爬虫并发及应用
协成asyncio模块
asyncio即Asynchronous I/O是python一个用来处理并发(concurrent)事件的包,是很多python异步架构的基础,多用于处理高并发网络请求方面的问题。
async:异步
sync:同步
io:input、output输入输出事件
简单来说,asyncio解决的是:IO阻塞导致cpu利用率降低的问题
-------------------------------------------------------------------------------------------------------------------------
为了简化并更好地标识异步,从ython 3.5开始引入了新的语法async和await,可以让coroutine的代码更简洁易读.
asyncio 被用作多个提供高性能 Python 异步框架的基础,包括网络和网站服务,数据库连接库,分布式任务队列等等。
asyncio 往往是构建lo 密集型和高层级 结构化 网络代码的最佳选择。
async与await
● async用于声明一个函数为异步函数,即该函数内部可能会使用到异步操作。
在定义异步函数时,需要在函数定义前加上async关键字。
-------->>>>>
● await用于等待一个异步操作完成。当在一个异步函数中使用await关键字时,该函数会暂停执行,直到等待的异步操作完成并返回结果后,才会继续执行后续代码。
● async.run() :运行协程
=====================================================================
简单示例如下:
import asyncio
import time
async def foo():
print("开始执行foo")
await asyncio.sleep(1) # 模拟异步操作,等待1秒
print("结束执行foo")
async def main():
start = time.time()
print("开始执行main")
await foo() # 等待foo函数执行完毕
print("结束执行main")
print("cost timer:", time.time() - start)
asyncio.run(main()) # 启动主协成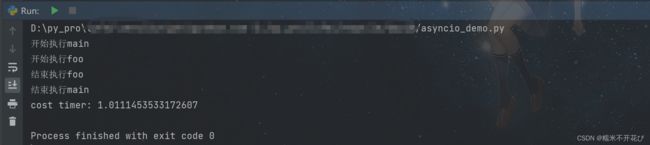
task
task:任务,对协程对象的进一步封装,包含任务的各个状态;
asyncio.Task是Future的一个子类,用于实现协作式多任务的库,且Task对象不能用户手动实例化,通过函数创建,这里重点介绍asyncio.create_task方法:
● async.create_task():创建task
● async.gather() :获取返回值
● asyncio.wait():获取返回值
=====================================================================
以下为3.11版本中,构建协成任务列表的示例:
import asyncio
import time
#主线程
async def foo(i):
print(f"任务{i}启动")
await asyncio.sleep(i) #主线程阻塞
print(f"任务{i}结束")
return i * i #返回每个任务的平方值
#主协成
async def main():
start = time.time()
#显式的创建子协成对象任务,并进行传参
tasks = [asyncio.create_task(foo(1)),
asyncio.create_task(foo(2)),
asyncio.create_task(foo(3))]
await asyncio.wait(tasks) #对协成tasks阻塞的结果收集,得到一个对象
print("cost timer:", time.time() - start) #总耗时
#获取每个任务对象的结果值
for task in tasks:
print(task.done(),task.result())
asyncio.run(main())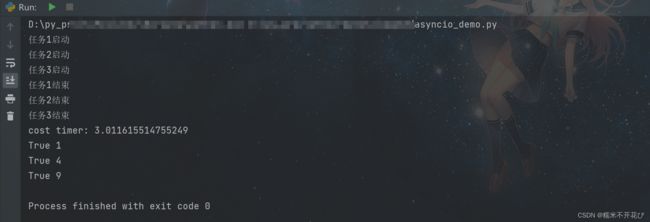
上面的栗子中,是等所有协成任务全部结束后,再打印获取每个任务的平方值
如果,我想要在某一个协成任务结束后,就立即获取到该任务的平方值呢?
很简单,只需要使用callback即可,具体代码如下:
import asyncio
import time
#主线程
async def foo(i):
print(f"任务{i}启动")
await asyncio.sleep(i) #主线程阻塞
print(f"任务{i}结束")
return i * i #返回每个任务的平方值
#获取第二个协成对象的返回值
def task2_callback(ret):
print("异步任务2的结果:",ret.result())
#主协成
async def main():
#显式的创建子协成对象任务,并进行传参
tasks = [asyncio.create_task(foo(1)),
asyncio.create_task(foo(2)),
asyncio.create_task(foo(3))]
#获取第二个协成任务之后的回调函数,即平方值
tasks[1].add_done_callback(task2_callback)
res = await asyncio.gather(*tasks) #使用gather直接收集协成对象的结果
print(res)
start = time.time()
asyncio.run(main())
print("cost timer:", time.time() - start) # 总耗时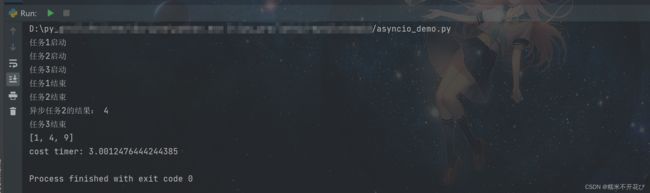
asyncio.gather和asyncio.wait
asyncio.gather和asyncio.wait都是用于并发执行多个协程(coroutine)的函数但它们之间有一些区别:
参数不同:
asyncio.gather接收一个协程列表作为参数,并返回一个新的协程。当所有传入的协程都完成时,这个新的协程也会完成。asyncio.wait接收一个或多个协程以及一个超时时间作为参数。它会阻塞主线程,直到至少有一个协程完成或者超时。返回值不同:
asyncio.gather返回一个新的协程,可以通过调用其result()方法获取所有协程的结果。asyncio.wait返回一个包含已完成协程对象的集合,可以通过遍历这个集合来获取每个协程的结果。异常处理不同:
asyncio.gather会等待所有传入的协程都完成,如果其中任何一个协程抛出异常,那么整个asyncio.gather协程都会抛出异常。asyncio.wait只会等待至少有一个协程完成,如果其中任何一个协程抛出异常,那么asyncio.wait会立即返回已完成的协程对象集合,而不会继续等待其他协程完成。总结来说,
asyncio.gather适用于需要等待所有协程都完成的场景,而asyncio.wait适用于只需要等待至少一个协程完成的场景。
aiohttp包
aiohtpo是一个为Python提供异步HTTP 客户端/服务端编程,基于 asyncio 的异步库。asyncio可以实现单线程并发10操作,其实现了TCP、UDP、SSL等协议,aiohttp就是基于asyncio实现的http框架。
-------->>>>>
我们之前学习过爬虫最重要的模块requests,但它是阻塞式的发起请求,每次请求发起后需阻塞等待其返回响应,不能做其他的事情。
如果需要实现异步爬虫,就不能用requests,可以理解为aiohtpo是requests升级版本。
aiohtpo它是基于 ayncio 的异步模块,可用于实现异步爬虫,优点就是更快于 requests 的同步爬虫。
-------->>>>>
安装方式,pip install aiohttp
一个简单的示例
import aiohttp
import asyncio
async def main():
#异步爬虫session的写法
async with aiohttp.ClientSession() as session:
#url和其他参数正常放在括号里,as response是响应体
async with session.get("http://httpbin.org/headers") as response:
print(await response.text()) #await固定写法,挂载异步循环,获取响应体文本内容
asyncio.run(main())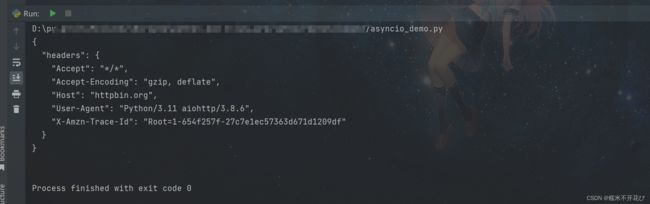
异步爬虫《斗图网》-- 爬取图片
目标url:斗图啦 - 斗图网 - 斗图大会 - 金馆长表情库 - 真正的斗图网站 - doutula.com
import aiohttp
import asyncio
import os
from lxml import etree
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
async def get_img_urls():
url = "https://www.pkdoutu.com/"
async with aiohttp.ClientSession() as session:
async with session.get(url, headers=headers, ssl=False) as response:
selector = etree.HTML(await response.text())
img_urls = selector.xpath('//li[@class="list-group-item"]/div/div/a//img[@data-backup]/@data-backup')
return img_urls
async def download_img(url):
name = os.path.basename(url)
async with aiohttp.ClientSession() as session:
async with session.get(url, ssl=False) as response:
img_name = os.path.basename(url)
path = os.path.join("imgs",img_name)
# 将得到的请求保存到文件中
with open(path, "wb") as f:
f.write(await response.content.read())
print(f"{img_name}下载完成!")
#主线程:
async def main():
img_urls = await get_img_urls()
tasks = [asyncio.create_task(download_img(url)) for url in img_urls]
await asyncio.wait(tasks)
#主逻辑:
if __name__ == '__main__':
start = time.time()
asyncio.run(main())
print(f"整体耗时{time.time() - start}秒")相比于上一篇初识爬虫并发-CSDN博客中的并发下载的速度还要快,非常丝滑:
mu38流视频爬取
m3u8介绍
HLS技术介绍
HLS(HTTP Live Streaming)是一种流媒体传输协议,最初由苹果公司开发并推出。它是一种基于HTTP的流媒体传输协议,旨在提供高质量的实时流媒体传输和适应不同网络条件的能力。HLS技术主要用于在互联网上实时传输音频和视频内容,通常用于直播活动、视频点播等场景。
HLS技术的工作原理如下:
媒体分片(Media Segmentation):源视频或音频内容首先被分割成短小的媒体分片,通常每个分片持续几秒到十几秒不等。
自适应码率(Adaptive Bitrate):每个媒体分片都会根据不同的码率进行编码,以便在不同网络条件下进行自适应码率的选择,以确保在不同带宽条件下的播放质量。
播放列表(Playlist):HLS服务器会生成一个包含媒体分片信息的播放列表文件(通常是M3U8格式),客户端通过该播放列表文件获取媒体分片的URL和其他相关信息。
HTTP传输:客户端通过HTTP协议请求播放列表文件和媒体分片,服务器则会通过HTTP协议响应这些请求,从而实现媒体内容的传输。
实时性和延迟:HLS技术通过调整媒体分片的大小和延迟时间来实现不同的实时性和延迟,通常可以在保证一定延迟的同时提供较好的流畅性和稳定性。
HLS的作用
- 跨平台兼容性:HLS可以在各种设备和平台上进行播放,包括iOS设备、Android设备、PC和智能电视等。
- 自适应码率:HLS可以根据网络带宽和设备性能动态调整码率,以提供更好的观看体验。
- 安全性:HLS可以与数字版权管理系统(DRM)结合使用,以提供内容加密和安全传输。
- 实时性和延迟控制:HLS可以通过调整媒体分片的大小和延迟时间来实现不同的实时性和延迟。
总之,HLS技术是一种流行的流媒体传输协议,适用于许多实时音视频传输的应用场景
M3U8文件详解
M3U文件:
如果想要爬取HLS技术下的资源数据,首先要对M3U8的数据结构和字段定义非常了解。M3U8是一个扩展文件格式,由M3U扩展而来。那么什么是M3U呢?
-----------------------------------------------
M3U文件:
M3U文件是一种常见的音频或视频播放列表文件格式,它是一种文本文件,其中包含了多个媒体文件的路径或URL。M3U文件通常用于描述播放列表,可以包含音乐、视频或流媒体的链接,以便播放器可以按照列表中指定的顺序播放这些媒体文件。
以下是一个简单的M3U文件示例:
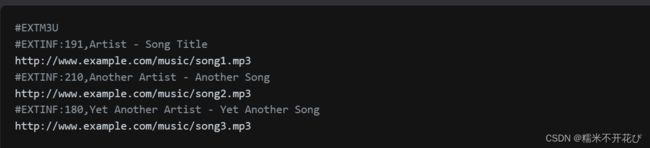
M3U8文件
M3U8文件是一种基于文本的播放列表文件,通常用于指定HLS(HTTP Live Streaming)流媒体的播放顺序和信息。
M3U8文件中包含了一系列媒体分片(.ts文件)的URL,以及其他相关的信息,如媒体时长、标题等。这些信息可以帮助播放器正确地按顺序播放HLS流。
#EXTM3U:每个M3U文件第一行必须是这个tag标识。
#EXT-X-VERSION:版本,此属性可用可不用。
#EXT-X-TARGETDURATION:目标持续时间,是用来定义每个TS的【最大】duration(持续时间)。
#EXT-X-ALLOW-CACHE是否允许允许高速缓存。
#EXT-X-MEDIA-SEQUENCE定义当前M3U8文件中第一个文件的序列号,每个ts文件在M3U8文件中都有固定唯一的序列号。
#EXT-X-DISCONTINUITY:播放器重新初始化
#EXT-X-KEY定义加密方式,用来加密的密钥文件key的URL,加密方法(例如AES-128),以及IV加密向量。(记住)
#EXTINF:指定每个媒体段(ts文件)的持续时间,这个仅对其后面的TS链接有效,每两个媒体段(ts文件)间被这个tag分隔开。
#EXT-X-ENDLIST表明M3U8文件的结束。
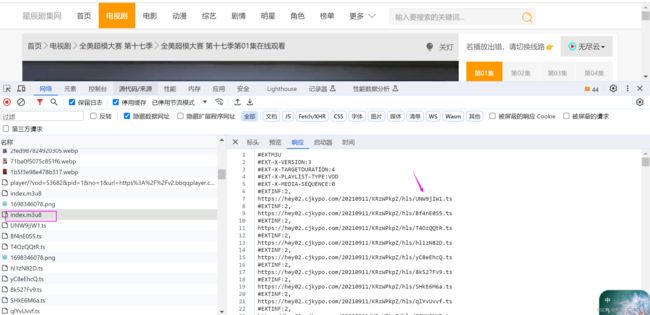
#以上借用他人描述以下是F12中能看到的一个m3u8的文示例:
可以看到index.m3u8中这个文件中包含多个ts片段的链接地址,这个就是上面描述的真正的视频文件。其中任何一个ts文件都是一小段视频,可以单独播放。我们做视频爬虫的目标就是把这些ts文件都爬取下来。
EXT-X-KEY判断视频文件是否加密(借用他人描述):
对于大多数的M3U8视频,一般是不加密的。对于一些重要的视频服务商,他们会对其视频做加密处理。M3U8视频目前的标准加密方式是使用AES-128进行加密处理。如果视频是加密的,就会在M3U8文件中出现以下信息。
#EXT-X-KEY:METHOD=AES-128,URI="https://edu.aliyun.com/hls/2452/clef/0VqtrHq9IkTfOsLqy0iC1FP9342VZm1s",IV=0x3f1c20b9dd4459d0adf972eaba85e0a2其中METHOD为加密方法,标准是AES-128(借用他人描述)。
Key是密钥文件的下载地址(密钥为16字节大小的文件,需要下载)。
IV是加密向量(16个字节大小的16进制数),如果没有IV值则使用b"0000000000000000"填充即可。
注意:Key和IV是AES加密解密的必要信息,这里我们就不用深入讲解。大家只需要知道Key和IV的值会作为解密函数的参数直接调用就可以了。如果文件中没有包含#EXT-X-KEY,则媒体文件将不会被加密。
m3u8实战案例
网站分析详解
在百度上随便找一个在线观看电视剧的网址
我这里用的是新辰剧集网:https://www.tamayaki.com/
很多视频网站是加密的,这里先找到一个不加密的
例如搜索《夏威夷神探第一季》,先下载第一集
打开F12看一下:
可以看到1-1.html是所有加载项的开头,也是第一集电视剧的url
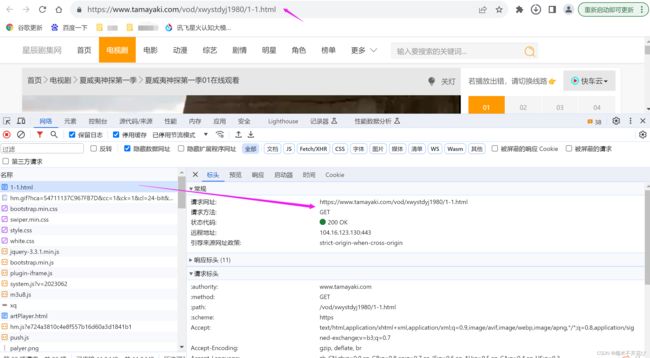
接下来,会一直不断地加载ts
所谓的ts其实就是每一集电视剧的一小个片段,几秒钟的,一集电视机大概几百个ts
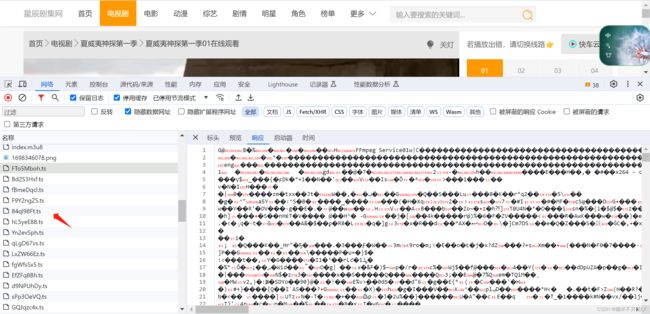
天呐,如果按照ts去爬取,这得下载到什么时候?
然后看看标头:会发现每个ts的url中,除了最后的数字编号不一致,其他都是一样的
再往上找,在第一个ts的上面有一个index.m3u8文件:响应里包含了所有ts片段
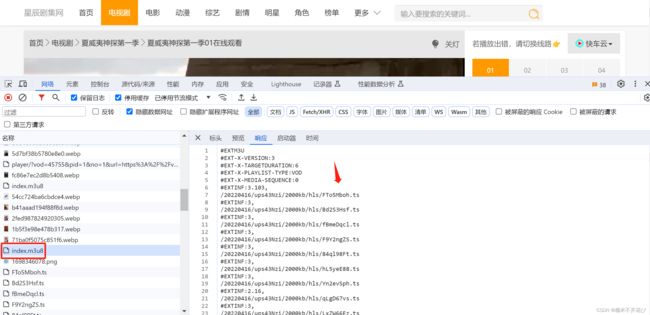
再往上看,还有一个index.m3u8的文件,并且关联是:
第一个index.m3u8的响应中"20220416/ups43Nzi/"也出现在第一个index.m3u8的响应、以及每个ts片段的url里
也就是说:
找到第一个index.m3u8的文件,就可以找到第二个包含所有ts片段的index.m3u8
然后就能关联到所有的ts片段下载
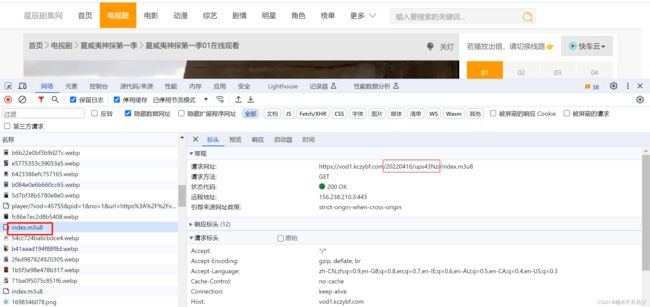
第一个index.m3u8的响应核心是:"2000kb/hls",与第二个index.m3u8和每个ts的url相对应
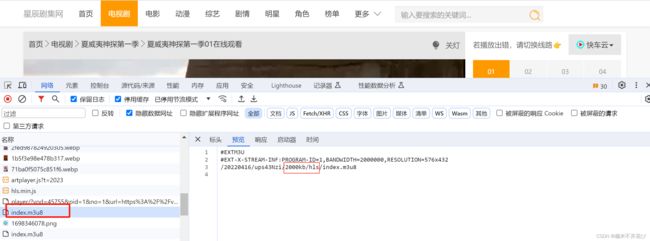
总结来说:
● 第一集视频播放的url:https://www.tamayaki.com/vod/xwystdyj1980/1-1.html,可认为是根节点
● 第一个index.m3u8的url:https://vod1.kczybf.com/20220416/ups43Nzi/index.m3u8,它包含在第一集的视频播放元素中,响应信息是“2000kb/hls”。
●第二个index.m3u8的url:https://vod1.kczybf.com/20220416/ups43Nzi/2000kb/hls/index.m3u8
所以它的域名是由第一个index.m3u8请求路径“vod1.kczybf.com/20220416/ups43Nzi”+第一个index.m3u8的响应“2000kb/hls”组成,响应信息包含所有ts片段信息。
● 后续的每个ts的url:https://vod1.kczybf.com/20220416/ups43Nzi/2000kb/hls/FTo5Mboh.ts
每个ts的url中都包含第二个index.m3u8的请求路径“vod1.kczybf.com/20220416/ups43Nzi/2000kb/hls”+ts片段名称,组成一个完整的url
那么现在基本思路就确定了:
1. 爬取第一集的视频播放页面,也就是1-1.html的url
2. 通过第一个播放的url获取到一个index.m3u8,然后关联到第二个index.m3u8
3. 通过第二个index.m3u8,拿到所有的ts文件
4. 下载第一集所有的ts片段
5. 最后将其合并为一个完整的mp4
问题来了:
第一个index.m3u8(url见上一张截图)与这一集视频播放的url是怎么关联上的,它是怎么来的?
下面提供两种方式,快速定位到index.m3u8
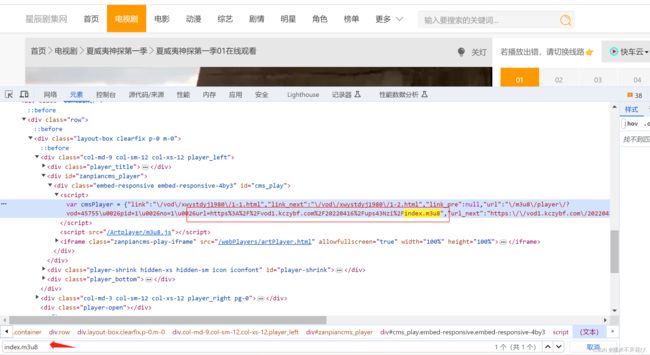
方式1:去元素里搜索index.m3u8,定位到一行源码:
但是源码中 JavaScript 的写法把对应第一个index.m3u8的url做了处理,带了一堆乱七八糟的字符
其实字符去掉,完整的url=第一个index.m3u8de 的url:https://vod1.kczybf.com/20220416/ups43Nzi/index.m3u8
只不过提取这个完整的url稍微麻烦一点
方式2:在【源代码/来源】-> 右侧“XHR/提取断点”点击+,在输入框中输入“m3u8”回车
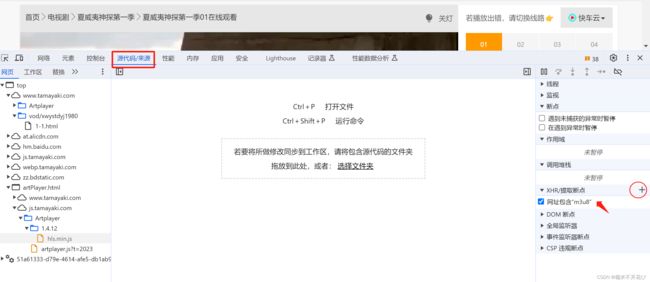
先把源码×掉,重新加载url,进入源码模式直接定位查看
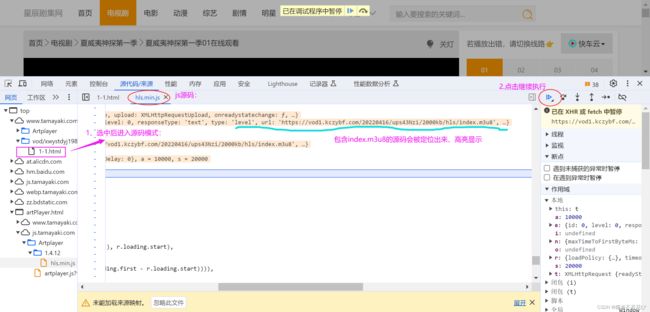
⑴ 协成并发版爬取ts文件
弄清楚了所有我们需要用到的加载项关系之后,就可以开始写代码了~~~
由于串行下载速度较慢,这里直接用协成并发版本
开始写代码:
函数串行版本:
第一版,主要目的是调试,确保能正常下载,但是串行下载速度比较慢
import requests
import os
import re
import time
from bs4 import BeautifulSoup
session = requests.session()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
def get_first_m3u8_link():
# 爬取第一集视频播放的url:
url = 'https://www.tamayaki.com/vod/xwystdyj1980/1-1.html'
res = session.get(url,headers=headers,verify=True)
#正则解析第一个m3u8的url:
html_content = res.text
first_m3u8_link = re.search(r'"url_next":"(https?:\\/\\/[^"]+)', html_content).group(1).replace("\\/", "/")
print("第一个m3u8:", first_m3u8_link)
#抓个名字:
soup = BeautifulSoup(html_content, 'html.parser')
name = soup.find('h1', string=re.compile(r'夏威夷神探第一季01')).get_text()[:-4]
print("视频名称:", name)
return first_m3u8_link,name
def get_second_m3u8_link(first_m3u8_link):
#获取第二个m3u8:直接字符串的分隔与拼接
res = session.get(first_m3u8_link) # 第一个m3u8的url
second_m3u8_link = first_m3u8_link.split("://")[0] + "://" + first_m3u8_link.split("/")[2] + res.text.split("\n")[2]
print("第二个m3u8:", second_m3u8_link)
return second_m3u8_link
def parse_ts(second_m3u8_link):
'''
#爬取m3u8具体的ts文件:
#https://vod1.kczybf.com/20220416/ups43Nzi/2000kb/hls/FTo5Mboh.ts;
ts域名 = 第二个m3u8的请求路径+ts文件路径 = ts真正的url
'''
res = requests.get(second_m3u8_link)
print(res.text)
#解析ts文件url:
ret = re.findall(r"hls/(.*?\.ts)",res.text)
print(ret)
return ret
def download_ts(ts,p):
#下载每一个ts文件:
with open(ts,"wb") as f:
path = os.path.join(p,ts)
res = requests.get(path)
f.write(res.content)
print(f"{ts}下载完成!")
#主程序:
def main():
#(1)爬取播放页面,获取第一个m3u8链接:
first_m3u8_link,name = get_first_m3u8_link()
#(2)获取第二个m3u8链接:
second_m3u8_link = get_second_m3u8_link(first_m3u8_link)
#(3)解析ts文件:
ts_list = parse_ts(second_m3u8_link)
#(4) 下载ts:
p = os.path.dirname(second_m3u8_link)
for ts in ts_list:
download_ts(ts,p)
main()第二版:在串行的基础上优化为协成版本,提高下载速度
import os
import re
import asyncio
import aiohttp
import time
from bs4 import BeautifulSoup
async def get_first_m3u8_link():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"}
# 第一集视频播放的url:
url = 'https://www.tamayaki.com/vod/xwystdyj1980/1-1.html'
# 异步爬虫session的写法
async with aiohttp.ClientSession() as session:
# url和其他参数正常放在括号里,as response是响应体
async with session.get(url,headers=headers,ssl=False) as response:
html_content = await response.text() # await固定写法,挂载异步循环,获取响应体文本内容
first_m3u8_link = re.search(r'"url_next":"(https?:\\/\\/[^"]+)', html_content).group(1).replace("\\/", "/")
print("第一个m3u8:", first_m3u8_link)
#抓个名字:
soup = BeautifulSoup(html_content, 'html.parser')
name = soup.find('h1', string=re.compile(r'夏威夷神探第一季01')).get_text()[:-4]
print("视频名称:", name)
return first_m3u8_link,name
async def get_second_m3u8_link(first_m3u8_link):
async with aiohttp.ClientSession() as session:
async with session.get(first_m3u8_link) as response:
text = await response.text()
#获取第二个m3u8:直接字符串的分隔与拼接:
second_m3u8_link = first_m3u8_link.split("://")[0] + "://" + first_m3u8_link.split("/")[2] + text.split("\n")[2]
print("第二个m3u8:", second_m3u8_link)
return second_m3u8_link
async def parse_ts(second_m3u8_link):
'''
#爬取m3u8具体的ts文件:
#https://vod1.kczybf.com/20220416/ups43Nzi/2000kb/hls/FTo5Mboh.ts;
ts域名 = 第二个m3u8的请求路径+ts文件路径 = ts真正的url
'''
async with aiohttp.ClientSession() as session:
async with session.get(second_m3u8_link) as response:
#解析ts文件url:
text = await response.text()
ret = re.findall(r"hls/(.*?\.ts)", text)
#将所有的ts文件名写入index.m3u8文件中,为合并做准备
abs_path = os.path.abspath("ts文件/index.m3u8")
with open(abs_path,"w") as f:
for ts in ret:
ts_url = "hls/"+ts
f.write(ts_url + "\n")
print(ret)
return ret
async def download_ts(ts, p, retry=3, delay=1):
# 下载每一个ts文件:
for _ in range(retry):
try:
async with aiohttp.ClientSession() as session:
async with session.get(os.path.join(p, ts)) as response:
with open(os.path.join("ts文件", ts), 'wb') as f:
f.write(await response.read())
print(f"{ts} 下载完成!")
break # 如果成功下载,跳出重试循环
except aiohttp.client_exceptions.ServerDisconnectedError:
print(f"下载 {ts} 时出现连接错误,正在重试...")
await asyncio.sleep(delay) # 添加延迟
except aiohttp.client_exceptions.ClientOSError as e:
print(f"下载 {ts} 时出现网络连接错误: {e}")
await asyncio.sleep(delay) # 添加延迟
else:
print(f"下载 {ts} 失败,达到最大重试次数")
#主程序:
async def main():
if not os.path.exists("ts文件"):
os.mkdir("ts文件")
#(1)爬取播放页面,获取第一个m3u8链接:
first_m3u8_link,name = await get_first_m3u8_link()
#(2)获取第二个m3u8链接:
second_m3u8_link = await get_second_m3u8_link(first_m3u8_link)
#(3)解析ts文件:
ts_list = await parse_ts(second_m3u8_link)
#(4) 下载ts:
p = os.path.dirname(second_m3u8_link)
#创建异步tasks任务:
tasks = [asyncio.create_task(download_ts(ts,p)) for ts in ts_list]
await asyncio.wait(tasks) #收集所有的tasks任务
start = time.time()
asyncio.run(main())
print(f"耗时{time.time() - start}秒")就非常优秀哈,效率杠杠的~~
至此,就已经完成了前四步下载任务,但是目前还只是n个ts片段,还剩下最后一个人合并的动作
(2) 基于ffmpeg合并ts文件
ffmpeg的安装步骤(这里以windows为例):
❶ 去ffmpeg官网下载windows版本:官网:https://www.ffmpeg.org/
❷ 本地解压安装包,解压后的原始文件目录如下:
在bin目录中再创建一个文件夹命名为ffmpeg,里面放入ffmpeg.exe
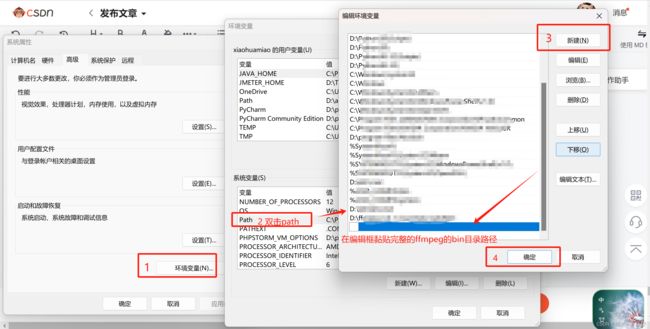
❸ 进行环境变量配置:
此电脑 -> 高级系统设置 -> 环境变量 -> 系统变量(s)中找到path双击 :
在编辑环境变量弹框中点击“新建” -> 在编辑框中黏贴完整的ffmpeg的bin目录路径
最后记得三个弹框的确定都需要点一下,这就完成了环境变量配置。
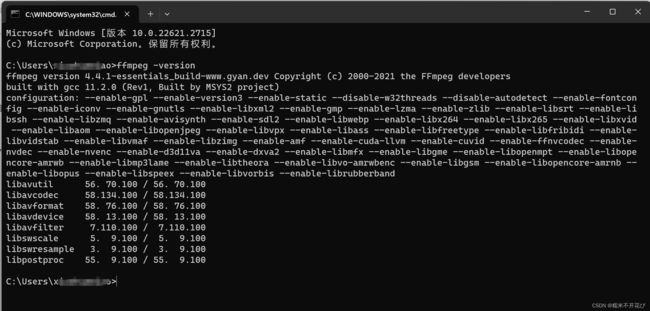
❹ 启动cmd,在终端执行:ffmpeg -version
安装成功会显示本地ffmpeg的版本信息,如下图:
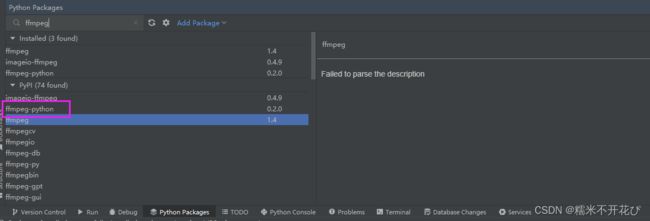
❺ 在Pycharm中安装ffmpeg,选择ffmpeg-python进行安装
最后,在上面的代码中添加ffmpeg视频合并的方法
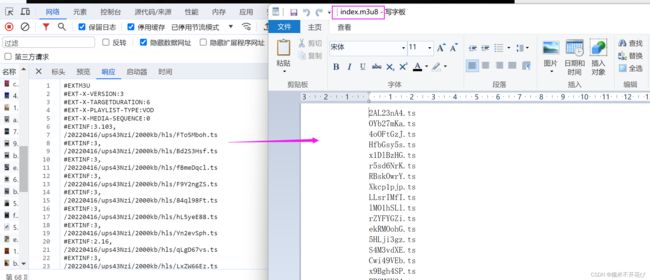
在视频合并之前,必须清楚的是,大几百个ts文件,它肯定是有先后顺序的,ffmpeg能够自动识别ts文件的顺序,进行有序合并,但是需要有一个ts文件列表,所以代码中需要添加生成index.m3u8的文件,提取每个ts的文件名写入该文件,f12中返回有ts文件的路径,我们只需要用ts文件名即可,如下右边的截图:
import os
import re
import asyncio
import aiohttp
import time
from bs4 import BeautifulSoup
async def get_first_m3u8_link():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"}
# 第一集视频播放的url:
url = 'https://www.tamayaki.com/vod/xwystdyj1980/1-1.html'
# 异步爬虫session的写法
async with aiohttp.ClientSession() as session:
# url和其他参数正常放在括号里,as response是响应体
async with session.get(url,headers=headers,ssl=False) as response:
html_content = await response.text() # await固定写法,挂载异步循环,获取响应体文本内容
first_m3u8_link = re.search(r'"url_next":"(https?:\\/\\/[^"]+)', html_content).group(1).replace("\\/", "/")
print("第一个m3u8:", first_m3u8_link)
#抓个名字:
soup = BeautifulSoup(html_content, 'html.parser')
name = soup.find('h1', string=re.compile(r'夏威夷神探第一季01')).get_text()[:-4]
print("视频名称:", name)
return first_m3u8_link,name
async def get_second_m3u8_link(first_m3u8_link):
async with aiohttp.ClientSession() as session:
async with session.get(first_m3u8_link) as response:
text = await response.text()
#获取第二个m3u8:直接字符串的分隔与拼接:
second_m3u8_link = first_m3u8_link.split("://")[0] + "://" + first_m3u8_link.split("/")[2] + text.split("\n")[2]
print("第二个m3u8:", second_m3u8_link)
return second_m3u8_link
async def parse_ts(second_m3u8_link):
'''
#爬取m3u8具体的ts文件:
#https://vod1.kczybf.com/20220416/ups43Nzi/2000kb/hls/FTo5Mboh.ts;
ts域名 = 第二个m3u8的请求路径+ts文件路径 = ts真正的url
'''
async with aiohttp.ClientSession() as session:
async with session.get(second_m3u8_link) as response:
#解析ts文件url:
text = await response.text()
ret = re.findall(r"hls/(.*?\.ts)", text)
# 将所有的ts文件名写入index.m3u8文件中,为合并做准备
abs_path = os.path.abspath("ts文件/index.m3u8")
with open(abs_path, "w") as f:
for ts in ret:
f.write(ts + "\n")
print(ret)
return ret
async def download_ts(ts, p, retry=5, delay=1):
for _ in range(retry):
try:
async with aiohttp.ClientSession() as session:
async with session.get(p + ts) as response:
with open(os.path.join("ts文件", ts), 'wb') as f:
f.write(await response.read())
print(f"{ts} 下载完成!")
return # 下载成功,直接返回
except aiohttp.client_exceptions.ServerDisconnectedError:
print(f"下载 {ts} 时发生了 ServerDisconnectedError 错误,正在重试...")
await asyncio.sleep(delay)
print(f"下载 {ts} 失败!")
async def merge_video(filename):
abs_index_m3u8 = os.path.abspath("ts文件/index.m3u8")
# os.system('chcp 65001')
# 修改 index.m3u8 文件的内容,添加 'file ' 前缀
with open(abs_index_m3u8, "r") as f:
lines = f.readlines()
with open(abs_index_m3u8, "w") as f:
for line in lines:
if line.strip(): # 确保不是空行
f.write(f"file '{os.path.join('ts文件', line.strip())}'\n")
output_file = f"{filename}.mp4"
# 构建 FFmpeg 命令行,并使用本地安装的 FFmpeg 进行视频合并
ffmpeg_path = 'D:\\ffmpeg-4.4.1-essentials_build\\bin'
ffmpeg_executable = 'ffmpeg' # 实际的可执行文件名称
ffmpeg_cmd = f'"{ffmpeg_path}\\{ffmpeg_executable}" -f concat -safe 0 -i {abs_index_m3u8} -c copy {output_file}'
process = await asyncio.create_subprocess_shell(ffmpeg_cmd, stdout=asyncio.subprocess.PIPE, stderr=asyncio.subprocess.PIPE)
# 等待进程结束
stdout, stderr = await process.communicate()
# 检查进程是否成功结束
if process.returncode == 0:
print(f"视频合集完成,输出文件:{output_file}")
else:
print(f"FFmpeg错误: {stderr.decode()}")
#主程序:
async def main():
if not os.path.exists("ts文件"):
os.mkdir("ts文件")
#(1)爬取播放页面,获取第一个m3u8链接:
first_m3u8_link,name = await get_first_m3u8_link()
#(2)获取第二个m3u8链接:
second_m3u8_link = await get_second_m3u8_link(first_m3u8_link)
#(3)解析ts文件:
ts_list = await parse_ts(second_m3u8_link)
#(4) 下载ts:
p = os.path.dirname(second_m3u8_link)
#创建异步tasks任务:
tasks = [asyncio.create_task(download_ts(ts,p)) for ts in ts_list]
await asyncio.wait(tasks) #收集所有的tasks任务
# (5)检查ts文件是否全部下载完成:
downloaded_files = os.listdir("ts文件")
expected_files = [os.path.basename(ts) for ts in ts_list]
if set(expected_files) - set(downloaded_files):
print("部分ts文件未能成功下载,无法进行视频合集!")
return
#(6)视频合集:
await merge_video("my_video")
if __name__ == '__main__':
start = time.time()
asyncio.run(main())
print(f"耗时{time.time() - start}秒")但是,一直没能合并成功,还没搞明白哪里出了问题
等小趴菜空了再继续研究之后,再更新代码,并记录上坑点,也欢迎大佬一起交流~