基于word2vec使用wiki中文语料库实现词向量训练模型--2019最新
目录
一、数据获取
二、将xml格式数据转为txt
三、繁体转为简体
方法1---自己使用opencc库手动了1个转换程序,pip install opencc进行安装
方法2---网上有一个exe应用程序进行转换,详情见:https://bintray.com/package/files/byvoid/opencc/OpenCC
四、分词
五、Word2Vec模型训练
六、Word2Vec模型检测
一、数据获取
使用的语料库是wiki百科的中文语料库
下载地址:https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2
![]()
上述地址下载较慢,我分享一个我已经下载好的文件(截止2019年7月11日)
下载地址:https://pan.baidu.com/s/1SAXNFcr4hQSZvcMi914_kQ , 提取码:kt20
二、将xml格式数据转为txt
使用了gensim库中的维基百科处理类WikiCorpus,该类中的get_texts方法原文件中的文章转化为一个数组,其中每一个元素对应着原文件中的一篇文章。然后通过for循环便可以将其中的每一篇文章读出,然后进行保存。
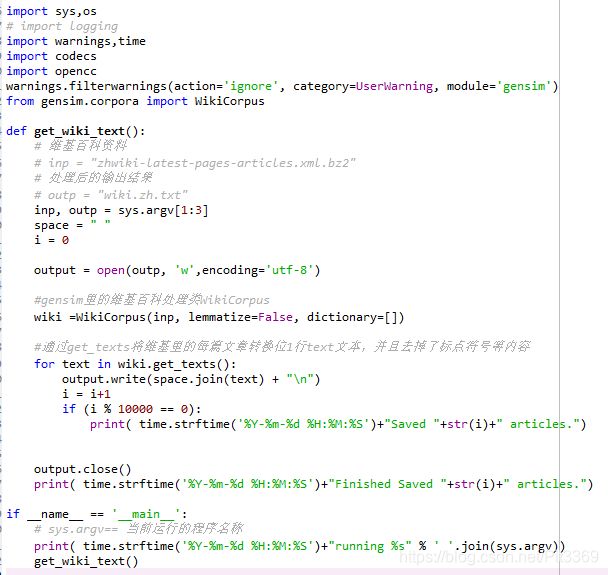 1_process.py
1_process.py

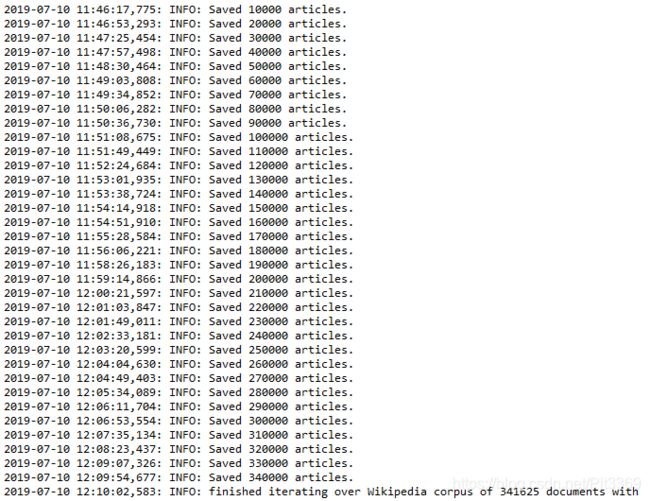
当时的转换过程,大概需要了30分钟吧!
三、繁体转为简体
由于维基内有些内容是繁体内容,需要进行繁体--简体转换。
方法1---自己使用opencc库手动了1个转换程序,pip install opencc进行安装
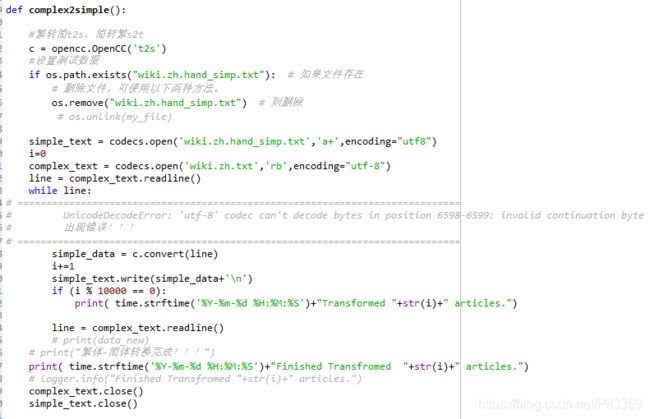 opencc库的繁简转换
opencc库的繁简转换
但是运行到130000+文章左右时出现了错误:(其实程序是对的,由于txt文件存在格式问题,后面详解!)
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 6598-6599: invalid continuation byte
但是我的所有文本操作都是“encoding="utf8",还是出现上述问题。
方法2---网上有一个exe应用程序进行转换,详情见:https://bintray.com/package/files/byvoid/opencc/OpenCC
进入解压后的opencc的目录(opencc-1.0.1-win32),双击opencc.exe文件。在当前目录打开dos窗口(Shift+鼠标右键->在此处打开命令窗口),输入如下命令行:
opencc -i wiki.zh.txt -o wiki.zh.simp.txt -c t2s.json
(wiki.zh.txt简繁混合文本,wiki.zh.simp.txt转换后的纯简体文本,t2s为繁体转简体,s2t为简体转繁体)
![]()
记事本无法打开这么大的txt文件,所以用notepad++打开,或者写几行代码打开:
四、分词
对于中文来说,分词是必须要经过的一步处理,下面就需要进行分词操作。在这里使用了大名鼎鼎的jieba库。调用其中的cut方法即可。顺便使用停用词进行了去除停用词!拿到了分词后的文件,在一般的NLP处理中,会需要去停用词。由于word2vec的算法依赖于上下文,而上下文有可能就是停词。因此对于word2vec,我们可以不用去停词。所以需要依据自己的需求,确定是否进行停用词!
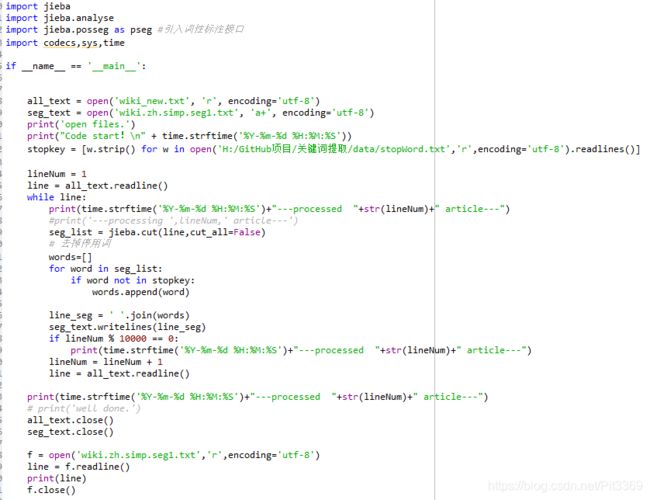 2_jieba_participle.py
2_jieba_participle.py
但是运行到130000+文章左右时出现了错误:
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 6598-6599: invalid continuation byte
但是我的所有文本操作都是“encoding="utf8",还是出现上述问题!!!好啦,现在就揭晓出错的原因是什么?
由于程序在写入txt文件的时候,存在类似于火星文的符号存在,所以这些符号会导致以'utf-8' 读取文件出现错误!
解决方法:
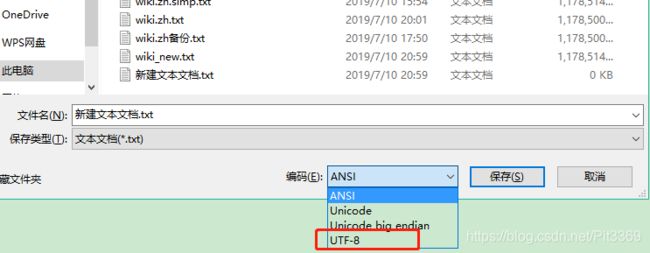
试了网上n种方法,都不可以,所以劳动人民最伟大!用notepad++打开“wiki.zh.txt”(wiki的txt文件),全选进行复制(或许会有点卡,做好准备!),新建一个txt文本(名字随意!),另存为的时候注意按照下图的方式进行存储!然后就是上面手动的繁简转换程序就可以正常运行了(也可以使用exe应用程序进行!),然后jieba分词就可以完美运行,但是有点心理准备,这个结巴分词的过程非常的缓慢!
分词的结果如下(貌似我的停用词好像不是很好!后续继续改进吧!)
 分词结果
分词结果
五、Word2Vec模型训练
分好词的文档即可进行word2vec词向量模型的训练了,文档较大,训练了应该有1个小时左右!
 3_train_word2vec_model.py
3_train_word2vec_model.py
代码运行完成后得到如下四个文件,其中wiki.zh.text.model是建好的模型,wiki.zh.text.vector是词向量。
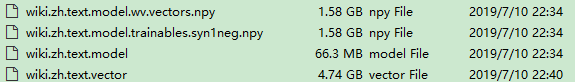 训练结果
训练结果
六、Word2Vec模型检测
模型训练好后,来测试模型的结果。
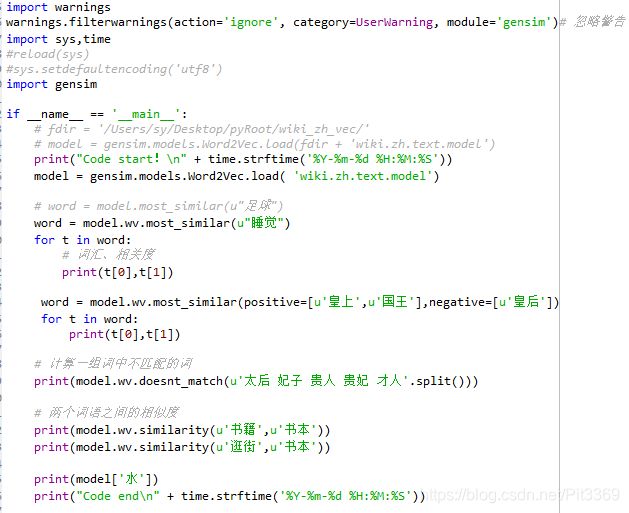 4_model_match.py
4_model_match.py
上述使用了gensim库,gensim是一个python的自然语言处理库,能够将文档根据TF-IDF, LDA, LSI 等模型转化成向量模式,以便进行进一步的处理。此外,gensim还实现了word2vec功能,能够将单词转化为词向量。
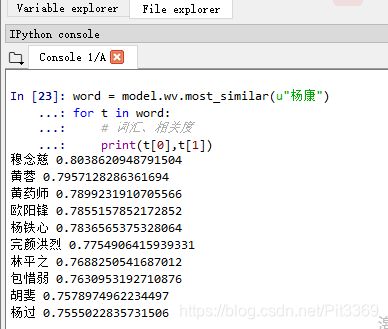 相关度计算
相关度计算
 计算词语之间相似度
计算词语之间相似度
推荐介绍gensim的博客:
https://blog.csdn.net/u014595019/article/details/52218249#commentBox
https://blog.csdn.net/l7h9ja4/article/details/80220939#commentBox
这是对于word2vec方法以及模型训练和检验的第一篇文章,其中关于文本2向量的有关知识进行了回顾,上面介绍gensim库的博客也对相关背景知识在其博客内详细说明了。
以上学习过程和代码,感谢两位博主:
liuwenqiang1202:https://github.com/liuwenqiang1202
AimeeLee77:https://github.com/AimeeLee77
代码及相关资料:
链接:https://pan.baidu.com/s/1JEvadkEflY1FrltWImw3BA , 提取码:u541