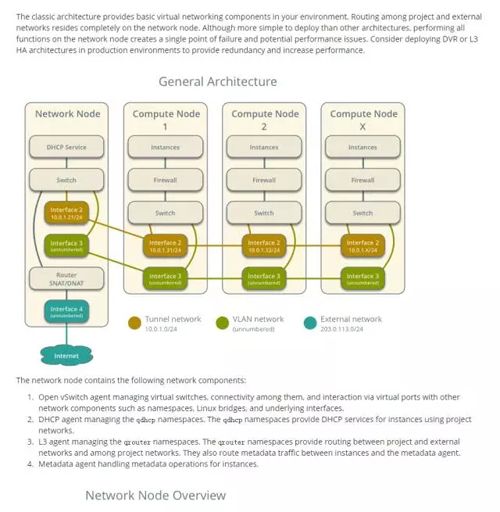
2.分类文件
分清楚代码库的各个文件的作用。
在恰当的时候,对所有文件做一个总体把握,有助于后续阅读代码的时候的优先级的选择。清楚哪些是核心、哪些是可以定制的。
如下是笔者收藏的nova的源码文件的部分内容:
/nova/api/auth.py:通用身份验证的中间件,访问keystone;
/nova/api/manager.py:Metadata管理初始化;
/nova/api/ec2/__init__.py:Amazon EC2 API绑定,路由EC2请求的起点;
/nova/api/ec2/apirequest.py:APIRequest类;
/nova/api/metadata/__init__.py:Nova元数据服务;
。。。
。。。
刚开始写注释的时候,其实有的东西自己也不是很确定。这样的注释也没有最终能让你对代码的所有文件的关系有非常清晰的了解。
不过不要紧,在初期的时候就尝试去做这样的事情是有好处的,这可能是你掌握源码整体结构的第一步。
3.掌握开发框架
框架存在的目的就是简化开发。但是也会让代码不那么直观。
举个例子,很多用spring开发的开源软件,如果你连spring都不懂,你就会发现连代码入口都找不到。因为在开发框架下的代码都被“劫持”啦!
我们举个例子,spring+springmvc+mybatis开发web应用的时候。如果理解了这三个基础框架,你就可以很清楚的知道如下文件的作用:
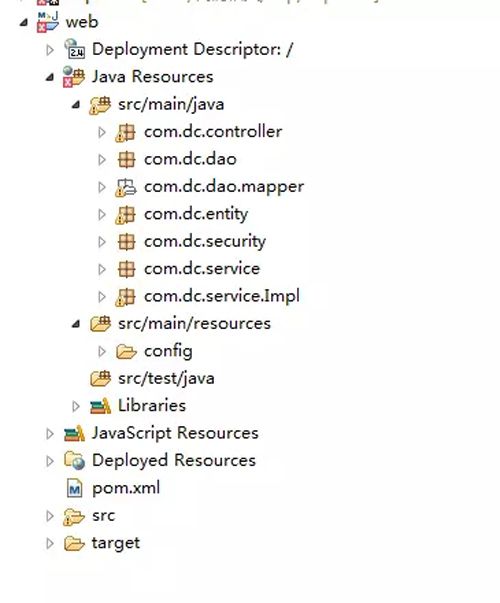
- 所有的url对应的controller都在com.dc.controller中
- 所有的数据接口都在com.dc.dao中
- 所有的实体对象都在com.dc.entity中
- 所有数据接口和sql语句对应关系都在com.dc.dao.mapper中
- 所有的服务定义都在com.dc.service和com.dc.service.Impl中
更具体的,当我看到这样一个函数:

马上就知道是spring中的一个处理url路径时/的controller函数。
所以,如果确信开源代码使用了成熟的开发框架,请一定先熟悉该框架。
三、熟悉代码行为
1. 组件执行流程
较为复杂的系统都是分组件的,分别熟悉各个组件,理清他们之间的关系。
例如,openstack的执行流程图:
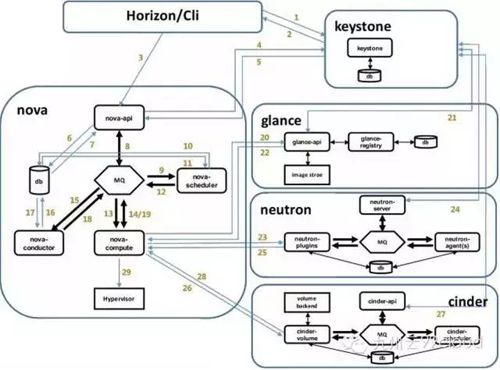
虚拟机启动过程如下:
a. 界面或命令行通过RESTful API向keystone获取认证信息。
b. keystone通过用户请求认证信息,并生成auth-token返回给对应的认证请求。
c. 界面或命令行通过RESTful API向nova-api发送一个boot instance的请求(携带auth-token)。
d. nova-api接受请求后向keystone发送认证请求,查看token是否为有效用户和token。
2. 利用示例代码和单元测试
示例代码可以帮助你学会使用相关开源项目的API。
大部分的开源项目在开发的过程中,为了验证其实现的功能,都会写很多单元测试代码。这些代码其实是非常好的示例代码。
读单元测试的好处太多了,这里给大家罗列一下知乎网友总结出来的好处:
- 由于一个单元测试一般也就是几个小时的开发工作量,你很容易就能读懂相关的代码。
- 每个单元测试都是可以独立运行的,这样节省你跟踪调试的时间。
- 单元测试在很大程度定义了软件的功能,可以帮助你快速掌握项目的相关API。
- 如果你修改的开源项目的代码,你可以通过修改单元测试来验证你的修改是否正确。
注1:原文链接 https://www.zhihu.com/question/19637879/answer/13545260
如果该项目有提供现成的example工程:
- 首先尝试按照开始文档的介绍运行example,如果运行顺利,那么恭喜你顺利开了个好头;如果遇到问题,首先尝试在项目的FAQ等文档里查找答案。
- 再次,可以将问题(例如异常信息)当成关键词去搜索,查找相关的解决办法,你遇到了,别人一般也会遇到,热心的朋友会记录下解决的过程。
- 最后,可以将问题提交到项目的邮件列表,请大家帮你看看。在没有成功运行example之前,不要尝试修改example。
运行了第一个example之后,尝试根据你的理解和需要修改example,测试高级功能等。
3. 跟踪分析
复杂的开源软件几乎没有一个是一个流程走到底的,这个时候就需要我们选择一个主要流程。
例如,在openstack中,笔者一开始就画了大量功夫去梳理创建虚拟机的流程。
第一步,从代码入口处沿着创建虚拟机这条流程进行一行一行的注释:

当该流程基本注释完成,自己也有所掌握后,抽丝剥茧,总结出更为直观、简介的表现方式:

当你逐渐理解了一个或者两个主要流程后,一般会发现其他的分支流程都十分类似。这就为掌握整个流程打下了很好的基础。
4. 对需要详细了解的函数进行排序
在安排自己深入阅读时,应该根据预估的工作量进行合理安排。
一般来说,初始化、读取参数等都是次要的,也是相对简单的。而核心模块就复杂的多。
还是以haproxy为例,main函数中最核心的代码就是run_poll_loop()。
笔者曾经尝试从init()函数开始,但是发现很多初始化的数据压根就不知道干什么,看过一遍后就都什么都记不得了。
但是直接从主函数开始,不断的发现对一些参数进行处理的时候,反向追踪他的初始化过程,则更容易理解。
四、掌握数据状态
1. 掌握数据流
从数据流的角度来讲,所有的代码逻辑都是在加工数据。
比如说openstack,从最初用户输入的虚拟机名称、配置等数据开始,openstack的代码逻辑对数据进行加工、处理、过滤、选择等内容,最终传递给libvirt,进行虚拟机的最后创建。
因此,掌握数据的组织方式,对理解代码逻辑是很有帮助的,也是二次开发的前提条件。
所以,在学习代码的时候,不断询问自己,我掌握数据的组织方式了吗?我掌握数据在整个流程中不断加工的流程了吗?
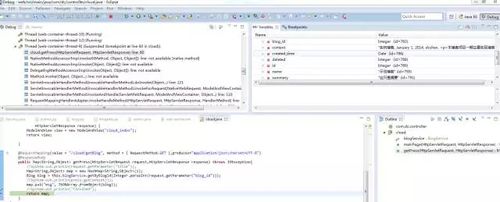
2. 使用debug观察数据状态
前面说到细化研究某一个流程的时候,一定要注意研究数据传递的方式和内容。数据流是理解流程的基础,扩展数据流也是二次开发常用的技能。
例如,在eclipse通过debug打断点,获取流程中某个点的数据内容:
3. 使用标准输出观察数据状态
笔者有时候也喜欢直接使用console进行输出,打印对象的一些信息。这个用于验证某段代码有没有被执行、或者查看某个数据的时候,也十分有效。
例如,通过chrome的标准输出查看javascript的输出:
五、举一反三阶段
1.研究底层调用
研究底层调用往往是运维的常用手段。比如在openstack的运行初期,我们对openstack的源码不熟悉,怎么办呢?
直接研究openstack的底层调用。Openstack底层都是调用libvirt的接口,创建虚拟机等基本操作我们都研究了个遍。
因此,对于大多数openstack的问题,我们都能直击问题现场,进行恢复和排查。
那研究底层调用对理解源代码有什么好处呢?
笔者在基本熟悉了openstack的所有底层调用之后,带着这样的问题去看源码“代码究竟是如何从入口逐渐运行到我所知道的那个底层调用的呢?”,笔者很快就梳理了代码的执行流程。
2. 学会在社区或者stackoverflow提问题
社区里面的热心人是相当多的。
当然笔者认为,提问也需要一定的技巧,这里引用知乎网友的话:
stackoverflow很多人问问题有一个共性,就是对提出的问题先发表自己的见解,描述自己的思路,自己达到了什么地方,这是对各位回答者的尊重。
你在阐述自己所能达到的地步,你表明了你已经做出了什么样的努力,这是你对问题的诚意。
这样回答者才会觉得有回答的价值,或许是想起自己过去也曾经小白却努力的岁月,或许是觉得你有相助的价值,或者等等。所谓自助者人助罢了。
原文链接:http://www.zhihu.com/question/24228283/answer/27102646
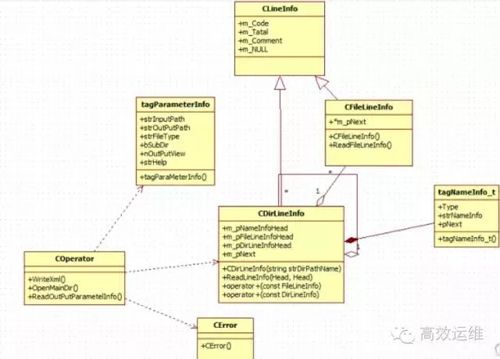
3. 学会画流程图
流程图可以更方便的展现代码执行的逻辑。忽略不重要的代码,强调主要的函数。
概要设计中常用的框图:
思维导图:
