python数分之PM2.5案例
文章目录
-
- 问题和数据
- PeriodIndex方法介绍
- 绘制北京地区中国数据和美国统计的中国的数据随时间变化图
- 做一个真实的项目
-
- 提出问题
- 观察数据
- 利用jupyter notebook快速分析
- 数据整理
- 数据筛选
- 代码1
- 数据探索性分析和可视化
- 总代码
- 总结
问题和数据
现在我们有北上广、深圳、和沈阳5个城市空气质量数据,请绘制出北京这个城市的PM2.5随时间的变化情况
观察这组数据中的时间结构,并不是字符串,这个时候我们应该怎么办?
数据来源: https://www.kaggle.com/uciml/pm25-data-for-five-chinese-cities
PeriodIndex方法介绍
之前所学习的DatetimeIndex可以理解为时间戳
那么现在我们要学习的PeriodIndex可以理解为时间段
periods = pd.PeriodIndex(year=data["year"],month=data["month"],day=data["day"],hour=data["hour"],freq="H")
# 那么如果给这个时间段降采样呢?
data = df.set_index(periods).resample("10D").mean()
绘制北京地区中国数据和美国统计的中国的数据随时间变化图
import pandas as pd
from matplotlib import pyplot as plt
file_path='C:/Users/ming/Desktop/DataAnalysis-master/day06/code/PM2.5/BeijingPM20100101_20151231.csv'
df=pd.read_csv(file_path)
# # 显示所以的列
# pd.set_option('display.max_columns', None)
# print(df.head(5))
# print(df.info())
# 把分开的时间字符串通过periodIndex的方法转化为pandas的时间类型
period=pd.PeriodIndex(year=df['year'],month=df['month'],day=df['day'],hour=df['hour'],freq="H")
# print(period)
# 增加一列名为datetime
df['datetime']=period
# pd.set_option('display.max_columns', None)
# print(df.head(5))
# 将datetime设置为索引
df.set_index('datetime',inplace=True)
# 按天进行降采样
df=df.resample('7D').mean()
# 看看有多少数据,结果为313
print(df.shape)
pd.set_option('display.max_columns', None)
print(df.head(5))
# 处理缺失数据,删除缺失数据
# print(df['PM_US Post'])
# data=df['PM_US Post'].dropna()
# data_china=df['PM_Dongsi'].dropna()
# # 查看data_china后20行
# print(data_china.tail(20))
# 不取消缺失值
data=df['PM_US Post']
data_china=df['PM_Dongsi']
# 画图
_x=data.index
_x=[i.strftime("%Y%m%d") for i in _x]
_x_china=[i.strftime("%Y%m%d") for i in data_china.index]
_y=data.values
_y_china=data_china.values
plt.figure(figsize=(10,6),dpi=80)
plt.plot(range(len(_x)), _y,label='US Post')
plt.plot(range(len(_x_china)), _y_china,label='CN Post')
# 取步长操作
plt.xticks(range(0,len(_x),10),list(_x)[::10],rotation=45)
plt.legend()
plt.show()

做一个真实的项目
我们不应该只会简单的画图,要学会分析问题
提出问题
在此项目中,你将以一名数据分析师的身份执行数据的探索性分析。你将了解数据分析过程的基本流程。但是在你开始查看数据前,请先思考几个你需要理解的关于PM2.5的问题,例如,如果你是一名环境工作者,你会想要获得什么类型的信息来了解不同城市的环境情况?如果你是一名生活在这个城市的普通人,你可以思考PM 2.5的变化会有什么样的周期性规律?选择什么时段出行空气质量最佳?
观察数据
书写代码如下来查看数据
import pandas as pd
from matplotlib import pyplot as plt
file_path='C:/Users/ming/Desktop/DataAnalysis-master/day06/code/PM2.5/BeijingPM20100101_20151231.csv'
df=pd.read_csv(file_path)
print(df.info())
我们看到结果如下
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 No 52584 non-null int64
1 year 52584 non-null int64
2 month 52584 non-null int64
3 day 52584 non-null int64
4 hour 52584 non-null int64
5 season 52584 non-null int64
6 PM_Dongsi 25052 non-null float64
7 PM_Dongsihuan 20508 non-null float64
8 PM_Nongzhanguan 24931 non-null float64
9 PM_US Post 50387 non-null float64
10 DEWP 52579 non-null float64
11 HUMI 52245 non-null float64
12 PRES 52245 non-null float64
13 TEMP 52579 non-null float64
14 cbwd 52579 non-null object
15 Iws 52579 non-null float64
16 precipitation 52100 non-null float64
17 Iprec 52100 non-null float64
对每列的标题进行解释
No: 行号
year: 年份
month: 月份
day: 日期
hour: 小时
season: 季节
PM: PM2.5浓度 (ug/m^3)
DEWP: 露点 (摄氏温度) 指在固定气压之下,空气中所含的气态水达到饱和而凝结成液态水所需要降至的温度。
TEMP: Temperature (摄氏温度)
HUMI: 湿度 (%)
PRES: 气压 (hPa)
cbwd: 组合风向
Iws: 累计风速 (m/s)
precipitation: 降水量/时 (mm)
Iprec: 累计降水量 (mm)
**问题 1:**至少写下两个你感兴趣的问题,请确保这些问题能够由现有的数据进行回答。
(问题示例:1. 2012年-2015年上海市PM 2.5的数据在不同的月份有什么变化趋势?2. 哪个城市的PM 2.5的含量较低?)
答案:
第一个问题:北京哪一年的PM 2.5平均值最高?
**第二个问题:**2015年各季节北京的平均PM 2.5是多少?
利用jupyter notebook快速分析
import csv
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn
%matplotlib inline
以北京数据为例子,我们先使用Pandas的read_csv函数导入第一个数据集,并使用head、info、describe方法来查看数据中的基本信息。
file_path='C:/Users/ming/Desktop/DataAnalysis-master/day06/code/PM2.5/BeijingPM20100101_20151231.csv'
Beijing_data=pd.read_csv(file_path)
Beijing_data.head()

北京数据中还包含有PM_Dongsi PM_Dongsihuan PM_Nongzhanguan PM_US Post 四个观测站点的数据。并且数据中PM2.5的这四列包含有缺失值“NaN”
Beijing_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 52584 entries, 0 to 52583
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 No 52584 non-null int64
1 year 52584 non-null int64
2 month 52584 non-null int64
3 day 52584 non-null int64
4 hour 52584 non-null int64
5 season 52584 non-null int64
6 PM_Dongsi 25052 non-null float64
7 PM_Dongsihuan 20508 non-null float64
8 PM_Nongzhanguan 24931 non-null float64
9 PM_US Post 50387 non-null float64
10 DEWP 52579 non-null float64
11 HUMI 52245 non-null float64
12 PRES 52245 non-null float64
13 TEMP 52579 non-null float64
14 cbwd 52579 non-null object
15 Iws 52579 non-null float64
16 precipitation 52100 non-null float64
17 Iprec 52100 non-null float64
dtypes: float64(11), int64(6), object(1)
memory usage: 7.2+ MB
变量名PM_US Post中包含空格,这也可能对我们后续的分析造成一定的困扰。因为大多数命令中,都是默认以空格做为值与值之间的分隔符,而不是做为文件名的一部分。因此我们需要将变量名中的空格改为下划线:
Beijing_data.columns = [c.replace(' ', '_') for c in Beijing_data.columns]
Beijing_data.head()

数据整理
现在你已使用单个数据集完成了一些探索,是时候更进一步,将所有数据整理到一个文件中并看看你能发现什么趋势。通过describe函数对数据进行查看,我们可以看出几个PM 2.5观察站的统计数据都很接近,经过进一步的分析,我们会能够发现这几个观测站的数据存在有很强的相关关系(本项目中并未包含,但你可以通过学习后面的统计学课程,自己来完成此部分)。
因为五个数据文件中都包含PM_US Post一列,并且该列的缺失值相对于其他列缺失值较小,因此在下面的分析中我们仅保留该列数据作为PM 2.5的关键数据。在下面的代码中我们也预先对所有城市的season进行了转换,并为数据添加了一个city列,便于对不同城市进行对比分析。
import pandas as pd
files = ['E:/DataAnalysis-master/day06/code/PM2.5/BeijingPM20100101_20151231.csv',
'E:/DataAnalysis-master/day06/code/PM2.5/ChengduPM20100101_20151231.csv',
'E:/DataAnalysis-master/day06/code/PM2.5/GuangzhouPM20100101_20151231.csv',
'E:/DataAnalysis-master/day06/code/PM2.5/ShanghaiPM20100101_20151231.csv',
'E:/DataAnalysis-master/day06/code/PM2.5/ShenyangPM20100101_20151231.csv']
out_columns = ['No', 'year', 'month', 'day', 'hour', 'season', 'PM_US Post']
# create a void dataframe
df_all_cities = pd.DataFrame()
# iterate to write diffrent files
for inx, val in enumerate(files):
df = pd.read_csv(val)
df = df[out_columns]
# create a city column
df['city'] = val.split('PM20')[0]
# map season
df['season'] = df['season'].map({1: 'Spring', 2: 'Summer', 3: 'Autumn', 4: 'Winter'})
# append each file and merge all files into one
df_all_cities = df_all_cities.append(df)
# replace the space in variable names with '_'
df_all_cities.columns = [c.replace(' ', '_') for c in df_all_cities.columns]
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#显示宽度无限长
pd.set_option('display.width', None)
print(df_all_cities.head()) # 看一下处理后的数据,观察数据是否符合我们的要求

数据筛选
接下来我们将会对你在问题1中提出的两个问题进行更进一步的思考。
df_all_cities是我们建立的一个包含所有数据的Pandas Dataframe,考虑到我们的分析目标,我们可能会需要提取部分数据来针对我们感兴趣的具体问题进行分析。为了方便大家对数据进行探索,在下面我们定义了一个filter_data和reading_stats的函数,通过输入不同的条件(conditions),该函数可以帮助我们筛选出这部分的数据。
def filter_data(data, condition):
"""
Remove elements that do not match the condition provided.
Takes a data list as input and returns a filtered list.
Conditions should be a list of strings of the following format:
' '
where the following operations are valid: >, <, >=, <=, ==, !=
Example: "duration < 15", "start_city == 'San Francisco'"
"""
# Only want to split on first two spaces separating field from operator and
# operator from value: spaces within value should be retained.
field, op, value = condition.split(" ", 2)
# check if field is valid
if field not in data.columns.values :
raise Exception("'{}' is not a feature of the dataframe. Did you spell something wrong?".format(field))
# convert value into number or strip excess quotes if string
try:
value = float(value)
except:
value = value.strip("\'\"")
# get booleans for filtering
if op == ">":
matches = data[field] > value
elif op == "<":
matches = data[field] < value
elif op == ">=":
matches = data[field] >= value
elif op == "<=":
matches = data[field] <= value
elif op == "==":
matches = data[field] == value
elif op == "!=":
matches = data[field] != value
else: # catch invalid operation codes
raise Exception("Invalid comparison operator. Only >, <, >=, <=, ==, != allowed.")
# filter data and outcomes
data = data[matches].reset_index(drop = True)
return data
def reading_stats(data, filters = [], verbose = True):
"""
Report number of readings and average PM2.5 readings for data points that meet
specified filtering criteria.
Example: ["duration < 15", "start_city == 'San Francisco'"]
"""
n_data_all = data.shape[0]
# Apply filters to data
for condition in filters:
data = filter_data(data, condition)
# Compute number of data points that met the filter criteria.
n_data = data.shape[0]
# Compute statistics for PM 2.5 readings.
pm_mean = data['PM_US_Post'].mean()
pm_qtiles = data['PM_US_Post'].quantile([.25, .5, .75]).values
# Report computed statistics if verbosity is set to True (default).
if verbose:
if filters:
print('There are {:d} readings ({:.2f}%) matching the filter criteria.'.format(n_data, 100. * n_data / n_data_all))
else:
print('There are {:d} reading in the dataset.'.format(n_data))
print('The average readings of PM 2.5 is {:.2f} ug/m^3.'.format(pm_mean))
print('The median readings of PM 2.5 is {:.2f} ug/m^3.'.format(pm_qtiles[1]))
print('25% of readings of PM 2.5 are smaller than {:.2f} ug/m^3.'.format(pm_qtiles[0]))
print('25% of readings of PM 2.5 are larger than {:.2f} ug/m^3.'.format(pm_qtiles[2]))
seaborn.boxplot(data['PM_US_Post'], showfliers=False)
plt.title('Boxplot of PM 2.5 of filtered data')
plt.xlabel('PM_US Post (ug/m^3)')
# Return three-number summary
return data
在使用中,我们只需要调用reading_stats即可,我们在这个函数中调用了filter_data函数,因此并不需要我们直接操作filter_data函数。下面是对于该函数的一些提示。
reading_stats函数中包含有3个参数:
- 第一个参数(必须):需要被加载的 dataframe,数据将从这里开始分析。
- 第二个参数(可选):数据过滤器,可以根据一系列输入的条件(conditions)来过滤将要被分析的数据点。过滤器应作为一系列条件提供,每个条件之间使用逗号进行分割,并在外侧使用""将其定义为字符串格式,所有的条件使用[]包裹。每个单独的条件应该为包含三个元素的一个字符串:’ '(元素与元素之间需要有一个空格字符来作为间隔),可以使用以下任意一个运算符:>、<、>=、<=、==、!=。数据点必须满足所有条件才能计算在内。例如,[“city == ‘Beijing’”, “season == ‘Spring’”] 仅保留北京市,季节为春天的数据。在第一个条件中, 是city,是 ==, 是’Beijing’,因为北京为字符串,所以加了单引号,它们三个元素之间分别添加一个空格。最后,这个条件需要使用双引号引用起来。这个例子中使用了两个条件,条件与条件之间使用逗号进行分割,这两个条件最后被放在[]之中。
- 第三个参数(可选):详细数据,该参数决定我们是否打印被选择的数据的详细统计信息。如果verbose = True,会自动打印数据的条数,以及四分位点,并绘制箱线图。如果verbose = False, 则只会返回筛选后的dataframe,不进行打印。
代码1
import pandas as pd
from matplotlib import pyplot as plt
import seaborn
files = ['E:/DataAnalysis-master/day06/code/PM2.5/BeijingPM20100101_20151231.csv',
'E:/DataAnalysis-master/day06/code/PM2.5/ChengduPM20100101_20151231.csv',
'E:/DataAnalysis-master/day06/code/PM2.5/GuangzhouPM20100101_20151231.csv',
'E:/DataAnalysis-master/day06/code/PM2.5/ShanghaiPM20100101_20151231.csv',
'E:/DataAnalysis-master/day06/code/PM2.5/ShenyangPM20100101_20151231.csv']
out_columns = ['No', 'year', 'month', 'day', 'hour', 'season', 'PM_US Post']
# create a void dataframe
df_all_cities = pd.DataFrame()
# iterate to write diffrent files
for inx, val in enumerate(files):
df = pd.read_csv(val)
df = df[out_columns]
# create a city column
df['city'] = val.split('PM20')[0]
# map season
df['season'] = df['season'].map({1: 'Spring', 2: 'Summer', 3: 'Autumn', 4: 'Winter'})
# append each file and merge all files into one
df_all_cities = df_all_cities.append(df)
# replace the space in variable names with '_'
df_all_cities.columns = [c.replace(' ', '_') for c in df_all_cities.columns]
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#显示宽度无限长
pd.set_option('display.width', None)
print(df_all_cities.head()) # 看一下处理后的数据,观察数据是否符合我们的要求
def filter_data(data, condition):
"""
Remove elements that do not match the condition provided.
Takes a data list as input and returns a filtered list.
Conditions should be a list of strings of the following format:
' '
where the following operations are valid: >, <, >=, <=, ==, !=
Example: "duration < 15", "start_city == 'San Francisco'"
"""
# Only want to split on first two spaces separating field from operator and
# operator from value: spaces within value should be retained.
field, op, value = condition.split(" ", 2)
# check if field is valid
if field not in data.columns.values:
raise Exception("'{}' is not a feature of the dataframe. Did you spell something wrong?".format(field))
# convert value into number or strip excess quotes if string
try:
value = float(value)
except:
value = value.strip("\'\"")
# get booleans for filtering
if op == ">":
matches = data[field] > value
elif op == "<":
matches = data[field] < value
elif op == ">=":
matches = data[field] >= value
elif op == "<=":
matches = data[field] <= value
elif op == "==":
matches = data[field] == value
elif op == "!=":
matches = data[field] != value
else: # catch invalid operation codes
raise Exception("Invalid comparison operator. Only >, <, >=, <=, ==, != allowed.")
# filter data and outcomes
data = data[matches].reset_index(drop=True)
return data
def reading_stats(data, filters=[], verbose=True):
"""
Report number of readings and average PM2.5 readings for data points that meet
specified filtering criteria.
Example: ["duration < 15", "start_city == 'San Francisco'"]
"""
n_data_all = data.shape[0]
# Apply filters to data
for condition in filters:
data = filter_data(data, condition)
# Compute number of data points that met the filter criteria.
n_data = data.shape[0]
# Compute statistics for PM 2.5 readings.
pm_mean = data['PM_US_Post'].mean()
pm_qtiles = data['PM_US_Post'].quantile([.25, .5, .75]).values
# Report computed statistics if verbosity is set to True (default).
if verbose:
if filters:
print('There are {:d} readings ({:.2f}%) matching the filter criteria.'.format(n_data,
100. * n_data / n_data_all))
else:
print('There are {:d} reading in the dataset.'.format(n_data))
print('The average readings of PM 2.5 is {:.2f} ug/m^3.'.format(pm_mean))
print('The median readings of PM 2.5 is {:.2f} ug/m^3.'.format(pm_qtiles[1]))
print('25% of readings of PM 2.5 are smaller than {:.2f} ug/m^3.'.format(pm_qtiles[0]))
print('25% of readings of PM 2.5 are larger than {:.2f} ug/m^3.'.format(pm_qtiles[2]))
seaborn.boxplot(data['PM_US_Post'], showfliers=False)
plt.title('Boxplot of PM 2.5 of filtered data')
plt.xlabel('PM_US Post (ug/m^3)')
plt.show()
# Return three-number summary
return data
df_test = reading_stats(df_all_cities, ["city == 'E:/DataAnalysis-master/day06/code/PM2.5/Beijing'", "year >= 2012"])
df_test.info()
There are 35064 readings (13.34%) matching the filter criteria.
The average readings of PM 2.5 is 93.23 ug/m^3.
The median readings of PM 2.5 is 67.00 ug/m^3.
25% of readings of PM 2.5 are smaller than 26.00 ug/m^3.
25% of readings of PM 2.5 are larger than 128.00 ug/m^3.

<class 'pandas.core.frame.DataFrame'>
RangeIndex: 35064 entries, 0 to 35063
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 No 35064 non-null int64
1 year 35064 non-null int64
2 month 35064 non-null int64
3 day 35064 non-null int64
4 hour 35064 non-null int64
5 season 35064 non-null object
6 PM_US_Post 34263 non-null float64
7 city 35064 non-null object
dtypes: float64(1), int64(5), object(2)
memory usage: 2.1+ MB
从这里的分析我们可以看出,北京市2012-2015年的PM2.5数据有35064条记录,其中PM_US Post站点的记录有34263条,缺失的数量并不是很大。因为Pandas(我们使用的第三方库)在计算统计数字的时候,会自动排除掉缺失的数值,因此在这里我们没有对缺失值进行任何处理。
北京市在2012-2015年期间PM 2.5的值主要分布
这个区间,平均数值为93.23ug/m^3,
中位数为67.00 ug/m^3,
有25%的读数小于26.00 ug/m^3,
有25%的读数大于128.00 ug/m^3。
数据探索性分析和可视化
得到了想要的数据之后,接下来你可以对数据进行探索性分析和可视化了,并报告你的发现!在这部分我们同样为你提供了一个函数来对PM 2.5的观测平均值制作柱形图的可视化,下面是关于本函数使用方法的一些提示:
第一个参数(必须):筛选后数据的 dataframe,将从这里分析数据。
第二个参数(必须):数据分析进行的维度,在这里可以填入一个column_name,比如’season’, ‘month’, 'hour’等,对数据进行分组分析。
第三个参数(可选):可视化中柱形的颜色,默认为蓝色,你也可以选择你喜爱的其他颜色,比如red,blue,green等。但是请尽量保证一份可视化报告中图表颜色的一致和整洁性。
def univariate_plot(data, key = '', color = 'blue'):
"""
Plot average PM 2.5 readings, given a feature of interest
"""
# Check if the key exists
if not key:
raise Exception("No key has been provided. Make sure you provide a variable on which to plot the data.")
if key not in data.columns.values :
raise Exception("'{}' is not a feature of the dataframe. Did you spell something wrong?".format(key))
# Create plot
plt.figure(figsize=(8,6))
data.groupby(key)['PM_US_Post'].mean().plot(kind = 'bar', color = color)
plt.ylabel('PM 2.5 (ug/m^3)')
plt.title('Average PM 2.5 Reading by {:s}'.format(key), fontsize =14)
plt.show()
return None
我们以北京市2012年之后不同月份的PM 2.5的观测平均值为例,使用univariate_plot函数绘制了可视化:
univariate_plot(df_test, 'month', 'grey')
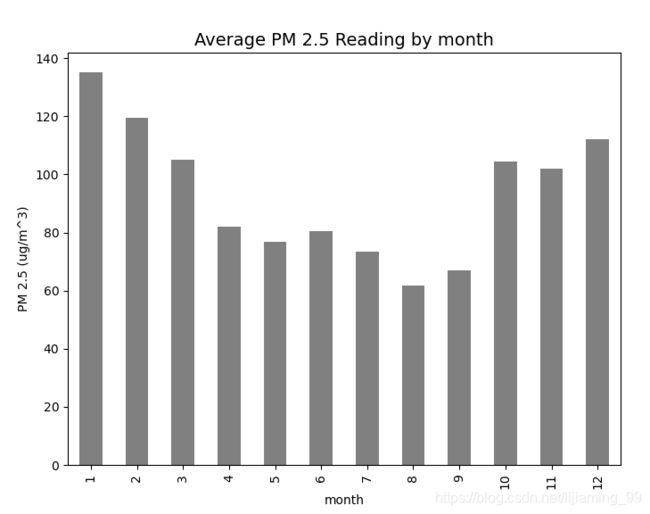
从本可视化中我们可以看出在较温暖的月份(6-10月)空气中的PM 2.5含量较低,而较寒冷的月份,比如(11-1月)空气中的PM 2.5含量较高。
总代码
import pandas as pd
from matplotlib import pyplot as plt
import seaborn
files = ['E:/DataAnalysis-master/day06/code/PM2.5/BeijingPM20100101_20151231.csv',
'E:/DataAnalysis-master/day06/code/PM2.5/ChengduPM20100101_20151231.csv',
'E:/DataAnalysis-master/day06/code/PM2.5/GuangzhouPM20100101_20151231.csv',
'E:/DataAnalysis-master/day06/code/PM2.5/ShanghaiPM20100101_20151231.csv',
'E:/DataAnalysis-master/day06/code/PM2.5/ShenyangPM20100101_20151231.csv']
out_columns = ['No', 'year', 'month', 'day', 'hour', 'season', 'PM_US Post']
# create a void dataframe
df_all_cities = pd.DataFrame()
# iterate to write diffrent files
for inx, val in enumerate(files):
df = pd.read_csv(val)
df = df[out_columns]
# create a city column
df['city'] = val.split('PM20')[0]
# map season
df['season'] = df['season'].map({1: 'Spring', 2: 'Summer', 3: 'Autumn', 4: 'Winter'})
# append each file and merge all files into one
df_all_cities = df_all_cities.append(df)
# replace the space in variable names with '_'
df_all_cities.columns = [c.replace(' ', '_') for c in df_all_cities.columns]
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#显示宽度无限长
pd.set_option('display.width', None)
print(df_all_cities.head()) # 看一下处理后的数据,观察数据是否符合我们的要求
def filter_data(data, condition):
"""
Remove elements that do not match the condition provided.
Takes a data list as input and returns a filtered list.
Conditions should be a list of strings of the following format:
' '
where the following operations are valid: >, <, >=, <=, ==, !=
Example: "duration < 15", "start_city == 'San Francisco'"
"""
# Only want to split on first two spaces separating field from operator and
# operator from value: spaces within value should be retained.
field, op, value = condition.split(" ", 2)
# check if field is valid
if field not in data.columns.values:
raise Exception("'{}' is not a feature of the dataframe. Did you spell something wrong?".format(field))
# convert value into number or strip excess quotes if string
try:
value = float(value)
except:
value = value.strip("\'\"")
# get booleans for filtering
if op == ">":
matches = data[field] > value
elif op == "<":
matches = data[field] < value
elif op == ">=":
matches = data[field] >= value
elif op == "<=":
matches = data[field] <= value
elif op == "==":
matches = data[field] == value
elif op == "!=":
matches = data[field] != value
else: # catch invalid operation codes
raise Exception("Invalid comparison operator. Only >, <, >=, <=, ==, != allowed.")
# filter data and outcomes
data = data[matches].reset_index(drop=True)
return data
def reading_stats(data, filters=[], verbose=True):
"""
Report number of readings and average PM2.5 readings for data points that meet
specified filtering criteria.
Example: ["duration < 15", "start_city == 'San Francisco'"]
"""
n_data_all = data.shape[0]
# Apply filters to data
for condition in filters:
data = filter_data(data, condition)
# Compute number of data points that met the filter criteria.
n_data = data.shape[0]
# Compute statistics for PM 2.5 readings.
pm_mean = data['PM_US_Post'].mean()
pm_qtiles = data['PM_US_Post'].quantile([.25, .5, .75]).values
# Report computed statistics if verbosity is set to True (default).
if verbose:
if filters:
print('There are {:d} readings ({:.2f}%) matching the filter criteria.'.format(n_data,
100. * n_data / n_data_all))
else:
print('There are {:d} reading in the dataset.'.format(n_data))
print('The average readings of PM 2.5 is {:.2f} ug/m^3.'.format(pm_mean))
print('The median readings of PM 2.5 is {:.2f} ug/m^3.'.format(pm_qtiles[1]))
print('25% of readings of PM 2.5 are smaller than {:.2f} ug/m^3.'.format(pm_qtiles[0]))
print('25% of readings of PM 2.5 are larger than {:.2f} ug/m^3.'.format(pm_qtiles[2]))
plt.figure(figsize=(8, 6))
seaborn.boxplot(data['PM_US_Post'], showfliers=False)
plt.title('Boxplot of PM 2.5 of filtered data')
plt.xlabel('PM_US Post (ug/m^3)')
# Return three-number summary
return data
def univariate_plot(data, key='', color='blue'):
"""
Plot average PM 2.5 readings, given a feature of interest
"""
# Check if the key exists
if not key:
raise Exception("No key has been provided. Make sure you provide a variable on which to plot the data.")
if key not in data.columns.values:
raise Exception("'{}' is not a feature of the dataframe. Did you spell something wrong?".format(key))
# Create plot
plt.figure(figsize=(8, 6))
data.groupby(key)['PM_US_Post'].mean().plot(kind='bar', color=color)
plt.ylabel('PM 2.5 (ug/m^3)')
plt.title('Average PM 2.5 Reading by {:s}'.format(key), fontsize=14)
return None
df_test = reading_stats(df_all_cities, ["city == 'E:/DataAnalysis-master/day06/code/PM2.5/Beijing'", "year >= 2012"])
df_test.info()
# univariate_plot(df_test, 'season', 'grey')
# # TO DO:
# please use univariate_plot to visualize your data
univariate_plot(df_test, 'year', 'grey')
univariate_plot(df_test, 'season', 'grey')
plt.show()
总结
从生成问题、整理数据到探索数据。通常,在数据分析过程的这个点,你可能想要通过执行统计检验或将数据拟合到一个模型进行预测,来对我们的数据得出结论。
参考文章