【遥遥领先】融合Gold-YOLO的改进YOLOv5的水果新鲜度分级分拣系统
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着人们对健康和营养的关注度不断提高,对新鲜水果的需求也越来越大。然而,传统的水果分级分拣系统往往需要大量的人力和时间,效率低下且易受主观因素影响。因此,开发一种高效准确的水果新鲜度分级分拣系统对于提高水果行业的生产效率和质量管理至关重要。
目前,深度学习技术在计算机视觉领域取得了巨大的突破,特别是目标检测算法的发展。其中,YOLO(You Only Look Once)算法以其快速、准确的特点成为了目标检测领域的热门算法之一。然而,传统的YOLO算法在处理水果新鲜度分级分拣任务时存在一些挑战,例如对于水果的颜色、纹理等特征的识别能力较弱,导致分级分拣的准确性不高。
因此,本研究旨在融合Gold-YOLO和改进的YOLOv5算法,开发一种遥遥领先的水果新鲜度分级分拣系统。具体来说,我们将利用Gold-YOLO算法的优势,即通过引入金字塔特征金字塔网络(FPN)和多尺度预测来提高目标检测的准确性。同时,我们将对YOLOv5算法进行改进,以增强其对水果颜色、纹理等特征的识别能力。
该研究的意义主要体现在以下几个方面:
-
提高水果分级分拣的准确性:通过融合Gold-YOLO和改进的YOLOv5算法,我们可以提高水果新鲜度分级分拣系统的准确性。这将有助于减少误判和漏判的情况,提高水果分级分拣的精度和效率。
-
提高水果行业的生产效率:传统的水果分级分拣系统需要大量的人力和时间,而且易受主观因素影响。采用遥遥领先的水果新鲜度分级分拣系统可以大大提高水果行业的生产效率,减少人力成本和时间成本。
-
促进水果行业的质量管理:水果的新鲜度是影响其品质和口感的重要因素。通过准确地分级分拣水果的新鲜度,可以有效提高水果行业的质量管理水平,确保消费者能够购买到新鲜、优质的水果产品。
-
推动深度学习技术在农业领域的应用:本研究将融合Gold-YOLO和改进的YOLOv5算法,为深度学习技术在农业领域的应用提供了一个典型案例。这将有助于推动农业领域的智能化发展,提高农业生产的效率和质量。
综上所述,开发一种遥遥领先的融合Gold-YOLO的改进YOLOv5的水果新鲜度分级分拣系统具有重要的研究意义和实际应用价值。通过提高水果分级分拣的准确性、提高生产效率和质量管理水平,以及推动深度学习技术在农业领域的应用,该系统将为水果行业的发展带来巨大的推动力。
2.图片演示
3.视频演示
【遥遥领先】融合Gold-YOLO的改进YOLOv5的水果新鲜度分级分拣系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集FreshnessDatasets。

下面是一个简单的方法是使用Python脚本,该脚本读取分类图片文件,然后将其转换为所需的格式。
import os
import shutil
import random
# 指定输入和输出文件夹的路径
input_dir = 'train'
output_dir = 'output'
# 确保输出文件夹存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 遍历输入文件夹中的所有子文件夹
for subdir in os.listdir(input_dir):
input_subdir_path = os.path.join(input_dir, subdir)
# 确保它是一个子文件夹
if os.path.isdir(input_subdir_path):
output_subdir_path = os.path.join(output_dir, subdir)
# 在输出文件夹中创建同名的子文件夹
if not os.path.exists(output_subdir_path):
os.makedirs(output_subdir_path)
# 获取所有文件的列表
files = [f for f in os.listdir(input_subdir_path) if os.path.isfile(os.path.join(input_subdir_path, f))]
# 随机选择四分之一的文件
files_to_move = random.sample(files, len(files) // 4)
# 移动文件
for file_to_move in files_to_move:
src_path = os.path.join(input_subdir_path, file_to_move)
dest_path = os.path.join(output_subdir_path, file_to_move)
shutil.move(src_path, dest_path)
print("任务完成!")
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----dataset
-----dataset
|-----train
| |-----class1
| |-----class2
| |-----.......
|
|-----valid
| |-----class1
| |-----class2
| |-----.......
|
|-----test
| |-----class1
| |-----class2
| |-----.......
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R [email protected] [email protected]:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 common.py
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1, bias=False):
'''Basic cell for rep-style block, including conv and bn'''
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups,
bias=bias))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class RepVGGBlock(nn.Module):
'''RepVGGBlock is a basic rep-style block, including training and deploy status
This code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
'''
def __init__(self, in_channels, out_channels, kernel_size=3,
stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
super(RepVGGBlock, self).__init__()
""" Initialization of the class.
Args:
in_channels (int): Number of channels in the input image
out_channels (int): Number of channels produced by the convolution
kernel_size (int or tuple): Size of the convolving kernel
stride (int or tuple, optional): Stride of the convolution. Default: 1
padding (int or tuple, optional): Zero-padding added to both sides of
the input. Default: 1
dilation (int or tuple, optional): Spacing between kernel elements. Default: 1
groups (int, optional): Number of blocked connections from input
channels to output channels. Default: 1
padding_mode (string, optional): Default: 'zeros'
deploy: Whether to be deploy status or training status. Default: False
use_se: Whether to use se. Default: False
"""
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
self.out_channels = out_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if use_se:
raise NotImplementedError("se block not supported yet")
else:
self.se = nn.Identity()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True,
padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(
num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
padding=padding_11, groups=groups)
def forward(self, inputs):
'''Forward process'''
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels,
out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation,
groups=self.rbr_dense.conv.groups, bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
class SimFusion_3in(nn.Module):
def __init__(self, in_channel_list, out_channels):
super().__init__()
self.cv1 = Conv(in_channel_list[0], out_channels, act=nn.ReLU()) if in_channel_list[0] != out_channels else nn.Identity()
self.cv2 = Conv(in_channel_list[1], out_channels, act=nn.ReLU()) if in_channel_list[1] != out_channels else nn.Identity()
self.cv3 = Conv(in_channel_list[2], out_channels, act=nn.ReLU()) if in_channel_list[2] != out_channels else nn.Identity()
self.cv_fuse = Conv(out_channels * 3, out_channels, act=nn.ReLU())
self.downsample = nn.functional.adaptive_avg_pool2d
def forward(self, x):
N, C, H, W = x[1].shape
output_size = (H, W)
if torch.onnx.is_in_onnx_export():
self.downsample = onnx_AdaptiveAvgPool2d
output_size = np.array([H, W])
x0 = self.cv1(self.downsample(x[0], output_size))
x1 = self.cv2(x[1])
x2 = self.cv3(F.interpolate(x[2], size=(H, W), mode='bilinear', align_corners=False))
return self.cv_fuse(torch.cat((x0, x1, x2), dim=1))
class SimFusion_4in(nn.Module):
def __init__(self):
super().__init__()
self.avg_pool = nn.functional.adaptive_avg_pool2d
def forward(self, x):
x_l, x_m, x_s, x_n = x
B, C, H, W = x_s.shape
output_size = np.array([H, W])
if torch.onnx.is_in_onnx_export():
self.avg_pool = onnx_AdaptiveAvgPool2d
x_l = self.avg_pool(x_l, output_size)
x_m = self.avg_pool(x_m, output_size)
x_n = F.interpolate(x_n, size=(H, W), mode='bilinear', align_corners=False)
out = torch.ca
common.py是一个包含一些常用函数和模型的程序文件。它包含以下几个部分:
-
conv_bn函数:这是一个用于创建卷积和批归一化层的函数。它接受输入通道数、输出通道数、卷积核大小、步长、填充大小等参数,并返回一个包含卷积和批归一化层的Sequential对象。
-
RepVGGBlock类:这是一个基于RepVGG的模块类。它包含了训练和部署状态下的前向传播方法和参数转换方法。在初始化时,它接受输入通道数、输出通道数、卷积核大小、步长、填充大小等参数,并根据部署状态和是否使用SE模块来创建不同的卷积层和批归一化层。它还包含了前向传播方法、获取等效卷积核和偏置项的方法以及切换到部署状态的方法。
-
onnx_AdaptiveAvgPool2d函数:这是一个用于在ONNX导出时进行自适应平均池化的函数。它接受输入张量和输出大小作为参数,并返回经过平均池化后的张量。
-
get_avg_pool函数:这是一个根据是否在ONNX导出中使用的函数。如果在ONNX导出中使用,则返回onnx_AdaptiveAvgPool2d函数;否则返回nn.functional.adaptive_avg_pool2d函数。
-
SimFusion_3in类:这是一个用于将三个输入特征图融合的模型类。它接受三个输入通道数和输出通道数作为参数,并包含了三个卷积层和一个融合卷积层。在前向传播过程中,它将输入特征图进行自适应平均池化,并将三个池化后的特征图与原始特征图进行融合。
-
SimFusion_4in类:这是一个用于将四个输入特征图融合的模型类。它包含了一个自适应平均池化层和一个融合卷积层。在前向传播过程中,它将输入特征图进行自适应平均池化,并将池化后的特征图与原始特征图进行融合。
这些函数和模型可以用于构建和训练神经网络模型。
5.2 export.py
def export_formats():
# YOLOv5 export formats
x = [
['PyTorch', '-', '.pt', True, True],
['TorchScript', 'torchscript', '.torchscript', True, True],
['ONNX', 'onnx', '.onnx', True, True],
['OpenVINO', 'openvino', '_openvino_model', True, False],
['TensorRT', 'engine', '.engine', False, True],
['CoreML', 'coreml', '.mlmodel', True, False],
['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
['TensorFlow GraphDef', 'pb', '.pb', True, True],
['TensorFlow Lite', 'tflite', '.tflite', True, False],
['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],
['TensorFlow.js', 'tfjs', '_web_model', False, False],
['PaddlePaddle', 'paddle', '_paddle_model', True, True],]
return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
def try_export(inner_func):
# YOLOv5 export decorator, i..e @try_export
inner_args = get_default_args(inner_func)
def outer_func(*args, **kwargs):
prefix = inner_args['prefix']
try:
with Profile() as dt:
f, model = inner_func(*args, **kwargs)
LOGGER.info(f'{prefix} export success ✅ {dt.t:.1f}s, saved as {f} ({file_size(f):.1f} MB)')
return f, model
except Exception as e:
LOGGER.info(f'{prefix} export failure ❌ {dt.t:.1f}s: {e}')
return None, None
return outer_func
@try_export
def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
# YOLOv5 TorchScript model export
LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
f = file.with_suffix('.torchscript')
ts = torch.jit.trace(model, im, strict=False)
d = {'shape': im.shape, 'stride': int(max(model.stride)), 'names': model.names}
extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()
if optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.html
optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)
else:
ts.save(str(f), _extra_files=extra_files)
return f, None
@try_export
def export_onnx(model, im, file, opset, dynamic, simplify, prefix=colorstr('ONNX:')):
# YOLOv5 ONNX export
check_requirements('onnx>=1.12.0')
import onnx
LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output0']
if dynamic:
dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640)
if isinstance(model, SegmentationModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)
elif isinstance(model, DetectionModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
torch.onnx.export(
model.cpu() if dynamic else model, # --dynamic only compatible with cpu
im.cpu() if dynamic else im,
f,
verbose=False,
opset_version=opset,
do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False
input_names=['images'],
output_names=output_names,
dynamic_axes=dynamic or None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# Metadata
d = {'stride': int(max(model.stride)), 'names': model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)
# Simplify
if simplify:
try:
cuda = torch.cuda.is_available()
check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))
import onnxsim
LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, 'assert check failed'
onnx.save(model_onnx, f)
except Exception as e:
LOGGER.info(f'{prefix} simplifier failure ❌ {e}')
return f, None
export.py是一个用于将YOLOv5 PyTorch模型导出为其他格式的程序文件。该文件包含了各种导出格式的命令和用法,以及相应的要求和依赖。它还定义了一些用于导出模型的函数,如export_torchscript和export_onnx。这些函数使用了PyTorch和ONNX库来导出模型,并提供了一些参数来控制导出过程。导出的模型可以用于推理任务,如目标检测和图像分割。
5.3 RepVGGBlock.py
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3,
stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
self.out_channels = out_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if use_se:
raise NotImplementedError("se block not supported yet")
else:
self.se = nn.Identity()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True,
padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(
num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = nn.Sequential()
self.rbr_dense.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups,
bias=False))
self.rbr_dense.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
self.rbr_1x1 = nn.Sequential()
self.rbr_1x1.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=1, stride=stride, padding=padding_11, groups=groups,
bias=False))
self.rbr_1x1.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels,
out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation,
groups=self.rbr_dense.conv.groups, bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
这个程序文件是一个名为RepVGGBlock的类的定义,它是一个基本的rep-style块,包括训练和部署状态。它有以下几个主要的方法和属性:
__init__方法用于初始化类的实例,接受一些参数来定义块的结构和属性。forward方法定义了前向传播过程,根据输入计算输出。get_equivalent_kernel_bias方法用于获取等效的卷积核和偏置。_pad_1x1_to_3x3_tensor方法用于将1x1的卷积核填充为3x3的卷积核。_fuse_bn_tensor方法用于融合卷积和批归一化层的参数。switch_to_deploy方法用于切换到部署状态,将块的参数转换为部署状态下的参数。
此外,程序文件还定义了一个辅助函数conv_bn,用于创建包含卷积和批归一化的基本单元。
该程序文件的主要功能是实现RepVGG网络的一个基本块,用于构建整个网络。
5.4 SimFusion_3in.py
class Attention(nn.Module):
def __init__(self, dim, key_dim, num_heads, attn_ratio=4):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads # num_head key_dim
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
self.to_q = nn.Conv2d(dim, nh_kd, 1, bias=False)
self.to_k = nn.Conv2d(dim, nh_kd, 1, bias=False)
self.to_v = nn.Conv2d(dim, self.dh, 1, bias=False)
self.proj = nn.Sequential(nn.ReLU6(), nn.Conv2d(self.dh, dim, 1, bias=False))
def forward(self, x): # x (B,N,C)
B, C, H, W = x.size()
qq = self.to_q(x).reshape(B, self.num_heads, self.key_dim, H * W).permute(0, 1, 3, 2)
kk = self.to_k(x).reshape(B, self.num_heads, self.key_dim, H * W)
vv = self.to_v(x).reshape(B, self.num_heads, self.d, H * W).permute(0, 1, 3, 2)
attn = torch.matmul(qq, kk)
attn = F.softmax(attn, dim=-1) # dim = k
xx = torch.matmul(attn, vv)
xx = xx.permute(0, 1, 3, 2).reshape(B, self.dh, H, W)
xx = self.proj(xx)
return xx
class TopBasicLayer(nn.Module):
def __init__(self, embedding_dim, ouc_list, block_num=2, key_dim=8, num_heads=4,
mlp_ratio=4., attn_ratio=2., drop=0., attn_drop=0., drop_path=0.):
super().__init__()
self.block_num = block_num
self.transformer_blocks = nn.ModuleList()
for i in range(self.block_num):
self.transformer_blocks.append(top_Block(
embedding_dim, key_dim=key_dim, num_heads=num_heads,
mlp_ratio=mlp_ratio, attn_ratio=attn_ratio,
drop=drop, drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path))
self.conv = nn.Conv2d(embedding_dim, sum(ouc_list), 1)
def forward(self, x):
# token * N
for i in range(self.block_num):
x = self.transformer_blocks[i](x)
return self.conv(x)
这个程序文件名为SimFusion_3in.py,它包含了几个类和函数。
-
Attention类:这是一个继承自torch.nn.Module的类,用于实现注意力机制。它接受输入的维度dim、关键维度key_dim、头数num_heads和注意力比例attn_ratio作为参数。在forward方法中,它将输入x进行线性变换,并计算注意力权重,然后将注意力权重与值进行加权求和并输出。
-
top_Block类:这是一个继承自nn.Module的类,用于实现Transformer中的一个top block。它接受输入的维度dim、关键维度key_dim、头数num_heads、MLP比例mlp_ratio、注意力比例attn_ratio、dropout比例drop和dropout路径比例drop_path作为参数。在forward方法中,它首先应用注意力机制,然后应用MLP,并将结果与输入进行残差连接。
-
TopBasicLayer类:这是一个继承自nn.Module的类,用于实现Transformer中的一个top basic layer。它接受输入的嵌入维度embedding_dim、输出通道数列表ouc_list、block数block_num、关键维度key_dim、头数num_heads、MLP比例mlp_ratio、注意力比例attn_ratio、dropout比例drop、注意力dropout比例attn_drop和dropout路径比例drop_path作为参数。在forward方法中,它应用多个top block,并通过卷积层将结果映射到指定的输出通道数。
-
AdvPoolFusion类:这是一个继承自nn.Module的类,用于实现进阶池化融合。在forward方法中,它接受两个输入x1和x2,并将x1进行自适应平均池化,然后将池化结果与x2进行拼接并输出。
以上是SimFusion_3in.py文件中的主要类和函数的概述。
5.6 ui.py
这个程序文件是一个基于PyQt5的图形用户界面程序,用于水果新鲜度分级分拣系统。程序文件名为ui.py。
该程序文件导入了一些必要的库和模块,包括pathlib、cv2、numpy、PyQt5等。然后定义了一些全局变量和函数。
在主函数run中,定义了一系列参数,包括模型路径、数据集路径、推理尺寸、设备类型等。然后加载模型、创建数据加载器,并进行推理和后处理。最后输出结果。
在主函数parse_opt中,解析命令行参数。
在主函数main中,检查依赖库,并调用run函数。
在主函数det中,解析命令行参数并调用main函数。
在类Thread_1中,定义了一个线程,用于运行det函数。
在类Ui_MainWindow中,定义了一个图形用户界面类,包含了界面的布局和事件处理函数。
6.系统整体结构
整体功能和构架概述:
该项目是一个水果新鲜度分级分拣系统,基于YOLOv5和其他相关模型。它包含了训练、推理和界面展示等功能。
主要文件功能如下:
| 文件路径 | 功能 |
|---|---|
| common.py | 包含一些常用函数和模型 |
| export.py | 将YOLOv5模型导出为其他格式 |
| RepVGGBlock.py | 实现RepVGG网络的一个基本块 |
| SimFusion_3in.py | 将三个输入特征图融合的模型类 |
| train.py | 训练YOLOv5模型的程序文件 |
| ui.py | 基于PyQt5的图形用户界面程序,用于水果新鲜度分级分拣系统 |
| val.py | 在验证集上评估模型性能的程序文件 |
| classify\predict.py | 进行水果分类预测的程序文件 |
| classify\train.py | 训练水果分类模型的程序文件 |
| classify\val.py | 在验证集上评估水果分类模型性能的程序文件 |
| models\common.py | 包含一些通用的模型定义和函数 |
| models\experimental.py | 包含一些实验性的模型定义和函数 |
| models\tf.py | 包含一些TensorFlow模型定义和函数 |
| models\yolo.py | 包含YOLO模型的定义和函数 |
| models_init_.py | 模型初始化文件 |
| segment\predict.py | 进行图像分割预测的程序文件 |
| segment\train.py | 训练图像分割模型的程序文件 |
| segment\val.py | 在验证集上评估图像分割模型性能的程序文件 |
| utils\activations.py | 包含一些激活函数的定义和函数 |
| utils\augmentations.py | 包含一些数据增强函数的定义和函数 |
| utils\autoanchor.py | 包含自动锚框生成的函数 |
| utils\autobatch.py | 包含自动批处理的函数 |
| utils\callbacks.py | 包含一些回调函数的定义和函数 |
| utils\dataloaders.py | 包含数据加载器的定义和函数 |
| utils\downloads.py | 包含一些下载函数的定义和函数 |
| utils\general.py | 包含一些通用函数的定义和函数 |
| utils\loss.py | 包含一些损失函数的定义和函数 |
| utils\metrics.py | 包含一些评估指标的定义和函数 |
| utils\plots.py | 包含一些绘图函数的定义和函数 |
| utils\torch_utils.py | 包含一些PyTorch工具函数的定义和函数 |
| utils\triton.py | 包含与Triton Inference Server集成的函数 |
| utils_init_.py | 工具函数初始化文件 |
| utils\aws\resume.py | 包含AWS训练恢复的函数 |
| utils\aws_init_.py | AWS初始化文件 |
| utils\flask_rest_api\example_request.py | 包含Flask REST API示例请求的函数 |
| utils\flask_rest_api\restapi.py | 包含Flask REST API的定义和函数 |
| utils\loggers_init_.py | 日志记录器初始化文件 |
| utils\loggers\clearml\clearml_utils.py | 包含ClearML日志记录器的一些辅助函数 |
| utils\loggers\clearml\hpo.py | 包含ClearML超参数优化的函数 |
| utils\loggers\clearml_init_.py | ClearML日志记录器初始化文件 |
7.Gold-YOLO简介
YOLO再升级:华为诺亚提出Gold-YOLO,聚集-分发机制打造新SOTA
在过去的几年中,YOLO系列模型已经成为实时目标检测领域的领先方法。许多研究通过修改架构、增加数据和设计新的损失函数,将基线推向了更高的水平。然而以前的模型仍然存在信息融合问题,尽管特征金字塔网络(FPN)和路径聚合网络(PANet)已经在一定程度上缓解了这个问题。因此,本研究提出了一种先进的聚集和分发机制(GD机制),该机制通过卷积和自注意力操作实现。这种新设计的模型被称为Gold-YOLO,它提升了多尺度特征融合能力,在所有模型尺度上实现了延迟和准确性的理想平衡。此外,本文首次在YOLO系列中实现了MAE风格的预训练,使得YOLO系列模型能够从无监督预训练中受益。Gold-YOLO-N在COCO val2017数据集上实现了出色的39.9% AP,并在T4 GPU上实现了1030 FPS,超过了之前的SOTA模型YOLOv6-3.0-N,其FPS相似,但性能提升了2.4%。
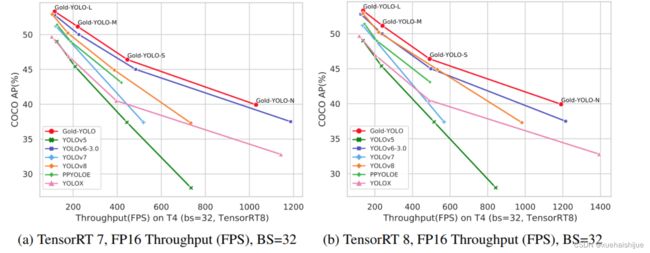
Gold-YOLO
YOLO系列的中间层结构采用了传统的FPN结构,其中包含多个分支用于多尺度特征融合。然而,它只充分融合来自相邻级别的特征,对于其他层次的信息只能间接地进行“递归”获取。
传统的FPN结构在信息传输过程中存在丢失大量信息的问题。这是因为层之间的信息交互仅限于中间层选择的信息,未被选择的信息在传输过程中被丢弃。这种情况导致某个Level的信息只能充分辅助相邻层,而对其他全局层的帮助较弱。因此,整体上信息融合的有效性可能受到限制。
为了避免在传输过程中丢失信息,本文采用了一种新颖的“聚集和分发”机制(GD),放弃了原始的递归方法。该机制使用一个统一的模块来收集和融合所有Level的信息,并将其分发到不同的Level。通过这种方式,作者不仅避免了传统FPN结构固有的信息丢失问题,还增强了中间层的部分信息融合能力,而且并没有显著增加延迟。

8.低阶聚合和分发分支 Low-stage gather-and-distribute branch
从主干网络中选择输出的B2、B3、B4、B5特征进行融合,以获取保留小目标信息的高分辨率特征。

低阶特征对齐模块 (Low-stage feature alignment module): 在低阶特征对齐模块(Low-FAM)中,采用平均池化(AvgPool)操作对输入特征进行下采样,以实现统一的大小。通过将特征调整为组中最小的特征大小( R B 4 = 1 / 4 R ) (R_{B4} = 1/4R)(R
B4 =1/4R),我们得到对齐后的特征F a l i g n F_{align}F align 。低阶特征对齐技术确保了信息的高效聚合,同时通过变换器模块来最小化后续处理的计算复杂性。其中选择 R B 4 R_{B4}R B4 作为特征对齐的目标大小主要基于保留更多的低层信息的同时不会带来较大的计算延迟。
低阶信息融合模块(Low-stage information fusion module): 低阶信息融合模块(Low-IFM)设计包括多层重新参数化卷积块(RepBlock)和分裂操作。具体而言,RepBlock以F a l i g n ( c h a n n e l = s u m ( C B 2 , C B 3 , C B 4 , C B 5 ) ) F_{align} (channel= sum(C_{B2},C_{B3},C_{B4},C_{B5}))F align (channel=sum(C B2 ,C B3 ,C B4 ,C B5 )作为输入,并生成F f u s e ( c h a n n e l = C B 4 + C B 5 ) F_{fuse} (channel= C_{B4} + C_{B5})F fuse (channel=C B4 +C B5 )。其中中间通道是一个可调整的值(例如256),以适应不同的模型大小。由RepBlock生成的特征随后在通道维度上分裂为F i n j P 3 Finj_P3Finj P 3和F i n j P 4 Finj_P4Finj P 4,然后与不同级别的特征进行融合。
8.高阶聚合和分发分支 High-stage gather-and-distribute branch
高级全局特征对齐模块(High-GD)将由低级全局特征对齐模块(Low-GD)生成的特征{P3, P4, P5}进行融合。
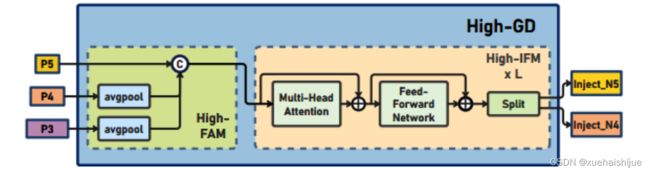
高级特征对齐模块(High-stage feature alignment module): High-FAM由avgpool组成,用于将输入特征的维度减小到统一的尺寸。具体而言,当输入特征的尺寸为{R P 3 R_{P3}R P3 , R P 4 R_{P4}R P4 , R P 5 R_{P 5}R P5 }时,avgpool将特征尺寸减小到该特征组中最小的尺寸(R P 5 R_{P5}R P5 = 1/8R)。由于transformer模块提取了高层次的信息,池化操作有助于信息聚合,同时降低了transformer模块后续步骤的计算需求。
Transformer融合模块由多个堆叠的transformer组成,transformer块的数量为L。每个transformer块包括一个多头注意力块、一个前馈网络(FFN)和残差连接。采用与LeViT相同的设置来配置多头注意力块,使用16个通道作为键K和查询Q的头维度,32个通道作为值V的头维度。为了加速推理过程,将层归一化操作替换为批归一化,并将所有的GELU激活函数替换为ReLU。为了增强变换器块的局部连接,在两个1x1卷积层之间添加了一个深度卷积层。同时,将FFN的扩展因子设置为2,以在速度和计算成本之间取得平衡。
信息注入模块(Information injection module): 高级全局特征对齐模块(High-GD)中的信息注入模块与低级全局特征对齐模块(Low-GD)中的相同。在高级阶段,局部特征(Flocal)等于Pi,因此公式如下所示:
9. 增强的跨层信息流动 Enhanced cross-layer information flow
为了进一步提升性能,从YOLOv6 中的PAFPN模块中得到启发,引入了Inject-LAF模块。该模块是注入模块的增强版,包括了一个轻量级相邻层融合(LAF)模块,该模块被添加到注入模块的输入位置。为了在速度和准确性之间取得平衡,设计了两个LAF模型:LAF低级模型和LAF高级模型,分别用于低级注入(合并相邻两层的特征)和高级注入(合并相邻一层的特征)。它们的结构如图5(b)所示。为了确保来自不同层级的特征图与目标大小对齐,在实现中的两个LAF模型仅使用了三个操作符:双线性插值(上采样过小的特征)、平均池化(下采样过大的特征)和1x1卷积(调整与目标通道不同的特征)。模型中的LAF模块与信息注入模块的结合有效地平衡了准确性和速度之间的关系。通过使用简化的操作,能够增加不同层级之间的信息流路径数量,从而提高性能而不显著增加延迟。

10.融合Gold-YOLO的改进YOLOv5网络结构
# YOLOv5 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 4 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[[2, 4, 6, 9], 1, SimFusion_4in, []], # 10
[-1, 1, IFM, [[64, 32]]], # 11
[9, 1, Conv, [512, 1, 1]], # 12
[[4, 6, -1], 1, SimFusion_3in, [512]], # 13
[[-1, 11], 1, InjectionMultiSum_Auto_pool, [512, [64, 32], 0]], # 14
[-1, 3, C3, [512, False]], # 15
[6, 1, Conv, [256, 1, 1]], # 16
[[2, 4, -1], 1, SimFusion_3in, [256]], # 17
[[-1, 11], 1, InjectionMultiSum_Auto_pool, [256, [64, 32], 1]], # 18
[-1, 3, C3, [256, False]], # 19
[[19, 15, 9], 1, PyramidPoolAgg, [352, 2]], # 20
[-1, 1, TopBasicLayer, [352, [64, 128]]], # 21
[[19, 16], 1, AdvPoolFusion, []], # 22
[[-1, 21], 1, InjectionMultiSum_Auto_pool, [256, [64, 128], 0]], # 23
[-1, 3, C3, [256, False]], # 24
[[-1, 12], 1, AdvPoolFusion, []], # 25
[[-1, 21], 1, InjectionMultiSum_Auto_pool, [512, [64, 128], 1]], # 26
[-1, 3, C3, [512, False]], # 27
[[19, 24, 27], 1, Detect, [nc, anchors]] # 28
]
11.训练结果可视化分析
评价指标
epoch:表示训练周期数。
train/loss:训练期间的损失函数值,衡量模型的性能。值越低表示性能越好。
test/loss:测试时的损失函数值,与train/loss未见过的测试数据类似。
metrics/accuracy_top1:Top-1 准确度指标,可能表示以最高概率正确分类的测试样本的百分比。
metrics/accuracy_top5:前 5 个准确度指标,可能表示正确类别属于模型前 5 个预测的测试样本的百分比。
lr/0:每个时期的学习率,显示它如何随着训练的进展而变化。
训练结果可视化
为了可视化这些数据,我们可以绘制历元内的损失和准确性,以观察趋势和性能改进。我们还可以分析学习率,看看它对训练过程的影响。
import matplotlib.pyplot as plt
# Set up the figure and axis
fig, ax1 = plt.subplots(figsize=(14, 7))
# Plot training and test loss
ax1.plot(data['epoch'], data['train/loss'], label='Training Loss', color='r')
ax1.plot(data['epoch'], data['test/loss'], label='Test Loss', color='g')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss')
ax1.set_title('Training and Test Loss over Epochs')
ax1.legend(loc='upper left')
# Instantiate a second axis that shares the same x-axis
ax2 = ax1.twinx()
ax2.plot(data['epoch'], data['metrics/accuracy_top1'], label='Top-1 Accuracy', color='b')
ax2.set_ylabel('Accuracy')
ax2.legend(loc='upper right')
# Show plot
plt.grid(True)
plt.show()

分析内容
损失分析:观察训练损失和测试损失随着时间的变化,以了解模型是否在学习和改进。理想情况下,随着迭代次数的增加,损失应该逐渐减少。
准确性分析:评估模型的准确率指标来判断其性能。Top-1准确率反映了模型对最可能的类别预测的准确性,而Top-5准确率提供了更广泛的性能评估。
学习率分析:检查学习率随时间的变化,因为不严格的学习率调整可能会导致训练不稳定或学习过慢。
经过检查:比较训练损失与测试损失,如果训练损失持续低于测试损失,可能表明模型在训练数据上过过。
改进点识别:根据上述分析,确定可能的问题区域和改进模型性能的策略。
训练和测试损失
下降趋势:训练和测试损失随着 epoch 数量的增加而减少,表明模型正在随着时间的推移学习并改进其预测。
稳定:经过最初的快速下降期后,丢失率似乎稳定下来,这表明在当前架构和数据的情况下,模型可能正在接近其最佳性能。
过拟合检查:测试损失并没有显着低于训练损失,这是一个好迹象,表明过拟合可能不会发生。过度拟合是指模型在训练数据上表现良好,但在未见过的数据上表现不佳。
Top-1 准确度
准确率高: top-1 准确率非常高,从 95% 左右开始,逐渐增加到接近 98%。这表明模型在大多数情况下都能以最高的概率正确识别正确的类别。
一致性:经过初始改进阶段后,准确率保持一致,这意味着模型能够可靠地对测试数据进行分类。
学习率
此处未将学习率可视化,但值得注意的是,学习率通常会随着训练时间的推移而降低,这使得模型在微调权重时可以进行较小的调整。
12.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《【遥遥领先】融合Gold-YOLO的改进YOLOv5的水果新鲜度分级分拣系统》
13.参考文献
[1]田梦瑶,周宏胜,唐婷婷,等.外源蔗糖处理对采后桃果皮色泽形成的影响[J].食品科学.2022,43(1).DOI:10.7506/spkx1002-6630-20201112-135 .
[2]邓莹,金爱武,朱强根,等.机器视觉下多特征组合的竹子分类方法[J].软件导刊.2021,(6).DOI:10.11907/rjdk.201972 .
[3]何军,马稚昱,褚璇,等.基于机器视觉的芒果果形评价方法研究[J].现代农业装备.2021,(1).
[4]陈林琳,姜大庆,黄菊,等.基于机器视觉的火龙果自动分级系统设计[J].农机化研究.2020,(5).DOI:10.3969/j.issn.1003-188X.2020.05.022 .
[5]邹运乾,张立,吴方方,等.打蜡处理对温州蜜柑果实异味物质积累的影响[J].中国农业科学.2020,(12).DOI:10.3864/j.issn.0578-1752.2020.12.012 .
[6]徐义鑫,张雪飞,李凤菊.一种减小基于机器视觉的水果尺寸测量误差的方法[J].天津农业科学.2020,(4).DOI:10.3969/j.issn.1006-6500.2020.04.009 .
[7]樊泽泽,柳倩,柴洁玮,等.基于颜色与果径特征的苹果树果实检测与分级[J].计算机工程与科学.2020,(9).DOI:10.3969/j.issn.1007-130X.2020.09.010 .
[8]廖娟,陈民慧,汪鹞,等.基于双重Gamma校正的秧苗图像增强算法[J].江苏农业学报.2020,(6).DOI:10.3969/j.issn.1000-4440.2020.06.009 .
[9]宋春华,彭泫知.机器视觉研究与发展综述[J].装备制造技术.2019,(6).DOI:10.3969/j.issn.1672-545X.2019.06.062 .
[10]周蓉,徐丽萍,王银磊,等.樱桃番茄果实光泽度测定方法的建立和应用[J].江苏农业学报.2018,(3).DOI:10.3969/j.issn.1000-4440.2018.03.021 .