JAVA全栈开发 day15_集合(Set接口、增强For循环、Map体系)
一、增加for遍历集合
- 语法:
for(数据类型 变量名: 数组名或集合){
}//集合遍历 ,推荐使用增加for
1.静态导入
注意事项:
- 方法必须是静态
- 注意不要和本类的方法同名,如果同名,记得加前缀,由此可见,静态导入的方式,意义不太
import static java.lang.Math.abs;
import static java.lang.Math.max;
public static void main(String[] args) {
System.out.println(abs(-100));
System.out.println(java.lang.Math.max(100,200));
}
2.可变参数
-
可变参数:
定义时方法时不知道参数具体个数,可以使用此技术
-
格式:
修饰符 返回值 类型 方法名(数据类型... 参数名){
}
// ... 表示是可变参数
注意事项
- 可以了可变参数,此变量相当于是一个数组
- 如果方法里有多个参数,其它包含可变参数,那可变参数必须放在最后

3.数组转集合
Arrays.asList 此方法可以将数组转集合,但是本质还是数组,所以不能操作集合改变数组大小的方法
List<String> list = Arrays.asList("hello","world","java");
System.out.println(list);
System.out.println(list.get(0));
//UnsupportedOperationException
//list.add("java ee");
list.set(1,"hahaha");
for(String str:list){
System.out.println(str);
}
二、Set 接口
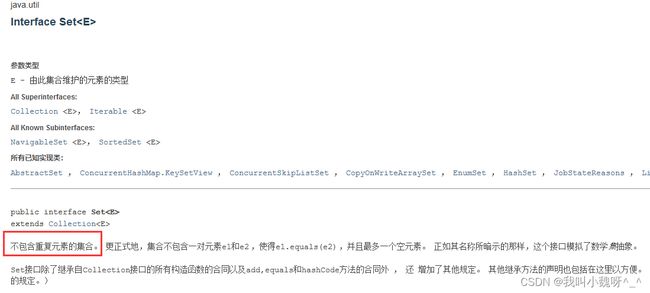
特点: 不包含重复的元素,无序(指的是存数据 ,和取数据的顺序是否一致)
1.HashSet子类
无序,唯一性
2.HashSet 如何实现唯一性(看源码)
HashSet 的底层是使用的HashMap
根据源码分析,得到要保证HashSet里的元素的唯一性,涉及到了Hash值 和equals方法
interface Collection{
....
}
interface Set extends Collection{
...
}
class HashSet implements Set{
// Collection 就相当于单身, Map 一对夫妻
private transient HashMap<E,Object> map;
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
}
class HashMap implements Map{
final float loadFactor;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
}
自定义对象,使用HashSet; 如果想实现当所有属性相同时,认为是重复,不添加;
需要重写hashcode 和 equals
3.去重原理
HashSet 的底层是HashMap, hashMap的底层是哈希表(数组和链表的结合)
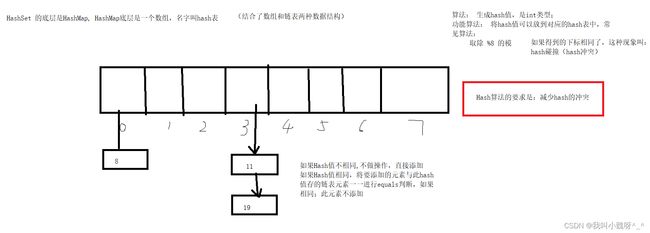
什么是哈希表呢?
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。
看到这张图就有人要问了,这个是怎么存储的呢?
为了方便大家的理解我们结合一个存储流程图来说明一下:
总而言之,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
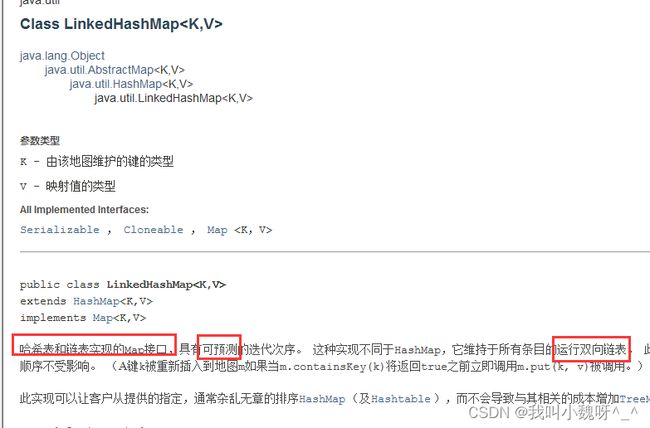
4.LinkedHashSet 子类
底层数据结构:哈希表+链表
保证了唯一性,链表保存有序(存储和取出是一致)
LinkedHashSet<String> hs = new LinkedHashSet<String>();
hs.add("hello");
hs.add("world");
hs.add("java");
hs.add("hello");
for(String str :hs){
System.out.println(str);
}
5.TreeSet 子类
-
特点:排序 和唯一
-
排序 : 自然排序(就是升序)和比较器排序
public static void main(String[] args) {
TreeSet<Integer> treeSet = new TreeSet<Integer>();
treeSet.add(66);
treeSet.add(18);
treeSet.add(12);
treeSet.add(66);
treeSet.add(77);
for(Integer integer: treeSet){
System.out.println(integer);
}
}
三、Map体系
1.概述
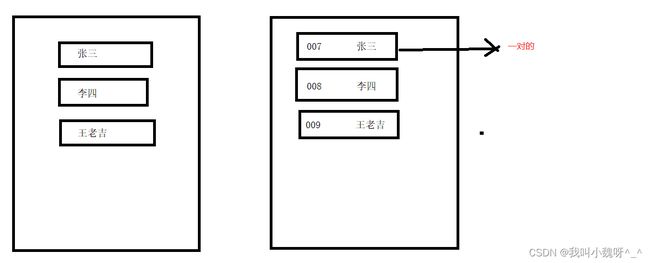
现实生活中,我们常会看到这样的一种集合:IP地址与主机名,身份证号与个人,系统用户名与系统用户对象等,这种一一对应的关系,就叫做映射。Java提供了专门的集合类用来存放这种对象关系的对象,即java.util.Map接口。
我们通过查看Map接口描述,发现Map接口下的集合与Collection接口下的集合,它们存储数据的形式不同,如下图。
Collection中的集合,元素是孤立存在的(理解为单身),向集合中存储元素采用一个个元素的方式存储。Map中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的值。Collection中的集合称为单列集合,Map中的集合称为双列集合。- 需要注意的是,
Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值。
2.Map接口中的常用方法
public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。public V get(Object key)根据指定的键,在Map集合中获取对应的值。boolean containsKey(Object key)判断集合中是否包含指定的键。public Set: 获取Map集合中所有的键,存储到Set集合中。keySet() public Set: 获取到Map集合中所有的键值对对象的集合(Set集合)。
四、作业:
HashMap 去存在自定义对象,自定义对象做为键名
基础题
练习一:Map接口的特点
一、请简述Map 的特点。
练习二:Entry键值对对象
二、说出Entry键值对对象遍历Map集合的原理。
练习三:Map接口中的常用方法
三、请使用Map集合的方法完成添加元素,根据键删除,以及根据键获取值操作。
练习四:Map接口中的方法
四、往一个Map集合中添加若干元素。获取Map中的所有value,并使用增强for和迭代器遍历输出每个value。
练习五:HashMap存储键是自定义对象值是String
五、请使用Map集合存储自定义数据类型Car做键,对应的价格做值。并使用keySet和entrySet两种方式遍历Map集合。
练习六:Map集合的使用(一)
六、现在有一个map集合如下:
Map
map.put(1, “张三丰”);
map.put(2, “周芷若”);
map.put(3, “汪峰”);
map.put(4, “灭绝师太”);
要求:
1.遍历集合,并将序号与对应人名打印。
2.向该map集合中插入一个编码为5姓名为李晓红的信息
3.移除该map中的编号为1的信息
4.将map集合中编号为2的姓名信息修改为"周林"
练习七:Map集合的使用(二)
七、有2个数组,第一个数组内容为:[黑龙江省,浙江省,江西省,广东省,福建省],第二个数组为:[哈尔滨,杭州,南昌,广州,福州],将第一个数组元素作为key,第二个数组元素作为value存储到Map集合中。如{黑龙江省=哈尔滨, 浙江省=杭州, …}。