Selenium 三种等待方式详解 (强制等待、隐式等待、显示等待)
前言
①在进行WEB自动化工作时,一般要等待某一页面元素加载完成后,才能对该元素执行操作,否则自动化脚本会抛出找不到元素的错误,这样就要求我们在UI自动化测试的有些场景上加上等待时间。
②等待方式的设置是保证自动化脚本稳定有效运行的一个非常重要的手段。
强制等待 sleep()
①强制等待,设置固定休眠时间。
②python 的 time 包提供了休眠方法 sleep() ; 导入 time 包后就可以使用 sleep() ,进行脚本的执行过程进行休眠。
代码如下:
# coding = utf-8
from time import sleep
from selenium import webdriver
# 驱动文件路径
driverfile_path = r'D:\coship\Test_Framework\drivers\chromedriver.exe'
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 等待3秒
sleep(3)
driver.find_element_by_css_selector("#kw").send_keys("selenium")
# 退出
driver.quit()隐式等待driver.implicitly_wait(time)
①相当于设置全局的等待,在定位元素时,对所有元素设置超时时间。
②设置一个等待时间,如果在这个等待时间内,网页加载完成,则执行下一步;否则一直等待时间截止,然后再执行下一步。这样也就会有个弊端,程序会一直等待整个页面加载完成,直到超时,但有时候我需要的那个元素早就加载完成了,只是页面上有个别其他元素加载特别慢,我仍要等待页面全部加载完成才能执行下一步。
③隐式等待使得 WebDriver 在查找一个 Element 或者 Elements 数组时,每隔一段特定的时间就会轮询一次DOM,如果 Element 或 Elements 数组没有马上被发现的话。默认设置是0。一旦设置,这个隐式等待会在WebDriver对象实例的整个生命周期起作用。
# coding = utf-8
from selenium import webdriver
# 驱动文件路径
driverfile_path = r'D:\coship\Test_Framework\drivers\chromedriver.exe'
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r'https://www.baidu.com/')
driver.find_element_by_css_selector("#kw").send_keys("selenium")
driver.find_element_by_css_selector("#su").click()
# 隐式等待30秒
driver.implicitly_wait(30)
result = driver.find_elements_by_css_selector("h3.t>a")
for i in result:
print(i.text)
# 退出
driver.quit()显示等待
①上面我们说了隐式等待的一个弊端,如果我想等我要的元素一加载出来就执行下一步,该怎么办?这里就要用到显示等待。
②显式等待是你定义的一段代码,用于等待某个条件发生然后再继续执行后续代码。
③ 在设置时间内,默认每隔一段时间检测一次当前页面元素是否存在,如果超过设置时间检测不到则抛出异常。默认检测频率为0.5s,默认抛出异常为: NoSuchElementException 。
④ WebDriverWait 的帮助文档:
>>> help(WebDriverWait)
Help on class WebDriverWait in module selenium.webdriver.support.wait:
class WebDriverWait(builtins.object)
| Methods defined here:
|
| __init__(self, driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
| Constructor, takes a WebDriver instance and timeout in seconds.
|
| :Args:
| - driver - Instance of WebDriver (Ie, Firefox, Chrome or Remote)
| - timeout - Number of seconds before timing out
| - poll_frequency - sleep interval between calls
| By default, it is 0.5 second.
| - ignored_exceptions - iterable structure of exception classes ignored
during calls.
| By default, it contains NoSuchElementException only.
|
| Example:
| from selenium.webdriver.support.ui import WebDriverWait
|
| element = WebDriverWait(driver, 10).until(lambda x: x.find_element_by_i
d("someId"))
|
| is_disappeared = WebDriverWait(driver, 30, 1, (ElementNotVisibleExcepti
on)).\
|
| until_not(lambda x: x.find_element_by_id("someId").is_displ
ayed())创建一个 WebDriverWait 类的实例对象: WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
主要有4个参数:
driver :浏览器驱动
timeout :等待时间
poll_frequency :检测的间隔时间,默认0.5s
ignored_exceptions :超时后的异常信息,默认抛出NoSuchElementException
⑤显示等待要用到 WebDriverWait 类:
from selenium.webdriver.support.wait import WebDriverWait
代码示例1:
#encoding=utf-8
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
#获取单个页面元素对象,显示等待
#locateType查找的方法类型
#locatorExpression查找的表达式
def getElement(driver,locateType,locatorExpression):
try:
element=WebDriverWait(driver,5).until(lambda x: x.find_element(by=locateType, value=locatorExpression))
except Exception, e:
raise e代码示例2:
# coding = utf-8
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
# 驱动文件路径
driverfile_path = r'D:\coship\Test_Framework\drivers\chromedriver.exe'
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r'https://www.baidu.com/')
driver.find_element_by_css_selector("#kw").send_keys("selenium")
driver.find_element_by_css_selector("#su").click()
# 超时时间为30秒,每0.2秒检查1次,直到class="tt"的元素出现
text = WebDriverWait(driver, 30, 0.2).until(lambda x:x.find_element_by_css_selector(".tt")).text
print(text)
# 退出
driver.quit()代码示例3:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
driver.get('http://www.baidu.com')
element = WebDriverWait(driver, 5, 0.5).until(EC.presence_of_element_located((By.ID, "kw")))
element.send_keys('selenium')在本例中,通过as关键字将 expected_conditions 重命名为EC,并调用 presence_of_element_located() 方法判断元素是否存在。
expected_conditions 类提供的预期条件判断的方法
| 方法 | 说明 |
|---|---|
| title_is | 判断当前页面的 title 是否完全等于(==)预期字符串,返回布尔值 |
| title_contains | 判断当前页面的 title 是否包含预期字符串,返回布尔值 |
| presence_of_element_located | 判断某个元素是否被加到了 dom 树里,并不代表该元素一定可见 |
| visibility_of_element_located | 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于 0 |
| visibility_of | 跟上面的方法做一样的事情,只是上面的方法要传入 locator,这个方法直接传定位到的 element 就好了 |
| presence_of_all_elements_located | 判断是否至少有 1 个元素存在于 dom 树中。举个例子,如果页面上有 n 个元素的 class 都是'column-md-3',那么只要有 1 个元素存在,这个方法就返回 True |
| text_to_be_present_in_element | 判断某个元素中的 text 是否 包含 了预期的字符串 |
| text_to_be_present_in_element_value | 判断某个元素中的 value 属性是否包含 了预期的字符串 |
| frame_to_be_available_and_switch_to_it | 判断该 frame 是否可以 switch进去,如果可以的话,返回 True 并且 switch 进去,否则返回 False |
| invisibility_of_element_located | 判断某个元素中是否不存在于dom树或不可见 |
| element_to_be_clickable | 判断某个元素中是否可见并且是 enable 的,这样的话才叫 clickable |
| staleness_of | 等某个元素从 dom 树中移除,注意,这个方法也是返回 True或 False |
| element_to_be_selected | 判断某个元素是否被选中了,一般用在下拉列表 |
| element_selection_state_to_be | 判断某个元素的选中状态是否符合预期 |
| element_located_selection_state_to_be | 跟上面的方法作用一样,只是上面的方法传入定位到的 element,而这个方法传入 locator |
| alert_is_present | 判断页面上是否存在 alert |
Expected Conditions 的使用场景有2种:
- 直接在断言中使用
- 与 WebDriverWait() 配合使用,动态等待页面上元素出现或者消失
实例:
#encoding:utf-8
# example of how to use https://github.com/SeleniumHQ/selenium/blob/master/py/selenium/webdriver/support/expected_conditions.py
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
import unittest
# dr = webdriver.PhantomJS('phantomjs')
dr = webdriver.Firefox()
# dr = webdriver.Chrome()
url = 'http://www.baidu.com'
search_text_field_id = 'kw'
dr.get(url)
class ECExample(unittest.TestCase):
def test_title_is(self):
''' 判断title是否符合预期 '''
title_is_baidu = EC.title_is(u'百度一下,你就知道')
self.assertTrue(title_is_baidu(dr))
def test_titile_contains(self):
''' 判断title是否包含预期字符 '''
title_should_contains_baidu = EC.title_contains(u'百度')
self.assertTrue(title_should_contains_baidu(dr))
def test_presence_of_element_located(self):
''' 判断element是否出现在dom树 '''
locator = (By.ID, search_text_field_id)
search_text_field_should_present = EC.visibility_of_element_located(locator)
''' 动态等待10s,如果10s内element加载完成则继续执行下面的代码,否则抛出异常 '''
WebDriverWait(dr, 10).until(EC.presence_of_element_located(locator))
WebDriverWait(dr, 10).until(EC.visibility_of_element_located(locator))
self.assertTrue(search_text_field_should_present(dr))
def test_visibility_of(self):
search_text_field = dr.find_element_by_id(search_text_field_id)
search_text_field_should_visible = EC.visibility_of(search_text_field)
self.assertTrue(search_text_field_should_visible('yes'))
def test_text_to_be_present_in_element(self):
text_should_present = EC.text_to_be_present_in_element((By.NAME, 'tj_trhao123'), 'hao123')
self.assertTrue(text_should_present(dr))
@classmethod
def tearDownClass(kls):
print 'after all test'
dr.quit()
print 'quit dr'
if __name__ == '__main__':
unittest.main()以title_is为例分析:
class title_is(object):
"""An expectation for checking the title of a page.
title is the expected title, which must be an exact match
returns True if the title matches, false otherwise."""
def __init__(self, title):
self.title = title
def __call__(self, driver):
return self.title == driver.title可以看到 title_is 实际上是1个类,其 __call__ 方法被定义成是返回1个bool值。因此,一般的用法就是:
# 实例化
the_instance = title_is('expected')
# 直接在实例上调用__call__
the_instance(dr) #return True or False详解webDriverWait()
WebDriverWait(self,driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None).until(self, method, message=)
或者:
WebDriverWait(self, driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None).until_not(self,method, message=)
① self : 函数本身,在实际使用的时候不需要输入。
② driver :webdriver的驱动程序,如(IE、FireFox、chrome、safari等)。
③ timeout :超时时间,默认以秒为单位 poll_frequency ,休眠时间(步长)的间隔,默认为0.5秒,即检测元素是否存在的频率。
④ ignored_exceptions :超时后的异常信息,默认情况下抛 NoSuchElementException 异常信息,可以定义忽略的异常信息。
⑤ WebDriverWait 一般由 until 或 until_not 配合使用。
⑥ until(method, message=") :调用该方法提供的驱动程序做为一个参数,直到返回值不为 False 。
⑦ until_not(method, message=") :调用该方法提供的驱动程序做为一个参数,直到返回值为 False 。
实际应用
在自动化测试中,很多时候都会有等待页面某个元素出现后能进行下一步操作,或者列表中显示加载,直到加载完成后才进行下一步操作,但时间都不确定,如下图所示:
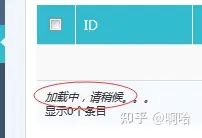
代码如下:
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
import selenium.webdriver.support.expected_conditions as EC
import selenium.webdriver.support.ui as ui
# 一直等待某元素可见,默认超时10秒
def is_visible(locator, timeout=10):
try:
ui.WebDriverWait(driver, timeout).until(EC.visibility_of_element_located((By.XPATH, locator)))
return True
except TimeoutException:
return False
# 一直等待某个元素消失,默认超时10秒
def is_not_visible(locator, timeout=10):
try:
ui.WebDriverWait(driver, timeout).until_not(EC.visibility_of_element_located((By.XPATH, locator)))
return True
except TimeoutException:
return False
# 调用
is_not_visible('//input[@input="search-error"]') 如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一键三连哦!