Python反反爬虫:JavaScript 逆向爬虫(二)了解前端 JS 混淆,加密等技术:
下面让我们一起探讨一下JS 的混淆,加密等过程
代码压缩:
这里javascript-obfuscator 也提供了代码压缩功能, 使用其参数 compact 即可完成 JS 代码的压缩,输出为一行内容, 参数 compact的默认值是 true, 如果定义为false, 则混淆后的代码会分行显示:
如果将compact设置为 true, 将会在一行显示:
const code = `
let x = '1' + 1
console.log('x', x)
`
const options = {
compact: true, // 设置为 true, 开启代码压缩功能
controlFlowFlattening: true
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options){
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))运行结果在一行显示, 但是终端没有那么大,所以分行了:

可以看到, 代码变量名进行了混淆,都变成了十六进制形式的字符串, 这是因为启用了一些默认压缩和混淆配置
变量名混淆:
变量名混淆可以通过在 javascript-obfuscator 中配置 identifierNamesGenerator 参数来实现, 我们通过这个参数可以控制变量名的混淆方式,如将其值改为 hexadecimal, 则会将变量名替换为十六进制形式的字符串, 该参数取值如下:
hexadecimal: 将变量名替换为十六进制形式的字符串,如 0xaabc123
mangled: 将变量名替换为普通的简写字符, 如: a, b, c 等
该参数的默认值为 hexadecimal
我们将该参数改为 mangled 试一下:
const code = `
let x = '1' + 1
console.log('x', x)
`
const options = {
compact: true,
controlFlowFlattening: true,
identifierNamesGenerator: 'mangled' // 将变量名改为单个字符,如 a, b ,c
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options){
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))运行结果:

可以看到,这里的变量名都变成了 单个字符, a b 这种形式
如果我们将 identifierNamesGenerator 修改为 hexadecimal 或者不设置,运行结果如下:

选用了mangled, 其代码体积会更小, 单选用了 hexadecimal 的可读性会更低
另外, 我们还可以通过设置 identifiersPrefix 参数 来控制混淆后的变量前缀:
const code = `
let hello = '1' + 1
console.log('hello', hello)
`
const options = {
compact: true,
controlFlowFlattening: true,
// identifierNamesGenerator: 'mangled', // 将变量名改为单个字符,如 a, b ,c
identifiersPrefix: 'evan' // 控制混淆后变量的前缀,
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options){
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))添加完 identifiersPrefix 后,代码运行结果:

可以看到, 混淆后的变量前缀添加了我们自定义的 evan 这个字符串
另外, renameGlobals 这个参数还可以指定是否混淆全局变量和函数名称, 默认值为false:
const code = `
var $ = function(id){
return document.getElementById(id)
};
`
const options = {
compact: true, // 压缩代码
controlFlowFlattening: true,
// identifierNamesGenerator: 'mangled', // 将变量名改为单个字符,如 a, b ,c
identifiersPrefix: 'evan', // 控制混淆后变量的前缀,
renameGlobals: true, // 控制是否混淆全局变量和函数名称
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options){
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))这里我们声明了一个全局变量 $ , 在renameGlobals 设置为 true之后, $ 这个变量也被替换了, 如果后文用到了这个 $ 对象, 可能就会有找不到定义的错误, 因此这个参数可能导致代码执行不通,
如果不设置 renameGlobals 或者将其设置为 false, 结果如下:
 我们可以看到, 最后还是有 $ 这样的声明的, 其全局名称没有被改变
我们可以看到, 最后还是有 $ 这样的声明的, 其全局名称没有被改变
字符串混淆:
字符串混淆, 即将一个字符串声明放在一个数组里, 使之无法被直接搜到, 这可以通过 stringArray 参数来控制, 默认为 true
此外, 我们还可以通过 rotateStringArray 参数来控制数组化后结果的元素顺序, 默认为true, 还可以通过stringArrayEncoding 参数来控制数字的编码形式, 默认不开启编码, 如果将其设置为 true 或 base64, 则会使用Base64 编码, 如果设置为 rc4, 则使用 RC4编码, 另外, 可以通过 stringArrayThreshold 来控制启用编码的概率, 其范围为 0 到 1, 默认值为 0.8。
实例如下:
const code = `
var a = 'hello world'
`
const options = {
compact: true, // 压缩代码
stringArray: true,
rotateStringArray: true,
// stringArrayEncoding: 'base64',
stringArrayThreshold: 1,
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options){
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))可能由于电脑配置或者是 js加密库 版本问题, stringArrayEncoding 这个选项会导致程序报 错, 这里就不演示代码运行结果了, 小伙伴们可以自行尝试一下, 当然,如果在你们电脑上依旧报错,感兴趣的小伙伴可以排查一下报错原因, 欢迎留言告知~~~
另外,我们还可以使用 unicodeEscapeSequence 这个参数对字符串进行 Unicode转码, 使之更加难以辨认:
const code = `
var a = 'hello world'
`
const options = {
compact: false, // 压缩代码
unicodeEscapeSequence: true // 将字符串进行Unicode 转码
// stringArray: true,
// rotateStringArray: true,
// stringArrayEncoding: 'base64',
// stringArrayThreshold: 1,
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options){
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))代码运行结果:
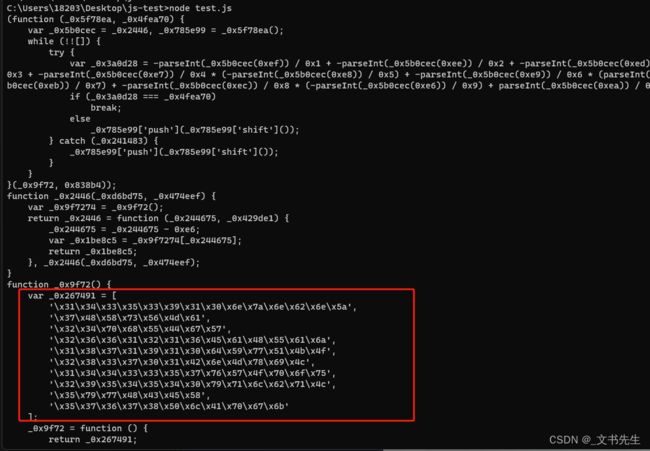
可以看到, 这里字符串被数字化和Unicode化, 非常难辨认,说实话小编也不晓得标记的是不是,但是小编通过Unicode转码前和转码后进行了分辨,猜测是转码后的
在很多JS 逆向的过程中, 一些关键的字符串可能会作为切入点来查找加密入口, 用了这种混淆之后, 如果有人想通过全局搜索的方式搜索 hello 这样的字符串找到加密入口, 也没法搜了
代码自我保护:
我们可以通过设置 selfDefending 参数来开启代码自我保护功能, 开启之后, 混淆后的JS 会强制以一行形式显示, 如果我们将混淆后的代码进行格式化或者重命名, 该段代码将无法执行
示例如下:
const code = `
console.log('hello world')
`
const options = {
// compact: true, // 压缩代码
selfDefending: true
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options){
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))代码运行结果如下:

我们将代码放到控制台, 它的执行结果和之前是一模一样的, 没有任何问题, 如果我们将其进行格式化, 然后沾到浏览器控制台里面, 浏览器会直接卡死无法运行, 这样如果有人对代码进行了格式化, 就无法正常对代码进行运行和调试, 从而起到了保护作用:

如果将混淆后的JS代码使用工具格式化后:

控制流平坦化:
控制流平坦化其实就是将代码的执行逻辑混淆, 使其变得复杂,难读, 其基本思想是将一些逻辑处理块都统一加上一个前驱逻辑块, 每个逻辑块都有前驱逻辑块进行条件判断和分发, 构成一个个闭环逻辑, 这导致整个执行逻辑十分复杂, 难读
比如:
console.log(c);
console.log(a);
console.log(b);
这里有三行代码,一目了然,就是要打印输出 c, b, a 这三个变量的值,但是如果把这段代码进行控制流平坦化处理后, 代码就会变成类似于这样:
const s = "3|1|2".split("|");
let x = 0;
while(true) {
switch (s[x++]){
case "1":
console.log(a);
continue;
case "2":
console.log(b);
continue;
case "3":
console.log(c);
continue;
}
break;
}可以看到, 混淆后的代码首先声明了一个变量s, 它的结果是一个列表, 其实就是 ["3", "1", "2"]
然后下面通过 Switch 语句对 s 中的元素进行了判断, 每个 case 都加上了各自的代码逻辑, 通过这样的处理, 一些连续的执行逻辑就被打破了, 代码被修改为一个 Switch语句, 原本我们可以一眼看出的逻辑是控制台先输出c,然后才是 a, b, 但是现在我们必须结合 Switch 的判断条件和对应 case的内容进行判断, 我们很难再一眼看出每条语句的执行顺序了, 这大大降低了代码的可读性
在javascript-obfuscator中, 我们可以通过 controlFlowFlattening 变量控制是否开启控制流平坦化, 示例如下:
const options = {
compact: false, // 压缩代码
controlFlowFlattening: true
}使用控制流平坦化可以使得执行逻辑更加复杂,难读,目前非常多的前段混淆都会加上这个选项, 但有利必有弊, 启用控制流平坦化后, 代码的执行时间会变长, 最长达1.5倍之多
另外, 我们还能使用 controlFlowFlatteningThreshold 这个参数来控制比例, 取值范围是 0 到 1,
默认值为 0.75 如果将该参数设置为 0, 那相当于将 controlFlowFlattening 设置为 false, 即不开启控制流平坦化
无用代码的注入:
无用代码即不会被执行的代码或对上下文没有任何影响的代码,注入之后可以对现有的 JS 代码的阅读形成干扰, 我们可以使用 deadCodeInjection 参数开启这个选项, 其默认值为 false
const options = {
compact: false, // 压缩代码
deadCodeInjection: true // 开启无用代码注入
}另外,我们还可以通过设置 deadCodeInjectionThreshold参数来控制无用代码注入的比例,该参数的取值范围为 0 到1, 默认值是 0.4
对象键名替换:
如果是一个JS对象, 可以使用 transformObjectKeys来对 对象的键值进行替换:
const code = `
(function(){
var object = {
foo: 'test1',
bar: {
baz: 'test2'
}
};
})();
`
const options = {
compact: false, // 压缩代码
transformObjectKeys: true
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options){
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))
可以看到,Object的变量名倍替换为特殊的变量, 代码的可读性变差, 这样我们就不好直接通过变量名进行搜寻了
禁用控制台输出:
我们可以使用 disableConsoleOutput 来禁用掉 console.log 输出功能, 加大调试难度:
const code = `
console.log("hello world")
`
const options = {
compact: true, // 压缩代码
// transformObjectKeys: true // 替换对象键名
// disableConsoleOutput: true // 禁用控制台输出
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options){
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))没有被禁用:

开启控制台禁用:

此时,如果我们执行这个被混淆过的代码, 控制台将什么都输出不了,因为被禁用了
调试保护:
如果在JS 代码中加入 debugger 关键字, 那么执行到该位置的时候, 就会进入 断点调试模式。如果在代码多个位置都加入debugger关键字, 或者定义某个逻辑反复执行debugger, 就会不断的进入断点调试模式, 原本的代码就无法顺畅执行了,这个过程可以成为调试保护, 即通过反复执行debugger来使得原本的代码无法顺畅执行,
其效果类似于执行如下代码:
setInterval(() => {debugger;}, 3000)如果将这段代码粘贴到控制台, 它就会反复执行 debugger语句, 进入断点调试模式, 从而干扰正常的调试流程,
在 javascript-obfuscator 中, 可以使用 debugProtection 来启用调试保护机制, 还可以使用debug ProtectionInterval 来启用无限调试 debug, 使得代码在调试过程中不断进入断点模式,无法顺畅执行, 配置如下:
const options = {
debugProtrection: true,
debugProtectionInterval: true,
} 混淆后的代码会不断跳到 debugger 代码的位置, 使得整个代码无法顺畅执行
域名锁定:
我们还可以通过控制 domainLock 来控制 JS 代码只能在特定域名下执行, 这样可以降低代码被模拟或盗用的风险
const code = `
console.log('hello world')
`
const options = {
domainLock: ['test.com']
} 这段混淆后的代码只能在指定域名 test.com 下运行,不能在其他网站运行
特殊编码:
另外,还有一些特殊的工具包, 例如:aaencode, jjencode, jsfuck 等,它们可以对代码进行混淆和编码。
例如:
由于我们只是了解前端的一些混淆,加密等技术手段的实现, 这里就不做详细的示范了,感兴趣的小伙伴可以自行操作

以上便是对 JS 混淆方式的介绍和总结, 总的来说, 经过混淆的JS 代码的可读性大大降低, 防护效果也大大增强, 对于爬虫而言, 分析代码的难度也大大增加了
WebAssembly:
