人体姿态估计算法
人体姿态估计算法
- 1 什么是人体姿态估计
- 2 基于经典传统和基于深度学习的方法
-
- 2.1 基于经典传统的人体姿态估计算法
- 2.2 基于深度学习的人体姿态估计算法
-
- OpenPose
- AlphaPose (RMPE)
- 3 算法应用
- 4 Paper
人体姿态估计在现实中的应用场景很丰富,如下
动作捕捉:三维特效场景
人机交互:动作控制、手势控制
VR, AR:元宇宙数字人、抖音尬舞机、3D试衣、虚拟主播
肢体语言理解:机场、交警警察手势翻译、手语翻译
摔倒检测、健身、跳舞、球类、武术运动指导、穴位定位
步态分析、识别身份、异常动作识别
其中关键点检测是最开始的一步,本文主要对第一步的关键点检测进行一个概述,方便大家更快速的了解这里面涉及到的算法原理,属于科普文章。
1 什么是人体姿态估计
人体姿态估计(Human Pose Estimation, HPE) 是一种识别和分类人体关节的方法。本质上,它是一种捕获每个关节(手臂、头部、躯干等)的一组坐标的方法,该坐标被称为可以描述人的姿势的关键点(keypoint)。

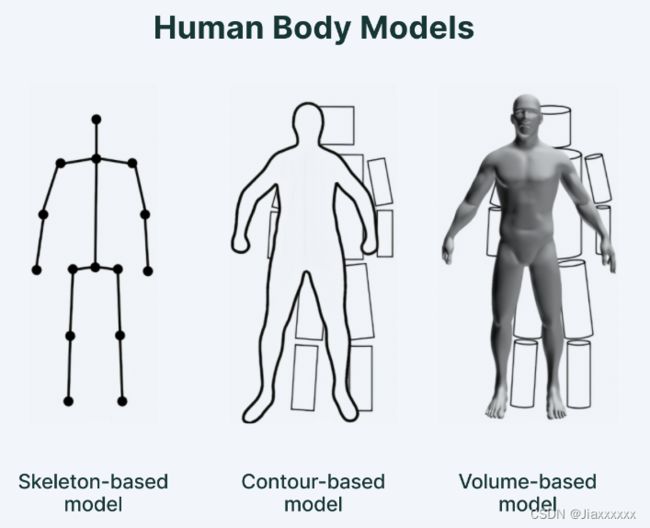
人体姿势估计模型主要有三种类型: 这三种类型是随着应用逐步发展出来的,先检测关键点,类似于火柴人,进一步的检测出人的轮廓,再根据轮廓进一步的把人体进行3D重建。
-
基于骨架的模型(Skeleton-based model): 也称为运动学模型,该模型包括一组关键点(关节),例如脚踝、膝盖、肩膀、肘部、手腕和肢体方向,主要用于 3D 和 2D 姿势估计。
这种灵活直观的人体模型包含人体的骨骼结构,经常用于捕捉不同身体部位之间的关系。
-
基于轮廓的模型(Contour-based model): 也称为平面模型,用于二维姿态估计,由身体、躯干和四肢的轮廓和粗略宽度组成。 基本上,它代表人体的外观和形状,其中身体部位用人的轮廓的边界和矩形显示。
一个著名的例子是主动形状模型(ASM),它采用主成分分析(PCA)技术捕获整个人体图形和轮廓变形。
-
基于体积的模型(Volume-based model): 也称为体积模型,用于 3D 姿态估计。 它由多个流行的 3D 人体模型和由人体几何网格和形状表示的姿势组成,通常用于基于深度学习的 3D 人体姿势估计。
2 基于经典传统和基于深度学习的方法
2.1 基于经典传统的人体姿态估计算法
早期人体姿态估计的经典传统方法是在“图结构框架(pictorial structure framework , PSF)”内应用随机森林。 该模型的特点在于引入人体生理结构作为先验知识,人体被预先表示为多个具有空间约束的部位,且每个部分都被看作是刚体。即先识别人体身体部位,再识别姿势。
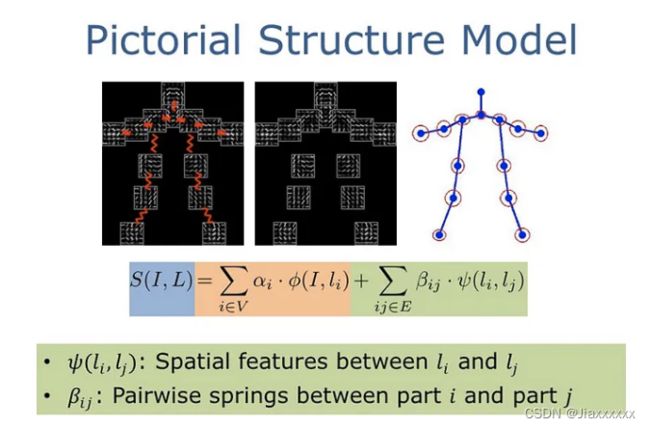
本质上,PSF 的目标是将人体表示为给定输入图像中每个身体部位的坐标集合; PSF 使用非线性联合回归器,理想情况下是两层随机森林回归器。
PSF优势在于当输入图像具有清晰可见的肢体时,这些模型效果很好,但是它们无法捕获和建模隐藏或从某个角度不可见的肢体。
为了克服这些问题,使用了诸如面向直方图的高斯(HOG)、轮廓、直方图等特征构建方法。 尽管使用了这些方法,但经典模型缺乏准确性、相关性和泛化能力。
2.2 基于深度学习的人体姿态估计算法
在计算机视觉任务方面,在HPE中,跟其他任务一样,深度卷积神经网络 (CNN) 的出现导致算法效果开启了腾飞模式。
- CNN 能够从给定的输入图像中提取特征,其精度和准确性比任何其他算法都更高;
- CNN泛化能力强(如果给定的隐藏层中存在足够数量的节点);
- 相比传统经典方法,传统方法中的特征提取、模版是人工制作的,人工设计的特征鲁棒性很差,学习到的特征复杂度有限。而且不一定是科学的,光照条件、拍摄角度等一变化,可能会导致检测失败。
Toshev等人于2014年首次使用CNN来估计人体姿势,从基于经典的方法转向基于深度学习的方法,发布的论文命名为 DeepPose: Human Pose Estimation via Deep Neural Networks.
作者还提出了另一种方法,他们实现了此类回归器的级联,以获得更精确和一致的结果。 他们认为,所提出的深度神经网络可以以整体方式对给定数据进行建模,即网络具有对隐藏姿势进行建模的能力,这对于经典方法来说是不正确的。
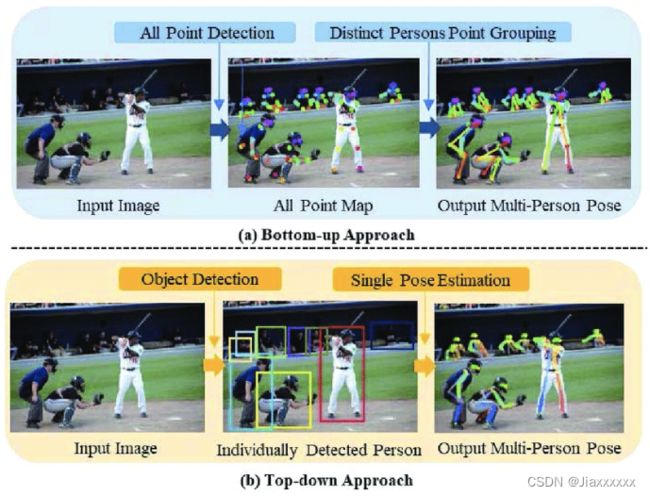
随着深度学习的发展,同时也带来了新的挑战,其中之一是解决多人姿态估计。深度学习在估计单人姿态方面很熟练,但是估计多人姿态时却很困难,原因是一张图像可以包含多个处于不同位置的人,随着人数的增加,相互之间的相互作用增加导致计算复杂性。计算复杂性的增加通常会导致实时推理时间的增加。
为了解决以上问题,引入了两个方法:Top Down和Bottom Up。
- Top Down:自顶向下,即先检测每个人的框,再每个人再单独预测关键点;
- Bottom Up:自底向上,即先检测所有关键点,再组装成每个人
OpenPose
是一种自底而上的方法,网络首先检测图像中的身体部位或关键点,然后组装成一个人。OpenPose 使用多级联的 CNN 作为主要架构,由 VGG-19 卷积网络组成,用于特征提取。
预测分支有两个:
1. 第一个分支预测每个身体部位的置信度图;
2. 第二个分支预测部位亲和力场 (Part Affinity Field, PAF),将不同部位关联起来组成一个人。
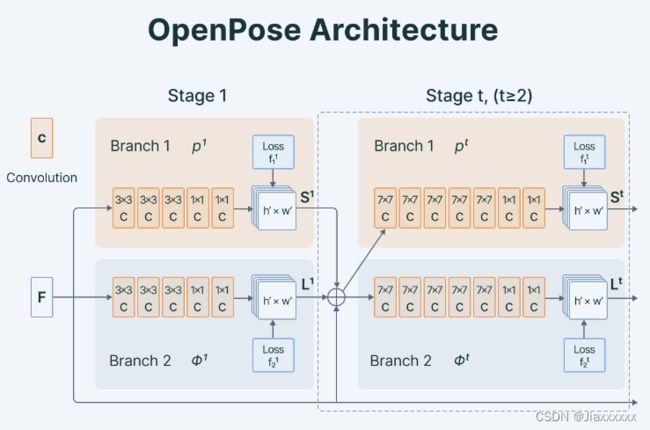
OpenPose pipeline如下:
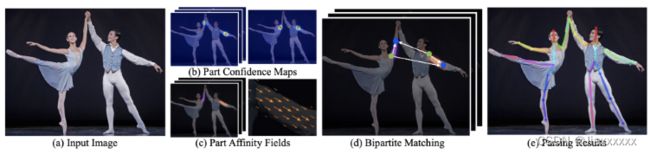
AlphaPose (RMPE)
采用自顶而下的方法,会在预测过程中产生大量定位错误和不准确性。
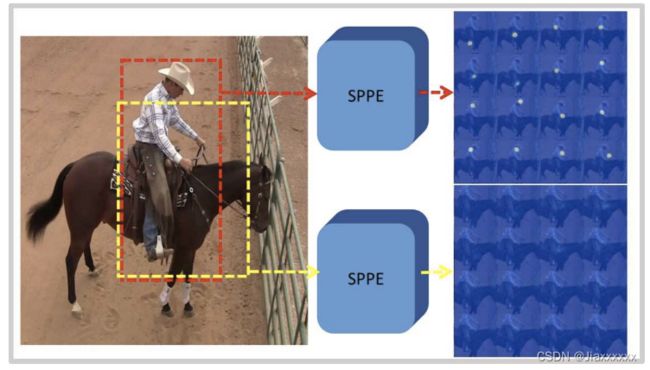
例如,上图显示了两个边界框,红色框代表真实值,而黄色框代表预测边界框。
在分类方面,黄色边界框将被视为对人类进行分类的“正确”边界框,即使使用“正确”的边界框,也无法估计人体姿势。
AlphaPose 的作者通过两步框架解决了人体检测不完美的问题。 在此框架中,他们引入了两个网络:
对称空间变换网络(SSTN): 有助于在输入中裁剪出适当的区域,从而简化分类任务,从而获得更好的性能。
单人姿势估计器(SPPE): 用于提取和估计人体姿势。
AlphaPose 的目标是通过将 SSTN 附加到 SPPE,从不准确的边界框中提取高质量的单人区域。 该方法通过解决不变性问题来提高分类性能,同时提供稳定的框架来估计人体姿势。

3 算法应用
动作捕捉:三维特效场景
人机交互:动作控制、手势控制
VR, AR:元宇宙数字人、抖音尬舞机、3D试衣、虚拟主播
肢体语言理解:机场、交警警察手势翻译、手语翻译
摔倒检测、健身、跳舞、球类、武术运动指导、穴位定位
步态分析、识别身份、异常动作识别
4 Paper
把一些经典的算法paper列举在下面,供大家参考:
- DeepPose: Human Pose Estimation via Deep Neural Networks. CVPR, 2014 首个使用深度卷积神经网络实现人体姿态估计, regression方法
- Efficient Object Localization Using Convolutional Networks, CVPR, 2015 首个使用heatmap方法
- OpenPose 经典多人姿态估计方法, Bottom-Up
- RMPE: Regional Multi-person Pose Estimation, 2018 Top-Down
- DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation Bottom-Up方法
- Mask R CNN 人体检测和关键点检测独立并行, 类似Top-Down方法
- Simple Baselines for Human Pose Estimation and Tracking,EECV, 2018
- HRNet: Deep High-Resolution Representation Learning for Visual Recognition
- RLE: Human Pose Regression with Residual Log-likelihood Estimation