- 【iOS越狱开发】iOS越狱步骤1之环境搭建
JR_Wang2491
MAC移动苹果iosiosiphoneipad
这段时间都是研究iOS越狱事情,如今我会一点一点的把自己学到的遇到的问题会陆续编写出来,让大家一起讨论,也让做逆向的朋友有个交流平台机会,废话不多说!!一、学习条件至少1~2年iOS开发经验基本UI界面操作多线程网络基本操作数据储存基本操作一台苹果手机,建议至少iPhone5S(因为从5S开始支持arm64架构)或者至少是iPadAir、iPadmini2等支持arm64架构的设备系统至少iOS8
- iphone se 一代 不完美越狱 14.6 视频壁纸教程(踩坑笔记)
YANG_301
iosiphone
iphonese一代不完美越狱14.6加视频壁纸教程-踩坑笔记越狱流程1.爱思助手制作启动u盘坑点:2.越狱好后视频壁纸软件1.源2.软件安装越狱流程1.爱思助手制作启动u盘https://www.i4.cn/news_detail_42302.html此网址为具体流程,但要注意!!!坑点:下图中最后一排quickmode应被勾选(勾选后是×(´ཀ`」∠))进入options后不禁要勾选allow
- Docker+Portainer 离线安装
qq_30024063
docker容器运维
1.Docker安装步骤一:官网下载docker安装包步骤二:解压安装包;tar-zxvfdocker-24.0.6.tgz步骤三:将解压之后的docker文件移到/usr/bin目录下;cpdocker/*/usr/bin/步骤四:将docker注册成系统服务;vim/etc/systemd/system/docker.service然后在文件中添加以下内容,退出并保存(:wq!)[Unit]D
- 【LlamaIndex核心组件指南 | 模型篇】一文通晓 LlamaIndex 模型层:LLM、Embedding 及多模态应用全景解析
Langchain系列文章目录01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南02-玩转LangChainMemory模块:四种记忆类型详解及应用场景全覆盖03-全面掌握LangChain:从核心链条构建到动态任务分配的实战指南04-玩转LangChain:从文档加载到高效问答系统构建的全程实战05-玩转LangChain:深度评估问答系统的三种高效方法(示例生成、手
- Python_计算两个省市之间的直线距离_2506
夏天里的肥宅水
PYTHONpythonspring开发语言
更新代码上一版链接importpandasaspdimporttimeimportpickleimportosimportsysfromgeopy.geocodersimportNominatimfromgeopy.distanceimportgeodesicfromtqdmimporttqdm#ConfigurationINPUT_FILE=r"距离.xlsx"#输入文件路径OUTPUT_FIL
- python中的*args 和 **kwargs
Hi_kenyon
pythonpython
简单来说,它们允许一个函数接收不定数量的参数。这在我们预先不知道会传递多少个参数给函数时非常有用。*args(任意数量的位置参数)*args用于在一个函数中接收任意数量的位置参数(positionalarguments)。当你在函数定义中使用*args时,Python会将所有传入的多余的位置参数收集到一个元组(tuple)中。这个名字args只是一个约定俗成的惯例(arguments的缩写),你也
- iPhone越狱基本流程
王景程
githubiphonexcodemacos
目录一、什么是越狱(Jailbreak)?二、越狱前的准备工作三、越狱方式总览(按iOS版本划分)越狱类型:主流越狱工具一览:四、以Checkra1n为例讲解越狱流程(适合iPhoneX及更早)✅支持设备(iOS12–14):步骤:五、越狱后的操作(以Cydia为例)⚠️六、越狱风险与注意事项总结流程图:一、iPhone16+iOS26:是否可以越狱?当前情况(截至2025年中):二、为何新设备(
- 《AI颠覆编码:GPT-4在编译器层面的奇幻漂流》的深度技术解析
踢足球的,程序猿
人工智能pythonc语言
一、传统编译器的黄昏:LLVM面临的AI降维打击1.1经典优化器的性能天花板//LLVM循环优化Pass传统实现(LoopUnroll.cpp)voidLoopUnrollPass::runOnLoop(Loop*L){unsignedTripCount=SE->getSmallConstantTripCount(L);if(!TripCount||TripCount>UnrollThreshol
- ref() 与 reactive()
前端岳大宝
前端框架Vuejavascript前端vue.js
下面,我们来系统的梳理关于ref()与reactive()的基本知识点:一、响应式编程核心概念1.1什么是响应式编程?响应式编程是一种声明式编程范式,它使数据变化能够自动传播到依赖它的代码部分。在Vue中,响应式系统实现了:数据驱动视图:数据变化自动更新DOM依赖追踪:自动跟踪数据依赖关系高效更新:最小化不必要的DOM操作1.2Vue响应式系统演进版本响应式实现特点Vue2Object.defin
- c语言实现2的n次方
network爬虫
算法c语言
#include#includeintmain(){intn;scanf("%d",&n);doublea=pow(2,n);printf("%lf\n",a);}
- 2025-6-28-C++ 学习 模拟与高精度(8)
文章目录2025-6-28-C++学习模拟与高精度(8)P1591阶乘数码题目描述输入格式输出格式输入输出样例#1输入#1输出#1提交代码P1249最大乘积题目描述输入格式输出格式输入输出样例#1输入#1输出#1提交代码P1045[NOIP2003普及组]麦森数题目描述输入格式输出格式输入输出样例#1输入#1输出#1说明/提示提交代码2025-6-28-C++学习模拟与高精度(8) 模拟题,Co
- 用 Python 开发文字冒险游戏:从零开始的教程
晓天天天向上
pythonmicrosoft开发语言
文字冒险游戏(Text-basedAdventureGame)是一种经典的游戏类型,玩家通过输入文字指令与游戏世界互动。这种游戏不依赖复杂的图形界面,非常适合初学者学习编程逻辑和用户交互。在本篇博客中,我们将用Python开发一个简单的文字冒险游戏,体验游戏开发的乐趣。1.游戏设计思路游戏背景玩家醒来发现自己身处一个神秘的地下城,需要探索房间、收集物品、战胜敌人并找到出口。核心机制房间导航:玩家可
- 从零开始理解零样本学习:AI人工智能必学技术
AI天才研究院
AgenticAI实战AI人工智能与大数据AI大模型企业级应用开发实战ai
从零开始理解零样本学习:AI人工智能必学技术关键词:零样本学习、人工智能、机器学习、知识迁移、语义嵌入摘要:本文旨在全面深入地介绍零样本学习这一在人工智能领域具有重要意义的技术。首先阐述零样本学习的背景和基本概念,通过详细的解释和直观的示意图让读者建立起对零样本学习的初步认识。接着深入剖析其核心算法原理,结合Python代码进行详细说明,同时引入相关数学模型和公式并举例阐释。通过项目实战部分,带领
- Java中的批处理优化:使用Spring Batch处理大规模数据的实践
微赚淘客系统开发者@聚娃科技
javaspringbatch
Java中的批处理优化:使用SpringBatch处理大规模数据的实践大家好,我是微赚淘客返利系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿!在处理大规模数据的场景中,批处理是一个非常常见且必要的操作。Java中的SpringBatch是一个强大的框架,能够帮助我们高效地执行复杂的批处理任务。本文将带大家了解如何使用SpringBatch处理大规模数据,并通过代码示例展示如何实现高效的批
- 稳定币独角兽:Circle
InnoLink_1024
区块链稳定币区块链
Circle公司背景分析CircleInternetFinancial(以下简称Circle)是一家成立于2013年的美国金融科技公司,总部位于波士顿,由JeremyAllaire和SeanNeville联合创立。公司最初专注于点对点加密货币支付和交易,后转型为全球领先的稳定币发行机构,其核心产品是与美元1:1挂钩的USDCoin(USDC),目前为全球第二大稳定币,仅次于Tether的USDT。
- Cline中配置MCP
Alexon Xu
MCP
1、自动安装MCP默认AI生成的配置会报错:spawnnpxENOENTspawnnpxENOENT,然后排查了npx安装都是OK的,需要使用cmd运行npx,配置如下:{"mcpServers":{"sequentialthinking":{"autoApprove":[],"disabled":false,"timeout":60,"command":"cmd.exe","args":["/c
- js递归性能优化
啃火龙果的兔子
开发DEMOjavascript开发语言ecmascript
JavaScript递归性能优化递归是编程中强大的技术,但在JavaScript中如果不注意优化可能会导致性能问题甚至栈溢出。以下是几种优化递归性能的方法:1.尾调用优化(TailCallOptimization,TCO)ES6引入了尾调用优化,但只在严格模式下有效:'usestrict';//普通递归functionfactorial(n){if(n===1)return1;returnn*fa
- 2025 VUE常见面试题
hmildj
vue.js面试前端
前言总结一些VUE面试的基础知识,共同学习1.什么是Vue?答案:Vue.js(通常简称为Vue)是一个用于构建用户界面的渐进式JavaScript框架,Vue3是Vue.js框架的最新版本,它引入了许多改进和优化,包括性能提升、更好的类型支持、组合API等。2.MVVM模式是什么?Vue如何体现这一模式?答案:MVVM将视图(View)与数据(Model)通过ViewModel层解耦,Vue
- 初学翁凯老师的c语言后对其中一些问题的看法
Obltv
#初学c语言c语言
文章目录初学翁凯老师的c语言后对其中一些问题的看法一、一个课后的简单逻辑语法问题二、解答和一些思考1.**++i++--**2.**i++++**3.**a=b+=c++-d+--e/-f**问题初探原代码逻辑举例初次写博客的看法及感受初学翁凯老师的c语言后对其中一些问题的看法学习c语言已有数天,其中一些问题今日来看仍有研究价值,故记录探讨之一、一个课后的简单逻辑语法问题++i+±-i++++a=
- 卷积神经网络(Convolutional Neural Network, CNN)
不想秃头的程序
神经网络语音识别人工智能深度学习网络卷积神经网络
卷积神经网络(ConvolutionalNeuralNetwork,CNN)是一种专门用于处理图像、视频等网格数据的深度学习模型。它通过卷积层自动提取数据的特征,并利用空间共享权重和池化层减少参数量和计算复杂度,成为计算机视觉领域的核心技术。以下是CNN的详细介绍:一、核心思想CNN的核心目标是从图像中自动学习层次化特征,并通过空间共享权重和平移不变性减少参数量和计算成本。其关键组件包括:卷积层(
- ResNet(Residual Network)
不想秃头的程序
神经网络语音识别人工智能深度学习网络残差网络神经网络
ResNet(ResidualNetwork)是深度学习中一种经典的卷积神经网络(CNN)架构,由微软研究院的KaimingHe等人在2015年提出。它通过引入残差连接(SkipConnection)解决了深度神经网络中的梯度消失问题,使得网络可以训练极深的模型(如上百层),并在图像分类、目标检测、语义分割等任务中取得了突破性成果。以下是ResNet的详细介绍:一、核心思想ResNet的核心创新是
- 《现代通信原理与技术》模拟调制与解调—FM 调制实验报告
不想秃头的程序
人工智能matlab信息与通信信号处理
摘要本实验旨在通过MATLAB软件进行模拟调制与解调的实践,加深对频率调制(FrequencyModulation,FM)原理的理解,并掌握FM调制与解调的实现方法。关键词:MATLAB引言在现代通信系统中,调制技术是实现信息传输的核心方法之一。频率调制(FrequencyModulation,FM)作为一种重要的模拟调制方式,通过改变载波信号的频率来传递信息,广泛应用于广播、电视、无线通信等领域
- 平台再升级!接入DeepSeek AI,三大能力一键生成
橙武科技
低代码AIdeepseek人工智能
在数字化项目落地过程中,很多企业都会面临相同的问题:数据库建模要写SQL表结构;业务流程需要画LogicFlow流程图;前端页面还要写AMISJSON配置。从想法到实现,中间至少要经历产品经理、架构师、后端、前端多轮沟通。每个环节都耗时,改起来还要推翻重来。demo地址:https://admin.cwcode.top✨我们的平台,现在直接整合了DeepSeekAI大模型只要输入一句需求,就能:✅
- P25:LSTM实现糖尿病探索与预测
?Agony
lstm人工智能rnn
本文为365天深度学习训练营中的学习记录博客原作者:K同学啊一、相关技术1.LSTM基本概念LSTM(长短期记忆网络)是RNN(循环神经网络)的一种变体,它通过引入特殊的结构来解决传统RNN中的梯度消失和梯度爆炸问题,特别适合处理序列数据。结构组成:遗忘门:决定丢弃哪些信息,通过sigmoid函数输出0-1之间的值,表示保留或遗忘的程度。输入门:决定更新哪些信息,同样通过sigmoid函数控制更新
- 什么是 QueryGPT?智能查询工具如何重塑信息检索的未来?
镜舟科技
StarRocksQueryGPT数据查询数据分析多模态交互
从客户行为数据到供应链信息,从市场趋势到内部运营指标,这些数据蕴含着巨大的商业价值。然而,数据量的激增也带来了前所未有的检索挑战:如何在海量信息中快速定位所需数据?如何确保查询结果的准确性和时效性?据统计,75%的企业正受困于低效的查询工具,这已成为阻碍企业数字化转型的关键痛点。传统的数据查询方式主要依赖SQL语句或特定的查询语言,这要求用户具备专业的编程知识和对数据结构的深入理解。即使对于数据分
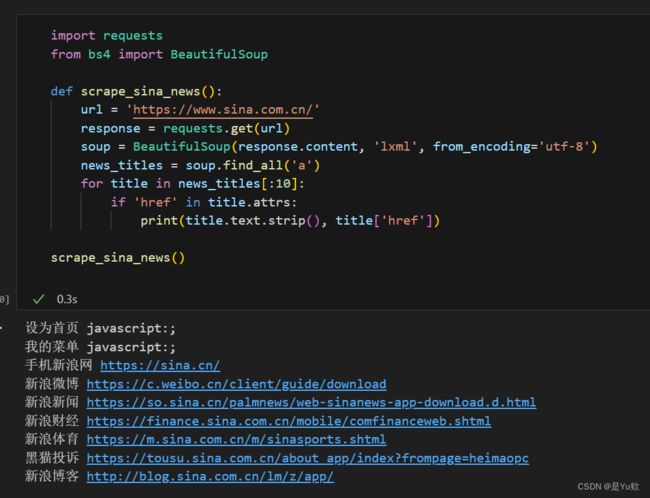
- Python训练营打卡——DAY16(2025.5.5)
cosine2025
Python训练营打卡python开发语言机器学习
目录一、NumPy数组基础笔记1.理解数组的维度(Dimensions)2.NumPy数组与深度学习Tensor的关系3.一维数组(1DArray)4.二维数组(2DArray)5.数组的创建5.1数组的简单创建5.2数组的随机化创建5.3数组的遍历5.4数组的运算6.数组的索引6.1一维数组索引6.2二维数组索引6.3三维数组索引二、SHAP值的深入理解三、总结1.NumPy数组基础总结2.SH
- AI助力基因遗传疾病检测:现状与未来
t0_54program
大数据与人工智能人工智能个人开发
在现代医学领域,与基因紊乱相关疾病的早期检测至关重要。像肺癌,早期诊断的患者5年生存率可达57%,而四期癌症患者生存率仅3%。阿尔茨海默病的早期检测,能让患者改变生活方式、参与临床试验并提前治疗脑部退化症状,有效延长生命。尽管基因检测对评估晚发性阿尔茨海默病的可能性有帮助,对早发性阿尔茨海默病也有指示作用,但其检测技术仍有待完善。目前,仅基于生物学研究的疾病检测技术多样,虽对特定病例精确,但通常需
- Python的一点基础教程------文件读写
卡提西亚
python开发语言
最近在看大佬写的Python教程自学,但是感觉有点头痛,因为大佬讲了一些底层的结构和原理,但是又没那么详细,然后作为一个初学者自学的情况下,看的很费劲.看完就有感而发,想写一篇更基础的教程,教会大家怎么去用它,尽量少的去讲原理.但是当然,你也需要有一定的编程语言基础,了解基本的语法和函数等功能.正所谓师傅领进门,修行在个人,有时候我们学了一个东西,如果觉得很有趣,自然就会去了解关于它的更多信息,但
- 1.2 Python 的特点与优势
Utopia Reverie
pythonpython开发语言
1.语法简洁易读Python以简洁的语法著称,代码可读性强,减少了不必要的符号和冗余代码。例如,使用缩进来表示代码块,而非传统的大括号。这使得代码更易于理解和维护,尤其适合初学者。示例:python运行【#计算斐波那契数列的前10项n=10a,b=0,1for_inrange(n);print(a,end='')a,b=b,a+b#输出:0112358132134】2.开源与社区支持Python是
- AI写作实战:从零开始撰写项目提案
SuperMale-zxq
AI编程写作投资专栏AI写作java人工智能AI编程python
AI写作实战:从零开始撰写项目提案为什么大多数项目提案一出生就已经死亡?还记得上周看到一封邮件吗?一位读者小李发了他精心准备的项目提案,希望有人给些建议。打开附件的那一刻,我叹了口气——这又是一份"自嗨式提案":密密麻麻的文字堆砌、技术术语泛滥、价值主张模糊不清。我发现数千份项目提案中,有超过80%在开头几分钟就失去了读者的注意力。更残酷的是,决策者通常只会花60秒浏览你的提案,如果没有在这短暂时
- VMware Workstation 11 或者 VMware Player 7安装MAC OS X 10.10 Yosemite
iwindyforest
vmwaremac os10.10workstationplayer
最近尝试了下VMware下安装MacOS 系统,
安装过程中发现网上可供参考的文章都是VMware Workstation 10以下, MacOS X 10.9以下的文章,
只能提供大概的思路, 但是实际安装起来由于版本问题, 走了不少弯路, 所以我尝试写以下总结, 希望能给有兴趣安装OSX的人提供一点帮助。
写在前面的话:
其实安装好后发现, 由于我的th
- 关于《基于模型驱动的B/S在线开发平台》源代码开源的疑虑?
deathwknight
JavaScriptjava框架
本人从学习Java开发到现在已有10年整,从一个要自学 java买成javascript的小菜鸟,成长为只会java和javascript语言的老菜鸟(个人邮箱:
[email protected])
一路走来,跌跌撞撞。用自己的三年多业余时间,瞎搞一个小东西(基于模型驱动的B/S在线开发平台,非MVC框架、非代码生成)。希望与大家一起分享,同时有许些疑虑,希望有人可以交流下
平台
- 如何把maven项目转成web项目
Kai_Ge
mavenMyEclipse
创建Web工程,使用eclipse ee创建maven web工程 1.右键项目,选择Project Facets,点击Convert to faceted from 2.更改Dynamic Web Module的Version为2.5.(3.0为Java7的,Tomcat6不支持). 如果提示错误,可能需要在Java Compiler设置Compiler compl
- 主管???
Array_06
工作
转载:http://www.blogjava.net/fastzch/archive/2010/11/25/339054.html
很久以前跟同事参加的培训,同事整理得很详细,必须得转!
前段时间,公司有组织中高阶主管及其培养干部进行了为期三天的管理训练培训。三天的课程下来,虽然内容较多,因对老师三天来的课程内容深有感触,故借着整理学习心得的机会,将三天来的培训课程做了一个
- python内置函数大全
2002wmj
python
最近一直在看python的document,打算在基础方面重点看一下python的keyword、Build-in Function、Build-in Constants、Build-in Types、Build-in Exception这四个方面,其实在看的时候发现整个《The Python Standard Library》章节都是很不错的,其中描述了很多不错的主题。先把Build-in Fu
- JSP页面通过JQUERY合并行
357029540
JavaScriptjquery
在写程序的过程中我们难免会遇到在页面上合并单元行的情况,如图所示
如果对于会的同学可能很简单,但是对没有思路的同学来说还是比较麻烦的,提供一下用JQUERY实现的参考代码
function mergeCell(){
var trs = $("#table tr");
&nb
- Java基础
冰天百华
java基础
学习函数式编程
package base;
import java.text.DecimalFormat;
public class Main {
public static void main(String[] args) {
// Integer a = 4;
// Double aa = (double)a / 100000;
// Decimal
- unix时间戳相互转换
adminjun
转换unix时间戳
如何在不同编程语言中获取现在的Unix时间戳(Unix timestamp)? Java time JavaScript Math.round(new Date().getTime()/1000)
getTime()返回数值的单位是毫秒 Microsoft .NET / C# epoch = (DateTime.Now.ToUniversalTime().Ticks - 62135
- 作为一个合格程序员该做的事
aijuans
程序员
作为一个合格程序员每天该做的事 1、总结自己一天任务的完成情况 最好的方式是写工作日志,把自己今天完成了什么事情,遇见了什么问题都记录下来,日后翻看好处多多
2、考虑自己明天应该做的主要工作 把明天要做的事情列出来,并按照优先级排列,第二天应该把自己效率最高的时间分配给最重要的工作
3、考虑自己一天工作中失误的地方,并想出避免下一次再犯的方法 出错不要紧,最重
- 由html5视频播放引发的总结
ayaoxinchao
html5视频video
前言
项目中存在视频播放的功能,前期设计是以flash播放器播放视频的。但是现在由于需要兼容苹果的设备,必须采用html5的方式来播放视频。我就出于兴趣对html5播放视频做了简单的了解,不了解不知道,水真是很深。本文所记录的知识一些浅尝辄止的知识,说起来很惭愧。
视频结构
本该直接介绍html5的<video>的,但鉴于本人对视频
- 解决httpclient访问自签名https报javax.net.ssl.SSLHandshakeException: sun.security.validat
bewithme
httpclient
如果你构建了一个https协议的站点,而此站点的安全证书并不是合法的第三方证书颁发机构所签发,那么你用httpclient去访问此站点会报如下错误
javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path bu
- Jedis连接池的入门级使用
bijian1013
redisredis数据库jedis
Jedis连接池操作步骤如下:
a.获取Jedis实例需要从JedisPool中获取;
b.用完Jedis实例需要返还给JedisPool;
c.如果Jedis在使用过程中出错,则也需要还给JedisPool;
packag
- 变与不变
bingyingao
不变变亲情永恒
变与不变
周末骑车转到了五年前租住的小区,曾经最爱吃的西北面馆、江西水饺、手工拉面早已不在,
各种店铺都换了好几茬,这些是变的。
三年前还很流行的一款手机在今天看起来已经落后的不像样子。
三年前还运行的好好的一家公司,今天也已经不复存在。
一座座高楼拔地而起,
- 【Scala十】Scala核心四:集合框架之List
bit1129
scala
Spark的RDD作为一个分布式不可变的数据集合,它提供的转换操作,很多是借鉴于Scala的集合框架提供的一些函数,因此,有必要对Scala的集合进行详细的了解
1. 泛型集合都是协变的,对于List而言,如果B是A的子类,那么List[B]也是List[A]的子类,即可以把List[B]的实例赋值给List[A]变量
2. 给变量赋值(注意val关键字,a,b
- Nested Functions in C
bookjovi
cclosure
Nested Functions 又称closure,属于functional language中的概念,一直以为C中是不支持closure的,现在看来我错了,不过C标准中是不支持的,而GCC支持。
既然GCC支持了closure,那么 lexical scoping自然也支持了,同时在C中label也是可以在nested functions中自由跳转的
- Java-Collections Framework学习与总结-WeakHashMap
BrokenDreams
Collections
总结这个类之前,首先看一下Java引用的相关知识。Java的引用分为四种:强引用、软引用、弱引用和虚引用。
强引用:就是常见的代码中的引用,如Object o = new Object();存在强引用的对象不会被垃圾收集
- 读《研磨设计模式》-代码笔记-解释器模式-Interpret
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
package design.pattern;
/*
* 解释器(Interpreter)模式的意图是可以按照自己定义的组合规则集合来组合可执行对象
*
* 代码示例实现XML里面1.读取单个元素的值 2.读取单个属性的值
* 多
- After Effects操作&快捷键
cherishLC
After Effects
1、快捷键官方文档
中文版:https://helpx.adobe.com/cn/after-effects/using/keyboard-shortcuts-reference.html
英文版:https://helpx.adobe.com/after-effects/using/keyboard-shortcuts-reference.html
2、常用快捷键
- Maven 常用命令
crabdave
maven
Maven 常用命令
mvn archetype:generate
mvn install
mvn clean
mvn clean complie
mvn clean test
mvn clean install
mvn clean package
mvn test
mvn package
mvn site
mvn dependency:res
- shell bad substitution
daizj
shell脚本
#!/bin/sh
/data/script/common/run_cmd.exp 192.168.13.168 "impala-shell -islave4 -q 'insert OVERWRITE table imeis.${tableName} select ${selectFields}, ds, fnv_hash(concat(cast(ds as string), im
- Java SE 第二讲(原生数据类型 Primitive Data Type)
dcj3sjt126com
java
Java SE 第二讲:
1. Windows: notepad, editplus, ultraedit, gvim
Linux: vi, vim, gedit
2. Java 中的数据类型分为两大类:
1)原生数据类型 (Primitive Data Type)
2)引用类型(对象类型) (R
- CGridView中实现批量删除
dcj3sjt126com
PHPyii
1,CGridView中的columns添加
array(
'selectableRows' => 2,
'footer' => '<button type="button" onclick="GetCheckbox();" style=&
- Java中泛型的各种使用
dyy_gusi
java泛型
Java中的泛型的使用:1.普通的泛型使用
在使用类的时候后面的<>中的类型就是我们确定的类型。
public class MyClass1<T> {//此处定义的泛型是T
private T var;
public T getVar() {
return var;
}
public void setVa
- Web开发技术十年发展历程
gcq511120594
Web浏览器数据挖掘
回顾web开发技术这十年发展历程:
Ajax
03年的时候我上六年级,那时候网吧刚在小县城的角落萌生。传奇,大话西游第一代网游一时风靡。我抱着试一试的心态给了网吧老板两块钱想申请个号玩玩,然后接下来的一个小时我一直在,注,册,账,号。
彼时网吧用的512k的带宽,注册的时候,填了一堆信息,提交,页面跳转,嘣,”您填写的信息有误,请重填”。然后跳转回注册页面,以此循环。我现在时常想,如果当时a
- openSession()与getCurrentSession()区别:
hetongfei
javaDAOHibernate
来自 http://blog.csdn.net/dy511/article/details/6166134
1.getCurrentSession创建的session会和绑定到当前线程,而openSession不会。
2. getCurrentSession创建的线程会在事务回滚或事物提交后自动关闭,而openSession必须手动关闭。
这里getCurrentSession本地事务(本地
- 第一章 安装Nginx+Lua开发环境
jinnianshilongnian
nginxluaopenresty
首先我们选择使用OpenResty,其是由Nginx核心加很多第三方模块组成,其最大的亮点是默认集成了Lua开发环境,使得Nginx可以作为一个Web Server使用。借助于Nginx的事件驱动模型和非阻塞IO,可以实现高性能的Web应用程序。而且OpenResty提供了大量组件如Mysql、Redis、Memcached等等,使在Nginx上开发Web应用更方便更简单。目前在京东如实时价格、秒
- HSQLDB In-Process方式访问内存数据库
liyonghui160com
HSQLDB一大特色就是能够在内存中建立数据库,当然它也能将这些内存数据库保存到文件中以便实现真正的持久化。
先睹为快!
下面是一个In-Process方式访问内存数据库的代码示例:
下面代码需要引入hsqldb.jar包 (hsqldb-2.2.8)
import java.s
- Java线程的5个使用技巧
pda158
java数据结构
Java线程有哪些不太为人所知的技巧与用法? 萝卜白菜各有所爱。像我就喜欢Java。学无止境,这也是我喜欢它的一个原因。日常
工作中你所用到的工具,通常都有些你从来没有了解过的东西,比方说某个方法或者是一些有趣的用法。比如说线程。没错,就是线程。或者确切说是Thread这个类。当我们在构建高可扩展性系统的时候,通常会面临各种各样的并发编程的问题,不过我们现在所要讲的可能会略有不同。
- 开发资源大整合:编程语言篇——JavaScript(1)
shoothao
JavaScript
概述:本系列的资源整合来自于github中各个领域的大牛,来收藏你感兴趣的东西吧。
程序包管理器
管理javascript库并提供对这些库的快速使用与打包的服务。
Bower - 用于web的程序包管理。
component - 用于客户端的程序包管理,构建更好的web应用程序。
spm - 全新的静态的文件包管
- 避免使用终结函数
vahoa.ma
javajvmC++
终结函数(finalizer)通常是不可预测的,常常也是很危险的,一般情况下不是必要的。使用终结函数会导致不稳定的行为、更差的性能,以及带来移植性问题。不要把终结函数当做C++中的析构函数(destructors)的对应物。
我自己总结了一下这一条的综合性结论是这样的:
1)在涉及使用资源,使用完毕后要释放资源的情形下,首先要用一个显示的方