多层感知机
relu函数
import torch
from d2l import torch as d2l
x = torch.arange(-8.0,8.0,0.1,requires_grad=True)
y = torch.relu(x)
d2l.plot(x.detach(),y.detach(),'x','relu(x)',figsize=(5,2.5))
d2l.plt.show()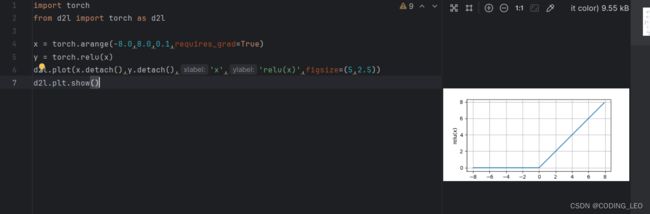
-8.0是数列的起始值。8.0是数列的结束值(不包括在数列内,即不包含该值)。0.1是数列的步长,也就是每个相邻元素之间的间隔。requires_grad=True表示创建的张量需要求梯度(Gradient),允许对其进行自动微分。
所以,torch.arange(-8.0, 8.0, 0.1, requires_grad=True) 会创建一个张量,包含从 -8.0 开始到 8.0 结束(不包括 8.0)的数列,步长为 0.1,并且允许对这个张量进行梯度计算。
如果你更改了 step 的值,将会影响生成的数列中元素的个数和间隔。例如:
- 如果将
step设为更大的值,如1.0,数列中的元素之间的间隔会变大,生成的数列中元素的个数会相应减少。 - 如果将
step设为更小的值,如0.01,数列中的元素之间的间隔会变小,生成的数列中元素的个数会相应增加。
举个例子:
pythonCopy code
x = torch.arange(-8.0, 8.0, 1.0)
上述代码会生成一个从 -8.0 到 7.0(不包含 8.0)的数列,间隔为 1.0,共有 16 个元素。
pythonCopy code
x = torch.arange(-8.0, 8.0, 0.5)
而这段代码会生成一个从 -8.0 到 7.5(不包含 8.0)的数列,间隔为 0.5,共有 32 个元素。
因此,step 参数的改变会影响生成数列的步长和元素的数量,可以根据需要调整这个参数来生成不同间隔的数列。
#绘制relu导数的图像
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(),x.grad,'x','grad of relu',figsize=(5,2.5))
d2l.plt.show() 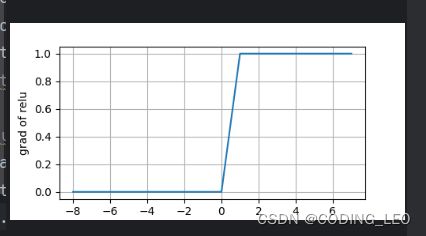
x.detach() 的作用是创建一个与原始张量 x 共享数据的新张量,但是不会保留 x 的计算图,也就是将张量从计算图中分离出来。
具体来说,x.detach() 返回一个新的张量,该张量与 x 具有相同的数据,但不再与计算图相关联。这意味着对于返回的 detach() 张量,不会再追踪其上的操作,也不会记录在计算图中。所以,它不会继续计算梯度。
sigmoid函数和tanh同理
多层感知机从零开始实现
import torch
from IPython import display
from torch import nn
from d2l import torch as d2l
from softmax import Accumulator, accuracy, evaluate_accuracy
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期(定义见第3章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
class Animator: #@save
"""在动画中绘制数据"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量地绘制多条线
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
d2l.plt.draw()
d2l.plt.pause(0.001)
display.display(self.fig)
display.clear_output(wait=True)
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
#W1 = torch.normal(0,0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
#W2 = torch.normal(0,0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
loss = nn.CrossEntropyLoss(reduction='none')
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
d2l.plt.show()报错d2l中没有train_ch3函数 我手动加了进去,3.6章节的
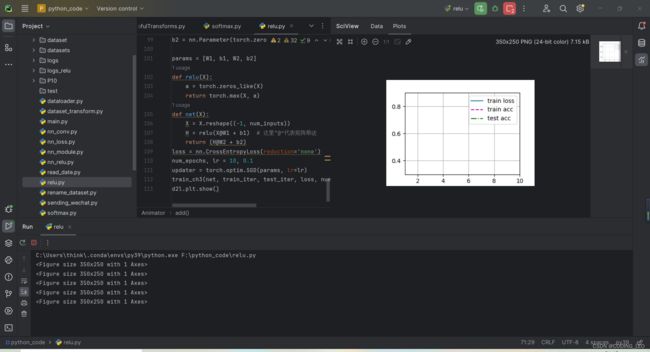
有点问题,不显示图像,别人也与这样的问题,好像是w
后续更新了d2l pip install==0.17.6
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
loss = nn.CrossEntropyLoss(reduction='none')
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
d2l.plt.show()可以跑 但是没图。