PyTorch自用笔记(第六周-实战2)
PyTorch自用笔记(第六周)
- 十一、循环神经网络RNN&LSTM
-
- 11.1 时间序列表示方法
- 11.2 RNN
- 11.3 时间序列预测实战
- 11.4 梯度弥散与梯度爆炸
- 11.5 LSTM原理
- 11.6 LSTM使用
- 十二、迁移学习
-
- 12.1 自定义数据集
- 12.2 创建模型
- 12.3 训练和测试
- 12.4 风格迁移
- 12.5 补充代码
- 12.6 遇到的问题
十一、循环神经网络RNN&LSTM
11.1 时间序列表示方法
[seq_len, feature_len]:[序列长度, 特征长度/维度/表示方法]
文本信息:
1.one-hot编码:
特定的位置编码为1,其余为0
缺点:稀疏
2.[words, words_vec]
Batch:
[word num, b, word vec]
[b, word num, word vec]
编码方式:
word2vec vs GloVe
from torcchnlp.word_to_vector import GloVe
vectors = GloVe()
vectors['hello']
-1.7494
0.6242
...
-0.6202
20.928
[torch.FloatTensor of size 100]
11.2 RNN
特征:
1.权值共享
2.持续记忆单元(保存语境信息)
PyTorch实现
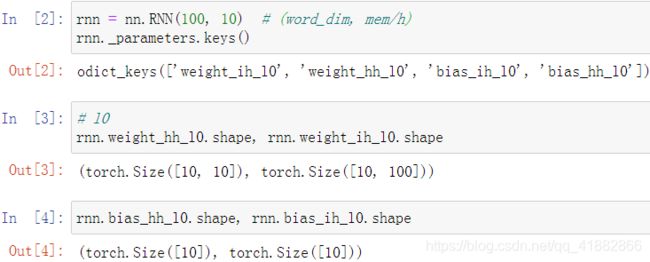
nn.RNN:
__init__
(input_size, hidden_size, num_layers)
input_size:输入的单词向量的维度
hidden_size:memory_size
num_layers:默认为1
forward
out, ht = forward(x, h0)
x:[seq len, b, word vec]
h0/ht:[num layers, b, h dim]
out:[seq len, b, h dim]
单层RNN

注:out_size不会发生变化;h表示最后一个时间戳下memory的状态
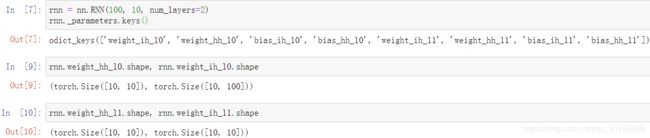
2层RNN-shape验证
nn.RNNCell:
__init__:与RNN完全相同
forward:
ht = rnncell(xt, ht_1)
xt:[b, word vec]
ht_1/ht:[num layers, b, h dim]
out = torch.stack([h1, h2, …, ht])

11.3 时间序列预测实战
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from matplotlib import pyplot as plt
num_time_steps = 50
input_size = 1
hidden_size = 16
output_size = 1
lr = 0.01
class Net(nn.Module):
def __init__(self, ):
super(Net, self).__init__()
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=hidden_size,
num_layers=1,
batch_first=True, # [b, seq, feature]
)
for p in self.rnn.parameters():
nn.init.normal_(p, mean=0.0, std=0.001)
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden_prev): # (self, x, h0)
out, hidden_prev = self.rnn(x, hidden_prev)
# [1, seq, h] => [seq, h]
out = out.view(-1, hidden_size)
out = self.linear(out) # [seq,h] => [seq, 1]
out = out.unsqueeze(dim=0) # => [1, seq, 1]
return out, hidden_prev
# Train
model = Net()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr)
hidden_prev = torch.zeros(1, 1, hidden_size) # h0
for iter in range(6000):
start = np.random.randint(3, size=1)[0] # 0~3
time_steps = np.linspace(start, start + 10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)
y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)
output, hidden_prev = model(x, hidden_prev)
hidden_prev = hidden_prev.detach()
loss = criterion(output, y)
model.zero_grad()
loss.backward()
# for p in model.parameters():
# print(p.grad.norm())
# torch.nn.utils.clip_grad_norm(p, 10)
optimizer.step()
if iter % 100 == 0:
print("Iteration: {} loss {} ".format(iter, loss.item()))
start = np.random.randint(3, size=1)[0]
time_steps = np.linspace(start, start + 10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)
y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)
predictions = []
input = x[:, 0, :]
for _ in range(x.shape[1]):
input = input.view(1, 1, 1)
(pred, hidden_prev) = model(input, hidden_prev)
input = pred
predictions.append(pred.detach().numpy().ravel()[0])
x = x.data.numpy().ravel()
y = y.data.numpy()
plt.scatter(time_steps[:-1], x.ravel(), s=90)
plt.plot(time_steps[:-1], x.ravel())
plt.scatter(time_steps[1:], predictions)
plt.show()
运行结果:
Iteration: 0 loss 0.5240068435668945
Iteration: 100 loss 0.004781486000865698
Iteration: 200 loss 0.0025698889512568712
Iteration: 300 loss 0.0021712062880396843
Iteration: 400 loss 0.003106305142864585
Iteration: 500 loss 0.006951724644750357
Iteration: 600 loss 0.00876646488904953
Iteration: 700 loss 0.0003261358942836523
Iteration: 800 loss 0.001015920890495181
Iteration: 900 loss 0.003062265692278743
Iteration: 1000 loss 0.0043131341226398945
Iteration: 1100 loss 0.00014511161134578288
Iteration: 1200 loss 0.0009089858504012227
Iteration: 1300 loss 0.0009695018525235355
Iteration: 1400 loss 0.001020518015138805
Iteration: 1500 loss 0.0009882590966299176
Iteration: 1600 loss 0.0004311317461542785
Iteration: 1700 loss 0.0012930548982694745
Iteration: 1800 loss 0.0005156291299499571
Iteration: 1900 loss 0.001561652636155486
Iteration: 2000 loss 0.0007380764000117779
Iteration: 2100 loss 0.0012094884878024459
Iteratio