【使用Selenium爬取视频】
使用Selenium爬取视频
先确定网站
先确定你需要爬取的视频在确定网站的url ,因为视频的url可能会多次跳转。所以需要多次检查并且找到真正的url
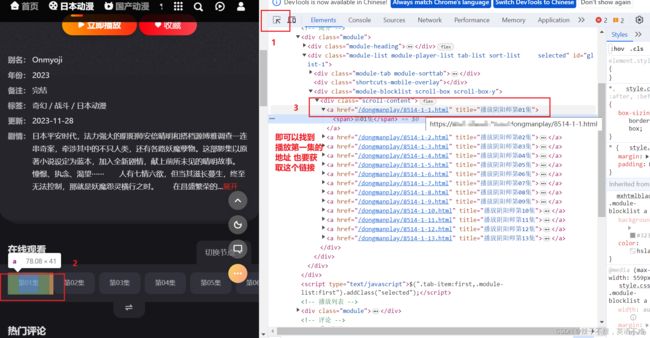
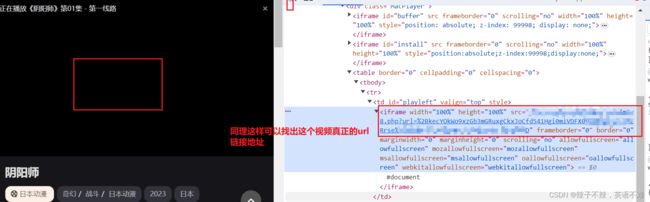

书写代码:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
import requests
from lxml import etree
import fake_useragent
from selenium.webdriver.edge import options
# 不打开页面的方式
opt = options.Options()
opt.add_argument("--headless")
# 爬取吞噬星空
url = "https://xxxxx/dongman/4925.html"
driver = webdriver.Chrome(opt)
driver.get(url)
time.sleep(3)
# 获得每一集的视频链接 全部的a标签
numbers = 1
a_list = driver.find_elements(By.XPATH,"//div[@class='module-listxxxxxxxt sort-list selected']/dixxxxx]/div/a")
print(a_list)
for a in a_list:
detail_url = a.get_attribute("href")
print(detail_url)
driver_edge = webdriver.Edge(opt)
driver_edge.get(detail_url)
time.sleep(3)
video_url = driver_edge.find_element(By.XPATH, '//div[@class="player-wrapper"]/xxxxxxx/tr/td/iframe').get_attribute('src')
print(video_url)
driver_fox = webdriver.Firefox()
driver_fox.get(video_url)
time.sleep(10)
video = driver_fox.find_element(By.XPATH, '//div[@class="xxxxxxx/video').get_attribute('src')
print(video)
print(f"开始爬取第{numbers}集")
response = requests.get(video,headers={"User-Agent": fake_useragent.UserAgent().random})
response_content = response.content
with open(f"./output/xxxxxx第{numbers}集.mp4", "wb") as fp:
fp.write(response_content)
numbers = numbers + 1
driver_fox.close()
driver_edge.close()
driver.close()
保存结果

分析网站的步骤大致都是很相同的,找到你要的东西,解析他的路径 然后用 requests ,selenium,或bs4进行爬取,最终找到你想要的东西。
== 如有侵权,请找我删除,抱歉==