YOLOv5改进 | 添加ECA注意力机制 + 更换主干网络之ShuffleNetV2

前言:Hello大家好,我是小哥谈。本文给大家介绍一种轻量化部署改进方式,即在主干网络中添加ECA注意力机制和更换主干网络之ShuffleNetV2,希望大家学习之后,能够彻底理解其改进流程及方法~!
目录
1.基础概念
2.添加位置
3.添加步骤
4.改进方法
步骤1:common.py文件修改
步骤2:yolo.py文件修改
步骤3:创建自定义yaml文件
步骤4:修改自定义yaml文件
步骤5:验证是否加入成功
步骤6:修改默认参数

1.基础概念
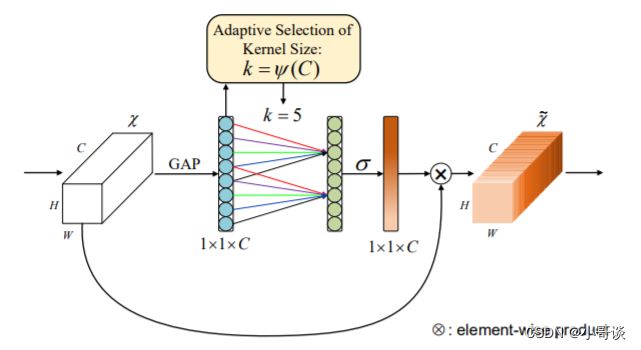
ECA注意力机制:
ECA注意力机制是一种用于提升卷积神经网络特征表示能力的方法。它通过嵌入式通道注意力模块,在保持高效性的同时,引入了通道注意力机制。具体来说,ECA注意力机制在通道维度上增加了注意力机制,以提升特征表示的能力。与SE注意力机制不同的是,ECA注意力机制只包含一个操作——excitation,而没有squeeze操作。这使得ECA注意力机制更加轻量级,适用于计算资源有限的场景。
ECA的结构主要分为两个部分:通道注意力模块和嵌入式通道注意力模块。
(1)通道注意力模块
通道注意力模块是ECA的核心组成部分,它的目标是根据通道之间的关系,自适应地调整通道特征的权重。该模块的输入是一个特征图(Feature Map),通过全局平均池化得到每个通道的全局平均值,然后通过一组全连接层来生成通道注意力权重。这些权重被应用于输入特征图的每个通道,从而实现特征图中不同通道的加权组合。最后,通过一个缩放因子对调整后的特征进行归一化,以保持特征的范围。
(2)嵌入式通道注意力模块
嵌入式通道注意力模块是ECA的扩展部分,它将通道注意力机制嵌入到卷积层中,从而在卷积操作中引入通道关系。这种嵌入式设计能够在卷积操作的同时,进行通道注意力的计算,减少了计算成本。具体而言,在卷积操作中,将输入特征图划分为多个子特征图,然后分别对每个子特征图进行卷积操作,并在卷积操作的过程中引入通道注意力。最后,将这些卷积得到的子特征图进行合并,得到最终的输出特征图。
ShuffleNetV2网络:
ShuffleNetV2是一种轻量级的神经网络模型,它是ShuffleNetV1的改进版本。ShuffleNetV2主要采用了两种技术:通道分离和组卷积。通道分离是指将输入的通道分成两个部分,分别进行不同的计算,然后再将它们合并在一起。这种方法可以减少计算量,提高模型的效率。组卷积是指将卷积操作分成多个小组,每个小组只处理一部分通道,然后再将它们合并在一起。这种方法可以减少参数量,提高模型的泛化能力。
2.添加位置
本文的改进是基于YOLOv5-6.0版本,关于其网络结构具体如下图所示:
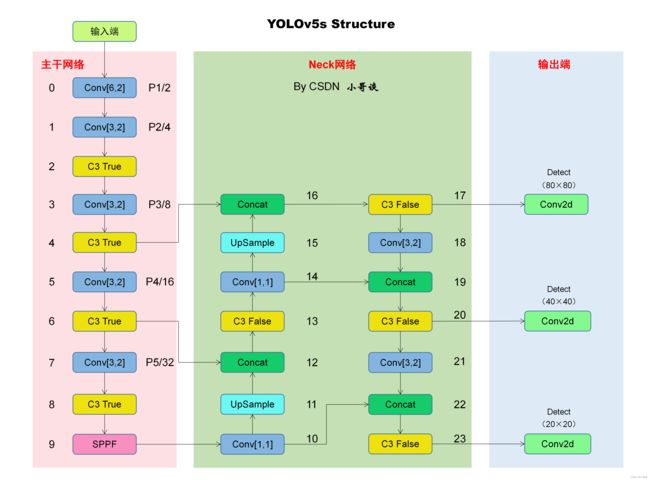
本文的改进是在主干网络中添加ECA注意力机制和更换主干网络之ShuffleNetV2,具体添加位置如下图所示:

所以,本节课改进后的网络结构图具体如下图所示:

3.添加步骤
针对本文的改进,具体步骤如下所示:
步骤1:common.py文件修改
步骤2:yolo.py文件修改
步骤3:创建自定义yaml文件
步骤4:修改自定义yaml文件
步骤5:验证是否加入成功
步骤6:修改默认参数
4.改进方法
步骤1:common.py文件修改
在common.py中添加ECA注意力机制模块和ShuffleNetV2模块,所要添加模块的代码如下所示,将其复制粘贴到common.py文件末尾的位置。
ECA注意力机制代码:
# ECA
class ECA(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, c1, c2, k_size=3):
super(ECA, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)ShuffleNetV2模块代码:
# 更换主干网络之shuffleNetV2
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x
class CBRM(nn.Module):
def __init__(self, c1, c2):
super(CBRM, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(c1, c2, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(c2),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
def forward(self, x):
return self.maxpool(self.conv(x))
class ShuffleNetV2(nn.Module):
def __init__(self, ch_in, ch_out, stride):
super(ShuffleNetV2, self).__init__()
if not (1 <= stride <= 2):
raise ValueError('illegal stride value')
self.stride = stride
branch_features = ch_out // 2
assert (self.stride != 1) or (ch_in == branch_features << 1)
if self.stride > 1:
self.branch1 = nn.Sequential(
self.depthwise_conv(ch_in, ch_in, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(ch_in),
nn.Conv2d(ch_in, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(ch_in if (self.stride > 1) else branch_features,
branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
@staticmethod
def depthwise_conv(i, o, kernel_size, stride=1, padding=0, bias=False):
return nn.Conv2d(i, o, kernel_size, stride, padding, bias=bias, groups=i)
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1) # 按照维度1进行split
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
步骤2:yolo.py文件修改
首先在yolo.py文件中找到parse_model函数这一行,加入ECA、CBAM和ShuffleNetV2。具体如下图所示:

步骤3:创建自定义yaml文件
在models文件夹中复制yolov5s.yaml,粘贴并重命名为yolov5s_ECA_ShuffleNetV2.yaml。具体如下图所示:

步骤4:修改自定义yaml文件
本步骤是修改yolov5s_ECA_ShuffleNetV2.yaml,根据改进后的网络结构图进行修改。
由下面这张图可知,当添加ECA注意力机制和更换主干网络之ShuffleNetV2之后,后面的层数会发生相应的变化,需要修改相关参数。

备注:层数从0开始计算,比如第0层、第1层、第2层......
综上所述,修改后的完整yaml文件如下所示:
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
# Shuffle_Block: [out, stride]
[[ -1, 1, CBRM, [ 32 ] ], # 0-P2/4
[ -1, 1, ShuffleNetV2, [ 128, 2 ] ], # 1-P3/8
[ -1, 3, ShuffleNetV2, [ 128, 1 ] ], # 2
[ -1, 1, ShuffleNetV2, [ 256, 2 ] ], # 3-P4/16
[ -1, 7, ShuffleNetV2, [ 256, 1 ] ], # 4
[ -1, 1, ShuffleNetV2, [ 512, 2 ] ], # 5-P5/32
[ -1, 3, ShuffleNetV2, [ 512, 1 ] ], # 6
[-1, 1, ECA, [512]], # 7
[-1, 1, SPPF, [1024, 5]], # 8
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 12
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 16 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 13], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 19 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 9], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 22 (P5/32-large)
[[16, 19, 22], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
步骤5:验证是否加入成功
在yolo.py文件里,将配置改为我们刚才自定义的yolov5s_ECA_ShuffleNetV2.yaml。
修改1,位置位于yolo.py文件165行左右,具体如图所示:

修改2,位置位于yolo.py文件363行左右,具体如下图所示:
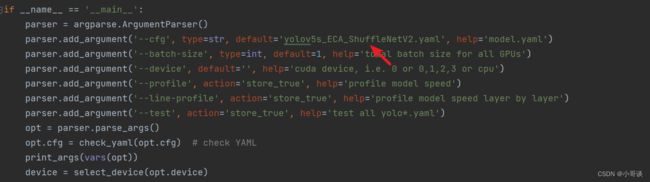
配置完毕之后,点击“运行”,结果如下图所示:

由运行结果可知,与我们前面更改后的网络结构图相一致,证明添加成功了!✅
说明:由上图可以看出,添加ECA注意力机制和更换主干网络之ShuffleNetV2之后,参数量大大减少,所以,该种改进方式适合于轻量化部署。
步骤6:修改默认参数
在train.py文件中找到parse_opt函数,然后将第二行 '--cfg' 的default改为 'models / yolov5s_ECA_ShuffleNetV2.yaml',然后就可以开始进行训练了。

结束语:关于更多YOLOv5学习知识,可参考专栏:《YOLOv5:从入门到实战》